片上总线协议学习(1)——SiFive的TileLink与ARM系列总线的概述与对比
link
片上总线协议学习(1)——SiFive的TileLink与ARM系列总线的概述与对比

一、背景介绍
随着超大规模集成电路的迅速发展,半导体工业进入深亚微米时代,器件特征尺寸越来越小,芯片规模越来越大,可以在单芯片上集成上百万到数亿只晶体管。如此密集的集成度使我们现在能够在一小块芯片上把以前由CPU和外设等数块芯片实现的功能集成起来,由单片集成电路构成功能强大的、完整的系统,这就是我们通常所说的片上系统。
IP复用是片上系统时代的核心技术之一。由于IP核的设计千差万别,不同的IP核间想要进行连接,就要遵守相同的接口标准。在片上系统中,处理器核和所有外设通过共享总线互通互联,因此这些IP核必须遵守相同的总线规范。总线规范定义的是IP核之间的通用接口,因此它定义了一套标准的信号类型与传输策略,以连接不同的模块,而不是试图去规范IP核的功能和接口如何实现。一个片上总线规范一般需要定义各个模块之间初始化、仲裁、请求传输、响应、发送接收等过程中驱动、时序、策略等关系。
随着多核系统的诞生与发展,总线协议也与时俱进:当面对单核情况时,一致性问题仅包括CPU缓存与内存间的读写一致性,以及一些IO设备映射地址uncachable,CPU与DMA设备间的交互等,这时总线需要提供的机制并不复杂;当延伸到多核或众核处理器应用场景,甚至异构并行架构下的一致性解决方案时,总线能否完备地支持缓存一致性协议也会成为重要考量点。
典型的片上总线标准包括ARM公司提出的AMBA总线标准,IBM提出的CoreConnect总线,Silicore推出的Wishbone总线以及Sifive公司推出的TileLink总线。目前业界使用最为广泛的是AMBA标准下的总线系列。下面将对AMBA系列总线和TileLink总线进行详细介绍。
二、TileLink整体概览
TileLink是近几年由伯克利孕育的芯片初创公司SiFive提出的一种全新的芯片级总线互连标准,允许多个主设备(masters)以支持一致性的存储器映射(memory-mapped)方式访问存储器和其他从端(slave)。TileLink的设计目标,是为SoC提供一个具有低延迟和高吞吐率传输的高速、可扩展的片上互连方式,来连接通用多处理器、协处理器、加速器、DMA以及各类简单或复杂的设备。
TileLink是一个协议框架,设计为多个缓存一致性策略的基板。其目的是将通信网络的设计和缓存控制器的实现与一致性协议本身的设计分离开来。这种关注点分离改进了内存层次结构的HDL描述的模块化,同时也使各个内存系统组件更加易于验证。
总体上来说,TileLink可以定义为:
- 免费开放的紧耦合、低延迟的 SoC 总线
- 为 RISC-V 设计,也支持其他 ISAs
- 提供物理寻址(physically addressed)、共享主存(shared-memory)的系统
- 可用于建立可扩展的、层次化结构的和点对点的网络
- 为任意数量的缓存或非缓存主设备提供一致性的访问
- 支持从单一简单外设到高吞吐量的复杂多外设的所有通讯需求
TileLink还具备以下特性:
- Cache一致性的内存共享系统,支持在该总线协议上实现MOESI等常见的一致性协议
- 对任何遵守该协议的SoC系统来说,可验证确保无死锁
- 使用乱序的并发操作以提高吞吐率
- 使用完全解耦的通讯接口,有利于插入寄存器来优化时序
- 总线宽度的透明自适应
- 突发传输序列的自动分割
- 针对功耗优化的信号译码
协议扩展
TileLink 支持多种类型的通讯代理模块,并定义了三个从简单到复杂的的协议扩展级别。每个级别定义了兼容该级别的通讯代理模块需要支持的协议扩展子集,如下表所示。最简单的是 TileLink 无缓存轻量级(Uncached Lightweight, TL-UL),只支持简单的单个字读写(Get/Put)的存储器操作。相对复杂的 TileLink无缓存重量级(Uncached Heavyweight,TL-UH),添加了预处理(hints)、原子访问和突发访问支持,但不支持一致性的缓存访问。最后,缓存支持级 TileLink Cached(TL-C)是最复杂,也是最完整的协议,支持使用一致性的缓存模块。
| TL-UL | TL-UH | TL-C | |
|---|---|---|---|
| 读/写访问 | √ | √ | √ |
| 多包突发传输 | √ | √ | |
| 原子访问 | √ | √ | |
| 预处理访问 | √ | √ | |
