基于深度学习lstm_基于LSTM的深度恶意软件分析
基于深度学习lstm
Malware development has seen diversity in terms of architecture and features. This advancement in the competencies of malware poses a severe threat and opens new research dimensions in malware detection. This study is focused on metamorphic malware that is the most advanced member of the malware family. It is quite impossible for anti-virus applications using traditional signature-based methods to detect metamorphic malware, which makes it difficult to classify this type of malware accordingly. Recent research literature about malware detection and classification discusses this issue related to malware behaviour.
恶意软件的开发在体系结构和功能方面具有多样性。 恶意软件能力的提高带来了严重威胁,并为恶意软件检测打开了新的研究领域。 这项研究的重点是变形恶意软件,它是恶意软件家族中最先进的成员。 使用传统的基于签名的方法的防病毒应用程序几乎不可能检测到变形的恶意软件,这使得很难对此类恶意软件进行分类。 有关恶意软件检测和分类的最新研究文献讨论了与恶意软件行为有关的问题。
Cite The Work If you find this implementation useful please cite it:
引用工作如果您发现此实现有用,请引用:
@article{10.7717/peerj-cs.285,title = {Deep learning based Sequential model for malware analysis using Windows exe API Calls},author = {Catak, Ferhat Ozgur and Yazı, Ahmet Faruk and Elezaj, Ogerta and Ahmed, Javed},year = 2020,month = jul,keywords = {Malware analysis, Sequential models, Network security, Long-short-term memory, Malware dataset},volume = 6,pages = {e285},journal = {PeerJ Computer Science},issn = {2376-5992},url = {https://doi.org/10.7717/peerj-cs.285},doi = {10.7717/peerj-cs.285}}You can access the dataset from my My GitHub Repository.
您可以从我的GitHub存储库中访问数据集。
介绍 (Introduction)
Malicious software, commonly known as malware, is any software intentionally designed to cause damage to computer systems and compromise user security. An application or code is considered malware if it secretly acts against the interests of the computer user and performs malicious activities. Malware targets various platforms such as servers, personal computers, mobile phones, and cameras to gain unauthorized access, steal personal data, and disrupt the normal function of the system.
恶意软件(通常称为恶意软件)是故意设计成对计算机系统造成损害并危及用户安全的任何软件。 如果应用程序或代码秘密地危害计算机用户的利益并执行恶意活动,则被认为是恶意软件。 恶意软件针对服务器,个人计算机,移动电话和相机等各种平台,以获取未经授权的访问,窃取个人数据并破坏系统的正常功能。
One approach to deal with malware protection problem is by identifying the malicious software and evaluating its behaviour. Usually, this problem is solved through the analysis of malware behaviour. This field closely follows the model of malicious software family, which also reflects the pattern of malicious behaviour. There are very few studies that have demonstrated the methods of classification according to the malware families.
解决恶意软件保护问题的一种方法是识别恶意软件并评估其行为。 通常,此问题是通过分析恶意软件行为来解决的。 该领域紧密遵循恶意软件家族的模型,它也反映了恶意行为的模式。 很少有研究证明了根据恶意软件家族进行分类的方法。
All operating system API calls made to act by any software show the overall direction of this program. Whether this program is a malware or not can be learned by examining these actions in-depth. If it is malware, then what is its malware family. The malware-made operating system API call is a data attribute, and the sequence in which those API calls are generated is also critical to detect the malware family. Performing specific API calls is a particular order that represents a behaviour. One of the deep learning methods LSTM (long-short term memory) has been commonly used in the processing of such time-sequential data.
由任何软件执行的所有操作系统API调用均显示该程序的总体方向。 可以通过深入检查这些操作来了解该程序是否为恶意软件。 如果是恶意软件,那么其恶意软件家族是什么。 恶意软件进行的操作系统API调用是一个数据属性,并且生成这些API调用的顺序对于检测恶意软件家族也很关键。 执行特定的API调用是代表行为的特定顺序。 深度学习方法之一LSTM(长期短期记忆)已普遍用于处理此类按时间顺序排列的数据。
系统架构 (System Architecture)
This research has two main objectives; first, we created a relevant dataset, and then, using this dataset, we did a comparative study using various machine learning to detect and classify malware automatically based on their types.
