大数据时代数据库-云HBase架构生态实践
2019独角兽企业重金招聘Python工程师标准>>> 
摘要: 2018第九届中国数据库技术大会,阿里云高级技术专家、架构师封神(曹龙)带来题为大数据时代数据库-云HBase架构&生态&实践的演讲。主要内容有三个方面:首先介绍了业务挑战带来的架构演进,其次分析了ApsaraDB HBase及生态,最后分享了大数据数据库的实际案例。
2018第九届中国数据库技术大会,阿里云高级技术专家、架构师封神(曹龙)带来题为大数据时代数据库-云HBase架构&生态&实践的演讲。主要内容有三个方面:首先介绍了业务挑战带来的架构演进,其次分析了ApsaraDB HBase及生态,最后分享了大数据数据库的实际案例。
直播视频回顾
PPT下载请点击
以下是精彩视频内容整理:
业务的挑战
存储量量/并发计算增大
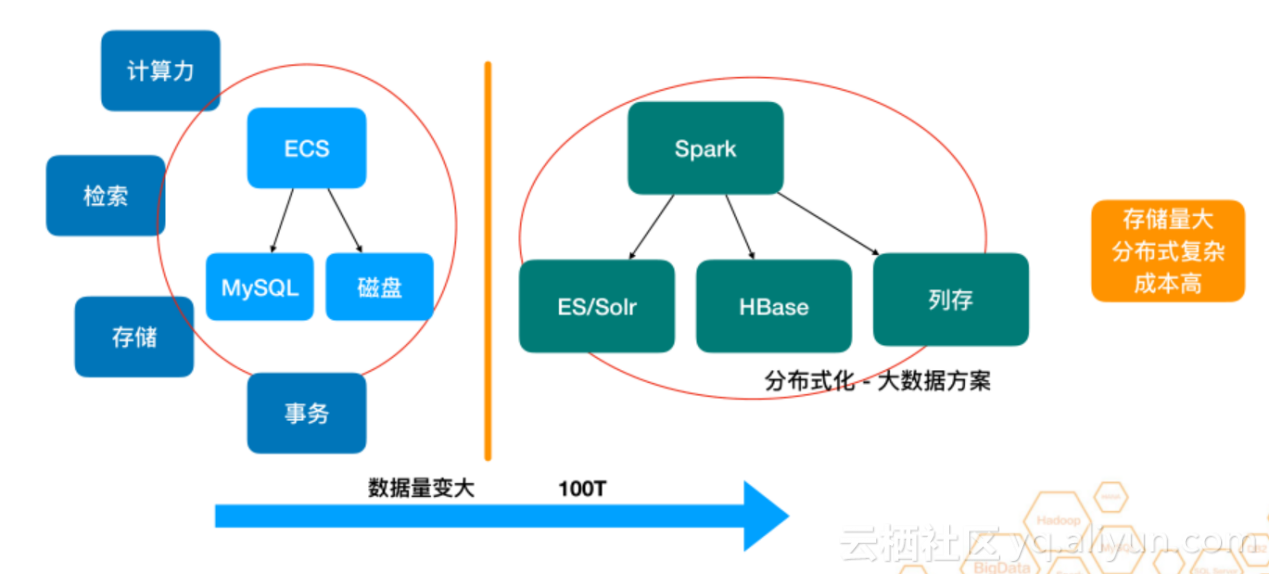
现如今大量的中小型公司并没有大规模的数据,如果一家公司的数据量超过100T,且能通过数据产生新的价值,基本可以说是大数据公司了 。起初,一个创业公司的基本思路就是首先架构一个或者几个ECS,后面加入MySQL,如果有图片需求还可加入磁盘,该架构的基本能力包括事务、存储、索引和计算力。