机器学习项目中遇到的难题_现代难题:何时使用规则与机器学习
机器学习项目中遇到的难题
Machine learning is taking the world by storm, and many companies that use rules engines for making business decisions are starting to leverage it. However, the two technologies are geared towards different problems. Rules engines are used to execute discrete logic that needs to have 100% precision. Machine learning on the other hand, is focused on taking a number of inputs and trying to predict an outcome. It’s important to understand the strengths of both technologies so you can identify the right solution for the problem. In some cases, it’s not one or the other, but how you can use both together to get maximum value.
机器学习正席卷全球,许多使用规则引擎制定业务决策的公司开始利用它。 但是,这两种技术都针对不同的问题。 规则引擎用于执行需要100%精度的离散逻辑。 另一方面,机器学习侧重于获取大量输入并试图预测结果。 了解这两种技术的优势很重要,这样您才能找到解决问题的正确方法。 在某些情况下,这不是一个或另一个,而是如何一起使用两者来获取最大价值。
业务逻辑,计算和工作流程 (Business Logic, Calculations and Workflows)
Let’s start first with understanding business logic. I’ve worked with various types of logic in systems over the years and its important to understand the context.
让我们首先从理解业务逻辑开始。 这些年来,我一直在系统中使用各种类型的逻辑,这对于理解上下文很重要。
What is business logic? At its simplest form, its logic that contains decisions that govern a business process. These decisions are business decisions. The logic tends to be variable with the market and may change often depending on that particular industry’s drivers. The logic focuses on the why and the when. Ultimately a condition has to be true before an action can be taken.
什么是业务逻辑? 最简单的形式是包含控制业务流程决策的逻辑。 这些决策是业务决策。 逻辑倾向于随市场而变化,并可能经常变化,具体取决于该特定行业的驱动因素。 逻辑重点在于“为什么”和“何时” 。 最终,一个条件必须为真,然后才能采取行动。
Business logic typically leverages business calculations. Unlike business logic, business calculations tend to stay the same. They focus on the what and the how. It’s important to decouple these two from a deployment aspect as they change at different rates. As a general rule, any reusable logic should be independently deployable. If reusable logic is tied to an application deployment, it can’t be individually reused and is coupled to other components. Ideally, we want to break apart the reusable pieces of an application into microservices so they are independently reusable and deployable. See Martin Fowler’s illustration under “Figure 1: Monoliths and Microservices” as an example.
业务逻辑通常利用业务计算。 与业务逻辑不同,业务计算往往保持不变。 他们专注于什么和如何 。 重要的是将这两者从部署方面分离开来,因为它们的变化速率不同。 通常,任何可重用的逻辑都应可独立部署。 如果将可重用逻辑与应用程序部署联系在一起,则不能将其单独重用并耦合到其他组件。 理想情况下,我们希望将应用程序的可重用部分分解为微服务,以便它们可以独立地重用和部署。 请参见Martin Fowler在“图1:单片和微服务”下的插图 。
How do we connect the different steps of business logic together? Workflows.
我们如何将业务逻辑的不同步骤联系在一起? 工作流程 。
They are the structured flow or sequencing of work tasks in a business process. Workflows can either be human-based, system-based (e.g. orchestration) or a hybrid between the two. In a previous blog I discussed when to react vs orchestrate.
它们是业务流程中工作任务的结构化流程或顺序。 工作流可以是基于人的,基于系统的(例如,业务流程),也可以是两者之间的混合。 在之前的博客中,我讨论了何时应对与协调。
实现业务逻辑的方法 (Approaches for Implementing Business Logic)
Now that we understand how these pieces fit together, let’s discuss some approaches for building business logic. In general, there are three different approaches for implementing business logic: Application code, decision table, and a rules engine. I’ve used each of these three in my experience and it’s important to identify the criteria that determines which one is the best fit.
现在我们了解了这些部分是如何组合在一起的,让我们讨论一些构建业务逻辑的方法。 通常,有三种实现业务逻辑的方法: 应用程序代码,决策表和规则引擎 。 在我的经验中,我已经使用了这三个条件中的每一个,并且确定确定哪个条件最合适的标准很重要。
申请代码 (Application Code)
Application is a good fit when the logic doesn’t change much and is fairly straightforward.
