图像特征分析方法---- 多维数据可视化方法
多维数据可视化方法
原标题:多维数据可视化方法,看这一篇就够了
多维数据可视化是指通过一些手段将高维的数据展示在二维的平面中。
在进行探索性数据分析及对聚类或分类问题的验证中有着重要的应用。
本文着重介绍7种基于iris数据集的多维数据可视化方法。
首先请出万能的鸢尾花数据
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
data = pd.read_csv('../input/iris/iris.csv')
data.head()

说明:前四列是特征,第五列是分类。
数据可视化方法
接下来,具体介绍对上述四个特征的数据进行可视化操作的7种方法。
1.Andrews曲线
Andrews曲线将每个样本的属性值转化为傅里叶序列的系数来创建曲线。
通过将每一类曲线标成不同颜色可以可视化聚类数据,属于相同类别的样本的曲线通常更加接近并构成了更大的结构。
from pandas.tools.plotting import andrews_curves
plt.figure()
andrews_curves(data, 'species')

2.平行坐标
平行坐标可以看到数据中的类别以及从视觉上估计其他的统计量。
使用平行坐标时,每个点用线段联接,每个垂直的线代表一个属性,一组联接的线段表示一个数据点。可能是一类的数据点会更加接近。
from pandas.tools.plotting import parallel_coordinates
plt.figure()
parallel_coordinates(data, 'species')

3.RadViz图
RadViz图是基于基本的弹簧压力最小化算法(在复杂网络分析中也会经常应用)。简单来说,将一组点放在一个平面上,每一个点代表一个属性。
上述案例中有四个点,被放在一个单位圆上,你可以设想每个数据集通过一个弹簧联接到每个点上,弹力和他们属性值成正比(属性值已经标准化),数据集在平面上的位置是弹簧的均衡位置。不同类的样本用不同颜色表示。
from pandas.tools.plotting import radviz
plt.figure()
radviz(data, 'species')

4.因子分析
因子分析最初由心理学家斯皮尔曼发明,用于研究人类的人格特质。
著名的卡特尔16PF(16种相对独立的人格特征)就是应用因素分析方法得来。
是基于高斯潜在变量的一个简单线性模型,假设每一个观察值都是由低维的潜在变量加正态噪音构成。
from sklearn import decomposition
pca = decomposition.FactorAnalysis(n_components=2)
X = pca.fit_transform(data.ix[:,:-1].values)
pos=pd.DataFrame()
pos['X'] =X[:, 0]
pos['Y'] =X[:, 1]
pos['species'] = data['species']
ax = pos.ix[pos['species']=='virginica'].
plot(kind='scatter', x='X', y='Y', color='blue', label='virginica')
ax = pos.ix[pos['species']=='setosa'].
plot(kind='scatter', x='X', y='Y', color='green', label='setosa', ax=ax)
pos.ix[pos['species']=='versicolor'].
plot(kind='scatter', x='X', y='Y', color='red', label='versicolor', ax=ax)

5.主成分分析
主成分分析是由因子分析进化而来的一种降维的方法。
通过正交变换将原始特征转换为线性独立的特征,转换后得到的特征被称为主成分。主成分分析可以将原始维度降维到n个维度。
有一个特例情况,就是通过主成分分析将维度降低为2维,可以将多维数据转换为平面中的点,来达到多维数据可视化的目的。
from sklearn import decomposition
pca = decomposition.PCA(n_components=2)
X = pca.fit_transform(data.ix[:,:-1].values)
pos=pd.DataFrame()
pos['X'] =X[:, 0]
pos['Y'] =X[:, 1]
pos['species'] = data['species']
ax = pos.ix[pos['species']=='virginica'].
plot(kind='scatter', x='X', y='Y', color='blue', label='virginica')
ax = pos.ix[pos['species']=='setosa'].
plot(kind='scatter', x='X', y='Y', color='green', label='setosa', ax=ax)
pos.ix[pos['species']=='versicolor'].
plot(kind='scatter', x='X', y='Y', color='red', label='versicolor', ax=ax

