[译] A Neural Algorithm of Artistic Style--图片风格化
题目:一个艺术风格化的神经网络算法

效果图
- 文章地址:《A Neural Algorithm of Artistic Style》. arXiv:1508.06576
- Github链接:https://github.com/jcjohnson/neural-style
(转载请注明出处:【译】A Neural Algorithm of Artistic Style (zhwhong) )
快读

a图的style 和 p图的content 进行融合,得到第三幅图x

代价函数Loss
正文

对于好的艺术,尤其是画作,人们掌握了通过在内容和风格中构成复杂的影响来创造独特的视觉体验的技能。因此这个过程的算法基础是未知的而且不存在任一人工系统有同样的能力。但是,在其他基于视觉概念的关键领域,比如说接近于人类表现的物体和脸部识别最近已由一系列仿生的称为深度神经网络的视觉模型做到了.在这时我们介绍一种其于深度神经网络的人工系统,它可以生成具有高感知品质的艺术图片.这个系统使用了神经的表达来分离并且再结合任意图片的内容和风格,为生成艺术图片提供了一个神经算法.而且,按照要去表现最优的人工神经网络和生物视觉中找到相同.我们的工作提供了人类是怎样创作和认知艺术图像的算法理解.
处理图像任务最有效的深度神经网络是卷积神经网络。卷积神经网络由几层小的在前馈中分层处理视觉信息的可计算单元组成。每一层单元都 可以被理解为一个图片过滤器的集合(collection),每一个从中提取特定的特征。因此,一个给定的层的输出包括我们称为特征谱(map):输入图片的不同的被过滤的版本。
当卷积网络在物体识别上被训练时,它们生成了一种对于图片的表达,能够沿着层次使特征的信息不断(increasingly)明确。因此,沿着网络的层次,这个输入图片被转化为的呈现越来越关注实际的图片内容,对比于它具体的像素值。我们可以直接可视化每层包括的关于输入图片的信息,通过只重构该层的特征图谱。网络的更高层捕捉了物体在高层的内容和在输入图片的应用,但是不含重构的精确的像素值。与此相反,从更低的层次的重构简单地重新生成了原始图像的具体像素值。我们因此参考了网络高层的特征反应作为内容表现。为了获取一个输入图片的风格表现,我们使用了一个特征空间被原始地设计来捕获纹理信息。这个特征空间是建立在网络每一层的过滤器的响应(response)上的。它由空间范围内的特征图谱不同的过滤响应间的联系组成(细节看method部分)。通过包括多层的特征关联,我们获得了一个固定的(stationry),多层规模的对于输入图片的陈述,这个表现可以捕获宽的纹理信息而不是全局的应用(arrangement)。

图像1 :卷积神经网络 (CNN)。一个给定的输入图像由一个被过滤过的存在于卷积网络各个处理过程中的图像集呈现。当不同的过滤器的数量沿着处理的层次增长时,过滤后图像的大小被一些下采样机制减小,导致了在网络每一层的单元总数的减小。
内容重构。我们可以通过从一个已知特定层的网络的响应重构输入图片来可视化CNN中不同处理层的信息。我们重构了输入图像从VGG的‘conv1 1’ (a), ‘conv2 1’ (b), ‘conv3 1’ (c), ‘conv4 1’ (d) and ‘conv5 1’ (e)。发现从较低层重构的几乎可以称完美 (a,b,c)。在网络的较高层,具体的像素值信息在更高层次的内容被保存的时候丢失了(d,e)。
风格重构。在原始的CNN的最高层我们建立了一个新的特征空间来捕获输入图片的风格。风格表现计算了CNN不同层中不同特征的联系。我们重构了输入图像的风格,建立在以下CNN层的子集( ‘conv1 1’ (a), ‘conv1 1’ and ‘conv2 1’ (b), ‘conv1 1’, ‘conv2 1’ and ‘conv3 1’ (c), ‘conv1 1’, ‘conv2 1’, ‘conv3 1’ and ‘conv4 1’ (d), ‘conv1 1’, ‘conv2 1’, ‘conv3 1’, ‘conv4 1’ and ‘conv5 1’ (e))。这创作的图像在增长的规模上符合了给定图像的风格,同时丢弃了全局的场景应用的信息。
再一次,我们可以通过重构一个可以符合(match)输入图风格表现的图像来可视化由在网络不同层风格特征空间捕获的信息(图1,风格重构)。事实上从风格特征重建产生的纹理化的输入图片,捕获了它依照颜色和局部结构捕获的外观。而且,沿着处理的层次,输入图片局部的图片结构的大小和复杂性增加,这可以解释为增长的感受野的大小和特征的复杂性。我们参考了多层的呈现现作为
风格表达。
这篇论文的关键发现在于风格和内容在卷积神经网络中的表达是可以分开的。也就是说,我们可以独立地操纵两种表达来产生新的、可以感受的有意义的图片。为了展示这个发现,我们生成了一些混合了不同源图片的内容和风格表现的图片。特别的,我们匹配了一张照片描绘the “Neckarfront” in Tubingen, Germany和一张几个不同时期的有名的艺术作品作为风格。
这类图片是发现一张和照片的内容表现和各自的艺术作品的风格表现两相匹配的图片合成的(图2)。

这些图片是通过寻找一个同时匹配照片的内容表现和各类艺术的图片合成的(see method for details).在原始照片的全局布置被保留的同时,构成全局景色的颜色和局部结构则由艺术作品提供.实际上,它把照片渲染成了艺术作品的风格,比如说合成图片的表现类似于艺术作品,尽管它的内容和照片相同.
正如概述所言,风格表现是一个多层次的表达,包括了多层神经网络.在我们在图2中展示的图片那样,这个风格表现包括了整 个神经网络结构的各个层次.风格也可以被定义为更为局部化,因为它只包含了少量的低层结构,这些结构能产生不同的视觉效果(图2,along the rows).当风格表现匹配到网络的更高层时,局部的图片结构会逐渐在大的尺寸上匹配,产生了一个更平滑更连续的视觉体验.因此,视觉上更有感染力的图片通常是由风格表现匹配到更高层网络的方法产生的(图2,last row).
当然,图片内容和风格不能被完全分离.当合成一张结合了某张图片的内容和另一张图片的风格时,通常不存在一个图片能同时完美的匹配这两张图片.然而,这个我们在合成过程中要最小化的loss函数包含了我们很好分离开的两个方面,内容和风格(see method).因此我们可以平滑地调节在重构内容或者是风格时的重点(图3,along the columns).着重强调风格产生的图片可以匹配艺术作品的表现,实际上也就是给了一个纹理化的版本,但是几乎不能表现任何照片的内容(图3,first column).当把比重放在内容上时,结果可以很清晰得确认到照片,但是画作的风格就不能很好地匹配(图3,last column).对于一对特定的源图片我们可以调节在内容和风格间的协调来产生视觉上有感染力的图片.

图3:合成 *Composition VII * by Wassily Kandinsky的风格的细节结果.每一行展示的结果,要匹配的风格表现用到的CNN的子集层数逐渐增加(see Methods).我们发现由风格表现捕获的局部的图片结构的大小和复杂性随着包括了更高的网络层次增加.这可以解释为是由于沿成网络处理的结构感受域的大小和特征复杂性增加.每一列展示了在内容和风格上取不同的相关权值的结果.每一列上方的数值指示了比值a/b(alpha/beta).
在这里我们展示了一个可以达到分离图片内容和风格的人工神经网络,因此它也可以用另一个图片的风格改写某张图片的内容.我们通过生成新的,艺术化的结合了一些有名的画作的风格和任意选定的照片的内容的合成图片来展示.特别的,我们推导出图片的内容和风格在神经网络中的表现的特征响应为了物体识别而训练的表现很好的深度神经网络.就我们所知,这是把整个自然图片的风格和内容的图片特征分开的首次展示.之前的在分离图片内容和风格上的工作所评估的图片的输入要简单很多,比如说不同的手写单词或者是人脸或者是不同姿势的小图片.
在我们的展示中,我们提供了一个在不同的有名的艺术作品风格下的给定图片.这个问题通常是由计算机视觉中的被称为相片拟真处理技术(photorealistic rendering)的方法研究的.在概念上更相关的方法使用了纹理转化来达到艺术风格转换.与此相反,通过使用为了物体识别训练的深度神经网络,我们在特征空间中使用的手法清楚得表现了图片高层的内容.
从为了物体识别训练的深度神经网络中提取的物征已经被应用到风格识别上来根据艺术作品产生的时期分类.那里,分类器是由原始的网络激活层训练的,我们将其称为内容表现.我们猜测向一个固定的特征空间的转化比如说我们的风格表现或许可以在风格分类上有一个更好的表现.
一般来说,我们合成图片的方法,混合了不同来源的内容和风格,提供了一个新的,有趣的工具来学习感知和艺术,风格和内容独立的图片通常的神经表现.我们可以设计新颖的激励(novel stiluli(?))来介绍两个独立的,感官上有意义的变体的源:图的表现(appearance)和内容 .我们想像这可能对于很多关于视觉感知的研究都会很有意义,范围从心理物理学(psychophysics)的功能影像到电生理学(electrophysiological)的神经记录.事实上,我们的工作提供了一个神经表达是怎样独立得捕获图片的内容和它被表达的风格的算法理解.重要的是,我们的风格表达的数学形式生成了一个清楚的,可检验的层次结构关于图现外观的表现,一直细微到一个神经元的层次.这个风格的表现简单地计算了在网络中不同种神经元的相互关系.提取的不同神经元间的相互关系是一种生物上可信的计算,也就是说,比如,由主要视觉系统中被称为的复杂细胞来执行.我们的结果表明了表现一个复杂细胞像沿着腹侧流(ventral stream)的不同处理过程的计算是一个可能的获得一个视觉输入的外观的内容独立的表达的方法.
总而言之一个被训练来处理一个生物视觉的核计算任务的神经系统,自动地学习允许图片内容和风格分离是很神奇的.或许可以这样解释,当学习物体识别时,这个网络变得对于所有的保留物体特征的图片变量都保持不变.因此,our ability to abstract content from style and therefore our ability to create and enjoy art might be primarily a preeminent(优秀的) signature of the powerful inference(推理) capabilities of our visual system.
Method
在正文中展示的结果是以VGG网络为基础产生的,一个在一般视觉物体识别的基准任务上可以和人类表现对抗的卷积神经网络,并且被大量地应用.我们使用由VGG19中的16个卷积层和5个池化层特征空间.我们不需要使用任何全连接层.这个模型公开可用而且可以在caffe框架中找到.为了图片合成我们用平均池化替代了最大池化来改进梯度流而且可以获得稍微更有感染力的结果.
事实上网络的每一层都定义了一个非线性的过滤器组,它的复杂性随着在网络中所在层的位置而增加.因此一个给定的输入图片x在CNN的每一层的编码的过滤器是响应图片的.一个有着Nl个不同的过滤器的层有Nl个特征图谱,每个图谱的大小Ml,Ml是特征图谱的长与宽的乘积.所以对于层L的响应可以被存储在矩阵中Fl中,Fij表示第i个过滤器在层L中的第j个位置的激活.为了可视化由不同层次编码的图片信息(图1,内容重构)我们对一个白噪声图片进行坡度下降来找到另外一张可以匹配原图的特征反应的图片.

