如何在Pandas中使用Excel文件
From what I have seen so far, CSV seems to be the most popular format to store data among data scientists. And that’s understandable, it gets the job done and it’s a quite simple format; in Python, even without any library, one can build a simple CSV parser in under 10 lines of code.
从目前为止我所看到的,CSV似乎是数据科学家中最流行的存储数据格式。 这是可以理解的,它可以完成工作,而且格式非常简单; 在Python中,即使没有任何库,也可以用不到10行代码构建一个简单的CSV解析器。
But you may not always find the data that you need in CSV format. Sometimes the only available format may be an Excel file. Like, for example, this dataset on ons.gov.uk about crime in England and Wales, which is only in xlsx format; dataset that I will use in the examples below.
但是您可能并不总是以CSV格式找到所需的数据。 有时,唯一可用的格式可能是Excel文件。 例如, ons.gov.uk上有关英格兰和威尔士犯罪的数据集,仅采用xlsx格式; 我将在以下示例中使用的数据集。
读取Excel文件 (Reading Excel files)
The simplest way to read Excel files into pandas data frames is by using the following function (assuming you did import pandas as pd):
将Excel文件读入pandas数据帧的最简单方法是使用以下函数(假设您确实import pandas as pd ):
df = pd.read_excel(‘path_to_excel_file’, sheet_name=’…’)
df = pd.read_excel('path_to_excel_file', sheet_name='…')
Where sheet_name can be the name of the sheet we want to read, it’s index, or a list with all the sheets we want to read; the elements of the list can be mixed: sheet names or indices. If we want all the sheets, we can use sheet_name=None. In the case in which we want more sheets to be read, they will be returned as a dictionary of data frames. The keys of such a dictionary will be either the index or name of a sheet, depending on how we specified in sheet_name; in the case of sheet_name=None, the keys will be sheet names.
其中sheet_name可以是我们要读取的工作表的名称,索引或包含我们要读取的所有工作表的列表; 列表中的元素可以混合使用:工作表名称或索引。 如果我们需要所有图纸,可以使用sheet_name=None 。 在我们希望读取更多图纸的情况下,它们将作为数据帧的字典返回。 这样的字典的键将是工作表的索引或名称,这取决于我们在sheet_name指定sheet_name ; 在sheet_name=None的情况下,键将是工作表名称。
Now, if we use it to read our Excel file we get:
现在,如果我们使用它来读取我们的Excel文件,则会得到:
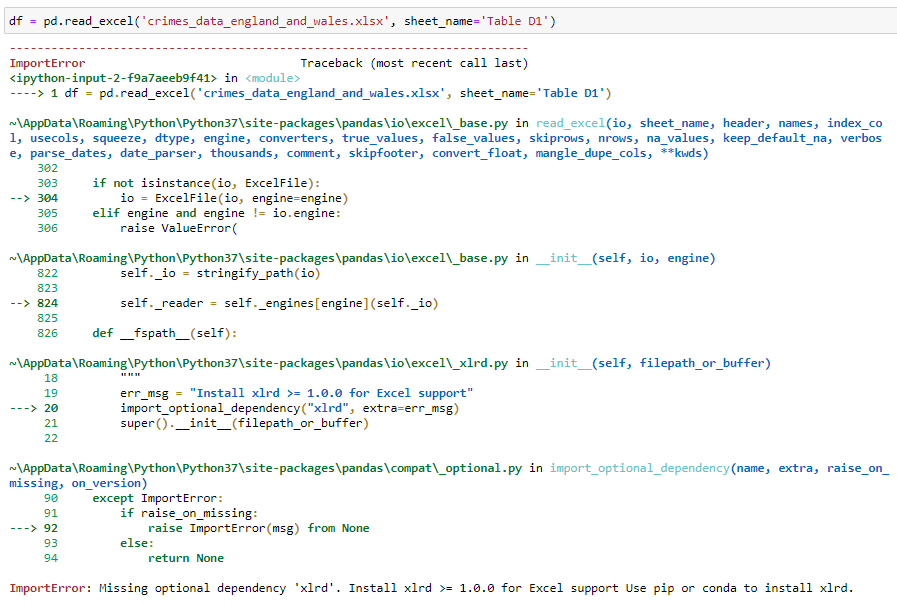
That’s right, an error! It turns out that pandas cannot read Excel files on its own, so we need to install another python package to do that.
