进阶爬虫:今日头条街拍美图
关键字: json 爬虫 MongoDB
GitHub:https://github.com/utopianist/JiePai
前言
今日我们在 今日头条 网站上爬取 街拍美图 。
今日头条 的数据都是用 Ajax 技术加载渲染完成,打开 今日头条 页面源码,连一根鸡毛都没有。
在我们爬虫界,按照 ‘可见即可爬’ 的原则, 所谓的 Ajax 就是 ’换一个页面‘ 爬取我们想要爬取的资源。
换的那个页面,有时是 XHR 文件,有时是 HTML 文件。
目标站点分析
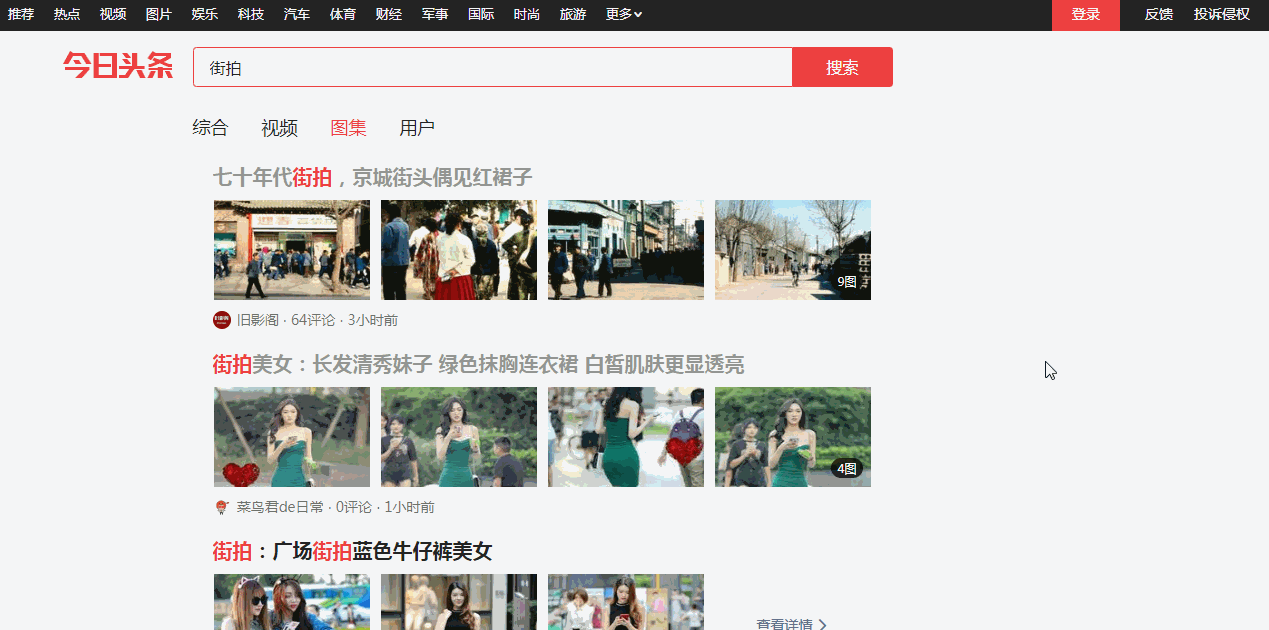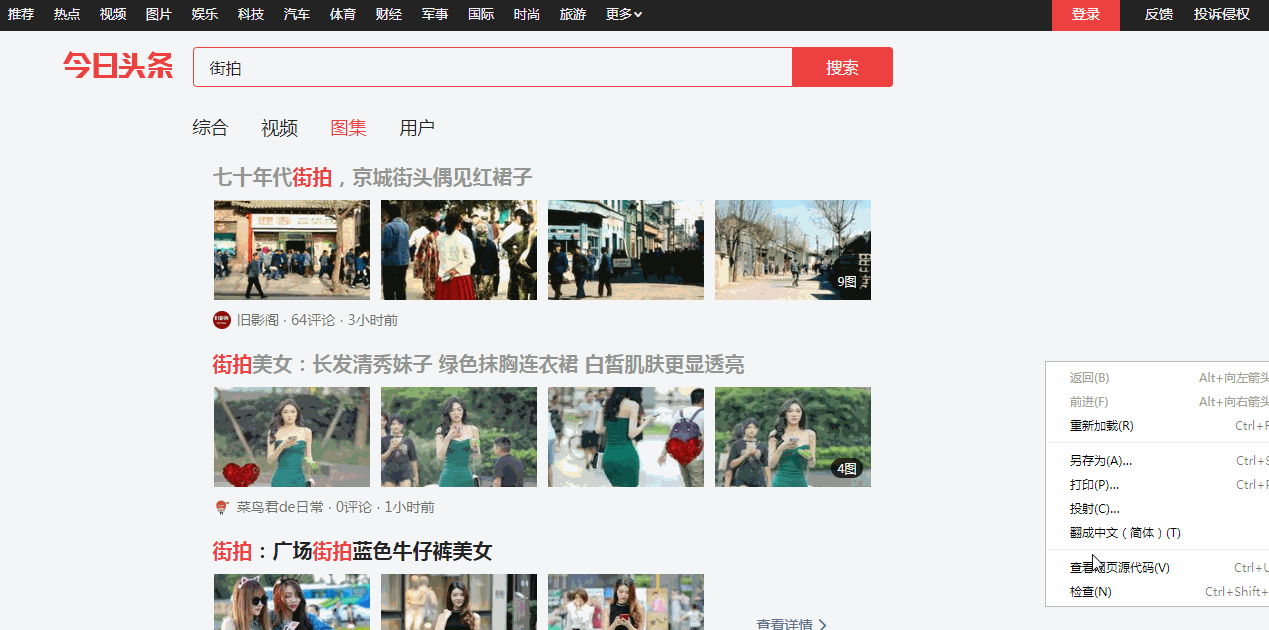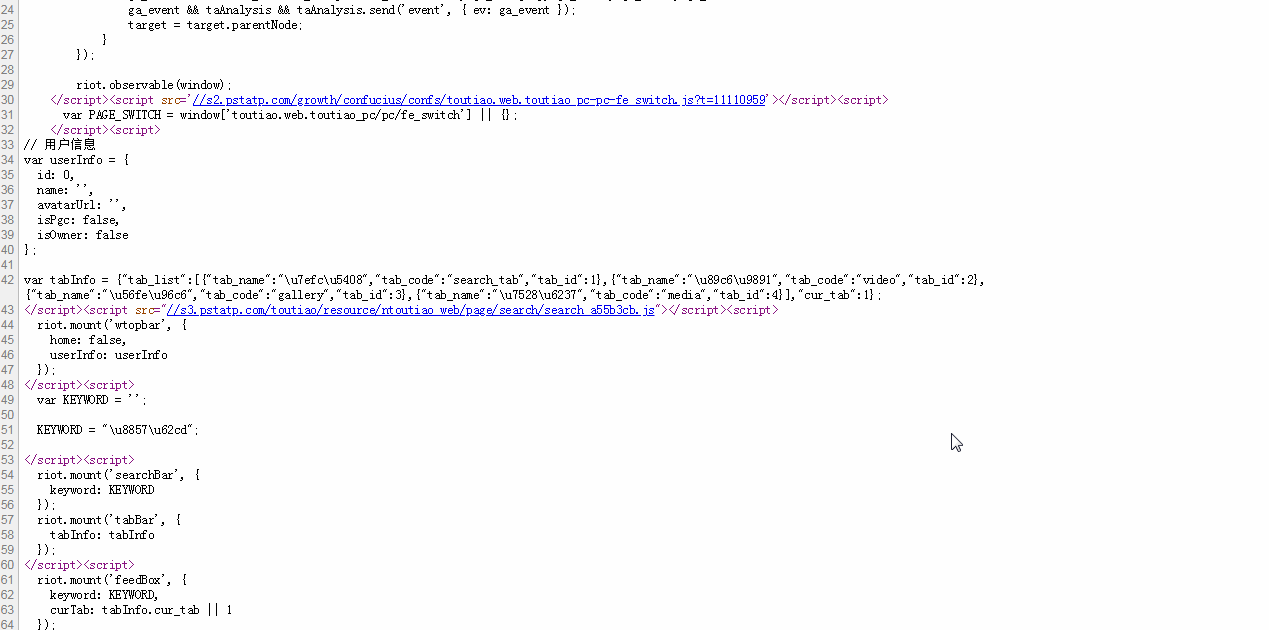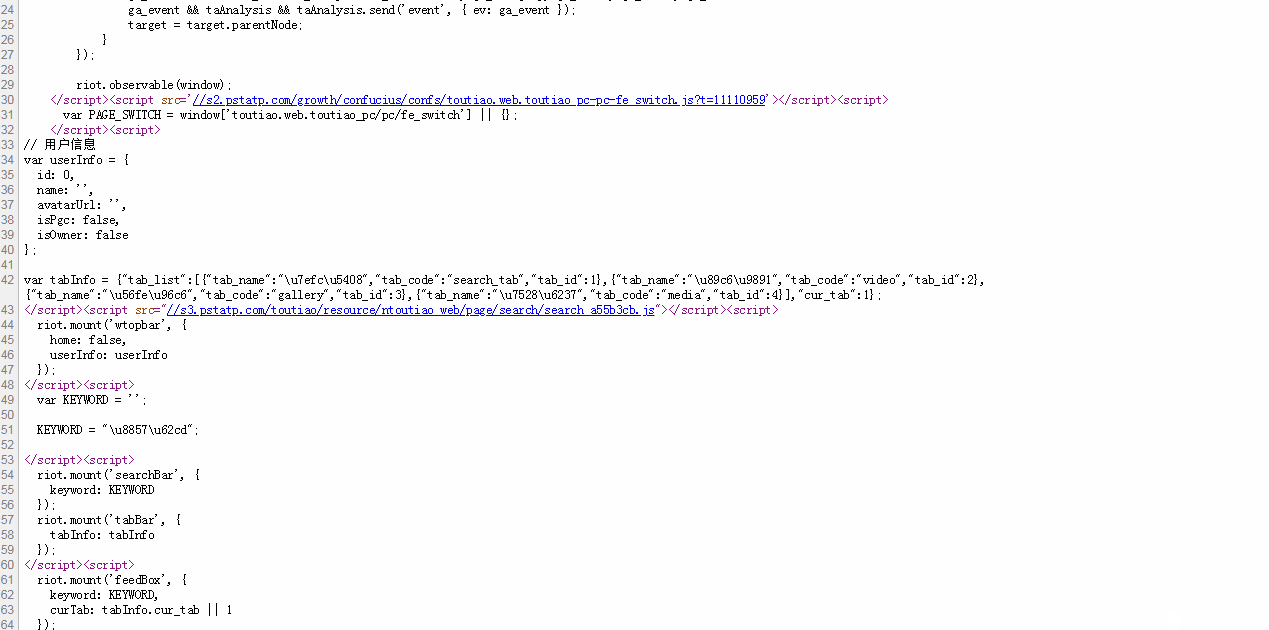
F12审查页面元素。
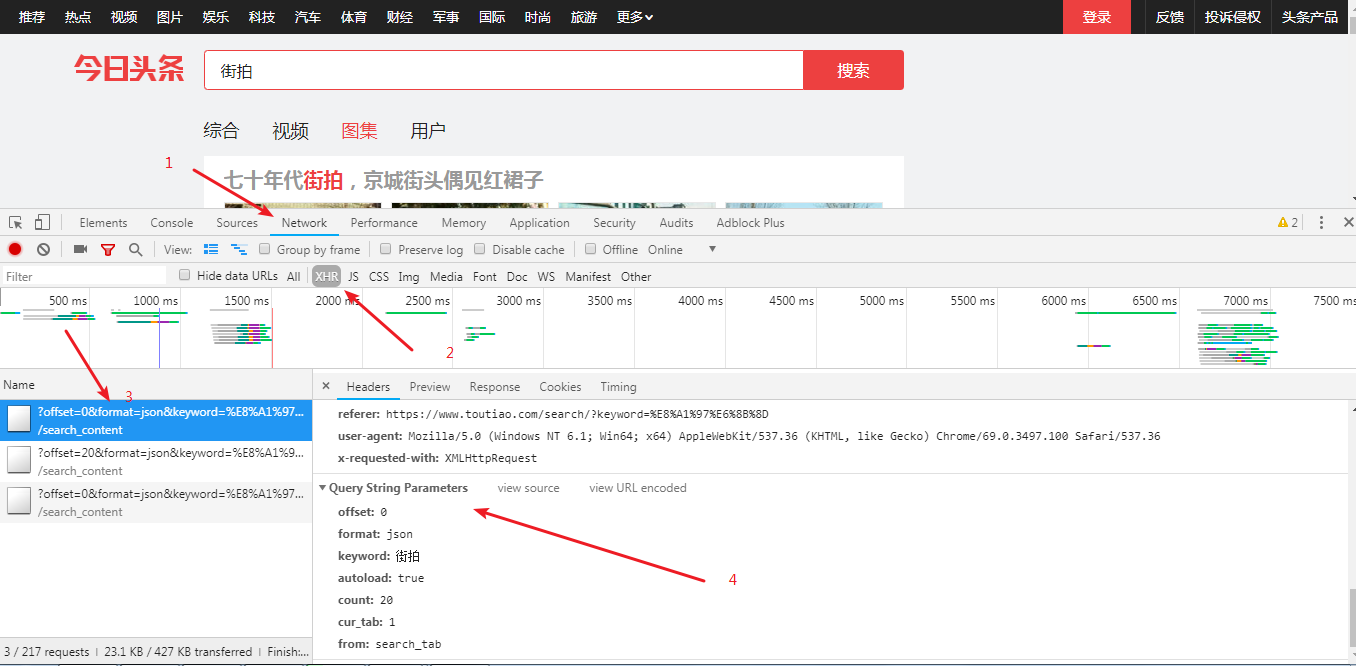
我们需要的资源全部在这个 URL 下。
获取JSON数据
def getPage(offset):params = {'offset': offset,'format': 'json','keyword': '街拍','autoload': 'true','count': '20','cur_tab': '3','from': 'gallery',}url = 'https://www.toutiao.com/search_content/?' + urlencode(params)try:r = requests.get(url)if r.status_code == 200:return r.json()except requests.ConnectionError:return ""
urllib.parse.urlencode()
转换映射对象或两个元素的元组,其可以包含的序列
str或bytes对象。如若是字符串,则结果是由‘&’分隔的key=value的系列队。
解析Json数据
def getImage(json):data = json.get('data')for item in data:title = item.get('title')image_list = item.get('image_list')if image_list:for item in image_list:yield{'title': title,'image': item.get('url')}