根据这个式子关于图片x的梯度可以用标准差反向传播计算出来.因此我们可以改变原始的随机图片x直到它在特定的CNN的某层生成了和原始图片P相同的响应. The five content reconstructions in Fig 1 are from layers ‘conv1_1’ (a), ‘conv2_1’ (b), ‘conv3_1’ (c), ‘conv4_1’ (d) and ‘conv5_1’(e) of the original VGG-Network.
在CNN的顶端对网络每层的响应我们建立了一个风格表达来计算不同的过滤器响应间的相互联系,期望是接办输入图的空间扩展(taken over the spatial extend of the input image).这些特征间的相互联系是由Gram矩阵计算的,其中Gij(l)是向量化(vectorised)特征图谱i和j在层l上的内积:

为了生成一个匹配给定图片的纹理(图1,风格重构),我们从一个白噪声图梯度下降,找到一张与原始图片的风格匹配的图片.这是通过最小化原始图片的Gram矩阵和待生成图片的Gram矩阵之间的平均方差做到的.

在这里wl是每一层在total loss中所占的权值.El的导数可以用解析的方法计算出来:

El在更低层的导数可以很轻易地用标准差反向传播计算出来.图1中五个风格的重构是通过匹配在‘conv1_1’ (a), ‘conv1_1’ and ‘conv2_1’(b), ‘conv1_1’, ‘conv2_1’ and ‘conv3_1’(c),‘ conv1_1’, ‘conv2_1’, ‘conv3_1’ and ‘conv4_1’ (d),‘conv1_1’, ‘conv2_1’, ‘conv3_1’, ‘conv4_1’ and ‘conv5_1’ (e)的风格表现生成的.
为了生成混合了照片的内容和画作的风格的图片,我们共同最小化了白噪声在网络某一层到照片的内容表达的距离以及在CNN网络多层上到风格表达的距离.我们最小化的loss function是


References and Notes
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, 1097–1105(2012). URL http://papers.nips.cc/paper/4824-imagenet.
Taigman, Y., Yang, M., Ranzato, M. & Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, 1701–1708 (IEEE, 2014). URL http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6909616.
G ̈uc ̧l ̈u, U. & Gerven, M. A. J. v. Deep Neural Networks Reveal a Gradient in the Complexity of Neural Representations across the Ventral Stream. The Journal of Neuroscience 35, 10005–10014 (2015). URL http://www.jneurosci.org/content/35/27/10005.
Yamins, D. L. K. et al. Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proceedings of the National Academy of Sciences 201403112 (2014). URL
http://www.pnas.org/content/early/2014/05/08/1403112111.Cadieu, C. F. et al. Deep Neural Networks Rival the Representation of Primate IT Cortex for Core Visual Object Recognition. PLoS Comput Biol 10, e1003963 (2014). URL
http://dx.doi.org/10.1371/journal.pcbi.1003963.K ̈ummerer, M., Theis, L. & Bethge, M. Deep Gaze I: Boosting Saliency Prediction with Feature Maps Trained on ImageNet. In ICLR Workshop (2015). URL /media/publications/1411.1045v4.pdf.
Khaligh-Razavi, S.-M. & Kriegeskorte, N. Deep Supervised, but Not Unsupervised, Models May Explain IT Cortical Representation. PLoS Comput Biol 10, e1003915 (2014). URL
http://dx.doi.org/10.1371/journal.pcbi.1003915.Gatys, L. A., Ecker, A. S. & Bethge, M. Texture synthesis and the controlled generation of natural stimuli using convolutional neural networks. arXiv:1505.07376 [cs, q-bio] (2015). URL http://arxiv.org/abs/1505.07376. ArXiv: 1505.07376.
Mahendran, A. & Vedaldi, A. Understanding Deep Image Representations by Inverting Them. arXiv:1412.0035 [cs] (2014). URL http://arxiv.org/abs/1412.0035. ArXiv: 1412.0035.
Heeger, D. J. & Bergen, J. R. Pyramid-based Texture Analysis/Synthesis. In Proceedings of the 22Nd Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’95, 229–238 (ACM, New York, NY, USA, 1995). URL http://doi.acm.org/10.1145/218380.218446.
Portilla, J. & Simoncelli, E. P.A Parametric Texture Model Based on Joint Statistics of Complex Wavelet Coefficients. International Journal of Computer Vision 40, 49–70 (2000). URL
http://link.springer.com/article/10.1023/A%3A1026553619983.Tenenbaum, J. B. & Freeman, W. T. Separating style and content with bilinear models. Neural computation 12, 1247–1283 (2000). URL http://www.mitpressjournals.org/doi/abs/10.1162/089976600300015349.
Elgammal, A. & Lee, C.-S. Separating style and content on a nonlinear manifold. In Computer Vision and Pattern Recognition, 2004. CVPR 2004. Proceedings of the 2004 IEEE Computer Society Conference on, vol. 1, I–478 (IEEE, 2004). URL http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1315070.
Kyprianidis, J. E., Collomosse, J., Wang, T. & Isenberg, T. State of the ”Art”: A Taxonomy of Artistic Stylization Techniques for Images and Video. Visualization and Computer 14Graphics, IEEE Transactions on 19, 866–885 (2013). URL http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6243138.
Hertzmann, A., Jacobs, C. E., Oliver, N., Curless, B. & Salesin, D. H. Image analogies. In Proceedings of the 28th annual conference on Computer graphics and interactive techniques, 327–340 (ACM, 2001). URL
http://dl.acm.org/citation.cfm?id=383295.Ashikhmin, N. Fast texture transfer. IEEE Computer Graphics and Applications 23, 38–43(2003).
Efros, A. A. & Freeman, W. T. Image quilting for texture synthesis and transfer. In Proceedings of the 28th annual conference on Computer graphics and interactive techniques, 341–346 (ACM, 2001). URL http://dl.acm.org/citation.cfm?id=383296.
Lee, H., Seo, S., Ryoo, S. & Yoon, K. Directional Texture Transfer. In Proceedings of the 8th International Symposium on Non-Photorealistic Animation and Rendering, NPAR ’10, 43–48 (ACM, New York, NY, USA, 2010). URL http://doi.acm.org/10.1145/1809939.1809945.
Xie, X., Tian, F. & Seah, H. S. Feature Guided Texture Synthesis (FGTS) for Artistic Style Transfer. In Proceedings of the 2Nd International Conference on Digital Interactive Media in Entertainment and Arts, DIMEA ’07, 44–49 (ACM, New York, NY, USA, 2007). URL http://doi.acm.org/10.1145/1306813.1306830.
Karayev, S. et al. Recognizing image style. arXiv preprint arXiv:1311.3715 (2013). URL
http://arxiv.org/abs/1311.3715.Adelson, E. H. & Bergen, J. R. Spatiotemporal energy models for the perception of
. JOSA A 2, 284–299 (1985). URL http://www.opticsinfobase.org/josaa/fulltext.cfm?uri=josaa-2-2-284.
Simonyan, K. & Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556 [cs] (2014). URL http://arxiv.org/abs/1409.1556. ArXiv: 1409.1556.
Russakovsky, O. et al. ImageNet Large Scale Visual Recognition Challenge. arXiv:1409.0575 [cs] (2014). URL http://arxiv.org/abs/1409.0575. ArXiv:1409.0575.
Jia, Y. et al. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the ACM International Conference on Multimedia, 675–678 (ACM, 2014). URL http://dl.acm.org/citation.cfm?id=2654889.
作者:zhwhong
链接:https://www.jianshu.com/p/9f03b61fdeac
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
主要参考的文献有《A Neural Algorithm of Artistic Style》和《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》这两篇论文,
以及深度学习实践:使用Tensorflow实现快速风格迁移等文章,
代码参考了OlavHN/fast-neural-style和hzy46/fast-neural-style-tensorflow等。
Ref: http://www.cnblogs.com/z941030/p/7056814.html
"需体会网络结构设计的思路“ -- Jeff
Link:
画风移植(Style Transfer)是一项已经在图像处理领域发展了多年的技术。The Verge的这篇报道中提及了一个用神经网络进行艺术作品画风移植的实现,源自Leon A. Gatys等人在2015年8月发布的一篇论文A Neural Algorithm of Artistic Style,其效果如下:
该研究组已经将论文中使用的代码分享至Github,普通用户可以在Deepart网站或者Prisma App上体验该算法的效果。此外,Facebook App也在2016年底上线了类似的实现(相关论文在此查看)。
图像风格转换
图像的风格理论上可以通过多层网络来提取图像里面可能含有的一些有意思的特征。
(1)
根据前面第一篇论文中提出的方法,风格迁移的速度非常慢的。
在风格迁移过程中,把生成图片的过程当做一个“训练”的过程。每生成一张图片,都相当于要训练一次模型,这中间可能会迭代几百几千次。
(2)
从头训练一个模型相对于执行一个已经训练好的模型来说相当费时。现在根据前面第二篇论文提出的另一种模型,
使得把生成图片当做一个“执行”的过程,而不是一个“训练”的过程。
快速风格迁移的网络结构包含两个部分。
- 一个是“生成网络”(Image Transform Net),
- 一个是“损失网络”(Loss Network)。
生成网络输入层接收一个输入图片,最终输出层输出也是一张图片(即风格转换后的结果)。
模型总体分为两个阶段,训练阶段和执行阶段。模型如图所示。 其中左侧是生成网络,右侧为损失网络。
![]()
训练阶段:选定一张风格图片。训练过程中,将数据集中的图片输入网络,生成网络生成结果图片y,损失网络提取图像的特征图,将生成图片y分别与目标风格图片ys和目标输入图片(内容图片)yc做损失计算,根据损失值来调整生成网络的权值,通过最小化损失值来达到目标效果。
执行阶段:给定一张图片,将其输入已经训练好的生成网络,输出这张图片风格转换后的结果。
生成网络
对于生成网络,本质上是一个卷积神经网络,这里的生成网络是一个深度残差网络,不用任何的池化层,取而代之的是用步幅卷积或微步幅卷积做网络内的上采样或者下采样。这里的神经网络有五个残差块组成。除了最末的输出层以外,所有的非残差卷积层都跟着一个空间性的instance-normalization,和RELU的非线性层,instance-normalization正则化是用来防止过拟合的。最末层使用一个缩放的Tanh来确保输出图像的像素在[0,255]之间。除开第一个和最后一个层用9x9的卷积核(kernel),其他所有卷积层都用3x3的卷积核。
损失网络
损失网络φ是能定义一个内容损失(content loss)和一个风格损失(style loss),分别衡量内容和风格上的差距。对于每一张输入的图片x我们有一个内容目标yc一个风格目标ys,对于风格转换,内容目标yc是输入图像x,输出图像y,应该把风格ys结合到内容x=yc上。系统为每一个目标风格训练一个网络。
为了明确逐像素损失函数的缺点,并确保所用到的损失函数能更好的衡量图片感知及语义上的差距,需要使用一个预先训练好用于图像分类的CNN,这个CNN已经学会感知和语义信息编码,这正是图像风格转换系统的损失函数中需要做的。所以使用了一个预训练好用于图像分类的网络φ,来定义系统的损失函数。之后使用同样是深度卷积网络的损失函数来训练我们的深度卷积转换网络。
这里的损失网络虽然也是卷积神经网络(CNN),但是参数不做更新,只用来做内容损失和风格损失的计算,训练更新的是前面的生成网络的权值参数。所以从整个网络结构上来看:
- 输入图像通过生成网络得到转换的图像,
- 然后计算对应的损失,
- 整个网络通过最小化这个损失去不断更新前面的生成网络权值。
感知损失
对于求损失的过程,不用逐像素求差构造损失函数,转而使用感知损失函数,从预训练好的损失网络中提取高级特征。在训练的过程中,感知损失函数比逐像素损失函数更适合用来衡量图像之间的相似程度。
(1)内容损失
上面提到的论文中设计了两个感知损失函数,用来衡量两张图片之间高级的感知及语义差别。内容的损失计算用VGG计算来高级特征(内容)表示,因为VGG模型本来是用于图像分类的,所以一个训练好的VGG模型可以有效的提取图像的高级特征(内容)。计算的公式如下:
![]()
找到一个图像 y使较低的层的特征损失最小,往往能产生在视觉上和y不太能区分的图像,如果用高层来重建,内容和全局结构会被保留,但是颜色纹理和精确的形状不复存在。用一个特征损失来训练我们的图像转换网络能让输出非常接近目标图像y,但并不是让他们做到完全的匹配
(2)风格损失
内容损失惩罚了输出的图像(当它偏离了目标y时),所以同样的,我们也希望对输出的图像去惩罚风格上的偏离:颜色,纹理,共同的模式,等方面。为了达成这样的效果,一些研究人员等人提出了一种风格重建的损失函数:让φj(x)代表网络φ的第j层,输入是x。特征图谱的形状就是Cj x Hj x Wj、定义矩阵Gj(x)为Cj x Cj矩阵(特征矩阵)其中的元素来自于:
![]()
如果把φj(x)理解成一个Cj维度的特征,每个特征的尺寸是Hj x Wj,那么上式左边Gj(x)就是与Cj维的非中心的协方差成比例。每一个网格位置都可以当做一个独立的样本。这因此能抓住是哪个特征能带动其他的信息。梯度矩阵可以很高效的计算,通过调整φj(x)的形状为一个矩阵ψ,形状为Cj x HjWj,然后Gj(x)就是ψψT/CjHjWj。风格重建的损失是定义的很好的,甚至当输出和目标有不同的尺寸是,因为有了梯度矩阵,所以两者会被调整到相同的形状。
具体实现
GitHub地址mrxlz/ImageStyleTransform,实现基本上参考了hzy的代码,代码从原版迁移到了python3.5,TensorFlow1.0,具体实现代码基本没变,加了一些注释,添加了一个web页面,效果如下。
![]()
![]()
A Neural Algorithm of Artistic Style 图像风格转换 - keras简化版实现
前言
- 深度学习是最近比较热的词语。说到深度学习的应用,第一个想到的就是Prisma App的图像风格转换。既然感兴趣就直接开始干,读了论文,一知半解;看了别人的源码,才算大概了解的具体的实现,也惊叹别人的奇思妙想。
声明
- 代码主要学习了【titu1994/Neural-Style-Transfer】的代码,算是该项目部分的简化版或者删减版。这里做代码的注解和解释,也作为一个小玩具。
- 论文可以参考【A Neural Algorithm of Artistic Style】,网上也有中文的版本。
- 使用的工具:py34、keras1.1.2、theano0.8.2、GeForce GT 740M (CNMeM is disabled, cuDNN not available)。
实现原理
1. 总流程
实现流程如下,可以看到这里总共分为5层,本次实验使用vgg16模型实现的。

