anyproxy批量自动采集微信公众号文章
我从2014年就开始做微信公众号内容的批量采集,最开始的目的是为了做一个html5的垃圾内容网站。当时垃圾站采集到的微信公众号的内容很容易在公众号里面传播。当时批量采集特别好做,采集入口是公众号的历史消息页。这个入口到现在也是一样,只不过越来越难采集了。采集的方式也更新换代了好多个版本。后来在2015年html5垃圾站不做了,转向将采集目标定位在本地新闻资讯类公众号,前端显示做成了app。所以就形成了一个可以自动采集公众号内容的新闻app。曾经我一直担心有一天微信技术升级之后无法采集内容了,我的新闻app就失效了。但随着微信不断的技术升级,采集方法也随之升级,反而使我越来越有信心。只要公众号历史消息页存在,就能批量采集到内容。所以今天决定将采集方法整理之后写下来。我的方法来源于许多同行的分享精神,所以我也会延续这个精神,将我的成果分享出来。
本篇文章将持续更新,你所看到的内容将保证在看到的时间是可用的。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5MzczNjY2NA==#wechat_webview_type=1&wechat_redirect
=========2017年1月11日更新=========
现在根据不同的微信个人号,会出现两种不同的历史消息页面地址,下面是另一种历史消息页的地址,第一种地址的链接会在anyproxy中显示302跳转:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzA3NDk5MjYzNg==&scene=124#wechat_redirect
第一种链接地址的页面样式:
 第二种链接地址的页面样式:
第二种链接地址的页面样式:
 根据目前掌握的信息,两种页面形式无规律的出现在不同的微信号中,有的微信号始终是第一种页面形式,有的就始终是第二种页面形式。
根据目前掌握的信息,两种页面形式无规律的出现在不同的微信号中,有的微信号始终是第一种页面形式,有的就始终是第二种页面形式。
上面这个链接是一个微信公众号历史消息页面的真实链接,但是我们把这个链接输入到浏览器中会显示:请从微信客户端访问。这是因为实际上这个链接地址还需要几个参数才能正常显示内容。下面我们就来看看可以正常显示内容的完整链接是什么样的:
//第一种链接
http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5NTM1NjczMw==&uin=NzM4MTk1ODgx&key=a226a081696afed0d9dfa0972fa431e116e5c4572ce52343178ad4e9a2b94aeaad6ac4dd87de3e56f72209a73a32e9cc2052f68aca4884e36cf726e99f2671630c741d8e4c29abe4a049d1a71eeb2be5&devicetype=android-17&version=2605033c&lang=zh_CN&nettype=WIFI&ascene=1&pass_ticket=zbA7PswOPKySRpyEYI5kDCjRiljxcpzdbTuVMauFGemgdp8R1DY1uQY49srehWab&wx_header=1
//第二种
http://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzA3NDk5MjYzNg==&scene=124&uin=NzM4MTk1ODgx&key=5134ab1cc362a0324183dbd55a2680d11ccbaa34cdb349ee9be58f5b666092ddb17adf8a88dc788831923f3c6087547d651f04209f72334d511c9e118a3800d7b05a324a38903f79cff940cf749ecd5a&devicetype=android-17&version=2605033c&lang=zh_CN&nettype=WIFI&a8scene=3&pass_ticket=Fo3zjtJcbPfijNHKUIQbV%2BeHsAqhbjJCwzTfV48u%2FCZRRGTmI8oqmHDxxfEL8ke%2B&wx_header=1
这个地址是通过微信客户端打开历史消息页面之后,再使用后面介绍的代理服务器软件获取到的。这里面有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
其中重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz是公众号的一个类似id的参数,每个公众号拥有一个微信的biz,目前极小概率会发生公众号的biz会变化的事件;
剩下的3个参数是有关用户的id和令牌票据之类的意思,这3个参数的值是通过微信的客户端生成后自动补充到地址栏中的。所以我们想采集公众号就必须通过一个微信客户端app。在以前的微信版本中这3个参数还可以获取一次之后在有效期之内多个公众号通用。现在的版本已经是每次访问一个公众号都会更换参数值。
我现在所使用的方法只需要关注__biz这个参数就可以了。
我的采集系统由以下几部分组成:
1、一个微信客户端:可以是一台手机安装了微信的app,或者是用电脑中的安卓模拟器。经过实测ios的微信客户端在批量采集过程中崩溃率高于安卓系统。为了降低成本,我使用的是安卓模拟器。

2、一个微信个人号:为了采集内容不仅需要微信客户端,还要有一个微信个人号专门用于采集,因为这个微信号就干不了其它事情了。
3、本地代理服务器系统:目前使用的方法是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器上。具体安装设置方法在后面详细介绍。
4、文章列表分析与入库系统:我用的是php语言编写的,后文将详细介绍如何分析文章列表和建立采集队列实现批量采集内容。
步骤
一、安装模拟器或使用手机安装微信客户端app,申请微信个人号并登录到app上面。这一点就不过多介绍了,大家都会。