当逻辑变化不大且非常简单时,应用程序非常适合。

决策表 (Decision Table)
Decision tables are a good fit for logic that changes often and has a large number of conditions that are easier to manage in a table than code
决策表非常适合经常更改的逻辑,并且具有大量条件,这些条件比代码更易于在表中管理
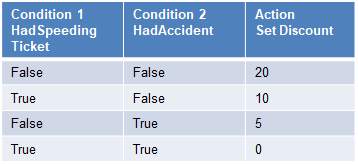
规则引擎 (Rules Engine)
A rules engine is a good fit for logic that changes often and is highly complex, involving numerous levels of logic. Rules engines are typically part of a Business Rules Management System (BRMS) that provide extensive capabilities to manage the complexity .
规则引擎非常适合经常更改且非常复杂的逻辑,涉及多个逻辑层次。 规则引擎通常是业务规则管理系统(BRMS)的一部分,该系统提供了广泛的功能来管理复杂性。

If we put this guidance into quadrants, it would look something like the below:
如果将本指南放到象限中,它将类似于以下内容:

As the rate of complexity and rate of change increases, application code is no longer suitable for business logic. Decision tables provide some relief as the rate of change increases, but ultimately a BRMS provides the best fit for high rate of change and high complexity.
随着复杂性和变化率的增加,应用程序代码不再适用于业务逻辑。 决策表可以随着变化率的增加而有所缓解,但是最终BRMS提供了最适合高变化率和高复杂性的方法。
业务规则管理系统(BRMS) (Business Rules Management System (BRMS))
Let’s take a closer look at the capabilities of a BRMS by reviewing the below capability reference view.
通过查看下面的功能参考视图,让我们仔细看一下BRMS的功能。

Let’s touch on a couple of the key capabilities in this reference view and highlight some that also overlap with machine learning capabilities.
让我们在此参考视图中触摸几个关键功能,并重点介绍一些与机器学习功能重叠的功能。
规则创作 (Rule Authoring)
- A Technical rule or Guided rule provides two different ways to author rules geared towards different end users. Technical rules are more for your developer audience, where guided rules consist of a point and click approach that may be better for less technical users.
技术规则或指导规则提供了两种不同的方式来编写针对不同最终用户的规则。 技术规则更适合您的开发人员受众,其中指导性规则由指向和单击的方法组成,这对于技术含量较低的用户可能更好。 - A Domain Specific Language (DSL) is another capability that can enable non-technical users to write rules in an easier to use language.
域特定语言(DSL)是另一种功能,可以使非技术用户以更易于使用的语言编写规则。 - Neural Networks are a form of an algorithm used in machine learning, it’s interesting to see that some BRMS have integration with this.
神经网络是机器学习中使用的一种算法形式,有趣的是一些BRMS已与之集成。
规则管理 (Rule Management)
The rule repository is one of the most powerful capabilities of a BRMS. It is the mechanism in which developers can find out what has already been built and what they may be able to reuse. Rule metadata is stored here that is critical in understanding the underlying intent.
规则存储库是BRMS的最强大功能之一。 通过这种机制,开发人员可以找出已经构建的内容以及可以重用的内容。 规则元数据存储在此处,这对于理解底层意图至关重要。
部署方式 (Deployment)
Typically, rules can be deployed in one of two ways - as either part of a standalone service that is invoked via REST API calls, or embedded as part of the application (in-process). A little later in this article, we will see that machine learning platforms share a similar model.
通常,可以通过以下两种方式之一部署规则-作为通过REST API调用调用的独立服务的一部分,或者作为应用程序(进程内)的一部分嵌入。 在本文的稍后部分,我们将看到机器学习平台具有相似的模型。
规则执行与部署 (Rule Execution & Deployment)
Predictive Model Markup Language (PMML), or Portable Format for Analytics (PFA), are both industry standard formats for making models interchangeable. They enable you to build a model in one language or platform and port it into another language or platform that supports PMML or PFA.
