拼音解析搜索--自动解析拼音汉子组合(包含多音字,拼音缩写)
最近在工作中用到拼音搜索,目前参考靠网上的例子做出一套,在这跟大家分享一下。
这套代码可以识别包快拼音缩写在内的拼音与汉字混合的字符串(例如:xiug手机h --> 修改手机号)
话不多说,直接开始:
1. 首先有一张中文词语对应拼音的表,然后建一张词语点击量的表(用于记录词语的常用度)
PinyinWord table
CREATE TABLE "public"."pinyinword" ("id" text COLLATE "default" NOT NULL,"word" text COLLATE "default" NOT NULL,"whole" text COLLATE "default" NOT NULL,"acronym" text COLLATE "default" NOT NULL,"wordlength" int4 NOT NULL,"wholelength" int4 NOT NULL,"acronymlength" int4 NOT NULL
)WordClick table
CREATE TABLE "public"."wordclick" ("wordcontent" text COLLATE "default","id" text COLLATE "default" NOT NULL
)表中数据自行初始化
2. 接下来介绍两个数据类型,在分析input时起到很重要的作用
/**
* 词元
*/
public class Lexeme {private String content; //词元内容private LexemeType lexemeType; //词元类型
}public enum LexemeType {CHINESE, //中文WHOLE, //全拼ACRONYM //拼音首字母缩写
}
/**
* 中文句子(处理用户输入的类)
*/
public class ChineseSentence {private String content; // 用户输入内容private List<Lexeme> sentenceUnits; // content中包含的词元private SentenceType sentenceType; // 句子最低级类型(不能set,赋值请看initSentenceType())public String getContent() {return content;}public void setContent(String content) {this.content = content;}public List<Lexeme> getSentenceUnits() {return sentenceUnits;}public SentenceType getSentenceType() {return sentenceType;}public void setSentenceUnits(List<Lexeme> sentenceUnits) {this.sentenceUnits = sentenceUnits;initSentenceType();}private void initSentenceType() {sentenceType = SentenceType.CHINESE_SENTENCE;for (Lexeme lexeme : sentenceUnits) {if (lexeme.getLexemeType() == LexemeType.ACRONYM) {sentenceType = SentenceType.ACRONYM_SENTENCE;break;} else if (lexeme.getLexemeType() == LexemeType.WHOLE&& sentenceType == SentenceType.CHINESE_SENTENCE) {sentenceType = SentenceType.WHOLE_SENTENCE;}}}
}
3. 接下来就是处理用户输入(xiug手机h),使用正则表达式将目标分解成词元(Lexeme)并 生成句子
//正则表达式(从网上copy下来做了一些修改,识别中文和疑似的拼音)
private static final String SUSPECTED_PINYIN_REGEX = "[\\u4e00-\\u9fa5]|(sh|ch|zh|[^aoeiuv])?[iuv]?(ai|ei|ao|ou|er|ang?|eng?|ong|a|o|e|i|u|ng|n)?";使用这个正则表达式可能会截取出 不存在的拼音组合,比如说jvao
这种直接成 j,v,a,o(找一个拼音组合的库,看看截出来的拼音属不属于库里即可)
经过截取并给每个词元附一个lexemeType,得到下边的结果
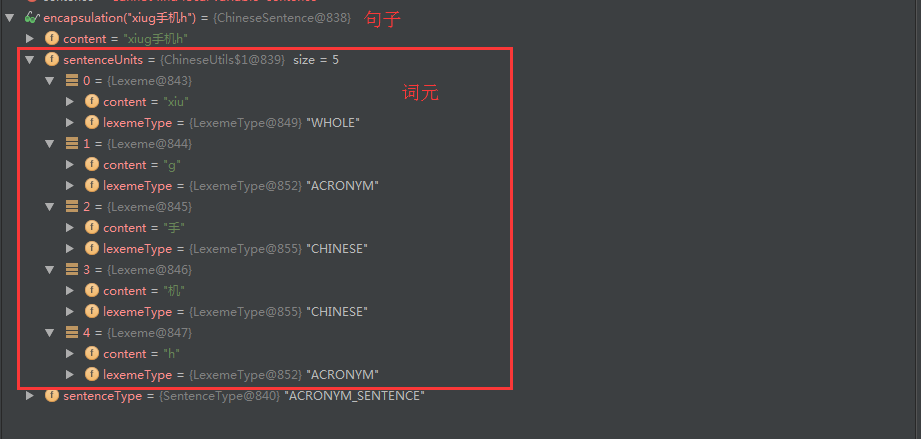
4. 接下来就是对句子中词元逐个进行分析
首先简要说明一下分析原理
先看一下查询条件
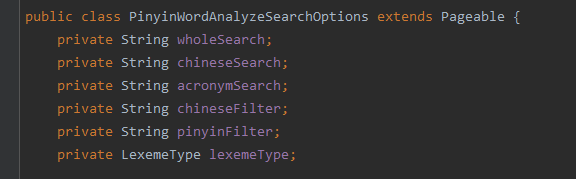
解释一下查询参数,首先是lexemeType 这个字段是指定搜索的词级,必须按照句子的最低词级进行搜索
例如: '修改' --> LexemeType.CHINESE
'xiu改' --> LexemeType.WHOLE
'修g' --> LexemeType.ACRONYM
Search结尾的三个参数是用来做搜索的,他们在SQL中用来做like操作, 这样可以击中索引
and pinyinword.acronym like #{acronymSearch} || '%'由于用户输入的句子中可能含有中文或者拼音,这两种类型里需要进行过滤
比如说用户输入 ‘修g’ 我们用最低词级进行搜索 就是 like 'xg' % 这样可能搜到 '鞋柜' 所以我用了chineseFilter 和 pinyinFilter 来进行过滤(把 '%修%' append到chineseFilter中),这样查询条件就变成了
and pinyinword.acronym like #{acronymSearch} || '%'
and pinyinword.word like #{chineseFilter}这样就不会搜到 '鞋柜' 了
来看一下mybatis下的SQL,这里join了wordclick表,取得了每个词语的点击量,用来排序