如上,a有个别名是
conv1_1,b是conv2_1,依次类推,c,d,e对应conv3_1,conv4_1,conv5_1;输入图片有风格图片style image和内容图片content image,输出的是就是合成图片,然后用合成图片为指导训练,但是训练的对象不像是普通的神经网络那样训练权值w和偏置项b,而是训练合成图片上的像素点,以达到损失函数不断减少的效果。论文使用的是随机的噪声像素图为初始合成图,但是使用原始图片会快一点。
2. 内容损失函数 - Content Loss
下面是content loss函数的定义。
l代表第l层的特征表示,p是原始图片,x是生成图片。公式的含义就是对于每一层,原始图片生成特征图和生成图片的特征图的一一对应做平方差。
3. 风格损失函数 - style loss
在定义风格损失函数之前首先定义一个Gram矩阵。
F是生成图片的特征图。上面式子的含义:Gram第i行,第j列的数值等于把生成图在第l层的第i个特征图与第j个特征图分别拉成一维后相乘求和。
![]()
- 上面是风格损失函数,
Nl是指生成图的特征图数量,Ml是图片宽乘高。a是指风格图片,x是指生成图片。G是生成图的Gram矩阵,A是风格图的Gram矩阵,wl是权重。
4. 总损失
- 总损失函数如下,
alpha与beta比例为1*10^-3或更小。
代码讲解
1. 图片预处理和还原
def preprocess_image(image_path):img = imread(image_path)// GPU显存有限,这里使用400*400大小的图片img = imresize(img, (400, 400)).astype('float32')// 这里要对RGB通道做预处理// 这里貌似是RGB的平均值,具体不清楚img = img[:, :, ::-1]img[:, :, 0] -= 103.939img[:, :, 1] -= 116.779img[:, :, 2] -= 123.68img = img.transpose((2, 0, 1)).astype("float32")img = np.expand_dims(img, axis=0)return imgdef deprocess_image(x):x = x.reshape((3, 400, 400))x = x.transpose((1, 2, 0))x[:, :, 0] += 103.939x[:, :, 1] += 116.779x[:, :, 2] += 123.68x = x[:, :, ::-1]x = np.clip(x, 0, 255).astype('uint8')return x2. content loss
def content_loss(base, combination):channel_dim = 0 if K.image_dim_ordering() == "th" else -1channels = K.shape(base)[channel_dim]size = 400 * 400multiplier = 1 / (2. * channels ** 0.5 * size ** 0.5)return multiplier * K.sum(K.square(combination - base))3. style loss
def gram_matrix(x):assert K.ndim(x) == 3features = K.batch_flatten(x)gram = K.dot(features, K.transpose(features))return gramdef style_loss(style, combination):assert K.ndim(style) == 3assert K.ndim(combination) == 3S = gram_matrix(style)C = gram_matrix(combination)channels = 3size = 400 * 400return K.sum(K.square(S - C)) / (4. * (channels ** 2) * (size ** 2))结果
输入:
![]()
![]()
输出:
![]()
![]()
分析
- 可以看出效果每一代都有进步,因为自己的显卡渣,跑一代估计要1.5个小时,自己测试的时候总共跑了14个小时,不过这里有个技巧,就是可以把上一代的图片继续做输入,这样中途有什么事就可以停止。下次只要把上次输出的图片当输入就可以。
- 因为是个小玩具,所以图片的切割都是用ps切出来的。其他的什么mask都没有实现。
- vgg16模型加载原项目的权值。
- 具体项目代码可见【自己的github项目】上的代码、权值文件和测试图片,因为中途修改过,可能有些地方需要改过来,不过代码比较简单,估计很快就可以找到问题了。
【深度学习】A neural algorithm of artistic style算法详解
2016年08月07日 11:45:17
阅读数:11379
Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. “A neural algorithm of artistic style.” arXiv preprint arXiv:1508.06576 (2015).
下面这篇发表于CVPR16,内容类似,排版更便于阅读。
Gatys, Leon A., Alexander S. Ecker, and Matthias Bethge. “Image Style Transfer Using Convolutional Neural Networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
概述
本文介绍Leon Gatys在2016年初大热的Style Transfer算法。这一算法结果直观,理论简洁,广受人民群众喜爱,在github上有各种平台的源码实现:
- 基于Torch的Neural-Style
- 基于Tensorflow的Neural Art
- 基于Caffe的Style Transfer。
本文的核心思路如下:
- 使用现成的识别网络,提取图像不同层级的特征。
- 低层次响应描述图像的风格,高层次响应描述图像的内容。
- 使用梯度下降方法,可以调整输入响应,在特定层次获得特定的响应。
- 多次迭代之后,输入响应即为特定风格和内容的图像。
【辨】一般网络层有如下形式
xt+1=f(Wxt+b)xt+1=f(Wxt+b)
网络的权重WW,网络的响应xt+1xt+1。
特别要强调的是,常见的深度学习问题利用输入-输出样本对训练网络的权重。这篇文章中,是利用已经训练好的权重,获取一个符合输出要求的输入。
复习:分类网络
直接使用VGG191分类网络(下图省略了末尾处做分类的几层)。和原始分类网络相比,本文仅将max pooling换成了average pooling,略微提升结果视效。
![]()
网络不同层次的响应描述了图像不同层次的信息:低层次描述小范围的边角、曲线,中层次描述方块、螺旋,高层次描述内容。
下文在提到“卷积层”时,实际指的是Conv+ReLU的复合体。用惯了Torch的同学尤其注意。
图像中的信息
使用分类网络中卷积层的响应来表达图像的风格和内容。
内容:响应
任取一张图像X0X0,将其输入上述分类网络。其第ll个卷积层的响应记为XlXl,其尺寸是Hl×Wl×NlHl×Wl×Nl。
对于目标图像X0¯¯¯¯¯¯¯X0¯,同样送入该网络,可以得到该层响应Xl¯¯¯¯¯¯Xl¯。
若希望X0X0和X0¯¯¯¯¯¯¯X0¯内容相似,可以最小化如下二范数误差:
Elc=12||Xl−Xl¯¯¯¯¯¯||2Ecl=12||Xl−Xl¯||2
这一误差可以对本层响应的每一元素求导2:
∂Elc∂xlhwk=xhwk−xhwk¯¯¯¯¯¯¯¯¯¯∂Ecl∂xhwkl=xhwk−xhwk¯
h=1,2...H,w=1,2...W,k=1,2...Nh=1,2...H,w=1,2...W,k=1,2...N
进一步,利用链式法则,可以求得误差对输入图像每一元素的导数∂Elc/∂x0hwk∂Ecl/∂xhwk0。这一步骤就是神经网络经典的back-propagation方法。
利用∂Elc/∂X0∂Ecl/∂X0来更新X0X0,可以获得一个新的输入图像,其在第l层的响应XlXl更接近目标图像的响应Xl¯¯¯¯¯¯Xl¯。也就是说:和目标图像的内容更接近。
风格:响应的矩阵积
先引入一个Nl×NlNl×Nl的特征矩阵GlGl:
Glij=∑hwxlhwi⋅xlhwjGijl=∑hwxhwil⋅xhwjl
i=1,2...N,j=1,2...Ni=1,2...N,j=1,2...N
GlGl由第l层的响应计算而来,但是消除了响应的位置信息,可以看做对于风格的描述。ij位置的元素描述第i通道响应和第j通道响应的相关性。
对于目标图像相应层的风格Gl¯¯¯¯¯Gl¯,最小化如下误差可以使X0X0和X0¯¯¯¯¯¯¯X0¯的风格近似:
Els=12||Gl−Gl¯¯¯¯¯||2Esl=12||Gl−Gl¯||2
可以求得误差对本层响应的导数:
∂Els∂xlhwk=(Xl)T(Gl−Gl¯¯¯¯¯)ji∂Esl∂xhwkl=(Xl)T(Gl−Gl¯)ji
同样可以通过back-propagation求得∂Els/∂X0∂Esl/∂X0,进而更新X0X0使其风格接近X0¯¯¯¯¯¯¯X0¯。
实验
以高斯噪声为初始输入图像,优化内容+风格的混合误差,多次执行前向/后向迭代使用L-BFGS方法优化,即可实现style transfer。其中:
内容层 - conv4_2
风格层 - conv1_1, conv2_1, conv3_1, conv4_1, conv5_1
权重
内容误差与风格误差的权重设为α,βα,β,两者之比从1×10−31×10−3到5×10−45×10−4,五个风格层权重相同。
当风格误差权重很高时,得到的结果近似风格图像的纹理。
风格层
和直觉相反,风格误差可以包含非常高的卷积层(conv5_1),反而有更自然,更“神似”的视觉效果。
![]()
这告诉我们:风格本身也是非常抽象的概念,需要较深的网络来描述。
速度
由于需要反复迭代,本文算法的速度很慢。512×512图像,使用NVIDIA K40 GPU,需要近1小时完成。
总结
这篇文章颇有一些启发:
- 深度学习不只是一头进一头出的“香肠工厂”。
-“识别”这个看似无关的高层任务包含了很丰富的信息。
我们并不需要特别训练,就能够欣赏非写实风格的绘画,识别其中的对象,辨认画家的风格。这说明人类在认识真实世界的过程中,就学习到了分别提取“内容”和“风格”的能力。
同样的,以真实世界物体训练的识别神经网络,也自然地能够分别提取“内容”和“风格”。
想要亲自体验的同学,可以使用DeepArt网站提交自己的风格图像和内容图像,不过免费版本需要等待几天。网站还提供了其他用户的精彩作品可以欣赏。
2016年夏季在俄罗斯大热的照片滤镜Prisma同样实现风格转移,只需等待几十秒到若干分钟,8月份的更新更是支持移动端的离线运算,不过其提速依赖于另外的论文。
在处理视频时,这篇文章考虑了结果的连续性和稳定性,这里有基于Torch的实现。
- K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556 [cs], Sept. 2014. arXiv: 1409.1556. 3 ↩
- 原文此处似乎混淆了非线性运算之前和之后的响应。 ↩
每个人都是梵高】A Neural Algorithm of Artistic Style
2016年01月12日 11:28:55
阅读数:15409
文章地址:A Neural Algorithm of Artistic Style
代码:https://github.com/jcjohnson/neural-style
这篇文章我觉得可以起个浪漫的名字——每个人都是梵高。
主要做的一件事情很有意思,就是如下图的等式,通过将a图的style和p图的content进行融合,得到第三幅图x。style+content=styled content
![]()
怎么做呢?首先他定义了两个loss,分别表示最终生成的图x和style图a的样式上的loss,以及x和content图p的内容上的loss,α,βα,β是调节两者比例的参数。最终的loss function是两者的加和。通过optimize总的loss求得最终的x。
![]()
Details
所用的CNN网络是VGG-16,利用了它16个卷积层和5个pooling层来生成feature。
假设某一层得到的响应是Fl∈RNl∗MlFl∈RNl∗Ml,其中NlNl为l层filter的个数,MlMl为filter的大小。FlijFijl表示的是第l层第i个filter在位置j的输出。
content loss
假设p和x在CNN中的响应分别为Pl和Fl,将他们内容上的loss表示成每个pixel的二范数:
![]()
则用梯度下降法,content loss对F求导为:
![]()
Style Loss
图x的style表示为Gl∈RNl∗NlGl∈RNl∗Nl,其中Glij=∑kFlik∗FljkGijl=∑kFikl∗Fjkl,即CNN同一层不同filter响应的互相关,至于为什么互相关能够表示style,well,I don’t know….
那么每一层style loss为
![]()
其中style图a的在CNN中的响应为A。
则总的style loss为每一层的加权和:
![]()
Total Loss
在定义好了两个loss的形式以后,又回到了最初的问题,就是最小化总的loss:
![]()
要注意的是,不同于一般的CNN优化,这里优化的参数不再是网络的w和b,而是初始输入的一张噪声图片x
![]()
最终我们想让他变成右图这样styled content。
Experiments
对同一张content图片运用不同style的结果如下图所示,fantastic!!
total loss中αα和ββ的比例:
从上到下表示的是运用不同conv层的feature进行style,conv1->conv5是一个从整体到局部的过程;
从左到右表示的是不同的α/βα/β的比例,10−510−5->10−210−2是指更注重style还是更强调content。
版权声明:本文为博主原创文章,转载请注明。 https://blog.csdn.net/elaine_bao/article/details/50502929
时间:2016年11月9日
译者:王小草
卷积神经网络是深层神经网络中处理图像最强大的一个类别。卷积神经网络由一层层小的计算单元(神经元)组成,可以以前馈的方式分层地处理视觉上的信息(图1)。每一层中的计算单元(神经元)可以被理解为是对过滤图像信息的收集,也就是说,每一个神经元都会从输入的图像中抽取某个特征。因此,每层的输出是由所谓的feature map组成,它们是对输入的图像进行不同类型的过滤得到的。(也就是说每个神经元都会关注图像的某个特征)
当卷积神经网络被训练用于物体识别时,会生成一个图像的表征(representations) ,随着处理层级的上升,物体的信息越来越明确。因此,随着神经网络中的层级一级一级地被处理,输入的图像会被转换成一种表征,与图片的像素细节相比,这种表征会越来越关注图片的实际内容。通过对某一层的提取出来的feaure map的重塑,我们可以直接看到该层包含的图片信息。层级越高,那么获取的图像中物体内容就越高质量,并且没有确切的像素值的约束(层级越高,像素丢失越多)。相反,在低层级中重塑的话,其实像素丢失地很少。所以我们参考的是神经网络高层的特征,用它来作为图片内容的表征。(因为我们要得到更多内容,更少像素)–内容表征
为了获取输入图像的风格表征,我们用一个特征空间去捕获纹理的信息。这个特征空间建立在每层神经网络的过滤响应之上(也就是上面提到的feature map)。在feature map的空间范围上(也就是同一层上的feature map),过滤响应各有不同(feature map关注的特征不同),而这个特征空间就是由这些差异构成。对每一层featute map两两求相关性,我们会获得一个静态的,多尺度的图像表征,它捕获了纹理的信息(但这纹理信息并非全局的)。–风格表征
译者总结:上面三段简而言之就是讲了三句话:
1.每个卷基层是有多个神经元组成,每个神经元输出的是一个feature map。
2.神经网络较高层输出的一组feature map是内容表征。
3.神经网络某一层输出的一组feature map,使他们两两求相关性,这个相关性就是风格表征。
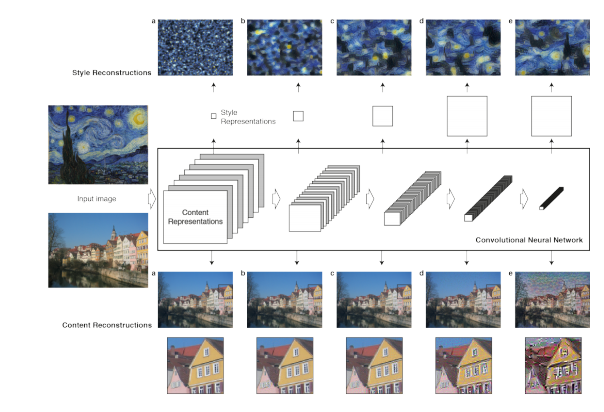
图1:
卷积神经网络(CNN)
一张输入的图片,会在卷积神经网的各层以一系列过滤后的图像表示。随着层级的一层一层处理,过滤后的图片会通过向下取样的方式不断减小(比如通过池化层)。这使得每层神经网的神经元数量会原来越小。(也就是层越深,因为经过了池化层,单个feature map会越来越小,于是每层中的神经元数量也会越来越少)
内容重塑
在只知道该层的输出结果,通过重塑输入图像,我们可以看到CNN不同阶段的图像信息。我们在原始的VGG-Network上的5个层级:conv1_1,conv1_2,conv1_3,conv1_4,conv1_5上重塑了输入的图像。
输入的图像是上图中的一排房子,5个层级分别是a,b,c,d,e。
我们发现在较低层的图像重构(abc)非常完美;在较高层(de),详细的像素信息丢失了。也就是说,我们提取出了图片的内容,抛弃了像素。
风格重塑
在原始的CNN表征之上(feature map),我们建立了一个新的特征空间(feature space),这个特征空间捕获了输入图像的风格。风格的表征计算了在CNN的不同层级间不用特征之间的相似性。通过在CNN隐层的不同的子集上建立起来的风格的表征,我们重构输入图像的风格。如此,便创造了与输入图像一致的风格而丢弃了全局的内容。
于是,同样,我们也可以在CNN的各层中利用风格特征空间所捕获的信息来重构图像。事实上,重塑风格特征就是通过捕获图片的颜色啊结构啊等等生产出输入的图像的纹理的版本。另外,随着层级的增加,图像结构的大小和复杂度也会增加。我们将这多尺度的表征称为风格表征。
本文关键的发现是对于内容和风格的表征在CNN中是可以分开的。我们可以独立地操作两个表征来产生新的,可感知意义的图像。为了展示这个发现,我们生成一个图像,这个图像混合了来自两个不同图像的内容和风格表征。确切的说,我们将著名艺术画“星空”的风格,和一张德国拍的照片的内容混合起来了。
我们寻找这样一张图片,它同时符合照片的内容表征,和艺术画的风格表征。原始照片的整体布局被保留了,而颜色和局部的结构却由艺术画提供。如此一来,原来的那张风景照旧像极了艺术作品。

