使用PowerShell和T-SQL在多服务器环境中规划SQL Server备份和还原策略
介绍 (Introduction)
Database availability is critical to every enterprise and conversely, unavailability directly can create a severe negative impact to the business in today’s world. As database administrators, it is important that we ensure we take all possible steps to minimize data loss. While it is naïve to think that our databases are invincible because of all such precautions, we can always aim to bring the databases back into operation as quickly as possible by meeting the RPO and RTO. This way, the business is unaffected, and we also meet our SLAs.
数据库可用性对每个企业都至关重要,相反,不可用性直接会给当今的企业带来严重的负面影响。 作为数据库管理员,重要的是我们确保采取所有可能的步骤来最大程度地减少数据丢失。 尽管由于所有这些预防措施而认为我们的数据库是不可战胜的,但我们始终可以通过满足RPO和RTO的目标,尽快使数据库恢复运行。 这样,业务不会受到影响,并且我们还满足我们的SLA。
Apart from good knowledge of the system, it is important we have a well-defined data and tested backup-and-restore strategy. Testing the backup-and-restore procedure to ensure quick recovery with minimal administrative overhead is one means towards that end. While advanced techniques such as AlwaysOn and Mirroring help ensure higher availability, disaster recovery is all about well-defined and tested backup and restoration methods.
除了对系统有充分的了解外,重要的是我们要有一个定义良好的数据和经过测试的备份和还原策略。 为此目的,测试备份和还原过程以确保以最少的管理开销进行快速恢复是一种方法。 尽管AlwaysOn和Mirroring等先进技术有助于确保更高的可用性,但灾难恢复只涉及定义良好且经过测试的备份和还原方法。
When planning for disaster recovery techniques, here are some points about volatility that we need to keep in mind:
在规划灾难恢复技术时,需要牢记以下有关波动性的几点:
- How frequently is the table updated? 该表多久更新一次?
- Are your databases transactions highly frequent? If so, one must perform more frequent log backup than a full backup. 您的数据库交易频繁吗? 如果是这样,则必须执行比完全备份更频繁的日志备份。
- How often does the database structure change? 数据库结构多久更改一次?
- How often does the database configuration change? 数据库配置多久更改一次?
- What are the data loading patterns and what is the nature of the data? 数据加载模式是什么,数据的性质是什么?
We must plan our backup-and-restore strategy keeping these aspects in mind. And to ensure the strategy is close to airtight, we need to try out all possible combinations of backup and restoration, observe the nuances in the results, and tune the strategy accordingly. So, we must:
我们必须牢记这些方面来计划我们的备份和还原策略。 为了确保该策略几乎是密不透风的,我们需要尝试备份和还原的所有可能组合,观察结果中的细微差别,并相应地调整策略。 因此,我们必须:
- Consider the size of the database, the usage patterns, nature of the content, and so on. 考虑数据库的大小,使用模式,内容的性质等等。
- Keep in mind any of the configuration constraints, such as hardware or backup media. 请记住任何配置限制,例如硬件或备份媒体。
In this article, we touch base on the aforementioned points, and decide on the requirements as well, based on attributes such as the database sizes, their internal details, and the frequency of changes. Let us now go ahead and look at the considerations that are important to build a backup strategy.
在本文中,我们基于上述几点进行探讨,并根据数据库大小,内部细节和更改频率等属性来确定需求。 现在,让我们继续研究构建备份策略的重要考虑因素。
By the end of the article, we would be equipped with a couple of scripts that would give us all vital information in a nice tabular format, that would help us with planning and decision-making when it comes to backups and their restoration.
到本文结尾,我们将配备一些脚本,这些脚本将以很好的表格格式向我们提供所有重要信息,这将有助于我们在备份和还原时进行计划和决策。
背景 (Background)
Take a look at the business requirements, as each database may have different requirements based on the application it serves. The requirements may be based on:
看一下业务需求,因为每个数据库根据其服务的应用程序可能有不同的需求。 这些要求可能基于:
- How frequently does the application access the database? Is there a specific off-peak period when the backups can be scheduled? 应用程序多久访问一次数据库? 可以安排备份的特定非高峰时段吗?
