机器学习中决策树的随机森林_决策树和随机森林在机器学习中的使用
机器学习中决策树的随机森林
机器学习 (Machine Learning)
Machine learning is an application of artificial intelligence that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. The 3 main categories of machine learning are supervised learning, unsupervised learning, and reinforcement learning. In this post, we shall focus on supervised learning for classification problems.
中号 achine学习是人工智能,它提供系统能够自动学习并从经验中提高,而不明确地编程能力的应用。 机器学习的3个主要类别是监督学习,无监督学习和强化学习。 在这篇文章中,我们将专注于分类问题的监督学习。
Supervised learning learns from past data and applies the learning to present data to predict future events. In the context of classification problems, the input data is labeled or tagged as the right answer to enable accurate predictions.
监督学习从过去的数据中学习,并将学习应用于当前的数据以预测未来的事件。 在分类问题的上下文中,将输入数据标记或标记为正确答案,以实现准确的预测。
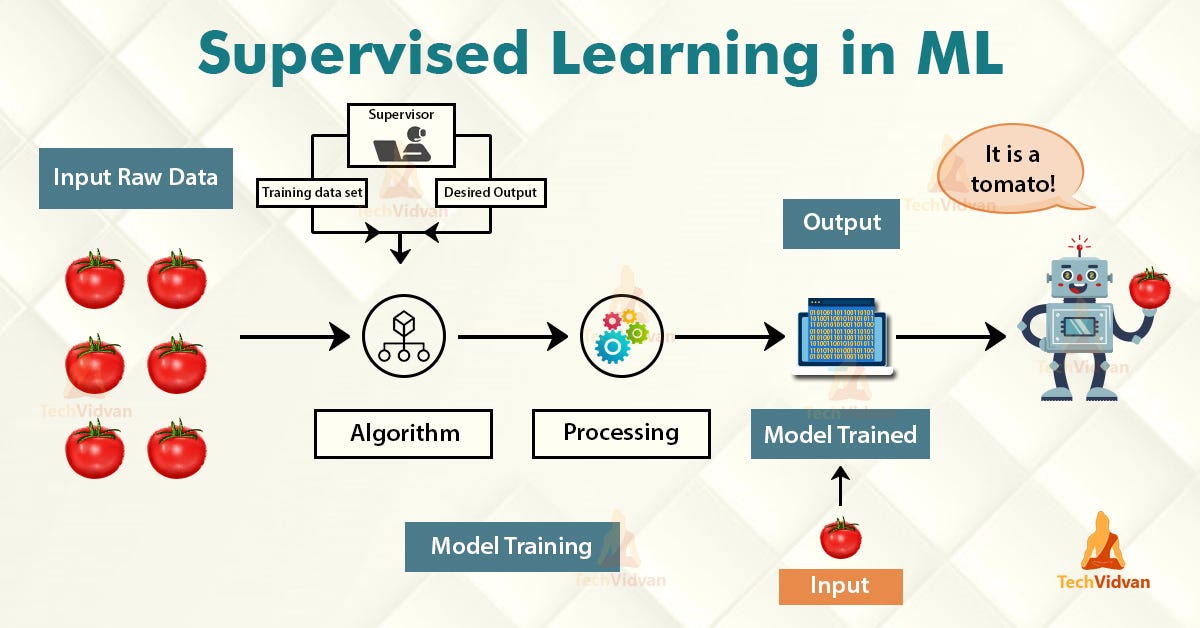
Tree-based learning algorithms are one of the most commonly used supervised learning methods. They empower predictive models with high accuracy, stability, ease of interpretation, and are adaptable at solving any classification or regression problem.
基于树的学习算法是最常用的监督学习方法之一。 它们使预测模型具有较高的准确性,稳定性,易解释性,并且适用于解决任何分类或回归问题。
Decision Tree predicts the values of responses by learning decision rules derived from features. In a tree structure for classification, the root node represents the entire population, while decision nodes represent the particular point where the decision tree decides on which specific feature to split on. The purity for each feature will be assessed before and after the split. The decision tree will then decide to split on a specific feature that produces the purest leaf nodes (ie. terminal nodes at each branch).
决策树通过学习从要素派生的决策规则来预测响应的值。 在用于分类的树结构中 , 根节点代表整个种群,而决策节点则代表决策树确定要分割的特定特征的特定点。 在拆分之前和之后,将评估每个功能部件的纯度。 然后,决策树将决定拆分产生一个最纯叶节点 (即每个分支的终端节点)的特定功能。
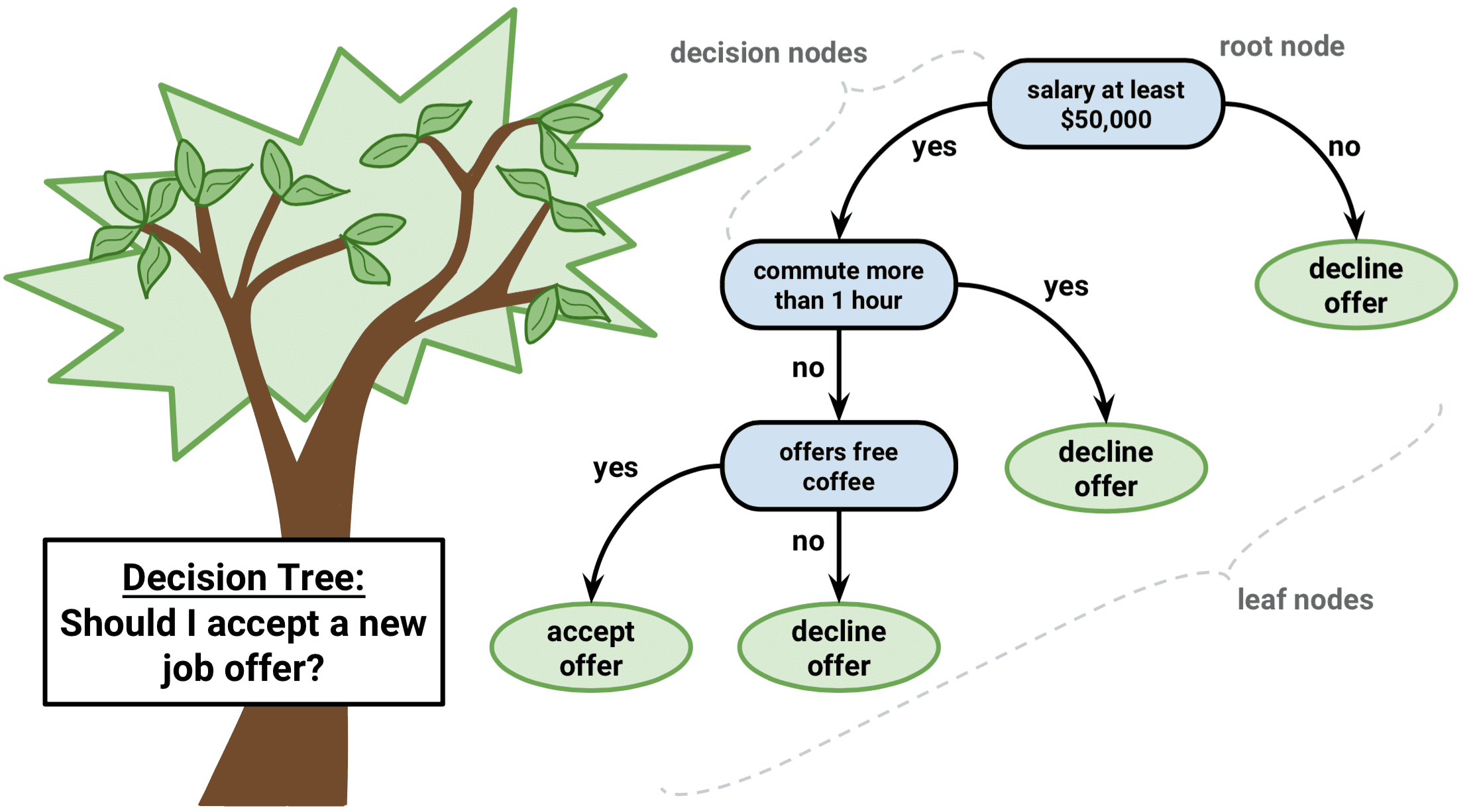
A significant advantage of a decision tree is that it forces the consideration of all possible outcomes of a decision and traces each path to a conclusion. It creates a comprehensive analysis of the consequences along each branch and identifies decision nodes that need further analysis.
决策树的显着优势在于,它可以强制考虑决策的所有可能结果,并跟踪得出结论的每条路径。 它对每个分支的后果进行全面分析,并确定需要进一步分析的决策节点。
However, a decision tree has its own limitations. The reproducibility of the decision tree model is highly sensitive, as a small change in the data can result in a large change in the tree structure. Space and time complexity of the decision tree model is relatively higher, leading to longer model training time. A single decision tree is often a weak learner, hence a bunch of decision tree (known as random forest) is required for better prediction.
但是, 决策树有其自身的局限性 。 决策树模型的可重复性非常敏感,因为数据的微小变化会导致树形结构的巨大变化。 决策树模型的时空复杂度相对较高,导致模型训练时间更长。 单个决策树通常学习能力较弱,因此需要一堆决策树(称为随机森林)才能更好地进行预测。
The random forest is a more powerful model that takes the idea of a single decision tree and creates an ensemble model out of hundreds or thousands of trees to reduce the variance. Thus giving the advantage of obtaining a more accurate and stable prediction.
随机森林是一个功能更强大的模型,它采用单个决策树的概念,并从数百或数千棵树中创建一个集成模型以减少差异。 因此具有获得更准确和稳定的预测的优势 。
Each tree is trained on a random set of observations, and for each split of a node, only a random subset of the features is used for making a split. When making predictions, the random forest does not suffer from overfitting as it averages the predictions for each of the individual decision trees, for each data point, in order to arrive at a final classification.