预测模型标记语言(PMML)或可分析的便携式格式(PFA)都是使模型可互换的行业标准格式。 它们使您能够使用一种语言或平台来构建模型,并将其移植到支持PMML或PFA的另一种语言或平台中。
One such example of a BRMS is Drools. Drools is an open source Apache licensed, Java-based rules engine. It supports a forward and backward chaining inference engine that leverages the PHREAK algorithm. This inference engine comes in handy if you want the rules engine to decide the order of your rules. Drools provides guided rules, technical rule DRL syntax, and support for Domain Specific Language (DSL). Drools also supports both in-process and standalone deployment models. A new community project known as Kogito is built on top of Drools 7 and creates rest deployable Drools services for you. I often found myself deploying drools rules inside Java microservices and then exposing those as restful APIs. Kogito does this for you.
一个这样的BRMS示例就是Drools 。 Drools是Apache许可的,基于Java的开源规则引擎。 它支持利用PHREAK算法的向前和向后链接推理引擎。 如果您希望规则引擎决定规则的顺序,则此推理引擎会派上用场。 Drools提供了指导规则,技术规则DRL语法以及对领域特定语言(DSL)的支持。 Drools还支持进程内和独立部署模型。 在Drools 7之上构建了一个称为Kogito的新社区项目, 该项目为您创建了可部署的其余Drools服务。 我经常发现自己在Java微服务中部署了Drools规则,然后将它们公开为宁静的API。 Kogito为您做到这一点。
机器学习平台 (Machine Learning Platforms)
Now that we have a good understanding of Rules Engines, let's compare them to Machine Learning Platforms. In a previous post, I provided an overview of what machine learning is and how you can use it with open source BPM. In a similar post, I explain how you can use machine learning with Akka. Let’s now take a look at a capability reference view for a machine learning platform.
现在,我们对规则引擎有了很好的了解,让我们将它们与机器学习平台进行比较。 在上一篇文章中 ,我概述了什么是机器学习以及如何将其与开源BPM结合使用 。 在类似的帖子中,我解释了如何在Akka中使用机器学习。 现在让我们看一下机器学习平台的功能参考视图。

Let’s touch on some of the key capabilities and again tie back to similar overlap with the BRMS view.
让我们来谈谈一些关键功能,并再次将其与BRMS视图绑定到相似的位置。
资料撷取 (Data Ingestion)
Data is the most important thing in machine learning. Your model is only as good as your data. You want as much data as possible and that may include both batch and real-time data sources.
数据是机器学习中最重要的事情。 您的模型仅与数据一样好。 您需要尽可能多的数据,其中可能包括批处理和实时数据源。
特征工程 (Feature Engineering)
Features are the inputs into models and some ML Platforms provide capabilities for you to create those features. Others provide capabilities that can automatically generate the features for you.
特征是模型的输入,某些ML平台为您提供创建这些特征的功能。 其他提供的功能可以自动为您生成功能。
建模范例 (Modeling Paradigms)
These are the different algorithms that can be used in a machine learning model. An important thing to note here is they aren’t tied to Supervised, UnSupervised, or Reinforcement Learning categories, rather they can be used across all three.
这些是可以在机器学习模型中使用的不同算法。 这里要注意的重要一点是,它们并不与“有监督” ,“ 无 监督”或“ 强化学习”类别相关联,而是可以在所有这三种类别中使用。
部署与执行 (Deployment & Execution)
You will notice some similarities to the BRMS capabilities in this space, specifically in-process and standalone REST API deployments along with support for PMML.
您会注意到与该领域中BRMS功能的一些相似之处,特别是进程内和独立REST API部署以及对PMML的支持。
管理 (Management)
One of the most important aspects of managing a machine learning model is monitoring it for accuracy. A common fallacy with machine learning is that a ML model never needs to be retrained as it can learn itself. That is not the case as machine learning models have to be re-trained every so often as the data they are trained on starts to drift from the data they are executing against in production.
管理机器学习模型的最重要方面之一是对其准确性进行监控。 机器学习的一个普遍谬误是,机器学习模型可以自学,因此无需重新训练。 事实并非如此,因为机器学习模型必须经常进行重新训练,因为他们所训练的数据开始从他们正在生产中执行的数据中漂移出来。
H2O is one such example of an open source in-memory Machine Learning Platform. It provides a number of algorithms (e.g. Generalized Linear Model, Random Forest, Gradient Boosting Machine, Principals Components Analysis, etc.) for training machine learning models along with generating metrics showing the accuracy and performance of the generated model. H2O will also generate a deployable artifact that you can include in your project, such a POJO (Plain Old Java Object) or MOJO ( Model ObJect,Optimized) artifact. MOJO is typically used when the POJO hits the size limit or higher performance is needed.