- How frequently does the data get changed? If the changes are too frequent, you may want to schedule incremental backups in between full backups. Differential backups also reduce the restoration time. 数据多久更改一次? 如果更改太频繁,则可能要在完全备份之间安排增量备份。 差异备份还减少了恢复时间。
- If only a small part of a large database changes frequently, partial and/or file backups can be used. 如果大型数据库中只有一小部分频繁更改,则可以使用部分和/或文件备份。
- Estimate the size of a full backup. Usually, the backup is smaller than the database itself, because it does not record the unused space in a database. 估计完整备份的大小。 通常,备份比数据库本身要小,因为它不会在数据库中记录未使用的空间。
This post demonstrates one of the ways to gather an inventory of database backup information. The output of the script includes various columns that show the internals of a database, backup size, and gives the latest completion statuses and the corresponding backup sizes. Though the output is derived from the msdb database, having the data consolidated at one place gives us better control and provides us with greater visibility into the database process. A clear understanding of these parameters is a good way to forecast storage requirements. We can schedule a job to pull the data to a central repository and then develop a report on capacity planning and forecasting on a broader spectrum of database backup. That way, we’d have an insight into the sizing of every backup type, such as Full, Differential and Log. With such information, we can easily decide on the type of backup required at a very granular level, i.e., at the database level.
Going this way, we can optimize our investments in storage and backup. It helps us decide on alternatives if needed. The base for every decision is accurate data. The accuracy of information gives us a baseline to decide the viable options to back up the SQL databases. The idea behind this implementation is to get the useful data using a technique native to SQL, and have brainstorming sessions based on that, to identify the best design and solution for the backup problem.
这篇文章演示了一种收集数据库备份信息清单的方法。 脚本的输出包括各个列,这些列显示数据库的内部信息,备份大小,并提供最新的完成状态和相应的备份大小。 尽管输出是从msdb数据库派生的,但是将数据整合到一个位置可以使我们更好地控制,并使我们对数据库过程具有更大的可视性。 清楚了解这些参数是预测存储需求的好方法。 我们可以安排工作以将数据提取到中央存储库,然后针对更广泛的数据库备份范围制定容量规划和预测报告。 这样,我们就可以洞悉每种备份类型(例如完全备份,差异备份和日志备份)的大小。 有了这些信息,我们可以轻松地在非常细微的级别(即数据库级别)上决定所需的备份类型。
通过这种方式,我们可以优化在存储和备份方面的投资。 如果需要,它可以帮助我们确定替代方案。 每个决定的基础都是准确的数据。 信息的准确性为我们提供了一个基准来确定备份SQL数据库的可行选项。 此实现背后的想法是使用SQL固有的技术获取有用的数据,并在此基础上进行集思广益的会议,以确定备份问题的最佳设计和解决方案。
入门 (Getting started)
There are many ways to gather data in a central server repository such as using T-SQL and PowerShell. In this section, I’m going to discuss the data gathering tasks using PowerShell cmdlets.
有很多方法可以在中央服务器存储库中收集数据,例如使用T-SQL和PowerShell。 在本节中,我将讨论使用PowerShell cmdlet进行数据收集的任务。
The pre-requisites are
前提条件是
- Require SSMS version 16.4.1 需要SSMS版本16.4.1
- SQL Server PowerShell module SQL Server PowerShell模块
New cmdlets have been introduced with the SQL Server module, which is going to replace SQLPS, by retaining the old functionality of SQLPS with added set of rich libraries. It is safe to remove the SQLPS and load the SQL Server module.
SQL Server模块中引入了新的cmdlet,它将通过添加一组丰富的库来保留SQLPS的旧功能,从而替换SQLPS。 删除SQLPS并加载SQL Server模块是安全的。
You can remove the SQLPS using below command:
您可以使用以下命令删除SQLPS:
Remove-Module SQLPS
删除模块SQLPS
Load the SQL Server Module using the below command:
使用以下命令加载SQL Server模块:
Import-Module SqlServer
导入模块SqlServer
The new cmdlets, Read-SQLTableData and Write-SqlTableData are introduced to load the data as SQLTABLE
引入了新的cmdlet Read-SQLTableData和Write-SqlTableData来将数据加载为SQLTABLE

With these cmdlets, a query can be executed and the results can be stored in a very simple way. It’s like storing everything as a table.
