gbk编码的简介以及针对gbk文本飘红截断原理以及实现
2019独角兽企业重金招聘Python工程师标准>>> 
一个检索系统,在归并拉链并获得摘要数据之后,必不可少的环节是飘红截断。
对于整个架构来说,检索索引以及rank等后端一般使用c/c++来实现,真正的展现ui可以使用php/python等脚本语言来实现。对于飘红而言,可以放在ui端使用php截断飘红,也可以放在后端通过c/c++来飘红截断。文本编码可以用gbk也可以用utf-8。对于存储而言,如果使用gbk编码可以比utf-8
使用php的优点:操作简单,有大量现成的库,不需要关注gbk等具体实现,通过mb_str库可以搞定所有事情,缺点在文本较长的时候性能及其低下。显而易见,使用C/C++的有点是性能极高,但是确定是需要自己去关注字符编码。
因为排期较紧,我起初使用了php来进行飘红截断,一个文本(字数大概在5k左右)飘红大概花了200+ms,这个性能是不能忍受的,之后我只好改成了c/c++来进行飘红截断,性能得到显著提升,耗时只有0.01ms。性能提升达到万倍。
现在描述下怎么来使用c/c++来飘红截断文本。
1、 gbk简介
首先先简要介绍一下gbk(gb2312编码)。
GBK是在国家标准GB2312基础上扩容后兼容GB2312的标准,包含所有的中文字符。一个中文需要3个字节,最高位为1,所以第一个字节大于0x80. 此外字符编码还有utf-8。gbk和utf-8之间可以通过Unicode编码进行转换。gbk,utf-8,Unicode之间的关系如果有不了解的请自己Google或者百度.
2、飘红需求
2.1、输入:
需要截断文本content
需要飘红的词组hi_words,用"|"进行进行分割
需要截断的字数 len
2.2、飘红截断规则
优先截断字节数目一定;优先截取飘红词右边的整句;如果整句不到截断字数,在拿飘红词左边的句子进行填充。
3、实现
3.1 把输入的飘红词语翻入vector.
这个使用strtok_r轻轻松松搞定(注意不要使用非线程安全的strtok).
int getHighWord(char* high_words, vector<string>& words)
{char keyword[1024];char *ptok = NULL;snprintf(keyword, sizeof(keyword), "%s", high_words);char *part = strtok_r(keyword, "|", &ptok);while( part != NULL){string tmp(part);words.push_back(tmp);part = strtok_r(NULL, "|", &ptok);}return 0;
}3.2、把句子分隔符放入到vector中。
sep_china是中文句子分隔符,sep_uni是英文分割符,他们都是一个整句。
vector<string> sep_china;
vector<string> sep_uni;
sep_china.push_back(",");
sep_china.push_back("。");
sep_china.push_back(";");
sep_china.push_back(":");
sep_china.push_back("!");sep_uni.push_back(",");
sep_uni.push_back(".");
sep_uni.push_back("?");
sep_uni.push_back(";");
sep_uni.push_back(":");3.3、具体处理流程
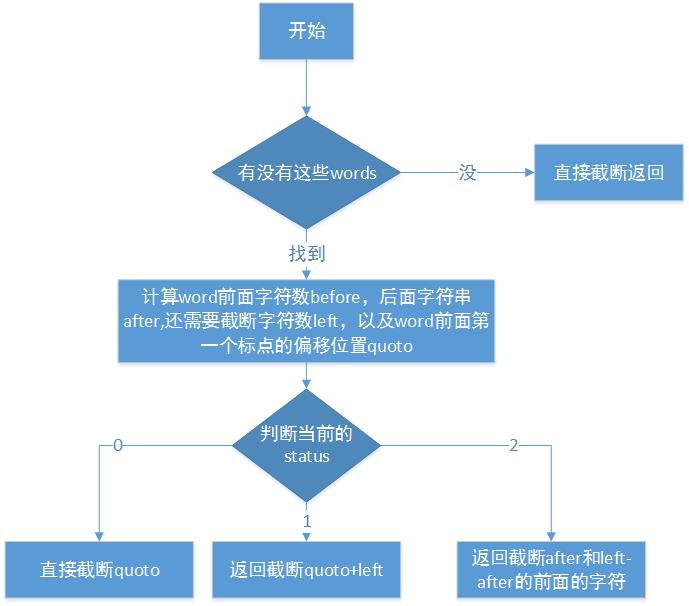
3.4 判断有没有这些words,返回pos_word
string str_cnt(content);//首先判断有没有这个wordint pos_word = -1;string min_word;int i;for(i=0; i<words.size(); i++){pos_word = str_cnt.find(words[i]);if(pos_word > 0){min_word = words[i];break;}}//如果没有找到,直接截断返回if( pos_word < 0){if( num <= getExtraWord(content, hi_word, 0, num) ){strcat(hi_word,"...");return 0;}}3.5 计算word前面字符数before,后面字符串after,还需要截断字符数left,以及word前面第一个标点的偏移位置quoto(需要考虑中文和英文)。
//还需要多少字节int left = num - min_word.size();//前面有多少字节int before = pos_word;//后面还有多少字节int after = str_cnt.size() - min_word.size() - pos_word;//获得前一个标点的位置int pos_quoto_china = -1;int pos_quoto_uni = -1;string quoto_str = str_cnt.substr(0, pos_word);pos_quoto_china = findMaxPos(quoto_str, sep_china) + 2; //一个标点2个字符 pos_quoto_uni = findMaxPos(quoto_str,sep_uni) +1 ; //一个标点一个字符int quoto_pos = pos_quoto_uni > pos_quoto_china ? pos_quoto_uni : pos_quoto_china;//获得前一个标点有多少字节int quoto = quoto_pos > 0 ? pos_word - quoto_pos : 0;3.6 根据before, after, quoto, left计算目前status