每棵树都在一组随机的观测值上训练,并且对于节点的每个拆分,仅使用特征的随机子集进行拆分。 在进行预测时,随机森林不会遭受过度拟合的影响,因为它会针对每个数据点对每个单独决策树的预测取平均,以得出最终分类。
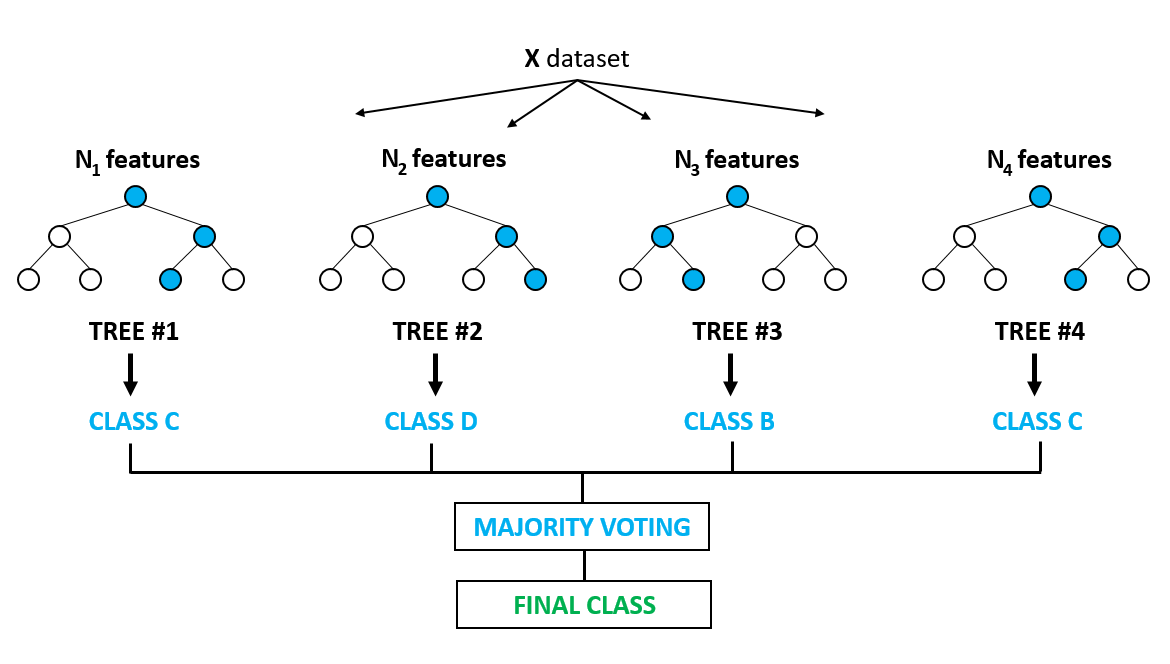
We shall approach a classification problem and explore the basics of how decision trees work, how individual decisions trees are combined to form a random forest, how to fine-tune the hyper-parameters to optimize random forest, and ultimately discover the strengths of using random forests.
我们将研究分类问题,并探索决策树如何工作,如何将单个决策树组合以形成随机森林,如何微调超参数以优化随机森林的基础知识,并最终发现使用随机森林的优势。森林。
问题陈述:预测一个人每年的收入是否超过50,000美元。 (Problem Statement: To predict whether a person makes more than U$50,000 per year.)
让我们开始编码! (Let’s start coding!)
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.utils import resample
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import classification_report, precision_recall_curve, roc_curve, roc_auc_score
import scikitplot as skplt
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline资料准备 (Data Preparation)
Load the Census Income Dataset from the URL and display the top 5 rows to inspect the data.
从URL加载人口普查收入数据集 ,并显示前5行以检查数据。
# Add header=None as the first row of the file contains the names of the columns.
# Add engine='python' to avoid parser warning raised for reading a file that doesn’t use the default ‘c’ parser.income_data = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data', header=None, delimiter=', ', engine='python')
income_data.head()
# Add headers to dataset
headers = ['age','workclass','fnlwgt','education','education_num','marital_status','occupation','relationship','race','sex','capital_gain','capital_loss','hours_per_week','native_country','income']income_data.columns = headers
income_data.head()
数据清理 (Data Cleaning)
# Check for empty cells and if data types are correct for the respective columns
income_data.info()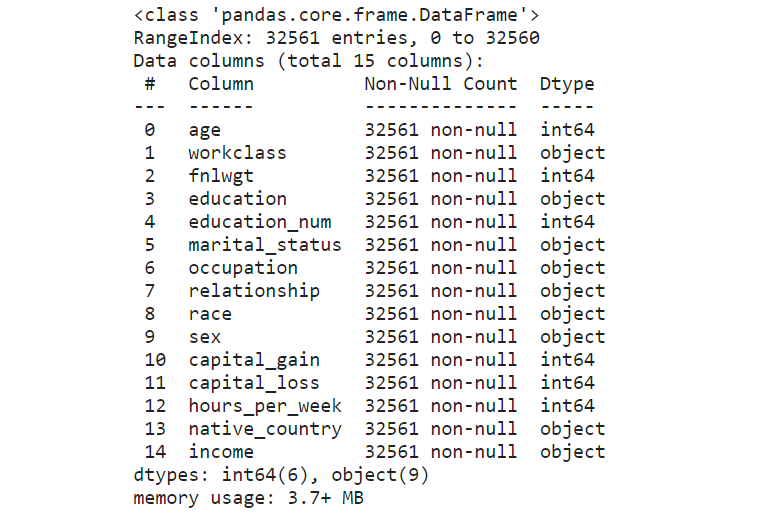
Box plots are useful as they show outliers for integer data types within a data set. An outlier is an observation that is numerically distant from the rest of the data. When reviewing a box plot, an outlier is defined as a data point that is located outside the whiskers of the box plot.
箱形图很有用,因为它们显示了数据集中整数数据类型的离群值。 离群值是在数值上与其余数据相距遥远的观测值 。 查看箱形图时,离群值定义为位于箱形图晶须之外的数据点。
# Use a boxplot to detect any outliers
income_data.boxplot(figsize=(30,6), fontsize=20);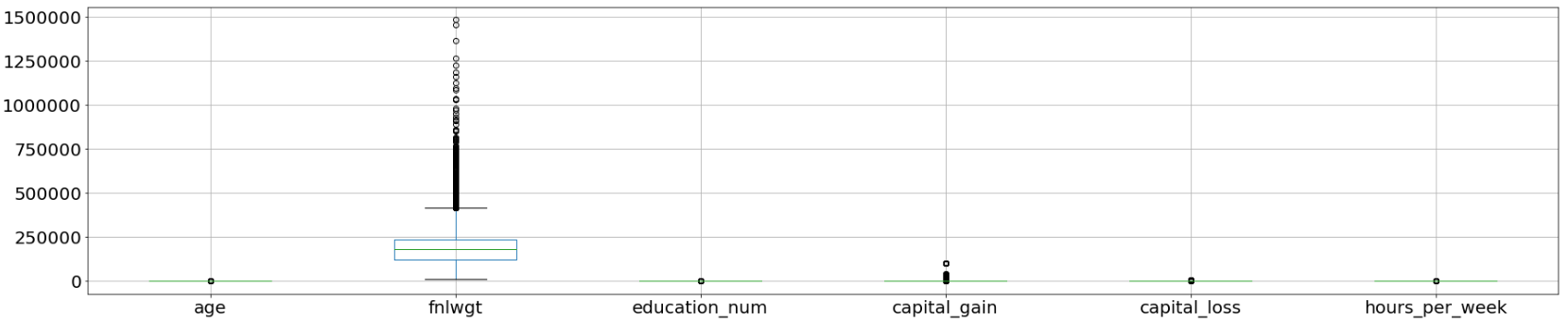
As extracted from the attributes listing in the Census Income Data Set, the feature “fnlwgt” refers to the final weight. It states the number of people the census believes the entry represents. Therefore, this outlier would not be relevant to our analysis and we would proceed to drop this column.
从“ 人口普查收入数据集 ”中的属性列表中提取的功能“ fnlwgt”是指最终权重。 它指出了人口普查相信该条目所代表的人数。 因此,此异常值与我们的分析无关,我们将继续删除此列。
clean_df = income_data.drop(['fnlwgt'], axis=1)
clean_df.info()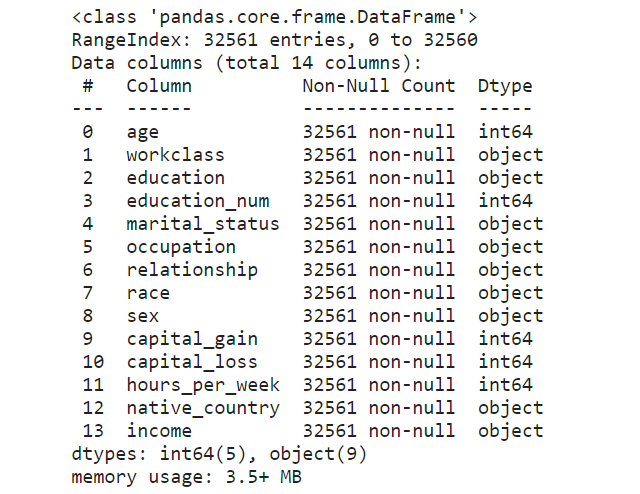
# Select duplicate rows except first occurrence based on all columns
dup_rows = clean_df[clean_df.duplicated()]
dup_rows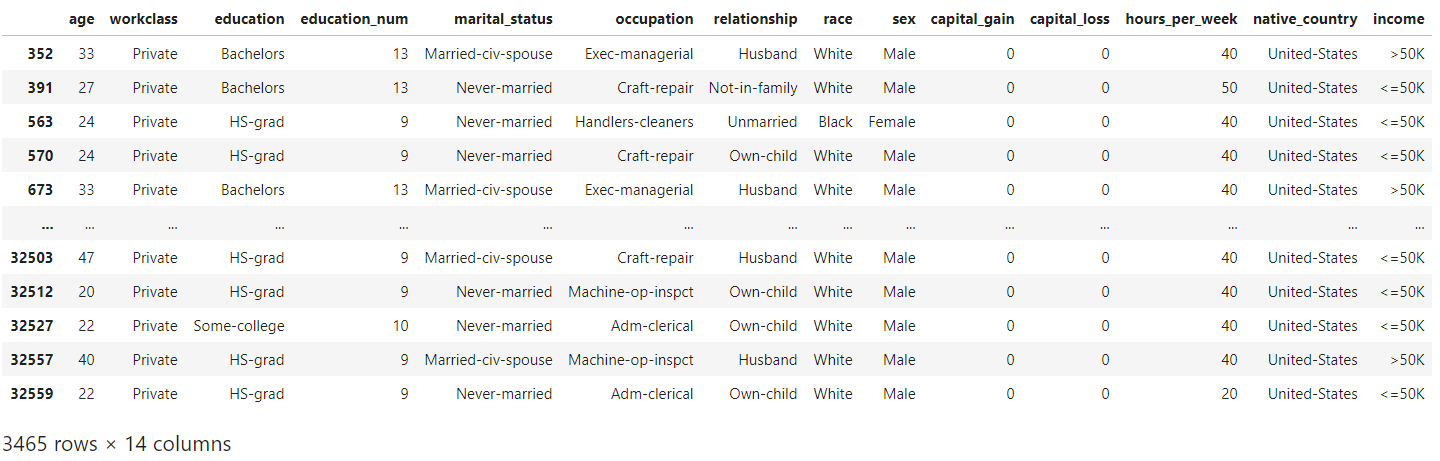
An example of duplicates can be seen in the above rows with the entries “Private” under the “workclass” column. These duplicate rows correspond to samples for different surveyed individuals instead of genuine duplicate rows. As such, we would not remove any duplicated rows to preserve the data for further analysis.
可以在上面的行中看到重复的示例,在“工作类别”列下有条目“私人”。 这些重复的行对应于不同调查对象的样本,而不是真正的重复行。 因此,我们不会删除任何重复的行来保留数据以供进一步分析。
标签编码 (Label Encoding)
Categorical features are encoded into numerical values using label encoding, to convert each class under the specified feature to a numerical value.