需要注意,通过PCA降维实际上是损失了一些信息,我们也可以看一下保留的两个主成分可以解释原始数据的多少。
6.独立成分分析
独立成分分析将多源信号拆分成较大可能独立性的子成分,它最初不是用来降维,而是用于拆分重叠的信号。
from sklearn import decomposition
pca = decomposition.FastICA(n_components=2)
X = pca.fit_transform(data.ix[:,:-1].values)
pos=pd.DataFrame()
pos['X'] =X[:, 0]
pos['Y'] =X[:, 1]
pos['species'] = data['species']
ax = pos.ix[pos['species']=='virginica'].
plot(kind='scatter', x='X', y='Y', color='blue', label='virginica')
ax = pos.ix[pos['species']=='setosa'].
plot(kind='scatter', x='X', y='Y', color='green', label='setosa', ax=ax)
pos.ix[pos['species']=='versicolor'].
plot(kind='scatter', x='X', y='Y', color='red', label='versicolor', ax=ax)
Out[42]:
<matplotlib.axes._subplots.AxesSubplot at 0x7f47f274af28>
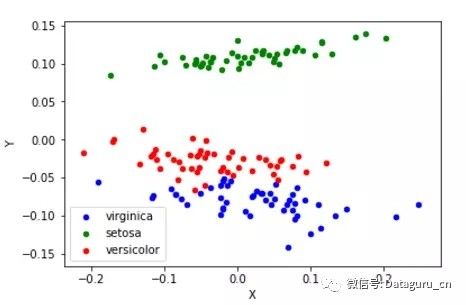
7.多维尺度分析
多维尺度分析试图寻找原始高维空间数据的距离的良好低维表征。
简单来说,多维尺度分析被用于数据的相似性,它试图用几何空间中的距离来建模数据的相似性,即用二维空间中的距离来表示高维空间的关系。
数据可以是物体之间的相似度、分子之间的交互频率或国家间交易指数,而且是基于欧式距离的距离矩阵。
多维尺度分析算法是一个不断迭代的过程,因此,需要使用max_iter来指定较大迭代次数,同时计算的耗时也是上面算法中较大的一个。
from sklearn import manifold
from sklearn.metrics import euclidean_distances
similarities = euclidean_distances(data.ix[:,:-1].values)
mds = manifold.MDS(n_components=2, max_iter=3000, eps=1e-9, dissimilarity="precomputed",
n_jobs=1)
X = mds.fit(similarities).embedding_
pos=pd.DataFrame(X, columns=['X', 'Y'])
pos['species'] = data['species']
ax = pos.ix[pos['species']=='virginica'].
plot(kind='scatter', x='X', y='Y', color='blue', label='virginica')
ax = pos.ix[pos['species']=='setosa'].
plot(kind='scatter', x='X', y='Y', color='green', label='setosa', ax=ax)
pos.ix[pos['species']=='versicolor'].
plot(kind='scatter', x='X', y='Y', color='red', label='versicolor', ax=ax)