二、代理服务器系统安装
目前我使用的是Anyproxy,AnyProxy 。这个软件的特点是可以获取到https链接的内容。在2016年年初的时候微信公众号和微信文章开始使用https链接。并且Anyproxy可以通过修改rule配置实现向公众号的页面中插入脚本代码。下面开始介绍安装与配置过程。
1、安装 NodeJS
2、在命令行或者终端运行 npm install -g anyproxy,mac系统需要加上sudo;
3、生成RootCA,https需要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy运行命令:sudo anyproxy -i;参数-i是解析HTTPS的意思;
5、安装证书,在手机或安卓模拟器中安装证书:
- 方法一: 启动anyproxy,浏览器打开 http://localhost:8002/fetchCrtFile ,能获取rootCA.crt文件
- 方法二:启动anyproxy,http://localhost:8002/qr_root 可以获取证书路径的二维码,移动端安装时会比较便捷
- 建议通过二维码将证书安装到手机中。
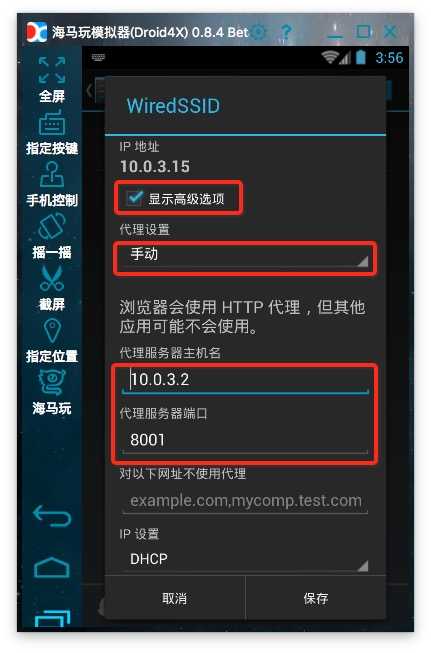
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网关,可以通过吧dhcp设置为静态后看到网关地址,看完后别忘了再设置为自动。手机中的代理服务器地址就是运行anyproxy的电脑的ip地址。代理服务器默认端口是8001;
现在打开微信,点击到任意一个公众号历史消息或文章中,在终端都可以看到响应的代码滚动。如果没有出现,请检查手机的代理设置是否正确。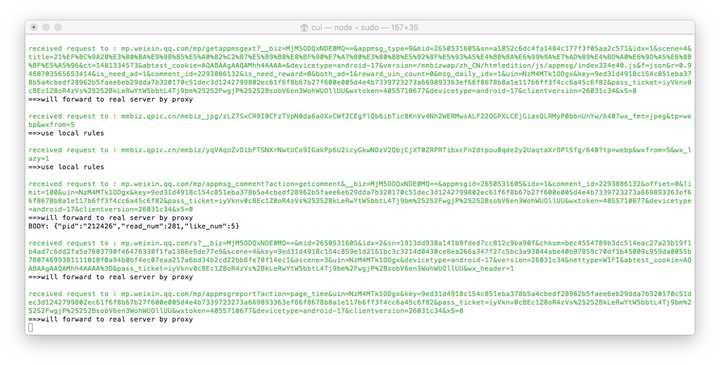
现在打开浏览器地址http://localhost:8002 可以看到anyproxy的web界面。从微信中点开一个历史消息页面,然后再看浏览器的web界面,会滚动出现历史消息页面的地址。
 以/mp/getmasssendmsg开头的网址就是微信历史消息页面。左边一个小锁头表示这个页面是https加密的。现在我们点击一下这一行;
以/mp/getmasssendmsg开头的网址就是微信历史消息页面。左边一个小锁头表示这个页面是https加密的。现在我们点击一下这一行;
=========2017年1月11日更新=========
部分微信号以/mp/getmasssendmsg开头的网址会出现302跳转,跳转到了/mp/profile_ext?action=home开头的地址。所以点开这个地址才可以看到内容。
 右边如果出现了html的文件内容则表示解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机是否正确安装证书。
右边如果出现了html的文件内容则表示解密成功。如果没有内容,请检查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机是否正确安装证书。
现在我们的手机中的所有内容都已经可以明文通过代理服务器了。下面我们要修改配置代理服务器,使公众号内容被获取到。
一、找到配置文件:
mac系统中配置文件的位置在/usr/local/lib/node_modules/anyproxy/lib/;windows系统请原谅我暂时不知道。应该可以根据类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详细阅读注释,这里只是介绍原理,理解后根据自己的条件修改内容):
=========2017年1月11日更新=========
因为出现了两种页面形式,且在不同的微信号中始终显示同一种页面形式,但为了能兼容两种页面形式,以下的代码会保留两种页面形式的判断,你也可以根据自己的页面形式去掉li
replaceServerResDataAsync: function(req,res,serverResData,callback){if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)if(serverResData.toString() !== ""){try {//防止报错退出程序var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则var ret = reg.exec(serverResData.toString());//转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器var http = require('http');http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。res.on('data', function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来})});}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。try {var json = JSON.parse(serverResData.toString());if (json.general_msg_list != []) {HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器}}catch(e){console.log(e);//错误捕捉}callback(serverResData);//直接返回第二页json内容}}}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)try {var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)var ret = reg.exec(serverResData.toString());//转换变量为stringHttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器var http = require('http');http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。