aws rds恢复数据库_使用AWS Glue将数据从AWS S3加载到AWS RDS SQL Server数据库
aws rds恢复数据库
This article explains how to develop ETL (Extract Transform Load) jobs using AWS Glue to load data from AWS S3 into AWS RDS SQL Server database objects.
本文介绍了如何使用AWS Glue开发ETL(提取转换加载)作业以将数据从AWS S3加载到AWS RDS SQL Server数据库对象中。
介绍 (Introduction)
ETL is one of the widely-used methods for data integration in any enterprise IT landscape. Data is transported from source to destination data repositories using ETL jobs. Enterprises host production workloads on AWS RDS SQL Server instances on the cloud. Data is often load in and out of these instances using different types of ETL tools. One of the AWS services that provide ETL functionality is AWS Glue. AWS S3 is the primary storage layer for AWS Data Lake. Often semi-structured data in the form of CSV, JSON, AVRO, Parquet and other file-formats hosted on S3 is loaded into Amazon RDS SQL Server database instances. In this article, we will explore the process of creating ETL jobs using AWS Glue to load data from Amazon S3 to an Amazon RDS SQL Server database instance.
ETL是在任何企业IT环境中用于数据集成的广泛使用的方法之一。 使用ETL作业将数据从源数据存储库传输到目标数据存储库。 企业将生产工作负载托管在云上的AWS RDS SQL Server实例上。 通常使用不同类型的ETL工具将数据加载到这些实例中或从其中加载数据。 提供ETL功能的AWS服务之一是AWS Glue。 AWS S3是AWS Data Lake的主要存储层。 S3上托管的CSV,JSON,AVRO,Parquet和其他文件格式形式的半结构化数据通常会加载到Amazon RDS SQL Server数据库实例中。 在本文中,我们将探讨使用AWS Glue创建ETL作业以将数据从Amazon S3加载到Amazon RDS SQL Server数据库实例的过程。
AWS RDS SQL Server实例 (AWS RDS SQL Server Instance)
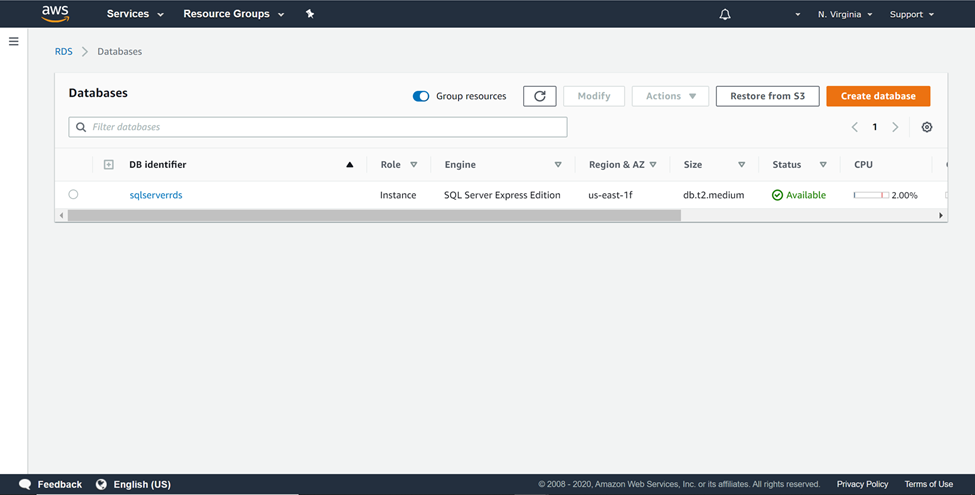
It’s assumed that an operational instance of AWS RDS SQL Server is already in place. Once the instance is available, it would look as shown below. For the ETL job that we would be developing in this article, we need a source and a target data repository. Amazon S3 would act as the source and the SQL Server database instance would act as the destination. Even a SQL Server Express edition hosted on SQL Server instance will work. Do ensure, that you have the required permissions to manage an AWS S3 bucket as well as the SQL Server database instance.
假定已经存在AWS RDS SQL Server的操作实例。 实例可用后,将如下所示。 对于本文将要开发的ETL作业,我们需要一个源和一个目标数据存储库。 Amazon S3将充当源,而SQL Server数据库实例将充当目的地。 甚至托管在SQL Server实例上SQL Server Express版本也可以使用。 请确保您具有管理AWS S3存储桶以及SQL Server数据库实例的必需权限。
使用示例数据设置AWS S3存储桶 (Setting up an AWS S3 Bucket with sample data)
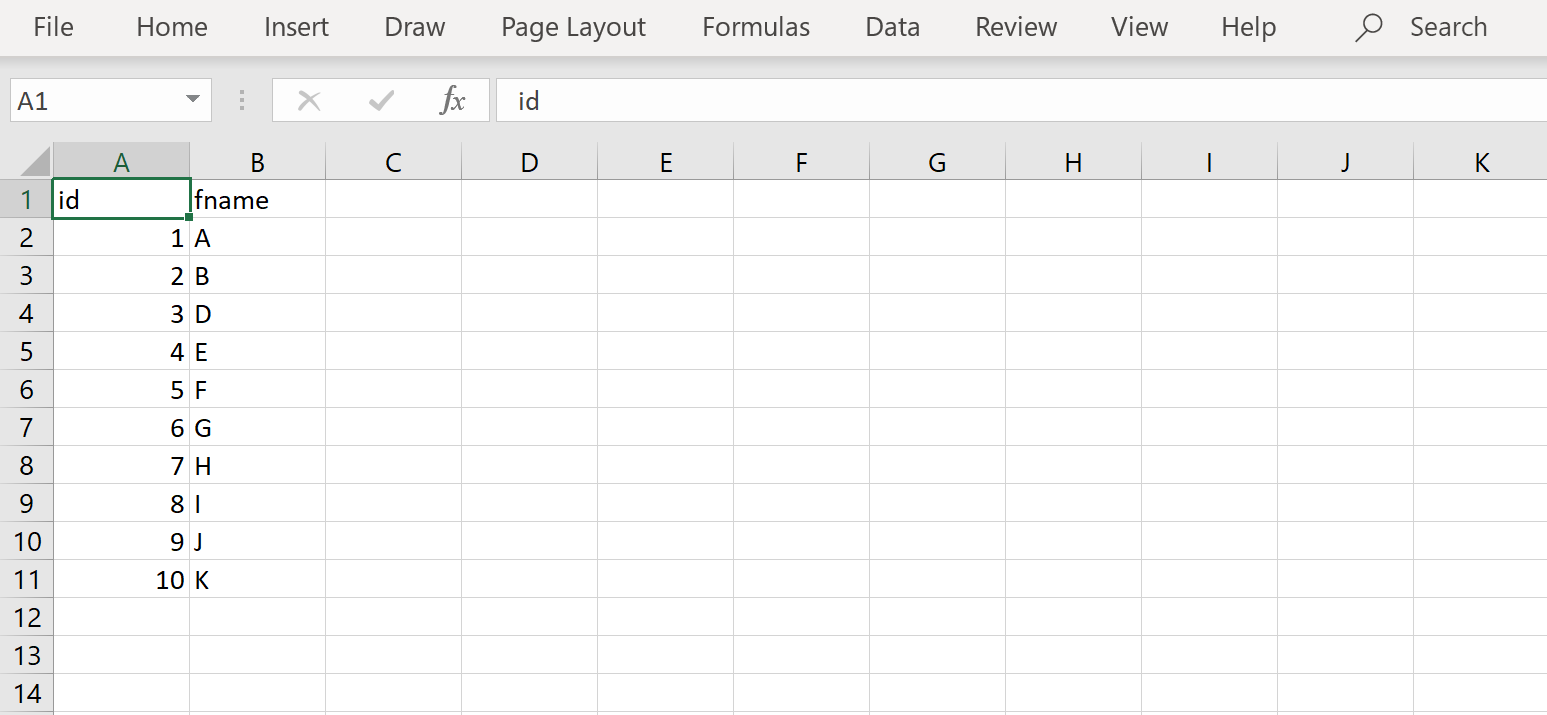
Navigate to the AWS S3 home page, by typing S3 on the AWS Console home page and then open the selected service. From the Amazon S3 home page, click on the Create Bucket button to create a new AWS S3 bucket. Provide a relevant name and create the bucket in the same region where you have hosted your AWS RDS SQL Server instance. Create a sample CSV file as shown below and add some sample data to it. In our case, we have a sample file named employees that has two fields and a few records as shown below.
