PageRank算法并行实现
算法为王系列文章,涵盖了计算机算法,数据挖掘(机器学习)算法,统计算法,金融算法等的多种跨学科算法组合。在大数据时代的背景下,算法已经成为了金字塔顶的明星。一个好的算法可以创造一个伟大帝国,就像Google。
算法为王的时代正式到来….
关于作者:
- 张丹(Conan), 程序员Java,R,PHP,Javascript
- weibo:@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/algorithm-pagerank-mapreduce/

前言
Google通过PageRank算法模型,实现了对全互联网网页的打分。但对于海量数据的处理,在单机下是不可能实现,所以如何将PageRank并行计算,将是本文的重点。
本文将继续上一篇文章 PageRank算法R语言实现,把PageRank单机实现,改成并行实现,利用MapReduce计算框架,在集群中跑起来。
目录
- PageRank算法并行化原理
- MapReduce分步式编程
1. PageRank算法分步式原理
单机算法原理请参考文章:PageRank算法R语言实现
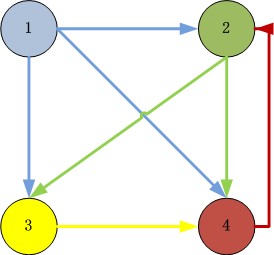
PageRank的分步式算法原理,简单来讲,就是通过矩阵计算实现并行化。
1). 把邻接矩阵的列,按数据行存储
邻接矩阵
[,1] [,2] [,3] [,4]
[1,] 0.0375000 0.0375 0.0375 0.0375
[2,] 0.3208333 0.0375 0.0375 0.8875
[3,] 0.3208333 0.4625 0.0375 0.0375
[4,] 0.3208333 0.4625 0.8875 0.0375
按行存储HDFS
1 0.037499994,0.32083333,0.32083333,0.32083333
2 0.037499994,0.037499994,0.4625,0.4625
3 0.037499994,0.037499994,0.037499994,0.88750005
4 0.037499994,0.88750005,0.037499994,0.037499994
2). 迭代:求矩阵特征值
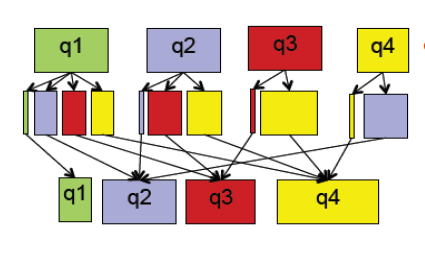
map过程:
- input: 邻接矩阵, pr值
- output: key为pr的行号,value为邻接矩阵和pr值的乘法求和公式
reduce过程:
- input: key为pr的行号,value为邻接矩阵和pr值的乘法求和公式
- output: key为pr的行号, value为计算的结果,即pr值
第1次迭代
0.0375000 0.0375 0.0375 0.0375 1 0.150000
0.3208333 0.0375 0.0375 0.8875 * 1 = 1.283333
0.3208333 0.4625 0.0375 0.0375 1 0.858333
0.3208333 0.4625 0.8875 0.0375 1 1.708333
第2次迭代
0.0375000 0.0375 0.0375 0.0375 0.150000 0.150000
0.3208333 0.0375 0.0375 0.8875 * 1.283333 = 1.6445833
0.3208333 0.4625 0.0375 0.0375 0.858333 0.7379167
0.3208333 0.4625 0.8875 0.0375 1.708333 1.4675000
… 10次迭代
特征值
0.1500000
1.4955721
0.8255034
1.5289245
3). 标准化PR值
0.150000 0.0375000
1.4955721 / (0.15+1.4955721+0.8255034+1.5289245) = 0.3738930
0.8255034 0.2063759
1.5289245 0.3822311
2. MapReduce分步式编程
MapReduce流程分解
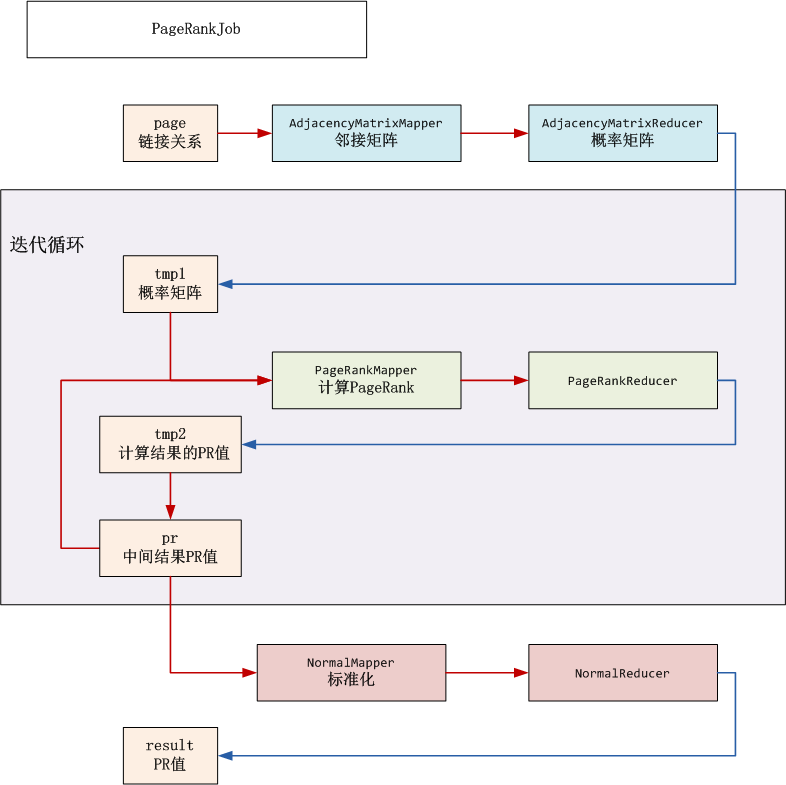
HDFS目录
- input(/user/hdfs/pagerank): HDFS的根目录
- input_pr(/user/hdfs/pagerank/pr): 临时目录,存储中间结果PR值
- tmp1(/user/hdfs/pagerank/tmp1):临时目录,存储邻接矩阵
- tmp2(/user/hdfs/pagerank/tmp2):临时目录,迭代计算PR值,然后保存到input_pr
- result(/user/hdfs/pagerank/result): PR值输出结果
开发步骤:
- 网页链接关系数据: page.csv
- 出始的PR数据:pr.csv
- 邻接矩阵: AdjacencyMatrix.java
- PageRank计算: PageRank.java
- PR标准化: Normal.java
- 启动程序: PageRankJob.java
1). 网页链接关系数据: page.csv
新建文件:page.csv
1,2
1,3
1,4
2,3
2,4
3,4
4,2
2). 出始的PR数据:pr.csv
设置网页的初始值都是1
新建文件:pr.csv
1,1
2,1
3,1
4,1
3). 邻接矩阵: AdjacencyMatrix.java

矩阵解释:
- 阻尼系数为0.85
- 页面数为4
- reduce以行输出矩阵的列,输出列主要用于分步式存储,下一步需要转成行
新建程序:AdjacencyMatrix.java
package org.conan.myhadoop.pagerank;import java.io.IOException;
import java.util.Arrays;
