python能写什么脚本_你用 Python 写过哪些牛逼的程序/脚本?
原标题:你用 Python 写过哪些牛逼的程序/脚本?
【导读】:有网友在 Quora 上提问,「你用 Python 写过最牛逼的程序/脚本是什么?」。本文摘编了 3 个国外程序员的多个小项目,含代码。
Manoj Memana Jayakumar, 3000+ 顶
更新:凭借这些脚本,我找到了工作!可看我在这个帖子中的回复,《Has anyone got a job through Quora? Or somehow made lots of money through Quora?》
1. 电影/电视剧 字幕一键下载器
我们经常会遇到这样的情景,就是打开字幕网站subscene 或者opensubtitles, 搜索电影或电视剧的名字,然后选择正确的抓取器,下载字幕文件,解压,剪切并粘贴到电影所在的文件夹,并且需把字幕文件重命名以匹配电影文件的名字。是不是觉得太无趣呢?对了,我之前写了一个脚本,用来下载正确的电影或电视剧字幕文件,并且存储到与电影文件所在位置。所有的操作步骤仅需一键就可以完成。懵逼了吗?
请看这个 Youtube 视频:https://youtu.be/Q5YWEqgw9X8
源代码存放在GitHub:subtitle-downloader
更新:目前,该脚本支持多个字幕文件同时下载。步骤:按住 Ctrl ,选择你想要为其下载字幕的多个文件 , 最后执行脚本即可
2. IMDb 查询/电子表格生成器
我是一个电影迷,喜欢看电影。我总是会为该看哪一部电影而困惑,因为我搜集了大量的电影。所以,我应该如何做才能消除这种困惑,选择一部今晚看的电影?没错,就是IMDb。我打开 http://imdb.com,输入电影的名字,看排名,阅读和评论,找出一部值得看的电影。
但是,我有太多电影了。谁会想要在搜索框输入所有的电影的名字呢? 我肯定不会这样做,尤其是我相信“如果某些东西是重复性的,那么它应该是可以自动化的”。因此,我写了一个 python 脚本, 目的是为了使用 非官方的 IMDb API 来获取数据。我选择一个电影文件(文件夹),点击右键,选择‘发送到’,然后 点击 IMDB.cmd (顺便提一下,IMDB.cmd 这个文件就是我写的 python 脚本),就是这样。
我的浏览器会打开这部电影在IMDb网站上的准确页面。
仅仅只需点击一个按键,就可以完成如上操作。如果你不能够了解这个脚本到底有多酷,以及它可以为你节省多少时间,请看这个 Youtube 视频:https://youtu.be/JANNcimQGyk
从现在开始,你再也不需要打开你的浏览器,等待加载IMDb的页面,键入电影的名字。这个脚本会帮你完成所有的操作。跟往常一样,源代码放在了GitHub:imdb ,并且附有操作说明。当然,由于这个脚本必须去掉文件或文件夹中的无意义的字符,比如“DVDRip, YIFY, BRrip”等,所以在运行脚本的时候会有一定比例的错误。但是经过测试,这个脚本在我几乎所有的电影文件上都运行的很好。
2014-04-01更新:
许多人在问我是否可以写一个脚本,可以发现一个文件夹中所有电影的详细信息,因为每一次只能发现一个电影的详细信息是非常麻烦的。我已经更新了这个脚本,支持处理整个文件夹。脚本会分析这个文件夹里的所有子文件夹,从 IMDb上抓取所有电影的详细信息 ,然后打开一个电子表格,根据IMDb 上的排名,从高到低降序排列所有的电影。这个表格中包含了 (所有电影)在 IMDb URL, 年份,情节,分类,获奖信息,演员信息,以及其他的你可能在 IMBb找到的信息。下面是脚本执行后,生成的表格范例:

Your very own personal IMDb database! What more can a movie buff ask for? ;)
Source on GitHub:imdb
你也可以有一个个人IMDb数据库!一个电影爱好者还能够要求更多吗?:)
源代码在GitHub:imdb
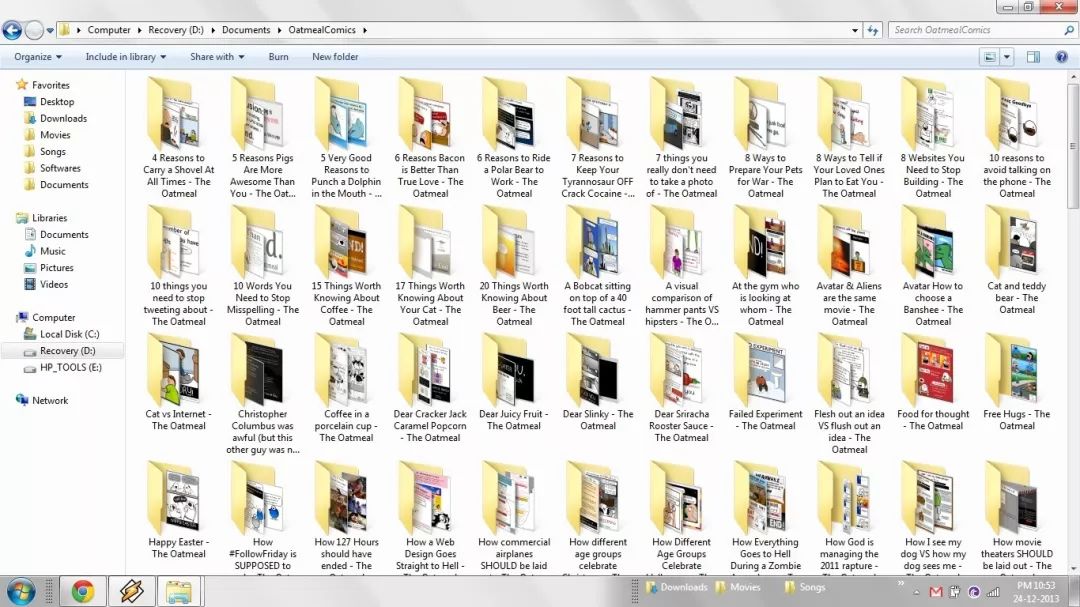
3. theoatmeal.com 连载漫画下载器

我个人超级喜欢 Matthew Inman 的漫画。它们在疯狂搞笑的同时,却又发人深省。但是,我很厌烦重复点击下一个,然后才能阅读每一个漫画。另外,由于每一个漫画都由多福图片组成,所以手动下载这些漫画是非常困难的。
基于如上原因,我写了一个 python 脚本 ,用来从这个站点下载所有的漫画。这个脚本利用 BeautifulSoup (http://www.crummy.com/software/B… ) 解析 HTML 数据, 所以在运行脚本前,必须安装 BeautifulSoup。 用于下载燕麦片(马修.英曼的一部漫画作品)的下载器已经上传到GitHub:theoatmeal.com-downloader 。(漫画)下载完后的文件夹是这样的 :D
4. someecards.com 下载器
成功地从http://www.theoatmeal.com 下载了整部漫画后,我在想是否我可以做同样的事情 , 从另一个我喜欢的站点— 搞笑的,唯一的http://www.someecards.com. 下载一些东西呢?

somececards 的问题是,图片命名是完全随机的,所有图片的排放没有特定的顺序,并且一共有52 个大的类别, 每一个类别都有数以千计的图片。
我知道,如果我的脚本是多线程的话,那将是非常完美的,因为有大量的数据需要解析和下载,因此我给每一个类别中的每一页都分配一个线程。这个脚本会从网站的每一个单独的分类下载搞笑的电子贺卡,并且把每一个放到单独的文件夹。现在,我拥有这个星球上最好笑的电子贺卡私人收藏。下载完成后,我的文件夹是这样的:
没错,我的私人收藏总共包括:52个类别,5036个电子贺卡。 源代码在这里:someecards.com-downloader
编辑:很多人问我是否可以共享我下载的所有文件,(在这里,我要说)由于我的网络不太稳定,我没办法把我的收藏上传到网络硬盘,但是我已经上传一个种子文件,你们可以在这里下载:somecards.com Site Rip torrent
种下种子,传播爱:)
Akshit Khurana,4400+ 顶感谢 500 多个朋友在 Facebook 上为我送出的生日祝福
有三个故事让我的21岁生日变的难忘,这是最后一个故事。我倾向于在每一条祝福下亲自评论,但是使用 python 来做更好。
…
1.# Thanking everyone who wished me on my birthday
2.importrequests
3.importjson
4.
5.# Aman's post time
6.AFTER=1353233754
7.TOKEN=' '
8.