随着公司的慢慢发展,数据量在不断地增大,其通过MySQL及磁盘基本无法满足需求,只有分布式化。 这个时候MySQL变成了HBase,检索变成了Solr/ES,再ECS提供的计算力变成了Spark。但这也会面临存储量大且存储成本高等问题。
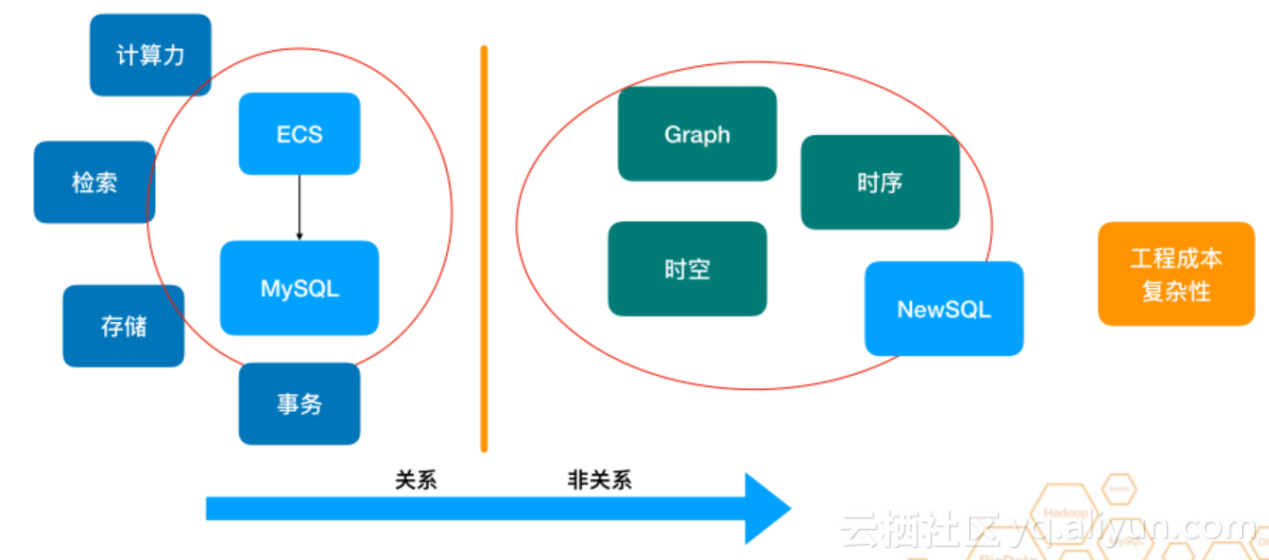
另外一个趋势就是非结构化的数据越来越多,数据结构的模式不仅仅是SQL,时序、时空、graph模式也越来越多,需要一些新的存储结构或新的算法去解决这类问题,也意味着所需要做的工程量就会相对较高。
引入更多的数据
对于数据处理大致可归类为四个方面,分别是复杂性、灵活性、延迟<读,写>和分布式,其中分布式肯定是不可少的,一旦缺少分布式就无法解决大规模问题 。灵活性的意思是业务可以任意改变的;复杂性就是运行一条SQL能够访问多少数据或者说SQL是否复杂;延迟也可分为读与写的延迟。Hadoop & Spark可以解决计算复杂性和灵活性,但是解决不了延迟的问题;HBase&分布式索引、分布式数据库可以解决灵活性与延迟的问题,但由于它没有很多计算节点,所以解决不了计算复杂性的问题。Kylin(满足读延迟)在计算复杂性与延迟之间找了一个平衡点,这个平衡点就是怎样快速出报表,但对于这个结果的输入时间我们并不关心,对于大部分的报表类的需求就是这样的。每个引擎都是一定的侧重,没有银弹!