图2:
图中描述的是同一张风景照的内容,融合来自不同的风景画的风格的图片。
风格表征是一个多尺度的表征,包括了神经网络的多层。在图2中看到的图像,风格的表征包含了整个神经网络的层级。而风格也可以只包含一小部分较低的层级。(见下面的图3,第一行是卷基层1,第5行是卷基层5的输出)。若符合了较高层级中的风格表征,局部的图像结构会大规模地增加,从而使得图像在视觉上更平滑与连贯。因此,看起来美美的图片通常是来自于符合了较高层级的风格表征。

当然啦,图像的内容和风格并不能被完全地分解开。当风格与内容来自不同的两个图像时,这个被合成的新图像并不存在在同一时刻完美地符合了两个约束。但是,在图像合成中最小化的损失函数分别包括了内容与风格两者,它们被很好地分开了。所以,我们可以平滑地将重点既放在内容上又放在风格上(可以从图3的一列中看出)。将重点过多地放在风格上会导致图像符合艺术画的外观,有效地给出了画的纹理,但是几乎看不到照片的内容了。而将重点过多地放在内容上,我们可以清晰地看到照片,但是风格就不那么符合艺术画了。因此,我们要在内容与风格之间调整trade-off,这样才能创造出美美的画。
在之前的研究中,是通过评估复杂度小很多的感官输入来将内容与风格分离的。比如说通过不同的手写字,人脸图,或者指纹。
而在我们的展示中,我们给出了一个有着著名艺术作品风格的照片。这个问题常常会更靠近与计算机视觉的一个分支–真实感渲染。理论上更接近于利用纹理转换来获取艺术风格的转换。但是,这些以前的方法主要依赖于非参数的技术并且直接对图像表征的像素进行操作。相反,通过在物体识别上训练深度神经网了,我们在特征空间上进行相关操作,从而明确地表征了图像的高质量内容。
神经网络在物体识别中产生的特征先前就已经被用来做风格识别,为的是根据艺术作品的创作时期来为作品分类。分类器是在原始的网络上被训练的,也就是我们现在叫的内容表征。我们猜测静态特征空间的转换,比如我们的风格表征也许可以在风格分类上有更好的表现。
通常来说,我们这种合成图像的方法提供了一个全新的迷人的工具用于学习艺术,风格和独立于内容的图像外观的感知与神经表征。总之,一个神经网络可以学习图像的表征,是的图像内容与风格的分离成为可能,是如此激动人心。若要给出解释的话,就是当学习物体识别到时候,神经网络对所有图像的变化都能保持不变从而保留了物体的特性。
方法论:
上文展示的结果是依赖于卷积神经网络–VGG神经网络模型产生的。我们使用由19层的VGG神经网络(16个卷积和5个池化层)提供的特征空间。并且这个神经网络中没有一个是全链接的。这个模型是可以被公开获取的,并且可以caffe这个深度学习的框架中被调用。对于图像合成,我们发现用均值池化层代替最大值池化层会提高梯度流,并且得到更加完美的结果。所以本案例中我们用的是均值池化层。–模型概述
每一层神经网络定义了一个非线性的过滤器(这里所说的过滤器就是神经元),这个过滤器的复杂度随着隐层的位置而增加。因此,给定一个输入的图像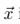 ,在CNN的每层都会被过滤器编码。一个有Nt个不同的过滤器的隐层有Nt个feature map(每个神经元输出一个feature map)。每个feature map的大小是Mt,Mt是feature map高乘以宽的大小。所以一个层的输出可以存储为矩阵:
,在CNN的每层都会被过滤器编码。一个有Nt个不同的过滤器的隐层有Nt个feature map(每个神经元输出一个feature map)。每个feature map的大小是Mt,Mt是feature map高乘以宽的大小。所以一个层的输出可以存储为矩阵: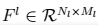 。
。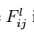 表示在l层的位置j上的第i个过滤器的激活结果。为了可视化不同层级中的图像信息,我们在一个白噪声上使用梯度下降来找到另一个图像,它与原始图像的特征输出结果相符合(白噪声上的图像其实就是定义一个随机的新图,然后通过梯度下降不断迭代,不断更新这个新图)。所以,让
表示在l层的位置j上的第i个过滤器的激活结果。为了可视化不同层级中的图像信息,我们在一个白噪声上使用梯度下降来找到另一个图像,它与原始图像的特征输出结果相符合(白噪声上的图像其实就是定义一个随机的新图,然后通过梯度下降不断迭代,不断更新这个新图)。所以,让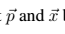 作为原始图像和后来产生的图像,
作为原始图像和后来产生的图像,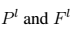 是他们在l层各自的特征表征。然后我们定义两个特征表征之间的平方误差损失。
是他们在l层各自的特征表征。然后我们定义两个特征表征之间的平方误差损失。
(也就是,输出的结果是14*14*256的矩阵,256是该层神经元的个数,14*14是feature map,将照片与新图都走一遍这个CNN,他们各自会生成以上矩阵,也就是P和F,将这两个矩阵在对应的位置求平方误差和,就是内容上的损失函数。乘以1/2是为了求导方便)
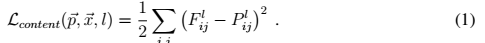
这个损失函数的导数是:(针对F求导)
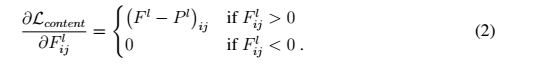
以上公式中,图像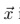 的梯度可以通过标准误差的后向计算传播。因此我们可以改变初始的随机图像
的梯度可以通过标准误差的后向计算传播。因此我们可以改变初始的随机图像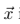 ,直到它产生了在CNN中与原始图像
,直到它产生了在CNN中与原始图像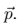 一样的输出结果。在图1中的5个内容重构来自于原始VGG的
一样的输出结果。在图1中的5个内容重构来自于原始VGG的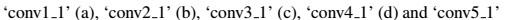
另外,我们通过计算不同过滤器输出结果之间的差异,来计算相似度。我们期望获得输入图片空间上的衍生。这些特征的相似性用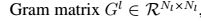 给出。
给出。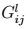 是产自于l层中矢量的feature map i 和j 之间。
是产自于l层中矢量的feature map i 和j 之间。
(直译心好累,解释一下上面讲的,就是将艺术画也放进CNN中,比如输出也是14*14*256的一个矩阵,然后将256个14*14的feature map两两求相似性,这里是两两相乘,于是会得带256*256的一个特征空间矩阵,G就是这个特征空间)

为了生成符合给定艺术作品风格的纹理,我们对一个带有白噪声的图像(也就是我们定义的随机的新图)做梯度下降,从而去寻找另一个图像,使得这个图像符合艺术画的风格表征。而这个梯度下降的过程是通过使得原始图像(艺术画)的Gram矩阵和被生成的图像(新图)的Gram矩阵的距离的均方误差最小化得到的。因此,令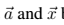 分别作为原始艺术图像与被生成的图像,
分别作为原始艺术图像与被生成的图像,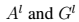 分别作为l层的两个风格表征。l层对于总损失的贡献是:
分别作为l层的两个风格表征。l层对于总损失的贡献是:
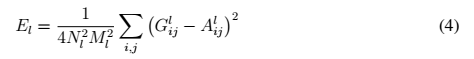
而总损失用公式表达为:

wt表示每一层对于总损失的贡献的权重因子。Et的导数可以这样计算:
El的在低层级的梯度可以很方便地计算出来,通过标准误差后向传播。在图1中5个风格的重塑可以通过满足一下这些层的风格表征来生成:
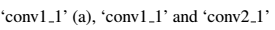

为了生成混合了照片内容和艺术画风格的新图像,我们需要联合最小化风格损失与内容损失:
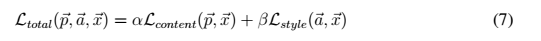
α和β分别是内容和风格在图像重构中的权重因子。α和β分别是内容和风格两个损失的权重。α+β=1.如果α比较大,那么输出后的新图会更多地倾向于内容上的吻合,如果β较大,那么输出的新图会更倾向于与风格的吻合。这两个参数是一个trade-off,可以根据自己需求去调整最好的平衡。论文的作者给出了它调整参数的不同结果,如下图,从左到右四列分别是α/β = 10^-5, 10^-4,10^-3, 10^-2.也就是α越来越大,的确图像也越来越清晰地呈现出了照片的内容。

