【Hinton大神新作】Dynamic Routing Between Capsules阅读笔记
Dynamic Routing Between Capsules
卷积
- 信号处理之卷积,信号的叠加与分解
- http://blog.csdn.net/lz0499/article/details/70195284
- 信息是由多个信号组成的,例如图片里面的车、人、天空、草地等等
- 傅里叶变换
核心概念
- Vector,instantiation parameters,个人理解类似于结构性的先验知识,Prior
- Length of Vector, probability of entity exists
- Orientation of Vector, instantiation parameters
Better at recognizing highly overlapping digits
信号处理中,正弦信号,频率,相位,幅值
假设有先验的结构信息
训练过程:Iterative Routing Process
网络结构
- Overall length of the vector of instantiation parameters to represent the existence
- Orientation of the vector to represent the properties of the entity
与CNN的区别
- Scalar Output feature detectors , Vector-output capsules
- Max-pooling, Routing-by-agreement
总结
- 过去的例子:Speech Recognition,hidden Markov models with Gaussian mixtures as output distributions.
- CNN is the dominant approach to object recoginiton,如何改变?
- Converting pixel intensities into vectors of instantiation parameters of recognized fragments.
- Capsules make a very strong representational assumption.
- And Capsules are also very god of dealing with segmentation.
知乎上的链接
https://www.zhihu.com/question/67287444
技术升级
【MATRIX CAPSULES WITH EM ROUTING】
https://openreview.net/pdf?id=HJWLfGWRb
原文翻译
作者:AI研习社
链接:https://www.zhihu.com/question/67287444/answer/252315722
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
胶囊间的动态路由摘要本论文所研究的胶囊意为一组神经元,其激活向量反映了某类特定实体(可能是整体也可能是部分)的表征。本论文使用激活向量的模长来描述实体存在的概率,用激活向量的方向表征对应实例的参数。某一层级的活跃胶囊通过矩阵变换做出预测,预测结果会用来给更高层级的胶囊提供实例参数。当多个预测值达成一致时,一个高层级的胶囊就会被激活。论文中展示了差异化训练的多层胶囊系统可以在MNIST上达到当前最高水平的表现,在识别高度重叠的数字上也要比卷积网络要好得多。网络的实现中运用迭代的一致性路由机制:当低层级的胶囊的预测向量和高层级胶囊的激活向量有较大的标量积时,这个低层级胶囊就会倾向于向高层级胶囊输出。一、简介人类视觉通过使用仔细确定的固定点序列来忽略不相关的细节,以确保只有极小部分的光学阵列以最高的分辨率被处理。要理解我们对场景的多少知识来自固定序列,以及我们从单个固定点中能收集到多少知识,内省不是一个好的指导,但是在本文中,我们假设单个固定点给我们提供的不仅仅是一个单一的识别对象及其属性。我们假设多层视觉系统在每个固定点上都会创建一个类似解析树这样的东西,并且单一固定解析树在多个固定点中如何协调的问题会被我们忽略掉。解析树通常通过动态分配内存来快速构建,但根据Hinton等人的论文「Learning to parse images,2000」,我们假设,对于单个固定点,从固定的多层神经网络中构建出一个解析树,就像从一块岩石雕刻出一个雕塑一样(雷锋网 AI 科技评论注: 意为只保留了部分树枝)。每个层被分成许多神经元组,这些组被称为“胶囊”(Hinton等人「Transforming auto-encoders,2011」),解析树中的每个节点就对应着一个活动的胶囊。通过一个迭代路由过程,每个活动胶囊将在更高的层中选择一个胶囊作为其在树中的父结点。对于更高层次的视觉系统,这样的迭代过程就很有潜力解决一个物体的部分如何层层组合成整体的问题。一个活动的胶囊内的神经元活动表示了图像中出现的特定实体的各种属性。这些属性可以包括许多不同类型的实例化参数,例如姿态(位置,大小,方向),变形,速度,反照率,色相,纹理等。一个非常特殊的属性是图像中某个类别的实例的存在。表示存在的一个简明的方法是使用一个单独的逻辑回归单元,它的输出数值大小就是实体存在的概率(雷锋网 AI 科技评论注: 输出范围在0到1之间,0就是没出现,1就是出现了)。在本文中,作者们探索了一个有趣的替代方法,用实例的参数向量的模长来表示实体存在的概率,同时要求网络用向量的方向表示实体的属性。为了确保胶囊的向量输出的模长不超过1,通过应用一个非线性的方式使矢量的方向保持不变,同时缩小其模长。胶囊的输出是一个向量,这一设定使得用强大的动态路由机制来确保胶囊的输出被发送到上述层中的适当的父节点成为可能。最初,输出经过耦合总和为1的系数缩小后,路由到所有可能的父节点。对于每个可能的父结点,胶囊通过将其自身的输出乘以权重矩阵来计算“预测向量”。如果这一预测向量和一个可能的父节点的输出的标量积很大,则存在自上而下的反馈,其具有加大该父节点的耦合系数并减小其他父结点耦合系数的效果。这就加大了胶囊对那一个父节点的贡献,并进一步增加了胶囊预测向量和该父节点输出的标量积。这种类型的“按协议路由”应该比通过最大池化实现的非常原始的路由形式更有效,其中除了保留本地池中最活跃的特征检测器外,忽略了下一层中所有的特征检测器。作者们论证了,对于实现分割高度重叠对象所需的“解释”,动态路由机制是一个有效的方式。卷积神经网络(CNN)使用学习得到的特征检测器的转移副本,这使得他们能够将图片中一个位置获得的有关好的权重值的知识,迁移到其他位置。这对图像解释的极大帮助已经得到证明。尽管作者们此次用矢量输出胶囊和按协议路由的最大池化替代CNN的标量输出特征检测器,他们仍然希望能够在整个空间中复制已习得的知识,所以文中构建的模型除了最后一层胶囊之外,其余的胶囊层都是卷积。与CNN一样,更高级别的胶囊得以覆盖较大的图像区域,但与最大池化不同,胶囊中不会丢弃该区域内实体精确位置的信息。对于低层级的胶囊,位置信息通过活跃的胶囊来进行“地点编码”。当来到越高的层级,越多的位置信息在胶囊输出向量的实值分量中被“速率编码”。这种从位置编码到速率编码的转变,加上高级别胶囊能够用更多自由度、表征更复杂实体的特性,表明更高层级的胶囊也相应地需要更高的维度。二、如何计算一个胶囊的向量输入和输出已经有很多方法可以实现胶囊的大致思路。这篇文章的目的,不是去探究所有可能的方法,而只是表明非常简单直接的方式就可以取得很好的效果,而且动态路由也可以起到帮助。作者们用胶囊输出向量的模长来表示一个胶囊所表征的实体在输入中出现的概率。因此作者们采用一个非线性函数对向量进行“压缩”,短向量被压缩到几乎为零,长向量也被压缩到1以下长度。判别学习中充分利用这个非线性函数。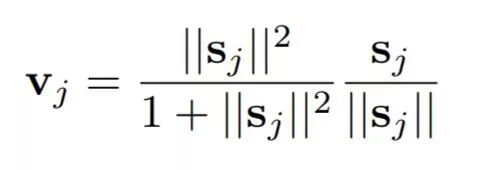 式1其中vj是胶囊j的输出向量,sj是它的全部输入。除了第一层胶囊,胶囊sj的全部输入是对预测向量uj|i的加权求和。这些预测向量都是由低一层的胶囊产生,通过胶囊的输出ui 和一个权重矩阵Wij相乘得来。
式1其中vj是胶囊j的输出向量,sj是它的全部输入。除了第一层胶囊,胶囊sj的全部输入是对预测向量uj|i的加权求和。这些预测向量都是由低一层的胶囊产生,通过胶囊的输出ui 和一个权重矩阵Wij相乘得来。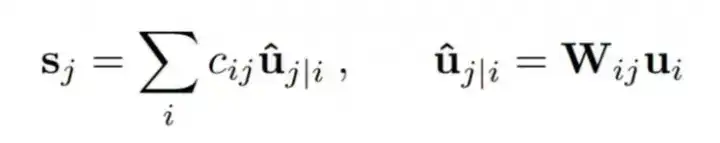 式2其中cij是由迭代的动态路径过程决定的耦合系数。胶囊i和其上一层中所有胶囊的耦合系数的和为1,并由“routing softmax”决定。这个“routing softmax”的初始逻辑值bij 是胶囊i耦合于胶囊j的对数先验概率。