通过在AWS Console主页上键入S3,导航到AWS S3主页,然后打开所选服务。 在Amazon S3主页上,单击创建存储桶按钮以创建一个新的AWS S3存储桶。 提供相关名称,并在托管AWS RDS SQL Server实例的同一区域中创建存储桶。 如下所示创建一个示例CSV文件,并向其中添加一些示例数据。 在我们的例子中,我们有一个名为employees的样本文件,它具有两个字段和一些记录,如下所示。
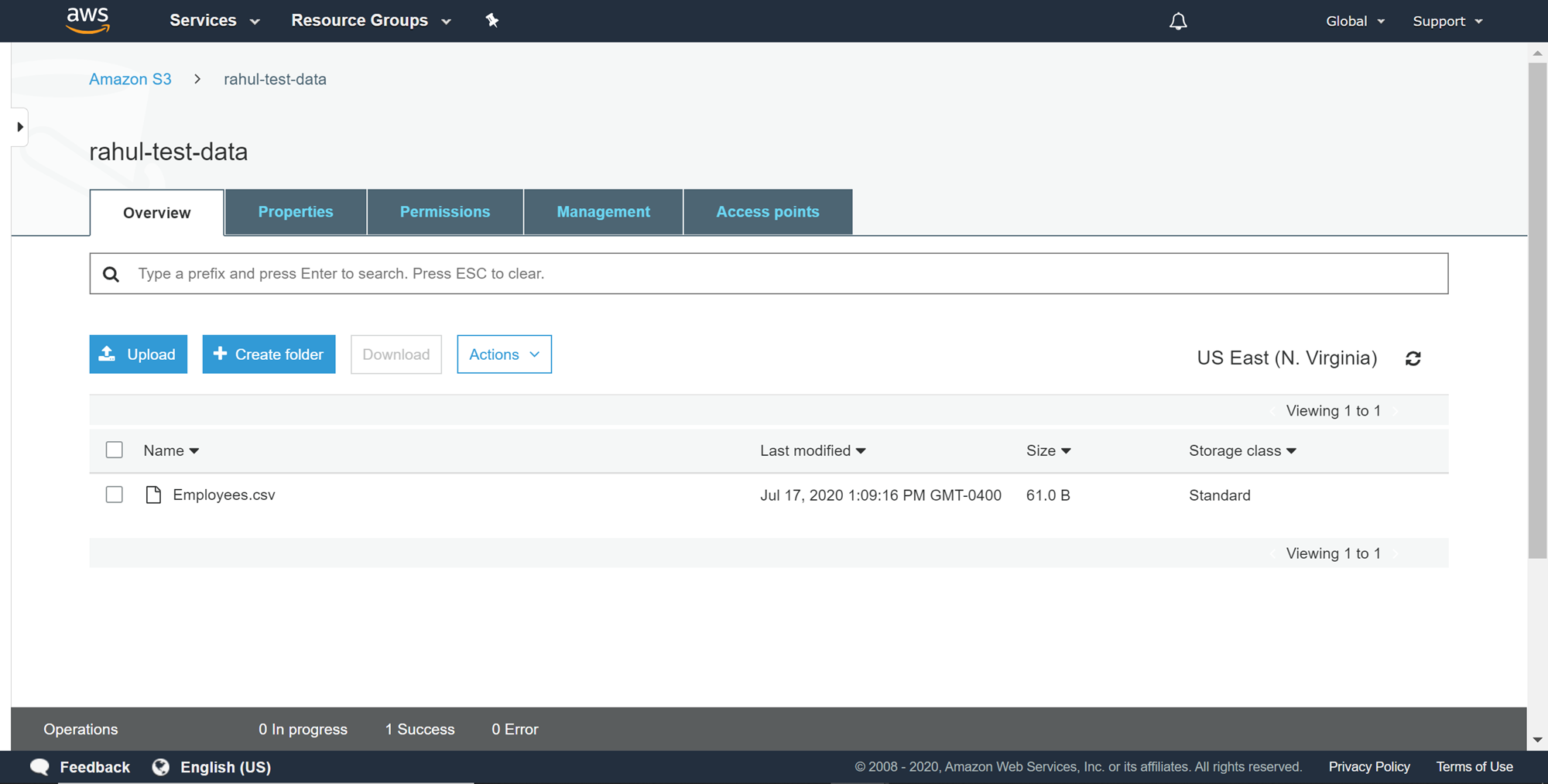
Once the file has been created, upload it to the newly created S3 bucket by clicking on the Upload button in the AWS S3 Bucket interface. Once you have uploaded the file successfully, it would look as shown below. This completes the creation of our source data setup.
创建文件后,通过单击AWS S3 Bucket界面中的Upload按钮将其上传到新创建的S3存储桶。 成功上传文件后,其外观如下所示。 这样就完成了源数据设置的创建。
AWS RDS SQL Server数据库对象设置 (AWS RDS SQL Server database objects setup)
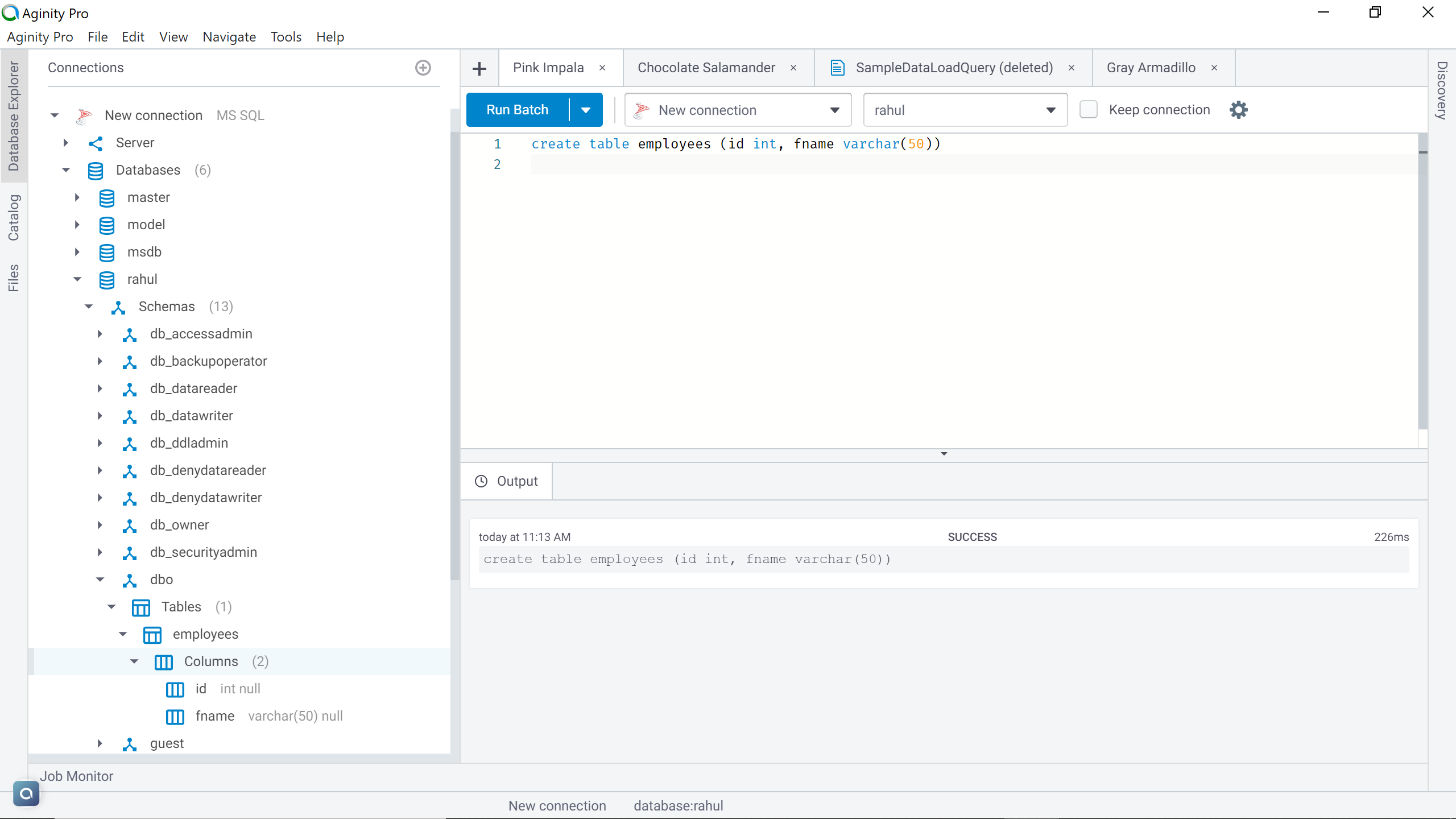
Log on to the AWS RDS SQL Server database instance using the editor of your choice. Once you have connected to the instance, create a table that matches the schema of the CSV file that we just created. The schema can be different as well, in that case, we will have to perform a transformation for the source data to load into the target table. To keep the transformation complexity minimum so that we focus on the configuration of the ETL job, here a table is created that has identical schema to the CSV file as shown below.
使用您选择的编辑器登录到AWS RDS SQL Server数据库实例。 连接到实例后,创建一个与我们刚刚创建的CSV文件的模式匹配的表。 模式也可以不同,在这种情况下,我们将必须执行转换以将源数据加载到目标表中。 为了使转换复杂度最小,以便我们专注于ETL作业的配置,此处创建了一个表,该表具有与CSV文件相同的架构,如下所示。
爬行AWS S3文件和AWS RDS SQL Server表 (Crawling AWS S3 files and AWS RDS SQL Server tables)
We learned how to crawl SQL Server tables using AWS Glue in my last article. In the same way, we need to catalog our employee table as well as the CSV file in the AWS S3 bucket. The only difference in crawling files hosted in Amazon S3 is the data store type is S3 and the include path is the path to the Amazon S3 bucket which hosts all the files. After all the Amazon S3 hosted file and the table hosted in SQL Server is a crawler and cataloged using AWS Glue, it would look as shown below.
