在大数据里:Hadoop可能是你的救命稻草
用于数据分析的开源Hadoop架构的巨大增长是由其结构化和非结构化数据量的增长所驱动的,并且很多权威组织也预测,未来Hadoop架构还将继续增长,并需要复杂的可访问工具来从数据中提取业务和市场信息。
对于Hadoop来说,前景很乐观——开源框架旨在促进巨大数据集的分布式处理。Hadoop对企业越来越具有吸引力,因为它既可以获取大数据的好处,同时又避免了基础架构费用。
联合市场研究部门最近的一份报告表明,Hadoop市场将实现从2013年到2020年的复合年增长率为58.2%,到2020年整个市场将达到502亿美元,而2012年为15亿美元。

大数据到底有多“大”?根据IBM的说法,每天都会产生2.5万亿字节的数据,世界上所有数据的90%都是在过去两年中创建的。意识到这个巨大的信息商店的价值就需要数据分析工具,这些数据分析工具足够复杂,价格便宜,而且对于各种规模的公司来说都很容易使用。
许多企业认为其专有数据太重要,无法在其他场合存储和处理。然而,云服务现在提供与内部系统相同的安全性和可用性。通过访问云中的数据库,企业也意识到可承受和可扩展的云架构的优势。
Morpheus数据库即服务提供企业对其数据智能操作所需的安全性,高可用性和可扩展性。通过Morpheus使用100%的裸机SSD托管和性能最大化。该服务为Amazon Web Services和其他对等点以及云托管平台提供超低延迟。
Hadoop的Nuts和Bolts大数据分析
Hadoop架构将数据存储和处理都分配到网络上的所有节点。 通过将处理数据的小程序放置在具有更大数据集的节点中,不需要将数据流传输到处理模块。Hadoop调度和资源管理框架执行映射并减少集群环境中的阶段步骤。
Hadoop分布式文件系统(HDFS)数据存储层使用副本来克服节点故障,并针对顺序读取进行了优化,以支持大规模并行处理。当框架扩展到支持Amazon Web Services S3和其他云存储文件系统时,Hadoop的市场真的要起飞了。
尽管由于设置和运行Hadoop集群的复杂性、框架的成本低和可扩展性等优势,在中小型企业中采用Hadoop仍然很难。新服务通过提供受管理并可以使用的Hadoop集群来消除复杂性:无需在集群节点上配置或安装任何服务。
Netflix数据仓库将Hadoop和Amazon S3结合在一起,实现无限可扩展性
Netflix针对其PB级数据仓库,通过Hadoop分布式文件系统选择亚马逊的存储服务(S3),以实现基于云服务的动态可扩展性和无限数据计算能力。Netflix从来自电视,计算机和移动设备的数十亿个流媒体事件中收集数据。
以S3作为其数据仓库,可以为具有数百个节点的Hadoop集群配置各种工作负载,所有这些都能够访问相同的数据。Netflix使用Amazon的弹性MapReduce分发Hadoop,并开发了自己的Hadoop平台即服务,它称之为Genie。Genie允许用户从Hadoop,Pig,Hive和其他工具提交作业,而无需通过RESTful API来配置新的集群或安装新的客户端。
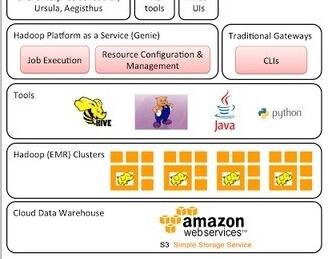
▲Netflix Hadoop-S3数据仓库在广泛分布的网络中提供了无与伦比的数据和计算能力。
Wired的Marco Visibelli在2014年8月13日的文章中解释说,结合Hadoop和云服务有显着的潜力。Visibelli描述了公司如何利用Big Data进行预测,通过Amazon Web Services从小型项目扩展,并在小项目取得成功的同时进行扩展。例如,一家欧洲汽车制造商使用Hadoop将几个供应商数据库结合到一个单一的15TB数据库中,两年内节省了1600万美元。
Hadoop为各种规模的组织打开了“大数据”大门。 利用Morpheus数据库作为服务的云服务的可扩展性,安全性,可访问性和可承受性的项目有更大的成功机会。
本文作者:钰莹
来源:51CTO
在大数据里:Hadoop可能是你的救命稻草相关推荐
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- 大数据与Hadoop有什么关系?大数据Hadoop入门简介
学习着数据科学与大数据技术专业(简称大数据)的我们,对于"大数据"这个词是再熟悉不过了,而每当我们越去了解大数据就越发现有个词也会一直被提及那就是--Hadoop 那Hadoop与 ...