式2其中cij是由迭代的动态路径过程决定的耦合系数。胶囊i和其上一层中所有胶囊的耦合系数的和为1,并由“routing softmax”决定。这个“routing softmax”的初始逻辑值bij 是胶囊i耦合于胶囊j的对数先验概率。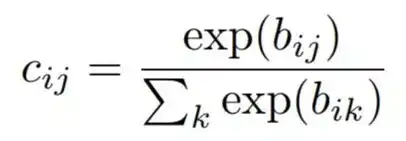 式3这个对数先验可以和其他权重一起被判别学习。他们由两个胶囊的位置和类型决定,而不是当前的输入图像决定。耦合系数会从初始值开始迭代,通过测量每个高一层胶囊j的当前输出vi和低一层胶囊i的预测值ui|j之间的一致性。所述一致性是简单的点积aij=vj . ui|j。这个一致性可被看做最大似然值,并在计算出所有将胶囊i连接到更高层胶囊得到的新耦合值前,加到初始逻辑值bi,j上。在卷积胶囊层中,胶囊内每一个单元都是一个卷积单元。因此每一个胶囊都会输出一个向量网格而不是一个简单的向量。路由计算的伪码如下图
式3这个对数先验可以和其他权重一起被判别学习。他们由两个胶囊的位置和类型决定,而不是当前的输入图像决定。耦合系数会从初始值开始迭代,通过测量每个高一层胶囊j的当前输出vi和低一层胶囊i的预测值ui|j之间的一致性。所述一致性是简单的点积aij=vj . ui|j。这个一致性可被看做最大似然值,并在计算出所有将胶囊i连接到更高层胶囊得到的新耦合值前,加到初始逻辑值bi,j上。在卷积胶囊层中,胶囊内每一个单元都是一个卷积单元。因此每一个胶囊都会输出一个向量网格而不是一个简单的向量。路由计算的伪码如下图 三、某类数字是否存在的边缘损失作者们用实例化向量的模长来表示胶囊要表征的实体是否存在。所以当且仅当图片里出现属于类别k的数字时,作者们希望类别k的最高层胶囊的实例化向量模长很大。为了允许一张图里有多个数字,作者们对每一个表征数字k的胶囊分别给出单独的边缘损失函数(margin loss):
三、某类数字是否存在的边缘损失作者们用实例化向量的模长来表示胶囊要表征的实体是否存在。所以当且仅当图片里出现属于类别k的数字时,作者们希望类别k的最高层胶囊的实例化向量模长很大。为了允许一张图里有多个数字,作者们对每一个表征数字k的胶囊分别给出单独的边缘损失函数(margin loss): 式4其中Tc=1当且仅当图片中有属于类别C的数字,m+=0.9,m-=0.1。是为了减小某类的数字没有出现时的损失,防止刚开始学习就把所有数字胶囊的激活向量模长都压缩了。作者们推荐选用 λ = 0.5。总损失就是简单地把每个数字胶囊的损失加起来的总和。四、CapsNet 结构
式4其中Tc=1当且仅当图片中有属于类别C的数字,m+=0.9,m-=0.1。是为了减小某类的数字没有出现时的损失,防止刚开始学习就把所有数字胶囊的激活向量模长都压缩了。作者们推荐选用 λ = 0.5。总损失就是简单地把每个数字胶囊的损失加起来的总和。四、CapsNet 结构 图1:一个简单的3层CapsNet。这个模型的结果能和深层卷积网络(比如. Batch-normalized maxout network in network,2015)的结果媲美。DigitCaps层每个胶囊的激活向量模长给出了每个类的实例是否存在,并且用来计算分类损失。 是PrimaryCapsules中连接每个 ui, i ∈ (1, 32 × 6 × 6) 和每个vj , j ∈ (1, 10)的权重矩阵。
图1:一个简单的3层CapsNet。这个模型的结果能和深层卷积网络(比如. Batch-normalized maxout network in network,2015)的结果媲美。DigitCaps层每个胶囊的激活向量模长给出了每个类的实例是否存在,并且用来计算分类损失。 是PrimaryCapsules中连接每个 ui, i ∈ (1, 32 × 6 × 6) 和每个vj , j ∈ (1, 10)的权重矩阵。 图2:从DigitCaps层来重构数字的解码结构。训练过程中极小化图像和Sigmoid层的输出之间的欧氏距离。训练中作者们用真实的标签作为重构的目标。图1展示的是一个简单的CapsNet结构。 这是一个很浅的网络,只有2个卷积层和1个全连接层。Conv1有256个9*9的卷积核,步长取1,激活函数为ReLU。这层把像素亮度转化成局部特征检测器的激活,接下去这个值会被用来作为原始胶囊(primary capsules)的输入。原始胶囊是多维实体的最底层。这个过程和图形生成的视角相反,激活了一个原始胶囊就和刚好是图形渲染的逆过程。与先分别计算实例的不同部分再拼在一起形成熟悉的总体理解(图像中的每个区域都会首先激活整个网络而后再进行组合)不同,这是一种非常不同的计算方式。而胶囊的设计就很适合这样的计算。第二层PrimaryCapsules是一个卷积胶囊层,有32个通道,每个通道有一个8维卷积胶囊(也就是说原始胶囊有8个卷积单元,9*9的卷积核,步长为2)。这一层中的胶囊能看到感受野和这个胶囊的中心重合的所有256*81 Conv1单元的输出。PrimaryCapsules一共有[32,6,6]个输出(每个输出是一个8维向量),[6,6]网格中每个胶囊彼此共享权重。由于具有区块非线性,可以把PrimaryCapsules视作一个符合式1的卷积层。最后一层(DigitCaps)有对每个数字类有一个16维的胶囊,所有低一层的胶囊都可以是这一层胶囊的输入。作者们只在两个连续的胶囊层(比如PrimaryCapsules和DigitCaps)之间做路由。因为Conv1的输出是1维的,它所在的空间中不存在方向可以和高层的向量方向达成一致性。所以在Conv1和PrimaryCapsules之间没有路由。所有的路由逻辑值(bij)被初始化为0。因此,一开始一个胶囊的输出(ui)会以相同的概率(cij)传入到所有的母胶囊(v0,v1,…,v10)。作者们用TensorFlow实现了这个网络,选择了Adam优化器和TensorFlow的默认参数,包括指数衰减的学习率用来优化式4的边缘损失的总和。4.1 为了正则化效果而做的重构工作作者们使用了一个额外的重构损失,希望数字胶囊能对输入数字的实例化参数做编码。在训练过程中,作者们用掩蔽的方法只把正确的数字胶囊的激活向量保留下来。然后用这个激活向量来做重构。数字胶囊的输出会传入一个由3个全连接层组成的解码器,它的结构如图2,用来建模像素密度。作者们极小化回归单元的输出和原来图片的像素亮度之间的平方误差,并把重构误差收缩到原来的0.0005倍,这样才不会在训练过程中盖过边缘误差的作用。如图3所示,CapsNet的16维输出的重构是鲁棒的,同时也只保留了重要的细节。五、把 Capsule 用在MNIST上使用 28×28 MNIST的图片集进行训练,训练前这些图片在每个方向不留白地平移了2个像素。除此之外,没有进行其他的数据增改或者转换。在MNIST数据库中,6万张图片用于训练,另外1万张用于测试。
图2:从DigitCaps层来重构数字的解码结构。训练过程中极小化图像和Sigmoid层的输出之间的欧氏距离。训练中作者们用真实的标签作为重构的目标。图1展示的是一个简单的CapsNet结构。 这是一个很浅的网络,只有2个卷积层和1个全连接层。Conv1有256个9*9的卷积核,步长取1,激活函数为ReLU。这层把像素亮度转化成局部特征检测器的激活,接下去这个值会被用来作为原始胶囊(primary capsules)的输入。原始胶囊是多维实体的最底层。这个过程和图形生成的视角相反,激活了一个原始胶囊就和刚好是图形渲染的逆过程。与先分别计算实例的不同部分再拼在一起形成熟悉的总体理解(图像中的每个区域都会首先激活整个网络而后再进行组合)不同,这是一种非常不同的计算方式。而胶囊的设计就很适合这样的计算。第二层PrimaryCapsules是一个卷积胶囊层,有32个通道,每个通道有一个8维卷积胶囊(也就是说原始胶囊有8个卷积单元,9*9的卷积核,步长为2)。这一层中的胶囊能看到感受野和这个胶囊的中心重合的所有256*81 Conv1单元的输出。PrimaryCapsules一共有[32,6,6]个输出(每个输出是一个8维向量),[6,6]网格中每个胶囊彼此共享权重。由于具有区块非线性,可以把PrimaryCapsules视作一个符合式1的卷积层。最后一层(DigitCaps)有对每个数字类有一个16维的胶囊,所有低一层的胶囊都可以是这一层胶囊的输入。作者们只在两个连续的胶囊层(比如PrimaryCapsules和DigitCaps)之间做路由。因为Conv1的输出是1维的,它所在的空间中不存在方向可以和高层的向量方向达成一致性。所以在Conv1和PrimaryCapsules之间没有路由。所有的路由逻辑值(bij)被初始化为0。因此,一开始一个胶囊的输出(ui)会以相同的概率(cij)传入到所有的母胶囊(v0,v1,…,v10)。作者们用TensorFlow实现了这个网络,选择了Adam优化器和TensorFlow的默认参数,包括指数衰减的学习率用来优化式4的边缘损失的总和。4.1 为了正则化效果而做的重构工作作者们使用了一个额外的重构损失,希望数字胶囊能对输入数字的实例化参数做编码。在训练过程中,作者们用掩蔽的方法只把正确的数字胶囊的激活向量保留下来。然后用这个激活向量来做重构。数字胶囊的输出会传入一个由3个全连接层组成的解码器,它的结构如图2,用来建模像素密度。作者们极小化回归单元的输出和原来图片的像素亮度之间的平方误差,并把重构误差收缩到原来的0.0005倍,这样才不会在训练过程中盖过边缘误差的作用。如图3所示,CapsNet的16维输出的重构是鲁棒的,同时也只保留了重要的细节。五、把 Capsule 用在MNIST上使用 28×28 MNIST的图片集进行训练,训练前这些图片在每个方向不留白地平移了2个像素。除此之外,没有进行其他的数据增改或者转换。在MNIST数据库中,6万张图片用于训练,另外1万张用于测试。  图3: 利用3次路由迭代学习的CapsNet对MNIST中的测试照片进行重构。(l, p, r)分别代表真实标签、模型预测和重建结果。最右两列展示的是重建失败的例子,解释了模型是如何混淆了图片中的“5”和“3”。其他列属于被正确分类了的,展示了模型可以识别图像中的细节,同时降低噪声。