| 使用BCE通道 | √ | ||
| 缓存块传输 | √ |
当一个处理器的TL-C通讯代理模块和一个外设的TL-UL通讯代理模块通信时,要么处理器代理避免使用更高级的特性,要么两者之间必须使用一个 TL-C 到 TL-UL 的适配器。TileLink中的各种代理可以支持一些其他特性的组合,但在TileLink的spec中只包括上述三种扩展级别。
TL基础架构
Tilelink 协议适用于在代理(agent)互联拓扑图中,完成消息(message)的传递。共享地址空间的代理经由点对点的通道(channel)收发消息,来完成操作(operation),该通道被称为链路(link)。
- 操作(operation):在特定地址范围内,改动存储数据的内容、权限或是其在多级缓存中的存储位置
- 代理(agent):在协议中,为完成操作负责接收、发送消息的有效参与者
- 通道(channel):一个用于在主(master)接口和从(slave)接口之间传递相同优先级消息的单向通信连接
- 消息(message):经由通道传输的控制和数据信息
- 链路(link):两个代理之间完成操作所需的通道组合
网络拓扑
TL网络的代理间通过链路(link)互相连接。每条链路的一端连接一个代理的主接口,另一端则连接另一个代理的从接口。主接口一端的代理可以向另一端代理发送请求让其执行访存操作,或者请求获取权限以传输并缓存数据副本。从接口端的代理是对应地址空间的访问和权限管理者,依据主接口发来的请求执行相应的访存操作。
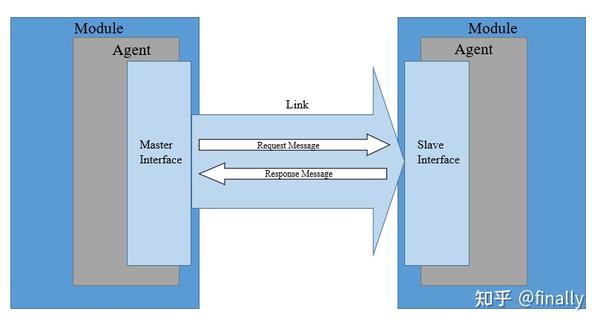
最基本的 TileLink 网络操作如下图所示。两个模块(Module)通过链路相连。左侧模块内的代理包含一个主接口,右侧模块内的代理包含一个从接口。带有主接口的代理向带有从接口的代理发起请求。如果需要,从接口端的代理可能和更底层的存储器进行通信。在获取到请求的数据或权限之后,从接口端的代理则通过消息响应原始请求。
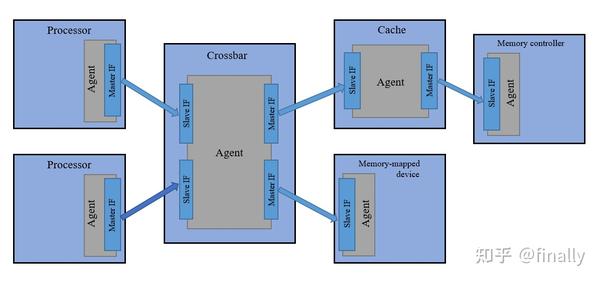
此外, TileLink 还支持多种网络拓扑。具体来说,如果将代理抽象为图论中的节点,而将链路抽象为从主接口指向从接口的有向边,那么任何有能被描述为有向无环图(DAG)的拓扑结构都可以被支持。下图展示了一个典型的拓扑结构。该拓扑中的交换器 (Crossbar)和缓存 (Cache) 模块都包含一个兼有主接口 (右端) 和从接口 (左端) 的代理节点。
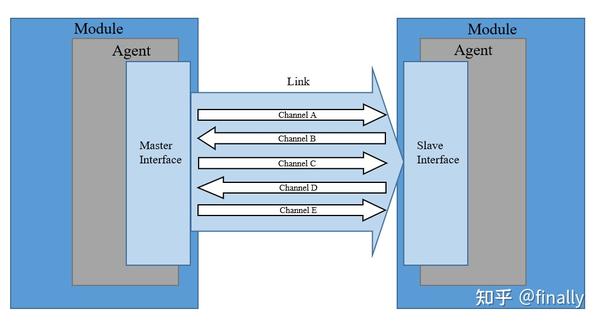
优先级通道
每个网络链路中,TileLink 协议定义了五个逻辑上相互独立的通道,代理可通过它们传递消息。为了避免死锁,TileLink 强制规定了这五个通道上传输消息的优先级。
大部分通道包含控制传输的信号以及实际数据的副本。通道上消息的传递是单向的,主向从接口传送消息,或从向主接口传送消息。下图标明了五个通道的方向。
任何访存操作都需要两个最基本的通道:
- 通道 A: 传送一个请求,访问指定的地址范围或对数据进行缓存操作
- 通道 D: 向最初的请求者传送一个数据回复响应或是应答消息
最高协议兼容层 TL-C 额外包含另外三个通道,具备管理数据缓存块权限的能力:
- 通道 B: 传输一个请求,对主代理已缓存的某个地址上的数据进行访问或是写回操作
- 通道 C: 响应通道 B 的请求,传送一个数据或是应答消息
- 通道 E: 传输来自最初请求者的缓存块传输的最终应答,用于序列化
各个通道传递消息的优先级顺序是 A << B << C << D << E 。设置优先级保证了消息在TileLink 网络的传输过程中不会进入路由环路或是资源死锁。换句话说,代理间消息在所有通道上的传输过程仍然保持为有向无环图。这对 TileLink 保证无死锁来说是一个必要的特性。
TileLink Cached(TL-C)
TL-C是通过给主代理(master agent)提供缓存共享数据块副本的方式构建起来的,依据具体实现过程中定义的一致性协议,这些本地副本可以保证一致性。换句话说,TL-C提供了一个基础的代理传输网络,指令与数据在网络中按照一套固定的规范进行传输,至于具体的一致性实现,需要设计者在理解了传输网络工作原理的基础上,利用TL-C提供的可用基本操作,消息和权限自行搭建。
TL-C一致性树
所有基于Tilelink的一致性协议都由一系列操作组成,通过这些操作,可以完成读写数据块权限的转变。在代理响应访存指令后,对已缓存的副本执行操作之前,必须在网络中使用转换操作获得正确的权限。转换操作在网络上创建或删除副本,从而修改每个副本可以提供的权限。