int getStatus(int before, int after, int quoto, int left)
{int status = 0;if(quoto >= left){//直接截断quotostatus = 0;}else if( quoto + after > left){//返回截断quoto+leftstatus =1 ;}else{//返回截断after和left-after的前面status =2;}return status;
}3.7 根据返回的status进行处理
char before_word[1024];char after_word[1024];int left_cnt;int right_cnt;before_word[0] = after_word[0] = '0';switch(status){case 0:getExtraWord(content, hi_word, pos_word, left);strcat(hi_word, "...");break;case 1:left_cnt = getExtraWord(content, before_word, pos_word -1, -1 * quoto);right_cnt = getExtraWord(content, after_word, pos_word + min_word.size(), left- quoto);if( left_cnt < pos_word){strcpy(hi_word, "...");}strcat(hi_word, before_word);strcat(hi_word, min_word.c_str() );strcat(hi_word, after_word);strcat(hi_word, "...");break;case 2:right_cnt = getExtraWord(content, before_word, pos_word + min_word.size() , after);left_cnt = getExtraWord(content, after_word, pos_word-1 , after- left);if( left_cnt < pos_word){strcpy(hi_word, "...");}strcat(hi_word, before_word);strcat(hi_word, min_word.c_str() );strcat(hi_word, after_word);strcat(hi_word, "...");break;default:getExtraWord(content, hi_word, 0, num);break;}3.8 截断函数
其中最为核心的为截断函数,如下所示,从word的begin位置截取length个字符(length小于0表示从左截断,0x80是判断标准。
int getExtraWord(const char* word, char* res, int begin, int length)
{if(length == 0 ){res[0] = '\0';return 0;}int i;int flag;const char *str = word + begin;const char *chech_vaild = (length >0 )? str : str+1;if( false == checkVaild(chech_vaild) ){cout << "not vaild\n";//尽力修复下吧begin ++;str++;}//如果从后截断 word没有 length,直接返回if( (int)strlen(str) <= length ){strcpy(res, str);return strlen(str);}//如果从前截断 word没有lenght长if( begin <= -1 * length) {strncpy(res, word, begin);res[begin ] = '\0';return begin;}flag = length > 0 ? 1 : -1;int num = 0;while( *str ){//如果是中文if((unsigned char)*str > 0x80){num += 2;str += flag * 2;}else{num ++;str += flag;}if( num >= flag * length){break;}}res[0] = '\0';i = 0;str = (length > 0) ? word + begin : word + begin - num + 1;while(*str){res[i++] = *(str++);if(i==num){break;}}res[i] = '\0';return i;
}4、结果
4.1 测试case:
int main()
{const char* content = "啊。鸡 从到信阳,然后在火车站有直达鸡公山的汽车,只收10元。约一个小时就到鸡公山脚下,以前票价是63,自从港中旅进驻鸡公山后,现在好像改成123了,当然了,港中旅把鸡公山搞得更加漂亮和特色了。 在鸡公山门口有去山顶的旅游大巴,单程15元,往返的20元,不过建议大家做单程上去,然后步行从登山古道或者长生谷下山,会更加有趣味。和朋友在登山古道的入口处景区处于全监控状态,所以相当安全。美龄舞厅外面的招牌很显眼啊。颐庐是鸡公山上最有名的建筑,尽管世界各国都曾有在山上建房子,但惟独中国人靳";vector<string> words;char* hi = "信阳";getHighWord(hi, words);for(int i=0; i<words.size(); i++){cout << words[i] << endl;}char hi_word[1024];hi_word[0] = '\0';getHilight(content, hi_word, words, 200);cout << "hi_word is " << hi_word << endl;