是的,这是一个错误! 事实证明,熊猫无法自行读取Excel文件,因此我们需要安装另一个python软件包来做到这一点。
There are 2 options that we have: xlrd and openpyxl. The package xlrd can open both Excel 2003 (.xls) and Excel 2007+ (.xlsx) files, whereas openpyxl can open only Excel 2007+ (.xlsx) files. So, we will install xlrd as it can open both formats:
我们有2个选项: xlrd和openpyxl 。 包xlrd可以同时打开Excel 2003(.xlsx)和Excel 2007+(.xlsx)文件,而openpyxl只能打开Excel 2007+(.xlsx)文件。 因此,我们将安装xlrd因为它可以打开两种格式:
pip install xlrd
pip install xlrd
Now, if we try to read the same data again:
现在,如果我们尝试再次读取相同的数据:
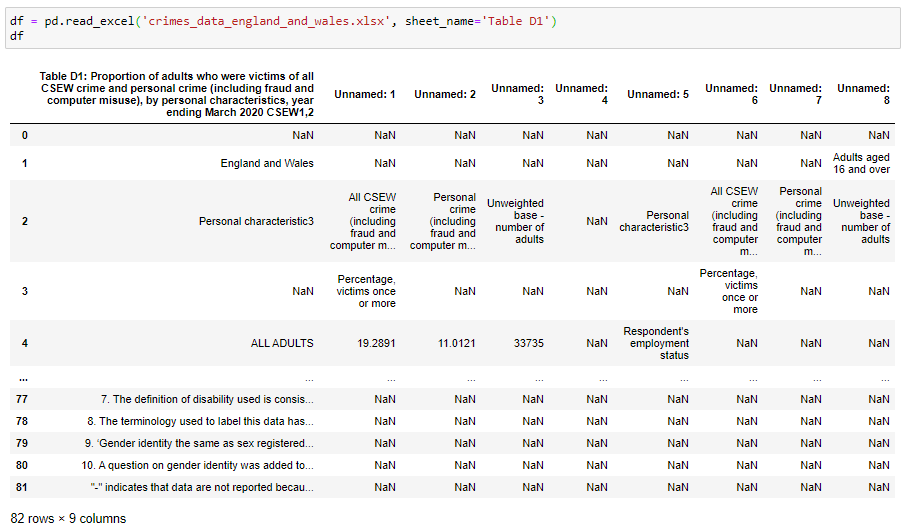
It works!
有用!
But Excel files can be a little bit messier. Besides data, they may have other comments/explanations in the first and/or last couple of rows.
但是Excel文件可能有点混乱。 除数据外,它们在第一和/或最后几行中可能还有其他注释/解释。
To tell pandas to start reading an Excel sheet from a specific row, use the argument header = 0-indexed row where to start reading. By default, header=0, and the first such row is used to give the names of the data frame columns.
要告诉熊猫开始从特定行读取Excel工作表,请使用参数header = 0索引行开始读取。 默认情况下,header = 0,并且第一个这样的行用于给出数据框列的名称。
To skip rows at the end of a sheet, use skipfooter = number of rows to skip.
要跳过工作表末尾的行,请使用skipfooter =要跳过的行数。
For example:
例如:
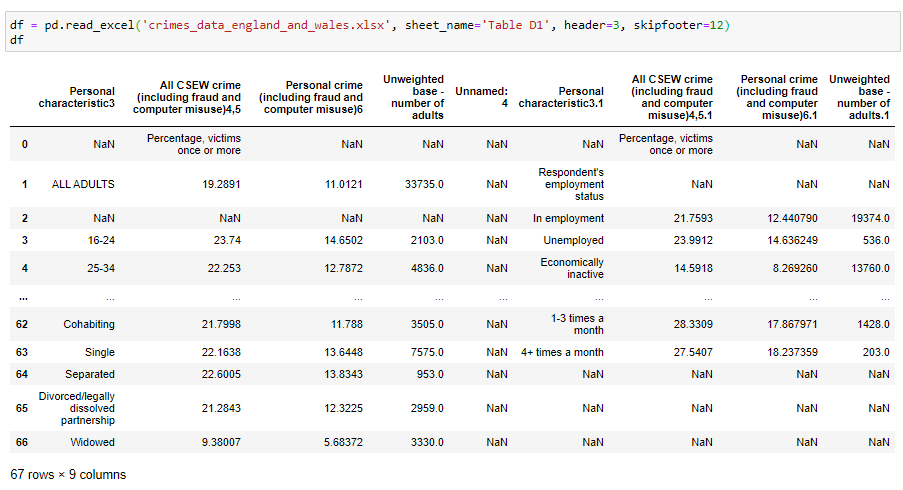
This is a little better. There are still some issues that are specific to this data. Depending on what we want to achieve we may also need to rearrange the data values into another way. But in this article, we will focus only on reading and writing to and from data frames.