版权声明:本文为王小草原创文章,要转载请先联系本人哦 https://blog.csdn.net/sinat_33761963/article/details/53521292
用深度学习模仿大师绘画的程序已经开源很久,但都是在乌版图系统tensorflow今天按捺不住自己的心情,心血来潮,开始探索在windows 下跑一下这个demo.
需求环境
1. win10
2. matlab 2016b
3. matcovnet version 1.0-beta22 下载地址:http://www.vlfeat.org/matconvnet/download/
4. demo(已编译matcovnet version 1.0-beta22cpu版本) 下载地址:https://github.com/unsky/draw-style
5. imagenet-vgg-verydeep-16 下载地址 http://www.vlfeat.org/matconvnet/pretrained/
demo里已经把编译环境全部编译好,目前是cpu版本,可以使用vl_complienn(2)命令编译GPU环境。
先运行vl_setupnn.m启动matcovnet
代码部分修改使用与matcovnet version 1.0-beta22改变一下图片的路径即可。直接运行:neuralStyle.m
具体的效果,使用1080GPU一分钟左右搞定,cpu半个小时(主要看机器)
学习的风格图片:
![]()
要绘制的图片:
![]()
绘制结果:
![]()
具体论文实现大家可以看代码或者看原论文:
@article{gatys2015neural,
title={A neural algorithm of artistic style},
author={Gatys, Leon A and Ecker, Alexander S and Bethge, Matthias},
journal={arXiv preprint arXiv:1508.06576},
year={2015}
}
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/m5482968/article/details/52729531
《A Neural Algorithm of Artistic Style》理解
在美术中,特别是绘画,人类掌握了通过在图像的内容和风格间建立复杂的相互作用从而创造独特的视觉体验的技巧。到目前为止,这个过程的算法基础是未知的,也没有现存的人工系统拥有这样的能力。然而在视觉感知的其他重要方向,如目标和人脸识别,一种受生物启发的深层神经网络最近展示了接近人类的表现。本文介绍了一种基于深层神经网络的人工神经网络系统,能够产生高感知质量的图片。该系统利用神经表示来分离和重组任意图像的内容和风格,为艺术图片创作提出了一种神经算法。不仅如此,在性能优良的人工神经网络和生物视觉的相似性之间,我们的工作提供了一条人类如何创造和感知艺术图像的算法理解之路。
深层神经网络中最善于处理图片任务的是卷积神经网络。卷积神经网络包含多个小计算单元,以前馈方式分层次地处理视觉信息。如下图1所示。每一层的单元可以认为是图片过滤器的集合,每一个都会从输入图片中提取一个特定的特征。因此输出层也被称为特征映射:对输入图片进行不同的滤波。
当卷积神经网络用于物体识别的训练时,它们学习到的图片表达随着处理层次信息变得越来越清晰。因此,随着网络的处理层次,输入图片转换成的表达越来越关注实际的图片内容而不是具体像素值。我们可以通过从特征映射中重建图片直接可视化每层包含的输入图片的信息(如图1,可以了解下如何重建图片的方法细节)。网络中的高层捕获物体中的高层次信息,它们的分布在输入图片中,但是重建不限于精确的像素值。与之相反,低层重建只是简单地从原图复制精确像素值。因此我们也称网络中的高层特征响应为内容表达。
![]()
为了获得输入图片的风格表达,我们使用最初设计的特征空间来捕获纹理信息。这个特征空间建立在网络中每一层的滤波器响应之上。它由不同过滤器响应在特征映射空间的相关性组成。通过包含多个层的特征相关性,我们获得了对于输入图片固定的,多尺寸的表达,它捕获到了纹理信息而不是全局分布。
我们能够通过建立与给定输入图片风格表达相匹配的图片来可视化这些建立在网络中不同层的风格特征空间捕获到的信息。实际上从风格特征中重建出了输入图片的纹理版本,它捕获了色彩和局部结构的综合表现。不仅如此,来自输入图像的局部图像结构的大小和复杂度也随着层次增加,这个是因为感受野的尺寸和特征复杂度在增加。我们称这种多尺寸的表达为风格表达。
这篇论文主要是发现了卷积神经网络的内容和风格是可以分割的。我们可以独立操纵表达来产生一个新的,感知上有意义的图片。为了演示这个发现,我们从两个不同的源图片生成了混合内容和风格表达的图片。如下图2所示,我们将描述“Neckarfront”的内容表达与一些不同时期有名的艺术作品相匹配。
![]()
这些图片通过寻找同时匹配照片内容表达与艺术作品风格表达的图片进行合成。虽然原始图片的全局分布被保存,但是构成全局的颜色和局部结构由艺术作品提供。实际上这使图片呈现出艺术风格,虽然内容是相同的,但是合成图片看起来像艺术图片。
如以上总结的,风格表达是个多尺寸的表达,包含神经网络的多个层。如上图2所示,风格表达包含来自全部网络层次的层。也可以仅仅包含少量的较低层定义一个更加局部的风格,这会带来不同的视觉体验,如下图3所示。当匹配网络中更高层的风格表达时,局部图片结构与更大的尺寸匹配,这会带来更细致连续的视觉感受。事实上,视觉上更吸引人的图片通常是与网络中最高层的风格表达匹配得来的。
当然,图片内容与风格不能完全分离。当结合不同图片的内容和风格合成新图片时,往往不存在一个图片完全同时匹配两种约束。然而,我们在图片合成时最小化的loss函数分别包含内容和风格两方面,它们很好地分隔开。我们因此可以顺利地调整侧重点,是选择注重重建内容还是风格。当过分强调风格时会导致图片与艺术作品的外貌相匹配,而看不清任何照片内容(下图3第1列)。当过分强调内容时,我们能够很清楚辨认图片,但是绘画风格又没有很好匹配(图3最后一列)。对于一个特定原图片对,我们可以调整比例来产生视觉上有吸引力的图片。
这里我们提出了一个人工神经网络实现了图片内容和风格的分离,因此允许使用任何另一张图片的风格来重铸图片内容。我们通过创建新的艺术图片来展示这点,它结合了一些有名的绘画风格与任意选择的图片内容。实际上,我们从用于目标识别的深层神经网络的特征响应中推导出了图片内容和风格的神经表达。据我们所知,这是第一次在整体的自然图片中展示图片内容与风格特征的分离。此前内容和风格上的分割工作的评估在一些复杂程度低得多的感官输入上进行,比如不同的手写字体或者不同姿态的人脸和小图片。
![]()
![]()
在演示中,我们以一系列著名的艺术作品风格来渲染一张照片。这个问题通常是一个计算机视觉的分支,称为非光性渲染。概念上最密切相关的方法是使用纹理转换达到艺术风格转换。然而,此前的这些方法主要依赖于非参数的技术直接操纵图像的像素表达。与之相反,使用在目标检测上训练的深层神经网络时,我们是在特征空间进行操作,它们明确表达了一张图片的高层次的内容。
在目标检测任务上训练的深层神经网络的特征此前已被用于风格识别,为的是根据艺术作品创作的时间进行分类(论文[20])。这里的分类器在原始网络响应的最顶端进行训练,被称为是内容表达。我们推测一个转换成一个固定的空间,所以我们的风格表达可能在风格分类中达到一个更好的表现。
总的来说,我们合成图片的方法从不同来源混合了内容和风格。提供了新的,有吸引力的工具来研究一般的艺术,风格,内容独立的图片外观的感知和神经表现。我们可以设计新的刺激引入两个独立的,感知上有意义的差异来源:图片外观和图片内容。我们设想这将在广泛有关视觉感知的实验研究上发挥作用,涉及心理物理学,功能成像甚至是电生理神经记录。实际上,我们的工作提供了一个算法理解神经表达如何独立捕捉图片的内容和风格。重要的是,数学上我们的风格表达生成了一个清晰,可验证的hypothesis,关于图片外观的表达下达到了单个神经元的层面。风格表达简单计算网络中不同类型神经元之间的联系。计算神经元之间的联系在生物上是一个合理的运算,例如在主视觉系统中,这一功能被所谓的复杂细胞实现。我们的结果表明沿着流的方向在不同的处理阶段执行类似复杂细胞的运算或许是获得视觉输入外观内容独立表达的一种可能方法。
总而言之这是一个令人着迷的神经系统,它被训练去执行一个生物视觉的核心计算任务,自动学习图片表达,能够允许图片内容和风格分离。可能的解释是当学习目标识别时,网络已经保存了目标个体而对所有图片变异具有不变性。将图片内容和外观进行分解的表示,对于这项任务是很实际的。因此,我们从风格中抽象内容的能力,创造和享受艺术的能力,可能是我们视觉系统强大推理能力的主要特征。
Method:
在主要文本中生成的结果是基于VGG网络的,它是一个卷积神经网络,在通用的视觉目标识别任务上取得了和人类表现相当的结果,被广泛使用。我们使用拥有16个卷积和5个池化层的VGG网络提供的特征空间。我们没有使用任何全连接层。这个模型是公开可获取的,可以在caffe-framework中获得。对于图片合成我们发现将最大池化替换为平均池化改善了梯度流动可以获得更吸引人的效果,这就是为什么展示的生成图片是使用平均池化的原因。网络中每一层定义了一组非线性的滤波器,它们的复杂度随着层在网络中的位置增加。因此给定一个输入图片![]() 在CNN中每一层都被滤波器的响应编码。一个拥有
在CNN中每一层都被滤波器的响应编码。一个拥有![]() 个不同过滤器的层拥有大小为
个不同过滤器的层拥有大小为![]() 的
的![]() 个特征映射,这里的
个特征映射,这里的![]() 等于特征映射的高度乘以宽度。所以l层的响应可以存储在矩阵
等于特征映射的高度乘以宽度。所以l层的响应可以存储在矩阵![]() ,这里
,这里![]() 是指在l层,位置j处的第i个过滤器。所以当原始图片为
是指在l层,位置j处的第i个过滤器。所以当原始图片为![]() 时,l层的特征表达分别为
时,l层的特征表达分别为![]() 。然后我们定义两个特征表达的平方差:
。然后我们定义两个特征表达的平方差:
![]()
在l层的loss相对响应梯度为:
![]()
这样我们能够使用标准的后向传播流程计算相对于图片![]() 的梯度。我们能够改变初始随机图片
的梯度。我们能够改变初始随机图片![]() 直到它在特定层产生和原始图片
直到它在特定层产生和原始图片![]() 相同的响应。图1中的5个内容重建来源于原始VGG网络的conv1_1(a),conv2_1(b),conv3_1(c),conv4_1(d)和conv5_1(e)层。
相同的响应。图1中的5个内容重建来源于原始VGG网络的conv1_1(a),conv2_1(b),conv3_1(c),conv4_1(d)和conv5_1(e)层。
在网络中每一层CNN响应的顶端我们建立了一个风格表达来计算不同滤波器响应之间的相关性,期望对输入图片进行空间扩展。这里的特征相关性由Gram矩阵![]() 表示,这里的
表示,这里的![]() 是l层向量化的特征映射i和j的内积
是l层向量化的特征映射i和j的内积
![]()
为了生成的纹理与给定图片相同(图1,风格重建),我们使用图片梯度从白噪声图片寻找另一张图片与原始图片的风格表达匹配。这是通过最小化原始图片和生成图片间Gram矩阵平均平方距离实现的。所以当![]() 分别代表原始图片和生成图片时,
分别代表原始图片和生成图片时,![]() 分别代表l层的风格表达。这一层对于总体loss的贡献为:
分别代表l层的风格表达。这一层对于总体loss的贡献为:
![]()
整体loss为:
![]() 这里的
这里的![]() 是每一层对于总体loss的权重(下面给出了我们结果中
是每一层对于总体loss的权重(下面给出了我们结果中![]() 的特定值)。
的特定值)。![]() 相对于l层的响应的导数可以如下计算:
相对于l层的响应的导数可以如下计算:
![]()
![]() 对应网络中低层响应的梯度可以使用使用标准的后向传播计算。图1中的5个风格重建生成是匹配conv1_1(a),conv1_1和conv2_1(b),conv1_1,conv2_1和conv3 _1(c),conv1_1,conv2_1,
对应网络中低层响应的梯度可以使用使用标准的后向传播计算。图1中的5个风格重建生成是匹配conv1_1(a),conv1_1和conv2_1(b),conv1_1,conv2_1和conv3 _1(c),conv1_1,conv2_1,
conv3 _1 和conv4 _1(d), conv1_ 1, conv2_1, conv3_1, conv4 _1, 和conv5 _1(e)层的风格。
为了生成混合图片内容和绘画风格的图片,我们联合优化白噪声图片与网络中照片的一层内容表达与绘画中多层风格表达的距离。令![]() 为照片,
为照片,![]() 为艺术作品。我们优化的loss函数为:
为艺术作品。我们优化的loss函数为:
![]()
这里的![]() 分别为内容和风格重建的比例。对于图2,我们的操作是匹配conv4_2的内容表达与conv1_1,conv2_1,conv3_1,conv4_1和conv5_1的风格表达(每一层的
分别为内容和风格重建的比例。对于图2,我们的操作是匹配conv4_2的内容表达与conv1_1,conv2_1,conv3_1,conv4_1和conv5_1的风格表达(每一层的![]() ,其他层的为0)。
,其他层的为0)。![]() 的比例为
的比例为![]() (图2的B,C,D)或
(图2的B,C,D)或![]() 图2的E,F)。图3展示了使用不同内容和风格重建loss相对比例的效果,匹配的风格表达层分别为conv1_1(A),conv1_1和conv2_1(B), conv1_1,conv2_1和conv3_1(C), conv1_1, conv2_1, conv3_1和conv4_1(D),conv1_1, conv2_1,conv3_1,conv4_1和conv5_1(E)。因子
图2的E,F)。图3展示了使用不同内容和风格重建loss相对比例的效果,匹配的风格表达层分别为conv1_1(A),conv1_1和conv2_1(B), conv1_1,conv2_1和conv3_1(C), conv1_1, conv2_1, conv3_1和conv4_1(D),conv1_1, conv2_1,conv3_1,conv4_1和conv5_1(E)。因子![]() 始终等于1除以非零loss权重的响应层数目。
始终等于1除以非零loss权重的响应层数目。
深度学习(图像处理)A Neural Algorithm of Artistic Style 图像风格转换 - keras简化版实现
2017年09月26日 15:42:59
阅读数:359
前言
- 深度学习是最近比较热的词语。说到深度学习的应用,第一个想到的就是Prisma App的图像风格转换。既然感兴趣就直接开始干,读了论文,一知半解;看了别人的源码,才算大概了解的具体的实现,也惊叹别人的奇思妙想。
声明
- 代码主要学习了【titu1994/Neural-Style-Transfer】的代码,算是该项目部分的简化版或者删减版。这里做代码的注解和解释,也作为一个小玩具。
- 论文可以参考【A Neural Algorithm of Artistic Style】,网上也有中文的版本。
- 使用的工具:py34、keras1.1.2、theano0.8.2、GeForce GT 740M (CNMeM is disabled, cuDNN not available)。
实现原理
1. 总流程
实现流程如下,可以看到这里总共分为5层,本次实验使用vgg16模型实现的。
如上,a有个别名是