import java.util.Map;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;public class AdjacencyMatrix {private static int nums = 4;// 页面数private static float d = 0.85f;// 阻尼系数public static class AdjacencyMatrixMapper extends Mapper<LongWritable, Text, Text, Text> {@Overridepublic void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {System.out.println(values.toString());String[] tokens = PageRankJob.DELIMITER.split(values.toString());Text k = new Text(tokens[0]);Text v = new Text(tokens[1]);context.write(k, v);}}public static class AdjacencyMatrixReducer extends Reducer<Text, Text, Text, Text> {@Overridepublic void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {float[] G = new float[nums];// 概率矩阵列Arrays.fill(G, (float) (1 - d) / G.length);float[] A = new float[nums];// 近邻矩阵列int sum = 0;// 链出数量for (Text val : values) {int idx = Integer.parseInt(val.toString());A[idx - 1] = 1;sum++;}if (sum == 0) {// 分母不能为0sum = 1;}StringBuilder sb = new StringBuilder();for (int i = 0; i < A.length; i++) {sb.append("," + (float) (G[i] + d * A[i] / sum));}Text v = new Text(sb.toString().substring(1));System.out.println(key + ":" + v.toString());context.write(key, v);}}public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {JobConf conf = PageRankJob.config();String input = path.get("input");String input_pr = path.get("input_pr");String output = path.get("tmp1");String page = path.get("page");String pr = path.get("pr");HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);hdfs.rmr(input);hdfs.mkdirs(input);hdfs.mkdirs(input_pr);hdfs.copyFile(page, input);hdfs.copyFile(pr, input_pr);Job job = new Job(conf);job.setJarByClass(AdjacencyMatrix.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);job.setMapperClass(AdjacencyMatrixMapper.class);job.setReducerClass(AdjacencyMatrixReducer.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);FileInputFormat.setInputPaths(job, new Path(page));FileOutputFormat.setOutputPath(job, new Path(output));job.waitForCompletion(true);}
}
4). PageRank计算: PageRank.java
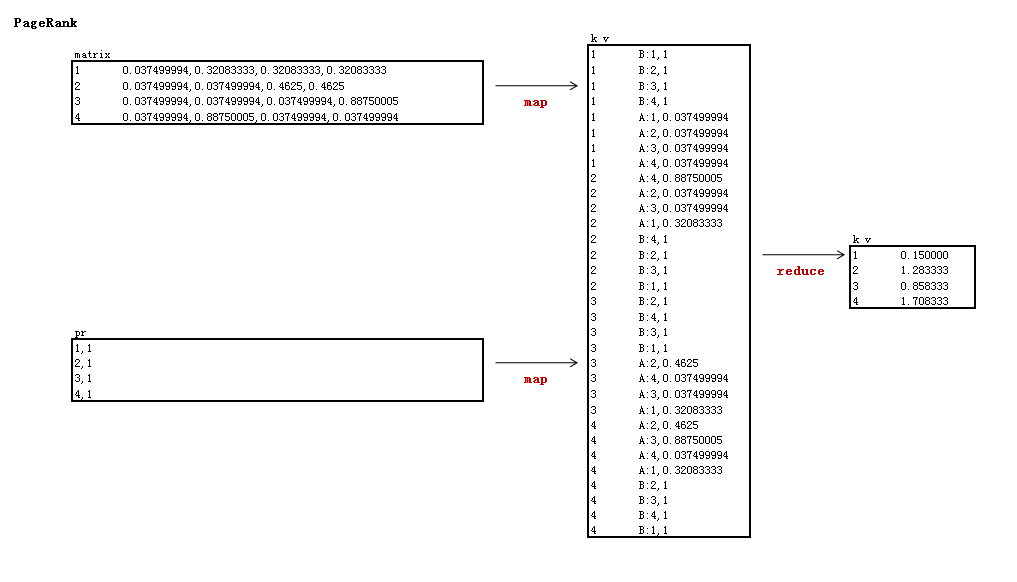
矩阵解释:
- 实现邻接与PR矩阵的乘法
- map以邻接矩阵的行号为key,由于上一步是输出的是列,所以这里需要转成行
- reduce计算得到未标准化的特征值
新建文件: PageRank.java
package org.conan.myhadoop.pagerank;import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;public class PageRank {public static class PageRankMapper extends Mapper<LongWritable, Text, Text, Text> {private String flag;// tmp1 or resultprivate static int nums = 4;// 页面数@Overrideprotected void setup(Context context) throws IOException, InterruptedException {FileSplit split = (FileSplit) context.getInputSplit();flag = split.getPath().getParent().getName();// 判断读的数据集}@Overridepublic void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {System.out.println(values.toString());String[] tokens = PageRankJob.DELIMITER.split(values.toString());if (flag.equals("tmp1")) {String row = values.toString().substring(0,1);String[] vals = PageRankJob.DELIMITER.split(values.toString().substring(2));// 矩阵转置for (int i = 0; i < vals.length; i++) {Text k = new