这样好一点了。 仍然存在一些特定于此数据的问题。 根据我们要实现的目标,我们可能还需要将数据值重新排列为另一种方式。 但是在本文中,我们将仅专注于读写数据帧。
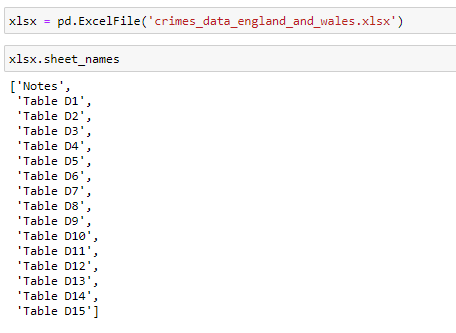
Another way to read Excel files besides the one above is by using a pd.ExcelFile object. Such an object can be constructed by using the pd.ExcelFile(‘excel_file_path’) constructor. An ExcelFile object can be used in a couple of ways. Firstly, it has a .sheet_names attribute which is a list of all the sheet names inside the opened Excel file.
除上述方法外,另一种读取Excel文件的方法是使用pd.ExcelFile对象。 可以使用pd.ExcelFile('excel_file_path')构造函数构造此类对象。 ExcelFile对象可以通过两种方式使用。 首先,它具有.sheet_names属性,该属性是打开的Excel文件中所有工作表名称的列表。
Then, this ExcelFile object also has a .parse() method that can be used to parse a sheet from the file and return a data frame. The first parameter of this method can be the index of the sheet we want to parse or its name. The rest of the parameters are the same as in the pd.read_excel() function.
然后,此ExcelFile对象还具有.parse()方法,该方法可用于从文件中解析工作表并返回数据框。 此方法的第一个参数可以是我们要解析的工作表的索引或其名称。 其余参数与pd.read_excel()函数中的参数相同。
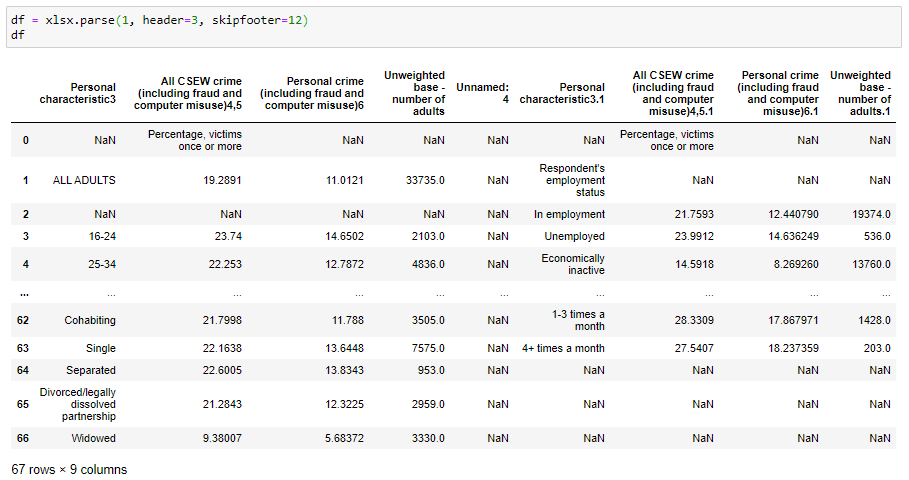
An example of parsing the second sheet (index 1):
解析第二张纸(索引1)的示例:
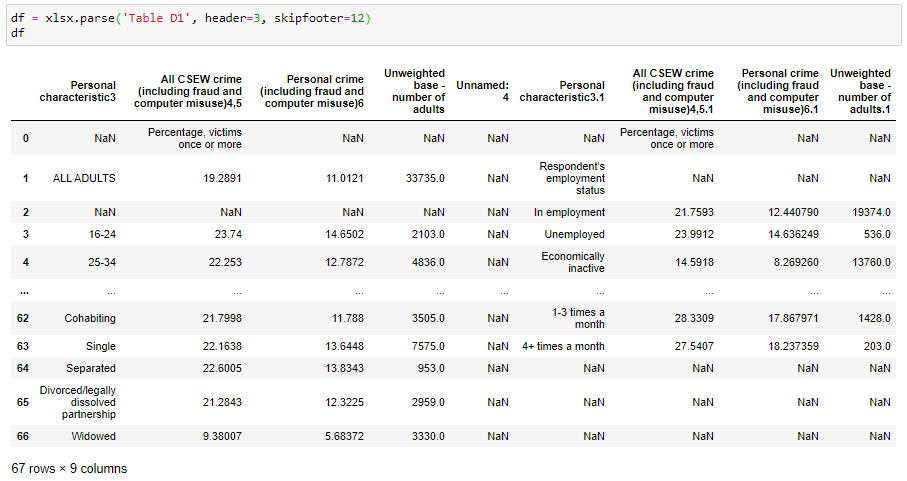
… and here we parse the same sheet using its name instead of an index:
…在这里,我们使用其名称而不是索引来解析同一张纸:
ExcelFiles can also be used inside with … as … statements, and if you want to do something a little more elaborate, like parsing only sheets with 2 words in their name, you can do something like:
ExcelFile也可以with … as …语句一起使用,如果您想做一些更复杂的事情,例如仅解析名称中带有2个单词的工作表,则可以执行以下操作:

The same thing you can do by using pd.read_excel() instead of .parse() method, like this:
您可以使用pd.read_excel()而不是.parse()方法来执行相同的操作,如下所示:

… or, if you simply want all the sheets, you can do:
…或者,如果您只想要所有工作表,则可以执行以下操作:

编写Excel文件 (Writing Excel Files)
Now that we know how to read excel files, the next step for us is to be able to also write a data frame to an excel file. We can do that by using the data frame method .to_excel(‘path_to_excel_file’, sheet_name=’…’).