conv1_1,b是conv2_1,依次类推,c,d,e对应conv3_1,conv4_1,conv5_1;输入图片有风格图片style image和内容图片content image,输出的是就是合成图片,然后用合成图片为指导训练,但是训练的对象不像是普通的神经网络那样训练权值w和偏置项b,而是训练合成图片上的像素点,以达到损失函数不断减少的效果。论文使用的是随机的噪声像素图为初始合成图,但是使用原始图片会快一点。
2. 内容损失函数 - Content Loss
下面是content loss函数的定义。
l代表第l层的特征表示,p是原始图片,x是生成图片。公式的含义就是对于每一层,原始图片生成特征图和生成图片的特征图的一一对应做平方差。
3. 风格损失函数 - style loss
在定义风格损失函数之前首先定义一个Gram矩阵。
F是生成图片的特征图。上面式子的含义:Gram第i行,第j列的数值等于把生成图在第l层的第i个特征图与第j个特征图分别拉成一维后相乘求和。
![]()
- 上面是风格损失函数,
Nl是指生成图的特征图数量,Ml是图片宽乘高。a是指风格图片,x是指生成图片。G是生成图的Gram矩阵,A是风格图的Gram矩阵,wl是权重。
4. 总损失
- 总损失函数如下,
alpha与beta比例为1*10^-3或更小。
代码讲解
1. 图片预处理和还原
def preprocess_image(image_path):img = imread(image_path)// GPU显存有限,这里使用400*400大小的图片img = imresize(img, (400, 400)).astype('float32')// 这里要对RGB通道做预处理// 这里貌似是RGB的平均值,具体不清楚img = img[:, :, ::-1]img[:, :, 0] -= 103.939img[:, :, 1] -= 116.779img[:, :, 2] -= 123.68img = img.transpose((2, 0, 1)).astype("float32")img = np.expand_dims(img, axis=0)return imgdef deprocess_image(x):x = x.reshape((3, 400, 400))x = x.transpose((1, 2, 0))x[:, :, 0] += 103.939x[:, :, 1] += 116.779x[:, :, 2] += 123.68x = x[:, :, ::-1]x = np.clip(x, 0, 255).astype('uint8')return x
2. content loss
def content_loss(base, combination):channel_dim = 0 if K.image_dim_ordering() == "th" else -1channels = K.shape(base)[channel_dim]size = 400 * 400multiplier = 1 / (2. * channels ** 0.5 * size ** 0.5)return multiplier * K.sum(K.square(combination - base))
3. style loss
def gram_matrix(x):assert K.ndim(x) == 3features = K.batch_flatten(x)gram = K.dot(features, K.transpose(features))return gramdef style_loss(style, combination):assert K.ndim(style) == 3assert K.ndim(combination) == 3S = gram_matrix(style)C = gram_matrix(combination)channels = 3size = 400 * 400return K.sum(K.square(S - C)) / (4. * (channels ** 2) * (size ** 2))
结果
输入:
![]()
![]()
输出:
![]()
![]()
分析
- 可以看出效果每一代都有进步,因为自己的显卡渣,跑一代估计要1.5个小时,自己测试的时候总共跑了14个小时,不过这里有个技巧,就是可以把上一代的图片继续做输入,这样中途有什么事就可以停止。下次只要把上次输出的图片当输入就可以。
- 因为是个小玩具,所以图片的切割都是用ps切出来的。其他的什么mask都没有实现。
- vgg16模型加载原项目的权值。
- 具体项目代码可见【自己的github项目】上的代码、权值文件和测试图片,因为中途修改过,可能有些地方需要改过来,不过代码比较简单,估计很快就可以找到问题了。
VGG实现《A Neural Algorithm of Artistic Style 》
该代码是实现A Neural Algorithm of Artistic Style ,具体可以参考https://github.com/apache/incubator-mxnet/tree/master/example/neural-style
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
|
![]()
#参数设置 import nstyle # Load code for neural style training args = nstyle.get_args([]) # get the defaults args object# Stopping criterion. A larger value means less time but lower quality. # 0.01 to 0.001 is a decent range. args.stop_eps = 0.005# Resize the long edge of the input images to this size. # Smaller value is faster but the result will have lower resolution. args.max_size = 600# content image weight. A larger value means more original content. args.content_weight = 10.0# Style image weight. A larger value means more style. args.style_weight = 1.0# Initial learning rate. Change this affacts the result. args.lr = 0.001# Learning rate schedule. How often to decrease and by how much args.lr_sched_delay = 50 args.lr_sched_factor = 0.6# How often to update the notebook display args.save_epochs = 50# How long to run for args.max_num_epochs = 1000# Remove noise. The amount of noise to remove. args.remove_noise = 0.02args.content_image = content_path args.style_image = style_pathargs.output_dir = 'output/' ensure_dir(args.output_dir)
![]()
![]()
import IPython.display
import mxnet.notebook.callback
import matheps_chart = mxnet.notebook.callback.LiveTimeSeries(y_axis_label='log_10(eps)',# Setting y-axis to log-scale makes sense, but bokeh has a bug# https://github.com/bokeh/bokeh/issues/5393# So I'll calculate log by hand below.#y_axis_type='log', )
def show_img(data):eps_chart.update_chart_data(math.log10(data['eps']))if data.get('filename',None):IPython.display.clear_output()print("Epoch %d\neps = %g\n" % (data['epoch'], data['eps']))h = IPython.display.HTML("<img src='"+data['filename']+"'>")IPython.display.display(h)
![]()
nstyle.train_nstyle(args, callback=show_img)
![]()
final_img = io.imread(args.output_dir+'final.jpg')plt.figure(figsize=(3,2))
plt.axis('off')
plt.title('final')
plt.imshow(final_img)
plt.show()
![]()
下面是主要函数文件nstyle.py
![]()
import find_mxnet
import mxnet as mx
import numpy as np
import importlib #动态导入Python库
import logging
logging.basicConfig(level=logging.DEBUG)
import argparse #Python命令参数传递
from collections import namedtuple #Python集合类
from skimage import io, transform
from skimage.restoration import denoise_tv_chambolle #加载该函数,使用TV模型的去噪CallbackData = namedtuple('CallbackData', field_names=['eps','epoch','img','filename'])def get_args(arglist=None): #加载运行时参数parser = argparse.ArgumentParser(description='neural style')#静态方法,定义一个参数对象parser.add_argument('--model', type=str, default='vgg19',#加载预训练好的模型VGGchoices = ['vgg'],help = 'the pretrained model to use')parser.add_argument('--content-image', type=str, default='input/IMG_4343.jpg',help='the content image') #内容图片parser.add_argument('--style-image', type=str, default='input/starry_night.jpg',help='the style image') #样式图片parser.add_argument('--stop-eps', type=float, default=.005,help='stop if the relative chanage is less than eps') #迭代次数误差parser.add_argument('--content-weight', type=float, default=10,help='the weight for the content image') #内容权重parser.add_argument('--style-weight', type=float, default=1, #样式权重help='the weight for the style image')parser.add_argument('--tv-weight', type=float, default=1e-2,help='the magtitute on TV loss') #TV模型中相邻两次的误差小于其值,就停止迭代parser.add_argument('--max-num-epochs', type=int, default=1000,help='the maximal number of training epochs') #最大的训练迭代次数parser.add_argument('--max-long-edge', type=int, default=600,help='resize the content image') #图像大小parser.add_argument('--lr', type=float, default=.001,help='the initial learning rate') #learning rateparser.add_argument('--gpu', type=int, default=-1,help='which gpu card to use, -1 means using cpu') #是否GPUparser.add_argument('--output_dir', type=str, default='output/',help='the output image') #输出目录parser.add_argument('--save-epochs', type=int, default=50,help='save the output every n epochs') #保存每一轮次parser.add_argument('--remove-noise', type=float, default=.02,help='the magtitute to remove noise') #TV模型去噪的参数,即光滑参数namedaparser.add_argument('--lr-sched-delay', type=int, default=75,help='how many epochs between decreasing learning rate')parser.add_argument('--lr-sched-factor', type=int, default=0.9,help='factor to decrease learning rate on schedule')if arglist is None:return parser.parse_args()else:return parser.parse_args(arglist) #这样写就可以加载默认参数 nstyle.get_args([])def PreprocessContentImage(path, long_edge):img = io.imread(path)logging.info("load the content image, size = %s", img.shape[:2]) #img.shape=(480,360) 就是height,widthfactor = float(long_edge) / max(img.shape[:2]) #这里表示最大值是600/480new_size = (int(img.shape[0] * factor), int(img.shape[1] * factor))# 新图像大小resized_img = transform.resize(img, new_size) #调整图像大小sample = np.asarray(resized_img) * 256 #因为调整图像大小后,数字范围在0-1之间# swap axes to make image from (224, 224, 3) to (3, 224, 224)sample = np.swapaxes(sample, 0, 2)sample = np.swapaxes(sample, 1, 2)# sub mean#图像预处理:减去的均值是数据集所有图片的RGB三个通道的均值构成的向量[Rmean, Gmean, Bmean]#每个通道各一个均值。