图3: 利用3次路由迭代学习的CapsNet对MNIST中的测试照片进行重构。(l, p, r)分别代表真实标签、模型预测和重建结果。最右两列展示的是重建失败的例子,解释了模型是如何混淆了图片中的“5”和“3”。其他列属于被正确分类了的,展示了模型可以识别图像中的细节,同时降低噪声。 表1:CapsNet 分类MNIST数字测试准确度。结果包含了三次测试得到的平均数和标准差。测试中作者使用的是单一模型,没有进行“综合”或者明显的数据扩增方法。(Wan等人在「Regularization of neural networks using dropconnect」中通过“综合”及数据扩增实现了0.21%的错误率,而未使用这两种方法时的错误率是0.57%)作者们通过3层神经网络实现了较低的错误率(0.25%),这一错误率以往只有更深的网络才能达到。表1展现的是不同设置的CasNet在NMIST数据库上的测试错误率,表明了路由以及正则器重构的重要性。其基线是一个标准的三层神经网络(CNN),分别具有256、256及128个通道。每个通道具有5×5的卷积核,卷积步长为1。接着有两个全连接层,大小分别为328、192。最后的全连接层通过dropout连接到带有交叉熵损失的10个分类输出的softmax层。5.1 capsule的单个维度表示什么由于模型中只向DigitCaps层的胶囊传递一个数字的编码并置零其他数字,所以这些胶囊应该学会了在这个类别已经具有一个实例的基础上拓展了变化空间。这些变化包括笔画粗细、倾斜和宽度。还包括不同数字中特定的变化,如数字2尾部的长度。通过使用解码器网络可以看到单个维度表示什么。在计算正确的数字胶囊的激活向量之后,可以将这个激活向量的扰动反馈给解码器网络,并观察扰动如何影响重建。这些扰动的例子如图4所示。可以看到,胶囊的一个维度(总数为16)几乎总是代表数字的宽度。有些维度表示了全局变化的组合,而有些维度表示数字的局部变化。例如,字母6上部分的长度和下部分圈的大小使用了不同的维度。
表1:CapsNet 分类MNIST数字测试准确度。结果包含了三次测试得到的平均数和标准差。测试中作者使用的是单一模型,没有进行“综合”或者明显的数据扩增方法。(Wan等人在「Regularization of neural networks using dropconnect」中通过“综合”及数据扩增实现了0.21%的错误率,而未使用这两种方法时的错误率是0.57%)作者们通过3层神经网络实现了较低的错误率(0.25%),这一错误率以往只有更深的网络才能达到。表1展现的是不同设置的CasNet在NMIST数据库上的测试错误率,表明了路由以及正则器重构的重要性。其基线是一个标准的三层神经网络(CNN),分别具有256、256及128个通道。每个通道具有5×5的卷积核,卷积步长为1。接着有两个全连接层,大小分别为328、192。最后的全连接层通过dropout连接到带有交叉熵损失的10个分类输出的softmax层。5.1 capsule的单个维度表示什么由于模型中只向DigitCaps层的胶囊传递一个数字的编码并置零其他数字,所以这些胶囊应该学会了在这个类别已经具有一个实例的基础上拓展了变化空间。这些变化包括笔画粗细、倾斜和宽度。还包括不同数字中特定的变化,如数字2尾部的长度。通过使用解码器网络可以看到单个维度表示什么。在计算正确的数字胶囊的激活向量之后,可以将这个激活向量的扰动反馈给解码器网络,并观察扰动如何影响重建。这些扰动的例子如图4所示。可以看到,胶囊的一个维度(总数为16)几乎总是代表数字的宽度。有些维度表示了全局变化的组合,而有些维度表示数字的局部变化。例如,字母6上部分的长度和下部分圈的大小使用了不同的维度。 图4:维度扰动。每一行表示DigitCaps16个维度表示中的一个维度在[-0.25, 0.25]范围,步长0.05时的重构结果5.2 仿射变换的鲁棒性实验表明,每个DigitCaps层的胶囊都比传统卷积网络学到了每个类的更鲁棒的表示。由于手写数字的倾斜、旋转、风格等方面存在自然差异,训练好的CapsNet对训练数据小范围的仿射变换具有一定的鲁棒性。为了测试CapsNet对仿真变换的鲁棒性,作者们首先基于MNIST训练集创造了一个新的训练集,其中每个样本都是随机放在40× 40像素的黑色背景上的MNIST数字。然后用这样的训练集训练了一个CapsNet和一个传统的卷积网络(包含MaxPooling和DropOut)。然后,作者们在affNIST数据集上测试了这个网络,其中,每个样本都是一个具有随机小范围仿射变换的MNIST数字。模型并没有在任何放射变换,甚至标准MNIST自然变换的训练集合上训练过,但一个训练好的带有早期停止机制(early stop)的CapsNet,在拓展的MNIST测试集上实现了99.23%的准确度,在仿射测试集上实现了79%的准确性。具有类似参数数量的传统卷积模型在扩展的MNIST测试集上实现了类似的准确度(99.22%),在仿射测试集上却只达到了66%。六、高度重叠数字的分割动态路由可以视为平行的注意力机制,允许同层级的胶囊参与处理低层级的活动胶囊,并忽略其他胶囊。理论上允许模型识别图像中的多个对象,即使对象重叠。Hinton等人的目的是分割并识别高度重合数字对象(「 Learning to parse images,2000」中提出,其它人也在类似的领域实验过他们的网络,Goodfellow等人在「Multi-digit number recognition from street view imagery using deep convolutional neural networks,2013」中,Ba等人在「Multiple object recognition with visual attention,2014」中,Greff等人在「Tagger: Deep unsupervised perceptual grouping,2016」中)。一致性路由使利用对象的形状的先验知识帮助进行分割成为了可能,并避免在像素领域进行更高级别的细分。6.1 MultiMNIST数据集作者们通过在数字上覆盖另一个来自相同集合(训练或测试)但不同类别的数字来生成MultiMNIST训练测试数据集。每个数字在每个方向上最多移动4个像素,产生36*36像素的图像。考虑到28*28像素图像中的数字是以20*20像素的范围作为边框,两个数字的边框内范围平均有80%的重合部分。MNIST数据集中的每个数字都会生成1K MultiMNIST示例。训练集的大小为60M,测试集的大小为10M。6.2 MultiMNIST数据集上的结果作者用MultiMNIST的训练数据中重新训练得到的3层CapsNet模型,比基线卷积模型获得了更高的分类测试准确率。相较于Ba等人在「Multiple object recognition with visual attention,2014」的序列注意力模型,他们执行的是更简单的、数字交叠远远更小的任务(本文的测试数据中,两个数字的外框交叠率达到80%,而Ba等人的只有4%),而本文的模型在高度交叠的数字对中获得了与他们同样的5%的错误率。测试图片由测试集中的成对的图片构成。作者们把两个最活跃的数字胶囊看作胶囊网络产生的分类结果。在重建过程中,作者们每次选择一个数字,用它对应的数字胶囊的激活向量来重建这个数字的图像(已经知道这个图像是什么,因为作者们预先用它来生成合成的图像)。与上文MNIST测试中模型的唯一不同在于,现在把将学习率的衰减步数提高到了原来的10倍,这是因为训练数据集更大。