看到以上几种算法的结果是不是觉得很神奇,相同类别的数据确实距离更近,尤其是后面几个降维算法的结果,基本上可以通过一些旋转或者坐标转换得到相似的图像。
文章来源:Cloga互联网笔记
《Python自然语言分析》这是一门基于Python实践自然语言处理典型应用场景的实战课程。理论与案例并行,通过编程实战将理论具体化展现,让学员更能理解其中的原理与实现方法。返回搜狐,查看更多
责任编辑:
相关文章:
- GSL中的多维最小值
- 数据可视化 复习笔记2022
- python聚类算法中x是多维、y是一维怎么画图_基于Python的数据可视化:从一维到多维...
- ESL3.2(下)最小二乘法学习笔记(含施密特正交化,QR分解)
- 正交设计 python算法_如何表示2D正交网格(Python)
- 标量除、矢量除、正交化
- 构建多维正交矩阵(Hadamard矩阵)
- emmm看了四个小时的天才基本法
- emmm,加了密码是因为一些东西没有写好
- emmm记不住
- emmm...记录一次愚蠢的报错
- Day1 Linux的安装emmm吧
- emmm~开个坑
- emmm自用软件
- emmm不知为何忘了写计划5.19-5.25
- emmm第一篇博客哦…
- cv2.seamlessClone遇到的问题(没有解决,只是记录用emmm)
- emmm开始我的博客世界
- 博客主Judge已跳槽搬家emmm
- 一个测试过好用的anaconda版本emmm
- 面向对象:中央戏精学院扛把子,emmm我应该是属小火车的吧~
- emmm算是来了
- 止不住的砸钱emmm
- 跳一跳 微信小程序中的跳一跳相信大家都玩过。emmm???只学习不玩游戏?那就吃亏了...好好读题理解吧 简化后的跳一跳规则如下:玩家每次从当前方块跳到下一个方块,如果没有跳到下一个方块上则游
- emmm小游戏 Construct
- emmm小游戏续集
- emmm
- Jensen不等式及其详细证明——Emmm...?Emmm...! EM算法(1)
- Linux基本命令用法(最基本的emmm)
- 无监督学习方法
图像特征分析方法---- 多维数据可视化方法相关推荐
- Tikz作图教程:pgfplots宏包二维数据可视化的数据导入方法
pgfplots 绘图思想简介 下面一段介绍来自pgfplots说明文档的引言部分,它对pgfplots的绘图思想作了清晰地描述: 科研工作者在交流研究结果.论文时,将数据可视化往往是必要和方便的. ...
- 基于HTML5的数据可视化方法有哪些
现在在大数据的带领下,数据可视化越来越突出,能够清楚的分析出自己想要的数据,这也是我们现在最求的数据可视化方法,那么实现HTML5的数据可视化方法有哪些?这都是我们值得研究的东西,数据可以给我们带 ...
- MATLAB科研数据可视化方法
互联网的飞速发展伴随着海量信息的产生,而海量信息的背后对应的则是海量数据.如何从这些海量数据中获取有价值的信息来供人们学习和工作使用,这就不得不用到大数据挖掘和分析技术.数据可视化分析作为大数据技术的 ...
- 大脑数据可视化方法_使用r可视化大脑
大脑数据可视化方法 介绍 (Introduction) Recently, I took an introductory psychology course in my first year of u ...
- 数据可视化方法:数据图表展示
相信大多数公司的领导都已失去了一字一句看表格和文字的耐心,简化数据信息的方式之一就是图表,图表能够直观地展示数据,支撑观点,图表已经成了报表中最常用的数据展现方式之一.人类大脑对视觉信息的处理优于对 ...
- 大数据可视化方法有哪些
数据可视化是指将数据以视觉的形式来呈现,如图表或地图,以帮助人们了解这些数据的意义.人类大脑对视觉信息的处理优于对文本的处理,因此使用图表.图形和设计元素把数据进行可视化,可以帮你更容易的解释数据模式 ...
- 从1维到6维,一文读懂多维数据可视化策略
本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载 选自towardsdatascience 作者:Dipanjan Sarkar 参与:Jane W.乾树.黄小天 数 ...
- python降维方法_机器学习数据降维方法总结(附python代码)
介绍 在机器学习实战时,如果面对一个数据集具有上千个特征,那么对于模型训练将是一个巨大的挑战.面对如此多的数据变量,如果我们认真的去分析每一个变量将耗费我们几周甚至几个月的时间,那么你估计也要被开除了 ...
- 【Python可视化展示】-多维数据可视化分析
前言 以下是我为大家准备的几个精品专栏,喜欢的小伙伴可自行订阅,你的支持就是我不断更新的动力哟! MATLAB-30天带你从入门到精通 MATLAB深入理解高级教程(附源码) tableau可视化数据 ...
最新文章
- 基于Smiles2vec预测化合物物理性质
- BZOJ 2820 YY的GCD 莫比乌斯反演
- 中国大学科技园市场投资规划及需求前景预测报告2022-2028年版
- 06_基本的图像分类案例、导入图片数据、探索数据的格式、数据预处理、构建模型(设置层、编译模型)、训练模型(Fit模型、评估精确度)、得出预测结果(验证预测结果)、使用训练过的模型
- pythonos pathjson_python进阶05 常用问题库(1)json os os.path模块
- Java未来路在何方?挑战大厂重燃激情!
- 五种方式让你在java中读取properties文件内容不再是难题
- Shell脚本——基础语法
- (王道408考研操作系统)第五章输入/输出(I/O)管理-第一节6:设备的分配和回收
- 【英语学习】【WOTD】adjudicate 释义/词源/示例
- 被绿以后,我成了年薪百万的“小三劝退师”
- 若在一分页存储管理系统中,某作业的页表如表所示。已知页面大小为 1024字节,试将逻辑地址 1011,2148,3000,4000,5012转化为相应的物理地址。
- 如何关闭电脑弹窗(2种方法)
- 软件设计模式(持续更新)
- linux应用程序调用aplay,linux - 在播放整首歌曲之前,aplay退出 - 堆栈内存溢出
- 本周AI热点回顾:百度推出全球首个mRNA疫苗不稳定性解决方案、性能提升20倍:英伟达GPU旗舰A100
- 重磅突发!支付宝下架互联网存款产品,蚂蚁集团回应
- 英语影视台词---绿皮书(1)
- Spring注入bean报错:Error creating bean with name的网上找不到的解决方案
- 存储系统 - 存储网络的发展