H2O就是开源内存中机器学习平台的一个例子。 它提供了许多算法(例如, 广义线性模型 , 随机森林 , 梯度提升机 , 主成分分析等)来训练机器学习模型,并生成表示所生成模型的准确性和性能的度量。 H2O还将生成可部署的工件,您可以将其包含在项目中,例如POJO(普通的Java对象)或MOJO(模型对象,优化的)工件。 当POJO达到大小限制或需要更高的性能时,通常使用MOJO。
By comparing the capabilities of machine learning platforms with rules engines we can now see how there are similarities along with differences at the capability level. Given how products in these areas are continuing to become closer together, it’s understandable how the choice between the two can be difficult.
通过将机器学习平台与规则引擎的功能进行比较,我们现在可以看到功能级别上的相似之处和不同之处。 鉴于这些领域中的产品如何继续变得越来越紧密,在这两者之间进行选择会很困难,这是可以理解的。

何时使用规则引擎与机器学习的指南 (Guidance for When to Use a Rules Engine vs. Machine Learning)
So how do we make the decision of when to use a Rules Engine or Machine Learning? To answer this, let’s answer this question from the dimensions of logic, logic type, what creates the logic, and data. Rules are a good fit in the situation where:
那么,我们如何决定何时使用规则引擎或机器学习呢? 为了回答这个问题,让我们从逻辑,逻辑类型,创建逻辑的内容和数据的维度来回答这个问题。 规则非常适合以下情况:
Logic: Exact logic is known. With rules you know ahead of time the logic you want to execute.
逻辑:确切的逻辑是已知的。 使用规则,您可以提前知道要执行的逻辑。
Logic Type: Precision based. If then business logic is precise and does not involve any predictions. It results in boolean type outcomes based on evaluation of facts.
逻辑类型:基于精度。 如果这样,则业务逻辑是精确的,并且不涉及任何预测。 它基于事实评估得出布尔型结果。
Logic creation: Done by a human. Software Engineers or business users create the rules that represent business logic.
逻辑创造:由人类完成。 软件工程师或业务用户创建代表业务逻辑的规则。
Data: Don’t need to automatically derive the logic from the data. Analysis typically occurs on data beforehand to determine what the exact logic should be.
数据:不需要从数据自动得出逻辑。 通常先对数据进行分析,以确定确切的逻辑。
Now, let’s look at machine learning using these same dimensions:
现在,让我们看一下使用这些相同维度的机器学习:
Logic: Exact logic is not known. Rather the inputs/features that are significant in creating a prediction may be known.
逻辑:确切的逻辑未知。 而是可以知道在创建预测中很重要的输入/特征。
Logic Type: Prediction based using algorithms.
逻辑类型:使用算法进行预测。
Logic creation: Created by machine learning software that runs algorithms via training.
逻辑创建:由机器学习软件创建,该软件通过培训运行算法。
Data: Is used to ultimately generate the model logic. Is the most important thing in machine learning. You want to use as much data as possible and also make sure the data is unbiased. If the data is biased, then the model will become biased.
数据:用于最终生成模型逻辑。 是机器学习中最重要的事情。 您要使用尽可能多的数据,并确保数据没有偏见。 如果数据有偏差,则模型将有偏差。
In summary, leverage rules when you need precision and know the logic. Leverage machine learning when you want to predict something but don’t know exactly how.
总之,在需要精确度并了解逻辑时利用规则。 当您想预测某些东西但不知道怎么做时,请利用机器学习。
But is it always as clear cut as that? What if you wanted to use the power of both? The answer is you can. There are a number of hybrid patterns where you can use machine learning and rules together to determine an outcome. Let’s look at an example use case.