图4:维度扰动。每一行表示DigitCaps16个维度表示中的一个维度在[-0.25, 0.25]范围,步长0.05时的重构结果5.2 仿射变换的鲁棒性实验表明,每个DigitCaps层的胶囊都比传统卷积网络学到了每个类的更鲁棒的表示。由于手写数字的倾斜、旋转、风格等方面存在自然差异,训练好的CapsNet对训练数据小范围的仿射变换具有一定的鲁棒性。为了测试CapsNet对仿真变换的鲁棒性,作者们首先基于MNIST训练集创造了一个新的训练集,其中每个样本都是随机放在40× 40像素的黑色背景上的MNIST数字。然后用这样的训练集训练了一个CapsNet和一个传统的卷积网络(包含MaxPooling和DropOut)。然后,作者们在affNIST数据集上测试了这个网络,其中,每个样本都是一个具有随机小范围仿射变换的MNIST数字。模型并没有在任何放射变换,甚至标准MNIST自然变换的训练集合上训练过,但一个训练好的带有早期停止机制(early stop)的CapsNet,在拓展的MNIST测试集上实现了99.23%的准确度,在仿射测试集上实现了79%的准确性。具有类似参数数量的传统卷积模型在扩展的MNIST测试集上实现了类似的准确度(99.22%),在仿射测试集上却只达到了66%。六、高度重叠数字的分割动态路由可以视为平行的注意力机制,允许同层级的胶囊参与处理低层级的活动胶囊,并忽略其他胶囊。理论上允许模型识别图像中的多个对象,即使对象重叠。Hinton等人的目的是分割并识别高度重合数字对象(「 Learning to parse images,2000」中提出,其它人也在类似的领域实验过他们的网络,Goodfellow等人在「Multi-digit number recognition from street view imagery using deep convolutional neural networks,2013」中,Ba等人在「Multiple object recognition with visual attention,2014」中,Greff等人在「Tagger: Deep unsupervised perceptual grouping,2016」中)。一致性路由使利用对象的形状的先验知识帮助进行分割成为了可能,并避免在像素领域进行更高级别的细分。6.1 MultiMNIST数据集作者们通过在数字上覆盖另一个来自相同集合(训练或测试)但不同类别的数字来生成MultiMNIST训练测试数据集。每个数字在每个方向上最多移动4个像素,产生36*36像素的图像。考虑到28*28像素图像中的数字是以20*20像素的范围作为边框,两个数字的边框内范围平均有80%的重合部分。MNIST数据集中的每个数字都会生成1K MultiMNIST示例。训练集的大小为60M,测试集的大小为10M。6.2 MultiMNIST数据集上的结果作者用MultiMNIST的训练数据中重新训练得到的3层CapsNet模型,比基线卷积模型获得了更高的分类测试准确率。相较于Ba等人在「Multiple object recognition with visual attention,2014」的序列注意力模型,他们执行的是更简单的、数字交叠远远更小的任务(本文的测试数据中,两个数字的外框交叠率达到80%,而Ba等人的只有4%),而本文的模型在高度交叠的数字对中获得了与他们同样的5%的错误率。测试图片由测试集中的成对的图片构成。作者们把两个最活跃的数字胶囊看作胶囊网络产生的分类结果。在重建过程中,作者们每次选择一个数字,用它对应的数字胶囊的激活向量来重建这个数字的图像(已经知道这个图像是什么,因为作者们预先用它来生成合成的图像)。与上文MNIST测试中模型的唯一不同在于,现在把将学习率的衰减步数提高到了原来的10倍,这是因为训练数据集更大。 图5:一个经3次路由迭代的CapsNet在MultiMNIST测试数据集上的样本重建结果如图中靠下的图像所示,两个重建出的互相交叠的数字分别显示为绿色和红色的。靠上的图显示的是输入的图像。表示图像中两个数字的标签;表示用于重建的两个数字。最右边的两列显示了从标签和从预测重建的两个错误分类样例。在例子中,模型将8错判成7;在的例子中,模型将9错判成0。其他的列都分类正确并且显示了模型不仅仅考虑了所有的像素同时能够在非常困难的场景下将一个像素分配给两个数字(1-4列)。值得说明的是,在数据集产生的过程中,像素的值都会被剪裁到1以内。两个含“*”的列显示了重建的数字既不是标签值也不是预测值。这些列显示模型不仅仅找到了所有存在的数字的最佳匹配,甚至还考虑了图像中不存在的数字。所以在的例子中,模型并不能重建数字7,是因为模型知道数字对5和0是最佳匹配,而且也已经用到了所有的像素。的例子也是类似的,数字8的环并没有触发为0的判断,因为该数字已经被当做8了。因此,如果两个数字都没有其他额外的支持的话,模型并不会将一个像素分配给这两个数字。图5中的重构表明,CapsNet 能够把图片分割成两个原来的数字。因为这一分割并非是直接的像素分割,所以可以观察到,模型可以准确处理重叠的部分(即一个像素同时出现在多个数字上),同时也利用到所有像素。每个数字的位置和风格在DigitCaps中都得到了编码。给定一个被编码数字,解码器也学会了去重构这一数字。解码器能够无视重叠进行重构的特性表明,每个数字胶囊都能从PrimaryCapsules层接收到的不同激活向量来获取位置和风格。表1 也着重表现了这一任务中胶囊之间路由的重要性。作为CapsNet分类器准确率的对比基线,作者们一开始先训练了带有两层卷积层和两层全连接层的卷积神经网络。 第一层有512个大小为9*9的卷积核,步长为1;第二层有256个大小为5*5的卷积核,步长为1。在每个卷积层后,模型都连接了一个2*2大小,步长2的池化层。 第三层是一个1024维的全连接层。所有的这三层都有ReLU非线性处理。 最后10个单元的层也是全连接。 我们用TF默认的Adam优化器来训练最后输出层的Sigmoid交叉熵损失。 这一模型有24.56M参数,是CapsNet的11.36M参数的两倍多。作者们从一个小点的CNN(32和64个大小为5*5的卷积核,步幅为1,以及一个512维的全连接层)开始,然后逐渐增大网络的宽度,直到他们在MultiMNIST的10K子集上达到最好的测试精度。他们也在10K的验证集上搜索了正确的学习率衰减步数。作者们一次解码了两个最活跃的DigitCaps胶囊,得到了两张图片。然后把所有非零的像素分配给不同的数字,就得到了每个数字的分割结果。七、其它数据集作者们在 CIFAR10 的数据及上测试了胶囊模型,在用了不同的超参和7个模型集成(其中每个模型都通过图像中24x24的小块进行三次路由迭代)后得到10.6%的错误率。这里的图片都是三个颜色通道的,作者们一共用了64种不同的 primary capsule,除此之外每个模型都和在 MNIST 数据集中用的一模一样。作者们还发现胶囊能够帮助路由softmax增加一个“以上皆非”的分类种类,因为不能指望10个 capsules 的最后一层就能够解释图片里的一切信息。在测试集上有 10.6% 的错误率差不多也是标准的卷积网络初次应用到 CIFAR10 上能达到的效果。和生成模型一个一样的缺点是,Capsules 倾向于解释图片中的一切。所以当能够对杂乱的背景建模时,它比在动态路由中只用一个额外的类别来的效果好。在 CIFAR-10 中,背景对大小固定的模型来说变化太大,因此模型表现也不好。作者们还用了和 MNIST 中一样的模型测试了 smallNORB 数据集,可以得到目前最好的 的 2.7% 的错误率。smallNORB 数据集由 96×96的双通道灰度图组成。作者们把图片缩放到 48×48 像素,并且在训练时从中随机裁剪 32×32 的大小。而在测试时,直接取中间 32×32 的部分。作者们还在 SVHN 的 73257 张图片的小训练集上训练了一个小型网络。我们把第一个卷积层的通道数减少到 64个,primary capsule 层为 16 个 6维胶囊,最后一个胶囊层为8维的。最后测试集错误率为 4.3%.八、讨论以及以往工作30年来, 语音识别的最新进展使用了以高斯混合作为输出分布的隐马尔可夫模型。这些模型虽然易于在一些计算机上学习,但是存在一个致命的缺陷:他们使用的“n种中的某一种”的表示方法的效率是呈指数下降的,分布式递归神经网络的效率就比这种方法高得多。为了使隐马尔可夫模型能够记住的迄今它所生成字符的信息倍增,需要使用的隐藏节点数目需要增加到原来的平方。而对于循环神经网络来说,只需要两倍的隐藏神经元的数量即可。现在卷积神经网络已经成为物体识别的主流方法,理所当然要问是其中是否也会有效率的指数下降,从而引发这种方法的式微。一个可能性是卷积网络在新类别上泛化能力的困难度。卷积网络中处理平移变换的能力是内置的,但对于仿射变换的其他维度就必须进行选择,要么在网格中复制特征检测器,网格的大小随着维度数目指数增长,要么同样以指数方式增加的标注训练集的大小。胶囊通过将像素强度转换为识别到的片段中的实例化参数向量,然后将变换矩阵应用于片段,以预测更大的片段的实例化参数,从而避免了效率的指数下降。学到了部分和整体之间固有的空间关系的转换矩阵构成了具有视角不变性的知识,从而可以自动泛化到的视角中。胶囊使得我们可以做出一个非常具有表征意义的假设:在图像的每一个位置,至多只有一个胶囊所表征的实体的实例。这种假设是由一种称为“crowding”(Pelli等人「Crowding is unlike ordinary masking: Distinguishing feature integration from detection,2004」) 的感知现象驱动的,它消除了绑定问题,并允许一个胶囊使用分布式表示(它的激活向量)来对给定位置的该类型实体的实例化参数进行编码。这种分布式表示比通过在高维网格上激活一个点来编码实例化参数的效率要高得多,并且通过正确的分布式表示,胶囊可以充分利用空间关系可以由矩阵乘法来建模的特点。胶囊中采用的神经活动会随着视角的变化而变化,而不是试图消除神经活动中视角变化带来的影响。这使它们比“归一化”法(如Jaderberg等「Spatial transformer networks,2015」)更具有优势:它们可以同时处理多个不同仿射变换或不同对象的不同部件。胶囊同时也非常擅长处理图像分割这样的另一种视觉上最困难的问题之一,因为实例化参数的矢量允许它们使用在本文中演示的那样的一致性路由。对胶囊的研究目前正处于一个与本世纪初研究用于语音识别的递归神经网络类似的阶段。根据基础表征性的特点,已经有理由相信这是一种更好的方法,但它可能需要一些更多的在细节上的洞察力才能把它变成一种可以投入应用的高度发达的技术。一个简单的胶囊系统已经在分割数字图像上提供了无与伦比的表现,这表明了胶囊是一个值得探索的方向。