ApsaraDB HBase产品架构及改进
应对的办法
我们也不能解决所有的问题,我们只是解决其中大部分的问题。如何找到一个在工程上能够解决大部分问题的方案至关重要,应对办法:
- 分布式:提供扩展性
- 计算力延伸:算子+SQL,从ECS到Spark其本质其实就是一种计算力的延伸
- 分层设计:降低复杂性,提供多模式的存储模型
- 云化:复用资源&弹性,降低成本
基本构架
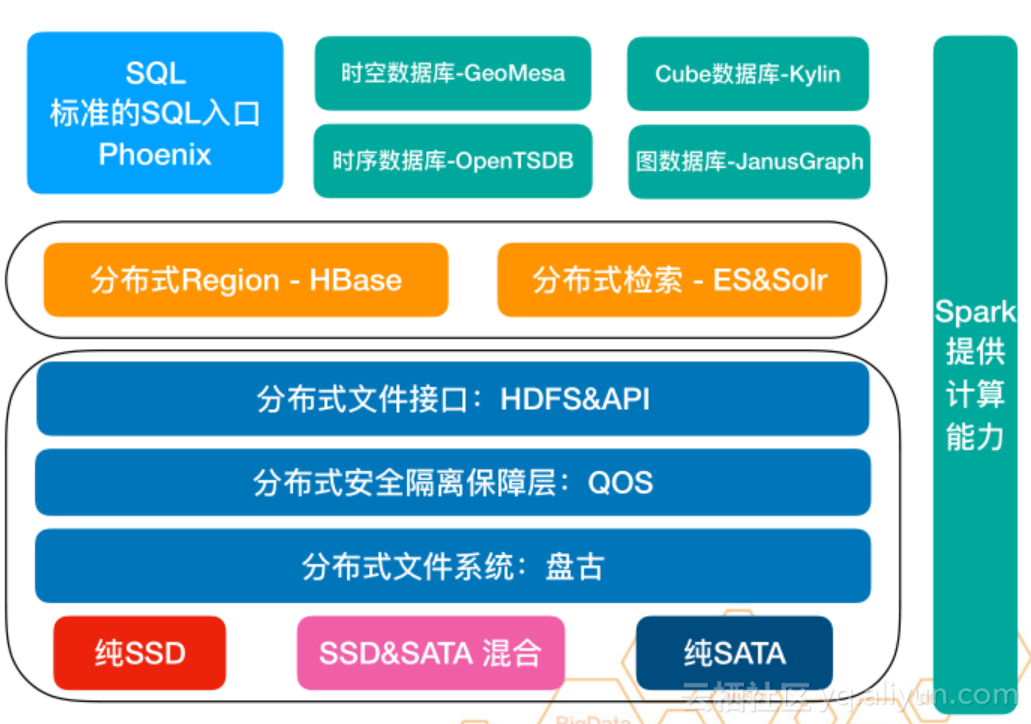
首先包含了两个分离
- 分别是HDFS与分布式Region分布式检索分离
- SQL时空图时序Cube与分布式Region检索分离
大致的分层机构如下: - 第一层:介质层,热SSD介质、温SSD&SATA 混合、冷纯SATA(做EC)
- 第二层:分布式文件系统,也就是盘古。事实上越是底层越容易做封装优化。
- 第三层:分布式安全隔离保障层QOS,如果我们做存储计算分离,就意味着底层的三个集群需要布三套,这样每个集群就会有几十台甚至几百台的节点,此时存储力是由大家来均摊的,这就意味着分布式安全隔离保障层要做好隔离性,引入QOS就意味着会增加延迟,此时会引入一些新的硬件(比如RDMA)去尽可能的减小延迟。
- 第四层:分布式文件接口:HDFS & API(此层看情况可有可无)
- 第五层:我们提供了两个组件,分布式Region-HBase与分布式检索-Solr,在研究分布索引的时候发现单机索引是相对简单的,我们提供针对二级索引采取内置的分布式Region的分布式架构,针对全文索引采取外置Solr分布式索引方案
- 第六层:建设在分布式KV之上,有NewSQL套件、时空套件、时序套件、图套件及Cube套件