在上一篇文章中,我们学习了如何使用AWS Glue对SQL Server表进行爬网。 以同样的方式,我们需要在AWS S3存储桶中对员工表以及CSV文件进行分类。 搜寻Amazon S3中托管的文件的唯一区别是数据存储类型为S3,而include路径是托管所有文件的Amazon S3存储桶的路径。 在所有Amazon S3托管文件和SQL Server中托管的表都是搜寻器并使用AWS Glue进行分类之后,它看起来如下所示。
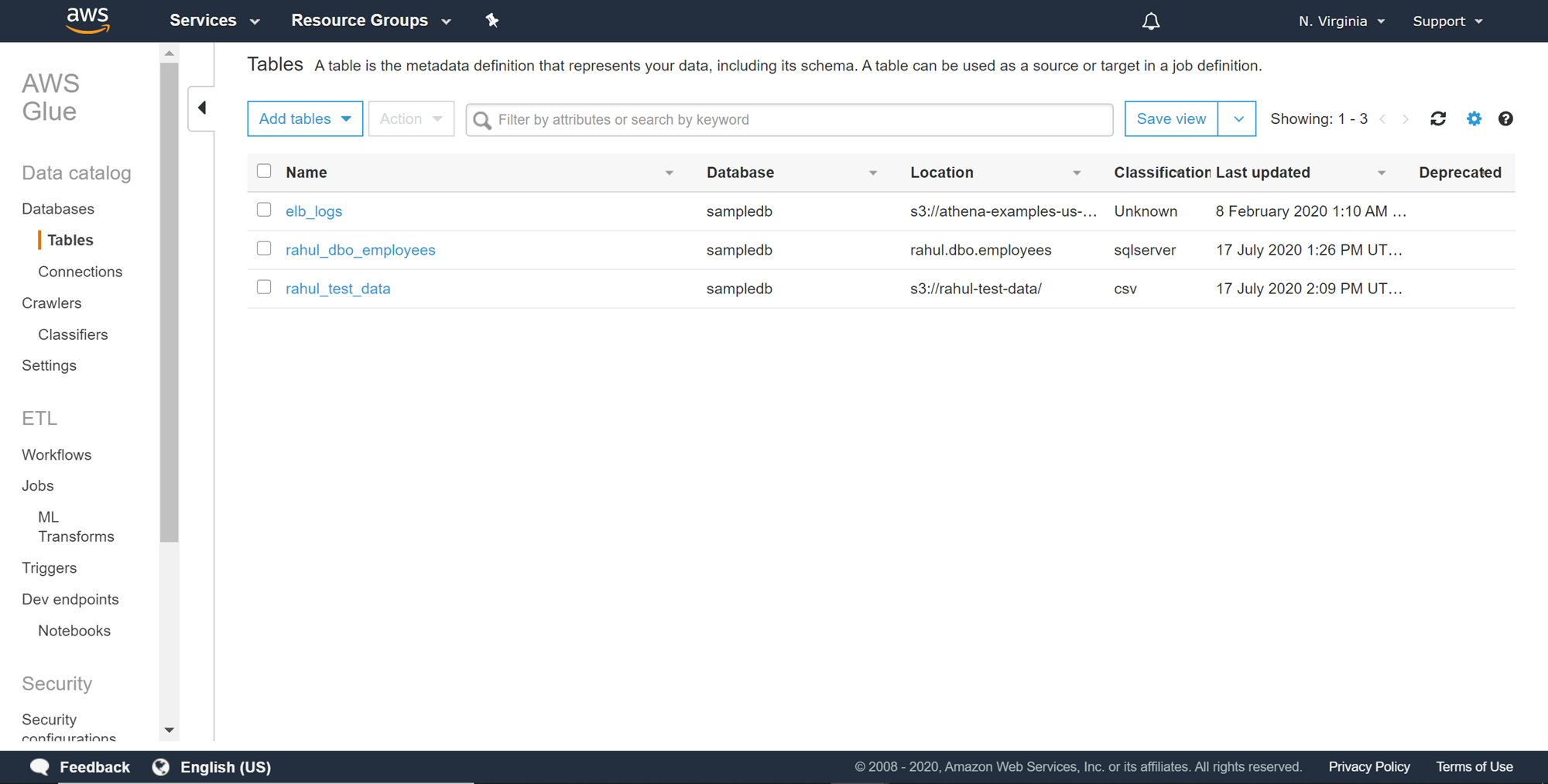
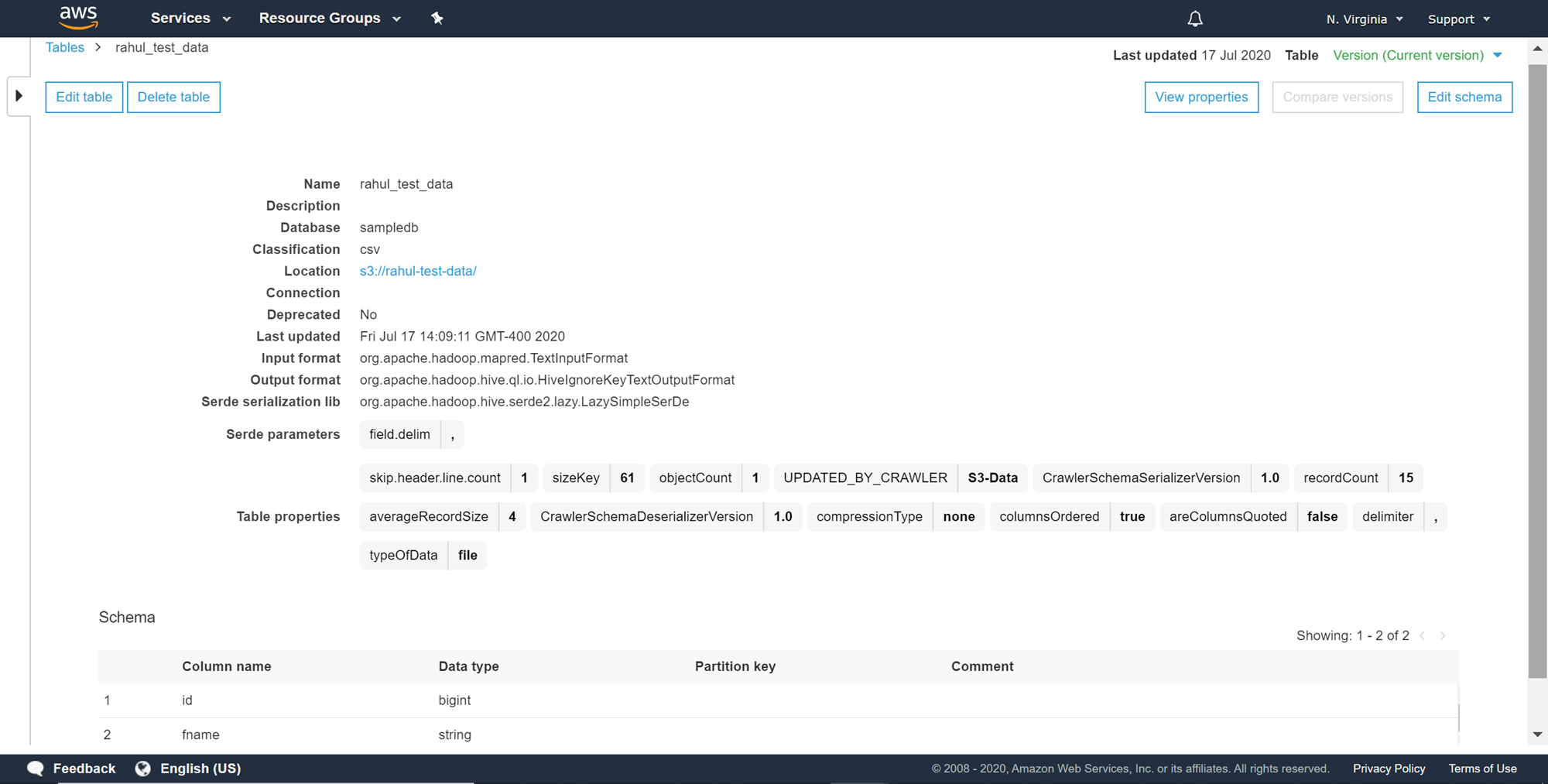
We learned how a cataloged AWS RDS SQL Server table would look in my last article, How to catalog AWS RDS SQL Server database. For reference, a cataloged AWS S3 bucket-based table, for a file having a schema like the CSV that we created earlier, would look as shown below.
我们在上一篇文章如何对AWS RDS SQL Server数据库进行分类中了解了已分类的AWS RDS SQL Server表的外观。 作为参考,对于具有类似我们之前创建的CSV之类的架构的文件,基于目录的AWS S3存储桶的外观如下所示。
开发AWS Glue ETL作业 (Developing an AWS Glue ETL Job)
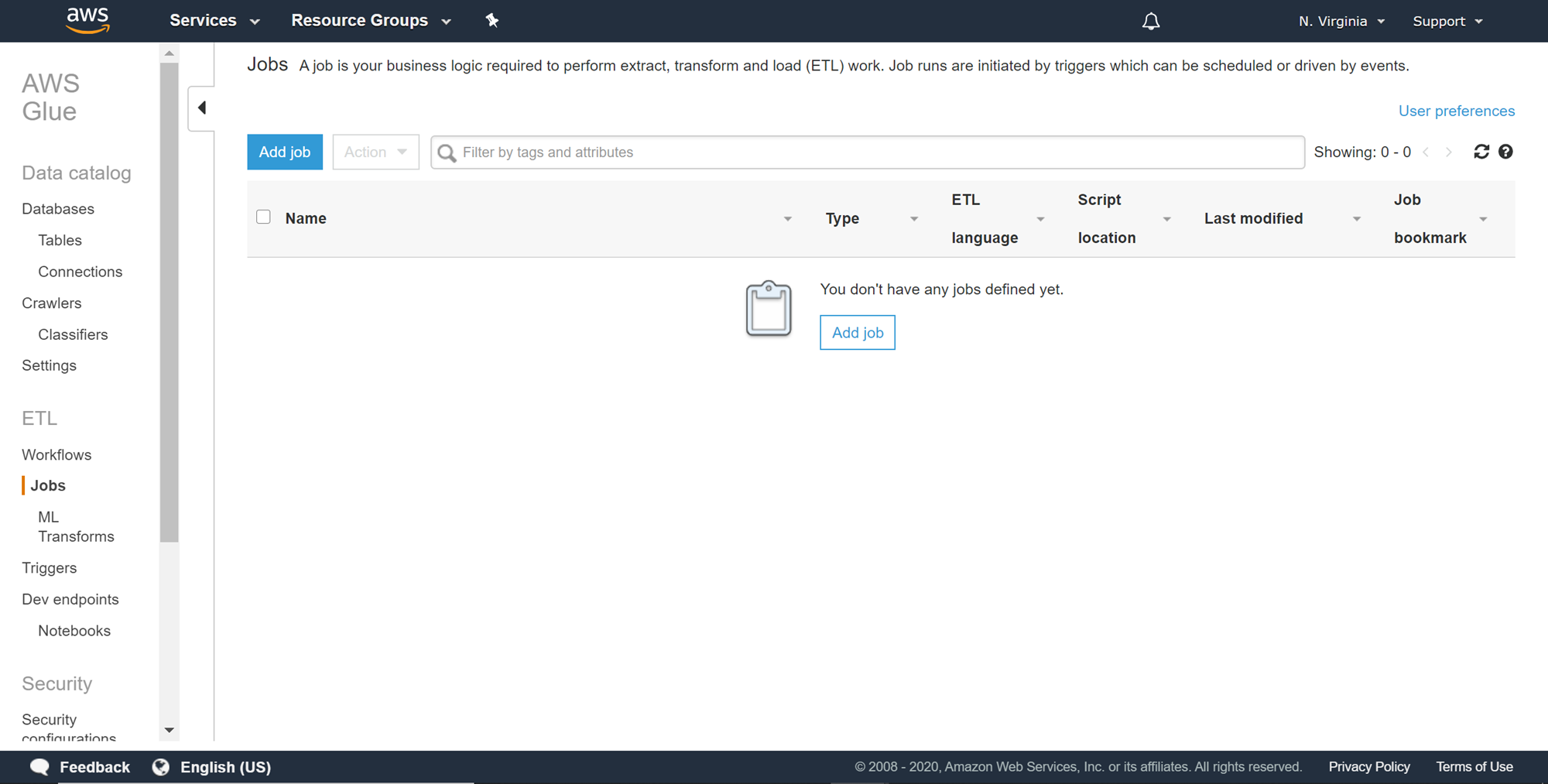
Now that the AWS Glue catalog is updated with source and destination metadata tables, now we can create the ETL job. Navigate to the ETL Jobs section from the left pane, and it would look as shown below.