<select id="searchByClickCount" resultType="model.value.WordClickCount" parameterType="model.options.PinyinWordAnalyzeSearchOptions">selectpw.word word, count(wc.id) clickCountfromPinyinWord pw left join wordclick wc on wc.wordcontent = pw.wordwhere 1=1<choose><when test="lexemeType.equals('CHINESE')"><if test="chineseSearch!=null">and pw.word like #{chineseSearch} || '%'</if>group by pw.wordorder by clickCount desc<if test="paging">limit 5 offset 0</if></when><when test="lexemeType.equals('WHOLE')"><if test="wholeSearch!=null">and pw.whole like #{wholeSearch} || '%'</if><if test="chineseFilter!=null">and pw.word like #{chineseFilter}</if>group by pw.wordorder by clickCount desc<if test="paging">limit 5 offset 0</if></when><otherwise><if test="acronymSearch!=null">and pw.acronym like #{acronymSearch} || '%'</if><if test="chineseFilter!=null">and pw.word like #{chineseFilter}</if><if test="pinyinFilter!=null">and pw.whole like #{pinyinFilter}</if>group by pw.wordorder by clickCount desc<if test="paging">limit 5 offset 0</if></otherwise></choose></select>
然后是分析用户的输入,把查询条件生成出来
这是部分代码,足以明了 查询条件生成原则了
LexemeType currentLexemeType; //当前词元类型LexemeType lastLexemeType = null; //之前词元最低级List<Lexeme> lexemes = sentence.getSentenceUnits(); //累积词元最低级for (int i = 0; i < lexemes.size(); i++) {Lexeme lexeme = lexemes.get(i);currentLexemeType = lexeme.getLexemeType();String content = lexeme.getContent();switch (currentLexemeType) { case CHINESE: //若当前词元为中文String pinyin = convertSmartAll(content); //转成拼音(pinyin4j)chineseSearch.append(content); //append到chineseSearch字段wholeSearch.append(pinyin); //append到wholeSearch字段acronymSearch.append(pinyin.charAt(0)); //append到acronymSearch字段chineseFilter.append(content).append("%"); //append到chineseFilter字段break;case WHOLE: //若为拼音 同理中文wholeSearch.append(content);acronymSearch.append(content.charAt(0));pinyinFilter.append(content).append("%");break;case ACRONYM: //同理acronymSearch.append(content);break;}//将lastLexemeType 转换成当前词元和当前lastLexemeType中的第一级别的LexeType,因为搜索时需要词元最低级lastLexemeType = LexemeType.changeDown(lastLexemeType, currentLexemeType); //new searchOptionsPinyinWordAnalyzeSearchOptions options = new PinyinWordAnalyzeSearchOptions(chineseSearch.toString(), wholeSearch.toString(), acronymSearch.toString(),chineseFilter.toString(), pinyinFilter.toString(), lastLexemeType);// 结果出来啦。。。List<WordClickCount> wordClickCounts = mapper.searchByClickCount(options);测试一下:
@Testpublic void analyzeAndSearchTest() throws Exception {List<List<WordClickCount>> results = pinyinWordService.analyzeSearch("xiugaishoujihao"); //为了初始化 pinyin4jlong start1 = System.currentTimeMillis();for (int i = 0; i < 100; i++) {long start = System.currentTimeMillis();List<List<WordClickCount>> results1 = pinyinWordService.analyzeSearch("xiugais机haoqyxgai修改");long end = System.currentTimeMillis();System.out.println(end - start + " ms");}long end1 = System.currentTimeMillis();System.out.println(end1 - start1 + " ms");}测试结果
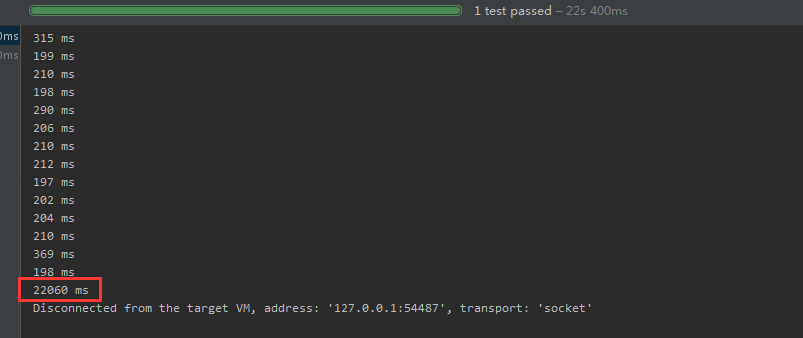 测试分解100条 11个词元的用户输入,话费22.1秒,平均每个221ms,效果还行
测试分解100条 11个词元的用户输入,话费22.1秒,平均每个221ms,效果还行
未来优化:
在sql中,使用了表关联和count操作,当数据量比较大的时候,可以考虑将pinyinword 加一个字段,每天跑定时把count update到pinyinword表中,这样可以对pinyinword进行单表查询了
开源中国博客地址
拼音解析搜索--自动解析拼音汉子组合(包含多音字,拼音缩写)相关推荐
- 【一起学习输入法】华宇拼音输入法开源版本解析(2)
[一起学习输入法]华宇拼音输入法开源版本解析(2) 原创:good02xaut(CSDN) 键盘的扫描码 薄膜式标准键盘的硬件构成由四部分组成:三层薄膜.104个按键矩阵.3个指示 ...