- 大数据之Hadoop学习——动手实战学习MapReduce编程实例
文章目录 一.MapReduce理论基础 二.Hadoop.Spark学习路线及资源收纳 三.MapReduce编程实例 1.自定义对象序列化 需求分析 报错:Exception in thread ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据 python hadoop_大数据与Hadoop
1. 大数据简介 1.1 大数据的由来 随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快,随着互联网.物联网建设的加快,信息更是爆炸式增长,收集.检索 ...
- 大讲台浅谈大数据与Hadoop之间的关系
在现如今,随着面对当前企业级用户对于自建数据中心兴趣的不断扩大,以及大数据正在以惊人的速度增长几乎触及各行各业,而大数据是一种新兴的数据挖掘技术,它正在让数据处理和分析变得更便宜更快速.大数据技术一旦 ...
- 大数据和Hadoop时代的维度建模和Kimball数据集市
维度建模已死? 在回答这个问题之前,让我们回头来看看什么是所谓的维度数据建模. 为什么需要为数据建模? 有一个常见的误区,数据建模的目的是用 ER 图来设计物理数据库,实际上远不仅如此.数据建模代表了 ...
- 打怪升级之小白的大数据之旅(四十一)<大数据与Hadoop概述>
打怪升级之小白的大数据之旅(四十) Hadoop概述 上次回顾 好了,经过了java,mysql,jdbc,maven以及Linux和Shell的洗礼,我们终于开始正式进入大数据阶段的知识了,首先我会 ...
- 细细品味大数据--初识hadoop
初识hadoop 前言 之前在学校的时候一直就想学习大数据方面的技术,包括hadoop和机器学习啊什么的,但是归根结底就是因为自己太懒了,导致没有坚持多长时间,加上一直为offer做准备,所以当时重心 ...
- GitChat · 大数据 | 一步一步学习大数据:Hadoop 生态系统与场景
目录(?)[-] Hadoop概要 Hadoop相关组件介绍 HDFS Yarn Hive HBase Spark Other Tools Hadoop集群硬件和拓扑规划 硬件配置 软件配置 Hado ...
最新文章
- oracle 10g undo 管理,Oracle 10g undo表空间管理
- 计算机不等长编码有哪些,第9讲最佳不等长编码_W
- BeetleX实现HTTP协议详解
- webstorm前端调用后端接口_软件测试面试题:怎么去判断一个bug是前端问题还是后端问题...
- ThinkPHP V5.0 正式版发布
- 三百行python代码的项目_300行Python代码打造实用接口测试框架
- 基于FPGA的车牌识别
- Weiss Ratings公布加密货币评级结果
- 【Matlab三维路径规划】狼群算法算法三维路径规划【含源码 167期】
- mysql计算1000天后的日期_Mysql中常用的日期函数
- 使用easypoi操作excel
- sql嵌套查询出现类型问题
- 微信小程序中使用emoji表情相关说明
- ONE~~~~~~~~~
- 架构之美【kubernetes、Prometheus、微服务、LVS负载均衡】
- 4G远程智能巡检摄像机解决方案对比
- 旋转关节(Revolute Joint)
- C语言实现设计模式-策略模式+命令模式组合使用
- 联想笔记本安装PHP环境,联想笔记本装系统步骤 教你如何正确安装笔记本系统...
- 谱密度 matlab,(完整word版)功率谱密度估计方法的MATLAB实现