谷歌drive收费_Google Drive的系统设计分析
谷歌drive收费
重点 (Top highlight)
重点 (Top highlight)
System design is one of the most important and feared aspects of software engineering. This opinion comes from my own learning experience in an associate architecture course. When I started my associate architecture course, I had a hard time understanding the idea of designing a system.
系统设计是软件工程中最重要和最令人担忧的方面之一。 这种观点来自我自己在助理架构课程中的学习经验。 当我开始助理架构课程时,我很难理解设计系统的想法。
One of the main reasons was that the terms used in software architecture books are pretty hard to understand at first, and there is no clear step by step guidelines. Everybody seems to have a different approach. And of course, there is a mental block also that these topics might be tough to understand.
主要原因之一是,一开始很难理解软件体系结构书籍中使用的术语,并且没有明确的分步指南。 每个人似乎都有不同的方法。 当然,还有一个心理障碍是这些主题可能很难理解。
So, I set out to design a system based on my experience of learning architecture courses. The first one is on Google Auto Suggestion. For this one, let’s design a cloud file storage service like Google drive. It’s a file storage and synchronization service, enables users to store their data on a remote server.
因此,我根据自己学习建筑课程的经验着手设计一个系统。 第一个是关于Google自动建议的。 为此,让我们设计一种云文件存储服务,例如Google驱动器。 这是一个文件存储 和同步服务,使用户可以将其数据存储在远程服务器上。

Now those who already used Google drive know that we can upload any size of files from any device, and it can be found on our mobile, laptop, personal computer, etc. A lot of us wonder how the system handles such a massive amount of files. In this article, we will design a google drive service!!
现在,那些已经使用过Google驱动器的人知道,我们可以从任何设备上载任何大小的文件,并且可以在我们的手机,笔记本电脑,个人计算机等设备上找到这些文件。我们很多人想知道该系统如何处理如此大量的文件。文件。 在本文中,我们将设计一个Google Drive服务!!
This is by no means a comprehensive guide, rather it’s an introduction to system design and a good place to start your journey to be a software architect.
这绝不是全面的指南,而是对系统设计的介绍,也是开始成为软件架构师的好地方。
★系统定义 (★ Definition of the System)
We need to clarify the goal of the system. System design is such a vast topic; if we don’t narrow it down to a specific purpose, then it will become complicated to design the system, especially for newbies.
我们需要澄清系统的目标。 系统设计是一个巨大的话题。 如果我们不将其范围缩小到特定目的,那么设计系统就会变得复杂,尤其是对于新手。
Users should be able to upload and download files/photos from any device. And the files will be synchronized in all the devices that the user is logged in.
用户应该能够从任何设备上载和下载文件/照片。 并且文件将在用户登录的所有设备中同步。
If we consider 10Million users, 100 M requests/day in the service, the number of writing and read operations will be huge. For simplification, we’re just designing the Google Drive storage. In other words, users can upload and download files, which effectively stores them in the cloud.
如果考虑到服务中有1000万用户,每天有1亿个请求,那么写入和读取操作的数量将是巨大的。 为简化起见,我们仅设计Google云端硬盘存储空间。 换句话说,用户可以上传和下载文件,从而有效地将它们存储在云中。
★系统要求 (★ The requirements of the system)
In this part, we decide on the features of the system. We can divide these requirements into two parts:
在这一部分中,我们决定系统的功能。 我们可以将这些要求分为两部分:
Functional requirement:
功能要求:
Users should be able to upload and download files from any device. And the files will be synchronized in all the devices that the user is logged in.
用户应该能够从任何设备上载和下载文件。 并且文件将在用户登录的所有设备中同步。
These are the primary goal of the system. This is the requirement that the system has to deliver.
这些是系统的主要目标。 这是系统必须交付的要求。
Non-Functional requirement:
非功能需求:
Now for the more critical requirements that need to be analyzed. If we don’t fulfill this requirement, it might be harmful to the business plan of the project. So, let’s define our NFRs:
现在,对于更关键的需求需要进行分析。 如果我们不满足此要求,则可能对项目的业务计划有害。 因此,让我们定义我们的NFR:
Users can upload and download files from any device. The service should support storing a single large file up to 1 GB. Service should synchronize automatically between devices; if one file is uploaded from a device, it should be synced on all devices that the user is logged in.