代理中数据块副本的基本权限可以包括:None、Read或Read+Write。缓存架构中副本可用的权限取决于缓存层次结构中副本的当前存在情况,如下所述:
对于任何给定的地址,在给定主端和拥有该地址范围的从端之间都只会存在一个具体的路径。在TileLink DAG网络中,所有这些路径都覆盖会形成一个树,根节点上仅有一个从端节点。对于每个地址,此树包含所有针对该地址的操作执行的路径。如果我们省略了所有不能缓存数据的代理,那么就会留下一个描述所有可能缓存该地址数据的缓存代理位置的树。
在逻辑时间的任意时刻,这些代理的某些子集真正包含缓存数据的副本。这些代理形成了一致性树。TileLink一致性协议要求树在响应内存访问操作时进行提权(Grow)和降权(Shrink)操作。图中的每个节点都属于树中的位置,分为以下四类:
- Nothing: 当前没有缓存数据副本的节点,没有读写权限
- Trunk: 主干,在尖端(Tip)和根(Root)之间的路径上拥有缓存副本的节点。具有其副本的读权限,该副本可能包含脏数据
- (Trunk)Tip: 顶点,具有缓存副本的节点,且可以用作内存访问序列化。对其拥有的可能包含脏数据的副本具有读写权限
- Branch: 分支,该节点由Trunk结点分出,具有只读数据缓存副本
下图列举了几个覆盖在单一TL网络上的一致性树(TT:Trunk Tip;T:Trunk;B:Branch)
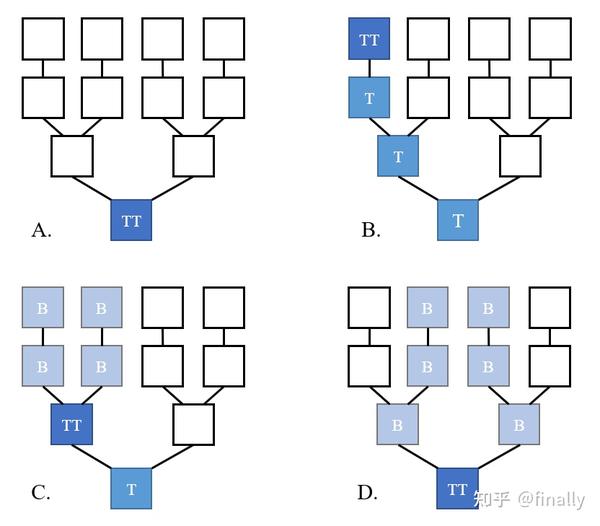
- A:初始状态,树的根节点有唯一的副本,这使得它既是树的根节点,也是树的顶端节点,只有根节点拥有副本的读写权限
- B:左上的主端代理需要获取副本,于是向网络提出申请,此时该地址空间并无其余代理发出请求或拥有副本,于是网络逐级提权,延伸主干,直到左上的主端获得写+读权限
- C:在B的基础上,另一个主端申请获得读权限,于是网络扩展一个分支,为请求的代理赋予副本与只读权限,同时将原分支上的代理进行降权,这意味着之前的顶点现在也是一个只读分支,公共的父节点是主干节点
- D:在C的基础上,其他主端也申请获取权限,于是网络创建新的分支,进行适当的降权升权操作,进一步将尖端向根部移动,需要注意的是,最初的请求主端已经主动修剪了它的分支
从图中可以做出如下几点分析,以帮助我们更好地理解这棵树的一致性维护方法:
- 分支一般存在其他兄弟分支,所以其中的节点不能被写,不然无法做到cache一致性
- 针对Trunk尖端(Tip)的写操作会穿透之前的所有Trunk节点,所以可以做到自然同步。如果针对TT之前的T节点进行写操作,则会需要额外的同步动作,所以T节点设计为只读
- 因为针对B节点的读必然经过TT节点(Cache命中,直接返回),所以无需把TT中的脏数据向B中同步
下表描述哪种状态下的节点上可以执行哪些访问操作,其定义与其在树中的位置相关。另外,协议可以基于这些基本状态定义具体的一致性状态
| Permissions | Supported Accesses |
|---|---|
| None | None |
| Branch | Get |
| Trunk | None |
| Tip(with Branches) | Get |
| Tip(no Branches) | Get, PutPartial, PutFull, Logical, Arithmetic |
TileLink总线规范中定义了更多具体细节,将在后续篇幅中展开论述。
三、ARM系列总线概述
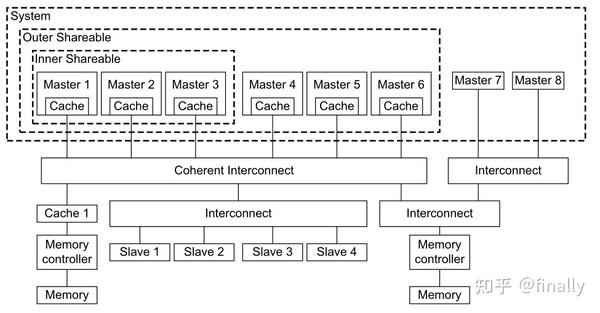
ARM公司的所有关键总线协议均基于AMBA(The Standard for On-Chip Communication)规范。AMBA,全称为Advanced Microcontroller Bus Architecture,是一个标准开放的,针对SoC设 计中片上互连的总线标准。AMBA总线的推出有助于开发具有大量控制器和具有总线结构的外围设备的多处理器设计。AMBA总线自从1996年由ARM提出之后,经过数十年的发展已经广泛运用于ASIC以及SoC设计之中,例如现今智能手机的SoC之中。到目前为止,AMBA总线已经发展至第五代,并在继续发展演进之中。
AMBA规范具有如下所示的特点:
- 灵活性(Flexibility):IP 重用需要一个通用标准,该标准支持具有不同功率、性能和面积要求的各种 SoC。AMBA 可以灵活地满足这些要求,提供设计选择并将性能和可扩展性扩展到兼容处理器