然后所有图像都减去此向量。 在训练集得到的均值要应用于测试集,保证变换形式相同。sample[0, :] -= 123.68sample[1, :] -= 116.779 sample[2, :] -= 103.939logging.info("resize the content image to %s", new_size)return np.resize(sample, (1, 3, sample.shape[1], sample.shape[2]))#返回shape参数提供给style使用 (1,3,480,360)def PreprocessStyleImage(path, shape):img = io.imread(path)resized_img = transform.resize(img, (shape[2], shape[3]))sample = np.asarray(resized_img) * 256sample = np.swapaxes(sample, 0, 2)sample = np.swapaxes(sample, 1, 2)sample[0, :] -= 123.68sample[1, :] -= 116.779sample[2, :] -= 103.939return np.resize(sample, (1, 3, sample.shape[1], sample.shape[2]))def PostprocessImage(img):img = np.resize(img, (3, img.shape[2], img.shape[3]))img[0, :] += 123.68img[1, :] += 116.779img[2, :] += 103.939img = np.swapaxes(img, 1, 2)img = np.swapaxes(img, 0, 2)img = np.clip(img, 0, 255) #将图像大小限制在0-255之间return img.astype('uint8')def SaveImage(img, filename, remove_noise=0.):logging.info('save output to %s', filename)out = PostprocessImage(img)if remove_noise != 0.0:out = denoise_tv_chambolle(out, weight=remove_noise, multichannel=True)#TV模型去噪io.imsave(filename, out)def style_gram_symbol(input_size, style):#求取样式图像在训练的过程中,在每一次output后加入一个全连接层,求神经元之间的点乘,即格拉姆矩阵_, output_shapes, _ = style.infer_shape(data=(1, 3, input_size[0], input_size[1]))#mxnet推测输入和输出参数gram_list = []grad_scale = []''' style的output_shapes如下所示[(1, 64, 480, 360),(1, 128, 240, 180),(1, 256, 120, 90),(1, 512, 60, 45),(1, 512, 30, 22)]style的list_outputs()如下所示'relu1_1_output','relu2_1_output','relu3_1_output','relu4_1_output','relu5_1_output''''for i in range(len(style.list_outputs())):shape = output_shapes[i]x = mx.sym.Reshape(style[i], target_shape=(int(shape[1]), int(np.prod(shape[2:])))) #np.prod(shape[2:])=480*360=172000# use fully connected to quickly do dot(x, x^T)gram = mx.sym.FullyConnected(x, x, no_bias=True, num_hidden=shape[1])#使用全连接层求X * X^Tgram_list.append(gram)grad_scale.append(np.prod(shape[1:]) * shape[1])return mx.sym.Group(gram_list), grad_scaledef get_loss(gram, content):gram_loss = []for i in range(len(gram.list_outputs())):gvar = mx.sym.Variable("target_gram_%d" % i)gram_loss.append(mx.sym.sum(mx.sym.square(gvar - gram[i])))cvar = mx.sym.Variable("target_content")content_loss = mx.sym.sum(mx.sym.square(cvar - content))return mx.sym.Group(gram_loss), content_lossdef get_tv_grad_executor(img, ctx, tv_weight):"""create TV gradient executor with input binded on img"""if tv_weight <= 0.0:return Nonenchannel = img.shape[1]simg = mx.sym.Variable("img")skernel = mx.sym.Variable("kernel")channels = mx.sym.SliceChannel(simg, num_outputs=nchannel)out = mx.sym.Concat(*[mx.sym.Convolution(data=channels[i], weight=skernel,num_filter=1,kernel=(3, 3), pad=(1,1),no_bias=True, stride=(1,1))for i in range(nchannel)])kernel = mx.nd.array(np.array([[0, -1, 0],[-1, 4, -1],[0, -1, 0]]).reshape((1, 1, 3, 3)),ctx) / 8.0out = out * tv_weightreturn out.bind(ctx, args={"img": img,"kernel": kernel})def train_nstyle(args, callback=None):"""Train a neural style network.Args are from argparse and control input, output, hyper-parameters.callback allows for display of training progress."""# input#dev = mx.gpu(args.gpu) if args.gpu >= 0 else mx.cpu()dev = mx.cpu()content_np = PreprocessContentImage(args.content_image, args.max_long_edge)style_np = PreprocessStyleImage(args.style_image, shape=content_np.shape)size = content_np.shape[2:] #shape为(1,3,480,360),所以size为 (480,360)# modelExecutor = namedtuple('Executor', ['executor', 'data', 'data_grad'])#将这些字符串加入集合Executor里面model_module = importlib.import_module('model_' + args.model) #加载模型 model_vgg19, 即model_vgg19.pystyle, content = model_module.get_symbol() #调用model_vgg19.py文件里面的get_symbol方法gram, gscale = style_gram_symbol(size, style)#求出style的格拉姆矩阵model_executor = model_module.get_executor(gram, content, size, dev) #调用model_vgg19.py文件里面的get_executor方法model_executor.data[:] = style_npmodel_executor.executor.forward()#样式前馈style_array = []for i in range(len(model_executor.style)):style_array.append(model_executor.style[i].copyto(mx.cpu()))model_executor.data[:] = content_npmodel_executor.executor.forward() #内容前馈content_array = model_executor.content.copyto(mx.cpu())# delete the executordel model_executorstyle_loss, content_loss = get_loss(gram, content) #获得损失值model_executor = model_module.get_executor( #再次调用get_executor方法,不过传入的是损失值style_loss, content_loss, size, dev)grad_array = []for i in range(len(style_array)):style_array[i].copyto(model_executor.arg_dict["target_gram_%d" % i])grad_array.append(mx.nd.ones((1,), dev) * (float(args.style_weight) / gscale[i]))grad_array.append(mx.nd.ones((1,), dev) * (float(args.content_weight)))print([x.asscalar() for x in grad_array])content_array.copyto(model_executor.arg_dict["target_content"])# train# initialize img with random noiseimg = mx.nd.zeros(content_np.shape, ctx=dev)img[:] = mx.rnd.uniform(-0.1, 0.1, img.shape)#生成一个空白图像lr = mx.lr_scheduler.FactorScheduler(step=args.lr_sched_delay,factor=args.lr_sched_factor)optimizer = mx.optimizer.NAG(learning_rate = args.lr,wd = 0.0001,momentum=0.95,lr_scheduler = lr)optim_state = optimizer.create_state(0, img)logging.info('start training arguments %s', args)old_img = img.copyto(dev)clip_norm = 1 * np.prod(img.shape)tv_grad_executor = get_tv_grad_executor(img, dev, args.tv_weight) #图像锐化for e in range(args.max_num_epochs):img.copyto(model_executor.data)model_executor.executor.forward()model_executor.executor.backward(grad_array)gnorm = mx.nd.norm(model_executor.data_grad).asscalar()if gnorm > clip_norm:model_executor.data_grad[:] *= clip_norm / gnormif tv_grad_executor is not None:tv_grad_executor.forward()optimizer.update(0, img,model_executor.data_grad + tv_grad_executor.outputs[0],optim_state)else:optimizer.update(0, img, model_executor.data_grad, optim_state)new_img = imgeps = (mx.nd.norm(old_img - new_img) / mx.nd.norm(new_img)).asscalar()old_img = new_img.copyto(dev)logging.info('epoch %d, relative change %f', e, eps)if eps < args.stop_eps:logging.info('eps < args.stop_eps, training finished')breakif callback:cbdata = {'eps': eps,'epoch': e+1,}if (e+1) % args.save_epochs == 0:outfn = args.output_dir + 'e_'+str(e+1)+'.jpg'npimg = new_img.asnumpy()SaveImage(npimg, outfn, args.remove_noise)if callback:cbdata['filename'] = outfncbdata['img'] = npimgif callback:callback(cbdata)final_fn = args.output_dir + '/final.jpg'SaveImage(new_img.asnumpy(), final_fn)if __name__ == "__main__":args = get_args()train_nstyle(args)
![]()
model_vgg19.py
![]()
import find_mxnet
import mxnet as mx
import os, sys