现在已经使用源和目标元数据表更新了AWS Glue目录,现在我们可以创建ETL作业。 从左窗格导航到“ ETL作业”部分,其外观如下图所示。
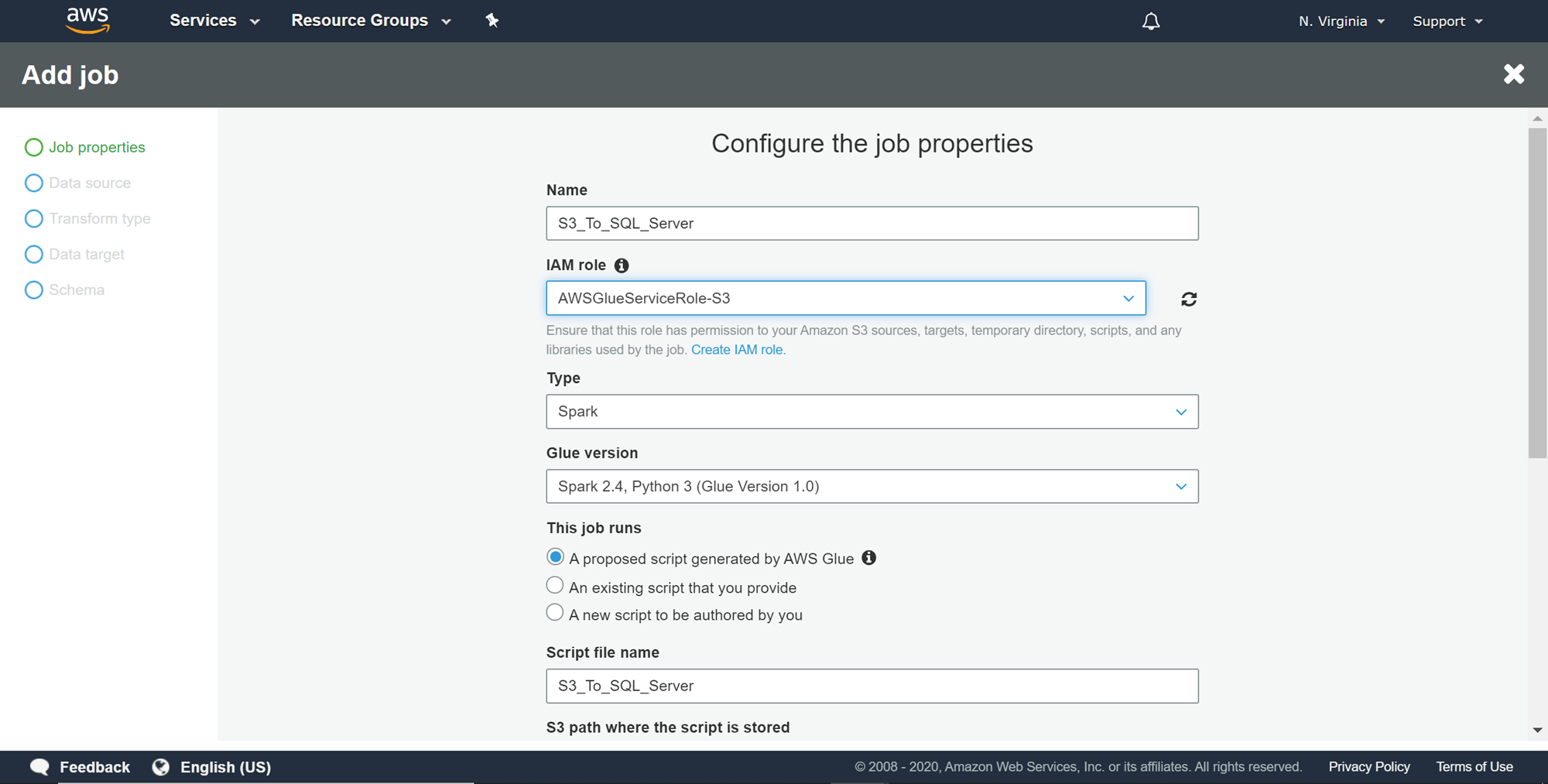
Click on the Add job button to start creating a new ETL job. A new wizard would start, and the first step would look as shown below. Provide a relevant name and an IAM role (with privileges to read and write on the metadata catalog as well as AWS S3) for the job. The type of job provides options to either create a Spark-based job or a Python shell job. Spark-based jobs are more feature-rich and provide more options to perform sophisticated ETL programming compared to Python shell jobs, and also support all the AWS Glue features with Python-based jobs do not. After we are done specifying all the options, the output of this job would be a script that is generated by AWS Glue. Alternatively, you can configure this job to execute a script that you already have in place or you wish to author. We are going to leave the job type and script related settings to default.
单击添加作业按钮以开始创建新的ETL作业。 一个新的向导将启动,第一步将如下所示。 为该作业提供一个相关的名称和一个IAM角色(具有在元数据目录以及AWS S3上进行读写的特权)。 作业类型提供了用于创建基于Spark的作业或Python Shell作业的选项。 与Python shell作业相比,基于Spark的作业具有更多功能,并提供了更多选项来执行复杂的ETL编程,并且还支持所有基于Python作业不支持的AWS Glue功能。 指定完所有选项后,此作业的输出将是由AWS Glue生成的脚本。 另外,您可以配置此作业以执行已经存在或希望编写的脚本。 我们将作业类型和与脚本相关的设置保留为默认设置。
Other options on this page will look as shown below. These options can be used to mainly configure any custom scripts or libraries, security, monitoring and logging, which is not required in our case for the purpose of demonstration. We can proceed with the next step.
该页面上的其他选项如下所示。 这些选项可用于主要配置任何自定义脚本或库,安全性,监视和日志记录,在本例中,出于演示目的,这不是必需的。 我们可以继续下一步。
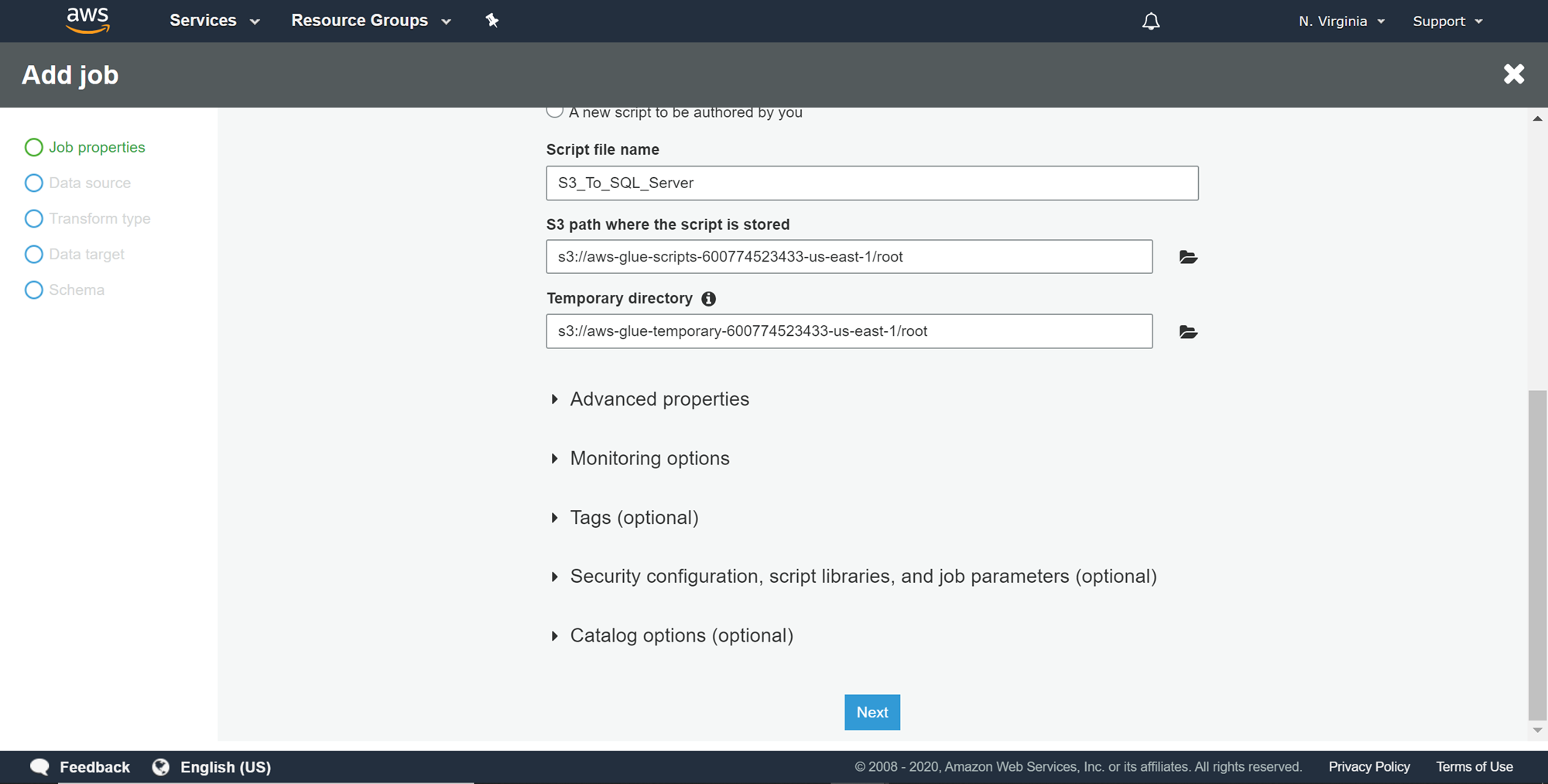
In this step, we need to select the data source, which is the table from the metadata catalog that points to the S3 bucket. Select the relevant table as shown below and click Next.