- 广泛使用(Widespread Adoption):AMBA 规范具有可靠性和信任的悠久传统。AMBA 在全球范围内广泛用于基于标准的 IP。它是 IP 产品片上连接最广泛采用的行业标准,包括内存控制器、互连、跟踪解决方案、加速器、GPU 和 CPU
- 兼容性(Compatibility):AMBA 规范确保来自不同设计团队或供应商的 IP 组件之间的兼容性和可扩展性。兼容的解决方案可实现设计重用、更低的拥有成本和更快的上市时间
- 全面支持(Comprehensive Support):AMBA 规范在整个半导体行业的广泛采用推动了第三方 IP 产品和工具的全面市场,以支持基于 AMBA 的系统的开发
下图是一张AMBA系列总线的概览图:
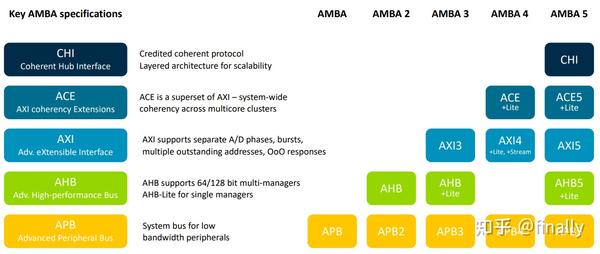
从图中可以看出,AMBA几乎每一代都会对原有的总线协议进行改进,同时推出具有全新针对性扩展(ACE)或者全新组织方式(CHI)的新一代总线协议。本文挑选AXI、ACE和CHI三种总线协议进行简要介绍。
AXI
随着集成电路技术的发展,人们对SoC的性能要求越来越高,导致片上总线的带宽需求和时延需求也不断增加。AHB总线虽然可以使用户不断增加总线位宽来达到性能的要求,但是在如今对高能效比的极致要求下,使用极小的总线数据位宽和极低的总线时钟频率来实现数据的高吞吐量已经成为现今的发展趋势。为了顺应这种趋势,ARM公司于2003年推出了第三代AMBA总线协议簇,第一次引入了AXI(Advanced Extensible Interface)协议来满足更高数据带宽的应用需求。到现今,AXI协议已经发展到了第五代。AXI协议具有以下特征:
- 用于高带宽和低延迟设计。
- 提供高频操作,无需使用复杂电桥。
- 协议满足各种组件的接口要求。
- 适用于具有高初始访问延迟的内存控制器。
- 提供了实现互连架构的灵活性。
- 与AHB和APB接口向后兼容
AXI有五个独立的事务通道,分别是:
- 读地址(Read Address,简称AR)
- 读数据(Read Data,简称R)
- 写地址(Write Address,简称AW)
- 写数据(Write Data,简称W)
- 写响应(Write response,简称B)
AXI的五个通道是单向的,且读写地址和读写数据通道各自独立,这样做的好处是便于单独优化某个通道,而且当经过复杂的片上网络时,能够优化时序减少延迟。
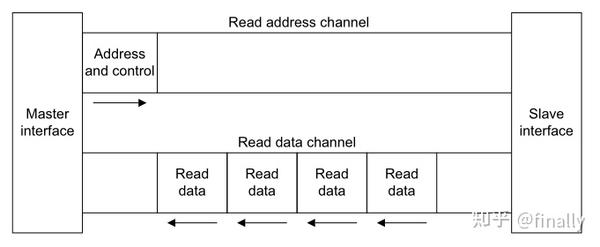
对于读操作,主端(master)通过AR通道发送读事务地址,从端(slave)通过R通道返回给主端所需要的数据,如下图:
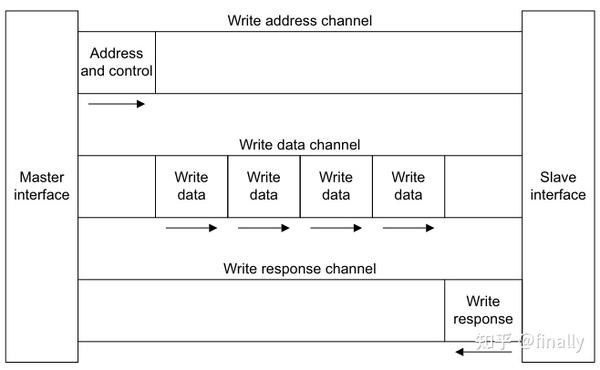
对于写操作,主端通过AW通道发送写事务地址,并通过W通道把数据发送给从端,而从端接收到数据后,需要通过B通道返回一个响应给主端,全过程如下:
AXI内另一个较为重要的就是发送方/接收方的Valid/Ready握手机制,此处简单介绍一下:
AXI协议内,为了避免死锁,发送方(发送地址/数据的一方,与主端从端概念有区别)在传输时天然受限,发送方的Valid信号必须等待逻辑靠前的信号全部完成后才能置高,且置高后不能主动置低;接收方天然自由,接收方的ready信号置高时机无限制,置高后就算没有握手成功就可主动置低,拥有较高的自由度。这一点同样体现在逻辑设计方面:发送方的逻辑不能写成等对方ready了才能valid,但是接收方的逻辑可以写成等对方valid了我再ready。
AXI支持突发(burst)传输,乱序(out-of-order)传输,大幅提高了数据吞吐能力,在满足高性能要求的同时,也减少了功耗。AXI的突发传输支持FIXED/INCR/WRAP类型,AXI4的INCR支持1-256突发传输,另两种类型支持1-16的突发传输。除此之外,AXI提供窄传输(Narrow transfers)、非对齐传输(unaligned transfer)和混合大小端(mixed-endian)传输等特殊传输类型的解决方案。
总而言之,AXI是一个功能齐全,性能强大的成熟片内总线协议,目前在超高性能和复杂SoC设计方面具有广泛的应用。
ACE