另外,可以引入spark来分析,这个也是社区目前通用的方案
解决成本的方案
对于解决成本的方案简单介绍如下:
- 分级存储:SSD与SATA的价格相差很多,在冷数据上,我们建议直接采取冷存储的方式 ,可以节约500%的成本
- 高压缩比:在分级存储上有一个较好的压缩,尤其是在冷数据,我们可以提高压缩比例,另外分布式文件系统可以采取EC进一步降低存储成本,节约100%的成本
- 基础设施共享:库存压力分担,云平台可以释放红利给客户
- 存储与计算分离:按需计费
- 优化性能:再把性能提升1倍左右
云数据库基本部署结构
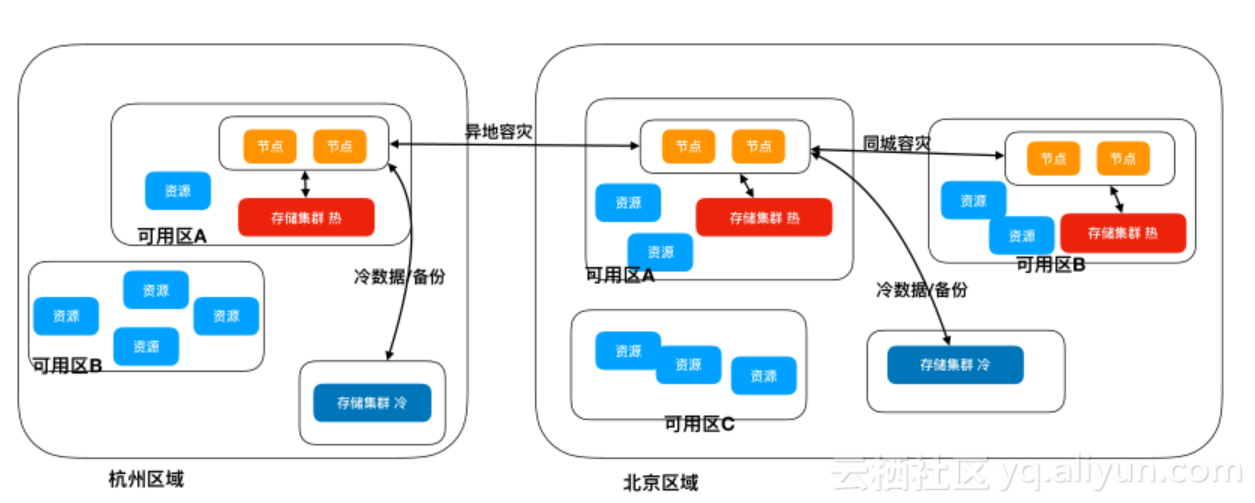
假设在北京有三个机房可用区A、B和C,我们会在可用区A中部署一个热的存储集群,在北京整体区域部一个冷的存储集群,实际上有几个可用区就可以有几个热集群,主要是保障延迟的;冷集群对延迟相对不敏感,可以地域单独部署,只要交换机满足冷集群所需的带宽即可。这样的好处是三个区共享一个冷集群,就意味着可以共享库存。
ApsaraDB HBase产品能力
我们提供两个版本,一是单节点版,其特点是给开发测试用或者可用性不高,数据量不大的场景。二是集群版本其特点是高至5000w QPS,多达10P存储与高可靠低延迟等。
- 数据可靠性:99.99999999%:之所以可靠性可以达到如此之高,其核心的原因就是存储集群是单独部署的,其会根据机架等进行副本放置优化
- 服务可用性:单集群99.9% 双集群99.99%。
- 服务保障:服务未满足SLA赔付。
- 数据备份及恢复。
- 数据热冷分离分级存储。