这项研究有两个主要目标; 首先,我们创建了一个相关的数据集,然后,使用此数据集,我们进行了一项比较研究,使用各种机器学习来根据恶意软件的类型自动检测和分类恶意软件。
数据集创建 (Dataset Creation)
One of the most important contributions of this work is the new Windows PE Malware API sequence dataset, which contains malware analysis information. There are 7107 malware from different classes in this dataset. The Cuckoo Sandbox application, as explained above, is used to obtain the Windows API call sequences of malicious software, and VirusTotal Service is used to detect the classes of malware.
这项工作最重要的贡献之一就是新的Windows PE恶意软件API序列数据集,其中包含恶意软件分析信息。 该数据集中有7107个来自不同类别的恶意软件。 如上所述,Cuckoo Sandbox应用程序用于获取恶意软件的Windows API调用序列,而VirusTotal Service用于检测恶意软件的类别。
The following figure illustrates the system architecture used to collect the data and to classify them using LSTM algorithms.
下图说明了用于收集数据并使用LSTM算法对其进行分类的系统体系结构。
Our system consists of three main parts, data collection, data pre-processing and analyses, and data classification.
我们的系统包括三个主要部分,数据收集,数据预处理和分析以及数据分类。
The following steps were followed when creating the dataset.
创建数据集时,遵循以下步骤。
Cuckoo Sandbox application is installed on a computer running Ubuntu Linux distribution. The analysis machine was run as a virtual server to run and analyze malware. The Windows operating system is installed on this server.
Cuckoo Sandbox应用程序安装在运行Ubuntu Linux发行版的计算机上。 分析机作为虚拟服务器运行,以运行和分析恶意软件。 Windows操作系统已安装在此服务器上。
让我们编码 (Let’s coding)
We import the usual standard libraries to build an LSTM model to detect the malware.
我们导入常用的标准库以构建LSTM模型来检测恶意软件。
import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.preprocessing import LabelEncoderfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import confusion_matrixfrom keras.preprocessing.text import Tokenizerfrom keras.layers import LSTM, Dense, Dropout, Embeddingfrom keras.preprocessing import sequencefrom keras.utils import np_utilsfrom keras.models import Sequentialfrom keras.layers import SpatialDropout1Dfrom mlxtend.plotting import plot_confusion_matrixIn this work, we will use standard our malware dataset to show the results. You can access the dataset from My GitHub Repository. We need to merge the call and the label datasets.
在这项工作中,我们将使用标准的恶意软件数据集来显示结果。 您可以从My GitHub Repository访问数据集。 我们需要合并调用和标签数据集。
malware_calls_df = pd.read_csv("calls.zip", compression="zip", sep="\t", names=["API_Calls"])malware_labels_df = pd.read_csv("types.zip", compression="zip", sep="\t", names=["API_Labels"])malware_calls_df["API_Labels"] = malware_labels_df.API_Labelsmalware_calls_df["API_Calls"] = malware_calls_df.API_Calls.apply(lambda x: " ".join(x.split(",")))malware_calls_df["API_Labels"] = malware_calls_df.API_Labels.apply(lambda x: 1 if x == "Virus" else 0)Let’s analyze the class distribution
让我们分析类的分布
sns.countplot(malware_calls_df.API_Labels)plt.xlabel('Labels')plt.title('Class distribution')plt.savefig("class_distribution.png")plt.show()
Now we can create our sequence matrix. In order to build an LSTM model, you need to create a tokenization based sequence matrix as the input dataset
现在我们可以创建序列矩阵。 为了构建LSTM模型,您需要创建一个基于标记化的序列矩阵作为输入数据集
max_words = 800max_len = 100X = malware_calls_df.API_CallsY = malware_calls_df.API_Labels.astype('category').cat.codestok = Tokenizer(num_words=max_words)tok.fit_on_texts(X)print('Found %s unique tokens.' % len(tok.word_index))X = tok.texts_to_sequences(X.values)X = sequence.pad_sequences(X, maxlen=max_len)print('Shape of data tensor:', X.shape)X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.15)le = LabelEncoder()Y_train_enc = le.fit_transform(Y_train)Y_train_enc = np_utils.to_categorical(Y_train_enc)Y_test_enc = le.transform(Y_test)Y_test_enc = np_utils.to_categorical(Y_test_enc)Found 278 unique tokens.Shape of data tensor: (7107, 100)The LSTM based classification model is then given for example as exercise here:
然后在此处作为示例给出基于LSTM的分类模型:
def malware_model(act_func="softsign"): model = Sequential() model.add(Embedding(max_words, 300, input_length=max_len)) model.add(SpatialDropout1D(0.1)) model.add(LSTM(32, dropout=0.1, recurrent_dropout=0.1, return_sequences=True, activation=act_func)) model.add(LSTM(32, dropout=0.1, activation=act_func, return_sequences=True)) model.add(LSTM(32, dropout=0.1, activation=act_func)) model.add(Dense(128, activation=act_func)) model.add(Dropout(0.1)) model.add(Dense(256, activation=act_func)) model.add(Dropout(0.1)) model.add(Dense(128, activation=act_func)) model.add(Dropout(0.1)) model.add(Dense(1, name='out_layer', activation="linear")) return modelThe next step is to train the model. I trained and saved my model. Because of the dataset, the training stage takes lots of time. In order to reduce the execution time, you can load my previous trained model from the GitHub repository.
下一步是训练模型。 我训练并保存了模型。 由于存在数据集,训练阶段需要很多时间。 为了减少执行时间,您可以从GitHub存储库加载我以前训练有素的模型。
model = malware_model()print(model.summary())model.compile(loss='mse', optimizer="rmsprop", metrics=['accuracy'])filepath = "lstm-malware-model.hdf5"model.load_weights(filepath)history = model.fit(X_train, Y_train, batch_size=1000, epochs=10, validation_data=(X_test, Y_test), verbose=1)Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param # =================================================================embedding (Embedding) (None, 100, 300) 240000 _________________________________________________________________spatial_dropout1d (SpatialDr (None, 100, 300) 0 _________________________________________________________________lstm (LSTM) (None, 100, 32) 42624 _________________________________________________________________lstm_1 (LSTM) (None, 100, 32) 8320 _________________________________________________________________lstm_2 (LSTM) (None, 32) 8320 _________________________________________________________________dense (Dense) (None, 128) 4224 _________________________________________________________________dropout (Dropout) (None, 128) 0 _________________________________________________________________dense_1 (Dense) (None, 256) 33024 _________________________________________________________________dropout_1 (Dropout) (None, 256) 0 _________________________________________________________________dense_2 (Dense) (None, 128) 32896 _________________________________________________________________dropout_2 (Dropout) (None, 128) 0 _________________________________________________________________out_layer (Dense) (None, 1) 129 =================================================================Total params: 369,537Trainable params: 369,537Non-trainable params: 0_________________________________________________________________NoneEpoch 1/107/7 [==============================] - 22s 3s/step - loss: 0.0486 - accuracy: 0.9487 - val_loss: 0.0311 - val_accuracy: 0.9672Epoch 2/107/7 [==============================] - 21s 3s/step - loss: 0.0378 - accuracy: 0.9591 - val_loss: 0.0302 - val_accuracy: 0.9672Epoch 3/107/7 [==============================] - 21s 3s/step - loss: 0.0364 - accuracy: 0.9604 - val_loss: 0.0362 - val_accuracy: 0.9625Epoch 4/107/7 [==============================] - 20s 3s/step - loss: 0.0378 - accuracy: 0.9593 - val_loss: 0.0328 - val_accuracy: 0.9616Epoch 5/107/7 [==============================] - 22s 3s/step - loss: 0.0365 - accuracy: 0.9609 - val_loss: 0.0351 - val_accuracy: 0.9606Epoch 6/107/7 [==============================] - 21s 3s/step - loss: 0.0369 - accuracy: 0.9601 - val_loss: 0.0369 - val_accuracy: 0.9606Epoch 7/107/7 [==============================] - 22s 3s/step - loss: 0.0371 - accuracy: 0.9594 - val_loss: 0.0395 - val_accuracy: 0.9625Epoch 8/107/7 [==============================] - 22s 3s/step - loss: 0.0378 - accuracy: 0.9601 - val_loss: 0.0365 - val_accuracy: 0.9588Epoch 9/107/7 [==============================] - 22s 3s/step - loss: 0.0358 - accuracy: 0.9618 - val_loss: 0.0440 - val_accuracy: 0.9456Epoch 10/107/7 [==============================] - 21s 3s/step - loss: 0.0373 - accuracy: 0.9589 - val_loss: 0.0354 - val_accuracy: 0.9644模型评估 (Model Evaluation)
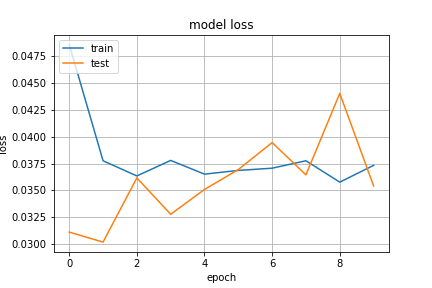
Now, we have finished the training phase of the LSTM model. We can evaluate our model’s classification performance using the confusion matrix. According to the confusion matrix, the model’s classification performance quite good.