ACE是AXI Coherency Extensions的缩写,顾名思义,ACE就是AXI加上支持一致性的扩展。上一小节介绍的AXI总线协议纵然功能全面且强大,但是却完全不支持缓存一致性的维护,于是ACE诞生了,它在AXI协议的基础上增添了硬件层面的系统级一致性维护,允许系统组件直接共享内存,而不需要软件执行软件缓存维护以维持缓存一致性。
ACE协议通过如下方式进行拓展:
- 五状态缓存模型:定义一致性系统中任意缓存行的状态,此状态决定了在访问该缓存行期间需要什么操作
- 原有AXI4通道内新信号拓展:允许将新的事务和信息传递到需要硬件一致性支持的位置
- 额外的通道拓展:当另一个主端正在访问一个可能被共享的地址位置时,启动与缓存主端的通信
此外,ACE还提供屏障(Barrier)事务以及分布式虚拟内存(DVM——Distributed Virtual Memory)的支持,此处篇幅受限,不再详细展开。
让我们将关注重点移回ACE协议的缓存模型上,ACE协议要求,如果cache中的一个缓存行是整个系统中的唯一拷贝,那么拥有这个缓存行的处理器单元可以修改数据,同时不必通知其它主端;如果这个缓存行数据在整个系统中存在其它拷贝(副本),则拥有这个缓存行的处理器在修改数据的同时,必须通知其它处理器知晓这个改动。所以,对于缓存行来说,记录其当前状态至关重要。为此,在ACE里面提出如下所示的缓存模型:
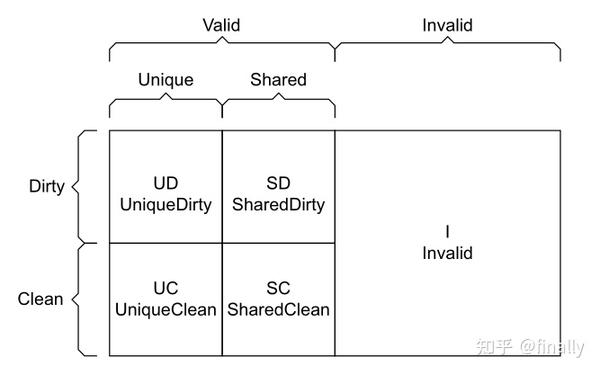
- Invalid:简称I,表示该缓存行无效
- UniqueClean:简称UC,表示缓存行是唯一的,并且数据未被本层缓存修改
- UniqueDirty:简称UD,表示缓存行是唯一的,但是数据被修改过,拥有该缓存行的主端必须保证修改后的数据要写回到主存
- SharedClean:简称SC,缓存行可能存在其它拷贝,但该缓存行数据没有被修改过
- SharedDirty:简称SD,缓存行可能存在其它拷贝,但该缓存行数据被修改过
ACE同时引入了共享域的概念,将处理器划分为多级域,每级域内需要共享一致性状态。对于inner域的所有处理器来说,一个处理器的操作会被这个域内其它处理器看到,但是不会影响别的inner域;对于outer域,可以由多个inner域组成,如果一个处理器的操作影响到outer域,那么这个操作会被outer域包含的所有inner域看到;system也比较简单了,就是整个系统。定义这么多域的作用,其实就是要确定某一个操作,需要广播到哪一个层次。
ACE增加了三个snoop通道(addr/resp/data)方便主端随时等待并响应一致性事务请求,协议采用集中控制的方式,每当主端发起读写事务时,Interconnect(ICN)会接收并包揽余下的任务(例如查询其它cache是否存在数据共享,如果存在则需要获取数据,如果不存在则需要去下级存储中查询等等),处理完毕后再将结果返回给发起事务的主端。协议拥有十余条复杂的cache事务,具体每种事务对于缓存行有何种影响则更加繁琐,读者若想了解详细的传输依赖,可以深入ACE spec探究。
CHI
CHI(Coherent Hub Interface)协议是AMBA的第五代协议,可以说是ACE协议的进化版,将所有的信息传输采用包packet的形式来完成,packet里分各个域段传递不同信息,本质还是用于解决多个CPU(RN)之间的数据一致性问题。基于CHI协议的系统架构可以包含独立CPU、处理器簇、图形处理器、memory控制器、I/O桥、PCIe子系统和CHI互联线,该架构主要有以下关键特性:
- 架构扩展方便;
- 独立的分层实现,包括协议层、网络层和链路层,各自具有不同的功能;
- 基于包传输;
- HN(Home Node)协调所有的传输请求,包括snoop请求、访问cache和memory;
- 支持64Byte的一致性粒度、Snoop Filter和Directory、MESI和MOESI cache模型、增加Partial和Empty cache状态;
- 支持Retry机制来管理协议层资源;
- 支持端到端的Qos(Quality of Service);
- 可配置的数据宽度来满足系统需求;
- 支持ARM TrustZone;
- 低功耗信号,可以使能flit级别门控、组件之间的建断链来支持时钟门控和电源门控、协议层的活动信号来控制电源和时钟;
与以往的总线协议不同,CHI开始提出了协议分层。CHI层次按功能可以划分为:协议层(Protocal)、网络层(Network)、链路层(Link),分别对应Transaction、Packet和Flit三级信号。其中Transaction代表一次单独的读写事务;Packet是互联端点(Nodes)间的传输粒度,每个packet包含有源和目的节点的ID来保证在ICN上独立路由;Flit是最小流控单位,一个packet可以由一个或多个flits组成,对于同一个packet的所有flits在互连上传输必须遵循同样的路径。