- 企业级安全:认证授权及加密。
- 提供检索及二级索引及NewSQL能力。
- 提供时序/图/时空/Cube相关能力。
- 与Spark无缝集成,提供AP能力。
数据备份及恢复
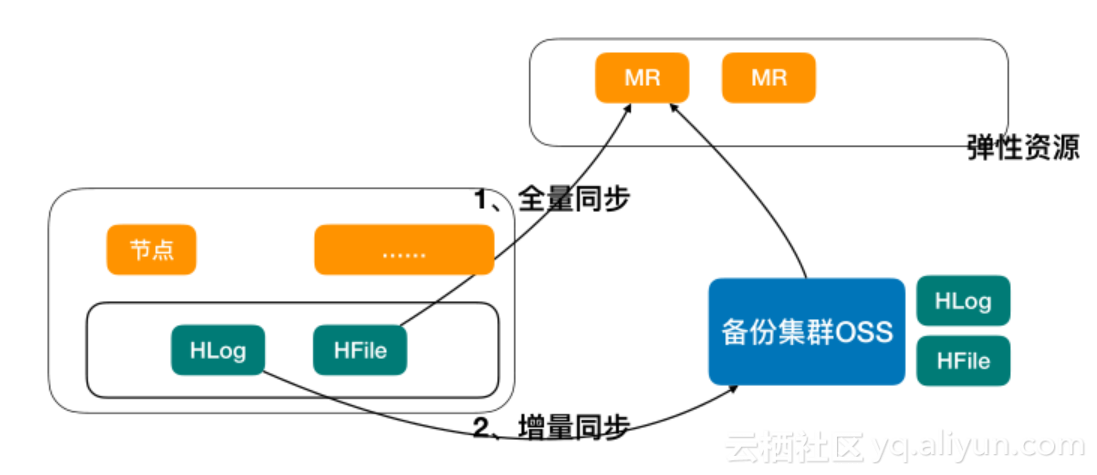
备份分为全量备份HFile与 增量量备份HLog;恢复分为HLog转化为HFile和BulkLoad加载。阿里云集团迄今为止已经有一万两千多台的HBase,大部分都是主备集群的,在云上由于客户成本的原因,大部分不选择主备,所以需要对数据进行备份。其难点在于备份需要引入计算资源,我们需要引入弹性的计算资源来处理备份的相关计算任务
Compaction 离线Compaction(研究中)
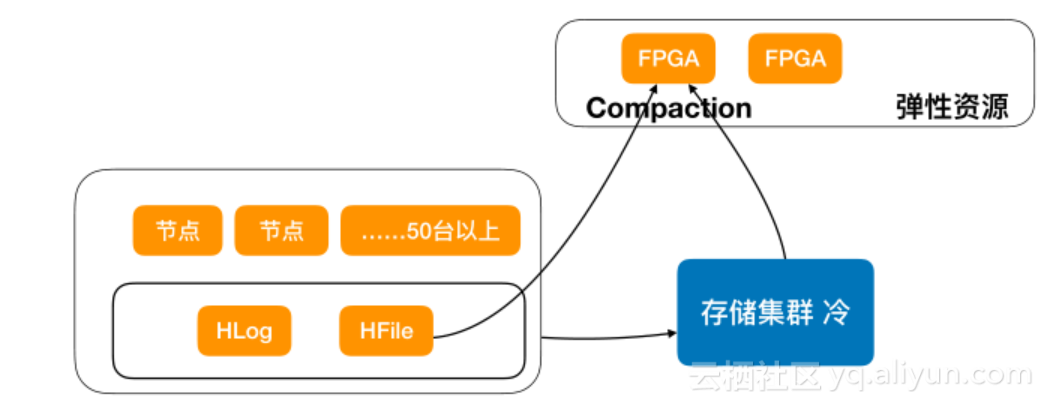
我们在内部研究如何通FPGA对Compaction进行加速,这会使得集群运行比较平缓,特别是对计算资源少,存储量大的情况下,可以通过离线的作业处理Compaction。
组件层
我们有5中组件,NewSQL(Phoenix)、时序OpenTSDB、时空GeoMesa、图JanusGraph及Cube的Kylin,及提供HTAP能力的Spark。这里简单描述几个,如下:
NewSQL-Phoenix
客户还是比较喜欢用SQL的,Phoenix会支持SQL及二级索引,在超过1T的数据量的情况下,对事务的需求就很少(所以我们并没有支持事务);二级索引是通过再新建一张HBase表来实现的。在命中索引的情况下,万亿级别的访问基本在毫秒级别,但由于Phoenix聚合点在一个节点,所以不能做Shuffle类似的事情,同时也就不能处理复杂的计算,所以任何说我是HTAP架构的,如果不能做Shuffle,就基本不能做复杂的计算。