现在,我们已经完成了LSTM模型的训练阶段。 我们可以使用混淆矩阵评估模型的分类性能。 根据混淆矩阵,该模型的分类性能相当好。
y_test_pred = model.predict_classes(X_test)cm = confusion_matrix(Y_test, y_test_pred)plot_confusion_matrix(conf_mat=cm, show_absolute=True, show_normed=True, colorbar=True)plt.savefig("confusion_matrix.png")plt.show()
Let’s continue with the training history of our model.
让我们继续我们模型的训练历史。
plt.plot(history.history['accuracy'])plt.plot(history.history['val_accuracy'])plt.title('model accuracy')plt.ylabel('accuracy')plt.xlabel('epoch')plt.legend(['train', 'test'], loc='upper left')plt.grid()plt.savefig("accuracy.png")plt.show()plt.plot(history.history['loss'])plt.plot(history.history['val_loss'])plt.title('model loss')plt.ylabel('loss')plt.xlabel('epoch')plt.legend(['train', 'test'], loc='upper left')plt.grid()plt.savefig("loss.png")plt.show()
结论 (Conclusion)
The purpose of this study was to create an LSTM based malware detection model using my previous malware dataset. Although our dataset contains instances that belong to some malware families with unbalanced distribution, we have shown that this problem does not affect classification performance.
这项研究的目的是使用我以前的恶意软件数据集创建基于LSTM的恶意软件检测模型。 尽管我们的数据集包含的实例属于不均衡分布的某些恶意软件家族,但我们已经表明此问题不会影响分类性能。
翻译自: https://towardsdatascience.com/deep-lstm-based-malware-analysis-6b36ac247f34
基于深度学习lstm
相关文章:
- 与DC漫画招牌角色“蝙蝠侠”结缘,NFT向前再迈进一步
- 捍卫自由的互联网,对 Web3 说不
- 基于深度学习lstm_深度学习和基于LSTM的恶意软件分类
- Lunch Time
- Android 4.03 编译系统------lunch
- android mm是什么版本,Android中m、mm、mmm、mma、mmma的区别
- Android编译详解之lunch命令 【转】
- 【Bash百宝箱】Android envsetup.sh及lunch
- 一段php代码,请问一段PHP代码是什么意思?
- Android 编译之source和lunch
- lunch
- 计算机课的英语怎么念,电脑课是什么意思
- Linux指令lunch,linux命令 launch是什么命令?
- dig是什么意思 java_dig的意思是挖掘,dig deep是什么意思呢?
- Android之lunch命令
- oracle+ace是什么意思,ace是什么意思
- Android编译详解之lunch命令
- no free lunch
- #1636 : Pangu and Stones(区间dp)
- PanGu 开发板构建 Yocto Linux 时的注意事项
- Pangu and Stones 解题报告
- Lucene.net(4.8.0)+PanGu分词器 问题记录一 分词器Analyzer的构造和内部成员ReuseStategy
- 2017 icpc beijing J - Pangu and Stones
- 我使用pangu模块做了一个文本格式化小工具!