Text(String.valueOf(i + 1));Text v = new Text(String.valueOf("A:" + (row) + "," + vals[i]));context.write(k, v);}} else if (flag.equals("pr")) {for (int i = 1; i <= nums; i++) {Text k = new Text(String.valueOf(i));Text v = new Text("B:" + tokens[0] + "," + tokens[1]);context.write(k, v);}}}}public static class PageRankReducer extends Reducer<Text, Text, Text, Text> {@Overridepublic void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {Map<Integer, Float> mapA = new HashMap<Integer, Float>();Map<Integer, Float> mapB = new HashMap<Integer, Float>();float pr = 0f;for (Text line : values) {System.out.println(line);String vals = line.toString();if (vals.startsWith("A:")) {String[] tokenA = PageRankJob.DELIMITER.split(vals.substring(2));mapA.put(Integer.parseInt(tokenA[0]), Float.parseFloat(tokenA[1]));}if (vals.startsWith("B:")) {String[] tokenB = PageRankJob.DELIMITER.split(vals.substring(2));mapB.put(Integer.parseInt(tokenB[0]), Float.parseFloat(tokenB[1]));}}Iterator iterA = mapA.keySet().iterator();while(iterA.hasNext()){int idx = iterA.next();float A = mapA.get(idx);float B = mapB.get(idx);pr += A * B;}context.write(key, new Text(PageRankJob.scaleFloat(pr)));// System.out.println(key + ":" + PageRankJob.scaleFloat(pr));}}public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {JobConf conf = PageRankJob.config();String input = path.get("tmp1");String output = path.get("tmp2");String pr = path.get("input_pr");HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);hdfs.rmr(output);Job job = new Job(conf);job.setJarByClass(PageRank.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);job.setMapperClass(PageRankMapper.class);job.setReducerClass(PageRankReducer.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);FileInputFormat.setInputPaths(job, new Path(input), new Path(pr));FileOutputFormat.setOutputPath(job, new Path(output));job.waitForCompletion(true);hdfs.rmr(pr);hdfs.rename(output, pr);}
}
5). PR标准化: Normal.java

矩阵解释:
- 对PR的计算结果标准化,让所以PR值落在(0,1)区间
新建文件:Normal.java
package org.conan.myhadoop.pagerank;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;public class Normal {public static class NormalMapper extends Mapper<LongWritable, Text, Text, Text> {Text k = new Text("1");@Overridepublic void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {System.out.println(values.toString());context.write(k, values);}}public static class NormalReducer extends Reducer<Text, Text, Text, Text> {@Overridepublic void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {List vList = new ArrayList();float sum = 0f;for (Text line : values) {vList.add(line.toString());String[] vals = PageRankJob.DELIMITER.split(line.toString());float f = Float.parseFloat(vals[1]);sum += f;}for (String line : vList) {String[] vals = PageRankJob.DELIMITER.split(line.toString());Text