现在我们知道了如何读取excel文件,对我们来说,下一步就是能够将数据帧写入excel文件。 我们可以通过使用数据框方法.to_excel('path_to_excel_file', sheet_name='…') 。
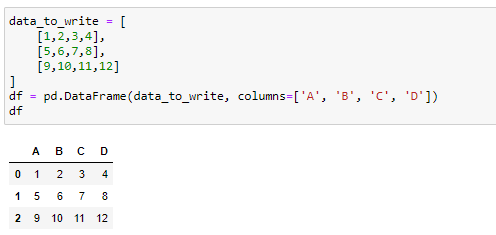
Let’s first create a simple data frame for writing to an excel file:
首先,让我们创建一个简单的数据框架以写入excel文件:
Now we want to write it to an excel file:
现在我们想将其写入一个excel文件:
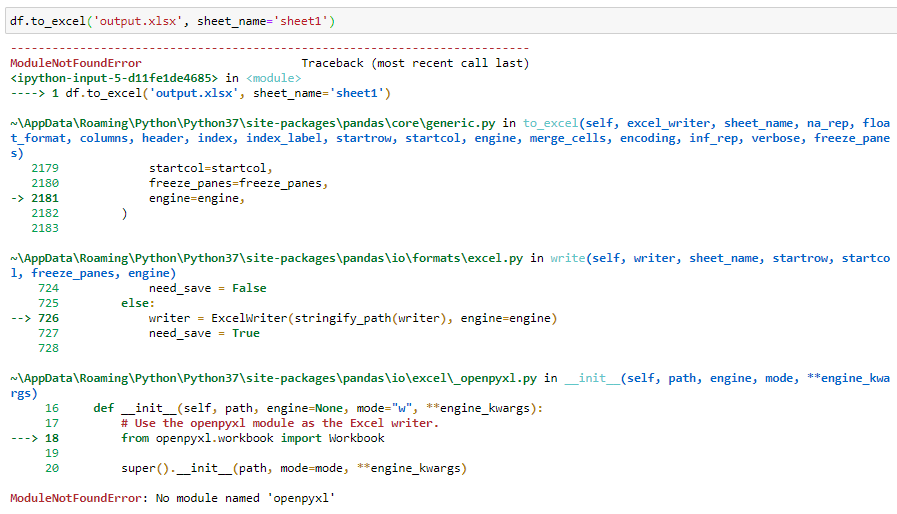
… and we got an error.
……我们遇到了一个错误。
Again, pandas can’t write to excel files on its own; we need another package for that. The main options that we have are:
同样,熊猫不能自己写入excel文件。 我们需要另一个软件包。 我们提供的主要选项是:
xlwt— works only with Excel 2003 (.xls) files; append mode not supportedxlwt仅适用于Excel 2003(.xls)文件; 不支持追加模式xlsxwriter— works only with Excel 2007+ (.xlsx) files; append mode not supportedxlsxwriter仅适用于Excel 2007+(.xlsx)文件; 不支持追加模式openpyxl— works only with Excel 2007+ (.xlsx) files; supports append modeopenpyxl仅适用于Excel 2007+(.xlsx)文件; 支持追加模式
If we want to be able to write to the old .xls format we should install xlwt as it is the only that handles those files. For .xlsx files, we will choose openpyxl as it also supports the append mode.
