DeepStyle(第2部分):时尚GAN
If you haven't read Part 1, please read it first since this article assumes you have read Part 1 already.
如果您尚未阅读第1部分 ,请先阅读,因为本文假定您已经阅读了第1部分。
Now assuming you have read Part 1, let’s go on.
现在,假设您已经阅读了第1部分,让我们继续。
步骤5在Pinterest数据库和作物上运行更快的R-CNN (Step 5 Run Faster R-CNN on Pinterest Database and Crop)
After gathering the Pinterest database, now we can perform inference on these images using our previously trained Faster R-CNN. But before we do that, we need to first add the functionality where we will crop the detected object and save the resulting image, since this functionality is not provided right out of the box. You can do this by going to the github repo of this project and download the vis.py . Then, navigate to detectron/utils and replace the existing vis.py with the downloaded version. The new vis.py is the same with the one already provided but with one major difference — crop the object detected and save it in a directory.
收集Pinterest数据库之后,现在我们可以使用我们以前训练的Faster R-CNN对这些图像进行推理。 但是在执行此操作之前,我们需要首先添加该功能,在该功能中我们将裁剪检测到的对象并保存生成的图像 ,因为此功能并未立即提供。 您可以通过转到该项目的github存储库并下载vis.py来做到这vis.py 。 然后,导航至detectron/utils并将现有的vis.py替换为下载的版本。 新的vis.py与已经提供的vis.py相同,但有一个主要区别-裁剪检测到的对象并将其保存在目录中。
The added code predicts the category for the detected object, and if the category is “Full” meaning full-body clothing, then it will crop the image and save it in the directory specified. We only save full-body clothing because we want to be able to generate full-body clothing as well, not only simple shirts or skirts.
添加的代码将预测检测到的对象的类别,如果类别为“ Full”(表示全身衣服),则它将裁剪图像并将其保存在指定的目录中。 我们只保存全身衣服是因为我们也希望能够生成全身衣服,而不仅仅是简单的衬衫或裙子。
After tiny modifications, we are ready to run our model on the Pinterest dataset! We can run inference on our Faster R-CNN previously trained by:
经过微小的修改后,我们准备在Pinterest数据集上运行我们的模型! 我们可以对先前受过以下训练的Faster R-CNN进行推断:
python tools/infer.py \ --im [path/to/image.jpg] \ --rpn-pkl [path/to/rpn/model.pkl] \ --rpn-cfg --output-dir [path/to/output/dir]The [path/to/image.jpg] is the directory where we store our Pinterest images, --rpn-pkl is where we previously saved our model .pkl file, --rpn-cfg is where we stored our configs file, and finally, --output-dir is where we want to save our predictions. However, this --output-dir is not that important as it will contain the uncropped images with the predictions. Where we want to look for is the directory we specified in vis.py because that’s where the cropped images will be saved.
[path/to/image.jpg]是我们存储Pinterest图像的目录,-- --rpn-pkl是我们先前存储模型.pkl文件的位置,-- --rpn-cfg是我们存储配置文件的位置,以及最后,-- --output-dir是我们要保存预测的位置。 但是,此--output-dir并不重要,因为它将包含未裁剪的图像以及预测。 我们要查找的是我们在vis.py指定的目录,因为这是裁剪图像的保存位置。

After performing inference on the model, we should get the cropped images with the clothing centered, and the model, as well as the background, mostly removed. Even though there is still some noise, what we have is already good enough.
在对模型进行推断之后,我们应该获取裁剪后的图像,其中衣服要居中,并且大部分移除模型以及背景。 即使仍然有些噪音,我们所拥有的已经足够好了。

步骤6将预测和图像传递给DCGAN以进行生成 (Step 6 Pass Predictions and Images to DCGAN for Generation)
Now that we finally have our high-quality clothing images, we can start building the DCGAN model!
现在我们终于有了高质量的服装图像,我们可以开始构建DCGAN模型了!
Note: The code is based on the official DCGAN tutorial from Pytorch where you access from here. The code won’t be explained in too detail, you can refer to the tutorial for more detailed explanations.
注意:该代码基于Pytorch的官方DCGAN教程,您可以从 此处 访问 。 不会对代码进行太详细的解释,您可以参考该教程以获取更详细的解释。
Let’s begin. First we have to import all the necessary libraries:
让我们开始。 首先,我们必须导入所有必需的库:
Next, we set up all the variables that we’ll need later on:
接下来,我们设置稍后将需要的所有变量:
After setting up the variables, we now create the dataset and dataloader which we will feed into our model later. We resize the images, center crop them to the desired image size, and normalize them. Our image size is set to 64 because smaller sizes are normally more consistent.
设置完变量后,我们现在创建数据集和数据加载器,稍后将它们输入模型中。 我们调整图像的大小,将其中心裁剪为所需的图像大小,然后对其进行归一化。 我们的图像尺寸设置为64,因为通常较小的尺寸会更一致。
We also plot some training images to visualize:
我们还绘制了一些训练图像以可视化:

After that, we define the weights initialization on the generator and discriminator about the be built:
之后,我们在生成器和鉴别器上定义要构建的权重初始化:
We build the generator:
我们构建生成器:

And the discriminator!
和鉴别器!