用户可以从任何设备上载和下载文件。 该服务应支持存储最大1 GB的单个大文件。 服务应在设备之间自动同步; 如果一个文件是从设备上传的,则应在用户登录的所有设备上同步该文件。
★服务器端组件设计 (★ Server-side Component Design)
For newbies to system design, please remember, “If you are confused about where to start for the system design, try to start with the data flow.”
对于系统设计的新手,请记住:“如果您对从哪里开始系统设计感到困惑,请尝试从数据流开始。”
Our user in this system can upload and download files. The user uploads files from the client application/browser, and the server will store them. And user can download updated files from the server. So, let’s see how we handle upload and download of files for such a massive amount of users.
我们在该系统中的用户可以上传和下载文件。 用户从客户端应用程序/浏览器上载文件,服务器将存储它们。 用户可以从服务器下载更新的文件。 因此,让我们看看我们如何为如此大量的用户处理文件的上传和下载。
上传/下载文件: (Upload/Download File:)
From the figure, we can see that if we upload the file with full size, it will cost us storage and bandwidth. And also, latency will be increased to complete upload or download.
从图中可以看到,如果我们上传完整大小的文件,则会浪费我们的存储和带宽。 而且,延迟会增加以完成上载或下载。

有效处理文件传输: (Handle file transfer efficiently:)
We may divide each file into smaller chunks. Then we can modify only small pieces where data is changed, not the whole file. In case data upload failure also this strategy will help. We need to divide each file into a fixed size, say 2 MB.
我们可以将每个文件分成较小的块。 然后,我们只能修改更改数据的小片段,而不是整个文件。 万一数据上传失败,该策略也将有所帮助。 我们需要将每个文件划分为固定大小,例如2 MB。
Our chunk size needs to be smaller. It will help to optimize space utilization, and network bandwidth is another considering factor while making the decision. Metadata should include the record of each file’s chunk information.
我们的块大小需要更小。 这将有助于优化空间利用率,而网络带宽是做出决定时的另一个考虑因素。 元数据应包括每个文件的块信息的记录。
As we have this article for practice, so we may assume that files need to be stored in small chunks of 2 MB. We will get benefits in case of retry operation also for smaller pieces of a file if a process is failed. If a file is not uploaded, then only the failing chunk will be retried.
正如我们有这篇文章供您练习一样,因此我们可以假设文件需要存储在2 MB的小块中。 如果进程失败,则在文件较小的部分重试操作的情况下,我们也会受益。 如果未上传文件,则仅重试失败的块。
Less amount of data transfer between clients and cloud storage will help us achieve a better response time. Instead of transmitting the entire file, we can send only the modified chunks of the files.
客户端和云存储之间较少的数据传输量将帮助我们获得更好的响应时间。 除了发送整个文件,我们只能发送文件的修改后的块。

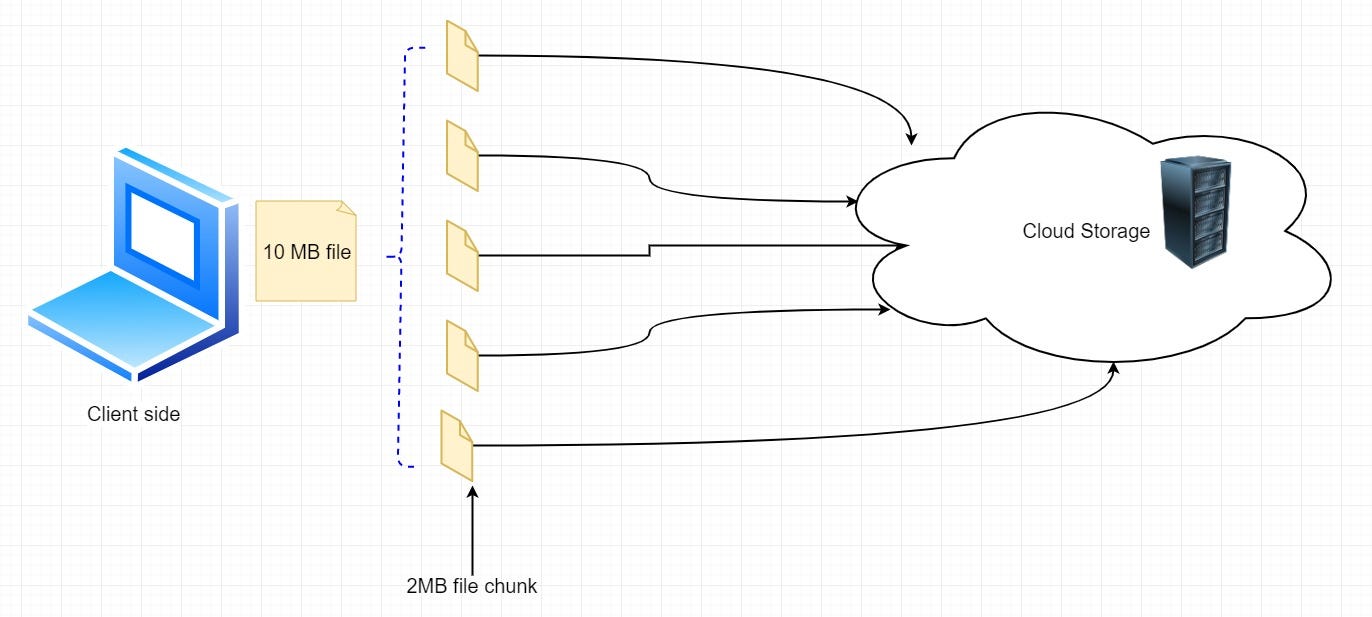
In that case, the updated part of the file will be transmitted. We will be dividing files into 2MB chunks and transfer the modified portion of files only, as you can see from the below figure.