HTAP-Spark
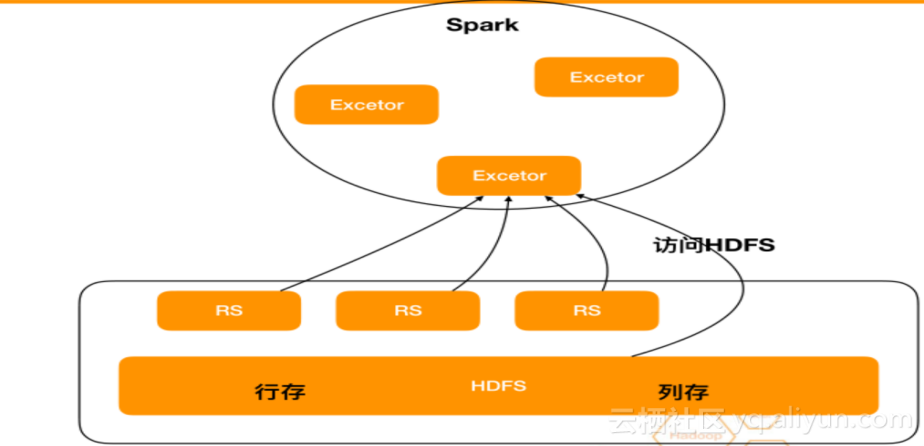
在HTAP-Spark这部分主要介绍一下RDD API、 SQL、直接访问HFile,它们的特点如下:
- RDD API具有简单方便,默认支持的特点,但高并发scan大表会影响稳定性;
- SQL支持算子下推、schema映射、各种参数调优,高并发scan大表会影响稳定性;
- 直接访问HFile,直接访问存储不经过计算,大批量量访问性能最好,需要snapshot对齐数据。
时序-OpenTSDB & HiTSDB
TSD没有状态,可以动态加减节点,并按照时序数据的特点设计表结构,其内置针对浮点的高压缩比的算法,我们云上专业版的HiTSDB增加倒排等能力,并能够针对时序增加插值、降精度等优化。
大数据数据库的实际案例
以下简单介绍几个客户的案例,目前已经在云上ApsaraDB HBase运行,数据量基本在10T以上:
某车联网公司
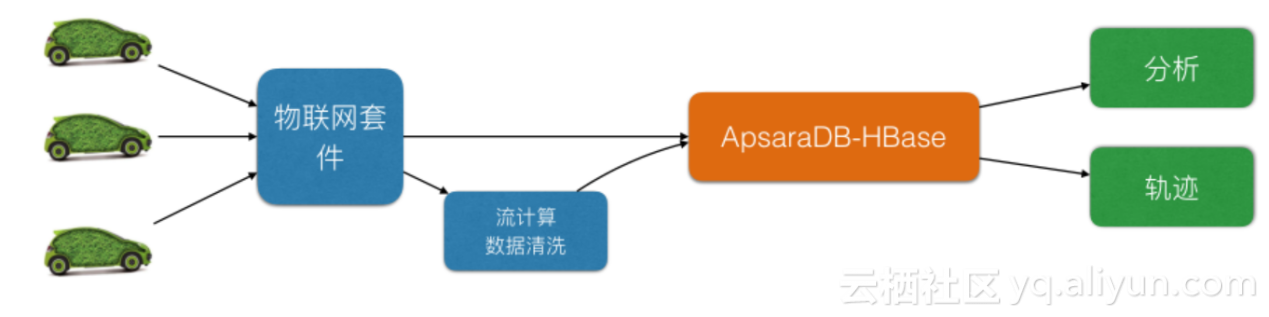
这是一个车联网的客户,有100万车,每辆车每10秒上传一次,每次1KB,这样一年就有300T数据,六个月以上是数据低频访问,所以他要做分级存储,把冷数据放到低介质上
某大数据控公司
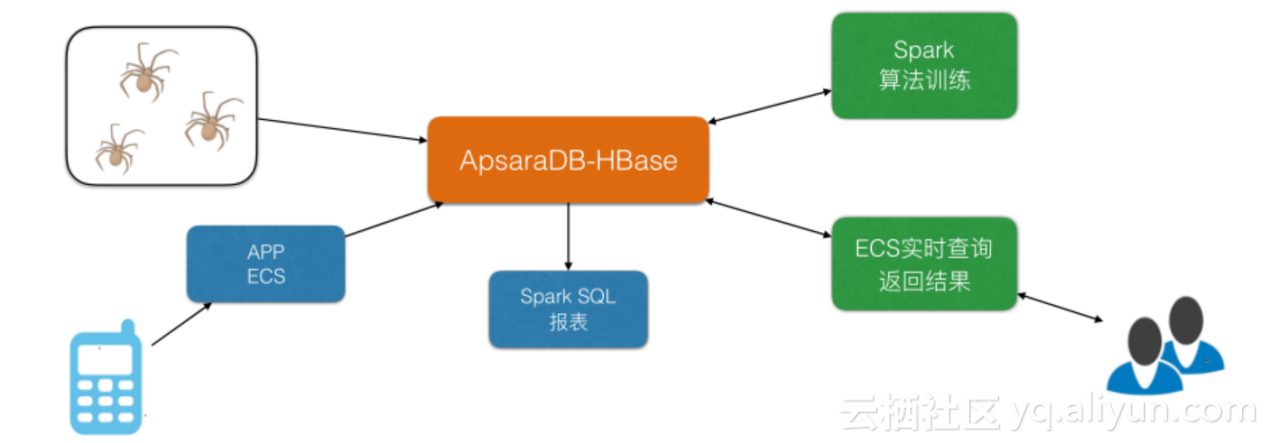
这是一个大数据控公司,它大约有200T+的数据量,将HBase数据 (在线实时大数据存储)作为主数据库,先用HBase做算法训练,再用HBase SQL出报表,另外做了一套ECS进行实时查以便与客户之间进行数据交换。