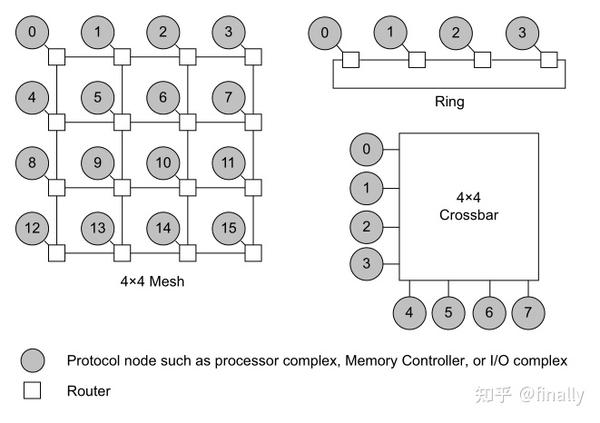
CHI协议并不规定拓扑互连,但是该规范中包含了某些与拓扑相关的优化,以使电路实现更有效。目前常用的SoC互连有三种方式:
- 交叉开关(crossbar),这种结构相对简单,互连部分延时小,多用于数量不多的组件互连,缺点是如果互连组件太多,这种结构的内部走线会非常多,不利于物理实现,比较常见的crossbar类型IP如ARM公司的NIC-400
- 环形网络(ring),折中考虑了互连组件数量和延时,有利于中等规模的SoC设计,比较常见的ring类型IP如ARM公司的CCN
- 二维网格(mesh),这种拓朴结构可以提供更大的带宽,而且是可以模块化,通过增加网格的行或列来增加更多的节点,ARM的CMN-600就是基于mesh的互连IP
CHI协议中,产生、传递和接收事务的基础单元为节点(与TileLink相似),CHI的节点分为四大类:HN(Home Node)用于接收来自RN的协议transaction,完成相应的一致性操作并返回一个响应。RN(Request Node)产生协议transaction给互连,包含读和写。SN(Slave Node)用于接收来自HN的请求,完成相应的操作并返回一个响应。MN(Misc/Miscellaneous Node)用于接收来自RN的DVM操作,完成相应的操作并返回一个响应。CHI协议的一个典型连接如下图:
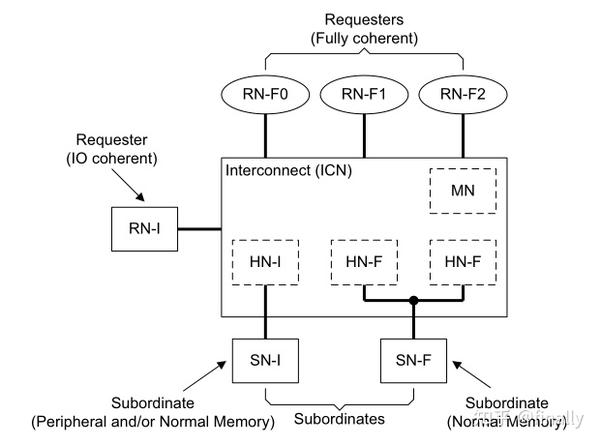
CHI协议规定,系统中的每一个节点有且只有一个唯一的节点号(Node ID),用于帮助packets记录流动时的路径信息。
另一个值得关注的重点是CHI的coherency model,下图所示为CHI包含三个master组件的典型一致性系统,每个master组件包含一份loacl cache和一致性协议节点。CHI协议允许memory数据存放在一处或多处master cache当中。
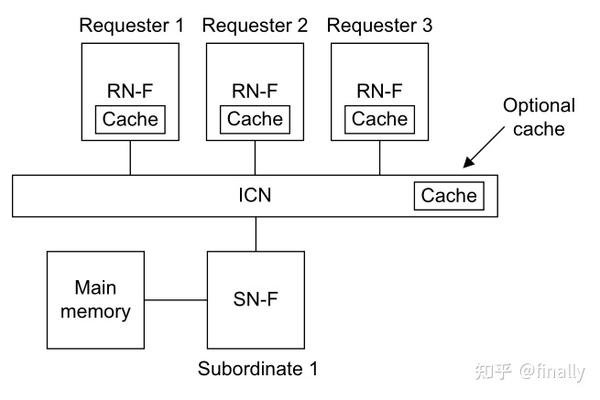
- 当需要存数据时,先把所有其它masters的数据备份失效掉,这样一致性协议可以使得所有的masters获取到任何地址的正确的数据值。在存储完成后,其它masters可以获取到新的数据到自己local cache
- CHI协议允许(不强求)主存的数据不是实时更新的,只有在所有master的cache都不需要该数据备份时,才把数据刷新到主存中
- 协议使得master可以确定一份cacheline是否是唯一的或者存在多份拷贝。如果是唯一的,master可以直接改变它的值不需要知会系统中其它masters,如果不是唯一的,master必须使用恰当的transaction知会其它masters
- 所有的一致性是以cacheline粒度对齐,cacheline在64bytes对齐存储系统中大小为64bytes
CHI协议定义的cache state相较于ACE新增了Full/Partial两种缓存行状态,代表cacheline中全部/部分bytes有效。CHI的7状态缓存模型如下:
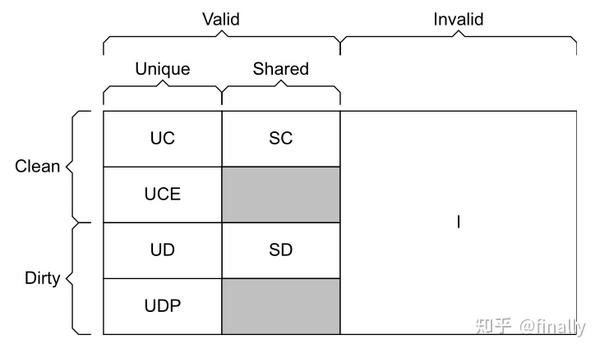
可以看出,相比于ACE,CHI多出了下面两个状态:
- Unique Clean Empty:简称UCE,表示该cacheline的数据只在当前cache中,但是所有的数据都是无效的
- Unique Dirty Partial:简称UDP,表示该cacheline的数据只在当前cache中,且和memory的数据不一致,部分被修改且有效
UCE态的获取:
- Requester故意产生UCE态:在Requester对cacheline写数据前,为了节省系统带宽,Requester获得UCE态而不是UC,就可以对该cacheline进行写操作
- Request切换到UCE态:如果Requester已经有该cacheline的拷贝,且正在申请获取写权限,但是在获得写权限之前该数据已经被失效掉了,这样会使得该cacheline变为UCE态
UDP态的获取:
- UDP态获得的前提是当前cacheline为UCE态,然后Request对齐进行partial写,这样就产生了UDP态