在此步骤中,我们需要选择数据源,它是元数据目录中指向S3存储桶的表。 选择相关的表格,如下所示,然后单击“ 下一步” 。
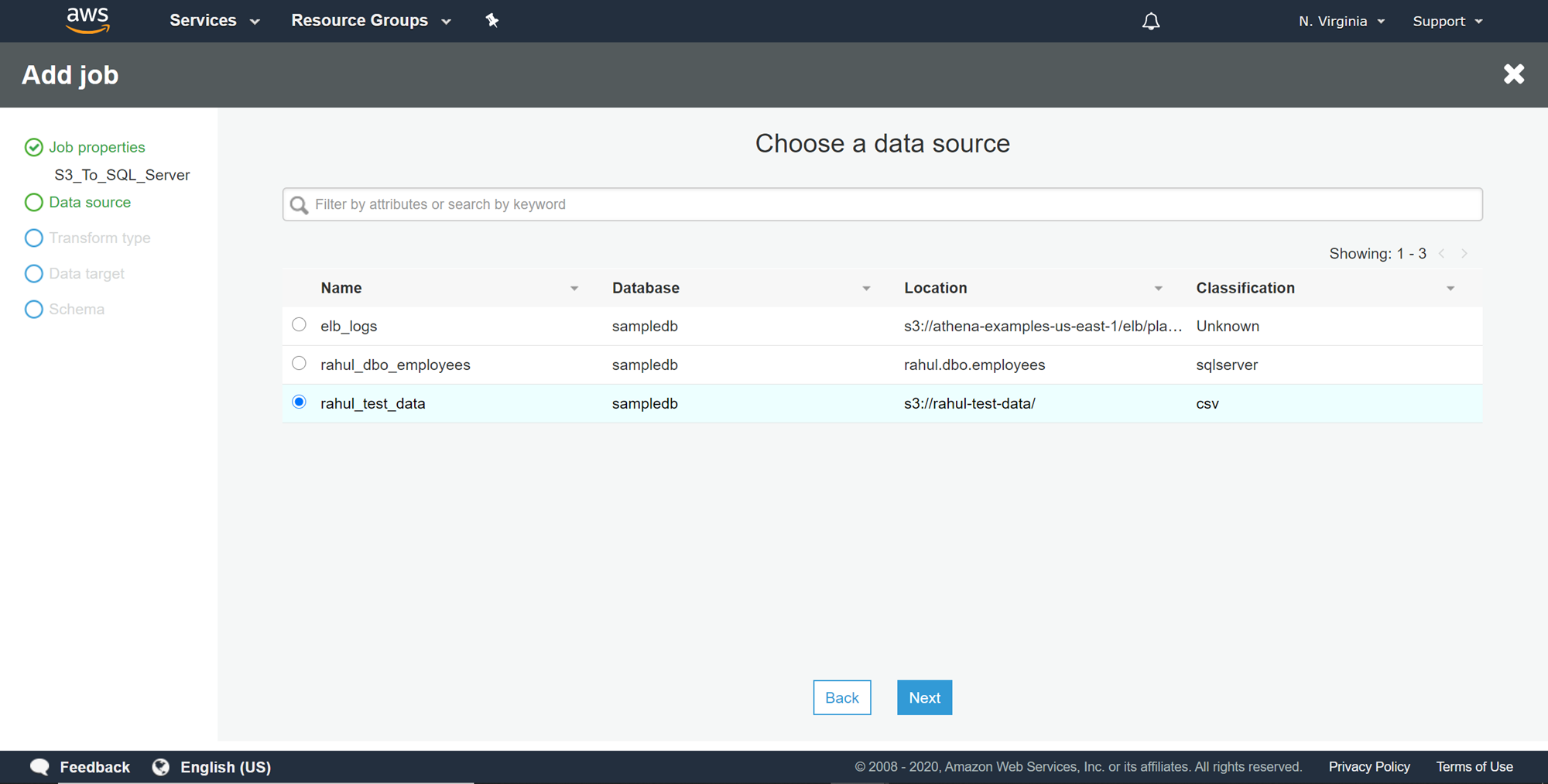
We need to select a transformation type in this step. Even can select not to make any transformation in the next step, but at this step, we need to either changing of schema or find matching records (for deduplication) as one of the transform types. Select Change schema and click Next.
我们需要在此步骤中选择一个转换类型。 甚至可以选择不进行下一步任何转换,但是在这一步中,我们需要更改架构或找到匹配的记录(用于重复数据删除)作为转换类型之一。 选择更改架构 ,然后单击下一步 。
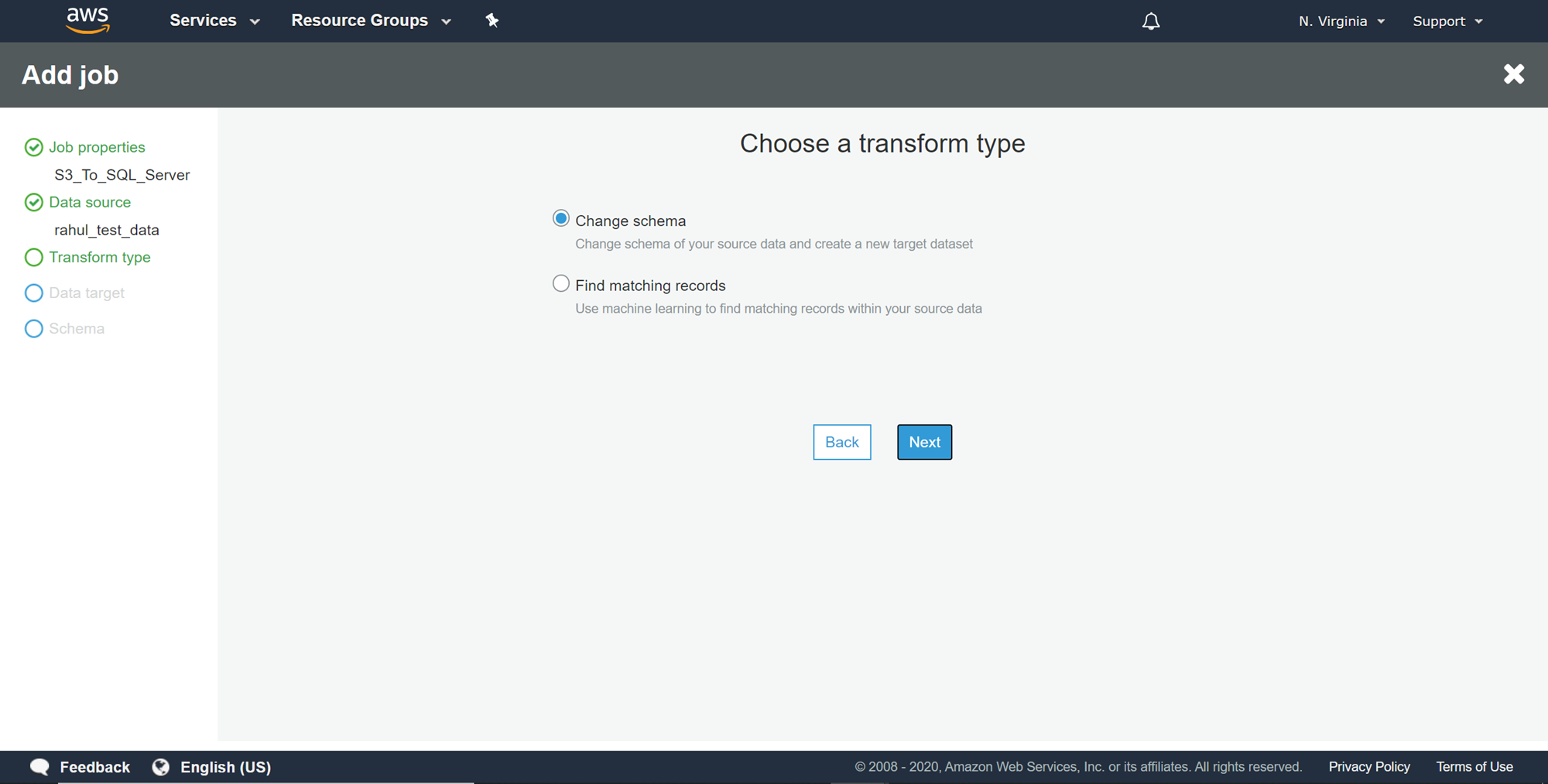
Now we need to select the destination metadata table that points to our AWS RDS SQL Server table. Select the relevant table as shown below and click Next.