}4.2 结果:

5、全部源代码
#include <stdio.h>
#include <iostream>
#include <string>
#include <vector>
using namespace std;/** 查看一句话是否是完整的gbk语句 */
bool checkVaild(const char* word)
{bool vaild = true;while(*word){if( (unsigned char)*word++ > 0x80 ){vaild = !vaild;}}return vaild;
}int getExtraWord(const char* word, char* res, int begin, int length)
{if(length == 0 ){res[0] = '\0';return 0;}int i;int flag;const char *str = word + begin;const char *chech_vaild = (length >0 )? str : str+1;if( false == checkVaild(chech_vaild) ){cout << "not vaild\n";//尽力修复下吧begin ++;str++;}//如果从后截断 word没有 length,直接返回if( (int)strlen(str) <= length ){strcpy(res, str);return strlen(str);}//如果从前截断 word没有lenght长if( begin <= -1 * length) {strncpy(res, word, begin);res[begin ] = '\0';return begin;}flag = length > 0 ? 1 : -1;int num = 0;while( *str ){//如果是中文if((unsigned char)*str > 0x80){num += 2;str += flag * 2;}else{num ++;str += flag;}if( num >= flag * length){break;}}res[0] = '\0';i = 0;str = (length > 0) ? word + begin : word + begin - num + 1;while(*str){res[i++] = *(str++);if(i==num){break;}}res[i] = '\0';return i;
}int getStatus(int before, int after, int quoto, int left)
{int status = 0;if(quoto >= left){//直接截断quotostatus = 0;}else if( quoto + after > left){//返回截断quoto+leftstatus =1 ;}else{//返回截断after和left-after的前面status =2;}return status;
}int findMaxPos(string content, vector<string>quotos)
{int i;int pos = string::npos;int tmp_pos;for(i=0; i<quotos.size(); i++){tmp_pos = content.rfind(quotos[i]);if( tmp_pos > pos){pos = tmp_pos;}}return pos;
}int getHilight(const char* content, char* hi_word, vector<string> words, int num)
{//如果不够长if( strlen(content) <= num ){strcpy(hi_word, content);return 0;}//首先分词vector<string> sep_china;vector<string> sep_uni;sep_china.push_back(",");sep_china.push_back("。");sep_china.push_back("?");sep_china.push_back(";");sep_china.push_back(":");sep_china.push_back("!");sep_uni.push_back(",");sep_uni.push_back(".");sep_uni.push_back("?");sep_uni.push_back(";");sep_uni.push_back(":");sep_uni.push_back(";");//sep_uni.push_back(" ");//内容string str_cnt(content);//首先判断有没有这个wordint pos_word = -1;string min_word;int i;for(i=0; i<words.size(); i++){pos_word = str_cnt.find(words[i]);if(pos_word > 0){min_word = words[i];break;}}//如果没有找到,直接截断返回if( pos_word < 0){if( num <= getExtraWord(content, hi_word, 0, num) ){strcat(hi_word,"...");return 0;}}//还需要多少字节int