但这是否总是那么清晰? 如果您想同时使用两者的功能怎么办? 答案是可以的。 有很多混合模式,您可以在其中使用机器学习和规则来确定结果。 让我们看一个示例用例。
一起使用机器学习和规则引擎的模式 (Patterns for Using Machine Learning and Rules Engines Together)
Imagine the use case where you are a realtor wanting to provide the best guidance to your clients on purchasing a home. Maybe there are several they are interested in, but aren’t sure how quickly they should act. Let’s walk through three different patterns for combining machine learning and rules together to achieve this.
想象一下一个用例,您是一名房地产经纪人,希望为客户提供有关购买房屋的最佳指导。 也许有几个他们感兴趣,但是不确定他们应该采取多快的行动。 让我们逐步介绍将机器学习和规则结合在一起以实现此目标的三种不同模式。
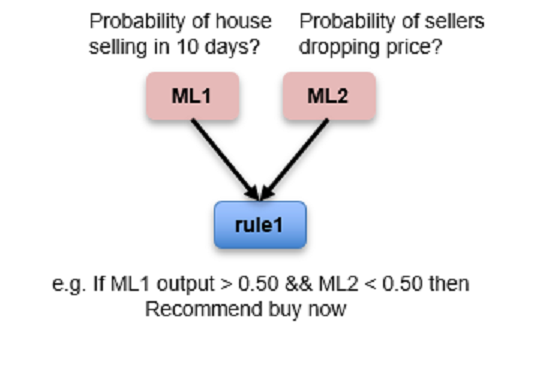
模式1:利用机器学习输出作为规则的输入 (Pattern 1: Leverage machine learning outputs as an input into rules)
In this pattern, two different machine learning models execute. One determines the probability of a house selling in 10 days. Another determines the probability of the sellers dropping the asking price. Both of these predictions are an input into rules. The rules then evaluate the output of the model and ultimately provide a recommendation to the realtor. Specifically, if the probability of the house selling in 10 days is greater than 50%, and the probability of the sellers dropping the price is less than 50%, then this pattern makes a specific recommendation for the realtor.
在这种模式下,执行两种不同的机器学习模型。 一个可以确定房屋在10天内出售的可能性。 另一个因素决定了卖方降低要价的可能性。 这两个预测都是对规则的输入。 然后,规则会评估模型的输出,并最终向房地产经纪人提供建议。 具体来说,如果房屋在10天之内卖出的概率大于50%,而卖方降低价格的概率小于50%,则此模式将为房地产经纪人提出具体建议。
模式2:将规则输出作为特征输入到机器学习模型中 (Pattern 2: Leverage rule outputs as a feature input into machine learning models)
In this pattern, we start with the rules being the input into the machine learning models. Rules execute business logic to determine boolean based values. Does the house need repairs? Is it the selling offseason? Do the sellers want to get rid of the house and sell it now? The output of these rules then are features into the machine learning models. The machine learning models then provide a probability back to the realtor of the house selling in 10 days and the sellers dropping the price. Notice in this pattern there is not a recommendation back to the realtor, rather the probability is provided and final recommendation left up to the realtor.
在这种模式中,我们从规则作为机器学习模型的输入开始。 规则执行业务逻辑以确定基于布尔的值。 这房子需要修理吗? 是销售淡季吗? 卖家是否要摆脱房屋并立即出售? 这些规则的输出将成为机器学习模型的特征。 然后,机器学习模型将概率提供给房屋经纪人,让其在10天内出售,而卖方则降低价格。 请注意,在这种模式下,没有向房地产经纪人的推荐,而是提供了可能性,而最终的建议则留给房地产经纪人。

模式3:将规则和机器学习输出作为输入 (Pattern 3: Leverage both rule and machine learning outputs as inputs)
In this pattern, it follows a mix of the previous two patterns. Both rules and machine learning outputs are inputs into a machine learning model. In this scenario the probability of the sellers dropping a price is an input into the probability of the house selling in 10 days. This pattern also leaves the ultimate recommendation up to the realtor.
