全面梳理:准确率,精确率,召回率,查准率,查全率,假阳性,真阳性,PRC,ROC,AUC,F1
二分类问题的结果有四种:
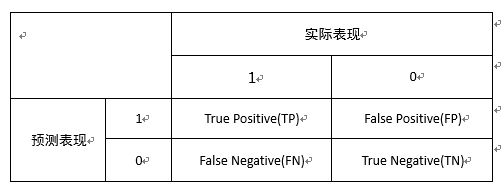
逻辑在于,你的预测是positive-1和negative-0,true和false描述你本次预测的对错
true positive-TP:预测为1,预测正确即实际1
false positive-FP:预测为1,预测错误即实际0
true negative-TN:预测为0,预测正确即实际0
false negative-FN:预测为0,预测错误即实际1
【混淆矩阵】
直观呈现以上四种情况的样本数
【准确率】accuracy
正确分类的样本/总样本:(TP+TN)/(ALL)
在不平衡分类问题中难以准确度量:比如98%的正样本只需全部预测为正即可获得98%准确率
【精确率】【查准率】precision
TP/(TP+FP):在你预测为1的样本中实际为1的概率
查准率在检索系统中:检出的相关文献与检出的全部文献的百分比,衡量检索的信噪比
【召回率】【查全率】recall
TP/(TP+FN):在实际为1的样本中你预测为1的概率
查全率在检索系统中:检出的相关文献与全部相关文献的百分比,衡量检索的覆盖率
实际的二分类中,positive-1标签可以代表健康也可以代表生病,但一般作为positive-1的指标指的是你更关注的样本表现,比如“是垃圾邮件”“是阳性肿瘤”“将要发生地震”。
因此在肿瘤判断和地震预测等场景:
要求模型有更高的【召回率】recall,是个地震你就都得给我揪出来不能放过
在垃圾邮件判断等场景:
要求模型有更高的【精确率】precision,你给我放进回收站里的可都得确定是垃圾,千万不能有正常邮件啊
【ROC】
常被用来评价一个二值分类器的优劣
ROC曲线的横坐标为false positive rate(FPR):FP/(FP+TN)
假阳性率,即实际无病,但根据筛检被判为有病的百分比。
在实际为0的样本中你预测为1的概率
纵坐标为true positive rate(TPR):TP/(TP+FN)
真阳性率,即实际有病,但根据筛检被判为有病的百分比。
在实际为1的样本中你预测为1的概率,此处即【召回率】【查全率】recall
接下来我们考虑ROC曲线图中的四个点和一条线。
第一个点,(0,1),即FPR=0,TPR=1,这意味着无病的没有被误判,有病的都全部检测到,这是一个完美的分类器,它将所有的样本都正确分类。
第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,没病的没有被误判但有病的全都没被检测到,即全部选0
类似的,第四个点(1,1),分类器实际上预测所有的样本都为1。
经过以上的分析可得到:ROC曲线越接近左上角,该分类器的性能越好。
【ROC是如何画出来的】
分类器有概率输出,50%常被作为阈值点,但基于不同的场景,可以通过控制概率输出的阈值来改变预测的标签,这样不同的阈值会得到不同的FPR和TPR。
从0%-100%之间选取任意细度的阈值分别获得FPR和TPR,对应在图中,得到的ROC曲线,阈值的细度控制了曲线的阶梯程度或平滑程度。
一个没有过拟合的二分类器的ROC应该是梯度均匀的,如图紫线
此图为PRC, precision recall curve,原理类似
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。而Precision-Recall曲线会变化剧烈,故ROC经常被使用。
【AUC】
AUC(Area Under Curve)被定义为ROC曲线下的面积,完全随机的二分类器的AUC为0.5,虽然在不同的阈值下有不同的FPR和TPR,但相对面积更大,更靠近左上角的曲线代表着一个更加稳健的二分类器。
同时针对每一个分类器的ROC曲线,又能找到一个最佳的概率切分点使得自己关注的指标达到最佳水平。
【AUC的排序本质】
大部分分类器的输出是概率输出,如果要计算准确率,需要先把概率转化成类别,就需要手动设置一个阈值,而这个超参数的确定会对优化指标的计算产生过于敏感的影响
AUC从Mann–Whitney U statistic的角度来解释:随机从标签为1和标签为0的样本集中分别随机选择两个样本,同时分类器会输出两样本为1的概率,那么我们认为分类器对“标签1样本的预测概率>对标签0样本的预测概率 ”的概率等价于AUC。