9.defget_posts():
10."""Returns dictionary of id, first names of people who posted on my wall
11. between start and end time"""
12.query=("SELECT post_id, actor_id, message FROM stream WHERE "
13."filter_key = 'others' AND source_id = me() AND "
14."created_time > 1353233754 LIMIT 200")
15.
16.payload={'q':query,'access_token':TOKEN}
17.r=requests.get('https://graph.facebook.com/fql',params=payload)
18.result=json.loads(r.text)
19.returnresult['data']
20.
21.defcommentall(wallposts):
22."""Comments thank you on all posts"""
23.#TODO convert to batch request later
24.forwallpostinwallposts:
25.
26.r=requests.get('https://graph.facebook.com/%s'%
27.wallpost['actor_id'])
28.url='https://graph.facebook.com/%s/comments'%wallpost['post_id']
29.user=json.loads(r.text)
30.message='Thanks %s :)'%user['first_name']
31.payload={'access_token':TOKEN,'message':message}
32.s=requests.post(url,data=payload)
33.
34.print"Wall post %s done"%wallpost['post_id']
35.
36.if__name__=='__main__':
37.commentall(get_posts())
…
为了能够顺利运行脚本,你需要从Graph API Explorer(需适当权限)获得 token。 本脚本假设特定时间戳之后的所有帖子都是生日祝福。
尽管对评论功能做了一点改变,我仍然喜欢每一个帖子。
当我的点赞数,评论数以及评论结构在 ticker(Facebook一项功能,朋友可以看到另一个朋友在做什么,比如点赞,听歌,看电影等) 中爆涨后,我的一个朋友很快发现此事必有蹊跷。
尽管这个不是我最满意的脚本,但是它简单,快捷,有趣。
当我和 Sandesh Agrawal 在网络实验室讨论时,有了写这个脚本的想法。 为此,Sandesh Agrawal 耽搁了实验室作业,深表感谢。
Tanmay Kulshrestha,3300+ 顶
好了,在我失去这个项目之前(一个猪一样的朋友格式化了我的硬盘,我的所有代码都在那个硬盘上)或者说,在我忘记这些代码之前,我决定来回答这个问题。
整理照片
当我对图像处理感兴趣之后,我一直致力于研究机器学习。我写这个有趣的脚本,目的是为了分类图片,很像 Facebook 做的那样(当然这是一个不够精确的算法)。 我使用了 OpenCV 的人脸检测算法,“haarcascade_frontalface_default.xml”,它可以从一张照片中检测到人脸。

你可能已经察觉到这张照片的某些地方被错误地识别为人脸。 我试图通过修改一些参数(来修正这一问题),但还是某些地方被错误地识别为人脸,这是由相机的相对距离导致的。我会在下一阶段解决这一问题(训练步骤)。
这个训练算法需要一些训练素材,每个人需要至少需要100-120个训练素材(当然多多益善)。 我太懒了,并没有为每一个人挑选照片,并把它们复制粘帖到训练文件夹。所以,你可能已经猜到,这个脚本会打开一个图片,识别人脸,并显示每一个人脸(脚本会根据处于当前节点的训练素材给每一个人脸预测一个名字)。伴随着每次你标记的照片,Recognizer 会被更新,并且还会包含上一次的训练素材。 在训练过程中,你可以增加新的名字。我使用 python 库 tkinter 做了一个 GUI。 因此,大多数时候,你必须初始化一小部分照片(给照片中的人脸命名),其他的工作都可以交给训练算法。 因此,我训练了 Recognizer ,然后让它(Recognizer)去处理所有的图片。
我使用图片中包含的人的人名来命名图片,(例如: Tanmay&*****&*****)。 因此,我可以遍历整个文件夹,然后可以通过输入人名的方法来搜索图片。
初始状态下,当一个人脸还没有训练素材时(素材库中还没有包括这个人脸的名字),需要询问他/她的名字。

我可以增加一个名字,像这个样子:

当训练了几个素材后,它会像这个样子:



最后一个是针对应对那些垃圾随机方块而使用的变通解决方案。
带名字的最终文件夹。

所以,现在寻找图片变得相当简单。顺便提一下,很抱歉(我)放大了这些照片。
…
importcv2
importsys
importos,random,string
#choices=['Add a name']
importos
current_directory=os.path.dirname(os.path.abspath(__file__))
fromTkinterimportTk
fromeasyguiimport*
importnumpyasnp
x=os.listdir(current_directory)
new_x=[]
testing=[]
foriinx:
ifi.find('.')==-1:
new_x+=[i]
else:
testing+=[i]
x=new_x
g=x
choices=['Add a name']+x
y=range(1,len(x)+1)
defget_images_and_labels():
globalcurrent_directory,x,y,g
ifx==[]:
return(False,False)
image_paths=[]
foriing:
path=current_directory+''+i
forfilenameinos.listdir(path):
final_path=path+''+filename
image_paths+=[final_path]
# images will contains face images
images=[]
# labels will contains the label that is assigned to the image
labels=[]
forimage_pathinimage_paths:
# Read the image and convert to grayscale
img=cv2.imread(image_path,0)