如果我们希望能够写入旧的.xls格式,则应该安装xlwt因为它是唯一处理那些文件的文件。 对于.xlsx文件,我们将选择openpyxl因为它也支持附加模式。
pip install xlwt openpyxl
pip install xlwt openpyxl
Now if we run again the above code, it works; an excel file was created:
现在,如果我们再次运行上面的代码,它可以工作; 创建了一个excel文件:
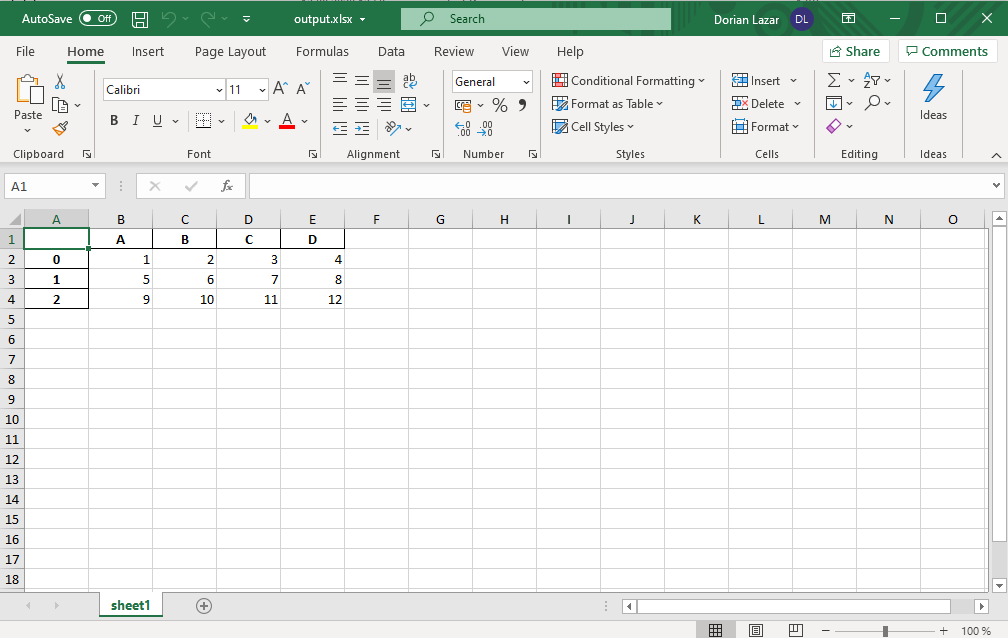
By default, pandas also writes the index column along with our columns. To get rid of it, use index=False like in the code below:
默认情况下,pandas还会将索引列与我们的列一起写入。 要摆脱它,请使用index=False如下面的代码所示:

The index column isn’t there now:
索引列现在不存在:
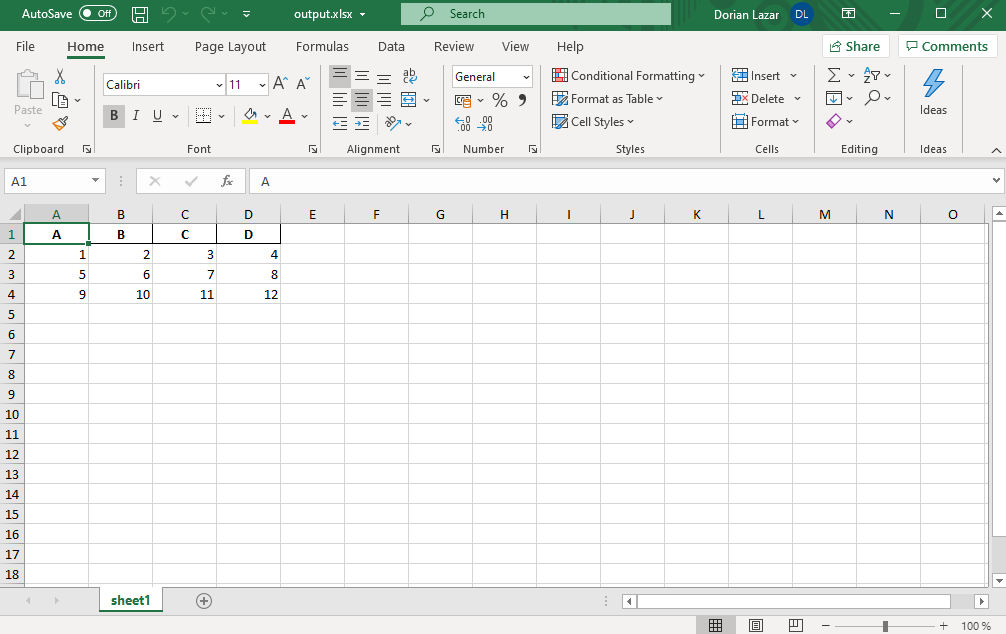
What if we want to write more sheets? If we want to add a second sheet to the previous file, do you think that the below code will work?
