在多节点集群中运行Cassandra
- 设置第一个节点
- 添加其他节点
- 监视集群– nodetool , jConsole , Cassandra GUI
我在Ubuntu OS中使用了Cassandra 1.1.0和Cassandra GUI – cassandra-gui-0.8.0-beta1版本(由于较旧的版本在显示数据方面存在问题)。
设置第一个节点
打开位于'apache-cassandra-1.1.0 / conf'中的cassandra.yaml。 更改listen_address:本地主机–> listen_address:<节点IP地址> rpc_address:本地主机–> rpc_address:<节点IP地址> –种子:'127.0.0.1'–> –种子:'节点IP地址'
侦听地址定义集群中其他节点应连接的位置。 因此,在多节点群集中,应将其更改为与以太网接口相同的地址。 rpc地址定义节点在哪里侦听客户端。 因此,如果我们想在所有可用接口上监听Thrift客户端,则它可以与节点IP地址相同或将其设置为通配符0.0.0.0。 种子充当交流点。
当新节点加入群集时,它将联系种子并获取有关其他节点的环和基本信息。 因此,在多节点中,需要如上所述将其更改为可路由地址,从而使该节点成为种子。
注意:在多节点群集中,最好有多个种子。 尽管使用一个节点作为种子并不意味着有单点故障,但会延迟在环网上传播状态消息。 可以定义充当种子的节点列表,如下所示: –种子:“ <ip1>,<ip2>,<ip3>”
目前,让我们继续使用单种子的先前配置。 现在我们可以简单地在该节点上启动Cassandra,它将在没有其余节点的情况下完美运行。 假设我们的集群需要提高性能,并且更多数据正在馈送到系统中。 现在是时候向集群添加另一个节点了。
添加其他节点
只需将第一个节点的Apache Cassandra文件夹复制到每个文件夹中。 现在,替换与每个节点相关的listen_address:<节点IP地址>和rpc_address:<节点IP地址>。 (无需触摸种子部分)现在,当我们启动每个节点时,它将使用种子作为八卦网络的集线器加入环。 在日志中,它将显示与集群中其他节点有关的信息。

监控集群
Nodetool –它随Apache Cassandra一起提供。 我们可以使用bin / nodetool在Cassandra文件夹中运行它。 使用nodetool的ring命令,我们可以按以下方式检查环的一些信息。 bin / nodetool -host <节点IP地址>环

它具有更多有用的功能,可以在现场参考。 jConsole –我们可以使用它来监视内存使用情况,线程行为等。详细分析集群并微调性能非常有帮助。 如果您还不熟悉jConsole,本指南还将提供有关使用jConsole的良好信息。
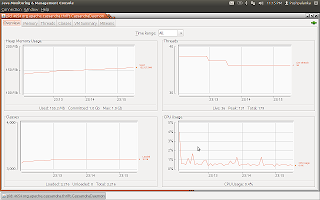
Cassandra GUI –这是为了满足可视化集群内部数据的需要。 这样,我们可以在一处看到整个集群中分布的内容。
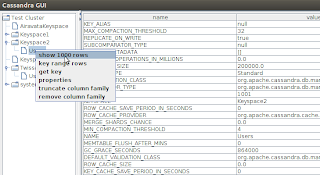
参考: Pushpalanka博客博客中的JCG合作伙伴 Pushpalanka在多节点集群中运行Cassandra 。
翻译自: https://www.javacodegeeks.com/2012/07/running-cassandra-in-multi-node-cluster.html
在多节点集群中运行Cassandra相关推荐
- 集群中运行Tachyon(译)
为什么80%的码农都做不了架构师?>>> 集群中运行Tachyon 单机集群 首先下载 Tachyon tar 文件,并且解压: $ wget https://github.c ...
- 从零到一编写一个 spark 程序并提交到集群中运行
怎样用IDEA编写spark程序并提交到集群上运行 1.安装scala sdk 1.下载 scala 安装程序 #下载地址 https://www.scala-lang.org/download #w ...
- 在kubernetes集群中运行nginx
在完成前面kubernetes数据持久化的学习之后,本节我们开始尝试在k8s集群中部署nginx应用,对于nginx来说,需要持久化的数据主要有两块: 1.nginx配置文件和日志文件 2.网页文件 ...
- Hadoop集群中运行MapReduce程序错误记录
Exception in thread "main" java.lang.SecurityException: Invalid signature file digest for ...
- python集群到hadoop_如何使用Hadoop流在本地Hadoop集群中运行MRJob?
我正在学习一个大数据类,我的一个项目是在本地建立的Hadoop集群上运行Mapper/Reducer.在 我一直在为类使用Python和MRJob库.在 下面是我当前用于Mapper/Reducer的 ...
- docker swarm英文文档学习-8-在集群中部署服务
Deploy services to a swarm在集群中部署服务 集群服务使用声明式模型,这意味着你需要定义服务的所需状态,并依赖Docker来维护该状态.该状态包括以下信息(但不限于): 应该运 ...
- Spark在不同集群中的运行架构
Spark注重建立良好的生态系统,它不仅支持多种外部文件存储系统,提供了多种多样的集群运行模式.部署在单台机器上时,既可以用本地(Local)模式运行,也可以使用伪分布式模式来运行:当以分布式集群部署 ...
- pythonspark集群模式运行_有关python numpy pandas scipy 等 能在YARN集群上 运行PySpark
有关这个问题,似乎这个在某些时候,用python写好,且spark没有响应的算法支持, 能否能在YARN集群上 运行PySpark方式, 将python分析程序提交上去? Spark Applicat ...
- 在Apache Hadoop(多节点群集)中运行Map-Reduce作业
我们将在这里描述在多节点集群中的Apache Hadoop中运行MapReduce Job的过程. 要在多节点群集中设置Apache Hadoop ,可以阅读设置Apache Hadoop多节点群集 ...
最新文章
- Elasticsearch搜索类型讲解(QUERY_THEN_FETCH,QUERY_AND_FEATCH,DFS_QUERY_THEN_FEATCH和DFS_QUERY_AND_FEATCH)...
- 计算最长的字符串长度
- Javascript 常用技巧 [2]
- SpringBoot配置logback-spring.xml日志
- 开源引擎推荐—ElGameEngine 作者:trcj(http://blog.csdn.net/trcj1)
- libaio.so.1: undefined reference to `__stack_chk_fail@GLIBC_2.4'
- python极客项目编程pdf微盘下载_Python极客项目编程
- Unity 3D | 在Unity3D中创建/执行C#脚本
- 360浏览器显示没网络连接服务器,360浏览器无法连接网络?怎么办?
- OpenWrt下Transmission下载
- 未来教育计算机二级office评分有问题,未来教育计算机二级-未来教育计算机二级msoffice题库评分 – 手机爱问...
- 【pwnable.kr】Toddler‘s Bottle-[collision]
- Failed to start component [Connector[HTTP/1.1-20001]]报错
- python 全栈开发,Day113(方法和函数的区别,yield,反射)
- Android之Scroller详解讲解-真正了解滚动处理
- 编写一个应用程序,给出“你”“我”“他”在Unicode表中的位置
- 华为 watch fit 鸿蒙,华为新款智能手表 Watch Fit 曝光,矩形表盘,支持近 100 种运动模式...
- linux 看不到新加硬盘,linux中 命令df -h查不到新添加的磁盘
- 计算机科学与技术导论ppt,计算机科学与技术专业导论.ppt
- HTML CSS笔记(没有基础内容,比如br标签是换行什么的),CSS2.1,CSS3,响应式布局