- 【一起学习输入法】华宇拼音输入法开源版本解析(6)
[一起学习输入法]华宇拼音输入法开源版本解析(6) 原创:good02xaut(CSDN) 输入法运行原理 汉字编码体系 汉字的编码就是汉字对应的字符集,历史上共有5种: GB23 ...
- ES 7.X 做类百度搜索,进行搜索自动补全和热搜词及拼音功能实现
文章目录 前言 一.如何使用ES做类似百度的检索? 二.全文检索自动补齐 1.创建索引 2.添加数据 3.高级检索 三 热搜词 1.思路 2.DSL语句 3.java代码实现 四 拼音补全 1.DSL ...
- 【一起学习输入法】华宇拼音输入法开源版本解析(3)
[一起学习输入法]华宇拼音输入法开源版本解析(3) 原创:good02xaut(CSDN) 键盘的虚拟码列表 鼠标虽然不是键盘,为了程序设计方便,依然提供了3个虚拟键码与鼠标上的三 ...
- 【一起学习输入法】华宇拼音输入法开源版本解析(8)
[一起学习输入法]华宇拼音输入法开源版本解析(8) 原创:good02xaut(CSDN) 输入法的码型转换 键盘的拼音输入法 输入法的核心工作是把输入码转换为正确的机内码.拼音输 ...
- 【一起学习输入法】华宇拼音输入法开源版本解析(4)
[一起学习输入法]华宇拼音输入法开源版本解析(4) 原创:good02xaut(CSDN) 键盘的扫描码列表
- 【一起学习输入法】华宇拼音输入法开源版本解析(10)
[一起学习输入法]华宇拼音输入法开源版本解析(10) 原创:good02xaut(CSDN) 硬件框图
- 【一起学习输入法】华宇拼音输入法开源版本解析(9)
[一起学习输入法]华宇拼音输入法开源版本解析(9) 原创:good02xaut(CSDN) 逻辑框图 汉字编码体系和计算机码型转换是汉字输入法的理论基础,无论采用何种设备输入,无论 ...
- php_excel表中_如何自动将多行中文转换成拼音,Excel2007怎么批量将汉字转换为拼音...
excel中录入的姓名全是中文,但是要发给老外,所以要改成拼音显示的,怎么批量转换呢?其实方法很简单Excel中自带转换功能,下面就跟学习啦小编一起看看excel2007批量将汉字转换成拼音的方法. ...
最新文章
- 【故事】创业者破产后自述:别总谈商业模式、推广和体验
- linux脚本批量复制文件,shell实现scp批量下发文件
- 5训练需要更改参数吗_糖尿病病人需要多喝水吗?多喝水的5大好处,了解一下...
- 古风一棵桃花树简笔画_广东有个现实版的“桃花源”,藏于秘境之中,最适合情侣来度假!...
- docker学习总结二
- 这个世界有一种无形的力量~梦想
- 使用AndroidStudio编译NDK的方法及错误解决方式
- Java运行报错问题——Picked up JAVA_TOOL_OPTIONS: -agentlib:jvmhook
- 语言abline画不出线_北师大版八下数学 2.1不等关系 知识点精讲
- Matlab基础知识
- sata 双硬盘 电源线_电脑双硬盘安装图解教程
- C语言新手入门贪吃蛇的链表实现-控制光标位置,流畅不闪屏
- 苹果手机投屏软件_苹果手机怎样投屏到笔记本?
- (2021总结篇)面向对象软件设计模式--(八)结构型模式---树形结构的处理--组合模式
- 组件、控件和插件的区别
- JavaEE项目的三层架构
- 用于提升多样性的Maximum Mutual Information算法
- 相关性扫描匹配CSM与分支限界加速
- 迅速处理多个ts转mp4格式 - 无需安装
- Linux是什么 ?