使用这些cmdlet,可以执行查询,并可以以非常简单的方式存储结果。 就像将所有内容存储为表格一样。
Invoke-Sqlcmd -Query "
SELECT name AS object_name ,SCHEMA_NAME(schema_id) AS schema_name,type_desc,create_date,modify_date
FROM sys.objects
WHERE modify_date > GETDATE() - 10
ORDER BY modify_date;" -OutputAs DataTables |
Write-SqlTableData -ServerInstance hqdbst11 -DatabaseName SQLShackDemo -
SchemaName dbo -TableName SQLSchemaChangeCapture -Force- In this case we are writing T-SQL data into the table using the Write-SqlTableData cmdlet 在这种情况下,我们使用Write-SqlTableData cmdlet将T-SQL数据写入表中
- Passthru – It just inserts the records into the destination table Passthru –仅将记录插入目标表中
- Force – Creates an object if the object is missing in the destination 强制–如果目标中缺少对象,则创建一个对象
- Shows backup size, previous backup size, and the change between the two 显示备份大小,以前的备份大小以及两者之间的变化
- Previous backup size based on the type and database根据类型和数据库的先前备份大小
- with size changes from previous backup 更改了先前备份的大小
- row per database per backup type 每个备份类型每个数据库的行
- One row per database, containing details about the latest backup 每个数据库一行,其中包含有关最新备份的详细信息
- Each row includes individual columns for the last time each backup type was completed 每行包括最后一次完成每种备份类型的各个列