对于每种transaction对各节点数据大小和缓存状态的影响,可以参考CHI spec的第四章,这里就不一一列举了。
借助节点组成的拓扑网络,CHI协议将事务分割成packet,在网络中乱序传输。ICN在协议中依旧有着非常重要的作用,包括协调所有传输请求,内部节点HN处理所有事务等。CHI同时提供了超发请求处理、同一缓存行的事务排序、多核系统的操作保序等拓展功能。由于CHI的完整spec近几年才完全公开,业界对其的探索实践还并不成熟,但不可否认的是,CHI是一个充满活力和潜力的总线协议,在ACE协议的基础取得了较大的突破。
四、对比
TileLink与上述三种AMBA总线协议的特点比较如下所示:
| AXI4 | ACE | CHI | TileLink | |
|---|---|---|---|---|
| 开放标准 | 开放 | 开放 | 开放 | 开放 |
| spec复杂度 | 较为复杂(130余页) | 较为复杂(180余页) | 复杂(500余页) | 简单(100余页) |
| 缓存块一致性迁移 | 不支持 | 支持 | 支持 | 支持 |
| 多级缓存 | 不支持 | 不支持 | 支持 | 支持 |
| 片外可重用性 | 不支持 | 不支持 | 支持(通过CCIX拓展) | 支持 |
| 应用场景 | 无一致性要求 | 有一致性要求/中小型设备 | 有一致性要求/大型设备 | 仍处于偏实验阶段 |
TileLink最初是SiFive公司为Rocket Chip设计的总线架构,设计人员在考察了当时业界使用广泛的几种总线协议,例如Silicore公司提出的Wishbone总线,以及使用最为广泛的ARM的AMBA系列总线(AHB/AXI/ACE/CHI)之后,认为这些总线协议都不能完全满足他们的预想。在他们看来,一个优秀且完备的RISC-V总线协议必须具有上表所示的所有特性。
AHB显然不符合要求,它虽然是开源协议,但是并不易于实现,且在缓存一致性方面没有支持;Wishbone总线是开源的,虽然在片上高速模块互联方面表现较为突出,实现也较为简单,但是和AHB一样没有缓存一致性方面的支持;AXI也存在和Wishbone相同的问题;ACE是ARM基于AXI做的一致性拓展(Coherency Extensions)版本,虽然支持缓存一致性,但是该协议的实现较为复杂,且尚不支持多级缓存一致性维护,也无法在片外进行使用,不利于长期发展;CHI总线较为特殊,它是AMBA的第五代协议,是ACE协议的进化版,支持缓存一致性,首次提出了协议分层技术,数据改为包传输等等,总体表现相较与ACE有很大提升,但是当SiFive评估各总线可行性时,在获取CHI协议的spec时受到了阻碍,最终没能成功获取,这也间接使他们下定了要自己开发一款总线协议的决心。
总而言之,TileLink是一款仍处于实验研究阶段的、轻量级的总线协议框架。类似精简指令集架构的诞生,TileLink在设计时注重轻便性与易实现性,抛弃了原有总线协议(例如ACE)的冗杂架构与事务,将总事务类型缩减至十余条,且将协议分为了三级扩展,视功能需求自行配置。TL总线协议与CHI较为相似,两者的事务处理主体均为节点,CHI协议拥有ICN总揽事务处理,TL也有Crossbar作为多节点的通路交互,但是两者对于具体一致性状态的维护和冲突处理的设计却大相径庭。
CHI对于众多事务与节点、缓存块之间的交互定义依旧非常复杂,但是TileLink却在大幅缩减交互项目和事务条数的情况下,很好地实现了预期的功能,这一点也可以从两种总线的spec页数看出(TL spec仅有100余页,但是CHI spec却多达500余页)。但是反过来说,AMBA系列的总线已经得到业界的广泛认可,较为成熟,而TileLink目前仍处于实验阶段,其轻量级总线的定义与ACE类似,但是设计理念却更加偏向于CHI,是一款颇具潜力的总线协议。
参考文献
-[1]SiFive TileLink Specification
-[2]AMBA 5 CHI Architecture Specification
-[3]AMBA AXI and ACE Protocol Specification
片上总线协议学习(1)——SiFive的TileLink与ARM系列总线的概述与对比相关推荐
- AXI 总线协议学习笔记(4)
引言 前面两篇博文从简单介绍的角度说明了 AXI协议规范. AXI 总线协议学习笔记(2) AXI 总线协议学习笔记(3) 从本篇开始,详细翻译并学习AXI协议的官方发布规范. 文档中的时序图说明: ...