在此模式中,它遵循前两种模式的混合。 规则和机器学习输出都是机器学习模型的输入。 在这种情况下,卖方降价的概率是房屋在10天内出售概率的输入。 这种模式还将最终建议留给房地产经纪人。

一个示例实现 (An Example Implementation)
Now let’s apply these patterns to an actual proof of concept. I am going to build off of a previous reactive microservice machine learning proof of concept that I built in a previous post. We will enhance it to contain a rules service that the machine learning model takes as an input. It will use pattern 1 above, Leverage machine learning outputs as an input into rules.
现在让我们将这些模式应用于实际的概念证明。 我要建概念的早期React的microService机器学习证明,我建在以前的关闭后 。 我们将对其进行增强,以包含机器学习模型作为输入的规则服务。 它将使用上面的模式1,利用机器学习输出作为规则的输入。
Let’s start with what we are changing in the proof of concept to support the integration of rules with machine learning. Below is a diagram that illustrates the architecture:
让我们从我们在概念证明方面所做的更改开始,以支持规则与机器学习的集成。 下图说明了该体系结构:

All components of the previous proof of concept hold true, (please see that previous blog for the details as I won’t repeat them here). The one new thing we introduced is the Java based Rules MS. This is the rules microservice that will evaluate the output of the machine learning model probability. H20 outputs a confidence value as part of its predictions. For a transaction that the machine learning model determines is OK/Not Fraudulent, the rules service will check this confidence value. If the confidence value is less than 50%, then it will evaluate the output of some additional fraud checks, in this case name and address. If either of those failed, the rule will recommend that the transaction is Fraudulent.
以前的概念证明的所有组成部分都是正确的(请参阅以前的博客以获取详细信息,因为我在这里不再赘述)。 我们引入的一件事是基于Java的Rules MS。 这是微服务规则,它将评估机器学习模型概率的输出。 H20输出置信度值作为其预测的一部分。 对于机器学习模型确定为“正常/不欺诈”的交易,规则服务将检查此置信度值。 如果置信度值小于50%,则它将评估一些其他欺诈检查的输出,在这种情况下为名称和地址。 如果其中任何一个失败,该规则将建议该交易是欺诈性的。
Here is a sequence flow that walks through the steps:
这是一个逐步执行步骤的流程:

Now let’s take a look at the Java Rules MS code to see how a drools rule would operate.
现在,让我们看一下Java Rules MS代码,以了解drools规则的工作方式。
rule “Trans OK and Prob < 0.50 and name check fail” when m : RulesData( modelProb <= 0.50, mymodelProb : modelProb) RulesData( status == “Transaction OK” ) RulesData( nameCheck <= 0 ) then m.setStatus(“Fraudulent Transaction from Rules, name check failed”);endrule “Trans OK and Prob < 0.50 and address check fail” when m : RulesData( modelProb <= 0.50, mymodelProb : modelProb) RulesData( status == “Transaction OK” ) RulesData( addressCheck <= 0 ) then m.setStatus(“Fraudulent Transaction from Rules, address check failed”);endWe can see this is using the Drools drl syntax, which is a way to write technical rules. There are two rules both checking if the transaction is OK and the machine learning output is less than 50%. The first rule also checks if a name check fails, where the second checks if an address check fails. You’ll notice in Drools there are not any else clauses. That is by design and rules fire based on conditions you specify. Within each rule you notice a RulesData function that is checking the status of several variables. In order for Drools rules to be evaluated against data, you have to create a POJO that represents the data model. This will include the getters and setters. See example below:
我们可以看到这使用了Drools drl语法,这是一种编写技术规则的方法。 有两个规则都检查事务是否正常以及机器学习输出是否小于50%。 第一条规则还检查名称检查是否失败,第二条规则检查地址检查是否失败。 您会在Drools中注意到没有其他子句。 这是设计使然,规则会根据您指定的条件触发。 在每个规则中,您会注意到一个RuleData函数正在检查多个变量的状态。 为了根据数据评估Drools规则,您必须创建一个代表数据模型的POJO。 这将包括getter和setter。 请参见下面的示例:
public static class RulesData { private int nameCheck=0, addressCheck=0; private String status=null; private double modelProb=0; public String getStatus() { return this.status; } public int getNameCheck() { return this.nameCheck; } public int getAddressCheck() { return this.addressCheck; } public double getModelProb() { return this.modelProb; } public void setNameCheck(int nameCheck) { this.nameCheck = nameCheck; } public void setAddressCheck(int addressCheck) { this.addressCheck = addressCheck; } public void setModelProb(double modelProb) { this.modelProb = modelProb; } public void setStatus(String status) { this.status = status; }}Let’s look at a snippet of the Java code that invokes the Drools rules, see below:
让我们看一下调用Drools规则的Java代码片段,如下所示:
//run drools rulesKieServices ks = KieServices.Factory.get();KieContainer kContainer = ks.getKieClasspathContainer();KieSession kSession = kContainer.newKieSession("ksession-rules");// go !kSession.insert(applicant);kSession.fireAllRules();kSession.destroy();This code creates a KieSession and then inserts the data we want the rules to execute against into the KieSession. FireAllRules() tells Drools to do just that, fire all rules. Then Destroy() is used for cleanup. The Java based Rules MS takes the output of the drools rules and ultimately writes it to Kafka where it can be consumed.