使用标签编码将分类要素编码为数值,以将指定要素下的每个类别转换为数值。
# Categorical boolean mask
categorical_feature_mask = clean_df.dtypes==object# Filter categorical columns using mask and turn it into a list
categorical_cols = clean_df.columns[categorical_feature_mask].tolist()# Instantiate labelencoder object
le = LabelEncoder()# Apply label encoder on categorical feature columns
clean_df[categorical_cols] = clean_df[categorical_cols].apply(lambda col: le.fit_transform(col))
clean_df[categorical_cols].head(5)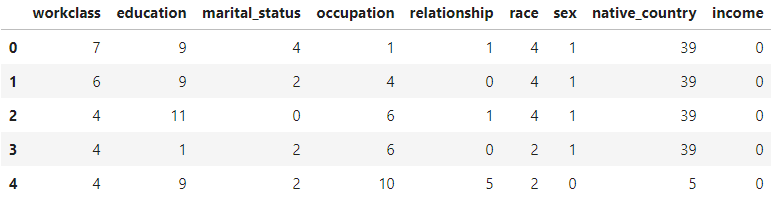
X = clean_df.iloc[:,0:13] # independent columns - features
y = clean_df.iloc[:,-1] # target column - income# Distribution of target variable
print(clean_df["income"].value_counts())
print(clean_df["income"].value_counts(normalize=True))
# 0 for label: <= U$50K
# 1 for label: > U$50K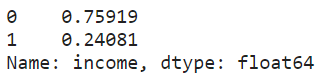
An imbalanced dataset was observed from the above-normalized distribution.
从上述归一化分布中观察到不平衡的数据集。
实验设计 (Design of Experiment)
It would be interesting to see how different factors can affect the performance of each classifier. Let’s consider the following 3 factors:
看看不同的因素如何影响每个分类器的性能会很有趣。 让我们考虑以下三个因素:
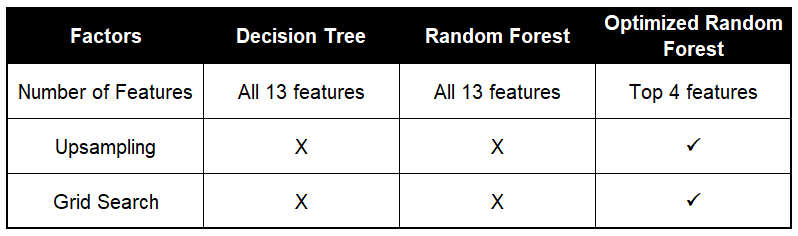
Number of features: When deciding on the number of features to use for a particular dataset, The Elements of Statistical Learning (section 15.3) states that:
特征数量:在确定用于特定数据集的特征数量时, 《统计学习的要素》 (第15.3节)指出:
Typically, for a classification problem with p features, √p features are used in each split.
通常,对于具有p个特征的分类问题,在每个拆分中使用√p个特征。
Thus, we would perform feature selection to choose the top 4 features for the modeling of the optimized random forest. With the ideal number of features, it would help to prevent overfitting and improve model interpretability.
因此,我们将执行特征选择,以选择用于优化随机森林建模的前4个特征。 具有理想数量的功能,将有助于防止过度拟合并提高模型的可解释性。
Upsampling: An imbalanced dataset would lead to a biased model after training. For this particular dataset, we see a distribution of 76% representing the majority class (ie. income <=U$50K) and the remaining 24% representing the minority class (ie. income >U$50K).
上采样:训练后,不平衡的数据集会导致模型产生偏差。 对于这个特定的数据集,我们看到76%的分布代表多数阶层(即,收入<= U $ 50K),其余24%的分布代表少数群体(即,收入> U $ 50K)。
Upon training of the models, we will have the decision tree and random forest achieving a high classification accuracy belonging to the majority class. To overcome this, we would perform an upsampling of the minority class (ie. income >U$50K) to create a balanced dataset for the optimized random forest model.
训练模型后,我们将拥有属于多数类别的,具有较高分类精度的决策树和随机森林。 为了克服这个问题,我们将对少数群体(即收入> 5万美元)进行上采样,以为优化的随机森林模型创建一个平衡的数据集。
Grid search: In order to maximize the performance of the random forest, we can perform a grid search for the best hyperparameters and optimize the random forest model.
网格搜索:为了最大化随机森林的性能,我们可以对最佳超参数执行网格搜索并优化随机森林模型。
资料建模 (Data Modelling)
An initial loading and splitting of the dataset were performed to train and test the decision tree and random forest models, before optimizing the random forest.
在优化随机森林之前,先对数据集进行初始加载和拆分,以训练和测试决策树和随机森林模型。
X_train_bopt, X_test_bopt, y_train_bopt, y_test_bopt = train_test_split(X, y,test_size = 0.3,random_state = 1)Standardization of datasets is a common requirement for many machine learning estimators implemented in scikit-learn. The dataset might behave badly if the individual features do not more or less look like standard normally distributed data, ie. Gaussian with zero mean and unit variance.
标准化 对于scikit-learn中实现的许多机器学习估计器,数据集的数量是一个普遍的要求。 如果各个要素看起来或多或少不像标准正态分布数据(即),则数据集的行为可能会很差。 具有零均值和单位方差的高斯。
# Perform pre-processing to scale numeric features
scale = preprocessing.StandardScaler()
X_train_bopt = scale.fit_transform(X_train_bopt)# Test features are scaled using the scaler computed for the training features
X_test_bopt = scale.transform(X_test_bopt)模型1:决策树 (Model 1: Decision Tree)
# Create decision tree classifier
tree = DecisionTreeClassifier(random_state=1)# Fit training data and training labels to decision tree
tree.fit(X_train_bopt, y_train_bopt)
print(f'Decision Tree has {tree.tree_.node_count} nodes with a maximum depth of {tree.tree_.max_depth}.')print(f'Model Accuracy for train data: {tree.score(X_train_bopt, y_train_bopt)}')
print(f'Model Accuracy for test data: {tree.score(X_test_bopt, y_test_bopt)}')
As there was no limit on the depth, the decision tree model was able to classify every training point perfectly to a large extent.
由于深度没有限制,因此决策树模型能够在很大程度上对每个训练点进行完美分类。
决策树的可视化 (Visualization of the Decision Tree)
By visualizing the decision tree, it will show each node in the tree which we can use to make new predictions. As the tree is relatively large, the decision tree is plotted below, with a maximum depth of 3.
通过可视化决策树,它将显示树中的每个节点,我们可以使用它们进行新的预测。 由于树比较大,下面绘制了决策树,最大深度为3。
# Create and fit decision tree with maximum depth 3
tree = DecisionTreeClassifier(max_depth=3, random_state=1)
tree.fit(X_train_bopt, y_train_bopt)
# Plot the decision tree
plt.figure(figsize=(25,10))
decision_tree_plot = plot_tree(tree, feature_names=X.columns, class_names=['<=50K','>50K'], filled=True, rounded=True, fontsize=14)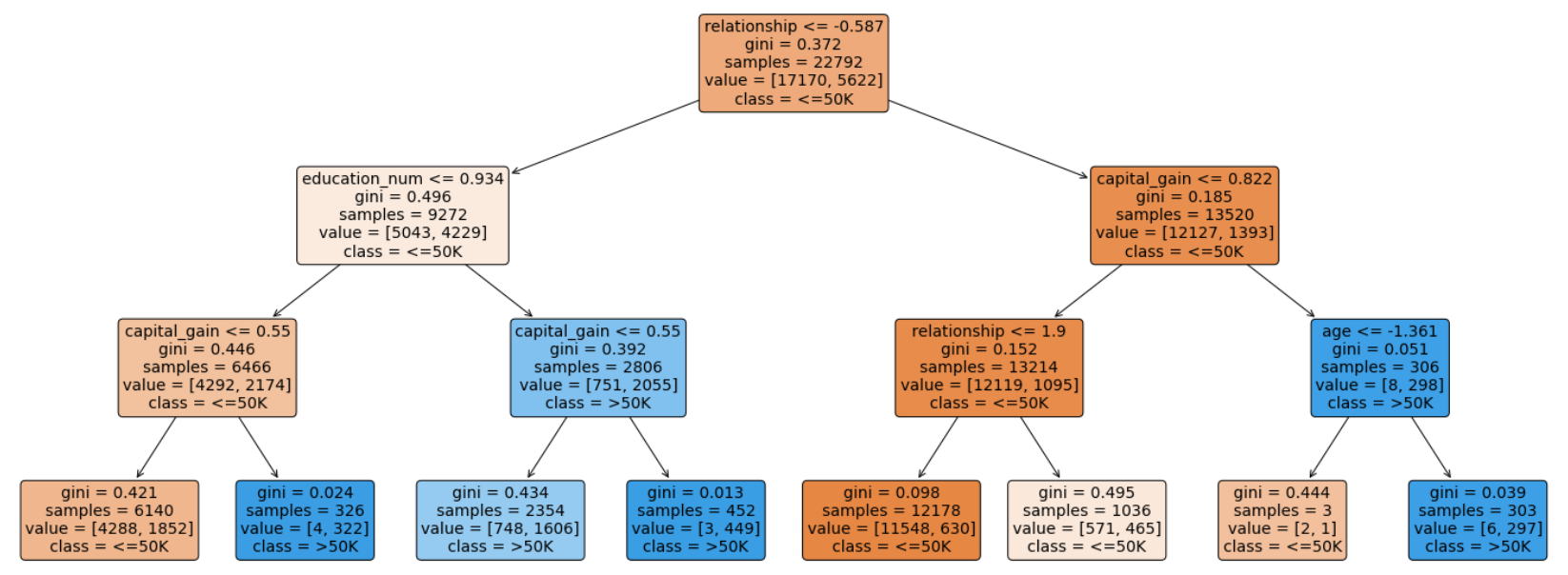
对于每个节点(叶节点除外),五行表示: (For each of the nodes (except the leaf nodes), the five rows represent:)
question asked about the data based on a feature: This determines the way we traverse down the tree for a new data point.question asked about the data based on a feature:这确定了我们遍历树以获取新数据点的方式。gini: The gini impurity of the node represents the probability that a randomly selected sample from a node will be incorrectly classified according to the distribution of samples in the node. The average (weighted by samples) gini impurity decreases with each level of the tree.gini:节点的gini杂质表示从节点中随机选择的样本将根据节点中样本的分布进行错误分类的概率。 树木的每个水平均会降低吉尼杂质的平均值(按样品加权)。samples: The number of training observations in the node.samples:节点中训练观测的数量。value: The number of samples in the respective classes.value:各个类别中的样本数。class: The class predicted for all the points in the node if the tree ended at this depth.class:如果树在此深度处结束,则为节点中所有点预测的类。
The leaf nodes are where the tree makes a prediction. The different colors correspond to the respective classes, with shades ranging from light to dark depending on the gini impurity.
叶子节点是树进行预测的地方。 不同的颜色对应于各个类别,取决于基尼杂质,阴影的范围从浅到深。
修剪决策树 (Pruning the Decision Tree)
Limiting the maximum depth of the decision tree can enable the tree to generalize better to testing data. Although this will lead to reduced accuracy on the training data, it can improve performance on the testing data and provide an objective performance evaluation.