因而AUC反应的是分类器对样本的排序能力,这样也可以理解AUC对不平衡样本不敏感的原因了。
【作为优化目标的各类指标】
最常用的分类器优化及评价指标是AUC和logloss,最主要的原因是:不同于accuracy,precision等,这两个指标不需要将概率输出转化为类别,而是可以直接使用概率进行计算。
顺便贴上logloss的公式
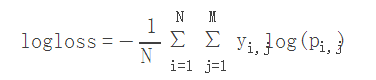
- N:样本数
- M:类别数,比如上面的多类别例子,M就为4
- yij:第i个样本属于分类j时为为1,否则为0
- pij:第i个样本被预测为第j类的概率
【F1】
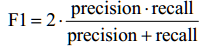
F1兼顾了分类模型的准确率和召回率,可以看作是模型准确率和召回率的调和平均数,最大值是1,最小值是0。
额外补充【AUC为优化目标的模型融合手段rank_avg】:
在拍拍贷风控比赛中,印象中一个前排队伍基于AUC的排序本质,使用rank_avg融合了最后的几个基础模型。
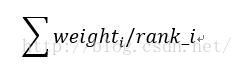
rank_avg这种融合方法适合排序评估指标,比如auc之类的
其中weight_i为该模型权重,权重为1表示平均融合
rank_i表示样本的升序排名 ,也就是越靠前的样本融合后也越靠前
能较快的利用排名融合多个模型之间的差异,而不用去加权样本的概率值融合
贴一段源码:
#三模型的概率输出
xgb_7844 = pd.read_csv('xgb_7844.csv')
svm_771 = pd.read_csv('svm_771.csv')
xgb_787 = pd.read_csv('xgb_787.csv')#score概率变为排名
xgb_7844.score = xgb_7844.score.rank()
svm_771.score = svm_771.score.rank()
xgb_787.score = xgb_787.score.rank()#排名加权融合的结果丧失了概率指义,但AUC的计算不用关系绝对大小,只关心相对大小
pred = 0.7*xgb_787.score + 0.2*xgb_7844.score + 0.1*svm_771.score#AUC的计算
auc = int(roc_auc_score(val.target.values,pred.values)*10000)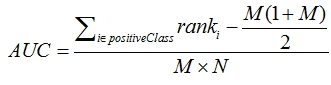
M为正类样本的数目,N为负类样本的数目,rank为分类器给出的排名。
可以发现整个计算过程中连直接的概率输出值都不需要,仅关心相对排名,所以只要保证submit的那一组输出的rank是有意义的即可,并不一定需要必须输出概率。
转:https://zhuanlan.zhihu.com/p/34079183
全面梳理:准确率,精确率,召回率,查准率,查全率,假阳性,真阳性,PRC,ROC,AUC,F1相关推荐
- 准确率(Precision)、召回率(Recall)以及F值(F-Measure)
在信息检索.分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常重要,因此最近根据网友的博客做了一个汇总. 准确率.召回率.F1 信息检索.分类.识别.翻译等领域两个最基本指标是召回率 ...
- 推荐系统评测指标—准确率(Precision)、召回率(Recall)、F值(F-Measure)
下面简单列举几种常用的推荐系统评测指标: 1.准确率与召回率(Precision & Recall) 准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量.其 ...
- 自然语言处理:分词评测指标——准确率(Precision)、召回率(Recall)、F值(F-Measure)
下面简单列举几种常用的推荐系统评测指标: 1.准确率与召回率(Precision & Recall) 准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量.其中精度 ...