# Convert the image format into numpy array
image=np.array(img,'uint8')
# Get the label of the image
backslash=image_path.rindex('')
underscore=image_path.index('_',backslash)
nbr=image_path[backslash+1:underscore]
t=g.index(nbr)
nbr=y[t]
# If face is detected, append the face to images and the label to labels
images.append(image)
labels.append(nbr)
#cv2.imshow("Adding faces to traning set...", image)
#cv2.waitKey(50)
# return the images list and labels list
returnimages,labels
# Perform the tranining
deftrain_recognizer():
recognizer=cv2.createLBPHFaceRecognizer()
images,labels=get_images_and_labels()
ifimages==False:
returnFalse
cv2.destroyAllWindows()
recognizer.train(images,np.array(labels))
returnrecognizer
defget_name(image_path,recognizer):
globalx,choices
#if recognizer=='':
# recognizer=train_recognizer()
cascadePath="haarcascade_frontalface_default.xml"
faceCascade=cv2.CascadeClassifier(cascadePath)
#recognizer=train_recognizer()
x1=testing
globalg
printimage_path
image=cv2.imread(image_path)
img=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
predict_image=np.array(img,'uint8')
faces=faceCascade.detectMultiScale(
img,
scaleFactor=1.3,
minNeighbors=5,
minSize=(30,30),
flags=http://cv2.cv.CV_HAAR_SCALE_IMAGE
)
for(x,y,w,h)infaces:
f=image[y:y+w,x:x+h]
cv2.imwrite('temp.jpg',f)
im='temp.jpg'
nbr_predicted,conf=recognizer.predict(predict_image[y:y+h,x:x+w])
predicted_name=g[nbr_predicted-1]
print"{} is Correctly Recognized with confidence {}".format(predicted_name,conf)
ifconf>=140:
continue
msg='Is this '+predicted_name
reply=buttonbox(msg,image=im,choices=['Yes','No'])
ifreply=='Yes':
reply=predicted_name
directory=current_directory+''+reply
ifnotos.path.exists(directory):
os.makedirs(directory)
random_name=''.join(random.choice(string.ascii_uppercase+string.digits)for_inrange(7))
path=directory+''+random_name+'.jpg'
cv2.imwrite(path,f)
else:
msg="Who is this?"
reply=buttonbox(msg,image=im,choices=choices)
ifreply=='Add a name':
name=enterbox(msg='Enter the name',title='Training',strip=True)
printname
choices+=[name]
reply=name
directory=current_directory+''+reply
ifnotos.path.exists(directory):
os.makedirs(directory)
random_name=''.join(random.choice(string.ascii_uppercase+string.digits)for_inrange(7))
path=directory+''+random_name+'.jpg'
printpath
cv2.imwrite(path,f)
# calculate window position
root=Tk()
pos=int(root.winfo_screenwidth()*0.5),int(root.winfo_screenheight()*0.2)
root.withdraw()
WindowPosition="+%d+%d"%pos
# patch rootWindowPosition
rootWindowPosition=WindowPosition
defdetect_faces(img):
globalchoices,current_directory
imagePath=img
faceCascade=cv2.CascadeClassifier(cascPath)
image=cv2.imread(imagePath)
gray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
faces=faceCascade.detectMultiScale(
gray,
scaleFactor=1.3,
minNeighbors=5,
minSize=(30,30),
flags=http://cv2.cv.CV_HAAR_SCALE_IMAGE
)
print"Found {0} faces!".format(len(faces))
m=0
for(x,y,w,h)infaces:
m+=1
padding=0
f=image[y-padding:y+w+padding,x-padding:x+h+padding]
cv2.imwrite('temp.jpg',f)
im='temp.jpg'
msg="Who is this?"