- Each row includes backup sizes, types, previous sizes, and the difference between the two 每行包括备份大小,类型,以前的大小以及两者之间的差异
- The output shows the nature of the backup and its corresponding sizes. This gives a clear indication of size estimates required for future growth which is in line with the retention period objective. 输出显示了备份的性质及其相应的大小。 这清楚地表明了未来增长所需的规模估算,这符合保留期目标。
Let’s run the T-SQL to see the output yielding the desired data; the T-SQL is available at Appendix A. The output of the T-SQL is given below.
让我们运行T-SQL来查看产生所需数据的输出。 T-SQL在附录A中可用。 T-SQL的输出如下。
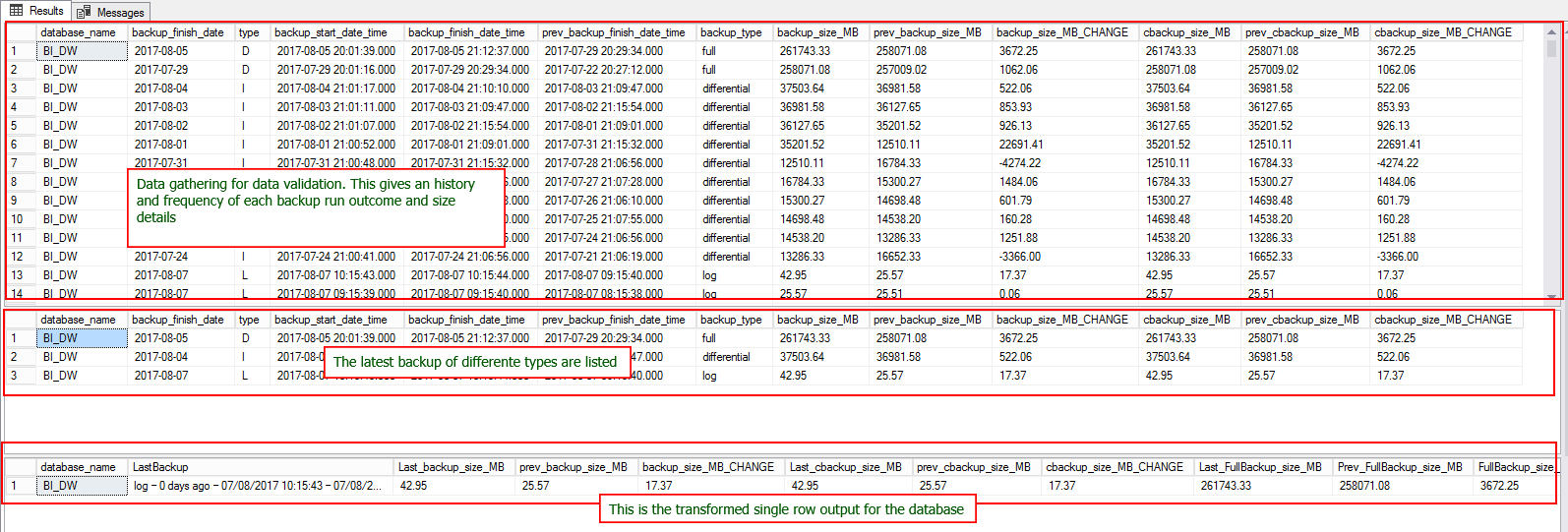
Let us now try to get the org-level information that would help us with planning. We’re going to use another T-SQL script, coupled with PowerShell. The PowerShell script is available at Appendix B.
现在,让我们尝试获取可以帮助我们进行计划的组织级信息。 我们将使用另一个T-SQL脚本以及PowerShell。 PowerShell脚本位于附录B中 。
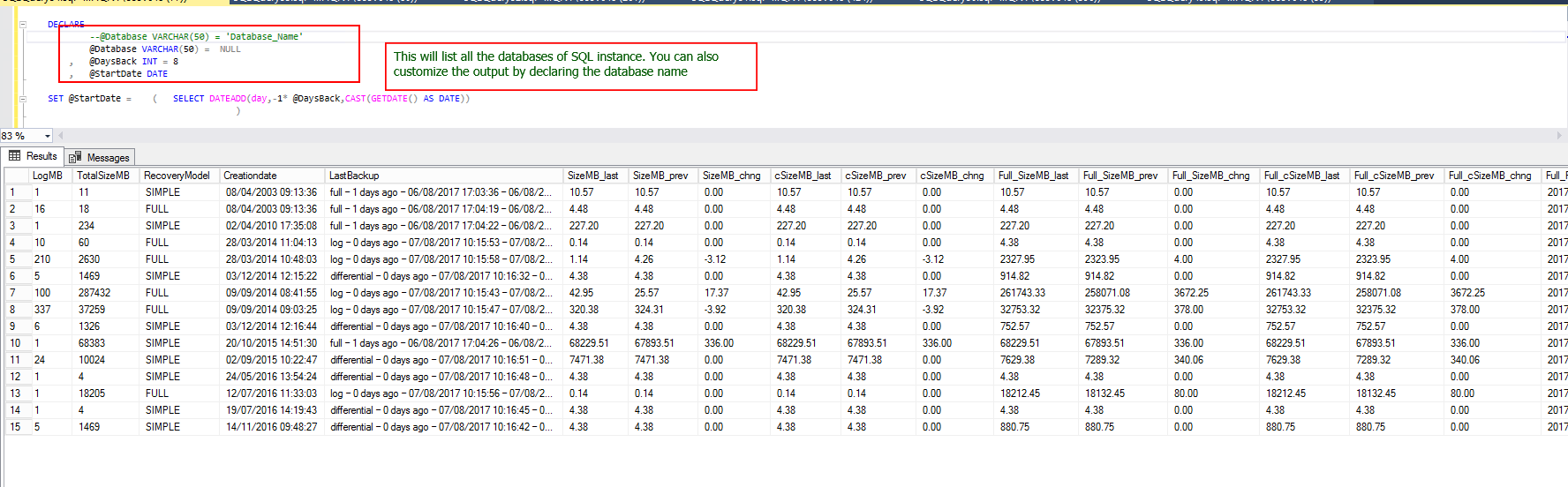
The PowerShell output window shows the data in a simple manner. With very few lines of code, the data is pulled and stored in a central repository (SqlShackDemo, in the BackupInfo table).