图5:一个经3次路由迭代的CapsNet在MultiMNIST测试数据集上的样本重建结果如图中靠下的图像所示,两个重建出的互相交叠的数字分别显示为绿色和红色的。靠上的图显示的是输入的图像。表示图像中两个数字的标签;表示用于重建的两个数字。最右边的两列显示了从标签和从预测重建的两个错误分类样例。在例子中,模型将8错判成7;在的例子中,模型将9错判成0。其他的列都分类正确并且显示了模型不仅仅考虑了所有的像素同时能够在非常困难的场景下将一个像素分配给两个数字(1-4列)。值得说明的是,在数据集产生的过程中,像素的值都会被剪裁到1以内。两个含“*”的列显示了重建的数字既不是标签值也不是预测值。这些列显示模型不仅仅找到了所有存在的数字的最佳匹配,甚至还考虑了图像中不存在的数字。所以在的例子中,模型并不能重建数字7,是因为模型知道数字对5和0是最佳匹配,而且也已经用到了所有的像素。的例子也是类似的,数字8的环并没有触发为0的判断,因为该数字已经被当做8了。因此,如果两个数字都没有其他额外的支持的话,模型并不会将一个像素分配给这两个数字。图5中的重构表明,CapsNet 能够把图片分割成两个原来的数字。因为这一分割并非是直接的像素分割,所以可以观察到,模型可以准确处理重叠的部分(即一个像素同时出现在多个数字上),同时也利用到所有像素。每个数字的位置和风格在DigitCaps中都得到了编码。给定一个被编码数字,解码器也学会了去重构这一数字。解码器能够无视重叠进行重构的特性表明,每个数字胶囊都能从PrimaryCapsules层接收到的不同激活向量来获取位置和风格。表1 也着重表现了这一任务中胶囊之间路由的重要性。作为CapsNet分类器准确率的对比基线,作者们一开始先训练了带有两层卷积层和两层全连接层的卷积神经网络。 第一层有512个大小为9*9的卷积核,步长为1;第二层有256个大小为5*5的卷积核,步长为1。在每个卷积层后,模型都连接了一个2*2大小,步长2的池化层。 第三层是一个1024维的全连接层。所有的这三层都有ReLU非线性处理。 最后10个单元的层也是全连接。 我们用TF默认的Adam优化器来训练最后输出层的Sigmoid交叉熵损失。 这一模型有24.56M参数,是CapsNet的11.36M参数的两倍多。作者们从一个小点的CNN(32和64个大小为5*5的卷积核,步幅为1,以及一个512维的全连接层)开始,然后逐渐增大网络的宽度,直到他们在MultiMNIST的10K子集上达到最好的测试精度。他们也在10K的验证集上搜索了正确的学习率衰减步数。作者们一次解码了两个最活跃的DigitCaps胶囊,得到了两张图片。然后把所有非零的像素分配给不同的数字,就得到了每个数字的分割结果。七、其它数据集作者们在 CIFAR10 的数据及上测试了胶囊模型,在用了不同的超参和7个模型集成(其中每个模型都通过图像中24x24的小块进行三次路由迭代)后得到10.6%的错误率。这里的图片都是三个颜色通道的,作者们一共用了64种不同的 primary capsule,除此之外每个模型都和在 MNIST 数据集中用的一模一样。作者们还发现胶囊能够帮助路由softmax增加一个“以上皆非”的分类种类,因为不能指望10个 capsules 的最后一层就能够解释图片里的一切信息。在测试集上有 10.6% 的错误率差不多也是标准的卷积网络初次应用到 CIFAR10 上能达到的效果。和生成模型一个一样的缺点是,Capsules 倾向于解释图片中的一切。所以当能够对杂乱的背景建模时,它比在动态路由中只用一个额外的类别来的效果好。在 CIFAR-10 中,背景对大小固定的模型来说变化太大,因此模型表现也不好。作者们还用了和 MNIST 中一样的模型测试了 smallNORB 数据集,可以得到目前最好的 的 2.7% 的错误率。smallNORB 数据集由 96×96的双通道灰度图组成。作者们把图片缩放到 48×48 像素,并且在训练时从中随机裁剪 32×32 的大小。而在测试时,直接取中间 32×32 的部分。作者们还在 SVHN 的 73257 张图片的小训练集上训练了一个小型网络。我们把第一个卷积层的通道数减少到 64个,primary capsule 层为 16 个 6维胶囊,最后一个胶囊层为8维的。最后测试集错误率为 4.3%.八、讨论以及以往工作30年来, 语音识别的最新进展使用了以高斯混合作为输出分布的隐马尔可夫模型。这些模型虽然易于在一些计算机上学习,但是存在一个致命的缺陷:他们使用的“n种中的某一种”的表示方法的效率是呈指数下降的,分布式递归神经网络的效率就比这种方法高得多。为了使隐马尔可夫模型能够记住的迄今它所生成字符的信息倍增,需要使用的隐藏节点数目需要增加到原来的平方。而对于循环神经网络来说,只需要两倍的隐藏神经元的数量即可。现在卷积神经网络已经成为物体识别的主流方法,理所当然要问是其中是否也会有效率的指数下降,从而引发这种方法的式微。一个可能性是卷积网络在新类别上泛化能力的困难度。卷积网络中处理平移变换的能力是内置的,但对于仿射变换的其他维度就必须进行选择,要么在网格中复制特征检测器,网格的大小随着维度数目指数增长,要么同样以指数方式增加的标注训练集的大小。胶囊通过将像素强度转换为识别到的片段中的实例化参数向量,然后将变换矩阵应用于片段,以预测更大的片段的实例化参数,从而避免了效率的指数下降。学到了部分和整体之间固有的空间关系的转换矩阵构成了具有视角不变性的知识,从而可以自动泛化到的视角中。胶囊使得我们可以做出一个非常具有表征意义的假设:在图像的每一个位置,至多只有一个胶囊所表征的实体的实例。这种假设是由一种称为“crowding”(Pelli等人「Crowding is unlike ordinary masking: Distinguishing feature integration from detection,2004」) 的感知现象驱动的,它消除了绑定问题,并允许一个胶囊使用分布式表示(它的激活向量)来对给定位置的该类型实体的实例化参数进行编码。这种分布式表示比通过在高维网格上激活一个点来编码实例化参数的效率要高得多,并且通过正确的分布式表示,胶囊可以充分利用空间关系可以由矩阵乘法来建模的特点。胶囊中采用的神经活动会随着视角的变化而变化,而不是试图消除神经活动中视角变化带来的影响。这使它们比“归一化”法(如Jaderberg等「Spatial transformer networks,2015」)更具有优势:它们可以同时处理多个不同仿射变换或不同对象的不同部件。胶囊同时也非常擅长处理图像分割这样的另一种视觉上最困难的问题之一,因为实例化参数的矢量允许它们使用在本文中演示的那样的一致性路由。对胶囊的研究目前正处于一个与本世纪初研究用于语音识别的递归神经网络类似的阶段。根据基础表征性的特点,已经有理由相信这是一种更好的方法,但它可能需要一些更多的在细节上的洞察力才能把它变成一种可以投入应用的高度发达的技术。一个简单的胶囊系统已经在分割数字图像上提供了无与伦比的表现,这表明了胶囊是一个值得探索的方向。
番外材料
- https://www.guokr.com/post/344980/
第一课 什么是卷积 卷积有什么用 什么是傅利叶变换 什么是拉普拉斯变换
引子
很多朋友和我一样,工科电子类专业,学了一堆信号方面的课,什么都没学懂,背了公式考了试,然后毕业了。
先说”卷积有什么用”这个问题。(有人抢答,”卷积”是为了学习”信号与系统”这门课的后续章节而存在的。我大吼一声,把他拖出去枪毙!)
讲一个故事:
张三刚刚应聘到了一个电子产品公司做测试人员,他没有学过”信号与系统”这门课程。一天,他拿到了一个产品,开发人员告诉他,产品有一个输入端,有一个输出端,有限的输入信号只会产生有限的输出。
然后,经理让张三测试当输入sin(t)(t<1秒)信号的时候(有信号发生器),该产品输出什么样的波形。张三照做了,花了一个波形图。
“很好!”经理说。然后经理给了张三一叠A4纸: “这里有几千种信号,都用公式说明了,输入信号的持续时间也是确定的。你分别测试以下我们产品的输出波形是什么吧!”