reply=buttonbox(msg,image=im,choices=choices)
ifreply=='Add a name':
name=enterbox(msg='Enter the name',title='Training',strip=True)
printname
choices+=[name]
reply=name
directory=current_directory+''+reply
ifnotos.path.exists(directory):
os.makedirs(directory)
random_name=''.join(random.choice(string.ascii_uppercase+string.digits)for_inrange(7))
path=directory+''+random_name+'.jpg'
printpath
cv2.imwrite(path,f)
defnew(img,recognizer):
imagePath=current_directory+''+img
printimagePath
get_name(imagePath,recognizer)
cascPath='haarcascade_frontalface_default.xml'
b=0
os.system("change_name.py")
forfilenameinos.listdir("."):
b+=1
ifb%10==0orb==1:
os.system("change_name.py")
recognizer=train_recognizer()
iffilename.endswith('.jpg')orfilename.endswith('.png'):
printfilename
imagePath=filename
#detect_faces(imagePath)
new(imagePath,recognizer)
os.remove(filename)
raw_input('Done with this photograph')
…
我想进一步修改它的搜索功能,其中会包含更多的搜索类型,比如基于地理位置,微笑的脸,伤心的脸等等。(这样我就可以在 Skylawns 上 搜索快乐的 Tanmay & 沮丧的 Akshay & 快乐的…)
我还写了很多脚本,但那都是很久之前的事情了,我也懒得再去检查这些代码了,我会列出部分代码。
GitHub 链接:tanmay2893/Image-Sorting
Gmail 邮件通知
在那段时间,我没有智能手机。 导致我常常错过来自于我所在的研究所的邮件(在我的研究所的邮件 ID),我写了一个脚本,可以在我的笔记本上运行,而且能给我的手机发信息。我使用 python 的 IMAP 库来获取邮件。我可以输入一些重要的人的名字,这样一来,当这些人给我发了邮件后,我可以收到短信通知。对于短信, 我使用了 way2sms.com(写了一个 python 脚本,自动登陆我的账户,然后发送 短信)。
PNR(Passenger Name Record旅客订座记录,下同)状态短讯
铁路方面不经常发送 PNR 状态消息。因此,我写了一个脚本,可以从印度铁路网站获取 PNR 状态。这是非常容易的,因为那个网站没有验证码,即使有,也只是形同虚设的验证码(在过去,一些字母会被写在看起来像图片一样的东西上面,因为他们为这些字母使用了一个 “check” 的背景图)。 我们可以轻松地从 HTML 网页得到这些字母。我不明白他们这样做的目的是什么,难道仅仅是为了愚弄他们自己吗? 不管怎么样,我使用短信息脚本来处理它,经过一段时间间隔,它会在我的笔记本上运行一次,就像是一个定时任务,只要 PNR 状态有更新,它就会把更新信息发送给我。
YouTube 视频下载器
这个脚本会从 Youtube 页面下载所有的 Youtube 视频 以及他们所有的字幕文件(从Download and save subtitles下载)。为了使下载速度更快一点,我使用了多线程。还有一个功能是,即使你的电脑重启了,仍然可以暂停和恢复播放下载的(视频)。我原本想做一个UI的,但是我太懒了… 一旦我的下载任务完成,我就不去关心 UI 的事情了。
板球比分通知器
我猜想这个功能已经在别的地方提到过了。一个窗口通知器。(在右下角的通知区域,它会告诉你实时比分以及评论信息)。如果你愿意的化,在某些时间段,你也可以关掉它。
WhatsApp 消息
这个并不太实用,我只是写着玩玩。因为 Whatsapp 有网页版,我使用 selenium 和 Python 下载我的所有联系人的显示图片,并且,一旦有人更新了他们的显示图片,我将会知道。(如何做到的?非常简单,在设定好时间间隔后,我会一遍又一遍的不停下载所有的头像信息,一旦照片的尺寸发生变化,我将会知道他/她更新了显示图片)。然后我会给他/她发一个信息,不错的头像。我仅仅使用了一次来测试它的可用性。
Nalanda 下载器
我们一般在这个叫 ‘Nalanda’ 的网站上下载一些教学课件以及其他的课程资料, ‘Nalanda’ 在 BITS Pilani (Nalanda). 我自己懒得在考试前一天下载所有的课件,所以,我写了这个这个下载器,它可以把每一门科的课件下载到相应的文件夹。



代码:
…
importmechanize,os,urllib2,urllib,requests,getpass,time
start_time=time.time()
frombs4importBeautifulSoup
br=mechanize.Browser()
br.open('https://nalanda.bits-pilani.ac.in/login/index.php')
br.select_form(nr=0)
name=''
whilename=='':
try:
print'*******'
username=raw_input('Enter Your Nalanda Username: ')
password=getpass.getpass('Password: ')
br.form['username']=username
br.form['password']=password
res=br.submit()
response=res.read()
soup=BeautifulSoup(response)