PowerShell输出窗口以简单的方式显示数据。 只需很少的代码行,就可以将数据提取并存储在中央存储库(SqlShackDemo,位于BackupInfo表中)中。
The T-SQL code is shown in gray. It’s just those few lines that do all the magic.
T-SQL代码以灰色显示。 只有这几行才能发挥全部魔力。
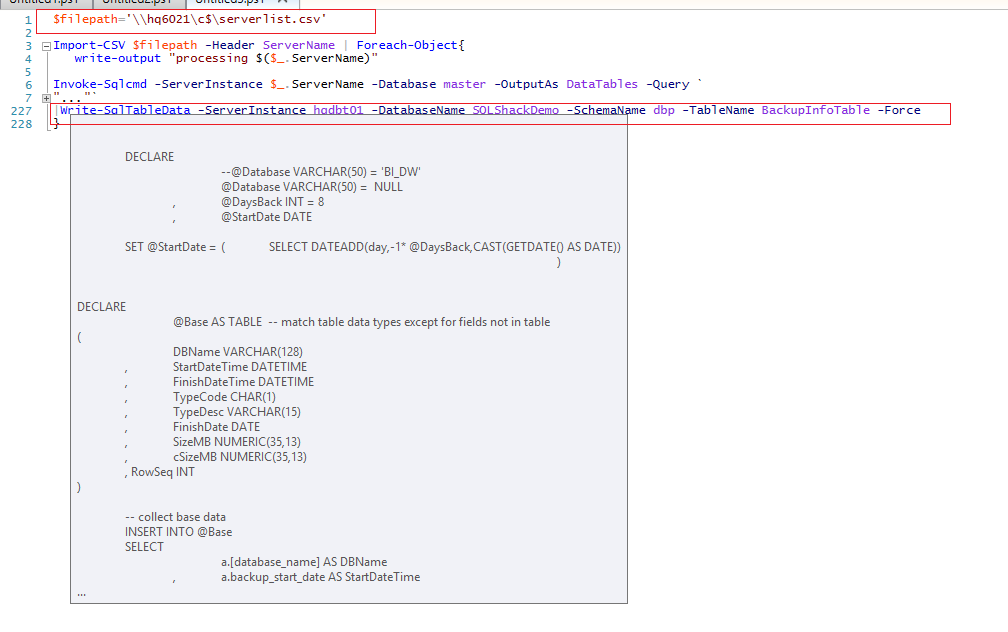
摘要 (Summary)
As administrators, we should understand the business impact that any amount of downtime causes. Business impact is measured based on the cost of the downtime and the loss of data, against the cost of reducing the downtime and minimizing data loss.
作为管理员,我们应该了解停机时间造成的业务影响。 业务影响的衡量依据是停机时间和数据丢失的成本,而不是减少停机时间和最大程度地减少数据丢失的成本。
One of the ways of cost optimization is proper backup and restoration. To optimize costs, decision-making is required, and for that, data is required. We fetch the necessary data, and store it in a centralized repository, which is a great place to understand how the system is functioning. This data also helps us generate projections, pertaining to capacity planning and forecasting in terms of database backup.
成本优化的方法之一是适当的备份和还原。 为了优化成本,需要决策,为此,需要数据。 我们获取必要的数据,并将其存储在集中式存储库中,这是了解系统运行方式的好地方。 这些数据还帮助我们生成有关容量备份和数据库备份方面的预测的预测。
Having a good understanding of the data and various test procedures for backup will help an administrator prevent various forms of failure by helping him maintain a low MTTR (Mean-Time-To-Recover) and MTBF (Mean-Time-Between-Failures).
充分了解数据和备份的各种测试过程,将有助于管理员维持较低的MTTR(平均恢复时间)和MTBF(平均间隔时间),从而帮助防止各种形式的故障。
Also, the use of the SQL Server PowerShell module along with the new cmdlets has made our life a lot easier, in that the PowerShell script output can be stored as Stables, with minimal efforts. The SQL Server module replaces the SQLPS—the old functionality still exists, but has been merged with a bunch of new functionalities.