res.on('data', function(chunk){callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来})});}catch(e){callback(serverResData);}}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的jsontry {var json = JSON.parse(serverResData.toString());if (json.general_msg_list != []) {HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器}}catch(e){console.log(e);}callback(serverResData);}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时try {HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器}catch(e){}callback(serverResData);}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)try {var http = require('http');http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。res.on('data', function(chunk){callback(chunk+serverResData);})});}catch(e){callback(serverResData);}}else{callback(serverResData);}},
上面这段代码是利用anyproxy可以修改返回页面内容的功能,向页面注入脚本,和将页面内容发送到服务器上。使用这个原理来批量采集公众号内容和阅读量。这段脚本中自定义了一个函数,下面详细介绍:
在rule_default.js文件末尾添加以下代码:
function HttpPost(str,url,path) {//将json发送到服务器,str为json内容,url为历史消息页面地址,path是接收程序的路径和文件名var http = require('http');var data = {str: encodeURIComponent(str),url: encodeURIComponent(url)};content = require('querystring').stringify(data);var options = {method: "POST",host: "www.xxx.com",//注意没有http://,这是服务器的域名。port: 80,path: path,//接收程序的路径和文件名headers: {'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',"Content-Length": content.length}};var req = http.request(options, function (res) {res.setEncoding('utf8');res.on('data', function (chunk) {console.log('BODY: ' + chunk);});});req.on('error', function (e) {console.log('problem with request: ' + e.message);});req.write(content);req.end();
}
上面就是rule规则修改的主要部分,需要将json内容发送到自己的服务器,还要从服务器获取到下一页的跳转地址。这就涉及到了四个php文件:getMsgJson.php、getMsgExt.php、getWxHis.php、getWxPost.php
在详细介绍这4个php文件之前,为了提高采集系统性能和降低崩溃率,我们还可以进行一些修改:
安卓模拟器经常会访问一些http://google.com的地址,这样会导致anyproxy死机,找到函数replaceRequestOption : function(req,option),修改函数内容:
replaceRequestOption : function(req,option){var newOption = option;if(/google/i.test(newOption.headers.host)){newOption.hostname = "www.baidu.com";newOption.port = "80";}return newOption;},
以上就是针对anyproxy的rule文件的修改配置,配置修改完成之后,重新启动anyproxy。mac系统里按control+c中断程序,再输入命令sudo anyproxy -i启动;如果启动报错,可能是程序没有退出干净,端口被占用。这时输入命令ps -a查看占用的pid,再输入命令“kill -9 pid”这里将pid替换成查询到的pid号码。杀死进程之后就可以启动anyproxy了。还是那句话windows的命令请原谅我不太熟悉。
接下来详细介绍服务器上接收程序的设计原理:
(以下代码并不是直接可以用的,只是介绍原理,其中一部分需要根据自己的服务器数据库框架进行编写)
1、getMsgJson.php:这个程序负责接收历史消息的json并解析后存入数据库
<?