如果我们想写更多的图纸怎么办? 如果我们想在先前的文件中添加第二张纸,您认为以下代码可以工作吗?

The answer is no. It will just overwrite the file with only one sheet: sheet2.
答案是否定的 。 它将仅用一张纸覆盖该文件:sheet2。
To write more sheets to an Excel file we need to use a pd.ExcelWriter object as shown below. First, we create another data frame for sheet2, then we open an Excel file as an ExcelWriter object in which we write the 2 data frames:
要将更多工作表写入Excel文件,我们需要使用pd.ExcelWriter对象,如下所示。 首先,我们为sheet2创建另一个数据框,然后打开一个Excel文件作为ExcelWriter对象,在其中写入2个数据框:
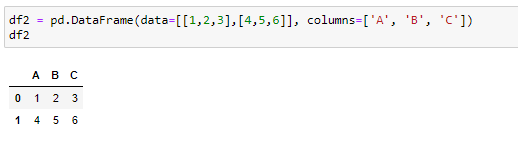

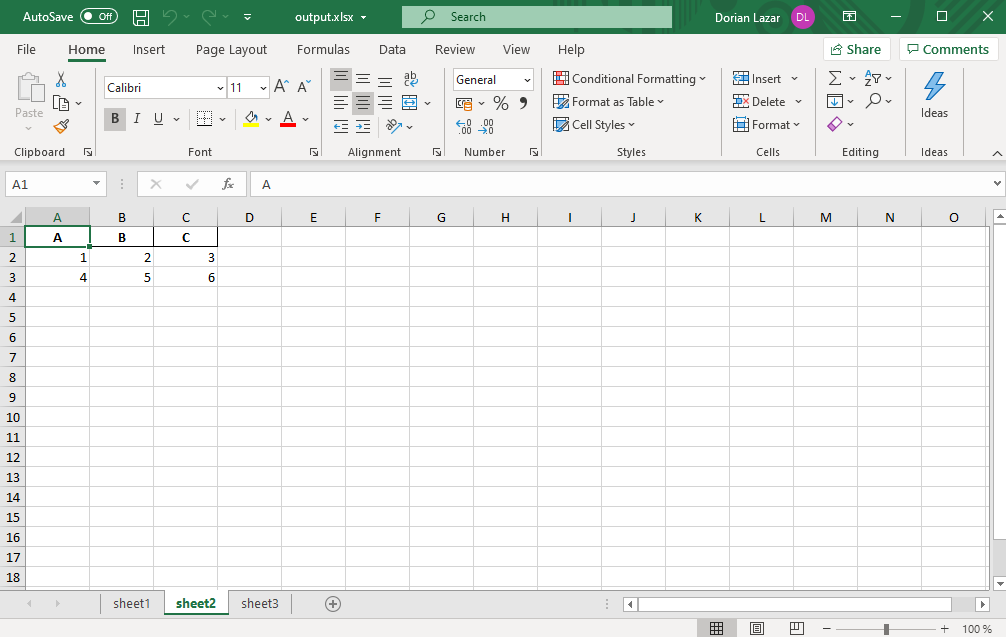
Now our Excel file should have 2 sheets. If we then want to add another sheet to it, we need to open the file in append mode and run code similar to the previous one. For example:
现在我们的Excel文件应该有2张纸。 然后,如果要向其添加另一张纸,则需要以附加模式打开文件,并运行与上一张相似的代码。 例如:

Our Excel file, now, has 3 sheets and looks like this:
我们的Excel文件现在有3张纸,看起来像这样:
使用Excel公式 (Working with Excel Formulas)
Probably you are wondering, at this point, about Excel formulas. What about them? How to read from files that have formulas? How to write them to Excel files?
此时,您可能想知道有关Excel公式的信息。 那他们呢 如何从具有公式的文件中读取? 如何将它们写入Excel文件?
Well… good news. It is quite easy. Writing formulas to Excel files is as simple as just writing the string of the formula, and these strings will be automatically interpreted by Excel as formulas.