限制决策树的最大深度可以使决策树更好地推广到测试数据。 尽管这将导致训练数据的准确性降低,但可以提高测试数据的性能并提供客观的性能评估。
# Create for loop to prune tree
scores = []for i in range(1, 31):tree = DecisionTreeClassifier(random_state=1, max_depth=i)tree.fit(X_train_bopt, y_train_bopt)score = tree.score(X_test_bopt, y_test_bopt)scores.append(tree.score(X_test_bopt, y_test_bopt))# Plot graph to see how individual accuracy scores changes with tree depth
sns.set_context('talk')
sns.set_palette('dark')
sns.set_style('ticks')plt.plot(range(1, 31), scores)
plt.xlabel("Depth of Tree")
plt.ylabel("Scores")
plt.title("Decision Tree Classifier Accuracy")
plt.show()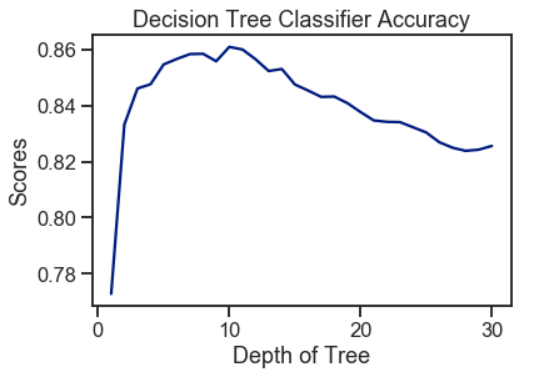
Using the decision tree, a peak of 86% accuracy was achieved with an optimal tree depth of 10. As the depth of the tree increases, the accuracy score decreases gradually. Hence, a deeper tree depth does not reflect a higher accuracy for prediction.
使用决策树时,最佳树深度为10时,达到了86%的精度峰值。随着树的深度增加,精度得分逐渐降低。 因此,更深的树深度不能反映更高的预测精度。
模型2:随机森林 (Model 2: Random Forest)
包外错误评估 (Out-of-Bag Error Evaluation)
The Random Forest Classifier is trained using bootstrap aggregation, where each new tree is fitted from a bootstrap sample of the training observations. The out-of-bag error is the average error for each training observation calculated using predictions from the trees that do not contain the training observation in their respective bootstrap sample. This allows the Random Forest Classifier to be fitted and validated whilst being trained.
使用引导聚合对随机森林分类器进行训练,其中从训练观测值的引导样本中拟合出每棵新树。 袋外误差是每个训练观测值的平均误差,这些误差是使用来自在其各自的引导样本中不包含训练观测值的树的预测所计算出的。 这允许在训练过程中对随机森林分类器进行拟合和验证。
The random forest model was fitted with a range of tree numbers and evaluated on the out-of-bag error for each of the tree’s numbers used.
随机森林模型配有一系列树木编号,并针对所使用的每个树木编号评估了袋外误差。
# Initialise the random forest estimator
# Set 'warm_start=true' so that more trees are added to the existing model each iteration
RF = RandomForestClassifier(oob_score=True, random_state=1, warm_start=True, n_jobs=-1)oob_list = list()# Iterate through all of the possibilities for the number of trees
for n_trees in [15, 20, 30, 40, 50, 100, 150, 200, 300, 400]:RF.set_params(n_estimators=n_trees) # Set number of treesRF.fit(X_train_bopt, y_train_bopt)oob_error = 1 - RF.oob_score_ # Obtain the oob erroroob_list.append(pd.Series({'n_trees': n_trees, 'oob': oob_error}))rf_oob_df = pd.concat(oob_list, axis=1).T.set_index('n_trees')ax = rf_oob_df.plot(legend=False, marker='o')
ax.set(ylabel='out-of-bag error',title='Evaluation of Out-of-Bag Error');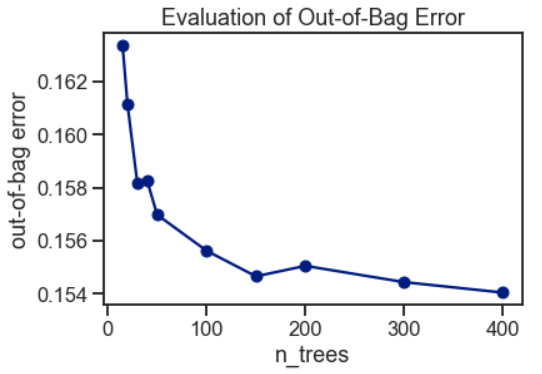
The out-of-bag error appeared to have stabilized around 150 trees.
袋外误差似乎已稳定在150棵树附近。
# Create the model with 150 trees
forest = RandomForestClassifier(n_estimators=150, random_state=1, n_jobs=-1)# Fit training data and training labels to forest
forest.fit(X_train_bopt, y_train_bopt)
n_nodes = []
max_depths = []for ind_tree in forest.estimators_:n_nodes.append(ind_tree.tree_.node_count)max_depths.append(ind_tree.tree_.max_depth)print(f'Random Forest has an average number of nodes {int(np.mean(n_nodes))} with an average maximum depth of {int(np.mean(max_depths))}.')print(f'Model Accuracy for train data: {forest.score(X_train_bopt, y_train_bopt)}')
print(f'Model Accuracy for test data: {forest.score(X_test_bopt, y_test_bopt)}')
From the above, each decision tree in the random forest has many nodes and is extremely deep. Although each individual decision tree may overfit to a particular subset of the training data, the use of random forest had produced a slightly higher accuracy score for the test data.
综上所述,随机森林中的每个决策树都有许多节点,并且深度非常大。 尽管每个决策树都可能过度适合训练数据的特定子集,但是使用随机森林对测试数据的准确性得分略高。
功能重要性 (Feature Importance)
The feature importance of each feature of the dataset can be obtained by using the feature importance property of the model. Feature importance gives a score for each feature of the data. The higher the score, the more important or relevant the feature is towards the target variable.
可以通过使用模型的特征重要性属性来获得数据集的每个特征的特征重要性。 特征重要性为数据的每个特征给出分数。 分数越高,特征对目标变量的重要性或相关性就越高。
Feature importance is an in-built class that comes with Tree-Based Classifiers. We have used the decision tree and random forest to rank the feature importance for the dataset.
功能重要性是基于树的分类器附带的内置类。 我们已经使用决策树和随机森林对数据集的特征重要性进行排序。
feature_imp = pd.Series(tree.feature_importances_, index=X.columns).sort_values(ascending=False)ax = feature_imp.plot(kind='bar')
ax.set(title='Feature Importance - Decision Trees',ylabel='Relative Importance');feature_imp = pd.Series(forest.feature_importances_, index=X.columns).sort_values(ascending=False)ax = feature_imp.plot(kind='bar')
ax.set(title='Feature Importance - Random Forest',ylabel='Relative Importance');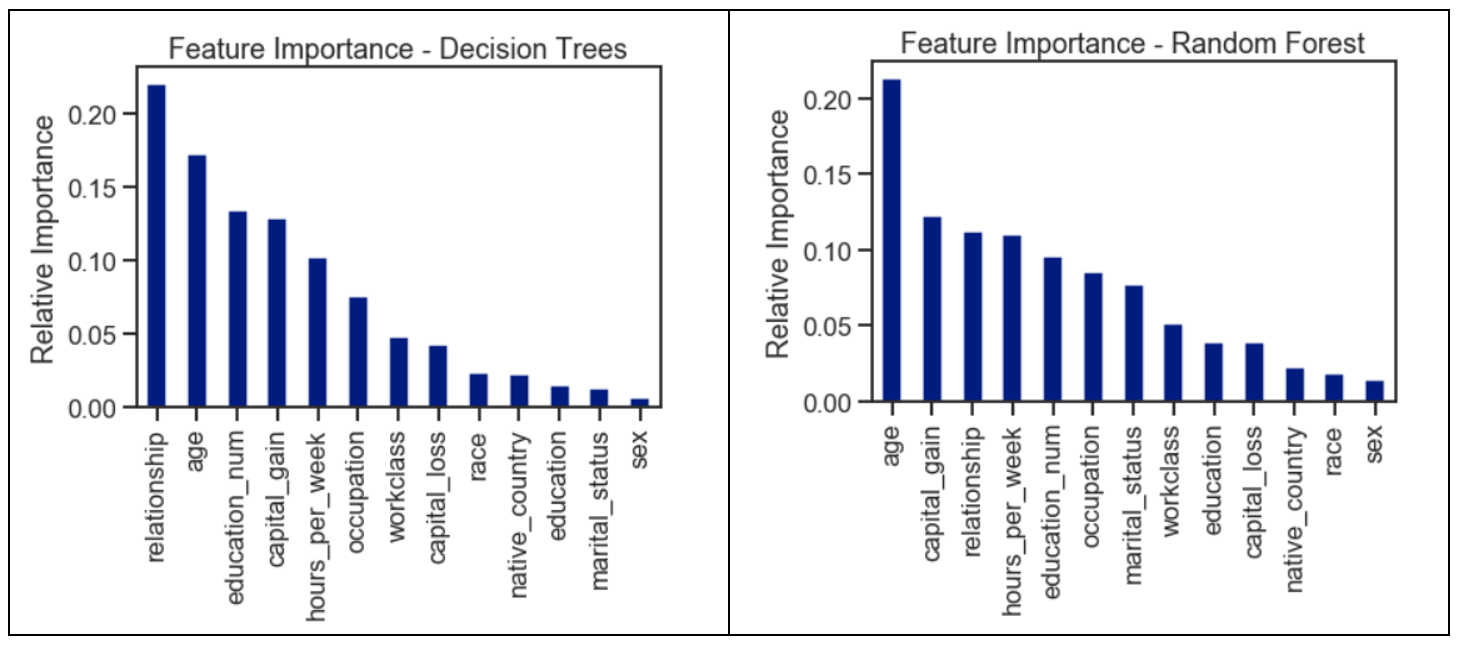
The features were ranked based on their importance considered by the respective classifiers. The values were computed by summing the reduction in Gini Impurity over all of the nodes of the tree in which the feature is used.
根据各个分类器考虑的重要性对功能进行排名。 通过对使用该特征的树的所有节点上的基尼杂质减少量求和来计算这些值。
使用2种方法进行特征选择: (Feature Selection using 2 Methods:)
1.单变量选择 (1. Univariate Selection)
Statistical tests can be used to select those features that have the strongest relationship with the target variable. The scikit-learn library provides the SelectKBest class to be used with a suite of different statistical tests to select a specific number of features. We used the chi-squared (chi²) statistical test for non-negative features to select 10 of the best features from the dataset.