某社交公司
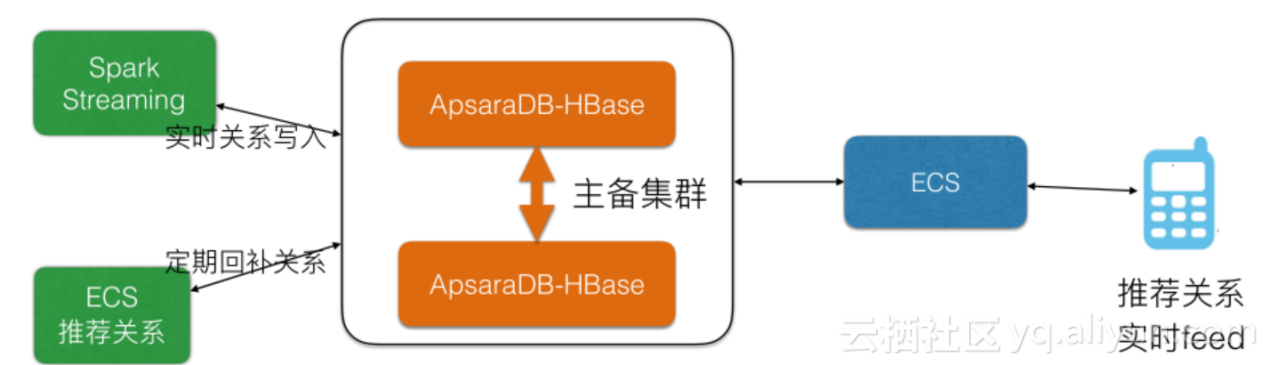
社交会有大量的推荐,所以SLA要求高达99.99,并采用双集群保障,单集群读写高峰QPS 可以达到1000w+,数据量在30T左右。
某基金公司

这是一个金融公司,它有10000亿以上的交易数据,目前用多个二级索引支持毫秒级别的查询,数据量在100T左右
某公司报表系统
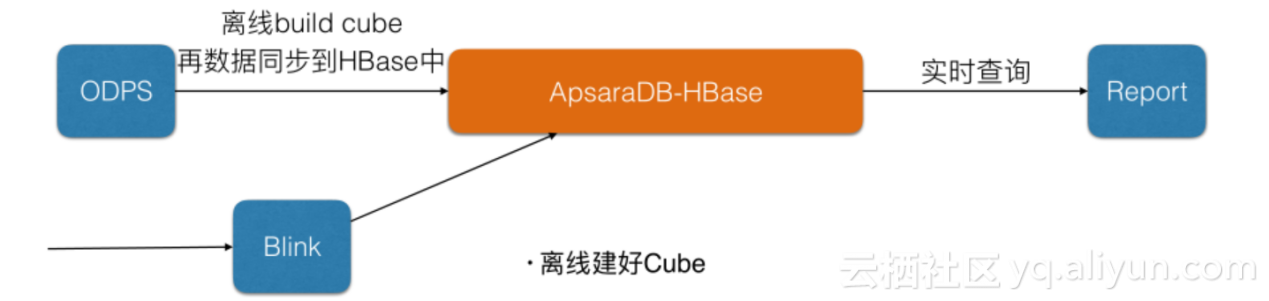
先离线建好Cube再把数据同步到HBase中,实时数据通过Blink对接进行更新,数据量在可达20T左右。
原文链接
转载于:https://my.oschina.net/u/3735980/blog/1820772
大数据时代数据库-云HBase架构生态实践相关推荐
- 柯南君:看大数据时代下的IT架构(5)消息队列之RabbitMQ--案例(Work Queues起航)...
二.Work Queues(using the Java Client) 走起 在第上一个教程中我们写程序从一个命名队列发送和接收消息.在这一次我们将创建一个工作队列,将用于分发耗时的任务在多个工作者 ...
- 柯南君:看大数据时代下的IT架构(4)消息队列之RabbitMQ--案例(Helloword起航)...
柯南君:看大数据时代下的IT架构(4)消息队列之RabbitMQ--案例(Helloword起航) 二.起航 本章节,柯南君将从几个层面,用官网例子讲解一下RabbitMQ的实操经典程序案例,让大家重 ...
