python scrapy 简单教程_Scrapy的简单使用教程
在这篇入门教程中,我们假定你已经安装了python。如果你还没有安装,那么请参考安装指南。
首先第一步:进入开发环境,workon article_spider
进入这个环境:

安装Scrapy,在安装的过程中出现了一些错误:通常这些错误都是部分文件没有安装导致的,因为大学时经常出现,所以对解决这种问题,很实在,直接到http://www.lfd.uci.edu/~gohlke/pythonlibs/这个网站下载对应的文件,下载后用pip安装,具体过程不在赘述。

然后进入工程目录,并打开我们的新创建的虚拟环境:

新建scrapy工程:ArticleSpider

创建好工程框架:在pycharm中导入
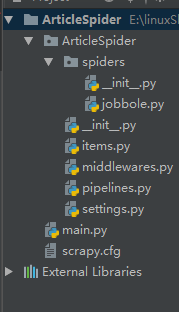
scrapy.cfg: 项目的配置文件。
ArticleSpeder/: 该项目的python模块。之后您将在此加入代码。
ArticleSpeder/items.py: 项目中的item文件。
ArticleSpeder/pipelines.py: 项目中的pipelines文件。
ArticleSpeder/settings.py: 项目的设置文件。
ArticleSpeder/spiders/: 放置spider代码的目录。
回到dos窗口用basic创建模板

上面pycharm的截图中已经创建好了:
为了今后更好的开发,创建一个用于debug的类main.py
from scrapy.cmdline import execute
import sys
import os
print(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy","crawl","jobbole"])
这是代码内容
import sys 为了设置工程目录,调用命令才会生效
里面的路径最好不要写死:可以通过os获取路径,更加灵活
execute用来执行目标程序的
jobbole.py的内容
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/110287']
def parse(self, response):
re_selector = response.xpath("/html/body/div[1]/div[3]/div[1]/div[1]/h1")
re2_selector = response.xpath('//*[@id="post-110287"]/div[1]/h1')
title = response.xpath('//div[@class="entry-header"]/h1/text()')
create_date = response.xpath("")
#//*[@id="112706votetotal"]
dian_zan = int(response.xpath("//span[contains(@class,'vote-post-up ')]/h10/text()").extract()[0])
pass
通过xpath技术获取对应文章的一些字段信息,包括标题,时间,评论数,点赞数等,因为比较简单所以不在赘述
写到这儿,大家也知道每次在pycharm里面debug和麻烦,因为scrapy比较大,所以这时候我们可以使用Scrapy shell来调试

标记部分是目标网站的地址:现在我们可以更加愉悦的进行调试了。
今天scrapy的初体验就到这里了
python scrapy 简单教程_Scrapy的简单使用教程相关推荐
- python scrapy框架爬虫_Scrapy爬虫框架教程(一)-- Scrapy入门
前言 转行做python程序员已经有三个月了,这三个月用Scrapy爬虫框架写了将近两百个爬虫,不能说精通了Scrapy,但是已经对Scrapy有了一定的熟悉.准备写一个系列的Scrapy爬虫教程,一 ...
- 廖雪峰python3爬虫教程_Scrapy爬虫框架入门教程(1)——爬取廖雪峰老师的博客...
最近一直在学习scrapy,但是网上关于scrapy的教程实在是太少,能找到的教程大多都是基于py2.7/scrapy0.2以下,甚至很多教程都是互相抄袭,连代码都抄漏了好多,更别提各种缩进错误.变量 ...
- pythonscrapy框架_简述python Scrapy框架
一.Scrapy框架简介 Scrapy是用纯Python实现一个为了爬取网站数据,提取结构性数据而编写的应用框架,用途非常广泛.利用框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网 ...
- python scrapy 框架的简单使用爬虫苏宁易购图书信息
python scrapy 框架的简单使用&&爬虫苏宁易购图书信息 前言 第一步: 分析网页 1.1 找到要爬取的数据位置 分类信息 图书信息 价格信息 1.2 分析如何获取数据 正则 ...
- Python爬虫入门教程:超级简单的Python爬虫教程
这是一篇详细介绍 [Python]爬虫入门的教程,从实战出发,适合初学者.读者只需在阅读过程紧跟文章思路,理清相应的实现代码,30 分钟即可学会编写简单的 Python 爬虫. 这篇 Python 爬 ...
- Python小型web服务 web.py 简单教程
最近有个项目需要通过Java调用Python的服务,有考虑过gRPC,那是一个很好的框架,通信效率高.但是基于够用就好的原则,决定选择使用简单的HTTP通信方式,Python建立服务器,公开JSON ...
- 在Python中安装GDAL(最简单,最详细图文教程)
在Python中安装GDAL(最简单,最详细图文教程) 今天是2021年1月20日.为了安装在pythong中安装GDAL,我浏览了几十个网页,发现有99%都是垃圾,浪费了我非常多的时间.最后我安装成 ...
- python简单圣诞树手工折纸_简单折纸圣诞树手工制作教程教你如何折简单的圣诞树...
简单折纸圣诞树手工制作教程教你如何折简单的圣诞树 圣诞节到来之际,各种有趣的折纸手工制作开始受到大家的关注和喜爱哦.纸艺网也开始给大家推荐一些有趣的手工折纸制作.这里纸艺网推荐的这个折纸制作是一个折纸 ...
- python画熊猫头_超简单的熊猫头简笔画原创教程步骤
导读:小编根据大家的需要整理了一份关于<超简单的熊猫头简笔画原创教程步骤>的内容,具体内容: 熊猫生活在海拔2600-3500米的茂密竹林里,那里常年空气稀薄,云雾缭绕,气温低于20℃.那 ...
最新文章
- cuda-convnet2与caffe对比
- Windows下完成端口移植Linux下的epoll
- 电大计算机应用模块四实2010,国家开放大学《计算机应用基础》考试与答案形考任务模块2Word2010文字处理系统—客观题测验答案.docx...
- react中用pace.js
- python创建脚本文件_python创建文件备份的脚本
- 信息加密之信息摘要加密MD2、MD4、MD5
- 安卓逆向_15( 一 ) --- JNI 和 NDK
- OpenShift 4 - Knative教程 (7) Eventing之Broker和Trigger
- 【我来解惑】.Net应该学什么怎么学(二)
- java 重定向关键字_springboot实现转发和重定向
- 【毕业设计】基于Android的家校互动平台开发(内含完整代码和所有文档)——爱吖校推(你关注的,我们才推)...
- [经验教程]谷歌浏览器google chrome网站不安全与网站的连接不安全怎么办?
- IDEA 2018 破解
- JavaScript封装拖动滑块验证
- BI数据分析师究竟是做什么的?
- html重复渐变包括,html – CSS:当设置为tbody / thead时,在Chrome中重复的渐变
- 当今主流浏览器内核简介
- 宁西铁路线 宁合线 宁西铁路
- SLAM大牛Cyrill 开源SuMa ++:基于语义激光雷达过滤动态物体提高定位精度
- mysql连接oracle视图_oracle数据库视图