这下张三懵了,他在心理想”上帝,帮帮我把,我怎么画出这些波形图呢?”
于是上帝出现了: “张三,你只要做一次测试,就能用数学的方法,画出所有输入波形对应的输出波形”。
上帝接着说:”给产品一个脉冲信号,能量是1焦耳,输出的波形图画出来!”
张三照办了,”然后呢?”
上帝又说,”对于某个输入波形,你想象把它微分成无数个小的脉冲,输入给产品,叠加出来的结果就是你的输出波形。你可以想象这些小脉冲排着队进入你的产品,每个产生一个小的输出,你画出时序图的时候,输入信号的波形好像是反过来进入系统的。”
张三领悟了:” 哦,输出的结果就积分出来啦!感谢上帝。这个方法叫什么名字呢?”
上帝说:”叫卷积!”
从此,张三的工作轻松多了。每次经理让他测试一些信号的输出结果,张三都只需要在A4纸上做微积分就是提交任务了!
张三愉快地工作着,直到有一天,平静的生活被打破。
经理拿来了一个小的电子设备,接到示波器上面,对张三说: “看,这个小设备产生的波形根本没法用一个简单的函数来说明,而且,它连续不断的发出信号!不过幸好,这个连续信号是每隔一段时间就重复一次的。张三,你 来测试以下,连到我们的设备上,会产生什么输出波形!”
张三摆摆手:”输入信号是无限时长的,难道我要测试无限长的时间才能得到一个稳定的,重复的波形输出吗?”
经理怒了:”反正你给我搞定,否则炒鱿鱼!”
张三心想:”这次输入信号连公式都给出出来,一个很混乱的波形;时间又是无限长的,卷积也不行了,怎么办呢?”
及时地,上帝又出现了:”把混乱的时间域信号映射到另外一个数学域上面,计算完成以后再映射回来”
“宇宙的每一个原子都在旋转和震荡,你可以把时间信号看成若干个震荡叠加的效果,也就是若干个可以确定的,有固定频率特性的东西。”
“我给你一个数学函数f,时间域无限的输入信号在f域有限的。时间域波形混乱的输入信号在f域是整齐的容易看清楚的。这样你就可以计算了”
“同时,时间域的卷积在f域是简单的相乘关系,我可以证明给你看看”
“计算完有限的程序以后,取f(-1)反变换回时间域,你就得到了一个输出波形,剩下的就是你的数学计算了!”
张三谢过了上帝,保住了他的工作。后来他知道了,f域的变换有一个名字,叫做傅利叶,什么什么… …
再后来,公司开发了一种新的电子产品,输出信号是无限时间长度的。这次,张三开始学拉普拉斯了……
后记:
不是我们学的不好,是因为教材不好,老师讲的也不好。
很欣赏Google的面试题: 用3句话像老太太讲清楚什么是数据库。这样的命题非常好,因为没有深入的理解一个命题,没有仔细的思考一个东西的设计哲学,我们就会陷入细节的泥沼: 背公式,数学推导,积分,做题;而没有时间来回答”为什么要这样”。做大学老师的做不到”把厚书读薄”这一点,讲不出哲学层面的道理,一味背书和翻讲 ppt,做着枯燥的数学证明,然后责怪”现在的学生一代不如一代”,有什么意义吗?
第二课 到底什么是频率 什么是系统?
这一篇,我展开的说一下傅立叶变换F。注意,傅立叶变换的名字F可以表示频率的概念(freqence),也可以包括其他任何概念,因为它只是一个概念模 型,为了解决计算的问题而构造出来的(例如时域无限长的输入信号,怎么得到输出信号)。我们把傅立叶变换看一个C语言的函数,信号的输出输出问题看为IO 的问题,然后任何难以求解的x->y的问题都可以用x->f(x)->f-1(x)->y来得到。
到底什么是频率?
一个基本的假设: 任何信息都具有频率方面的特性,音频信号的声音高低,光的频谱,电子震荡的周期,等等,我们抽象出一个件谐振动的概念,数学名称就叫做频率。想象在x-y 平面上有一个原子围绕原点做半径为1匀速圆周运动,把x轴想象成时间,那么该圆周运动在y轴上的投影就是一个sin(t)的波形。相信中学生都能理解这 个。
那么,不同的频率模型其实就对应了不同的圆周运动速度。圆周运动的速度越快,sin(t)的波形越窄。频率的缩放有两种模式
(a) 老式的收音机都是用磁带作为音乐介质的,当我们快放的时候,我们会感觉歌唱的声音变得怪怪的,调子很高,那是因为”圆周运动”的速度增倍了,每一个声音分量的sin(t)输出变成了sin(nt)。
(b) 在CD/计算机上面快放或满放感觉歌手快唱或者慢唱,不会出现音调变高的现象:因为快放的时候采用了时域采样的方法,丢弃了一些波形,但是承载了信息的输出波形不会有宽窄的变化;满放时相反,时域信号填充拉长就可以了。F变换得到的结果有负数/复数部分,有什么物理意义吗?
解释: F变换是个数学工具,不具有直接的物理意义,负数/复数的存在只是为了计算的完整性。信号与系统这们课的基本主旨是什么?
对于通信和电子类的学生来说,很多情况下我们的工作是设计或者OSI七层模型当中的物理层技术,这种技术的复杂性首先在于你必须确立传输介质的电气特 性,通常不同传输介质对于不同频率段的信号有不同的处理能力。以太网线处理基带信号,广域网光线传出高频调制信号,移动通信,2G和3G分别需要有不同的 载频特性。那么这些介质(空气,电线,光纤等)对于某种频率的输入是否能够在传输了一定的距离之后得到基本不变的输入呢? 那么我们就要建立介质的频率相应数学模型。同时,知道了介质的频率特性,如何设计在它上面传输的信号才能大到理论上的最大传输速率?—-这就是信号与 系统这们课带领我们进入的一个世界。
当然,信号与系统的应用不止这些,和香农的信息理论挂钩,它还可以用于信息处理(声音,图像),模式识别,智能控制等领域。如果说,计算机专业的课程是 数据表达的逻辑模型,那么信号与系统建立的就是更底层的,代表了某种物理意义的数学模型。数据结构的知识能解决逻辑信息的编码和纠错,而信号的知识能帮我 们设计出码流的物理载体(如果接受到的信号波形是混乱的,那我依据什么来判断这个是1还是0? 逻辑上的纠错就失去了意义)。在工业控制领域,计算机的应用前提是各种数模转换,那么各种物理现象产生的连续模拟信号(温度,电阻,大小,压力,速度等) 如何被一个特定设备转换为有意义的数字信号,首先我们就要设计一个可用的数学转换模型。如何设计系统?
设计物理上的系统函数(连续的或离散的状态),有输入,有输出,而中间的处理过程和具体的物理实现相关,不是这们课关心的重点(电子电路设计?)。信号 与系统归根到底就是为了特定的需求来设计一个系统函数。设计出系统函数的前提是把输入和输出都用函数来表示(例如sin(t))。分析的方法就是把一个复 杂的信号分解为若干个简单的信号累加,具体的过程就是一大堆微积分的东西,具体的数学运算不是这门课的中心思想。
那么系统有那些种类呢?
(a) 按功能分类: 调制解调(信号抽样和重构),叠加,滤波,功放,相位调整,信号时钟同步,负反馈锁相环,以及若干子系统组成的一个更为复杂的系统—-你可以画出系统 流程图,是不是很接近编写程序的逻辑流程图? 确实在符号的空间里它们没有区别。还有就是离散状态的数字信号处理(后续课程)。
(b) 按系统类别划分,无状态系统,有限状态机,线性系统等。而物理层的连续系统函数,是一种复杂的线性系统。最好的教材?
符号系统的核心是集合论,不是微积分,没有集合论构造出来的系统,实现用到的微积分便毫无意义—-你甚至不知道运算了半天到底是要作什么。以计算机的观点来学习信号与系统,最好的教材之一就是<>, 作者是UC Berkeley的Edward A.Lee and Pravin Varaiya—-先定义再实现,符合人类的思维习惯。国内的教材通篇都是数学推导,就是不肯说这些推导是为了什么目的来做的,用来得到什么,建设什 么,防止什么;不去从认识论和需求上讨论,通篇都是看不出目的的方法论,本末倒置了。
第三课 抽样定理是干什么的
- 举个例子,打电话的时候,电话机发出的信号是PAM脉冲调幅,在电话线路上传的不是话音,而是话音通过信道编码转换后的脉冲序列,在收端恢复语音波形。那 么对于连续的说话人语音信号,如何转化成为一些列脉冲才能保证基本不失真,可以传输呢? 很明显,我们想到的就是取样,每隔M毫秒对话音采样一次看看电信号振幅,把振幅转换为脉冲编码,传输出去,在收端按某种规则重新生成语言。
那么,问题来了,每M毫秒采样一次,M多小是足够的? 在收端怎么才能恢复语言波形呢?