保存图片
def saveImage(item):img_path = 'img' + os.path.sep + item.get('title')if not os.path.exists(img_path):os.makedirs(img_path)local_image_url = item.get('image')new_image_url = local_image_url.replace('list', 'large')r = requests.get('http:' + new_image_url)if r.status_code == 200:file_path = img_path + os.path.sep +'{0}.{1}'.format(md5(r.content).hexdigest(), 'jpg')if not os.path.exists(file_path):with open(file_path, 'wb') as f:f.write(r.content)
在官方文档中描述 hexdigest() 函数的一段话:
At any point you can ask it for the digest of the concatenation of the strings fed to it so far using the digest() or hexdigest() methods.
大概意思是:
到目前为止,hexdigest() 和 digest() 函数能满足你把一串字符串的组合物变成一段摘要的需要。
官方文档:
https://docs.python.org/2/library/hashlib.html
保存到MongDB
def saveToMongo(item):if db[MONGO_TABLE].insert(item):print('储存到MONGODB成功', item)return False
主函数和进程池
def main(offset):json = getPage(offset)for item in getImage(json):saveImage(item)saveToMongo(item)if __name__ == '__main__':pool = Pool()groups = [x * 20 for x in range(2)] #爬取五页pool.map(main, groups)pool.close() #关闭进程池(pool),使其不在接受新的任务pool.join() #主进程阻塞等待子进程的退出
对 pool 对象调用 join() 方法会让主进程等待所有子进程自行完毕,调用 join() 之前必须先调用 close() ,让其不再接受新的 Process 了。
总结
主要关注如何下载和解析 Json数据。
公众号内输出 ‘崔佬视频’ 获取崔庆才大佬的《Python3WebSpider》全套视频。
全码
import requests
from urllib.parse import urlencode
import os
from hashlib import md5
import pymongo
from multiprocessing.pool import PoolMONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao' #数据集合Collectionclient = pymongo.MongoClient(MONGO_URL) # MongoClient 对象,并且指定连接的 URL 地址
db = client[MONGO_DB] #要创建的数据库名def getPage(offset):params = {'offset': offset,'format': 'json','keyword': '街拍','autoload': 'true','count': '20','cur_tab': '3','from': 'gallery',}url = 'https://www.toutiao.com/search_content/?' + urlencode(params)try:r = requests.get(url)if r.status_code == 200:return r.json()except requests.ConnectionError:return ""def getImage(json):data = json.get('data')for item in data:title = item.get('title')image_list = item.get('image_list')if image_list:for item in image_list:yield{'title': title,'image': item.get('url')}def saveImage(item):img_path = 'img' + os.path.sep + item.get('title')if not os.path.exists(img_path):os.makedirs(img_path)local_image_url = item.get('image')new_image_url = local_image_url.replace('list', 'large')r = requests.get('http:' + new_image_url)if r.status_code == 200:file_path = img_path + os.path.sep +'{0}.{1}'.format(md5(r.content).hexdigest(), 'jpg')if not os.path.exists(file_path):with open(file_path, 'wb') as f:f.write(r.content)def saveToMongo(item):if db[MONGO_TABLE].insert(item):print('储存到MONGODB成功', item)return Falsedef main(offset):json = getPage(offset)for item in getImage(json):saveImage(item)saveToMongo(item)if __name__ == '__main__':pool = Pool()groups = [x * 20 for x in range(2)] #爬取五页pool.map(main, groups)pool.close() #关闭进程池(pool),使其不在接受新的任务pool.join() #主进程阻塞等待子进程的退出
![]()
进阶爬虫:今日头条街拍美图相关推荐
- python爬虫今日头条街拍美图开发背景_【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图...