现在,我们需要选择指向我们的AWS RDS SQL Server表的目标元数据表。 选择相关的表格,如下所示,然后单击“ 下一步” 。
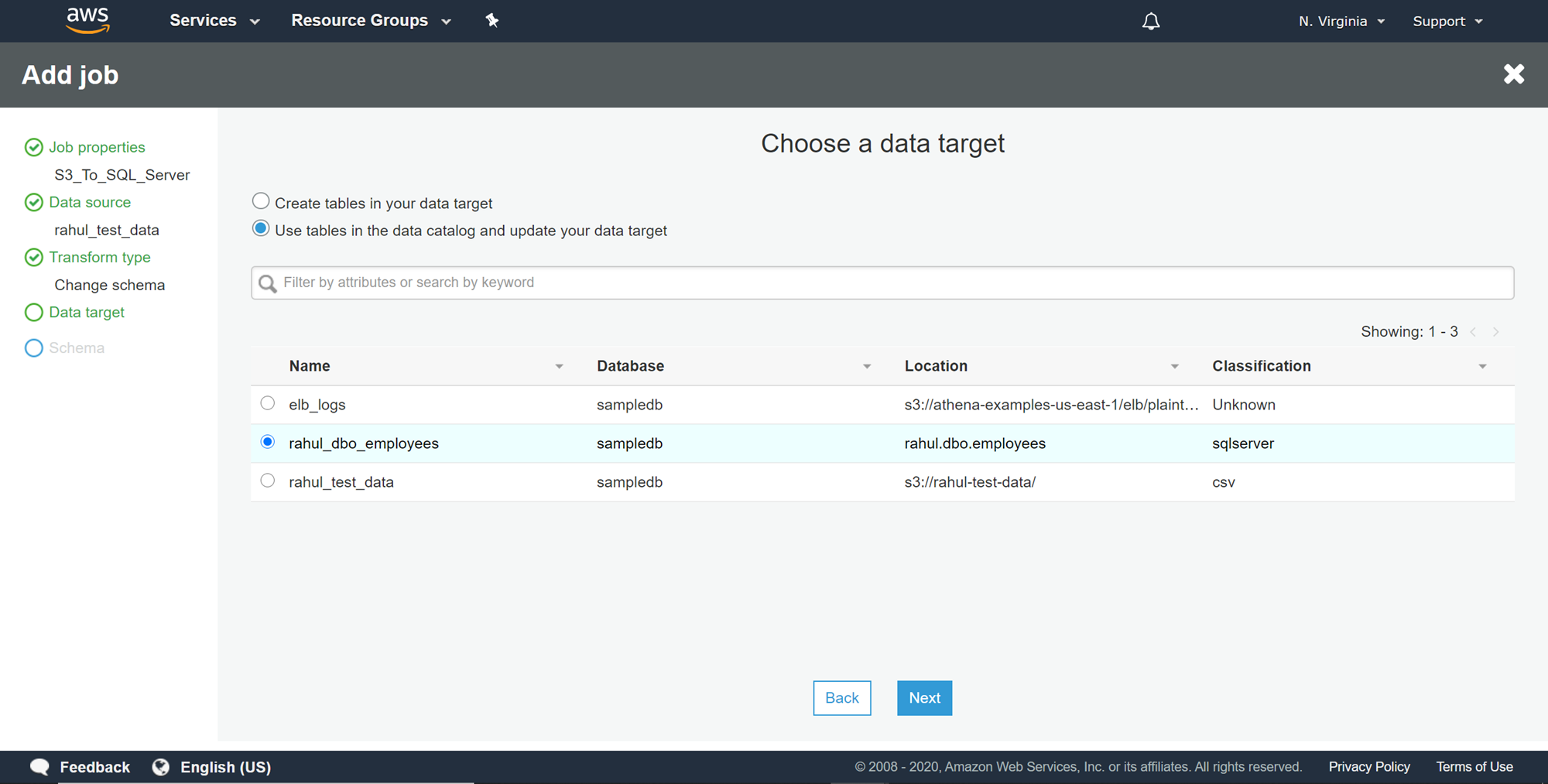
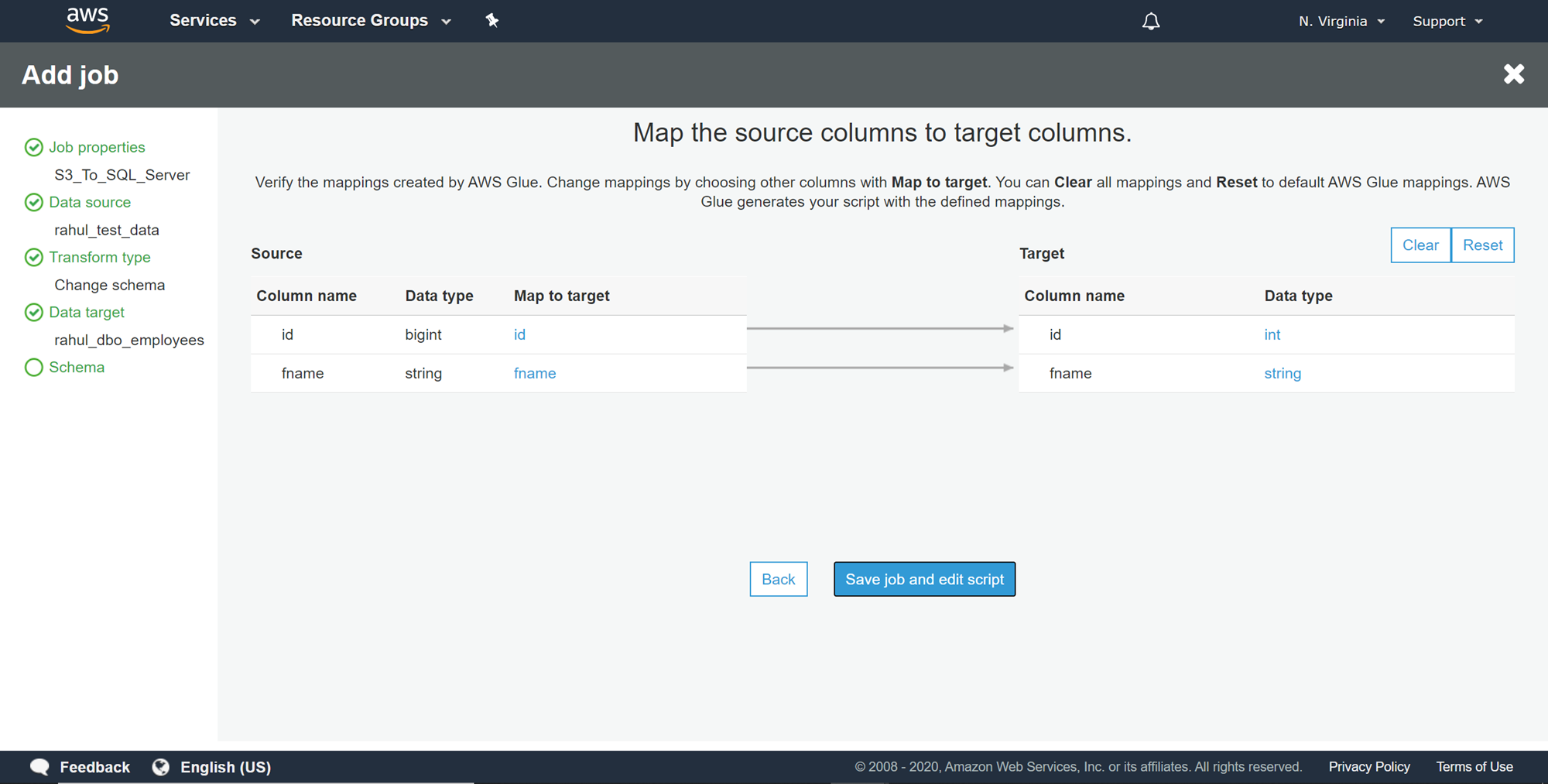
In this step, we can make the required changes to the mapping and schema if required. As we do not need to make any changes to the mapping, we can click on the Save job and edit script button.
在此步骤中,我们可以根据需要对映射和架构进行必要的更改。 由于我们不需要对映射进行任何更改,因此可以单击“ 保存作业并编辑脚本”按钮。
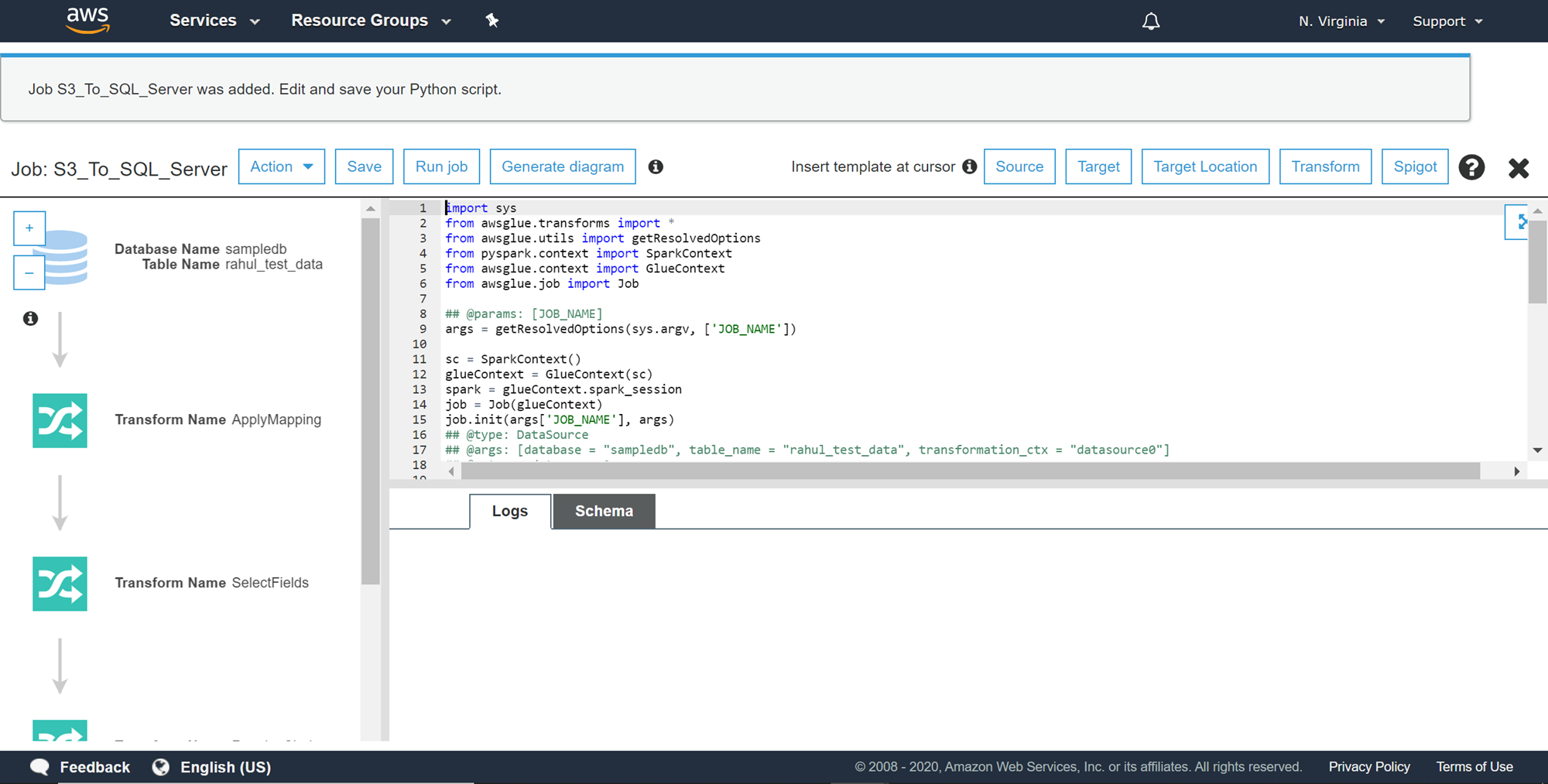
This would take us to the python script generated by this job for the ETL as per the specifications that we provided for the job. Now that our job is ready, we can click on the Run Job button to execute the ETL job.