from collections import namedtupleConvExecutor = namedtuple('ConvExecutor', ['executor', 'data', 'data_grad', 'style', 'content', 'arg_dict'])def get_symbol():# declare symboldata = mx.sym.Variable("data")conv1_1 = mx.symbol.Convolution(name='conv1_1', data=data , num_filter=64, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu1_1 = mx.symbol.Activation(name='relu1_1', data=conv1_1 , act_type='relu')conv1_2 = mx.symbol.Convolution(name='conv1_2', data=relu1_1 , num_filter=64, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu1_2 = mx.symbol.Activation(name='relu1_2', data=conv1_2 , act_type='relu')pool1 = mx.symbol.Pooling(name='pool1', data=relu1_2 , pad=(0,0), kernel=(2,2), stride=(2,2), pool_type='avg')conv2_1 = mx.symbol.Convolution(name='conv2_1', data=pool1 , num_filter=128, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu2_1 = mx.symbol.Activation(name='relu2_1', data=conv2_1 , act_type='relu')conv2_2 = mx.symbol.Convolution(name='conv2_2', data=relu2_1 , num_filter=128, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu2_2 = mx.symbol.Activation(name='relu2_2', data=conv2_2 , act_type='relu')pool2 = mx.symbol.Pooling(name='pool2', data=relu2_2 , pad=(0,0), kernel=(2,2), stride=(2,2), pool_type='avg')conv3_1 = mx.symbol.Convolution(name='conv3_1', data=pool2 , num_filter=256, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu3_1 = mx.symbol.Activation(name='relu3_1', data=conv3_1 , act_type='relu')conv3_2 = mx.symbol.Convolution(name='conv3_2', data=relu3_1 , num_filter=256, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu3_2 = mx.symbol.Activation(name='relu3_2', data=conv3_2 , act_type='relu')conv3_3 = mx.symbol.Convolution(name='conv3_3', data=relu3_2 , num_filter=256, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu3_3 = mx.symbol.Activation(name='relu3_3', data=conv3_3 , act_type='relu')conv3_4 = mx.symbol.Convolution(name='conv3_4', data=relu3_3 , num_filter=256, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu3_4 = mx.symbol.Activation(name='relu3_4', data=conv3_4 , act_type='relu')pool3 = mx.symbol.Pooling(name='pool3', data=relu3_4 , pad=(0,0), kernel=(2,2), stride=(2,2), pool_type='avg')conv4_1 = mx.symbol.Convolution(name='conv4_1', data=pool3 , num_filter=512, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu4_1 = mx.symbol.Activation(name='relu4_1', data=conv4_1 , act_type='relu')conv4_2 = mx.symbol.Convolution(name='conv4_2', data=relu4_1 , num_filter=512, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu4_2 = mx.symbol.Activation(name='relu4_2', data=conv4_2 , act_type='relu')conv4_3 = mx.symbol.Convolution(name='conv4_3', data=relu4_2 , num_filter=512, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu4_3 = mx.symbol.Activation(name='relu4_3', data=conv4_3 , act_type='relu')conv4_4 = mx.symbol.Convolution(name='conv4_4', data=relu4_3 , num_filter=512, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu4_4 = mx.symbol.Activation(name='relu4_4', data=conv4_4 , act_type='relu')pool4 = mx.symbol.Pooling(name='pool4', data=relu4_4 , pad=(0,0), kernel=(2,2), stride=(2,2), pool_type='avg')conv5_1 = mx.symbol.Convolution(name='conv5_1', data=pool4 , num_filter=512, pad=(1,1), kernel=(3,3), stride=(1,1), no_bias=False, workspace=1024)relu5_1 = mx.symbol.Activation(name='relu5_1', data=conv5_1 , act_type='relu')# style and content layersstyle = mx.sym.Group([relu1_1, relu2_1, relu3_1, relu4_1, relu5_1])content = mx.sym.Group([relu4_2])return style, contentdef get_executor(style, content, input_size, ctx):out = mx.sym.Group([style, content])# make executorarg_shapes, output_shapes, aux_shapes = out.infer_shape(data=(1, 3, input_size[0], input_size[1]))arg_names = out.list_arguments()arg_dict = dict(zip(arg_names, [mx.nd.zeros(shape, ctx=ctx) for shape in arg_shapes]))grad_dict = {"data": arg_dict["data"].copyto(ctx)}# init with pretrained weightpretrained = mx.nd.load("./model/vgg19.params")for name in arg_names:if name == "data":continuekey = "arg:" + nameif key in pretrained:pretrained[key].copyto(arg_dict[name])else:print("Skip argument %s" % name)executor = out.bind(ctx=ctx, args=arg_dict, args_grad=grad_dict, grad_req="write")return ConvExecutor(executor=executor,data=arg_dict["data"],data_grad=grad_dict["data"],style=executor.outputs[:-1],content=executor.outputs[-1],arg_dict=arg_dict)def get_model(input_size, ctx):style, content = get_symbol()return get_executor(style, content, input_size, ctx)
![]()
加入mxnet的Python的环境
![]()
try:import mxnet as mx except ImportError:import os, syscurr_path = os.path.abspath(os.path.dirname(__file__))sys.path.append(os.path.join(curr_path, "../../python"))import mxnet as mx
![]()
实验结果如下:
![]()
分类: 深度学习
[译] A Neural Algorithm of Artistic Style--图片风格化相关推荐
- 【每个人都是梵高】A Neural Algorithm of Artistic Style
文章地址:A Neural Algorithm of Artistic Style 代码:https://github.com/jcjohnson/neural-style 这篇文章我觉得可以起个浪漫 ...
- A Neural Algorithm of Artistic Style
油画风格(Neural style) 参考文献:< A Neural Algorithm of Artistic Style>
- NS之VGG(Keras):基于Keras的VGG16实现之《复仇者联盟3》灭霸图像风格迁移设计(A Neural Algorithm of Artistic Style)
NS之VGG(Keras):基于Keras的VGG16实现之<复仇者联盟3>灭霸图像风格迁移设计(A Neural Algorithm of Artistic Style) 导读 通过代码 ...
- 艺术风格转换之《A Neural Algorithm of Artistic Style》
源码地址:https://github.com/fzliu/style-transfer scipy.optimize.minimize的使用 scipy.optimize.minimize(fun, ...
- 计算机也能成为艺术家?(基于论文A Neural Algorithm of Artistic Style的图像风格迁移)
文章目录 引言 可解释性 一种途径:特征可视化 特征和风格,两者或许是一种东西 图像纹理生成 格拉姆矩阵 纹理生成网络 纹理损失函数 从纹理合成到风格迁移 内容损失函数 总损失函数 Torch代码实战 ...
- 【转】模仿绘画风格的算法:A Neural Algorithm of Artistic Style
http://blog.csdn.net/bat67/article/details/52049983 有代码,论文方面说的不多,有图,很有趣.等有时间看看这篇论文和代码,自己实现下.
- 【A Neural Algorithm of Artistic Style】 Pics
图中是我市的标志
- Convolutional neural networks for artistic style transfer
https://harishnarayanan.org/writing/artistic-style-transfer/ 转载于:https://www.cnblogs.com/guochen/p/6 ...
- A Learned Representation for Artistic Style论文理解
A Learned Representation for Artistic Style论文理解 这篇论文是在Perceptual losses for real-time style transfer ...
- CVPR-Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer
[CVPR-2021] Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Tr ...
最新文章
- CDH大数据集群安全风险汇总
- oracle+手工创建pfile,oracle 手工创建数据库
- HDU - 6203 ping ping ping(LCA+dfs序+线段树)
- iOS APP 安全测试
- python装饰器应用论文_Python装饰器的应用场景代码总结
- 日常问题——阿里云服务器ssh经常一段时间就断掉解决办法
- linux透明防火墙--br_netfilter
- 卡巴斯基一年版 送序列号
- html文本图片如何排版,【姿势】10种照片的文字排版
- oracle bam教程,Oracle BAM原理简介
- FFplay文档解读-7-比特流过滤器
- 最常见的8种网络安全攻击类型!
- Win32之ShowWindow
- 又来了!10分钟实现微信 “炸屎“大作战
- 传奇M2server用到的文件一些txt或Ini文件解释说明(整理中……)
- 《高效程序员的修炼》读后感
- android vitamio集成教程,集成Vitamio实现万能播放器(示例代码)
- 推荐一些有趣的编程书籍和电影
- 当米友遇到终端(三)
- 盘点一下国内智能巡检机器人TOP5
热门文章
- STL中的序列式容器——stack(栈)
- Django学习笔记-MySQL
- 原生JS实现各种经典网页特效——Banner图滚动、选项卡切换、广告弹窗等
- jQuery插件开发精品教程,让你的jQuery提升一个台阶
- RPC(RemoteProcedureCallProtocol)
- 通过编程方式在InfoPath 2010表单的下拉框修改事件中获取数据
- BZOJ1079 [SCOI2008]着色方案 【dp记忆化搜索】
- C# ObjectCache、OutputCache缓存
- cocos2d-x学习之旅(二):1.2 cocos2d-x Visual Studio2010 开发环境搭建 windows 7 32位
- 看看人家怎么学英语,用一年时间从六级水平到考上欧盟口译司!(转载)