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- python爬虫今日头条街拍美图开发背景_分析Ajax请求并抓取今日头条街拍美图:爬取详情页的url与实际页面上显示不符...
from urllib.parse import urlencode import re from requests.exceptions import RequestException from b ...
- Python爬虫 | 批量爬取今日头条街拍美图
点击上方"Python爬虫与数据挖掘",进行关注 回复"书籍"即可获赠Python从入门到进阶共10本电子书 今日鸡汤浮云一别后,流水十年间. 专栏作者:霖he ...
- python爬虫今日头条_python爬虫—分析Ajax请求对json文件爬取今日头条街拍美图
python爬虫-分析Ajax请求对json文件爬取今日头条街拍美图 前言 本次抓取目标是今日头条的街拍美图,爬取完成之后,将每组图片下载到本地并保存到不同文件夹下.下面通过抓取今日头条街拍美图讲解一 ...
- [Python3网络爬虫开发实战] --分析Ajax爬取今日头条街拍美图
[Python3网络爬虫开发实战] --分析Ajax爬取今日头条街拍美图 学习笔记--爬取今日头条街拍美图 准备工作 抓取分析 实战演练 学习笔记–爬取今日头条街拍美图 尝试通过分析Ajax请求来抓取 ...
- python爬取今日头条_Python3网络爬虫实战-36、分析Ajax爬取今日头条街拍美图
本节我们以今日头条为例来尝试通过分析 Ajax 请求来抓取网页数据的方法,我们这次要抓取的目标是今日头条的街拍美图,抓取完成之后将每组图片分文件夹下载到本地保存下来. 1. 准备工作 在本节开始之前请 ...
- 爬取今日头条街拍美图
相关背景: 本篇文章是基于爬虫实践课程–分析Ajax请求并抓取今日头条街拍美图 其实我最开始也只想在CSDN上面找一篇文章看看结果都是分析没有实操,没办法最后只能自己写了,本篇文章里面的问题也是我遇到 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- Python3网络爬虫开发实战分析Ajax爬取今日头条街拍美图
本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 很多人学习pyt ...
最新文章
- 辞职前为什么挣扎_当您感到自己像开发人员一样挣扎时,为什么学得最多
- k means聚类算法_一文读懂K-means聚类算法
- python七段数码管设计图案-python实现七段数码管和倒计时效果
- Linux内核社区是数字军火商、斯拉夫兵工厂甚至NSA的最爱
- 四篇NeurIPS 2019论文,快手特效中的模型压缩了解一下
- 2009年全国计算机软件考试推荐用书目录
- gbk编码的简介以及针对gbk文本飘红截断原理以及实现
- JS new操作符执行之后背后的操作
- Elasticsearch 日期时间处理
- iOS开发之Xcode项目文件自动展开问题的解决办法
- 超级全面的iOS资源
- Git版本控制(完美整理版)
- 存储数据恢复案例_磁盘阵列数据恢复_raid5磁盘掉线数据恢复方法
- app上架华为应用市场流程
- 如何优化前端页面的LCP?
- JavaScript.07.淘宝购物车案例
- 下载Windows ISO镜像的方法 (超详细 适合新手入门)
- 使用Python解析MNIST数据集(IDX格式文件)
- 主动降噪耳机排行榜10强,主动降噪耳机十大品牌
- Webdings,Wingdings图形字体对照表