根据我们为作业提供的规范,这将带我们进入此作业为ETL生成的python脚本。 现在我们的作业已经准备好了,我们可以单击“运行作业”按钮来执行ETL作业。
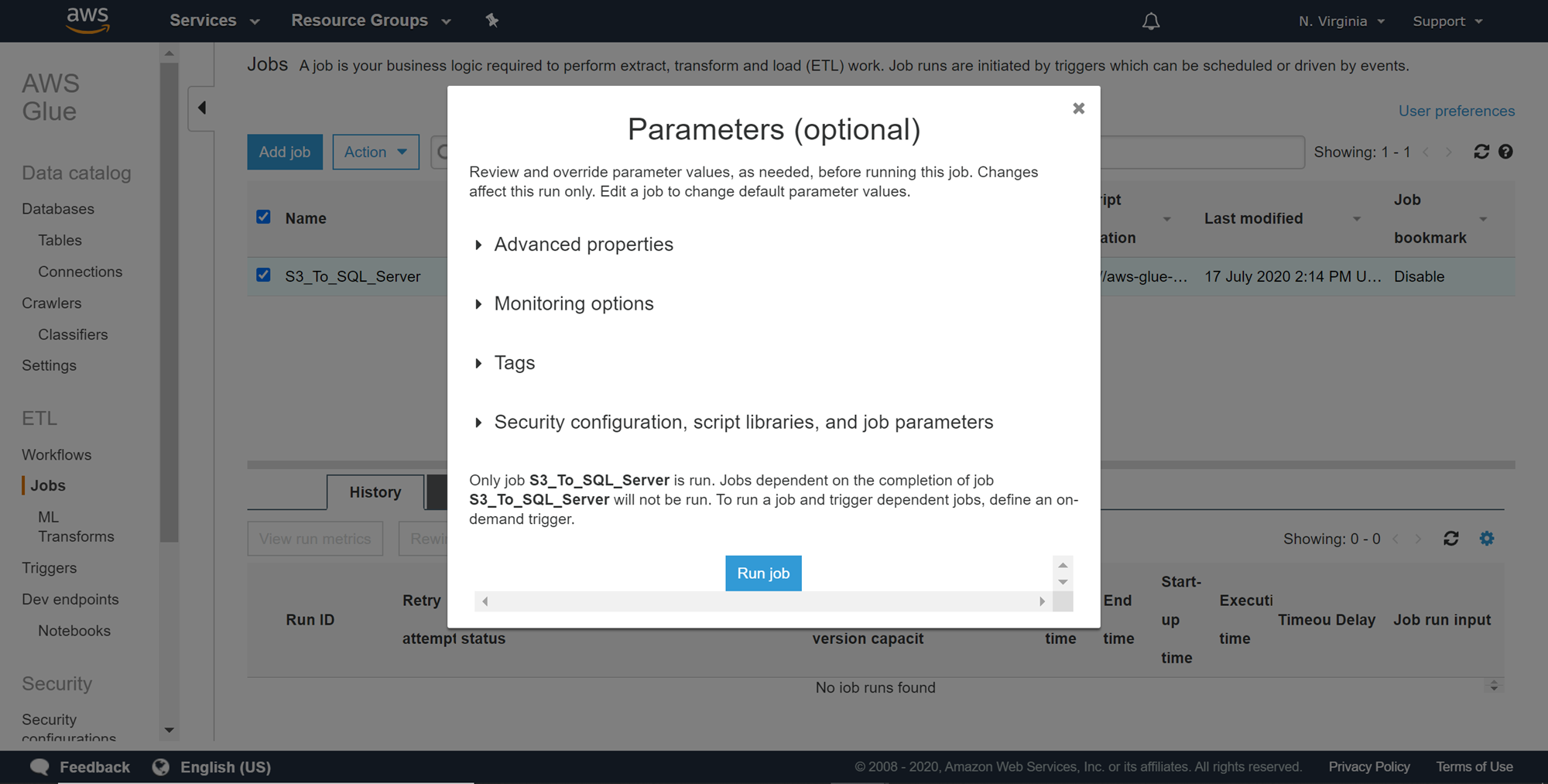
A prompt is shown before executing the job, where we can change runtime parameters if required. We do not need to change any parameters in our case, so click on the Run job button. This would start the execution of our ETL job.
在执行作业之前会显示一个提示,我们可以在需要时更改运行时参数。 在这种情况下,我们不需要更改任何参数,因此单击“运行作业”按钮。 这将开始执行我们的ETL作业。
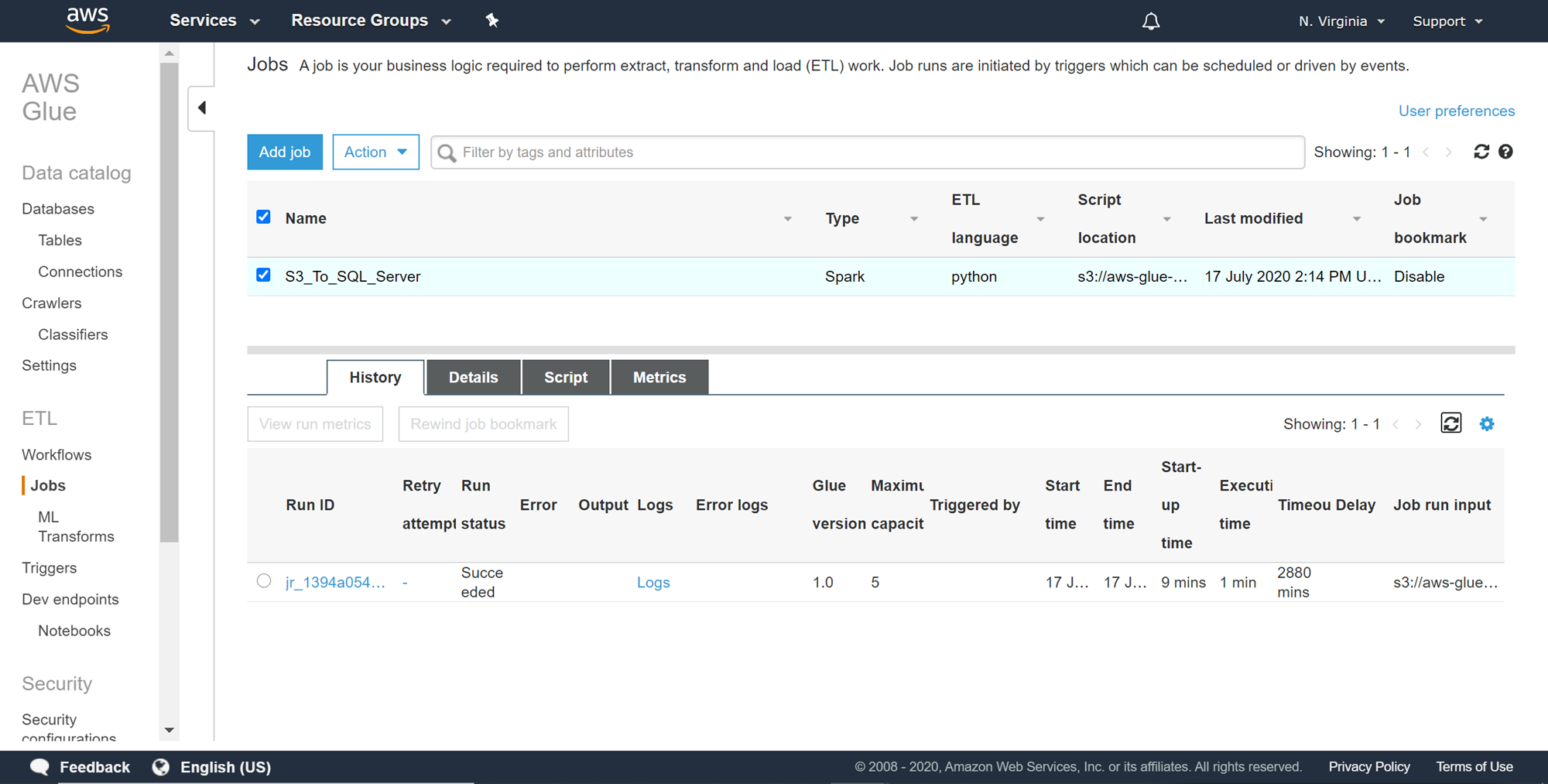
Once the job execution starts, you can select the job and it would show us the status of the job in the bottom pane as shown below. It can take a few minutes to start the job, as it warms up the spark environment in the background to execute the job. Once the job execution is complete, it would provide the details of the job execution in the bottom pane as shown below.