$str = $_POST['str'];
$url = $_POST['url'];//先获取到两个POST变量//先针对url参数进行操作
parse_str(parse_url(htmlspecialchars_decode(urldecode($url)),PHP_URL_QUERY ),$query);//解析url地址
$biz = $query['__biz'];//得到公众号的biz
//接下来进行以下操作
//从数据库中查询biz是否已经存在,如果不存在则插入,这代表着我们新添加了一个采集目标公众号。//再解析str变量
$json = json_decode($str,true);//首先进行json_decode
if(!$json){$json = json_decode(htmlspecialchars_decode($str),true);//如果不成功,就增加一步htmlspecialchars_decode
}foreach($json['list'] as $k=>$v){$type = $v['comm_msg_info']['type'];if($type==49){//type=49代表是图文消息$content_url = str_replace("\\", "", htmlspecialchars_decode($v['app_msg_ext_info']['content_url']));//获得图文消息的链接地址$is_multi = $v['app_msg_ext_info']['is_multi'];//是否是多图文消息$datetime = $v['comm_msg_info']['datetime'];//图文消息发送时间//在这里将图文消息链接地址插入到采集队列库中(队列库将在后文介绍,主要目的是建立一个批量采集队列,另一个程序将根据队列安排下一个采集的公众号或者文章内容)//在这里根据$content_url从数据库中判断一下是否重复if('数据库中不存在相同的$content_url') {$fileid = $v['app_msg_ext_info']['fileid'];//一个微信给的id$title = $v['app_msg_ext_info']['title'];//文章标题$title_encode = urlencode(str_replace(" ", "", $title));//建议将标题进行编码,这样就可以存储emoji特殊符号了$digest = $v['app_msg_ext_info']['digest'];//文章摘要$source_url = str_replace("\\", "", htmlspecialchars_decode($v['app_msg_ext_info']['source_url']));//阅读原文的链接$cover = str_replace("\\", "", htmlspecialchars_decode($v['app_msg_ext_info']['cover']));//封面图片$is_top = 1;//标记一下是头条内容//现在存入数据库echo "头条标题:".$title.$lastId."\n";//这个echo可以显示在anyproxy的终端里}if($is_multi==1){//如果是多图文消息foreach($v['app_msg_ext_info']['multi_app_msg_item_list'] as $kk=>$vv){//循环后面的图文消息$content_url = str_replace("\\","",htmlspecialchars_decode($vv['content_url']));//图文消息链接地址//这里再次根据$content_url判断一下数据库中是否重复以免出错if('数据库中不存在相同的$content_url'){//在这里将图文消息链接地址插入到采集队列库中(队列库将在后文介绍,主要目的是建立一个批量采集队列,另一个程序将根据队列安排下一个采集的公众号或者文章内容)$title = $vv['title'];//文章标题$fileid = $vv['fileid'];//一个微信给的id$title_encode = urlencode(str_replace(" ","",$title));//建议将标题进行编码,这样就可以存储emoji特殊符号了$digest = htmlspecialchars($vv['digest']);//文章摘要$source_url = str_replace("\\","",htmlspecialchars_decode($vv['source_url']));//阅读原文的链接//$cover = getCover(str_replace("\\","",htmlspecialchars_decode($vv['cover'])));$cover = str_replace("\\","",htmlspecialchars_decode($vv['cover']));//封面图片//现在存入数据库echo "标题:".$title.$lastId."\n";}}}}}
?>
再次强调代码只是原理,其中一部分注视的代码要自己编写。
2、getMsgExt.php获取文章阅读量和点赞量的程序
<?
$str = $_POST['str'];
$url = $_POST['url'];//先获取到两个POST变量
//先针对url参数进行操作
parse_str(parse_url(htmlspecialchars_decode(urldecode($url)),PHP_URL_QUERY ),$query);//解析url地址
$biz = $query['__biz'];//得到公众号的biz
$sn = $query['sn'];
//再解析str变量
$json = json_decode($str,true);//进行json_decode//$sql = "select * from `文章表` where `biz`='".$biz."' and `content_url` like '%".$sn."%'" limit 0,1;
//根据biz和sn找到对应的文章$read_num = $json['appmsgstat']['read_num'];//阅读量
$like_num = $json['appmsgstat']['like_num'];//点赞量
//在这里同样根据sn在采集队列表中删除对应的文章,代表这篇文章可以移出采集队列了
//$sql = "delete from `队列表` where `content_url` like '%".$sn."%'" //然后将阅读量和点赞量更新到文章表中。
exit(json_encode($msg));//可以显示在anyproxy的终端里
?>
3、getWxHis.php、getWxPost.php两个程序比较类似,一起介绍
==========2017年1月11日更新==========
因为出现了两种页面表现形式,拼接历史消息页面的地址也应该发生改变,但是目前实测,即使微信客户端出现的是第二种页面表现形式,也可以将第一种页面的链接地址发送给微信,同样有效。
<?