name=str(soup.find('div',attrs={'class':'logininfo'}).a.string)[:-2]
except:
print'Wrong Password'
f=open('details.txt','w')
f.write(username+'n'+password)
f.close()
print'Welcome, '+name
print'All the files will be downloaded in your Drive C in a folder named "nalanda"'
#print soup.prettify()
div=soup.find_all('div',attrs={'class':'box coursebox'})
l=len(div)
a=[]
foriinrange(l):
d=div[i]
s=str(d.div.h2.a.string)
s=s[:s.find('(')]
c=(s,str(d.div.h2.a['href']))
path='c:nalanda'+c[0]
ifnotos.path.exists(path):
os.makedirs(path)
a+=[c]
#print a
overall=[]
foriinrange(l):
response=br.open(a[i][1])
page=response.read()
soup=BeautifulSoup(page)
li=soup.find_all('li',attrs={'class':'section main clearfix'})
x=len(li)
t=[]
folder=a[i][0]
print'Downloading '+folder+' files...'
o=[]
forjinrange(x):
g=li[j].ul
#print g
#raw_input('')
ifg!=None:
temp=http://g.li['class'].split(' ')
#raw_input('')
iftemp[1]=='resource':
#print 'yes'
#print '********************'
o+=[j]
h=li[j].find('div',attrs={'class':'content'})
s=str(h.h3.string)
path='c:nalanda'+folder
ifpath[-1]==' ':
path=path[:-1]
path+=''+s
ifnotos.path.exists(path):
os.makedirs(path)
f=g.find_all('li')
r=len(f)
z=[]
foreinrange(r):
p=f[e].div.div.a
q=f[e].find('span',attrs={'class':'resourcelinkdetails'}).contents
link=str(p['href'])
text=str(p.find('span').contents[0])
typ=''
ifstr(q[0]).find('word')!=-1:
typ='.docx'
elifstr(q[0]).find('JPEG')!=-1:
typ='.jpg'
else:
typ='.pdf'
iftyp!='.docx':
res=br.open(link)
soup=BeautifulSoup(res.read())
iftyp=='.jpg':
di=soup.find('div',attrs={'class':'resourcecontent resourceimg'})
link=di.img['src']
else:
di=soup.find('div',attrs={'class':'resourcecontent resourcepdf'})
link=di.object['data']
try:
ifnotos.path.exists(path+''+text+typ):
br.retrieve(link,path+''+text+typ)[0]
except:
print'Connectivity Issues'
z+=[(link,text,typ)]
t+=[(s,z)]
ift==[]:
print'No Documents in this subject'
overall+=[o]
#raw_input('Press any button to resume')
#print overall
print'Time Taken to Download: '+str(time.time()-start_time)+' seconds'
print'Do you think you can download all files faster than this :P'
print'Closing in 10 seconds'
time.sleep(10)
…
我自己的 DC++
这个脚本并不是很有用,目前只有一些学生在用它, 况且,DC ++ 已经提供了一些很酷的功能。我原本可以优化我自己的版本,但是,由于我们已经有了DC ++,我并没有这么做,尽管我已经使用 nodeJS 和 python 写了一个基础版本。
工作原理:
打开 DC++ , 进入一个中心站点,然后连接,我写了一个 python 脚本来做这件事。 脚本会在 PC上创建一个服务器(可以通过修改 SimpleHTTPRequestHandler 来完成)。
在服务器端(使用了NodeJS),它会拿到 PC 的连接,共享给其他的用户。



这个是主页面:

这个页面显示了所有的用户和他们的链接。因为我给 Nick 加了一个超链接,所以在链接这一拦是空的。
所以,当用户数量增加以后,这个页面会列出所有的用户列表。基本上,这个页面充当了一个你和另外一个人联系的中间人角色。 我还做了一个在所有用户中搜索特定文件的功能。
这里是客户端的 python 文件(这是一段很长的代码,我上传到了 Ideone)
所有这些代码仅仅用于教育目的。返回搜狐,查看更多
英文:Quora
http://python.jobbole.com/85986/
程序员大咖整理发布,转载请联系作者获得授权
责任编辑:
python能写什么脚本_你用 Python 写过哪些牛逼的程序/脚本?相关推荐
- python中脚本是指什么_你用Python写过最牛逼的程序/脚本是什么?