对于第一个问题,我们考虑,语音信号是个时间频率信号(所以对应的F变换就表示时间频率)把语音信号分解为若干个不同频率的单音混合体(周期函数的复利叶 级数展开,非周期的区间函数,可以看成补齐以后的周期信号展开,效果一样),对于最高频率的信号分量,如果抽样方式能否保证恢复这个分量,那么其他的低频 率分量也就能通过抽样的方式使得信息得以保存。如果人的声音高频限制在3000Hz,那么高频分量我们看成sin(3000t),这个sin函数要通过抽 样保存信息,可以看为: 对于一个周期,波峰采样一次,波谷采样一次,也就是采样频率是最高频率分量的2倍(奈奎斯特抽样定理),我们就可以通过采样信号无损的表示原始的模拟连续 信号。这两个信号一一对应,互相等价。
对于第二个问题,在收端,怎么从脉冲序列(梳装波形)恢复模拟的连续信号呢? 首先,我们已经肯定了在频率域上面的脉冲序列已经包含了全部信息,但是原始信息只在某一个频率以下存在,怎么做? 我们让输入脉冲信号I通过一个设备X,输出信号为原始的语音O,那么I()X=O,这里()表示卷积。时域的特性不好分析,那么在频率域 F(I)*F(X)=F(O)相乘关系,这下就很明显了,只要F(X)是一个理想的,低通滤波器就可以了(在F域画出来就是一个方框),它在时间域是一个 钟型函数(由于包含时间轴的负数部分,所以实际中不存在),做出这样的一个信号处理设备,我们就可以通过输入的脉冲序列得到几乎理想的原始的语音。在实际 应用中,我们的抽样频率通常是奈奎斯特频率再多一点,3k赫兹的语音信号,抽样标准是8k赫兹。 - 再举一个例子,对于数字图像,抽样定理对应于图片的分辨率—-抽样密度越大,图片的分辨率越高,也就越清晰。如果我们的抽样频率不够,信息就会发生混 叠—-网上有一幅图片,近视眼戴眼镜看到的是爱因斯坦,摘掉眼睛看到的是梦露—-因为不带眼睛,分辨率不够(抽样频率太低),高频分量失真被混入 了低频分量,才造成了一个视觉陷阱。在这里,图像的F变化,对应的是空间频率。
话说回来了,直接在信道上传原始语音信号不好吗? 模拟信号没有抗干扰能力,没有纠错能力,抽样得到的信号,有了数字特性,传输性能更佳。
什么信号不能理想抽样? 时域有跳变,频域无穷宽,例如方波信号。如果用有限带宽的抽样信号表示它,相当于复利叶级数取了部分和,而这个部分和在恢复原始信号的时候,在不可导的点上面会有毛刺,也叫吉布斯现象。 - 为什么傅立叶想出了这么一个级数来? 这个源于西方哲学和科学的基本思想: 正交分析方法。例如研究一个立体形状,我们使用x,y,z三个互相正交的轴: 任何一个轴在其他轴上面的投影都是0。这样的话,一个物体的3视图就可以完全表达它的形状。同理,信号怎么分解和分析呢? 用互相正交的三角函数分量的无限和:这就是傅立叶的贡献。
入门第四课 傅立叶变换的复数 小波
说的广义一点,”复数”是一个”概念”,不是一种客观存在。
什么是”概念”? 一张纸有几个面? 两个,这里”面”是一个概念,一个主观对客观存在的认知,就像”大”和”小”的概念一样,只对人的意识有意义,对客观存在本身没有意义(康德: 纯粹理性的批判)。把纸条的两边转一下相连接,变成”莫比乌斯圈”,这个纸条就只剩下一个”面”了。概念是对客观世界的加工,反映到意识中的东西。
数的概念是这样被推广的: 什么数x使得x^2=-1? 实数轴显然不行,(-1)(-1)=1。那么如果存在一个抽象空间,它既包括真实世界的实数,也能包括想象出来的x^2=-1,那么我们称这个想象空间 为”复数域”。那么实数的运算法则就是复数域的一个特例。为什么1(-1)=-1? +-符号在复数域里面代表方向,-1就是”向后,转!”这样的命令,一个1在圆周运动180度以后变成了-1,这里,直线的数轴和圆周旋转,在复数的空间 里面被统一了。
因此,(-1)*(-1)=1可以解释为”向后转”+”向后转”=回到原地。那么复数域如何表示x^2=-1呢? 很简单,”向左转”,”向左转”两次相当于”向后转”。由于单轴的实数域(直线)不包含这样的元素,所以复数域必须由两个正交的数轴表示–平面。很明 显,我们可以得到复数域乘法的一个特性,就是结果的绝对值为两个复数绝对值相乘,旋转的角度=两个复数的旋转角度相加。高中时代我们就学习了迪莫弗定理。 为什么有这样的乘法性质? 不是因为复数域恰好具有这样的乘法性质(性质决定认识),而是发明复数域的人就是根据这样的需求去弄出了这么一个复数域(认识决定性质),是一种主观唯心 主义的研究方法。为了构造x^2=-1,我们必须考虑把乘法看为两个元素构成的集合: 乘积和角度旋转。
因为三角函数可以看为圆周运动的一种投影,所以,在复数域,三角函数和乘法运算(指数)被统一了。我们从实数域的傅立叶级数展开入手,立刻可以得到形式更 简单的,复数域的,和实数域一一对应的傅立叶复数级数。因为复数域形式简单,所以研究起来方便—-虽然自然界不存在复数,但是由于和实数域的级数一一 对应,我们做个反映射就能得到有物理意义的结果。
那么傅立叶变换,那个令人难以理解的转换公式是什么含义呢? 我们可以看一下它和复数域傅立叶级数的关系。什么是微积分,就是先微分,再积分,傅立叶级数已经作了无限微分了,对应无数个离散的频率分量冲击信号的和。 傅立叶变换要解决非周期信号的分析问题,想象这个非周期信号也是一个周期信号: 只是周期为无穷大,各频率分量无穷小而已(否则积分的结果就是无穷)。那么我们看到傅立叶级数,每个分量常数的求解过程,积分的区间就是从T变成了正负无 穷大。而由于每个频率分量的常数无穷小,那么让每个分量都去除以f,就得到有值的数—-所以周期函数的傅立叶变换对应一堆脉冲函数。同理,各个频率分 量之间无限的接近,因为f很小,级数中的f,2f,3f之间几乎是挨着的,最后挨到了一起,和卷积一样,这个复数频率空间的级数求和最终可以变成一个积分 式:傅立叶级数变成了傅立叶变换。注意有个概念的变化:离散的频率,每个频率都有一个”权”值,而连续的F域,每个频率的加权值都是无穷小(面积=0), 只有一个频率范围内的”频谱”才对应一定的能量积分。频率点变成了频谱的线。
因此傅立叶变换求出来的是一个通常是一个连续函数,是复数频率域上面的可以画出图像的东西? 那个根号2Pai又是什么? 它只是为了保证正变换反变换回来以后,信号不变。我们可以让正变换除以2,让反变换除以Pi,怎么都行。慢点,怎么有”负数”的部分,还是那句话,是数轴 的方向对应复数轴的旋转,或者对应三角函数的相位分量,这样说就很好理解了。有什么好处? 我们忽略相位,只研究”振幅”因素,就能看到实数频率域内的频率特性了。
我们从实数(三角函数分解)->复数(e和Pi)->复数变换(F)->复数反变换(F-1)->复数(取幅度分量)-> 实数,看起来很复杂,但是这个工具使得,单从实数域无法解决的频率分析问题,变得可以解决了。两者之间的关系是: 傅立叶级数中的频率幅度分量是a1-an,b1-bn,这些离散的数表示频率特性,每个数都是积分的结果。而傅立叶变换的结果是一个连续函数: 对于f域每个取值点a1-aN(N=无穷),它的值都是原始的时域函数和一个三角函数(表示成了复数)积分的结果—-这个求解和级数的表示形式是一样 的。不过是把N个离散的积分式子统一为了一个通用的,连续的积分式子。
复频域,大家都说画不出来,但是我来画一下!因为不是一个图能够表示清楚的。我用纯中文来说:
1. 画一个x,y轴组成的平面,以原点为中心画一个圆(r=1)。再画一条竖直线: (直线方程x=2),把它看成是一块挡板。
2. 想象,有一个原子,从(1,0)点出发,沿着这个圆作逆时针匀速圆周运动。想象太阳光从x轴的复数方向射向x轴的正数方向,那么这个原子运动在挡板(x=2)上面的投影,就是一个简协震动。
3. 再修改一下,x=2对应的不是一个挡板,而是一个打印机的出纸口,那么,原子运动的过程就在白纸上画下了一条连续的sin(t)曲线!