在这种情况下,文件的更新部分将被发送。 我们将把文件分成2MB的块,并且仅传输文件的修改部分,如下图所示。
From the figure above, you may see, instead of updating the whole 10 MB file, we can just update the modified 2MB potion of the file. It will decrease bandwidth consumption and cloud storage for the user. Most importantly, the response time will be faster.
从上图可以看到,我们没有更新整个10 MB的文件,而是更新了文件的修改后的2MB部分。 它将为用户减少带宽消耗和云存储。 最重要的是,响应时间将更快。
客户端离线时会发生什么? (What will happen when the client is offline?)
A client component, Watcher, will observe client-side folders. If any change occurs by the user, it will notify the Index Controller(another client component) about the action of the user. It will also monitor if any change is happening on other clients(devices), which are broadcasted by the Notification server.
客户端组件Watcher将观察客户端文件夹。 如果用户发生任何更改,它将通知索引控制器(另一个客户端组件)用户的操作。 它还将监视其他客户端(设备)是否发生任何更改,这些更改由Notification Server广播。
When the Metadata service receives an update/upload request, it needs to check with the metadata DB for consistency and then proceed with the update. After that, a notification will be sent to all subscribed devices to report the file update.
当元数据服务收到更新/上传请求时,它需要检查元数据数据库的一致性,然后继续进行更新。 之后,将向所有订阅的设备发送通知以报告文件更新。
元数据数据库: (Metadata Database:)
We need a database that is responsible for keeping information about files, users, etc. It can be a relational database like MySQL or NoSQL like MongoDB. We need to save data like chunks, files, user information, etc. in the Database.
我们需要一个负责保存有关文件,用户等信息的数据库。它可以是关系数据库,例如MySQL或NoSQL,例如MongoDB。 我们需要将数据块,文件,用户信息等保存在数据库中。
As we all know, we have to choose between two types of Database, SQL or NoSQL. Whatever we choose, we need to ensure data consistency.Using a SQL database may give us the benefit of the implementation of the synchronization as they support ACID properties.
众所周知, 我们必须在两种类型的数据库(SQL或NoSQL)之间进行选择。 无论我们选择什么,我们都需要确保数据的一致性。 使用SQL数据库可以为我们带来同步实现的好处,因为它们支持ACID属性。
NoSQL databases do not support ACID properties. But they provide support for scalability and performance. So, we need to provide support for ACID properties programmatically in the logic of our Metadata server for this type of Database.
NoSQL数据库不支持ACID属性。 但是它们提供了对可伸缩性和性能的支持。 因此,我们需要在Metadata Server的逻辑中以编程方式为此类数据库提供对ACID属性的支持。
同步: (Synchronization:)
Now the client updates a file from a device; there needs to be a component that process updates and applies the change to other devices. It needs to sync the client’s local Database and remote Metadata DB. MetaData server can perform the job to manage metadata and synchronize the user’s files.