//getWxHis.php 当前页面为公众号历史消息时,读取这个程序
//在采集队列表中有一个load字段,当值等于1时代表正在被读取
//首先删除采集队列表中load=1的行
//然后从队列表中任意select一行
if('队列表为空'){//队列表如果空了,就从存储公众号biz的表中取得一个biz,这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,就得到时间戳最小的一个公众号记录,并取得它的biz$url = "http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=".$biz."#wechat_webview_type=1&wechat_redirect";//拼接公众号历史消息url地址(第一种页面形式)$url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=".$biz."&scene=124#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
}else{//取得当前这一行的content_url字段$url = $content_url;//将load字段update为1
}
echo "<script>setTimeout(function(){window.location.href='".$url."';},2000);</script>";//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
?>
<?
//getWxPost.php 当前页面为公众号文章页面时,读取这个程序
//首先删除采集队列表中load=1的行
//然后从队列表中按照“order by id asc”选择多行(注意这一行和上面的程序不一样)if(!empty('队列表') && count('队列表中的行数')>1){//(注意这一行和上面的程序不一样)//取得第0行的content_url字段$url = $content_url;//将第0行的load字段update为1}else{//队列表还剩下最后一条时,就从存储公众号biz的表中取得一个biz,这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,就得到时间戳最小的一个公众号记录,并取得它的biz$url = "http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=".$biz."#wechat_webview_type=1&wechat_redirect";//拼接公众号历史消息url地址(第一种页面形式)$url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=".$biz."&scene=124#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。}echo "<script>setTimeout(function(){window.location.href='".$url."';},2000);</script>";//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
?>
这两段程序的意义是:从队列表中读取出下一个采集内容的信息,如果是历史消息页,则将biz拼接到地址中(注意:评论区有朋友以为key和pass_ticket也要拼接,实则不需要),通过js的方式输出到页面,如果下一条是文章,则将历史消息列表json中的文章地址直接输出为js。同样文章内容的地址中不包含uin和key这样的参数,这些参数都是由客户端自动补充的。
这两个程序的微小差别是因为当读取公众号历史消息页面时,anyproxy会同时做两件事,第一是将历史消息的json发送到服务器,第二是获取到下一页的链接地址。但是这两个操作是存在时间差的,第一次读取下一页地址时候本来应该是得到当前这个公众号文章的第一条链接地址,但是这时候历史消息的json还没有发送到服务器,所以只能得到第二个公众号的历史消息页面。在读取第二个公众号历史消息页面之后得到的下一页地址则是第一个公众号的第一篇文章的地址。当队列还剩下一条记录时,就需要再去取得下一个公众号的链接地址,否则如果当队列空了再去取得下一个公众号的链接地址,就会循环到上面提到的第一次读取时的情况,这样就会出现两个公众号历史消息列表和文章采集穿插进行的情况。
刚才这4个PHP程序提到了几个数据表,下面再讲一下数据表如何设计。这里只介绍一些主要字段,现实应用中还会根据自己程序的不同添加上其它有必要的字段。
1、微信公众号表
CREATE TABLE `weixin` (`id` int(11) NOT NULL AUTO_INCREMENT,`biz` varchar(255) DEFAULT '' COMMENT '公众号唯一标识biz',`collect` int(11) DEFAULT '1' COMMENT '记录采集时间的时间戳',PRIMARY KEY (`id`)
) ;
2、微信文章表
CREATE TABLE `post` (`id` int(11) NOT NULL AUTO_INCREMENT,`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '文章对应的公众号biz',`field_id` int(11) NOT NULL COMMENT '微信定义的一个id,每条文章唯一',`title` varchar(255) NOT NULL DEFAULT '' COMMENT '文章标题',`title_encode` text CHARACTER SET utf8 NOT NULL COMMENT '文章编码,防止文章出现emoji',`digest` varchar(500) NOT NULL DEFAULT '' COMMENT '文章摘要',`content_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '文章地址',`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '阅读原文地址',`cover` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '封面图片',`is_multi` int(11) NOT NULL COMMENT '是否多图文',`is_top` int(11) NOT NULL COMMENT '是否头条',`datetime` int(11) NOT NULL COMMENT '文章时间戳',`readNum` int(11) NOT NULL DEFAULT '1' COMMENT '文章阅读量',`likeNum` int(11) NOT NULL DEFAULT '0' COMMENT '文章点赞量',PRIMARY KEY (`id`)
) ;
3、采集队列表
CREATE TABLE `tmplist` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`content_url` varchar(255) DEFAULT NULL COMMENT '文章地址',`load` int(11) DEFAULT '0' COMMENT '读取中标记',PRIMARY KEY (`id`),UNIQUE KEY `content_url` (`content_url`)
) ;
以上就是由微信客户端、微信号、anyproxy代理服务器、PHP程序、mysql数据库共同组成的微信公众号文章批量自动采集系统。
anyproxy批量自动采集微信公众号文章相关推荐
- python公众号文章_python采集微信公众号文章
本文实例为大家分享了python采集微信公众号文章的具体代码,供大家参考,具体内容如下 在python一个子目录里存2个文件,分别是:采集公众号文章.py和config.py. 代码如下: 1.采集公 ...