k = new Text(vals[0]);float f = Float.parseFloat(vals[1]);Text v = new Text(PageRankJob.scaleFloat((float) (f / sum)));context.write(k, v);System.out.println(k + ":" + v);}}}public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {JobConf conf = PageRankJob.config();String input = path.get("input_pr");String output = path.get("result");HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);hdfs.rmr(output);Job job = new Job(conf);job.setJarByClass(Normal.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);job.setMapperClass(NormalMapper.class);job.setReducerClass(NormalReducer.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);FileInputFormat.setInputPaths(job, new Path(input));FileOutputFormat.setOutputPath(job, new Path(output));job.waitForCompletion(true);}
}
6). 启动程序: PageRankJob.java
新建文件:PageRankJob.java
package org.conan.myhadoop.pagerank;import java.text.DecimalFormat;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;import org.apache.hadoop.mapred.JobConf;public class PageRankJob {public static final String HDFS = "hdfs://192.168.1.210:9000";public static final Pattern DELIMITER = Pattern.compile("[\t,]");public static void main(String[] args) {Map<String, String> path = new HashMap<String, String>();path.put("page", "logfile/pagerank/page.csv");// 本地的数据文件path.put("pr", "logfile/pagerank/pr.csv");// 本地的数据文件path.put("input", HDFS + "/user/hdfs/pagerank");// HDFS的目录path.put("input_pr", HDFS + "/user/hdfs/pagerank/pr");// pr存储目path.put("tmp1", HDFS + "/user/hdfs/pagerank/tmp1");// 临时目录,存放邻接矩阵path.put("tmp2", HDFS + "/user/hdfs/pagerank/tmp2");// 临时目录,计算到得PR,覆盖input_prpath.put("result", HDFS + "/user/hdfs/pagerank/result");// 计算结果的PRtry {AdjacencyMatrix.run(path);int iter = 3;for (int i = 0; i < iter; i++) {// 迭代执行PageRank.run(path);}Normal.run(path);} catch (Exception e) {e.printStackTrace();}System.exit(0);}public static JobConf config() {// Hadoop集群的远程配置信息JobConf conf = new JobConf(PageRankJob.class);conf.setJobName("PageRank");conf.addResource("classpath:/hadoop/core-site.xml");conf.addResource("classpath:/hadoop/hdfs-site.xml");conf.addResource("classpath:/hadoop/mapred-site.xml");return conf;}public static String scaleFloat(float f) {// 保留6位小数DecimalFormat df = new DecimalFormat("##0.000000");return df.format(f);}
}
程序代码已上传到github:
https://github.com/bsspirit/maven_hadoop_template/tree/master/src/main/java/org/conan/myhadoop/pagerank
这样就实现了,PageRank的并行吧!接下来,我们就可以用PageRank做一些有意思的应用了。
转载请注明出处:
http://blog.fens.me/algorithm-pagerank-mapreduce/
PageRank算法并行实现相关推荐
- hadoop上的pageRank算法
简单的pageRank实现参考:http://wlh0706-163-com.iteye.com/blog/1397694 较为复杂的PR值计算以及在hadoop上的实现:http://deathsp ...
- [转]PageRank算法
原文引自: 原文引自: http://blog.csdn.net/hguisu/article/details/7996185 感谢 1. PageRank算法概述 PageRank,即网页排名,又称 ...