- 大数据时代证券核心交易系统架构演化
大数据时代证券核心交易系统架构演化 推荐阅读: 世界的真实格局分析,地球人类社会底层运行原理 不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)企业IT技术架构规划方案论数字化转型--转什 ...
- 【2016年第6期】大数据时代空间科学领域的科研信息化实践与成果
邹自明,佟继周,熊森林,胡晓彦,纪珍 中国科学院国家空间科学中心,北京 100190 摘要:随着人类对空间探索的拓展以及对空间认知的加深,空间科学探测大工程任务相继推进.实施,催生了空间科学领域大数 ...
- 看大数据时代下的IT架构(1)图片服务器之演进史
柯南君的公司最近产品即将上线,由于产品业务对图片的需求与日俱增,花样百出,与此同时,在大数据时代,大流量的冲击下,对图片服务器的压力可想而知,那么今天,柯南君结合互联网的相关热文,加上 ...
- 第一篇文献:谈大数据时代的云控制摄影测量 ——张祖勋院士
提出背景:大数据时代的到来,通过无人机等手段获取到的摄影测量影像具有传统航测影像不具备的优势和缺点.优势主要是数据量大,获取到的周期短,时效性高.劣势是规范性弱,缺乏严格的航线规划.且大多为非量测型相 ...
- 大数据-NoSQL数据库:HBase【基于Zookeeper/HDFS的分布式、高并发、可扩展的NoSQL数据库;支持“十亿行”ד百万列”海量数据的实时随机读写;仅支持单表查询;不擅长数据分析】
HBase适合场景:单表超千万,上亿,且高并发! HBase不适合场景:主要需求是数据分析,比如做报表.数据量规模不大,对实时性要求高! HBase的查询工具有很多,如:Hive.Tez.Impala ...
- 大数据时代:架构师该具备什么?
揭秘|学习|创新|实践 诚邀台湾"Android教父".国际资深架构师专家高焕堂先生3月31日亲临上海授课.4月12日将由Hadoop源码级专家王家林上海张江首场授课. ...
- 昨日黄花Hadoop 方兴未艾云原生——传统大数据平台的云原生化改造
本文6539字,阅读时间约20分钟 以Hadoop为中心的大数据生态系统从2006年开源以来,一直是大部分公司构建大数据平台的选择,但这种传统选择随着人们深入地使用,出现越来越多的问题,比如:数据开发 ...
最新文章
- 香港中文大学(深圳)罗元教授招收计算机与信息工程全奖博士
- C#操作XML方法集合
- SAP 电商云 Spartacus UI 出现 breaking change 时,如何用文字来描述
- 重温SQL——行转列,列转行(转:http://www.cnblogs.com/kerrycode/archive/2010/07/28/1786547.html)...
- linux socket bind 内核详解,Socket与系统调用深度分析(示例代码)
- iPhone 13 Pro 成本价曝光,不到4000元
- CDN---共享单车算啥,阿里云发布共享网络黑科技PCDN,降低视频行业75%的成本
- tcp 裸流 发送 html,ffmpeg 命令学习
- ppt 制作海报 导出高分辨率图片
- 在家或者公司如何登录服务器
- dismiss和remove_eliminate, remove, dismiss的区别:新东方考研英语词汇辨析
- windowsPE制作工具
- https://api-hmugo-web.itheima.net 不在以下 request 合法域名列表中,请参考文档:https://developers.weixin.qq.com/minip
- 读书笔记:普通心理学之个体心理
- MySQL—关联查询与子查询(从小白到大牛)
- 华为CT6100双千M路由记录
- LS-DYNA (动力分析程序)
- Unreal Engine4(虚幻4)学习心得-材质
- Alos PALSAR 12.5米免费DEM下载教程
- 搜狗CEO强烈推荐,98%好评,这本深度学习宝典刷爆IT圈!
热门文章
- c++ Segmentation fault (core dumped) 的一个实例
- 8086标志寄存器介绍及作用(未完)
- linux 运行c b停止,以下Linux命令中,用于终止某个进程的命令是()。A.deadB.killC.quitD.exit...
- Struts2中OGNL,valueStack,stackContext的学习
- 大话数据结构之算法 时间复杂度
- spring和ejb2.x集成共享applicationContext.xml的问题
- vue使用echarts可视化图形插件
- [Verilog] parameter
- 推荐六款帮助你实现惊艳视差滚动效果的 jQuery 插件
- Kotlin学习笔记(2)- 空安全