- 获取、采集 微信公众号文章点赞阅读数量,实时获取点赞阅读
讲解客户端如何进行采集.首先我们看一下微信文章的永久链接的格式 :https://mp.weixin.qq.com/s?__biz=MzAwMDE0OTU5Nw==&mid=265748275 ...
- 爬虫实战教程:采集微信公众号文章
一.场景简介 1.场景描述:通过搜狗采集微信公众号的文章 2.入口网址:https://weixin.sogou.com/weixin?type=1&s_from=input&quer ...
- php公众号批量推送,微信公众号文章如何批量发送给指定的用户
微信公众号文章如何批量发送给指定的用户 导读:小编根据大家的需要整理了一份关于<微信公众号文章如何批量发送给指定的用户>的内容,具体内容:微信公众号的文章群发的时候,会发给所有的用户,但是 ...
- 采集微信公众号文章只需几步(非搜狗微信)
我们先去下载采集微信文章软件或者百度"小蜜蜂公众号文章助手"下载最新版 第一步:打开软件 第二步:登录微信电脑版 点击"公众号" 选择要采集的公众号 点击右上角 ...
- Python批量爬取微信公众号文章中的图片重建PowerPoint文件
开学第一课:一定不要这样问老师Python问题 董付国老师Python系列教材推荐与选用参考 3000道Python习题免费在线练习 ============= 版权声明:由于公众号后台规则问题,本文 ...
- [乐意黎]phpQuery采集微信公众号文章乱码
终于找到解决方案了,这是一个值得庆祝的事情.... 原来是因为微信在源码中加入了防采集代码<!--headTrap<body></body><head>< ...
- 微信公众号文章中的音乐怎么设置自动播放
1.搜微信公众号登录,点网"微信公众号官网". 微信公众号文章中的音乐怎么设置自动播放? 2.点新建群发. 微信公众号文章中的音乐怎么设置自动播放? 3.进入新建群发,在正文里输入 ...
- 最新微信公众号文章数据导出软件工具
相信大家经常都会使用微信软件,对于微信公众号都不陌生,有很多人都会经常阅读公众号的文章.下面集宝数据就给大家说说如何找到好用的微信公众号文章采集器? 如何找到好用的微信公众号文章采集器 第一步:首先, ...
最新文章
- 只用一张训练图像进行图像的恢复
- python能处理图片吗_python图片处理(一)
- envi导出jpg文件_保存技巧,完美解决PS导出文件过大的问题
- php调用mysql库_PHP调用三种数据库的方法(1)
- wxlogin php,wxlogin.php
- mysql延时优化教程_Mysql优化之延迟索引和分页优化_MySQL
- 【BO】WEBI文件打开时提示Illegal access错误
- This application requires Java Runtime Environment
- java ssdb查询_java连接ssdb数据库
- 聊天机器人不仅能省下客服成本 体验可能会更好
- 计算机辅助制造讲义翻译,计算机辅助制造讲义-2007-2演示文稿.PPT
- “他们”将变身为全国最大的房屋租赁供应商
- SQL Server 2016安装指南——针对“Microsoft R Open和Microsoft R Serve”提供解决经验
- Flutter Android权限问题
- http和https连接下载
- 〖Python 数据库开发实战 - MySQL篇④〗- MacOS 配置 MySQL 环境变量及安装MySQL图形化工具 - MySQL Workbench
- 融云出海洞察,海外社交市场地区篇
- import mysql data to solr4.2.0
- YunEngine SDK已经开始发放了!!!
- 李振杰:腾讯入股京东=京东引狼入室