作业开始执行后,您可以选择该作业,它将在底部窗格中向我们显示该作业的状态,如下所示。 启动作业可能需要几分钟,因为它会在后台预热火花环境以执行作业。 作业执行完成后,它将在底部窗格中提供作业执行的详细信息,如下所示。
Now that the job has completed execution, if the job worked as expected, all the ten records that we have in our CSV file that is hosted on AWS S3, the same records should have got loaded into AWS RDS SQL Server table that we created earlier. Navigate to a query editor and query the SQL Server table. You should be able to see all those records in the table as shown below.
现在,该作业已完成执行,如果该作业按预期方式工作,那么我们在AWS S3上托管的CSV文件中拥有的所有十条记录都将被加载到我们之前创建的AWS RDS SQL Server表中。 导航到查询编辑器并查询SQL Server表。 您应该能够在表中看到所有这些记录,如下所示。
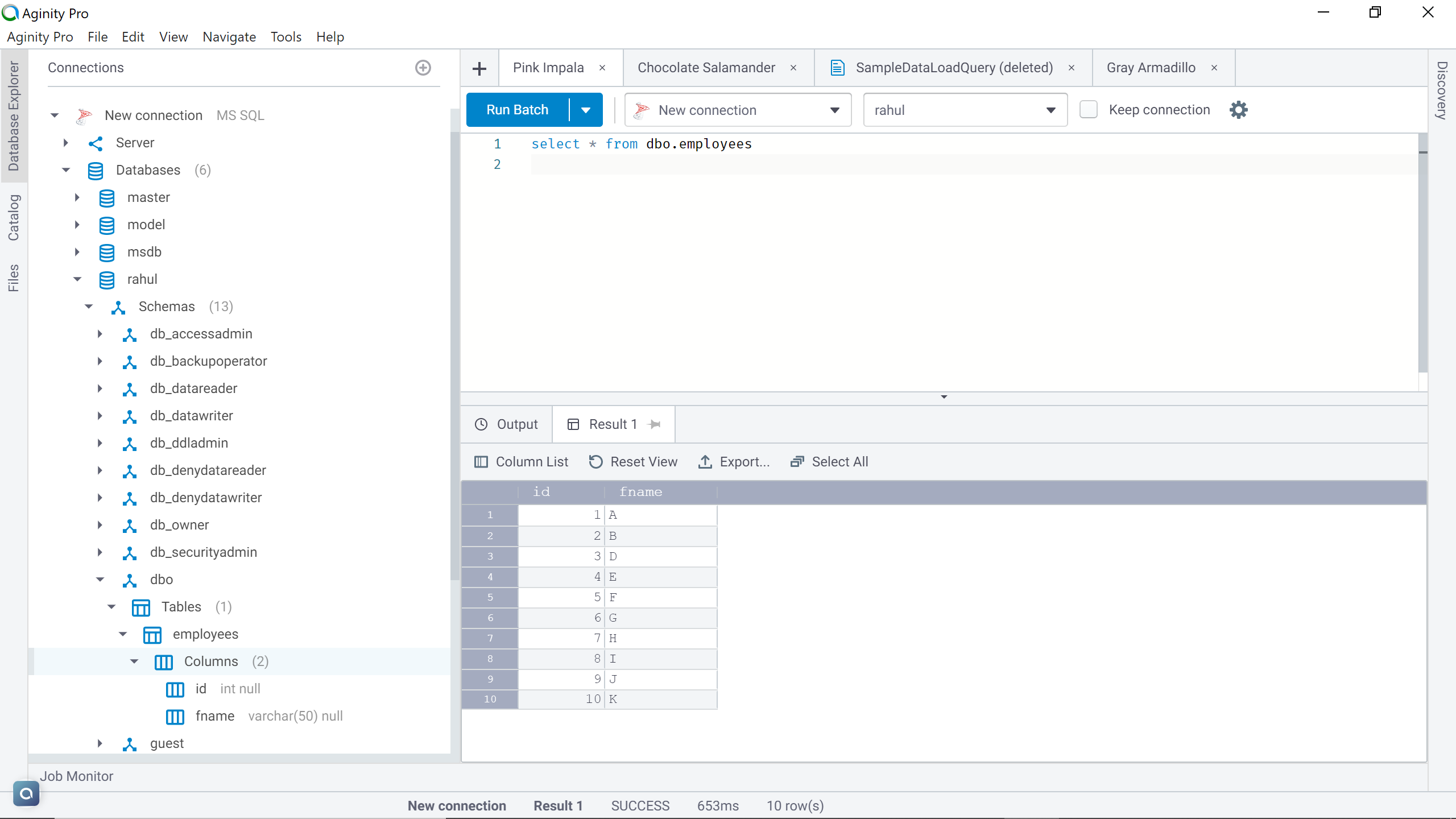
In this way, we can use AWS Glue ETL jobs to load data into Amazon RDS SQL Server database tables.
通过这种方式,我们可以使用AWS Glue ETL作业将数据加载到Amazon RDS SQL Server数据库表中。
结论 (Conclusion)
In this article, we learned how to use AWS Glue ETL jobs to extract data from file-based data sources hosted in AWS S3, and transform as well as load the same data using AWS Glue ETL jobs into the AWS RDS SQL Server database. We also learned the details of configuring the ETL job as well as pre-requisites for the job like metadata tables in the AWS Glue metadata catalog.
在本文中,我们学习了如何使用AWS Glue ETL作业从AWS S3中托管的基于文件的数据源中提取数据,以及使用AWS Glue ETL作业将相同的数据转换并加载到AWS RDS SQL Server数据库中。 我们还了解了配置ETL作业的详细信息以及该作业的先决条件,例如AWS Glue元数据目录中的元数据表。
翻译自: https://www.sqlshack.com/load-data-from-aws-s3-to-aws-rds-sql-server-databases-using-aws-glue/
aws rds恢复数据库
aws rds恢复数据库_使用AWS Glue将数据从AWS S3加载到AWS RDS SQL Server数据库相关推荐
- 利用花生壳实现B电脑远程连接或程序访问A电脑上的数据库,并将图片音频从B电脑存储至A电脑上的SQL Server数据库并读出
想必大家都有这样的疑问,A电脑上安装了SQL Server并创建了数据库,B电脑上也安装有SQL Server,现在需要用B电脑上的SQL Server连接A电脑上SQL Server里的数据库并进行 ...
- 5、SQL Server数据库、T-SQL
SQL Server数据库基础 一.安装SQL Server数据库 setup.exe->安装->全新SQL Server独立安装或向现有安装添加功能->输入序列号->下一步- ...
- ExcelToDatabase:批量导入Excel文件到MySQL/Oracle/SQL Server数据库的自动化工具
ExcelToDatabase:批量导入Excel到MySQL/Oracle/SQL Server数据库的自动化工具 简介 ExcelToDatabase 是一个可以批量导入excel到mysql/o ...
- SQL Server数据库查询速度慢的原因和解决方法
SQL Server数据库查询速度慢的原因和解决方法 参考文章: (1)SQL Server数据库查询速度慢的原因和解决方法 (2)https://www.cnblogs.com/MyChange/p ...
- 在ASP.NET中将图片存储到Sql Server数据库中
在ASP.NET中将图片存储到Sql Server数据库中 http://hi.baidu.com/rayshow/blog/item/360e8ff9662c8b5a252df268.html 索引 ...
- Visual Studio listView控件绑定SQL Server数据库并动态显示数据,调整列宽
在Visual Studio中,可以用listView控件直接从SQL Server数据库中动态读取数据,并自动调整列宽.本文讲解如何通过ADO.net连接SQL Server数据库,并用SqlDat ...
- 查看sql server 数据库连接数
连到master这个数据库 写如下语句 select * from sysprocesses where dbid in (select dbid from sysdatabases where na ...
- 如何使用SQL Server数据库实验助手(DEA)工具
介绍 (Introduction) This is my second article about Database Experimentation Assistant (DEA). Please r ...
- 检测java是否连接到SQL server数据库 + SQL server数据库内置账户sa无法登录
检测java是否连接到SQL server数据库 + SQL server数据库内置账户sa无法登录 SQL 检测java是否连接到SQL server数据库 SQL server数据库内置账户SA登 ...
最新文章
- NYOJ541 最强DE 战斗力(第五届省赛试题)
- java中不用impore导入的_java import机制(不用IDE)
- sql 写query_为什么需要动态SQL
- android开发中EditText自动获取焦点时隐藏hint的代码
- 相信自己, 许自己一个未来
- python打印字符串所在行_python打印文件中某个字符串的前几行
- 小程序 tab 切换点击无效
- 数字基础设施可视化管理,任重而道远
- 怎么把html导入xmind,XMind思维导图怎么导入图标?
- NFT市场可二开开源系统
- java facade dao_nsg-DAO
- Android仿Qzone底部导航栏加号弹出菜单
- Android rom开发:mtk android9.0 开放预置app权限
- 为什么正态分布如此常见?
- 【MySQL】Schema与数据类型优化
- c语言中双星号,C中的双星号和`malloc`
- Facebook 新品 Lexical, 比 Quill 更好用的 Editor ?
- CSS 文字内容底部对齐
- autocad2016安装教程_CAD插件快速计算面积安装教程及资源链接
- 【资料总结系列】机器人仿真——webots资料总结