好吧...好消息。 这很容易。 将公式写入Excel文件就像编写公式的字符串一样简单,并且Excel将自动将这些字符串解释为公式。
As an example:
举个例子:
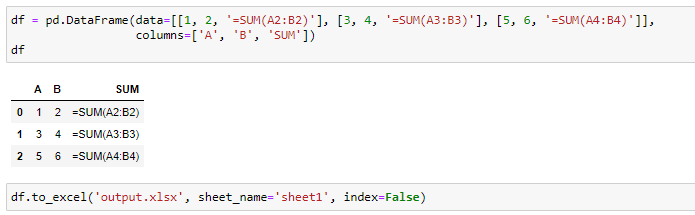
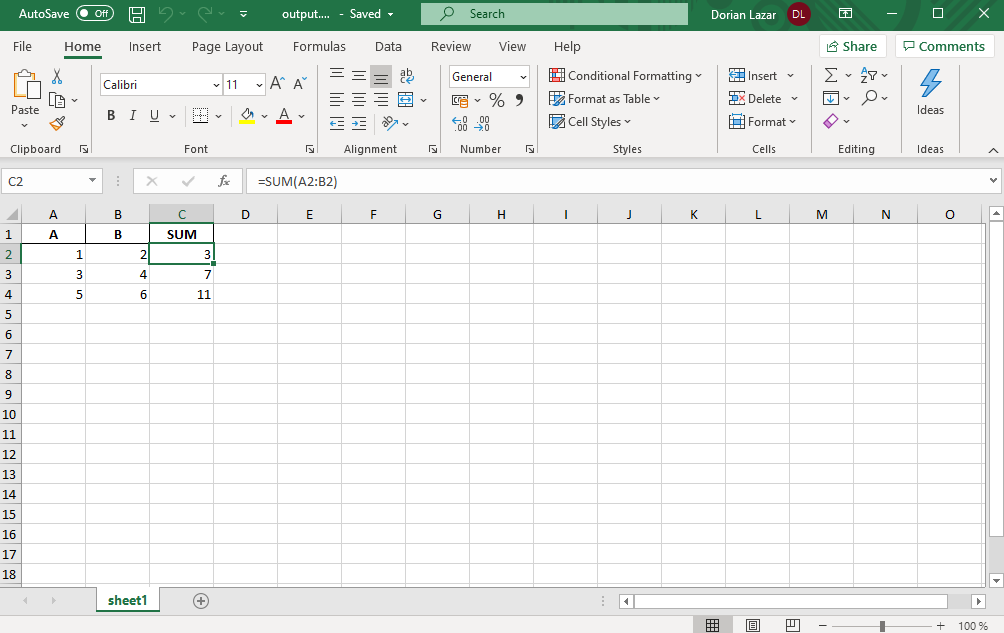
The Excel file produced by the code above is:
上面的代码生成的Excel文件是:
Now, if we want to read an Excel file with formulas in it, pandas will read into data frames the result of those formulas.
现在,如果我们要读取其中包含公式的Excel文件,则大熊猫会将这些公式的结果读入数据框。
For example, let’s read our previously created file:
例如,让我们阅读之前创建的文件:
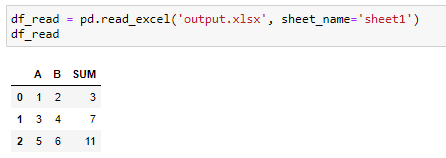
Sometimes you need to save the Excel file manually for this to work and not get zeros instead of the result of formulas (hit CTRL+S before executing the above code).
有时,您需要手动保存Excel文件才能使其正常工作,而不是获取零而不是公式的结果(执行上述代码之前,请按CTRL + S)。
Below is the code as a Jupyter notebook:
以下是Jupyter笔记本的代码:
That’s all for this article. Thanks for reading!
这就是本文的全部内容。 谢谢阅读!
翻译自: https://towardsdatascience.com/how-to-work-with-excel-files-in-pandas-c584abb67bfb
http://www.taodudu.cc/news/show-997519.html
相关文章:
- tableau使用_使用Tableau升级Kaplan-Meier曲线
- numpy 线性代数_数据科学家的线性代数—用NumPy解释
- 数据eda_银行数据EDA:逐步
- Bigmart数据集销售预测
- dt决策树_决策树:构建DT的分步方法
- 已知两点坐标拾取怎么操作_已知的操作员学习-第3部分
- 特征工程之特征选择_特征工程与特征选择
- 熊猫tv新功能介绍_熊猫简单介绍
- matlab界area_Matlab的数据科学界
- hdf5文件和csv的区别_使用HDF5文件并创建CSV文件
- 机器学习常用模型:决策树_fairmodels:让我们与有偏见的机器学习模型作斗争
- 100米队伍,从队伍后到前_我们的队伍
- mongodb数据可视化_使用MongoDB实时可视化开放数据
- Python:在Pandas数据框中查找缺失值
- Tableau Desktop认证:为什么要关心以及如何通过
- js值的拷贝和值的引用_到达P值的底部:直观的解释
- struts实现分页_在TensorFlow中实现点Struts
- 钉钉设置jira机器人_这是当您机器学习JIRA票证时发生的事情
- 小程序点击地图气泡获取气泡_气泡上的气泡
- PopTheBubble —测量媒体偏差的产品创意
- 面向Tableau开发人员的Python简要介绍(第3部分)
- pymc3使用_使用PyMC3了解飞机事故趋势
- 吴恩达神经网络1-2-2_图神经网络进行药物发现-第2部分
- 数据图表可视化_数据可视化十大最有用的图表
- 接facebook广告_Facebook广告分析
- eda可视化_5用于探索性数据分析(EDA)的高级可视化
- css跑道_如何不超出跑道:计划种子的简单方法
- 熊猫数据集_为数据科学拆箱熊猫
- matplotlib可视化_使用Matplotlib改善可视化设计的5个魔术技巧
- 感知器 机器学习_机器学习感知器实现
如何在Pandas中使用Excel文件相关推荐
- 如何在Java中转换Excel文件到图像?