Then we define the training process. We use BCELoss function because the job of the discriminator is identifying whether an image is real or fake. We setup Adam optimizers for both the generator and the discriminator. Then, we update both networks batch-by-batch:
然后我们定义培训过程。 我们使用BCELoss函数是因为鉴别器的工作是识别图像是真实的还是伪造的。 我们为生成器和鉴别器设置了Adam优化器。 然后,我们逐批更新两个网络:
This will start the training process. The output is:
这将开始培训过程。 输出为:

The training process will take a while. After training, we can plot the generator and discriminator loss during training:
培训过程将需要一段时间。 训练后,我们可以绘制训练过程中的生成器和鉴别器损失:
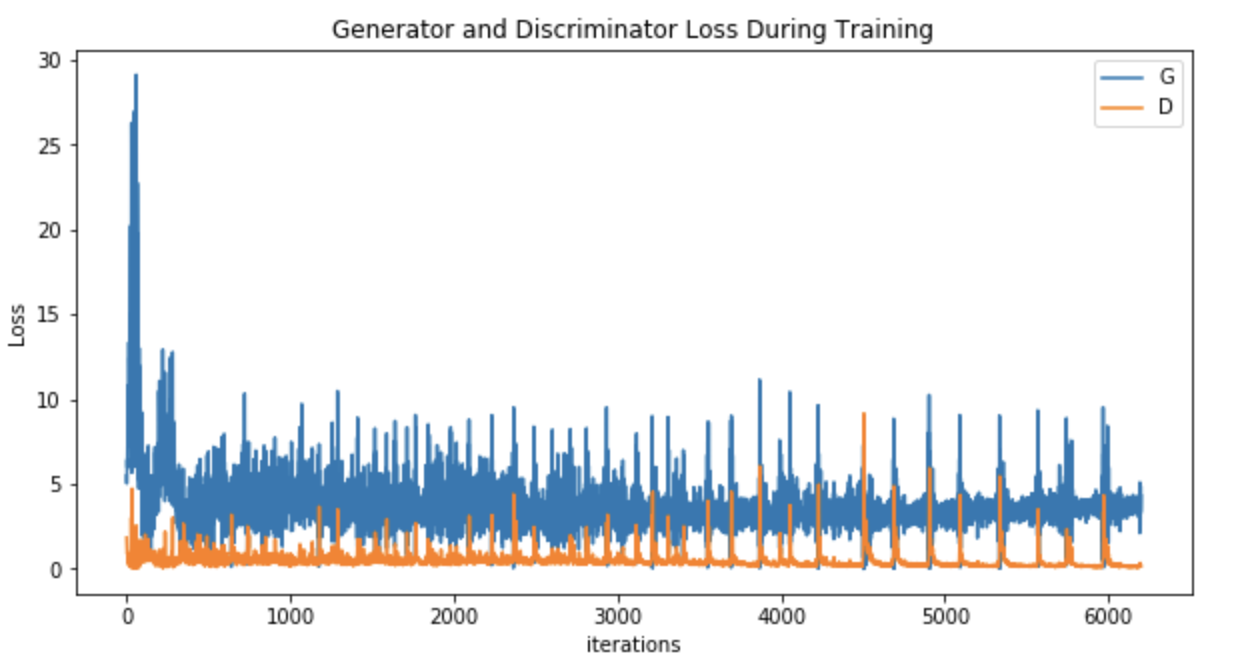
Then after all this work, this is the last step — to save the images to local hard disk:
然后,完成所有这些工作,这是最后一步-将图像保存到本地硬盘:
结果 (Results)
And finally guys, after all this work! We get to see the generated results:
终于,伙计们,完成了所有这些工作! 我们可以看到生成的结果 :
Now we can plot and compare between the real images from our dataset and generated images, side-by-side.
现在,我们可以并排绘制和比较数据集中的真实图像和生成的图像。