可以使用统计检验来选择与目标变量关系最密切的那些特征 。 scikit-learn库提供SelectKBest类,该类将与一组不同的统计测试一起使用,以选择特定数量的功能。 我们使用非负特征的卡方(chi²)统计检验从数据集中选择10个最佳特征。
# Apply SelectKBest class to extract top 10 best features
bestfeatures = SelectKBest(score_func=chi2, k=10)
fit = bestfeatures.fit(X,y)
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(X.columns)# Concatenate two dataframes for better visualization
featureScores = pd.concat([dfcolumns,dfscores],axis=1)
featureScores.columns = ['Features','Score'] # naming the dataframe columns
print(featureScores.nlargest(10,'Score')) # print 10 best features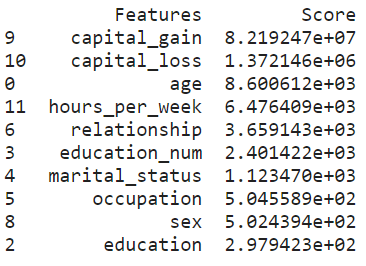
2.具有热图的相关矩阵 (2. Correlation Matrix with Heat Map)
Correlation states how the features are related to each other or the target variable. Correlation can be positive (increase in one value of feature increases the value of the target variable) or negative (increase in one value of feature decreases the value of the target variable). A heat map makes it easy to identify which features are most related to the target variable.
关联说明要素之间如何相互关联或与目标变量关联。 相关可以是正的(增加一个特征值增加目标变量的值)或负的(增加一个特征值减少目标变量的值)。 通过热图 ,可以轻松识别出哪些特征与目标变量最相关 。
# Obtain correlations of each features in dataset
sns.set(font_scale=1.4)
corrmat = clean_df.corr()
top_corr_features = corrmat.index
plt.figure(figsize=(30,30))# Plot heat map
correlation = sns.heatmap(clean_df[top_corr_features].corr(),annot=True,fmt=".3f",cmap='Blues')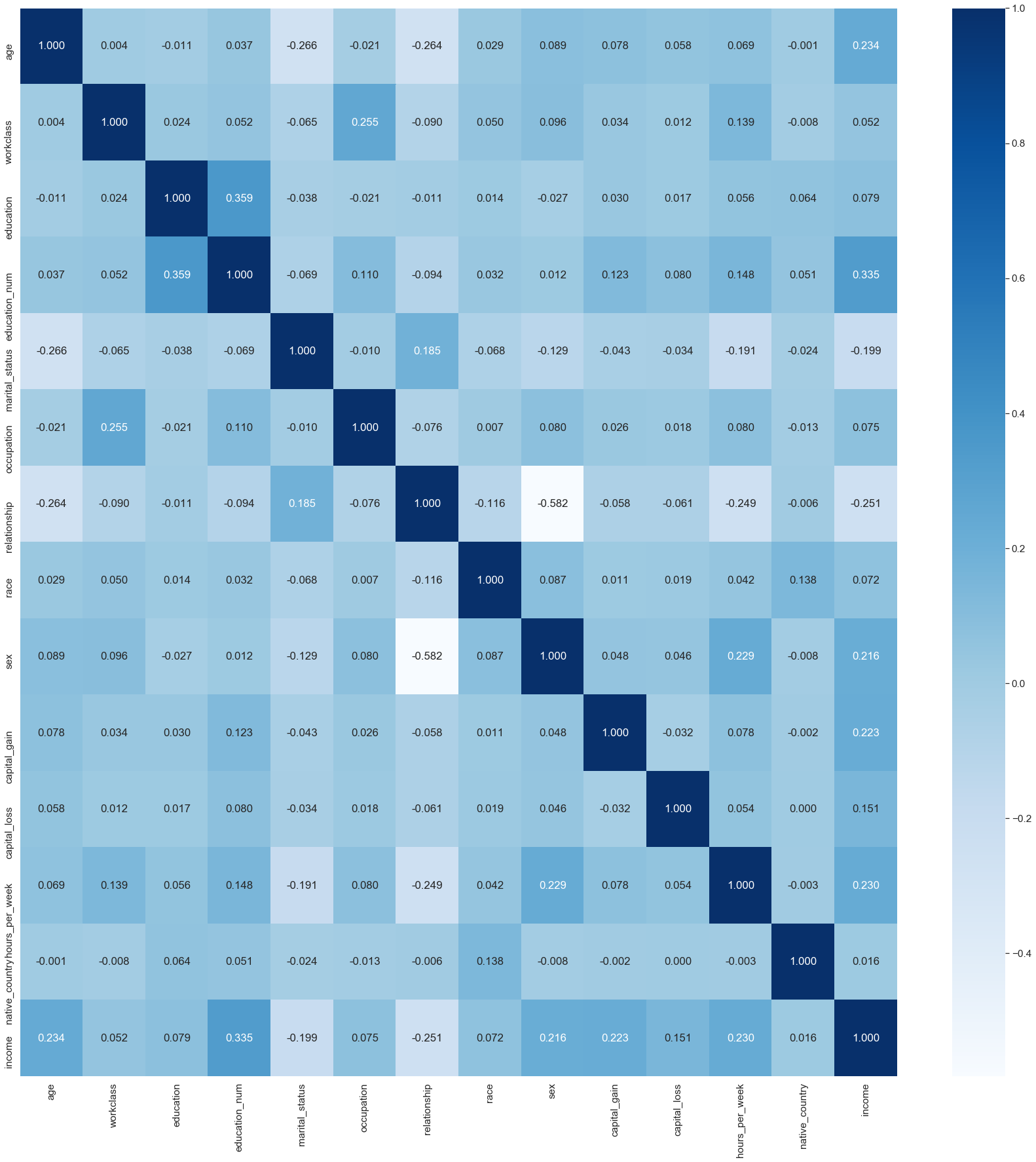
上采样 (Upsampling)
Upsampling is the process of randomly duplicating observations from the minority class in order to reinforce its signal. There are several heuristics for doing so, but the most common way is to simply resample with replacement.
上采样是随机复制少数群体的观察结果以增强其信号的过程 。 这样做有几种启发式方法,但是最常见的方法是简单地用替换进行重新采样。
# Separate majority and minority classes
df_majority = clean_df[clean_df.income==0]
df_minority = clean_df[clean_df.income==1]# Upsample minority class
df_minority_upsampled = resample(df_minority, replace=True, # sample with replacementn_samples=24720, # to match majority classrandom_state=1) # reproducible results# Combine majority class with upsampled minority class
df_upsampled = pd.concat([df_majority, df_minority_upsampled])# Display new class counts
df_upsampled.income.value_counts()
df_upsampled.income.value_counts(normalize=True)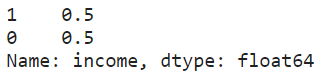
Now that the dataset has been balanced, we are ready to split and scale this dataset for training and testing using the optimized random forest model.
现在数据集已经达到平衡,我们已经准备好使用优化的随机森林模型拆分和缩放该数据集,以进行训练和测试。
X_upsamp = df_upsampled[feature_cols]
y_upsamp = df_upsampled['income']X_train, X_test, y_train, y_test = train_test_split(X_upsamp, y_upsamp, test_size = 0.3, random_state = 1)# Perform pre-processing to scale numeric features
scale = preprocessing.StandardScaler()
X_train = scale.fit_transform(X_train)# Test features are scaled using the scaler computed for the training features
X_test = scale.transform(X_test)通过网格搜索进行随机森林优化 (Random Forest Optimization through Grid Search)
Grid search is an exhaustive search over specified parameter values for an estimator. It selects combinations of hyperparameters from a grid, evaluates them using cross-validation on the training data, and returns the values that perform the best.
网格搜索是对估计器的指定参数值的详尽搜索 。 它从网格中选择超参数组合,对训练数据使用交叉验证对它们进行评估,然后返回性能最佳的值。
We have selected the following model parameters for the grid search:
我们为网格搜索选择了以下模型参数 :
n_estimators: The number of trees in the forest.
n_estimators:森林中树木的数量。
max_depth: The maximum depth of the tree.
max_depth:树的最大深度。
min_samples_split: The minimum number of samples required to split an internal node.
min_samples_split:拆分内部节点所需的最小样本数。
# Set the model parameters for grid search
model_params = {'n_estimators': [150, 200, 250, 300],'max_depth': [15, 20, 25],'min_samples_split': [2, 4, 6]}# Create random forest classifier model
rf_model = RandomForestClassifier(random_state=1)# Set up grid search meta-estimator
gs = GridSearchCV(rf_model, model_params,n_jobs=-1, scoring='roc_auc', cv=3)# Train the grid search meta-estimator to find the best model
best_model = gs.fit(X_train, y_train)# Print best set of hyperparameters
from pprint import pprint
pprint(best_model.best_estimator_.get_params())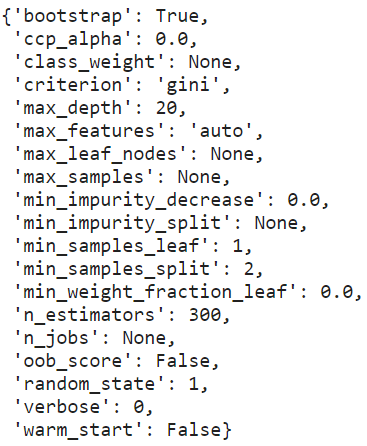
Based on the grid search, the best hyperparameter values were not the defaults. This shows the importance of tuning a model for a specific dataset. Each dataset will have different characteristics, and the model that does best on one dataset will not necessarily do the best across all datasets.
基于网格搜索,最佳超参数值不是默认值。 这表明为特定数据集调整模型的重要性。 每个数据集将具有不同的特征,并且在一个数据集上表现最佳的模型不一定会在所有数据集上表现最佳。
使用最佳模型优化随机森林 (Use the Best Model to Optimize Random Forest)
n_nodes = []
max_depths = []for ind_tree in best_model.best_estimator_:n_nodes.append(ind_tree.tree_.node_count)max_depths.append(ind_tree.tree_.max_depth)print(f'The optimized random forest has an average number of nodes {int(np.mean(n_nodes))} with an average maximum depth of {int(np.mean(max_depths))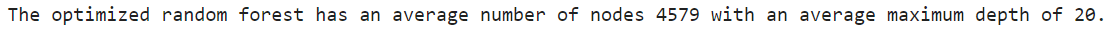
The best maximum depth was not unlimited, this indicates that restricting the maximum depth of the individual decision trees can improve the cross validation performance of the random forest.
最佳最大深度不是无限的,这表明限制单个决策树的最大深度可以提高随机森林的交叉验证性能。
print(f'Model Accuracy for train data: {best_model.score(X_train, y_train)}')
print(f'Model Accuracy for test data: {best_model.score(X_test, y_test)}')
Although the performance achieved by the optimized model was slightly below that of the decision tree and default model, the gap between the model accuracy obtained for both the train data and test data was minimized (~4%). This represents a good fit of the learning curve where a high accuracy rate was achieved by using the trained model on the test data.
尽管通过优化模型获得的性能略低于决策树和默认模型,但是针对火车数据和测试数据获得的模型精度之间的差距已最小化(〜4%)。 这代表了学习曲线的良好拟合,其中通过在测试数据上使用经过训练的模型可以实现较高的准确率。
模型的性能评估 (Performance Evaluation of Models)
# Predict target variables (ie. labels) for each classifer
dt_classifier_name = ["Decision Tree"]
dt_predicted_labels = tree.predict(X_test_bopt)rf_classifier_name = ["Random Forest"]
rf_predicted_labels = forest.predict(X_test_bopt)best_model_classifier_name = ["Optimized Random Forest"]
best_model_predicted_labels = best_model.predict(X_test)1.分类报告 (1. Classification Report)
The classification report shows a representation of the main classification metrics on a per-class basis and gives a deeper intuition of the classifier behavior over global accuracy, which can mask functional weaknesses in one class of a multi-class problem. The metrics are defined in terms of true and false positives, and true and false negatives.