- C - Pangu and Stones 区间DP
- Pangu and Stones (hihocoder 1636)
- PANGU 生态乐园 NFT 系列上线 The Sandbox 市场平台
- 区间dp(Pangu and Stones)
- Pangu and Stones(区间 dp)
- PanGu STM32MP开发板更新固件
基于深度学习lstm_基于LSTM的深度恶意软件分析相关推荐
- 浅谈深度学习:基于对LSTM项目`LSTM Neural Network for Time Series Prediction`的理解与回顾
浅谈深度学习:基于对LSTM项目LSTM Neural Network for Time Series Prediction的理解与回顾#### 总包含文章: 一个完整的机器学习模型的流程 浅谈深度学 ...
- 深度学习必备书籍——《Python深度学习 基于Pytorch》
作为一名机器学习|深度学习的博主,想和大家分享几本深度学习的书籍,让大家更快的入手深度学习,成为AI达人!今天给大家介绍的是:<Python深度学习 基于Pytorch> 文章目录 一.背 ...
- 深度学习实战—基于TensorFlow 2.0的人工智能开发应用
作者:辛大奇 著 出版社:中国水利水电出版社 品牌:智博尚书 出版时间:2020-10-01 深度学习实战-基于TensorFlow 2.0的人工智能开发应用
- Python深度学习:基于TensorFlow
作者:吴茂贵,王冬,李涛,杨本法 出版社:机械工业出版社 品牌:机工出版 出版时间:2018-10-01 Python深度学习:基于TensorFlow
- Python深度学习:基于PyTorch [Deep Learning with Python and PyTorch]
作者:吴茂贵,郁明敏,杨本法,李涛,张粤磊 著 出版社:机械工业出版社 品牌:机工出版 出版时间:2019-11-01 Python深度学习:基于PyTorch [Deep Learning with ...
- 深度学习入门 基于Python的理论与实现
作者:斋藤康毅 出版社:人民邮电出版社 品牌:iTuring 出版时间:2018-07-01 深度学习入门 基于Python的理论与实现
- 【深度学习】基于Pytorch进行深度神经网络计算(一)
[深度学习]基于Pytorch进行深度神经网络计算(一) 文章目录 1 层和块 2 自定义块 3 顺序块 4 在正向传播函数中执行代码 5 嵌套块 6 参数管理(不重要) 7 参数初始化(重要) 8 ...
- 【深度学习】基于Pytorch进行深度神经网络计算(二)
[深度学习]基于Pytorch进行深度神经网络计算(二) 文章目录 1 延后初始化 2 Pytorch自定义层2.1 不带参数的层2.2 带参数的层 3 基于Pytorch存取文件 4 torch.n ...
- 【深度学习】基于Pytorch的卷积神经网络概念解析和API妙用(一)
[深度学习]基于Pytorch的卷积神经网络API妙用(一) 文章目录 1 不变性 2 卷积的数学分析 3 通道 4 互相关运算 5 图像中目标的边缘检测 6 基于Pytorch的卷积核 7 特征映射 ...
最新文章
- 为什么要读源代码,如何阅读源代码
- centos 自动挂载磁盘
- WCF 第六章 序列化与编码 编码选择
- TCPIP header
- python新手入门代码-[代码全屏查看]-新手初学Python实现某论坛自动签到功能
- 大数据在零售业的应用
- 数据分析------数据处理(2)及 AutoML 学习
- css position, display, float 内联元素、块级元素
- linux 环境变量的设置
- python入门学习—字典(FishC)
- excel两列数据对比找不同_25岁约基奇和25岁姚明得分数据对比,结果和想象中不同...
- php mysql免安装版_资源共享:免安装版nginx+php+mysql+phpmyadmin+memcache开发环境包
- 关于TP3.2.3的反序列化学习
- Unity 视频播放器插件 AVPro Video -- 360全景视频播放+暴风魔镜sdk
- 【王道考研】操作系统 笔记 第一章
- UnrealEditor-RHI.dll 没有被指定在windows上运行
- 选择适合你的虚拟现实体验
- 数字IC设计工程师职业发展规划是什么样的?
- 笔记:springboot-admin 整合spring security应用注册失败问题
- 题目23:打印出如下图案(菱形)