left = num - min_word.size();//前面有多少字节int before = pos_word;//后面还有多少字节int after = str_cnt.size() - min_word.size() - pos_word;//获得前一个标点的位置int pos_quoto_china = -1;int pos_quoto_uni = -1;string quoto_str = str_cnt.substr(0, pos_word);pos_quoto_china = findMaxPos(quoto_str, sep_china) + 2; //一个标点2个字符 pos_quoto_uni = findMaxPos(quoto_str,sep_uni) +1 ; //一个标点一个字符int quoto_pos = pos_quoto_uni > pos_quoto_china ? pos_quoto_uni : pos_quoto_china;//获得前一个标点有多少字节int quoto = quoto_pos > 0 ? pos_word - quoto_pos : 0;int status = getStatus(before, after, quoto, left);char before_word[1024];char after_word[1024];int left_cnt;int right_cnt;before_word[0] = after_word[0] = '0';switch(status){case 0:getExtraWord(content, hi_word, pos_word, left);strcat(hi_word, "...");break;case 1:left_cnt = getExtraWord(content, before_word, pos_word -1, -1 * quoto);right_cnt = getExtraWord(content, after_word, pos_word + min_word.size(), left- quoto);if( left_cnt < pos_word){strcpy(hi_word, "...");}strcat(hi_word, before_word);strcat(hi_word, min_word.c_str() );strcat(hi_word, after_word);strcat(hi_word, "...");break;case 2:right_cnt = getExtraWord(content, before_word, pos_word + min_word.size() , after);left_cnt = getExtraWord(content, after_word, pos_word-1 , after- left);if( left_cnt < pos_word){strcpy(hi_word, "...");}strcat(hi_word, before_word);strcat(hi_word, min_word.c_str() );strcat(hi_word, after_word);strcat(hi_word, "...");break;default:getExtraWord(content, hi_word, 0, num);break;}return 0;
}int getHighWord(char* high_words, vector<string>& words)
{char keyword[1024];char *ptok = NULL;snprintf(keyword, sizeof(keyword), "%s", high_words);char *part = strtok_r(keyword, "|", &ptok);while( part != NULL){string tmp(part);words.push_back(tmp);part = strtok_r(NULL, "|", &ptok);}return 0;
}int main()
{const char* content = "啊。鸡 从到信阳,然后在火车站有直达鸡公山的汽车,只收10元。约一个小时就到鸡公山脚下,以前票价是63,自从港中旅进驻鸡公山后,现在好像改成123了,当然了,港中旅把鸡公山搞得更加漂亮和特色了。 在鸡公山门口有去山顶的旅游大巴,单程15元,往返的20元,不过建议大家做单程上去,然后步行从登山古道或者长生谷下山,会更加有趣味。和朋友在登山古道的入口处景区处于全监控状态,所以相当安全。美龄舞厅外面的招牌很显眼啊。颐庐是鸡公山上最有名的建筑,尽管世界各国都曾有在山上建房子,但惟独中国人靳";vector<string> words;char* hi = "信阳";getHighWord(hi, words);for(int i=0; i<words.size(); i++){cout << words[i] << endl;}char hi_word[1024];hi_word[0] = '\0';getHilight(content, hi_word, words, 100);cout << "hi_word is " << hi_word << endl;
}转载于:https://my.oschina.net/jungleliu0923/blog/198469
gbk编码的简介以及针对gbk文本飘红截断原理以及实现相关推荐
- GBK编码具体解析(附GBK码位分布图)
1.GBK码位分布图 2.GBK码位说明 GBK 亦採用双字节表示,整体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线.总计 23940 ...