有网友在 Quora 上提问,「你用 Python 写过最牛逼的程序/脚本是什么?」.本文摘编了 3 个国外程序员的多个小项目,含代码. Manoj Memana Jayakumar, 3000+ 顶 ...
- python写简单的脚本-你用 Python 写过哪些牛逼的程序/脚本?
原标题:你用 Python 写过哪些牛逼的程序/脚本? [导读]:有网友在 Quora 上提问,「你用 Python 写过最牛逼的程序/脚本是什么?」.本文摘编了 3 个国外程序员的多个小项目,含代码 ...
- 你用 Python 写过最牛逼的程序是什么?
点击上方"Python高校",关注 文末干货立马到手 编译:Python开发者 - Jake_on 英文:Quora 有网友在 Quora 上提问,「你用 Python 写过最牛 ...
- python能写什么脚本_如何用python编写一个阴阳师脚本(自动刷御魂,业原火)(2)...
在上一篇文章里,我们已经安装好了python,安装好了所有需要的库,现在可以开始码代码了嗷 先让我们来分析一下需要实现的脚本功能,首先就是这个开始战斗此时队友还没来... 当队友(舍友)进来时,开始战 ...
- python write 写多行_如何用 Python 执行单行命令
一般来说,面对日常处理的一些小任务,直接用 sed,grep 之类的就可以搞定,更复杂一点的就会考虑 awk 或者用一些现成的轮子,要是 awk 搞不定我就只好用 Python 了.但有些时候,我仅仅 ...
- python编写接口自动化脚本_简单的python http接口自动化脚本
摘抄:今天给大家分享一个简单的python脚本,使用python进行http的接口测试,脚本很简单,逻辑是:读取excel写好的测试用例,然后根据excel中的用例内容进行调用,判断预期结果中的返回值 ...
- python如何运行脚本_怎么执行python脚本文件
1.脚本式编程 将如下代码拷贝至 hello.py文件中:print ("Hello, Python!");python学习网,大量的免费python视频教程,欢迎在线学习! 通过 ...
- python 魔兽世界升级脚本_第一次用python:python脚本用来实现增量更新项目代码...
项目采用增量更新,每次更新需要将提交到svn的代码手动一一拖到本地文件夹再拖到服务器上,非常麻烦.正好学习python,就弄了个批量复制脚本,顺便熟悉下Python语法.第一次写,很多方法不熟,写的比 ...
- 有两个python怎么停用其中一_如何在python中停止另一个已经运行的脚本?
There is a way to start another script in python by doing this: import os os.system("python [na ...
最新文章
- limma包分析差异表达基因
- 谷歌发布深度学习新算法,适用于真实机器人的技能学习
- Java工程师成神之路 转
- 初识OSGI.NET插件框架
- SpringBoot项目中对mysql数据库进行定时备份为sql文件的实现思路
- macosx jdk_MacOSX环境上的多个Java JDK
- JS----正则表达式
- win8平板App-文件上传
- angularJS添加form验证:自定义验证
- java跨平台_Java如何实现跨平台
- 关于excel数据透视表的数据填充
- 23000字,讲清信息流广告数据分析。
- 做好加密手机 任重而道远
- 所谓笔法在也其次-《述张长史笔法十二意》
- Hadoop中Namenode单点故障的解决方案
- /usr/bin/ld: cannot find -lxxx
- 计算机在材料科学与工程中的应用课后答案,材料科学与工程导论课后习题答案...
- C语言---qsort函数(初步了解)
- 微信公众号运营两大痛点
- js worker 个人使用教程