现在,客户端从设备更新文件; 需要有一个组件来处理更新并将更改应用到其他设备。 它需要同步客户端的本地数据库和远程元数据数据库。 MetaData服务器可以执行这项工作来管理元数据并同步用户的文件。
消息队列: (Message Queue:)
Now think about it; such a huge amount of users are uploading files simultaneously, how the server can handle such a large number of requests. To be able to handle such a huge amount of requests, we may use a message queue between client and server.
现在考虑一下; 如此大量的用户正在同时上传文件,服务器如何处理如此大量的请求。 为了能够处理如此大量的请求,我们可能在客户端和服务器之间使用消息队列。

The message queue provides temporary message storage when the destination program is busy or not connected. It provides an asynchronous communications protocol. It is a system that puts a message onto a queue and does not require an immediate response to continue processing. RabbitMQ, Apache Kafka, etc. are some of the examples of the messaging queue.
当目标程序忙或未连接时,消息队列提供临时消息存储。 它提供了异步通信协议。 它 是将消息放入队列并且不需要立即响应即可继续处理的系统。 RabbitMQ,Apache Kafka等是消息传递队列的一些示例。
In case of a message queue, messages will be deleted from the queue once received by a client. So, we need to create several Response Queues for each subscribed device of the client.
如果是消息队列,则一旦客户端接收到消息,就会从队列中删除消息。 因此,我们需要为客户端的每个订阅的设备创建多个响应队列。

For a massive amount of users, we need a scalable message Queue that supports asynchronous message-based communication between client and synchronization service. The service should be able to efficiently store any number of messages in a highly available, reliable, and scalable queue. Example: apache Kafka, rabbitMQ, etc.
对于大量用户,我们需要一个可伸缩的消息队列,该队列支持客户端和同步服务之间基于异步消息的通信。 该服务应该能够在高度可用,可靠和可伸缩的队列中有效地存储任意数量的消息。 例如:apache Kafka,rabbitMQ等。
云储存: (Cloud Storage:)
Nowadays, there are many platforms and operating systems like smartphones, laptops, personal computers, etc. They provide mobile access from any place at any time.
如今,有许多平台和操作系统,例如智能手机,笔记本电脑,个人计算机等。它们可随时随地提供移动访问。
If you keep files in the local storage of your laptop and you are going out but want to use it on your mobile phone, how can you get the data? That’s why we need cloud storage as a solution.
如果您将文件保存在笔记本电脑的本地存储中,并且出门在外但想在手机上使用它,那么如何获取数据? 这就是为什么我们需要云存储作为解决方案。
It stores files(chunks) uploaded by the users. Clients can interact with the storage through File Processing Server to send and receive objects from it. It holds only the files; Metadata DB keeps the data of the chunk size and numbers of a file.
它存储用户上传的文件(块)。 客户端可以通过文件处理服务器与存储进行交互,以从存储发送和接收对象。 它只保存文件; 元数据数据库保留文件的块大小和编号的数据。
文件处理工作流程: (File processing Workflow:)
Client A uploads chunk to cloud storage. Client A updates metadata and commits changes in MetadataDB using the Metadata server. The client gets confirmation, and notifications are sent to other devices of the same user. Other devices receive metadata changes and download updated chunks from cloud storage.
客户端A将块上传到云存储。 客户端A使用元数据服务器更新元数据并提交对MetadataDB的更改。 客户端得到确认,并将通知发送到同一用户的其他设备。 其他设备接收元数据更改并从云存储下载更新的块。

★可扩展性 (★Scalability)
We need to partition the metadata database so that we can store information about 1 million users and billions of files/chunks. We can partition data to distribute the read-write request on servers.