- AXI 总线协议学习笔记(3)
引言 上篇文章主要介绍了 AMBA以及AXI协议的基本内容,本文接续前文,继续介绍AXI协议的 原子访问.传输行为和事务顺序等. AXI 总线协议学习笔记(2)https://blog.csdn.ne ...
- AMBA总线协议(三)——一文看懂AHB总线所有协议总结(AHB2 AHB-Lite AHB5 )
AMBA AHB 总线协议介绍请点击以下链接: AMBA总线协议(一)--一文看懂APB总线协议 AMBA总线协议(二)一文看懂AMBA2 AHB2与AMBA3 AHB-Lite总线协议的区别 AMB ...
- AMBA总线协议(一)——一文看懂APB总线协议
0.AMBA总线概括 AMBA AHB 总线协议介绍请点击以下链接: AMBA总线协议(二)一文看懂AMBA2 AHB2与AMBA3 AHB-Lite总线协议的区别 AMBA总线协议(三)--一文看懂 ...
- pci总线协议学习笔记——PCI总线基本概念
1.pci总线概述 (1)PCI,外设组件互连标准(Peripheral Component Interconnection),是一种由英特尔(Intel)公司1991年推出的用于定义局部总线的标准; ...
- 数字IC设计入门篇:APB总线协议学习心得
声明:本文章是本人学习AMBA APB协议的一些个人理解,仅用于学习交流之用.本人学习APB协议时参考的是ARM公司官方的APB协议技术规范文档(编号:IHI0024D).受限于本人的知识水平,本文 ...
- TM1637芯片使用(I2C总线协议学习),含完整程序
目录 1.TM1637芯片(大自然的搬运工) 芯片介绍 引脚图 时序图 其他关键 管脚功能 命令格式 封装 2. 51单片机程序编写 I2C_START(): I2C_WR(): I2C_ACK(): ...
- AXI 总线协议学习笔记(2)
引言 从本文开始,正式系统性学学习AXI总线. 如何获取官方协议标准? 第一步:登陆官网:armDeveloper 第二步:登录,无账号需要注册 第三步:点击文档 第四步: 第五步:浏览页面建议下载下 ...
- 总线全称_一篇文章讲透I2C总线协议
最近一段时间工作上比较忙,一直没有抽出空来写文章与大家分享,这两天腾出些时间静下心来沉淀一番.看标题大家已经知道了是来总结I2C总线,我相信大家或多或少的都接触过I2C总线,这篇文章我们就由浅入深的仔 ...
最新文章
- 如何使用gensim来加载和使用词向量模型word2vec
- cloudstack 4.0 XenServer 日常简单故障处理
- CentOS 6.7 Gitolite 服务搭建及TortoiseGit配置连接
- python中frame用法_python操作dataFrame基本知识点
- vue如何取消下拉框按回车自动下拉_按逗号拆分Excel单元格,再分离中文数字,春节压岁钱统计就用它...
- hdu 1863(最小生成树kruskal)
- angular 渐进_如何创建具有Angular和无头CMS的渐进式Web应用程序
- SpringBoot 如何进行对象复制,老鸟们都这么玩的!
- TensorFlow 教程 --教程--2.3MNIST机器学习入门
- websocket握手失败_WebSocket握手期间出错:意外的响应代码:500
- 有什么软件可用于Mac系统的硬盘格式转换
- onmouseover|onmouseout和onmouseenter|onmouseleave的区别
- Servlet的九大内置对象
- SSD1306 OLED驱动芯片 详细介绍(使用I2C)
- 如何使用可提高员工敬业度的绩效管理软件
- 时钟芯片S35390A
- 四旋翼无人机PID调节(无数次实验总结经验和理论支持)
- A - Chloe and the sequence
- c语言flappy bird,c语言版本flappy bird
- CSV文件格式——方便好用个头最小的数据传递方式
热门文章
- Map和Set,简单模拟实现哈希表以及哈希表部分底层源码的分析
- html页面小宠物代码大全,纯css3实现宠物小鸡实例代码
- 小程序源码:全新动态视频壁纸下载支持多种分类短视频另外也有静态壁纸
- 北大新任校长王恩哥的10句话
- django自动生成问卷表的软件的设计与实现毕业设计源码291138
- 【Python】pass,continue和break的区别
- 服务器系统如何截图,电脑截图的快捷键是什么,小编告诉你电脑怎么截图
- STLINK下载程序出现cannot access target. shutting down debug session问题解决的一般步骤
- CVE-2017-8570微软office漏洞复现与研究
- c51单片机时钟c语言程序设计,51单片机C编程(六、定时器时钟显示时分秒)