- GBK编码详细解析(附GBK码位分布图)
1.GBK码位分布图 2.GBK码位说明 GBK 亦采用双字节表示,总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线.总计 23940 ...
- 小程序服务器gbk编码,微信小程序实现GBK和UTF-8互转
js虽然有第三方支持的GBK工具,但是小程序没有:而我开发中又需要进行格式的转化,就依据前人的经验做了一份出来. 分为两部分:Decode.js和Encode.js.分别是GBK格式的二进制文件转化为 ...
- php 怎么将a 转成65,详细阐述PHP环境下如何将gbk编码转成utf8格式
\n apache 字符集 GB 2312 mysql 字符集 GBK 现要从 mysql 中提出信息(GBK) 写入到 XML 中 XML中的编码格式是 UTF-8 \n 那么,如何将GBK编码成 ...
- Python中文gbk编码输出报错
Python使用requests模块作接口请求,在处理response响应时,经常会出现乱码或者报错,比如 import requests #--请求接口查询天气 result = requests. ...
- 第一章 编程基础_ASCII 编码和GBK编码
计算机是一种改变世界的发明,很快就从美国传到了全球各地,得到了所有国家的认可,成为了一种不可替代的工具.计算机在广泛流行的过程中遇到的一个棘手问题就是字符编码,计算机是美国人发明的,它使用的是 ASC ...
- Computer:字符编码(ASCII编码/GBK编码/BASE64编码/UTF-8编码)的简介、案例应用(python中的编码格式及常见编码问题详解)之详细攻略
Computer:字符编码(ASCII编码/GBK编码/BASE64编码/UTF-8编码)的简介.案例应用(python中的编码格式及常见编码问题详解)之详细攻略 目录 符串编码(ASCII编码/GB ...
- mac下html编辑器,【已解决】Mac下好用的支持GBK编码的文本代码编辑器
Mac中已安装了Sublime Text 3和ATOM编辑器,但是对于从Windows拷贝过来的,GBK编码的文本支持都不好: 打开后,中文是乱码: 但是Mac中的 文本编辑器,却是可以正常打开的: ...
- pythongbk编码怎么解决_如何解决 Python print 输出文本显示 gbk 编码错误
前阵子想爬点东西,结果一直提示错误UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position,在网上一查,发现是 ...
最新文章
- 【青少年编程】黄羽恒:平行空间
- C++ 基础知识总结
- 卷积神经网络鼻祖LeNet网络分析
- linux环境双网卡主机路由配置
- 横坐标标签如何变斜体?
- 计算机网络协议(一)
- 她发明了可以“喝的饭”,估值已超过10亿美金!从此每天多睡半小时....
- 【计算机网络】比较TCP与UDP
- 开发人员必备的 Chrome 扩展
- python机器学习彩票_Python机器学习及实战kaggle从零到竞赛PDF电子版分享
- 魔术师利用一副牌中的13张红桃c语言,魔术师的猜牌术(1) 魔术师利用一副牌中的13张黑桃 - 下载 - 搜珍网...
- 很多人搞不清楚的两个类Vector,ArrayList
- Kotlin 新版来了,支持跨平台!
- 数学建模-常见模型整理及分类
- python爬取酷狗音乐top500_Python爬取酷狗音乐TOP500榜单
- Swagger注解传参
- python金融分析小知识(25)——如何计算股票每日的收益率并进一步计算净值
- adsl modem的内置命令(viking)
- 如何注册电子邮箱账号,教你创建email邮箱账号
- 策略盈亏分布统计——从零到实盘11