分类报告显示了每个分类的主要分类指标,并给出了分类器行为相对于全局准确性的更直观认识,这可以掩盖一类多分类问题中的功能弱点。 度量是根据正确和错误肯定以及正确和错误否定来定义的。
Precision is the ability of a classifier not to label an instance positive that is actually negative. For each class, it is defined as the ratio of true positives to the sum of true and false positives.
精度是分类器不标记实际为负的实例正的能力。 对于每个类别,它定义为真阳性与真假阳性之和的比率。
For all instances classified positive, what percent was correct?
对于所有归类为阳性的实例,正确的百分比是多少?
Recall is the ability of a classifier to find all positive instances. For each class, it is defined as the ratio of true positives to the sum of true positives and false negatives.
回忆是分类器查找所有正实例的能力。 对于每个类别,它定义为真阳性与真阳性与假阴性总和之比。
For all instances that were actually positive, what percent was classified correctly?
对于所有实际为正的实例,正确分类的百分比是多少?
The F1-score is a weighted harmonic mean of precision and recall such that the best score is 1.0 and the worst is 0.0. Generally, F1-scores are lower than accuracy measures as they embed precision and recall into their computation. As a rule of thumb, the weighted average of the F1-score should be used to compare classifier models, not global accuracy.
F1分数是精确度和召回率的加权谐波平均值,因此最佳分数是1.0,最差分数是0.0。 通常,F1分数将精度和召回率嵌入到计算中,因此它们比精度度量要低。 根据经验,应该使用F1分数的加权平均值来比较分类器模型,而不是整体精度。
Support is the number of actual occurrences of the class in the specified dataset. Imbalanced support in the training data may indicate structural weaknesses in the reported scores of the classifier and could indicate the need for stratified sampling or re-balancing. Support does not change between models but instead diagnoses the evaluation process.
支持是指定数据集中该类的实际出现次数。 训练数据中支持不平衡可能表明分类器报告的分数存在结构性缺陷,并且可能表明需要分层抽样或重新平衡。 支持在模型之间不会改变,而是诊断评估过程。
print("Classification Report for",dt_classifier_name, " :\n ",metrics.classification_report(y_test_bopt, dt_predicted_labels, target_names=['Income <= U$50K','Income > U$50K']))print("Classification Report for ",rf_classifier_name, " :\n ",metrics.classification_report(y_test_bopt, rf_predicted_labels,target_names=['Income <= U$50K','Income > U$50K']))print("Classification Report for ",best_model_classifier_name, " :\n ",metrics.classification_report(y_test,best_model_predicted_labels,target_names=['Income <= U$50K','Income > U$50K']))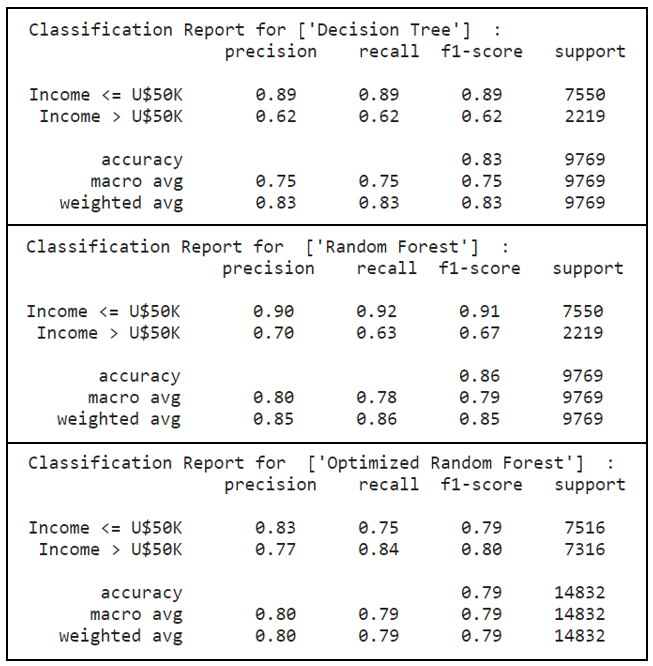
The optimized random forest has performed well in the above metrics. In particular, with upsampling performed to maintain a balanced dataset, a significant observation was noted in the minority class (ie. label ‘1’ representing income > U$50K), where recall scores had improved 35%, from 0.62 to 0.84, by using the optimized random forest model.
经过优化的随机森林在上述指标中表现良好。 尤其是,为了保持数据集的平衡而进行了上采样, 在少数族裔类别中观察到了显着的结果(即标签“ 1”代表收入> 5万美元), 召回得分提高了35%,从0.62提高到0.84,使用优化的随机森林模型。
With a higher precision and recall scores, the optimized random forest model was able to correctly label instances that were indeed positive. Out of these instances which were actually positive, the optimized random forest model had classified them correctly to a large extent. This directly translates into a higher F1-score as a weighted harmonic mean of precision and recall.
优化的随机森林模型具有更高的精度和召回得分 ,能够正确标记确实为阳性的实例。 在这些实际为阳性的实例中,优化后的随机森林模型在很大程度上将它们正确分类。 这直接转化为更高的F1得分,作为精确度和召回率的加权谐波平均值。
2.混淆矩阵 (2. Confusion Matrix)
The confusion matrix takes a fitted scikit-learn classifier and a set of test x and y values and returns a report showing how each of the test values predicted classes compare to their actual classes. These provide similar information as what is available in a classification report, but rather than top-level scores, they provide deeper insight into the classification of individual data points.
混淆矩阵采用适合的scikit-learn分类器和一组测试x和y值,并返回报告,显示每个预测值预测类与实际类的比较。 这些提供的信息与分类报告中提供的信息类似,但是它们不是顶级分数,而是提供了对单个数据点分类的更深入了解。
print("Confusion Matrix for",dt_classifier_name)
skplt.metrics.plot_confusion_matrix(y_test_bopt, dt_predicted_labels, normalize=True)
plt.show()print("Confusion Matrix for",rf_classifier_name)
skplt.metrics.plot_confusion_matrix(y_test_bopt, rf_predicted_labels, normalize=True)
plt.show()print("Confusion Matrix for",best_model_classifier_name)
skplt.metrics.plot_confusion_matrix(y_test, best_model_predicted_labels, normalize=True)
plt.show()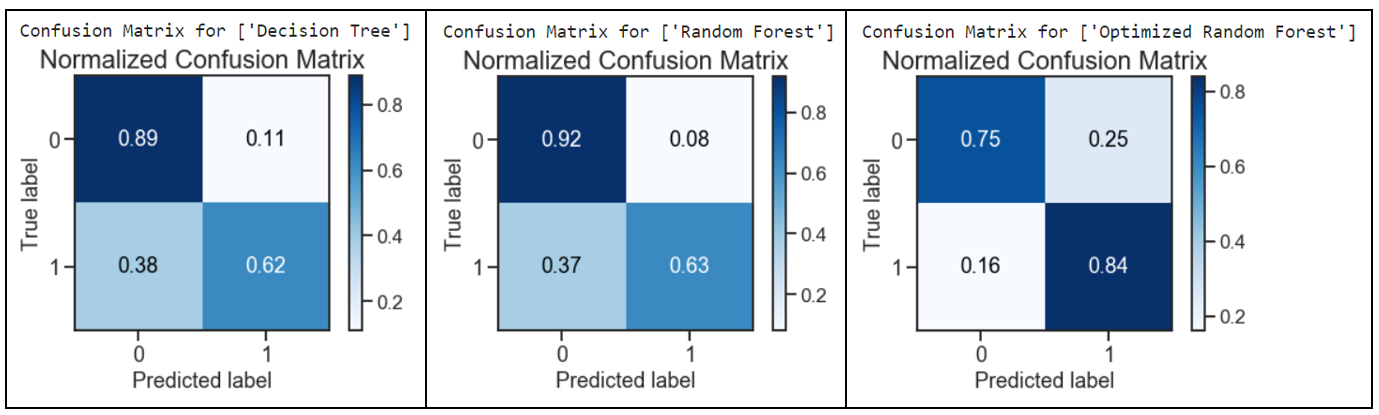
The optimized random forest had performed well with a decrease in the Type 2 Error: False Negatives (predicted income <= U$50K but actually income > U$50K). A remarkable decrease of 58% was obtained from a score of 0.38 to 0.16 when comparing the results for decision tree against the optimized random forest.
经过优化的随机森林表现良好,并且减少了Type 2错误:False Negatives (预期收入<= 5万美元,但实际收入> 5万美元)。 将决策树的结果与优化的随机森林进行比较时, 得分从0.38下降到0.16 , 下降了58% 。
However, the Type 1 Error: False Positives (predicted > U$50K but actually <= U$50K) had approximately tripled, from 0.08 to 0.25, by comparing the optimized random forest with the default random forest model.
但是,通过将优化后的随机森林与默认随机森林模型进行比较, 类型1错误:误报 (预测为> 5万美元,但实际<= 5万美元) 大约增加了三倍,从0.08到0.25 。
Overall, the impact of having more false positives was mitigated with a notable decrease in false negatives. With a good outcome of the test values predicted classes as compared to their actual classes, the confusion matrix results for the optimized random forest had outperformed the other models.
总体而言,误报率明显下降,减轻了更多误报率的影响。 测试值预测类比其实际类具有更好的结果,优化随机森林的混淆矩阵结果优于其他模型。
3.精确调用曲线 (3. Precision-Recall Curve)
Precision-Recall curve is a metric used to evaluate a classifier’s quality. The precision-recall curve shows the trade-off between precision, a measure of result relevancy, and recall, a measure of how many relevant results are returned. A large area under the curve represents both high recall and precision, the best-case scenario for a classifier, showing a model that returns accurate results for the majority of classes it selects.
