https://mp.weixin.qq.com/s/O7VTHqpCFNJQi3EpucXkIw
简单介绍AtomicAutomata的实现。(细节问题太多,恕不完全表述。)

1. 基本功能
AtomicAutomata是一个适配模块,为下游节点添加Atomic操作的支持。Atomic操作包括数学运算和逻辑运算两大类。
类参数如下:
a. logical:是否为下游节点添加logical操作支持,也就是AtomicAutomata这个节点是否实现logical原子操作;
b. arithmetic:同logical,是否实现数学运算原子操作;
c. concurrency:并行通道数目,也就是最大能够支持多少个原子操作同时进行;
d. passthrough:如果下游节点支持某原子操作,是否直接把消息传递给下游节点;如果不透传(passthrough == false),那么If !passthrough, intercept all Atomics. Otherwise, only intercept those unsupported downstream.
2. 基本原理
所有的节点都支持Get/Put消息,而TL-UL的节点不支持Atomic消息。所以可以通过Get/Put来模拟Atomic的消息。
AtomicAutomata节点处在中间做适配工作。流程如下:
a. 上游节点发送Atomic请求;
b. AtomicAutomata节点收到Atomic请求后,向下游节点发送Get请求获取数据;
c. Get响应(AccessAckData)返回数据;
d. AtomicAutomata节点收到数据后,执行数学或逻辑运算;
e. 把运算结果写回(Put)下游节点;
f. AtomicAutomata节点收到Put响应(AccessAck)后,返回Get的数据给上游节点;
3. 功能限制
为了避免缓存过多数据,AtomicAutomata节点只处理大小在beatBytes之内的请求,即数据传输只需要一个beat。
4. Diplomatic节点:node
用于与上下游节点协商参数的适配节点:

因为功能限制,所以参数在向上传递时需要做适配。
1) ourSupport
当前AtomicAutomata支持的传输大小:

最小为1个字节,最多为mp.beatBytes个字节。
mp为下游节点,根据下游节点的带宽,确定当前节点支持的数据宽度。
2) widen
相较于下游节点支持的传输大小,是否需要扩大:

a. 如果不透传,则支持的大小就是当前AtomicAutomata节点的能力大小(ourSupport);
b. x.min和mp.beatBytes都是2的幂,如果x.min > 2*mp.beatBytes,代表x和ourSupport没有交集。也就是说下游节点支持的最小传输大小都大于ourSupport;所以只能由我们来替下游节点实现原子操作,支持的传输大小为ourSupport;
c. 如果可以透传,并且x和ourSupport有交集,那么可以把x和ourSupport合并。传输大小在[1, mp.beatBytes]的由当前AtomicAutomata处理,传输大小在(mp.beatBytes, x.max](如果x.max大于mp.beatBytes的话)透传给下游节点处理。
3) canDoIt

能否代为实现原子操作,还要看下游节点支持的Get/Put传输大小,是否不小于ourSupport所需要的大小。
4) supportsArithmetic
把更新后的supportsArithmetic参数传递给AtomicAutomata节点的上游节点知道:

a. 如果AtomicAutomata节点不支持arithmetic功能或者无法根据原理实现arithmetic原子则做,则直接把下游节点的支持情况告知上有节点;
b. 如果可以代为实现,则把合并后的传输大小告知上游节点;
5) supportsLogical
参考supportsArithmetic。
5. 逻辑实现:module
1) 输入边与输出边
输入边连接上游节点,输出边连接下游节点,两者成对出现:

2) violations
最新版本的代码如下:

个人理解:为了保证实现原子操作的Get/Put中不被插入其他请求,要求下游节点只有一个输入边。
3) managersNeedingHelp
查找需要帮助的managers:

三个条件:
a. 需要帮:supportsLogical小于ourSupport:!m.supportsLogical .contains(ourSupport);
b. 可以帮:条件如:m.supportsGet.contains(ourSupport)等;
c. 我能帮:logical/arithmetic/passthrough;
4) domainsNeedingHelp
请求以fifoId排序,而非managers:

5) CAM
CAM中的每一个entry对应着一个并行的原子操作请求。上游节点的Atomic请求按fifoId划分,选择CAM entry存储,然后再向下游节点发起Get/Put请求。
a. camSize
CAM entry的数目:

concurrency是最多支持多少并行请求的数量,domainsNeedingHelp.size是存在的并行请求的数量。
b. camFifoId
计算manager的fifoId在domainsNeedingHelp中的序号:

用于确定使用哪一个CAM entry。
c. state
标识原子请求的处理过程的几个状态:

a. FREE:当前CAM entry没有被使用,收到上游节点的Atomic请求后变为GET状态;
b. GET:已经向下游节点发出了Get请求;收到下游节点返回的数据后转入AMO状态;
c. AMO:Atomic Memory Operation,正在进行数学或逻辑运算;运算完成向下游节点发出写数据请求后转入ACK状态;
d. ACK:Put已经向下游节点发出,等待回复AccessAck;
6) 如果没有节点需要帮助:camSize == 0
则直接把in和out相连即可:

下面主要关注如何实现帮助下游节点实现原子操作的逻辑。
7) cam_s/a/d

cam_s:存放CAM entry的状态;
cam_a:存放上游节点在Atomic操作中发来的数据(in.a.data),为第一个运算数;
cam_d:存放下游节点在AccessAckData中发来的数据,为第二个运算数;
8) cam_free/amo/abusy/dmatch
把cam的状态转换为Bool类型的标志:

cam_free:每一个entry是否FREE;
cam_amo:每一个entry是否在AMO状态;
cam_abusy:如果已经缓存了一个同fifoId的Atomic请求,则不能再接收新的Atomic请求;
cam_dmatch:处理下游节点返回的消息时,是否需要检查这一个entry;
9) 检查上游节点的请求:in.a

a. a_address:取出访问地址;
b. a_size:取出访问大小;
c. a_canLogical
下游节点是否可以处理当前访问空间(起始地址、访问大小)上的逻辑运算,需要满足两个条件:
- 在请求的访问空间上,下游节点支持逻辑运算;
- 允许透传请求;
d. a_canArithmetic:同a_canLogical;
e. a_isLogical:是否逻辑运算原子操作请求;
f. a_isArithmetic:是否数学运算原子操作请求;
g. a_isSupported:下游节点是否可以处理这个请求;如果既非逻辑运算,亦非数学运算,则不是原子操作,默认可以支持。
10) 是否需要向下游节点发起Put请求

a. a_cam_any_put:是否存在AMO状态的entry,如果存在则需要发起Put请求;
b. a_cam_por_put:用于实现低序号entry的优先级;
c. a_cam_sel_put:找出第一个AMO状态的entry(按序号从低到高排序);
d. a_cam_a:根据cam_amo从cam_a中取出缓存的第一个运算数;PriorityMux低序号优先;
e. a_cam_d:根据cam_amo从cam_d中取出缓存的第二个运算数;
f. a_a:取出第一个运算数;
g. a_d:取出第二个运算数;
11) cam_a的entry是否已被占用

a. a_fifoId:计算Atomic请求的地址a_address所属的fifoId;
b. cam_a.map(_.fifoId === a_fifoId):检查每个entry中的请求所属的fifoId是否与当前请求的fifoId即a_fifoId相同;
c. a_cam_busy:如果有相同fifoId的请求存在,则无法处理当前请求,需要等待;
12) 找出第一个空闲的CAM entry,用于缓存Atomic请求:

13) 计算逻辑运算的结果:

参考Atomics中的介绍:

14) 计算数学运算的结果:
参考Atomics中的介绍:

一点区别是:这里把高的无效字节使用符号位进行扩展。
15) 原子计算的结果:

16) source_i:源自in.a的消息
结合当前节点的状态,决定是否接收上游节点的请求:

A. a_allow
是否允许上游节点发送请求:

需要满足两个条件:
a. 没有相同fifoId的Atomic请求存在,即a_cam_busy为假;
b. 下游节点可以处理这个请求或者存在空闲的CAM entry;
B. a_isSupported
这里单独提一下,即便没有空闲的CAM entry(a_cam_any_free为假),只要下游节点可以处理这个请求(a_isSupported为真),也是可以接收这个请求的。即当前AtomicAutomata节点不处理,透传给下游节点处理。
另外一个角度看,如果a_cam_busy为真,即CAM中有一个相同fifoId的Atomic请求存在,为了保证FIFO的顺序,即便a_isSupported为真,也不能透传给下游处理。
C. in.a.ready

a. in.a.ready:同时满足source_i.ready和a_allow才允许上游节点发送;
b. source_i.valid:上游节点有需要发送,并且允许发送;
D. !a_isSupported
如果需要我们代理这个Atomic请求,则把这个Atomic请求修改为发向下游节点的Get请求:

17) source_c:源自cam_a的消息

a. source_c.valid:取决于是否有cam要发起Put请求;
b. source_c.bits:使用a_cam_a生成一个Put请求(a_cam_a为第一个要发起Put的CAM entry)。需要注意的是amo_data是使用a_cam_a和a_cam_d计算产生的。
也就是说Atomic请求最多可以缓存camSize个,而运算单元(数学运算、逻辑运算)只有一个,所以这些请求要使用运输单元需要排队,低序号的优先级高。
18) 谁向out.a输出
需要使用仲裁器(低序优先):

这里是source_c优先,也就是先到先得(first come, first serve),否则可能会导致CAM中缓存的请求一直得不到响应。
因为AtomicAutomata节点只支持[1, m.beatBytes]大小的传输,所以只需要一个beat。而source_i则需要计算一下。
这里理一下流程:
A. 如果仲裁结果是source_i输出到out.a,那么发给下游节点的消息,分两种情况:
如果是下游节点可以处理的请求(a_isSupported为真),那么直接透传;
如果是下游节点不可以处理的请求(a_isSupported为假),那么发送的是被转换之后的Get请求:
B. 如果仲裁结果是source_c输出到out.a,那么发给下游节点的是Put请求,写入AMO的计算结果;
19) source_i输出
记录上游节点的Atomic请求消息到第一个空闲的CAM entry中:

这个entry的状态,从FREE转变为了GET,因为source_i.fire()即是把Get请求通过out.a发给了下游节点。
需要注意的是这里是a_isSupported为假的情况,即下游节点不可以处理这个Atomic请求的情况。如果下游节点可以处理这个请求,那么就不需要缓存到CAM entry中,而是直接透传了。
20) source_c输出
向下游节点发出了Put请求之后,状态就从AMO,转换为了ACK:

21) out.d
输出边的channel d即out.d,用于接收下游节点返回的AccessAckData和AccessAck消息。
22) d_first
是否响应消息的第一个beat。
23) d_cam_sel

a. d_cam_sel_raw:根据CAM entry中存放的Atomic请求的source字段,确定响应消息所属的CAM entry;
如何保证同样source的Atomic请求在CAM中只有一个?相同的source必然具有相同的fifoId,CAM中不存在两个相同fifoId的请求,所以也就不存在两个相同source的请求。
这里有一个隐含条件是正在处理的Atomic请求。
因为缓存在cam_a中并且处理完的Atomic请求,并不会擦掉_.bits.source这一个字段,而只是修改对应的状态为空闲。所以cam_a中可能存在两个以上source为in.d.bits.source的entry。需要使用状态再过滤一下。
为什么使用in.d.bits.source,而非out.d.bits.source?因为两者相同:

b. d_cam_sel_match:过滤掉空闲的CAM entry,只剩下一个唯一的非空闲的entry。
24) d_cam_data
使用d_cam_sel_match从cam_d中选出data/denied/corrupt:

25) 先忽略d_cam_sel_bypass

a. d_cam_sel = d_cam_sel_match;
b. d_cam_sel_any:是否有一个缓存的Atomic请求,匹配当前响应;
26) d_ack/d_ackd
判断channel d返回的响应的类型,以决定CAM entry下一步的状态:

a. d_ackd:返回的是AccessAckData消息,是针对Get请求的响应;
b. d_ack:返回的是AccessAck消息,是针对Put请求的响应;
27) out.d.fire()
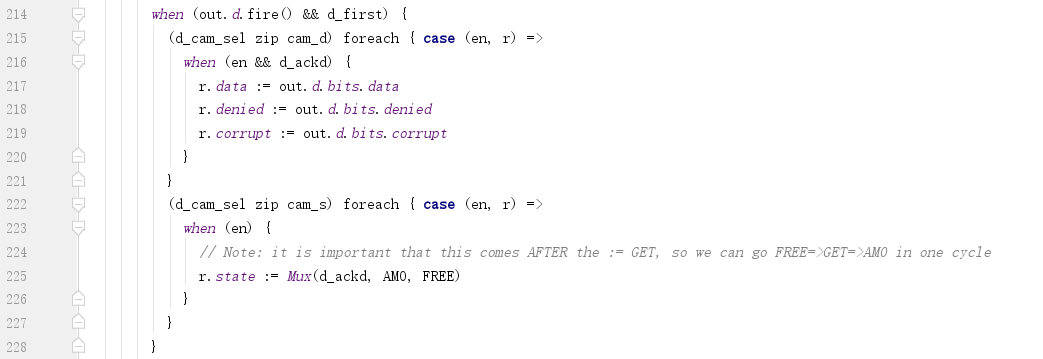
a. 使用d_cam_sel确定匹配的CAM entry;
b. d_ackd为真时,才需要缓存返回的数据到cam_d中:

c. d_ackd为真时,状态转为AMO,下一步进行原子运算;为假时状态转为FREE,已经与下游节点完成了最后的Put流程。
28) d_drop
out.d返回的AccessAckData响应消息会被丢弃:

不向in.d传递:

29) d_replace

out.d返回的AccessAck响应消息会被替换,并发送给in.d:

发送的数据为d_cam_data,即读取的原值。
30) d_first
功能所限,AtomicAutomata节点只处理响应的第一个beat。
a. 只缓存返回的AccessAckData消息的第一个beat中的数据:

b. 只drop返回的AccessAckData消息的第一个beat中的数据:
c. 只替换返回的AccessAck消息的第一个beat(实际上AccessAck也只有一个beat):

31) d_cam_sel_bypass
标志着manager是否可以在同一个时钟周期内,返回Get请求的响应数据:

A. 定义

a. 如果manager的最小延迟大于或等于1个时钟周期,则manager无法在同一个时钟周期内返回数据,即d_cam_sel_bypass = Bool(false);
b. !a_isSupported:即Atomic请求不是透传给下游节点(manager)处理的;
c. out.d.bits.source === in.a.bits.source: out.d返回的响应与in.a发送的Atomic请求相匹配;
d. in.a.valid:in.a的发送还没有结束;
B. d_cam_sel
因为cam_s是寄存器,寄存器的值无法在同一个时钟周期内变两次,所以需要从a_cam_sel_free和d_cam_sel_match两组值中选择。
原本是FREE状态的CAM entry,需要在下一个时钟周期才能变为Get发送之后的GET状态,进而驱动d_cam_sel_match产生变化。所以如果d_cam_sel_bypass为真,直接从a_cam_sel_free中取对应的CAM entry。第一个为1的比特对应的CAM entry就是刚刚选择用来缓存in.a的entry,也是out.d返回的AccessAckData消息对应的CAM entry。
C. d_cam_sel_any
如果d_cam_sel_bypass为真,则必然与out.d返回消息相匹配的CAM entry:

32) 不处理channel b/c/e:
无论是否支持,简单连接即可:

6. 一般流程
简要介绍需要当前AtomicAutomata节点处理的Atomic请求的一般流程,这个流程通过状态机控制(cam_s)。
1) in.a发出Atomic请求
请求被改写为Get请求:

2) 请求缓存到cam_a

3) 发送Get请求到out.a
source_i.fire()时,Atomic请求更改成的Get请求,即发送到out.a:

4) out.a返回AccessAckData响应消息

5) 执行AMO运算
从cam_a和cam_d中选择第一个和第二个运算数,进行运算:

6) 把运算结果通过Put请求通过out.a发送

更新状态机:

7) out.a返回AccessAck响应消息
把AccessAck消息转换为AccessAckData消息,发送给in.a:

更新状态机:

7. 透传流程
简要介绍当前AtomicAutomata节点透传到下游节点处理的Atomic请求的处理流程。
透传具体到代码中的标志为:a_isSupported为真。
1) 单beat
A. 透传Atomic请求
a. 即便没有空闲的CAM entry,也可以向out.a输出:

b. 不会被缓存到CAM中:
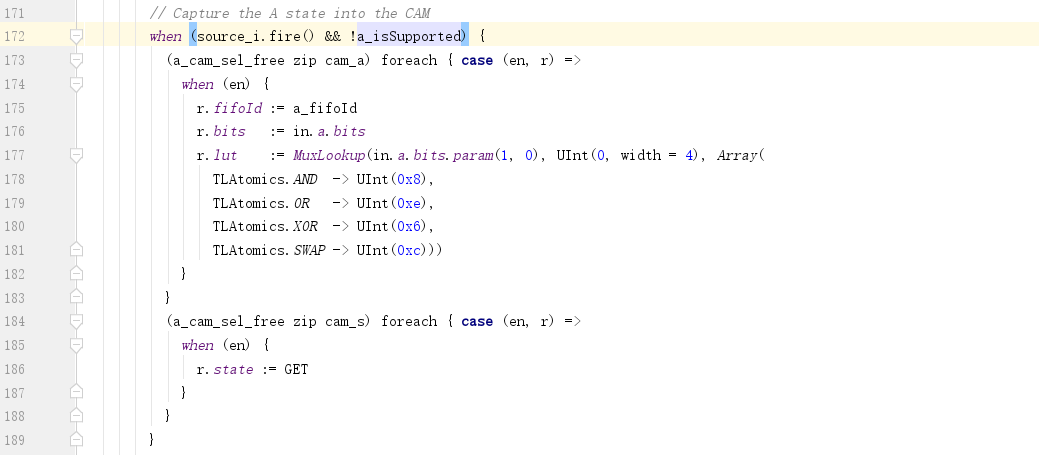
c. 不会被更改为Get请求:

结果就是:
a. 直接通过source_i发送到out.a;
b. 这个请求会阻塞in.a,直到被仲裁器选中,发送给out.a;
c. 仲裁器选中时,cam_a中缓存的Atomic请求已经全部都处理完了,也就是说cam_a和cam_d中的所有CAM entry都是空闲的;
B. 透传Atomic响应
a. cam_dmatch为全0(所有entry都FREE),进而d_cam_sel_match为全0:

b. d_cam_sel_bypass为假:

c. d_cam_sel为全0,d_cam_sel_any为假:

d. cam_d不缓存数据,不更改状态:

e. d_drop为假:

out.d可以发送到in.d:

- in.d.valid取决于out.d.valid;
- out.d.ready取决于in.d.ready;
- in.d.bits连接到out.d.bits;
相当于直连。
f. d_replace为假:

不会更改out.d返回的响应消息:

2) 多beat:burst
Diplomatic节点中对managerFn的适配,决定了如果下游节点无法处理大于beatBytes的Atomic请求,那么传递给上游节点的参数supportsArithmetic最大是ourSupport。也就是说上游节点最大只能发起beatBytes大小的Atomic请求,不存在burst请求的情况。
也就是说,burst请求只存在于透传给下游节点处理的情况。即:a_isSupported为真。
具体分析与单beat一致,相当于in.a与out.a直连,in.d与out.d直连。