我们需要对元数据数据库进行分区,以便可以存储约100万用户和数十亿文件/块的信息。 我们可以对数据进行分区,以在服务器上分配读写请求。
元数据分区: (MetaData Partitioning:)
i) We can store file-chunks in partitions based on the first letter of the File Path. For example, we keep all the files starting with the letter ‘A’ in one partition and those beginning with the letter ‘B’ into another partition and so on. This is called range-based partitioning. Less frequently occurring letters like ‘Z’ or ‘Y,’ we can combine them into one partition.
i)我们可以基于文件路径的首字母将文件块存储在分区中。 例如,我们将所有以字母“ A”开头的文件保留在一个分区中,并将所有以字母“ B”开头的文件保留在另一个分区中,依此类推。 这称为基于范围的分区 。 不太频繁出现的字母(例如“ Z”或“ Y”),我们可以将它们组合成一个分区。
The main problem is that some letters are common in case of a starting letter. For example, if we put all files starting with the letter ‘A’ into a DB partition, and we have too many files that begin with the letter ‘A,’ so that that we cannot fit them into one DB partition. In such cases, this approach will have a disadvantage.
主要问题是,某些字母在首字母的情况下很常见。 例如,如果我们将所有以字母“ A”开头的文件放入一个数据库分区中,而又有太多以字母“ A”开头的文件,那么我们就无法将它们放入一个数据库分区中。 在这种情况下,这种方法将有一个缺点。
ii) We may also partition based on the hash of the ‘fileId’ of the file. Our hash function will randomly generate a server number, and we will store the file in that server. But we might need to ask all the servers to find a suggested list and merge them together to get the result. So, response time latency might be increased.
ii)我们也可以基于文件'fileId'的哈希值进行分区。 我们的哈希函数将随机生成一个服务器号,并将文件存储在该服务器中。 但是我们可能需要要求所有服务器找到建议列表,然后将它们合并在一起以得到结果。 因此,响应时间延迟可能会增加。
If we use this approach, it can still lead to overloaded partitions, which can be solved by using Consistent Hashing.
如果我们使用这种方法,它仍然会导致分区过载,这可以通过使用“一致性哈希”来解决。
缓存: (Caching:)
As we know, caching is a common technique for performance. This is very helpful to lower the latency. The server may check the cache server before hitting the Database to see if the search list is already in the cache. We can’t have all the data in the cache; it’s too costly.
众所周知, 缓存是提高性能的常用技术。 这对于降低延迟非常有帮助。 服务器可以在访问数据库之前检查缓存服务器,以查看搜索列表是否已在缓存中。 我们不能将所有数据都保存在缓存中。 太贵了
When the cache is full, and we need to replace a chunk with a newer chunk. Least Recently Used (LRU) can be used for this system. In this approach, the least recently used chunk is removed from the cache first.
当缓存已满时,我们需要用更新的块替换块。 最近最少使用(LRU)可以用于此系统。 在这种方法中,首先从高速缓存中删除最近最少使用的块。
★安全性: (★Security:)
In a file-sharing service, the privacy and security of user data are essential. To handle this, we can store the permissions of each file in the metadata database to give perm what files are visible or modifiable by which user.
在文件共享服务中,用户数据的私密性和安全性至关重要。 为了解决这个问题,我们可以将每个文件的权限存储在元数据数据库中,以使perm哪些文件可由哪个用户查看或修改。
★客户端: (★ Client-Side:)
The client application(web or mobile) transfers all files that users upload in cloud storage. The application will upload, download, or modify files to cloud storage. A client can update metadata like rename file name, edit a file, etc.
客户端应用程序(Web或移动设备)传输用户上传到云存储中的所有文件。 该应用程序将上传,下载或修改文件到云存储。 客户端可以更新元数据,例如重命名文件名,编辑文件等。
The client app features include upload, download files. As mentioned above, we will divide each file into smaller chunks of 2MB so that we transfer only the modified chunks, not the whole file.
客户端应用程序功能包括上传,下载文件。 如上所述,我们将每个文件分成2MB的较小块,以便仅传输修改后的块,而不传输整个文件。
In case any conflict arises due to the offline status of the user, the app needs to handle it. Now, we can keep a local copy of metadata on the client-side to enable us to do offline updates.
如果由于用户的离线状态而引起任何冲突,则应用程序需要对其进行处理。 现在,我们可以在客户端保留元数据的本地副本,以使我们能够进行脱机更新。
The client application needs to detect if any file is changed in the client-side folder. We may have a component, Watcher. It will check if any file changes occurred on the client-side.
客户端应用程序需要检测客户端文件夹中的文件是否已更改。 我们可能有一个组件Watcher。 它将检查客户端是否发生任何文件更改。
★客户如何知道云存储已完成更改? (★How would clients know change is done in cloud storage?)