精确召回曲线是用于评估分类器质量的指标。 精度调用曲线显示了精度(即结果相关性的度量)和召回率(即返回了多少相关结果的度量)之间的权衡。 曲线下的较大区域代表了较高的查全率和精度,这是分类器的最佳情况,它显示了一个模型,该模型针对选择的大多数类别返回准确的结果。
fig, axList = plt.subplots(ncols=3)
fig.set_size_inches(21,6)# Plot the Precision-Recall curve for Decision Tree
ax = axList[0]
dt_predicted_proba = tree.predict_proba(X_test_bopt)
precision, recall, _ = precision_recall_curve(y_test_bopt, dt_predicted_proba[:,1])
ax.plot(recall, precision,color='black')
ax.set(xlabel='Recall', ylabel='Precision', xlim=[0, 1], ylim=[0, 1],title='Precision-Recall Curve - Decision Tree')
ax.grid(True)# Plot the Precision-Recall curve for Random Forest
ax = axList[1]
rf_predicted_proba = forest.predict_proba(X_test_bopt)
precision, recall, _ = precision_recall_curve(y_test_bopt, rf_predicted_proba[:,1])
ax.plot(recall, precision,color='green')
ax.set(xlabel='Recall', ylabel='Precision', xlim=[0, 1], ylim=[0, 1],title='Precision-Recall Curve - Random Forest')
ax.grid(True)# Plot the Precision-Recall curve for Optimized Random Forest
ax = axList[2]
best_model_predicted_proba = best_model.predict_proba(X_test)
precision, recall, _ = precision_recall_curve(y_test, best_model_predicted_proba[:,1])
ax.plot(recall, precision,color='blue')
ax.set(xlabel='Recall', ylabel='Precision', xlim=[0, 1], ylim=[0, 1],title='Precision-Recall Curve - Optimised Random Forest')
ax.grid(True)
plt.tight_layout()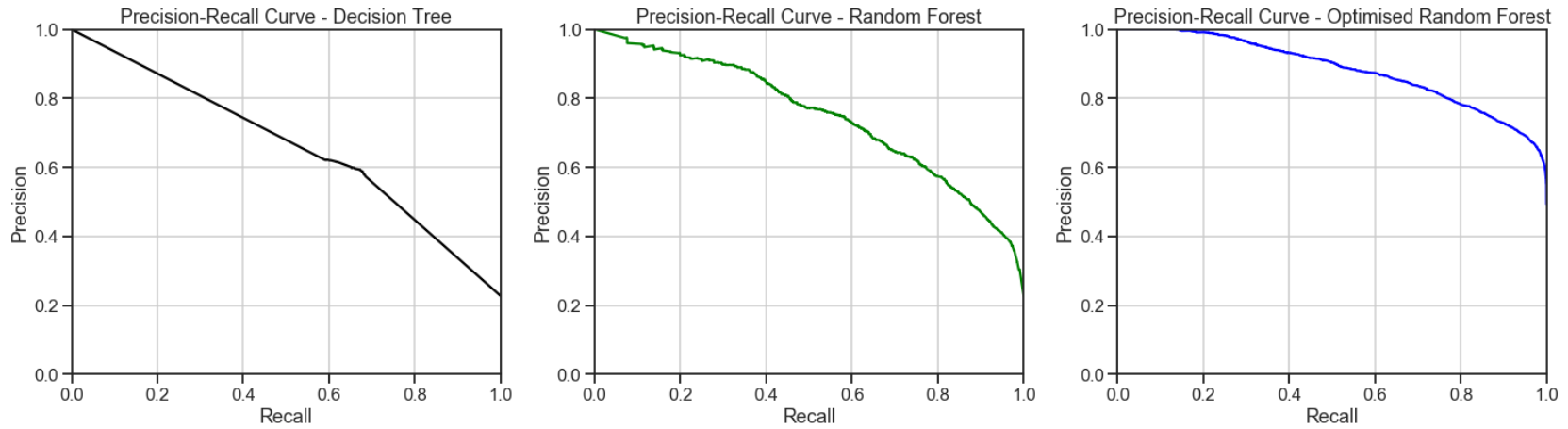
The optimized random forest classifier achieved a higher area under the precision-recall curve. This represents high recall and precision scores, where high precision relates to a low false-positive rate, and a high recall relates to a low false-negative rate. High scores in both showed that the optimized random forest classifier had returned accurate results (high precision), as well as a majority of all positive results (high recall).
优化的随机森林分类器在精确召回曲线下获得了更大的面积。 这代表了较高的查全率和精确度分数,其中高精度与低假阳性率相关,而高查全率与较低的假阴性率相关。 两者均获得高分,表明优化后的随机森林分类器已返回准确结果(高精度),以及大部分积极结果(高召回率)。
4. ROC曲线和AUC (4. ROC Curve and AUC)
A Receiver Operating Characteristic (“ROC”)/Area Under the Curve (“AUC”) plot allows the user to visualize the trade-off between the classifier’s sensitivity and specificity.
接收器工作特征(“ ROC”)/曲线下面积(“ AUC”)曲线图使用户可以直观地看到分类器的灵敏度和特异性之间的权衡。
The ROC is a measure of a classifier’s predictive quality that compares and visualizes the trade-off between the model’s sensitivity and specificity. When plotted, a ROC curve displays the true positive rate on the Y axis and the false positive rate on the X axis on both a global average and per-class basis. The ideal point is therefore the top-left corner of the plot: false positives are zero and true positives are one.
ROC是对分类器预测质量的一种度量,它比较并可视化模型的敏感性和特异性之间的权衡。 绘制时,ROC曲线在全局平均值和每个类别的基础上,在Y轴上显示真实的阳性率,在X轴上显示假的阳性率。 因此理想点是图的左上角:假阳性为零,真阳性为一。
AUC is a computation of the relationship between false positives and true positives. The higher the AUC, the better the model generally is. However, it is also important to inspect the “steepness” of the curve, as this describes the maximization of the true positive rate while minimizing the false positive rate.
AUC是假阳性和真阳性之间的关系的计算。 AUC越高,模型通常越好。 但是,检查曲线的“陡度”也很重要,因为这描述了真实阳性率的最大化,同时最小化了阳性阳性率。
fig, axList = plt.subplots(ncols=3)
fig.set_size_inches(21,6)# Plot the ROC-AUC curve for Decision Tree
ax = axList[0]
dt = tree.fit(X_train_bopt, y_train_bopt.values.ravel())
dt_predicted_label_r = dt.predict_proba(X_test_bopt)def plot_auc(y, probs):fpr, tpr, threshold = roc_curve(y, probs[:,1])auc = roc_auc_score(y_test_bopt, dt_predicted_labels)ax.plot(fpr, tpr, color = 'black', label = 'AUC_Decision Tree = %0.2f' % auc)ax.plot([0, 1], [0, 1],'r--')ax.legend(loc = 'lower right')ax.set(xlabel='False Positive Rate',ylabel='True Positive Rate',xlim=[0, 1], ylim=[0, 1],title='ROC curve') plot_auc(y_test_bopt, dt_predicted_label_r)
ax.grid(True)# Plot the ROC-AUC curve for Random Forest
ax = axList[1]
rf = forest.fit(X_train_bopt, y_train_bopt.values.ravel())
rf_predicted_label_r = rf.predict_proba(X_test_bopt)def plot_auc(y, probs):fpr, tpr, threshold = roc_curve(y, probs[:,1])auc = roc_auc_score(y_test_bopt, rf_predicted_labels)ax.plot(fpr, tpr, color = 'green', label = 'AUC_Random Forest = %0.2f' % auc)ax.plot([0, 1], [0, 1],'r--')ax.legend(loc = 'lower right')ax.set(xlabel='False Positive Rate',ylabel='True Positive Rate',xlim=[0, 1], ylim=[0, 1],title='ROC curve') plot_auc(y_test_bopt, rf_predicted_label_r);
ax.grid(True)# Plot the ROC-AUC curve for Optimized Random Forest
ax = axList[2]
best_model = best_model.fit(X_train, y_train.values.ravel())
best_model_predicted_label_r = best_model.predict_proba(X_test)def plot_auc(y, probs):fpr, tpr, threshold = roc_curve(y, probs[:,1])auc = roc_auc_score(y_test, best_model_predicted_labels)ax.plot(fpr, tpr, color = 'blue', label = 'AUC_Optimised Random Forest = %0.2f' % auc)ax.plot([0, 1], [0, 1],'r--')ax.legend(loc = 'lower right')ax.set(xlabel='False Positive Rate',ylabel='True Positive Rate',xlim=[0, 1], ylim=[0, 1],title='ROC curve') plot_auc(y_test, best_model_predicted_label_r);
ax.grid(True)
plt.tight_layout()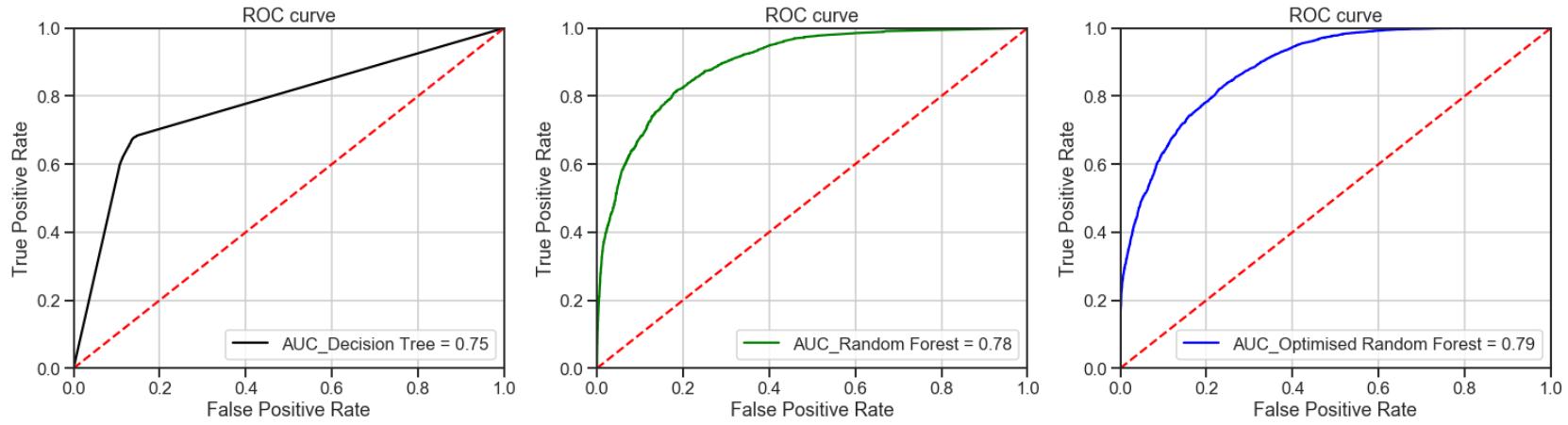
All the models had outperformed the baseline guess with the optimized random forest achieving the best AUC results. Thus, indicating that the optimized random forest is a better classifier.
所有模型均优于基线猜测,优化的随机森林获得了最佳的AUC结果。 因此,表明优化的随机森林是更好的分类器。
5.校准曲线 (5. Calibration Curve)
When performing classification, one often wants to predict not only the class label, but also the associated probability. This probability gives some kind of confidence on the prediction. Thus, the calibration plot is useful for determining whether predicted probabilities can be interpreted directly as an confidence level.