- 准确率(Precision)、召回率(Recall)、F值对于模型的评估
一.有哪些模型评估方法? 在机器学习.数据挖掘.推荐系统完成建模之后,需要对模型的效果做评价. 业内目前常常采用的评价指标有准确率(Precision).召回率(Recall).F值(F-Measur ...
- 【机器学习入门】(13) 实战:心脏病预测,补充: ROC曲线、精确率--召回率曲线,附python完整代码和数据集
各位同学好,经过前几章python机器学习的探索,想必大家对各种预测方法也有了一定的认识.今天我们来进行一次实战,心脏病病例预测,本文对一些基础方法就不进行详细解释,有疑问的同学可以看我前几篇机器学习 ...
- 准确率 召回率_机器学习中F值(F-Measure)、准确率(Precision)、召回率(Recall)
在机器学习.数据挖掘.推荐系统完成建模之后,需要对模型的效果做评价. 业内目前常常采用的评价指标有准确率(Precision).召回率(Recall).F值(F-Measure)等,下图是不同机器学习 ...
- 机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure)
转载自:https://www.cnblogs.com/Zhi-Z/p/8728168.html 摘要: 数据挖掘.机器学习和推荐系统中的评测指标-准确率(Precision).召回率(Recall) ...
- 机器学习:准确率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲线、PR曲线
增注:虽然当时看这篇文章的时候感觉很不错,但是还是写在前面,想要了解关于机器学习度量的几个尺度,建议大家直接看周志华老师的西瓜书的第2章:模型评估与选择,写的是真的很好!! 以下第一部分内容转载自:机 ...
- 机器学习深度学习:准确率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲线、PR曲线
增注:虽然当时看这篇文章的时候感觉很不错,但是还是写在前面,想要了解关于机器学习度量的几个尺度,建议大家直接看周志华老师的西瓜书的第2章:模型评估与选择,写的是真的很好!! 以下第一部分内容转载自:机 ...
最新文章
- vim括号匹配跳转操作
- 获得 bootstrapTable行号index
- android 放大镜动画,Android在图片上进行放大镜效果(放大镜形状)
- 快速了解babel工作原理
- K3s(Kubernetes)环境使用Let‘s Encrypt证书的部署及自动配置https域名-阿里云域名解析管理
- 基于Springboot的景区旅游管理系统 JAVA MySQL
- PS2022新增功能简介
- Colaboratory读取谷歌云盘(Google drive)中的数据(2020年3月28日更新)
- 使用Java生成验证码
- mysql rand_MySQL中的RAND()函数使用详解
- 助力自己在金融领域中更加游刃有余的人大与加拿大女王大学金融硕士项目你读到了吗?
- vue安装使用v-chart时报错解决方案
- BART 文本摘要示例
- html图片左右转换,jquery实现图片左右切换的方法
- C#实现毫秒级计时器
- 第二阶段--团队冲刺--第六天
- RTSP、RTMP、HTTP协议
- 推动线下网吧转型 京东Game+ CEST总决赛圆满落幕
- 介绍一款VideoPad 6.01汉化版免费的电影制作视频编辑器
- linux 详解邮件服务器
热门文章
- 准备搞个google play账号玩玩
- window下查看TCP端口连接情况:netstat -ano -p tcp|findstr 10001
- python俄罗斯方块编程思路_少儿编程分享:手把手教你用Python编写俄罗斯方块(十)...
- 【精品】机器学习模型可解释的重要及必要性
- 【map】高德地图点聚合—按索引聚合
- docker目录 /var/lib/docker/containers 日志清理
- Kylin3.1.1集成CDH6.2.1
- 机器人让你摆脱电销压力
- 白鹭发布html5,白鹭Egret Engine 1.5发布 HTML5游戏性能大幅提升
- python找出列表里大于输出_python找出列表中大于某个阈值的数据段示例