Not bad right? The fake images are not that far off from real images. In fact, some actually look quite high-fashion to my eyes
DeepStyle(第2部分):时尚GAN相关推荐
- ICCV2017 | 一文详解GAN之父Ian Goodfellow 演讲《生成对抗网络的原理与应用》(附完整PPT)
当地时间 10月 22 日到10月29日,两年一度的计算机视觉国际顶级会议 International Conference on Computer Vision(ICCV 2017)在意大利威尼斯开 ...
- 深度学习布料交换:在Keras中实现条件类比GAN
2017年10月26日SHAOANLU 条件类比GAN:交换人物形象的时尚文章(链接) 给定三个输入图像:人穿着布A,独立布A和独立布B,条件类比GAN(CAGAN)生成穿着布B的人类图像.参见下图. ...
- 万物皆可JOJO:这个GAN直接让马斯克不做人啦 !Demo在线可玩!
来源:量子位 这下真的是万物皆可JOJO化了! 本来就神采飞扬的马斯克,下一刻更是仿佛要直接"我不做人啦!" 世界名画蒙娜丽莎神秘优雅的微笑,似乎也变得JO灼了起来-- 再来个同一 ...
- 今日 Paper | 跨模态行人重识别;对抗时尚迁移;学会注意错误等
2020-03-11 15:11:09 目录 跨模态行人重识别:共享与特异特征变换算法cm-SSFT GarmentGAN:具有图片真实感的对抗时尚迁移 学习将纹理从服装图像转移到3D人体 学会注意错 ...
- 一些非常酷的GAN的应用
2019-08-27 20:48:57 作者:Jonathan Hui 编译:ronghuaiyang 导读 GANs被称为是深度学习"过去20年内在深习上最酷的想法",既然是最酷 ...
- 万物皆可JOJO:这个GAN直接让马斯克不做人啦 | Demo可玩
博雯 发自 凹非寺 量子位 报道 | 公众号 QbitAI 这下真的是万物皆可JOJO化了! 本来就神采飞扬的马斯克,下一刻更是仿佛要直接"我不做人啦!" 世界名画蒙娜丽莎神秘优雅 ...
- 裤子换裙子,就问你GAN的这波操作秀不秀
全世界只有3.14 % 的人关注了 数据与算法之美 把照片里的绵羊换成长颈鹿.牛仔长裤换成短裙.听起来有点不可思议,但韩国科学技术院和浦项科技大学的研究人员目前已实现了这一骚操作. 他们开发的一种机器 ...
- GAN的一些很酷的应用
在GAN发展的最初几年里,我们取得了令人瞩目的进展.当然,现在不会是像恐怖电影里那样有邮票大小的面部照片了.2017年,Gan制作了1024×1024张能愚弄人才童子军的照片.在未来几年,我们可能会看 ...
- 当时尚遇上AI!港中文MMLab开源MMFashion工具箱
点击我爱计算机视觉标星,更快获取CVML新技术 我们今天在OpenMMLab下正式开源了MMFashion这个项目的代码和预训练模型.它是一个针对视觉时尚分析(Visual Fashion Analy ...
- 让机器也拥有品味!时尚图像补全网络FiNet| ICCV 2019 Oral
点击我爱计算机视觉标星,更快获取CVML新技术 本文对ICCV 2019 Oral 论文 FiNet: Compatible and Diverse Fashion Image Inpainting进 ...
最新文章
- python正确方法,方法 - 廖雪峰的官方网站
- hdu1280 前m大的数(数组下标排序)
- 「后端小伙伴来学前端了」Vuex进阶操作,让你的代码更加高效(简称如何学会偷懒 【手动狗头】)
- 使用 udev 进行动态内核设备管理(转自suse文档)
- 字节跳动Deep Retrieval召回模型笔记
- 统计dataframe中所有列的null数量与填充null注意事项
- sklearn自学指南(part59)--神经网络模型(监督)
- Vs Code:Remote SSH
- C++中使用try{}catch()的优/缺点
- java第一天上班需要安装那些_明天第一天上班,应该带什么包啊
- Latex 调整表格大小 表格过大 表格过小
- 微信推视频红包;百度春晚红包互动 137 亿次;谷歌用皮影庆猪年 | 极客头条...
- 2021-04-23 商业文章版权协议分类
- SAS 9.4 的sid问题解决方案汇总(头疼...)
- 【转】请不要做浮躁的人。
- linux如何远程装java_使用Shell远程给Linux安装JDK
- android 叠加视图 重启,android-后台应用程序以侦听拖动手势
- orCAD导入AD库 连不上线 更改元件库 出现Unable To Save Part
- 建筑专业规范大全 2020版_房屋建筑工程现行规范标准目录汇编(2020版)—防水工程...
- 什么是数据可视化大屏?有哪些优点
热门文章
- 第四次黄鹤楼之老照片
- hdu 1907John博弈
- 20200623每日一句
- 第五章 线性回归 学习笔记下
- 190708每日一句 努力VS天赋;假如生活欺骗了你
- Image Pyramids
- Atitit 数据库重复数据产生原因与解决总结 目录 1. 原因 1 1.1. 缺少数据约束校验 1 1.2. 表关系关联设计错误 1 2. 约束种类 1 2.1. 分类 表级约束vs列级别约束 2
- Atitit 前端算法技术体系总结 目录 1. 3. Ui方面的算法 3 2 3.1. 软键盘算法 计算软键盘上下左右按键位置 3 2 3.2. Sprire生成随机位置算法 随机数算法 3
- Atitit 项目风险管理 目录 1. 技术分险 2 1.1. 全面跟随大公司解决方案 2 1.2. 过度设计 2 1.3. 可读性 扩展性不足 2 1.4. 教条僵化 2 1.5. 技术方案超出了
- Atitit 提升开发进度大方法--高频功能与步骤的优化 类似性能优化