The client can periodically check with the server if there is any change, which is a manual strategy. But if the client frequently checks server changes, it will be pressure for the server, keep servers busy.
客户端可以定期与服务器核对是否有任何更改,这是一项手动策略。 但是,如果客户端经常检查服务器的更改,将对服务器造成压力,使服务器保持繁忙。
We may use HTTP Long polling technique instead. In this technique, the server does not immediately respond to client requests. Instead of sending an empty response, the server keeps the request open. Once new information is ready, then the server sends a response to the client.
我们可以使用HTTP 长时间轮询 技术。 在这种技术中,服务器不会立即响应客户端请求。 服务器没有发送空响应,而是使请求保持打开状态。 一旦准备好新信息,服务器就会向客户端发送响应。

We can divide client application into these parts:
我们可以将客户端应用程序分为以下几部分:
✓ Local Database will keep track of all the files, chunks, directory path, etc. in the client system.
✓本地数据库将跟踪客户端系统中的所有文件,块,目录路径等。
✓ The Chunk Controller will split files into smaller pieces. It will also perform the duty to reconstruct the full file from its chunks. And this part will help to determine only the latest modified chunk of a file. And only modified chunks of a file will be sent to the server, which will save bandwidth and server computation time.
✓ 块控制器会将文件分割成较小的部分。 它还将负责从其块中重建整个文件。 这部分将有助于确定文件的最新修改块。 而且仅将文件的已修改块发送到服务器,这将节省带宽和服务器计算时间。
✓ The Watcher will observe client-side folders, and if any change occurs by the user, it will notify the Index Controller about the action of the user. It will also monitor if any change is happening on other clients(devices), which are broadcasted by Synchronization service.
✓Watcher将观察客户端文件夹,如果用户发生任何更改,它将通知索引控制器用户的操作。 它还将监视由同步服务广播的其他客户端(设备)上是否发生了任何更改。
✓ The Index controller will process events received from the Watcher and update the local Database about modified file-chunk information. It will communicate with the Metadata service to transfer changes to other devices and update the metadata database. This request will be sent to the metadata service via the message request queue.
✓索引控制器将处理从观察程序收到的事件,并更新有关已修改文件块信息的本地数据库。 它将与元数据服务通信,以将更改传送到其他设备并更新元数据数据库。 该请求将通过消息请求队列发送到元数据服务。
Below is the full diagram of the system:
下面是系统的完整图:

★结论: (★Conclusion:)
In this system, we did not consider the UI part. The history of the updates and offline editing was also not considered in the system. The mobile client could sync on-demand to save the user’s bandwidth and space. Here we did not use another server for synchronization. The Metadata Server is performing that task.We decided to divide files into smaller chunks to save storage, bandwidth usage, and also decrease latency. We added the Loadbalancer to distribute incoming requests equally among backend servers. If a server is dead, LB will stop sending any request to it.
在此系统中,我们未考虑UI部分。 系统中也未考虑更新和脱机编辑的历史记录。 移动客户端可以按需同步以节省用户的带宽和空间。 在这里,我们没有使用其他服务器进行同步。 元数据服务器正在执行该任务。 我们决定将文件分成较小的块,以节省存储空间,带宽使用并减少延迟。 我们添加了Loadbalancer,以在后端服务器之间平均分配传入请求。 如果服务器死了,LB将停止向它发送任何请求。
In cloud architecture, the privacy and security of user data are essential. We can store the permissions of each file in the metadata DB to check which files are visible or modifiable by which user.
在云架构中,用户数据的隐私和安全性至关重要。 我们可以将每个文件的权限存储在元数据数据库中,以检查哪些文件对哪个用户可见或可修改。
The first part of this series is on Google Auto Suggestion.
本系列的第一部分是关于Google自动建议 。
Reference: Grokking the System Design course. And for video reference you may check this link. Thank you for reading the article. Have a good day
谷歌drive收费_Google Drive的系统设计分析相关推荐
- 华为android系统最新版,谷歌再放大招截胡鸿蒙系统!发布最新版安卓系统:国产手机抢先升级...
原标题:谷歌再放大招截胡鸿蒙系统!发布最新版安卓系统:国产手机抢先升级 [5月21日讯]相信大家都知道,随着华为鸿蒙OS 2.0正式版系统推出旗舰确认,也让华为鸿蒙OS系统在近期越来越火热,受到的关注 ...