Excel电子表格被广泛用于存储,组织和分析数据.但是,不能将Excel工作簿或工作表直接嵌入到Web或桌面应用程序中.合适的选项之一是将工作表转换为图像或HTML格式.在本文中,将学习如何使用Jav ...
- python发送excel文件_如何在Python中使用Excel文件(xlsx)附件发送电子邮件
我需要发送一封带有Excel附件的电子邮件 我的代码如下,可以发送电子邮件 但是当我收到邮件时,附件文件不是Excel文件~~ 看来我附加的格式不对~~~ 我添加了不同的电子邮件地址来接收此电子邮件 ...
- 如何在word中插入excel文件
word excel数据表 方法/步骤 1 首先要打开我们的word文档,小编这里就新建了一个word文档,里面没有写文章,我们主要把这个功能实现就可以了,在word的左上角有个插入的工具的选项: 2 ...
- 利用xpath爬取链家租房房源数据并利用pandas保存到Excel文件中
我们的需求是利用xpath爬取链家租房房源数据,并将数据通过pandas保存到Excel文件当中 下面我们看一下链家官网的房源信息(以北京为例) 如图所示,我们通过筛选得到北京租房信息 那么我们需要将 ...
- 如何在VB.NET中把excel文件转化为PDF文件
文章目录 一.如何在VB.NET中把excel文件转化为PDF文件 二.使用步骤 一.如何在VB.NET中把excel文件转化为PDF文件 基于之前获取打印机端口号的教程 二.使用步骤 代码如下(示例 ...
- mysql数据库 导入excel_如何在MySQL数据库中导入excel文件内的数据 详细始末
在开发项目的时候通常需要使用数据库,数据库Database是用来存储和管理数据的仓库.下面,我们以MySQL数据库为例来看看如何在数据库中导入excel文件内的数据吧. 操作方法 01 MySQL 打 ...
- python爬虫爬取豆瓣电影排行榜并通过pandas保存到Excel文件当中
我们的需求是利用python爬虫爬取豆瓣电影排行榜数据,并将数据通过pandas保存到Excel文件当中(步骤详细) 我们用到的第三方库如下所示: import requests import pan ...
- python打不开xls文件,wps下用vba实现合并文件夹中所有excel文件
python打不开xls文件,用wps下vba解决问题 用了常用的三种python读写xls文件的方法都报错 xlrd openpyxl pandas 原因 解决方法 用vba实现合并文件夹中所有ex ...
- pandas无法创建excel文件或者无法读取excel文件
使用pandas,创建excel文件刚开始报错如下: Traceback (most recent call last):File "d:/sources/pythons/pandas/te ...
最新文章
- 如何在PHP中获取客户端IP地址[重复]
- 8 种常见的SQL错误用法
- 【OpenCV3】级联分类器训练——traincascade快速使用详解
- 2019春季季节跳动招聘笔试(回忆版)第二题
- 【企业管理】自我管理时代,你的专注度决定未来
- 腾讯DevOps全链路解决方案
- excel中如何动态地创建控件以显示查询结果_Excel催化剂开源第23波-VSTO开发辅助录入功能...
- android自定义tab的分隔符,TabView中的分隔符
- 一个基于WF的业务流程平台
- 二叉树——新二叉树(洛谷 P1305)
- 特斯拉全球超级充电站已超过25000座 国内超过870座
- Buildroot根文件系统构建
- 编程语言python怎么读-网红编程语言Python将纳入高考你怎么看?
- nodejs 模板引擎ejs的使用
- graphx项目实战 — 航班飞行网图分析
- linux下libreoffice增加字体,自由办公说:LibreOffice添加中文标点扩展
- Oracle数据库中文排序问题记录
- 浏览器ocx控件安装 IE浏览器可用
- 9款用HTML5/CSS3制作的动物、人物动画
- Android图文识别