在进行分类时,人们经常不仅要预测分类标签,还要预测相关的概率。 这种可能性使预测具有某种信心。 因此,校准图可用于确定预测的概率是否可以直接解释为置信度。
# Plot calibration curves for a set of classifier probability estimates.
tree = DecisionTreeClassifier()
forest = RandomForestClassifier()tree_probas = tree.fit(X_train_bopt, y_train_bopt).predict_proba(X_test_bopt)
forest_probas = forest.fit(X_train_bopt, y_train_bopt).predict_proba(X_test_bopt)probas_list = [tree_probas, forest_probas]
clf_names = ['Decision Tree','Random Forest']skplt.metrics.plot_calibration_curve(y_test_bopt, probas_list, clf_names,figsize=(10,6))
plt.show()# Plot calibration curves for a set of classifier probability estimates.
best_model = RandomForestClassifier()best_model_probas = best_model.fit(X_train, y_train).predict_proba(X_test)probas_list = [best_model_probas]
clf_names = ['Optimized Random Forest']skplt.metrics.plot_calibration_curve(y_test, probas_list, clf_names, cmap='winter', figsize=(10,6))
plt.show()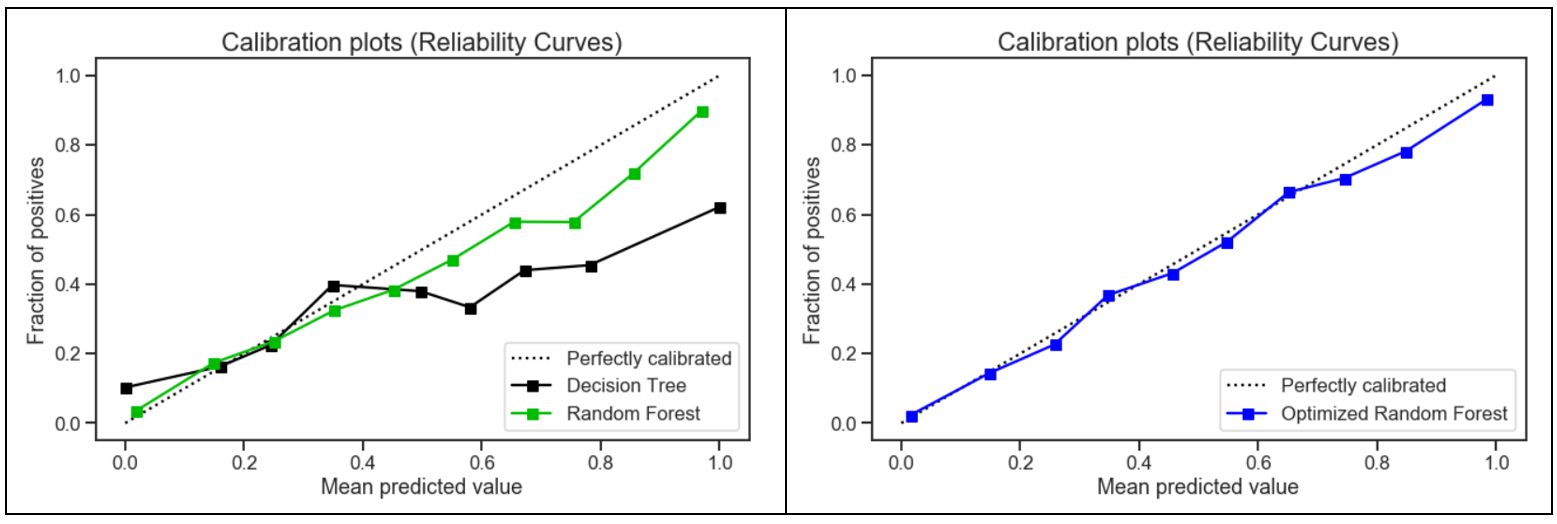
Compared to the other two models, the calibration plot for the optimized random forest was the closest to being perfectly calibrated. Hence, the optimized random forest was more reliable and better able to generalize to new data.
与其他两个模型相比,优化后的随机森林的校准图最接近于完美校准。 因此,优化后的随机森林更加可靠,能够更好地推广到新数据。
结论 (Conclusion)
The optimized random forest had a better generalization performance on the testing set with reduced variance as compared to the other models. Decision trees tend to overfit and pruning helped to reduce variance to a point. The random forest addressed the shortcomings of decision trees with a strong modeling technique which was more robust than a single decision tree.
与其他模型相比, 优化后的随机森林在测试集上具有更好的泛化性能 ,并且方差减小。 决策树倾向于过度拟合,而修剪有助于将方差降低到一定程度。 随机森林使用强大的建模技术解决了决策树的缺点,该技术比单个决策树更强大。
The use of optimization for random forest had a significant impact on the results with the following 3 factors being considered:
对随机森林的优化使用对结果有重大影响,考虑了以下三个因素:
Feature selection to chose the ideal number of features to prevent overfitting and improve model interpretability
选择特征以选择理想数量的特征,以防止过度拟合并提高模型的可解释性
Upsampling of the minority class to create a balanced dataset
少数类的上采样以创建平衡的数据集
Grid search to select the best hyper-parameters to maximize model performance
网格搜索以选择最佳超参数以最大化模型性能
Lastly, the results were also attributed by the unique quality of random forest, where it adds additional randomness to the model while growing the trees. Instead of searching for the most important feature while splitting a node, it searches for the best feature among a random subset of features. This results in a wide diversity that generally results in a better model for classification problems.
最后,结果还归因于随机森林的独特质量,即在树木生长时为模型增加了额外的随机性。 它不是在分割节点时搜索最重要的特征,而是在特征的随机子集中搜索最佳特征 。 这导致了广泛的多样性,通常可以为分类问题提供更好的模型。
翻译自: https://medium.com/towards-artificial-intelligence/use-of-decision-trees-and-random-forest-in-machine-learning-1e35e737b638
机器学习中决策树的随机森林
相关文章:
- bzoj3083 遥远的国度 bzoj3626 LCA (树链剖分)
- 在WebGL场景中管理多个卡牌对象的实验
- 速看: 加解密、加签验签,你想要的都在这了
- 新年了,5G手机芯片,到底买谁?
- sql习题
- 罗曼 matlab,成年人简易钢琴教程100首
- 你不必去一个遥远的星系去寻找这些奇怪的世界
- 有一种遥远,叫从家到公司的距离
- cnpm报错:Error: Cannot find module ‘diagnostics_channel‘
- System.Diagnostics 记录
- System.Diagnostics.Process执行获取程序实时输出消息
- C#的System.Diagnostics.Trace.WriteLine 写入文件
- Diagnostics - DID, DTC区别与联系
- ERROR org.springframework.boot.diagnostics.LoggingFailureAnalysisReporter
- System.Diagnostics.Process.Start的妙用
- mysql sys模式_mysql8 参考手册-sys模式存储过程diagnostics()过程
- sp_server_diagnostics
- thinkpad硬件测试软件,Lenovo Diagnostics Windows(联想硬件诊断工具)
- System.Diagnostics.Debug和System.Diagnostics.Trace
- 按丶自动打开计算机,联想电脑台式机启动自动进入Lenovo diagnostics界面
- System.Diagnostics.Process.Start 用法
- C# 之 System.Diagnostics.Process.Start 的妙用
- System.Diagnostics.Stopwatch
- 从零开始学习CANoe(十九)—— Diagnostics
- GBase8s数据库GET DIAGNOSTICS 语句
- DIAGNOSTICS
- 华硕计算机硬件信息,ASUS PC Diagnostics
- 海信智慧黑板Android版本,海信推出智慧黑板来打造沉浸式智慧课堂,保护视力让学生爱上上课...
- 【LeetCode每日一题】810. 黑板异或游戏
- 电梯、签到、黑板测试用例
机器学习中决策树的随机森林_决策树和随机森林在机器学习中的使用相关推荐
- 在envi做随机森林_基于模糊孤立森林算法的多维数据异常检测方法
引用:李倩, 韩斌, 汪旭祥. 基于模糊孤立森林算法的多维数据异常检测方法[J]. 计算机与数字工程, 2020, 48(4): 862-866. 摘要:针对孤立森林算法在进行异常检测时,忽略了每一条 ...
- 微信红包随机数字_微信红包随机算法转载
php固定红包 + 随机红包算法 1 需求 CleverCode最近接到一个需求,需要写一个固定红包 + 随机红包算法. 1 固定红包就是每个红包金额一样,有多少个就发多少个固定红包金额就行. 2 随 ...
- mysql中的索引什么意思_索引是什么意思(数据库中的索引是什么)
mysql中索引是存储引擎层面用于快速查询找到记录的一种数据结构,索引对性能的影响非常重要,特别是表中数据量很大的时候,正确的索引会极大的提成查询效率.简单理解索引,就相当于一本砖头厚书的目录部分,通 ...
- java中关于包的描述_下列关于Java包的描述中,错误的是() (1.0分)_学小易找答案
[单选题]食物中1g脂肪产生的热量是 [判断题]要是你体重正常,这表明你摄取的营养是正常的. [判断题]多吃维生素,并不能增加身体活力. [判断题]节食或减肥时,要避免米.面之类富含淀粉的食物. [判 ...
- 把音频中的某个人声去掉_能不能把一段音频中的人声和背景音乐分开
能不能把一段音频中的人声和背景音乐分开 能不能把一段音频中的人声和背景音乐分开 [方法一]1.可以尝试使用音频编辑软件Audacity 2.打开音频文件,在特效菜单有个Vocal Remover工具, ...
- python中from是什么意思_听说你还在找python中import与from方法?
这篇文章主要介绍了python中import与from方法总结,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 一.模块& ...
- 决策树剪枝python实现_决策树剪枝问题python代码
决策树在生长过程中有可能长得过于茂盛,对训练集学习的很好,但对新的数据集的预测效果不好,即过拟合,此时生成的模型泛化能力较差.因此,我们需要对决策树进行剪枝,使得生成的模型具有较强的泛化能力. 为了检 ...
- 小程序中input标签没有反应_鸢尾花预测:如何创建机器学习Web应用程序?
全文共2485字,预计学习时长12分钟 图源:unsplash 数据科学的生命周期主要包括数据收集.数据清理.探索性数据分析.模型构建和模型部署.作为数据科学家或机器学习工程师,能够部署数据科学项目非 ...
- 过程中存根的作用有_模温机的作用 模压过程中模温机的作用有哪些?
模温机又叫模具温度控制机,最初应用在注塑模具的控温行业.后来随着机械行业的发展应用越来越广泛,现在模温机一般分水温机.油温机控制的温度可以达到正负0.1度.模温机主要用于塑胶,注塑,挤出等工业,它能精 ...
最新文章
- 对.net知识结构相关讲解
- python需要下载哪些插件-python需要装哪些工具包
- 查看ocx控件方法_Appium自动化测试入门教程No.8——定位控件
- poj 3164(最小树形图)
- boost::statechart模块实现状态迭代测试
- 致家长:疫情期间教育好自己的孩子,就是你最重要的事业!
- vue @input带参数_Vue 全家桶开发的一些小技巧和注意事项
- opencv7-绘制形状和文字
- selenium自动化案例(二)滑动验证码破解
- vue项目打包,生成dist文件夹,如何修改文件夹的名字
- kmeans算法详解与spark实战
- java基础学习(3)
- 基于MATLAB的发票识别系统
- linux exclude用法,Linux tar exclude参数的用法
- 能测试护肤品成分的软件,查化妆品成分的app
- CTF解题基本思路步骤(misc和web)
- 新手也能看懂,Kubernetes其实很简单
- vue实现关注与取消关注的按钮
- via浏览器皮肤html,Via浏览器 v4.2.1 身材小巧功能全面
- 解决Authorization not available. Check if polkit service...问题