上面3条说明了什么呢? 三角函数和圆周运动是一一对应的。如果我想要sin(t+x),或者cos(t)这种形式,我只需要让原子的起始位置改变一下就可以了:也就是级坐标的向量,半径不变,相位改变。
傅立叶级数的实数展开形式,每一个频率分量都表示为AnCos(nt)+BnSin(nt),我们可以证明,这个式子可以变成 sqr(An^2+Bn^2)sin(nt+x)这样的单个三角函数形式,那么:实数值对(An,Bn),就对应了二维平面上面的一个点,相位x对应这个 点的相位。实数和复数之间的一一对应关系便建立起来了,因此实数频率唯一对应某个复数频率,我们就可以用复数来方便的研究实数的运算:把三角运算变成指数 和乘法加法运算。
但是,F变换仍然是有限制的(输入函数的表示必须满足狄义赫立条件等),为了更广泛的使用”域”变换的思想来表示一种”广义”的频率信息,我们就发明出了 拉普拉斯变换,它的连续形式对应F变换,离散形式就成了Z变换。离散信号呢? 离散周期函数的F级数,项数有限,离散非周期函数(看为周期延拓以后仍然是离散周期函数),离散F级数,仍然项数有限。离散的F变换,很容易理解—- 连续信号通过一个周期采样滤波器,也就是频率域和一堆脉冲相乘。时域取样对应频域周期延拓。为什么? 反过来容易理解了,时域的周期延拓对应频率域的一堆脉冲。
两者的区别:FT=从负无穷到正无穷对积分 LT=从零到正无穷对积分 (由于实际应用,通常只做单边Laplace变换,即积分从零开始) 具体地,在Fourier积分变换中,所乘因子为exp(-jwt),此处,-jwt显然是为一纯虚数;而在laplace变换中,所乘因子为 exp(-st),其中s为一复数:s=D+jw,jw是为虚部,相当于Fourier变换中的jwt,而D则是实部,作为衰减因子,这样就能将许多无法 作Fourier变换的函数(比如exp(at),a>0)做域变换。
而Z变换,简单地说,就是离散信号(也可以叫做序列)的Laplace变换,可由抽样信号的Laplace变换导出。ZT=从n为负无穷到正无穷对求和。 Z域的物理意义: 由于值被离散了,所以输入输出的过程和花费的物理时间已经没有了必然的关系(t只对连续信号有意义),所以频域的考察变得及其简单起来,我们把 (1,-1,1,-1,1,-1)这样的基本序列看成是数字频率最高的序列,他的数字频率是1Hz(数字角频率2Pi),其他的数字序列频率都是N分之 1Hz,频率分解的结果就是0-2Pi角频率当中的若干个值的集合,也是一堆离散的数。由于时频都是离散的,所以在做变换的时候,不需要写出冲击函数的因 子
离散傅立叶变换到快速傅立叶变换—-由于离散傅立叶变换的次数是O(N^2),于是我们考虑把离散序列分解成两两一组进行离散傅立叶变换,变换的计算复杂度就下降到了O(NlogN),再把计算的结果累加O(N),这就大大降低了计算复杂度。
再说一个高级话题: 小波。在实际的工程应用中,前面所说的这些变换大部分都已经被小波变换代替了。
什么是小波?先说什么是波:傅立叶级数里面的分量,sin/cos函数就是波,sin(t)/cos(t)经过幅度的放缩和频率的收紧,变成了一系列的波 的求和,一致收敛于原始函数。注意傅立叶级数求和的收敛性是对于整个数轴而言的,严格的。不过前面我们说了,实际应用FFT的时候,我们只需要关注部分信 号的傅立叶变换然后求出一个整体和就可以了,那么对于函数的部分分量,我们只需要保证这个用来充当砖块的”波函数”,在某个区间(用窗函数来滤波)内符合 那几个可积分和收敛的定义就可以了,因此傅立叶变换的”波”因子,就可以不使用三角函数,而是使用一系列从某些基本函数构造出来的函数族,只要这个基本函 数符合那些收敛和正交的条件就可以了。怎么构造这样的基本函数呢?sin(t)被加了方形窗以后,映射到频域是一堆无穷的散列脉冲,所以不能再用三角函数 了。我们要得到频率域收敛性好的函数族,能覆盖频率域的低端部分。说的远一点,如果是取数字信号的小波变换,那么基础小波要保证数字角频率是最大的 2Pi。利用小波进行离频谱分析的方法,不是像傅立叶级数那样求出所有的频率分量,也不是向傅立叶变换那样看频谱特性,而是做某种滤波,看看在某种数字角 频率的波峰值大概是多少。可以根据实际需要得到如干个数字序列。
我们采用(0,f),(f,2f),(2f,4f)这样的倍频关系来考察函数族的频率特性,那么对应的时间波形就是倍数扩展(且包含调制—所以才有频 谱搬移)的一系列函数族。频域是窗函数的基本函数,时域就是钟形函数。当然其他类型的小波,虽然频率域不是窗函数,但是仍然可用:因为小波积分求出来的变 换,是一个值,例如(0,f)里包含的总能量值,(f,2f)里面包含的总能量值。所以即使频域的分割不是用长方形而是其他的图形,对于结果来说影响不 大。同时,这个频率域的值,它的分辨率密度和时域
小波基函数的时间分辨率是冲突的(时域紧频域宽,时域宽频域紧),所以设计的时候受到海森堡测不准原理的 制约。Jpeg2000压缩就是小波:因为时频都是局部的,变换结果是数值点而不是向量,所以,计算复杂度从FFT的O(NlgN)下降到了O(N),性 能非常好。
PS:不要瞧不起人人党啊 =。=
【Hinton大神新作】Dynamic Routing Between Capsules阅读笔记相关推荐
- capsule系列之Dynamic Routing Between Capsules
文章目录 1.背景 2.什么是capsule 3.capsule原理和结构 3.1.capsule结构 3.2.Dynamic Routing 算法 3.3.小部件 3.3.1.为耦合系数(coupl ...
- 论文阅读2 Dynamic Routing Between Capsules
论文阅读<2> Dynamic Routing Between Capsules Abstract 1 Introduction 2 How the vector inputs and o ...
- 初读Geoffrey Hinton颠覆之作《Dynamic Routing Between Capsules》
最近在搜资料时忽然看到一条消息,Hinton老爷子在NIPS 2017大会上放了大招,宣布要革CNN和反向传播的命.武林盟主在武林大会上要推翻自己之前的武学门派,另起炉灶,如此精彩的大戏怎能不吃瓜围观 ...
- Capsule:Dynamic Routing Between Capsules
Capsule介绍 Hinton在<Dynamic Routing Between Capsules>中提出了capsule,以神经元向量代替了从前的单个神经元节点,以dynamic ro ...
- 看完这篇,别说你还不懂Hinton大神的胶囊网络,capsule network
from:https://www.sohu.com/a/226611009_633698 倒计时 2 天 来源 | 王的机器(公众号ID:MeanMachine1031) 作者 | 王圣元 0 引言 ...
- Dynamic Routing Between Capsules学习资料总结
Dynamic Routing Between Capsules(NIPS2017) Dynamic Routing Between Capsules这篇文章已被NIPS 2017接收.2017年10 ...
- LiDAR-based Panoptic Segmentation via Dynamic Shifting Network(论文阅读笔记)
LiDAR-based Panoptic Segmentation via Dynamic Shifting Network(论文阅读笔记) 环形扫描骨干网络.动态漂移.一致性驱动的融合 一.重点内容 ...
- 何恺明大神新作:一种用于目标检测的主流ViT架构,效果SOTA
链接:https://arxiv.org/abs/2203.16527 作者单位:Facebook AI Research 1导读 3月30日,何恺明大神团队在ArXiv上发布了最新研究工作,该工作主 ...
- 何恺明大神新作--UnNAS:无监督神经网络架构搜索
点击上方,选择星标或置顶,不定期资源大放送! 阅读大概需要15分钟 Follow小博主,每天更新前沿干货 作者:江山如画 编辑:Cver 链接:https://zhuanlan.zhihu.com/p ...
最新文章
- 关于程序猿的几个阶段!
- Python中的map和reduce函数简介
- 20应用统计考研复试要点(part18)--概率论与数理统计
- 关于二叉堆(优先队列)的其他操作及其应用
- 一步一步SharePoint 2007之四十一:实现Search(4)——设定爬网Schedule
- Linux主机如何连接刀片机,刀片服务器RAID配置及Linux操作系统的安装.doc
- laravel excel 导出图片
- 阿里、腾讯裁员,2022金三银四Android开发该何去何从?
- Nginx报错failed (13: Permission denied)
- 2022年卫浴行业报告:套系化+智能化拓宽边际,箭牌家居内资领航
- 北邮电教授思想洗礼之不二之选TGB
- GitHub上最火的Android开源项目整理
- SQL Server获取当年第一天当年最后一天当月第一天当月最后一天
- 自定义View之网易云音乐听歌识曲水波纹动画
- linux machine start,Linux中的MACH定义之MACHINE_START / MACHINE_END
- PAT A1027 Colors in Mars
- 读书寄语之春天该很好,你若尚在场
- 如何将电脑的动态IP设置成静态IP,并成功上网
- 如何修改文件的创建时间和修改时间?
- 使用LEADTOOLS文档比较工具比较文档和图像