- fuchsiaos和鸿蒙os区别,谷歌Fuchsia OS和华为鸿蒙系统(HarmonyOS)没有必然联系
谷歌Fuchsia OS和华为鸿蒙系统(HarmonyOS)都是属于新一代的操作系统,这两个系统都不基于Linux,更不基于安卓(Android).基于这个思路,有人认为它们有一些联系,或者说在开发构 ...
- 谷歌云服务_Google Cloud_使用注意
谷歌云服务_Google Cloud_使用注意 谷歌云服务_Google Cloud_使用注意 使用前提 SDK使用 REST api使用 谷歌云服务_Google Cloud_使用注意 因为近期工作 ...
- 山东省高速公路不停车收费建设项目灾备系统招标
山东省高速公路不停车收费建设项目灾备系统招标评标结果公示 山东省高速公路不停车收费建设项目灾备系统招标评标工作已经结束.现将评标结果公示如下: 一.项目名称:山东省高速公路不停车收费建设项目灾 ...
- 鸿蒙狙击谷歌,全面狙击华为鸿蒙OS系统!谷歌霸气联手三星:发布新版鸿蒙OS系统...
原标题:全面狙击华为鸿蒙OS系统!谷歌霸气联手三星:发布新版"鸿蒙OS"系统 [5月15日讯]相信大家都知道,华为方面已经正式确认,部分华为.荣耀手机(仅使用麒麟旗舰芯片)将会在6 ...
- java计算机毕业设计停车场收费管理系统源码+系统+数据库+lw文档+mybatis+运行部署
java计算机毕业设计停车场收费管理系统源码+系统+数据库+lw文档+mybatis+运行部署 java计算机毕业设计停车场收费管理系统源码+系统+数据库+lw文档+mybatis+运行部署 本源码技 ...
- 三星电视与android手机,三星难敌谷歌安卓,放弃自研系统Tizen,彻底沦为电视专属系统...
原标题:三星难敌谷歌安卓,放弃自研系统Tizen,彻底沦为电视专属系统 说到手机厂商自主研发的操作系统,大家可能首先会想到苹果的iOS,近半年可能还会想到华为的鸿蒙,其实三星也是有自主研发的操作系统的 ...
- 华为鸿蒙系统界面_谷歌懵圈!华为鸿蒙系统界面首次曝光,网友纷纷表示支持...
谷歌懵圈!华为鸿蒙系统界面首次曝光,网友纷纷表示支持 最近的科技圈被华为禁令的消息刷屏,甚至已经上升到人尽皆知的地步,制裁华为的禁令诱发一连串的连锁效应.大量海外供应商集体宣布断供,而就连和华为合作已 ...
- Nvidia Drive Orin/Drive AGX Orin DRIVE OS相关资源介绍
nvidia orin平台,分为 jetson orin 和 drive orin,本文介绍 nv drive orin,drive orin又分为 drive orin (其develop kit ...
最新文章
- “卖我一枝笔”:如何史蒂夫·乔布斯将这一经典问题作出回应?
- 【机器学习基础】用Python构建和可视化决策树
- k8s get命令:以yaml格式输出deployment对象
- 安卓跑linux程序_Android下运行Linux可执行程序
- android踩坑日记1
- WinForm LED循环显示信息,使用定时器Threading.Timer
- cloudare mysql 密码修改_CentOS7.3 LAMP环境搭建私有云NextCloud过程记录
- 如何提升人脸识别的精度_宝比万像人脸识别:健身房人脸识别门禁系统如何助力健身房管理?...
- c语言 程序停止,Go语言宕机(panic)——程序终止运行
- 随笔记--Pycharm中Terminal字体大小的设置
- 在哪一类期刊中发表论文最难,SCI、SSCI、还是AHCI?
- C语言科学计数法字符串转化为实数
- ps 改变图片中的文字
- ubuntu 您不是所有者所以您不能更改
- .jpeg 格式图片URL在浏览器里默认是下载
- MNIST在CPU、FPGA、ARM上的运行对比
- 概念模型、数据模型、关系数据模型
- 一年后再回头看系列之C/C++中的选择法排序、冒泡排序
- sql怎么与oracle连接,sql怎么连接oracle数据库
- 【校招VIP】产品设计分析之文案功底考察
热门文章