这段代码创建了一个KieSession,然后将要对其执行规则的数据插入KieSession中。 FireAllRules()告诉Drools这样做,触发所有规则。 然后使用Destroy()进行清理。 基于Java的Rules MS获取drools规则的输出,并最终将其写入Kafka,以便在其中使用。
摘要 (Summary)
Rules and machine learning each have their own strengths and are even more powerful when used together. Using the right solution for the problem is key. Leverage rules when you need precision and know the logic, leverage machine learning when you want to predict something but don’t know exactly how. Both can be used in a reactive microservices architectural style that provides a more maintainable, scalable, and faster to deliver architecture.
规则和机器学习各有各的长处,并且在一起使用时会更加强大。 使用正确的解决方案是关键。 当您需要精确度并了解逻辑时,可以利用规则;当您要预测某些事物但又不知道确切的方法时,可以利用机器学习。 两者都可以以React性微服务架构样式使用,该架构样式提供了更易维护,可扩展和更快的交付架构。
I hope you found this blog valuable and thank you for your time!
希望您发现此博客有价值,并感谢您的宝贵时间!
DISCLOSURE STATEMENT: © 2020 Capital One. Opinions are those of the individual author. Unless noted otherwise in this post, Capital One is not affiliated with, nor endorsed by, any of the companies mentioned. All trademarks and other intellectual property used or displayed are property of their respective owners.
披露声明:©2020 Capital One。 观点是个别作者的观点。 除非本文中另有说明,否则Capital One不与任何提及的公司有附属关系或认可。 使用或显示的所有商标和其他知识产权均为其各自所有者的财产。
翻译自: https://medium.com/capital-one-tech/a-modern-dilemma-when-to-use-rules-vs-machine-learning-61cc908769b0
机器学习项目中遇到的难题
相关文章:
- 摩根大通银行被黑客攻克, ATM机/网银危在旦夕,winxp退市灾难来临了
- 使用 Flutter 加速应用开发
- 微软能攻克云计算吗
- 攻克微服务中的最大难点:用户数据
- stm32进不去串口中断的问题
- nodeJs 接收上传文件
- [Python黑帽] 一.获取Windows主机信息、注册表、U盘历史痕迹和回收站文件
- [IOS APP] 夜听刘筱
- AVR USART接收中断程序
- 关于post数据服务器端接收不全
- 计算机中的二进制实验报告,+实验二 计算机的数据表示和计算.doc
- 周例会总结
- 软件工程例会一
- 第二次例会
- 第七次例会
- 第六次例会
- 第八次例会
- 第三次例会
- 第四次例会
- 第五次例会
- 如何开好项目例会?
- 计算机工程学院文艺例会,计算机工程系团总支学生会召开第二次全体例会
- 计算机工程学院文艺例会,信息科学与工程学院学生会学生会全体例会暨部门风采展示大会...
- 工作例会定义
- 项目周例会
- Java发送报文与接收报文
- java 报文长度_关于报文长度的理解
- 数据报文大小
- 普通报文和定长报文
- 报文的理解
机器学习项目中遇到的难题_现代难题:何时使用规则与机器学习相关推荐
- 如何在机器学习项目中使用统计方法的示例
摘要: 在本文中,将通过十个实例介绍在机器学习项目中起关键作用的统计学方法. 统计学和机器学习是两个密切相关的领域.两者的界限有时非常模糊,例如有一些明显属于统计学领域的方法可以很好地处理机器学习项目 ...