- 张洋:浅析PageRank算法
本文引自http://blog.jobbole.com/23286/ 很早就对Google的PageRank算法很感兴趣,但一直没有深究,只有个轮廓性的概念.前几天趁团队outing的机会,在动车上看 ...
- PageRank算法--从原理到实现
本文将介绍PageRank算法的相关内容,具体如下: 1.算法来源 2.算法原理 3.算法证明 4.PR值计算方法 4.1 幂迭代法 4.2 特征值法 4.3 代数法 5.算法实现 5.1 基于迭代法 ...
- 数据挖掘十大经典算法之——PageRank 算法
数据挖掘十大经典算法系列,点击链接直接跳转: 数据挖掘简介及十大经典算法(大纲索引) 1. 数据挖掘十大经典算法之--C4.5 算法 2. 数据挖掘十大经典算法之--K-Means 算法 3. 数据挖 ...
- pagerank算法实现matlab,Matlab 入门及PageRank算法求解.ppt
Matlab 入门及PageRank算法求解 矩阵运算 + 矩阵加 - 矩阵减 * 矩阵乘 / 矩阵左除 \ 矩阵右除 ^ 矩阵幂 维数相同才能加减:方 阵才能求幂. 注意左乘,右乘. a\b?求a* ...
- 复现经典:《统计学习方法》第21章 PageRank算法
第21章 PageRank算法 本文是李航老师的<统计学习方法>一书的代码复现.作者:黄海广 备注:代码都可以在github中下载.我将陆续将代码发布在公众号"机器学习初学者&q ...
- 【白话机器学习】算法理论+实战之PageRank算法
1. 写在前面 如果想从事数据挖掘或者机器学习的工作,掌握常用的机器学习算法是非常有必要的,常见的机器学习算法: 监督学习算法:逻辑回归,线性回归,决策树,朴素贝叶斯,K近邻,支持向量机,集成算法Ad ...
- SEO算法:如何通过PageRank算法判断SEO排序结果
想必在做SEO的时候有同学发现相同的网站有两个页面但是排名的名次不同,既然是同一个网站那么应该权重都一样怎么会一个排名前面一个后面呢?在搜索引擎当中每个网页都有对应的页面得分在决定这两个页面排名顺序是 ...
最新文章
- 网站基于vs,复选框,单选款
- python转换数据类型(int、float、str、eval、tuple、list、chr、ord、bin、oct、hex)
- ubuntu下eclipse中键盘失灵
- C++习题 商品销售(商店销售某一商品,每天公布统一的折扣(discount)。同时允许销售人员在销售时灵活掌握售价(price),在此基础上,一次购10件以上者,还可以享受9.8折优惠。)...
- springboot配置文件加载顺序
- mysql 视图慢_第03问:磁盘 IO 报警,MySQL 读写哪个文件慢了?
- unity, 非public变量需要加[SerializeField]才能序列化
- php 23种设计模型 - 组合模式(合成模式)
- 驱动中定时器,taskle,工作队列编程
- 家里门不小心反锁应该怎么办?
- python requests 异步调用_构建高效的python requests长连接池详解
- Kubernetes 小白学习笔记(28)--kubernetes云原生应用开发-高可用私有镜像仓库搭建
- NVMe驱动解析-前言
- Zabbix5 安装教程
- html自由变换图形,ps自由变换的快捷键是什么?
- Craps小游戏简单代码实现
- JVM性能调优1:JVM性能调优理论及实践(收集整理)
- 解决Appium Desktop 测试中,元素不能准确定位的问题
- Unity游戏开发客户端面经——算法(初级)
- 【手机端测试的关注点】Android 和 IOS 两大主流系统测试点
热门文章
- Apache ZooKeeper - Leader Election使用场景
- 白话Elasticsearch46-深入聚合数据分析之Cardinality Aggs-cardinality去重算法以及每月销售品牌数量统计
- Spring-AOP 通过配置文件实现 前置增强
- in java中文版百度云 thinking_小程序订阅消息推送(含源码)java实现小程序推送,springboot实现微信消息推送...
- 同一事务多次加for_Synchronized锁在Spring事务管理下,为啥还线程不安全?
- python学习笔记(一)——操作符和运算变量
- Seata阿里分布式事务中间件(一):Seata的基本介绍
- git指定版本openwrt源码_[OpenWrt Wiki] LEDE源代码
- c语言编写的程序停止运行程序,C语言中,编译成功但运行停止的几个原因
- 远程过程调用失败_Dubbo 本地调用