- 使用什么优化器_在机器学习项目中该如何选择优化器?
导读 几种流行的优化器的介绍以及优缺点分析,并给出了选择优化器的几点指南. 本文概述了计算机视觉.自然语言处理和机器学习中常用的优化器.此外,你会找到一个基于三个问题的指导方针,以帮助你的下一个机器学 ...
- 凸优化 机器学习 深度学习_我应该在机器学习项目中使用哪个优化程序
凸优化 机器学习 深度学习 This article provides a summary of popular optimizers used in computer vision, natural ...
- 机器学习项目中的数据预处理与数据整理之比较
要点 在常见的机器学习/深度学习项目里,数据准备占去整个分析管道的60%到80%. 市场上有各种用于数据清洗和特征工程的编程语言.框架和工具.它们之间的功能有重叠,也各有权衡. 数据整理是数据预处理的 ...
- 【机器学习基础】在机器学习项目中该如何选择优化器
作者:Philipp Wirth 编译:ronghuaiyang 导读 几种流行的优化器的介绍以及优缺点分析,并给出了选择优化器的几点指南. 本文概述了计算机视觉.自然语言处理和机器学习中常用的优 ...
- java项目中多个定时器_在java项目中如何使用Timer定时器
在java项目中如何使用Timer定时器 发布时间:2020-11-16 16:36:16 来源:亿速云 阅读:97 作者:Leah 在java项目中如何使用Timer定时器?很多新手对此不是很清楚, ...
- 设计模式在项目中的应用案例_设计模式在项目中的应用(初学者版)
文章首发链接: 设计模式在项目中的实际应用(应试版)mp.weixin.qq.com 本文适用于设计模式初学者. 很多人学习了设计模式,但在项目开发中仍然不知道如何使用: 很多小伙伴在课堂上跟着老师 ...
- IntelliJ IDEA 如何知道项目中的模块数据_如何从项目源中选择模块加入当前项目中(添加模块)_如何移除项目中的模块(移除模块/删除模块)
文章目录 IDEA 如何获取项目的模块数据 从项目源中选择模块加入当前项目中 如何移除项目中的模块 方式一,选择模块的根目录(Content Root),鼠标右键 Remove 方式二,打开[项目结构 ...
- pycharm项目中如何安装包_如何将Thymeleaf技术集成到SpringBoot项目中
给天气预报一个"面子" 截至目前,不仅有了天气预报的API接口,也有了数据的缓存方案.现在,就要进行天气预报服务的实现,也就是说,这里需要一个面向用户的应用.这个应用应该拥有友好的 ...
最新文章
- 34.TokenInterceptor防止表单重复提交
- [Share]2008年国外最佳Web设计/开发技巧、脚本及资源总结
- redis实现分布式锁——核心 setx+pipe watch监控key变化-事务
- Mysql报错Fatal error occurred in the transaction branch - check your data for consistency
- 数据分析工具有哪些类型
- 比较 Cache 和虚拟存储器,说明它们的相似点和不同。
- 三层交换机与路由器对接上网
- Atitit Java内容仓库(Java Content Repository,JCR)的JSR-170 文件存储api标准 目录 1. Java内容仓库 1 2. Java内容仓库 2 2.1.
- 递推DP UVA 473 Raucous Rockers
- 常用的薪酬管理系统有哪些,薪酬管理需要具备哪些功能?
- 阿里云安全恶意程序检测冠军经验分享(万字长文)
- C#简单实现office转pdf、pdf转图片
- JavaBean技术的应用——购物车
- ventory做U盘启动,使用vmware进行测试U盘系统盘是否制作成功
- 【CSS】线性渐变属性值及范例详解
- 推荐系统(1)——先做一个出来(先实战,后理论)
- 第四章-循环程序设计代码实例(C++蓝豹子)
- [fielddata] Data too large, data for [_id] would be [13181907968/12.2gb]
- 超级大脑计算机,潮湿计算机:拥有人类智慧的超级大脑
- 实战笔记:利用pandas提升分词后过滤停用词的效率