此外,将SQL Server PowerShell模块与新的cmdlet一起使用使我们的工作变得更加轻松,因为只需花费很少的精力即可将PowerShell脚本输出存储为Stable。 SQL Server模块取代了SQLPS,旧功能仍然存在,但已与许多新功能合并。
The implementation discussed in this post gives us an ample amount of data that helps decide a good backup strategy and planning methodology, that meets our business needs.
这篇文章中讨论的实现为我们提供了大量数据,这些数据可帮助您确定满足我们业务需求的良好备份策略和规划方法。
参考资料 (References)
- Nearly everything has changed for SQL Server PowerShell 对于SQL Server PowerShell,几乎一切都已更改
- backupset (Transact-SQL) 备份集(Transact-SQL)
- Introduction to Backup and Restore Strategies in SQL Server SQL Server中的备份和还原策略简介
附录(A) (Appendix (A))
DECLARE@Database VARCHAR(50) = 'BI_DW'--@Database VARCHAR(50) = NULL-- collect base dataSELECTa.[database_name], a.backup_set_id, a.backup_start_date AS backup_start_date_time, a.backup_finish_date AS backup_finish_date_time, a.[type], CASE a.[type]WHEN 'D' THEN 'full'WHEN 'L' THEN 'log'WHEN 'I' THEN 'differential'ELSE 'other'END AS backup_type, CASE a.[type]WHEN 'D' THEN 'Weekly'WHEN 'L' THEN 'Hourly'WHEN 'I' THEN 'Daily'ELSE 'other'END AS backup_freq_def, CAST(a.backup_finish_date AS DATE) AS backup_finish_date, a.backup_size/1024/1024.00 AS backup_size_MB, a.compressed_backup_size/1024/1024.00 AS cbackup_size_MB --, ROW_NUMBER()OVER(PARTITION BY a.[database_name], a.[type] ORDER BY a.backup_finish_date) AS Row_Seq, ROW_NUMBER()OVER(ORDER BY a.[database_name], a.[type], a.backup_finish_date DESC) AS Row_Seq -- this makes the last queries easier than the previous methodINTO #BaseFROM msdb.dbo.backupset aWHERE ( a.[database_name] = @DatabaseOR @Database IS NULL)AND a.backup_finish_date >= DATEADD(day,-21,CAST(GETDATE() AS DATE)) -- get 21 days so get at least 2 weeks of FULL backups to compare. filter to 14 for the rest in next query.-- create details from baseSELECTa.[database_name], a.backup_finish_date, a.[type], a.backup_start_date_time, a.backup_finish_date_time, b.backup_finish_date_time AS prev_backup_finish_date_time, a.backup_type, CAST(a.backup_size_MB AS DECIMAL(10,2)) AS backup_size_MB, CAST(b.backup_size_MB AS DECIMAL(10,2)) AS prev_backup_size_MB, x.backup_size_MB_CHANGE, CAST(a.cbackup_size_MB AS DECIMAL(10,2)) AS cbackup_size_MB, CAST(b.cbackup_size_MB AS DECIMAL(10,2)) AS prev_cbackup_size_MB, x.cbackup_size_MB_CHANGE, a.Row_SeqINTO #DetailsFROM #Base aINNER JOIN #Base b -- do INNER, don't show the row with no previous records, nothing to compare to anyway except NULLON b.[database_name] = a.[database_name]AND b.[type] = a.[type]AND b.Row_Seq = a.Row_Seq + 1 -- get the previous row (to compare difference in size changesCROSS APPLY ( SELECTCAST(a.backup_size_MB - b.backup_size_MB AS DECIMAL(20,2)) AS backup_size_MB_CHANGE, CAST(a.cbackup_size_MB - b.cbackup_size_MB AS DECIMAL(10,2)) AS cbackup_size_MB_CHANGE) xWHERE a.backup_finish_date >= DATEADD(day,-14,CAST(GETDATE() AS DATE)) -- limit result set to last 14 days of backups-- Show detailsSELECTa.[database_name], a.backup_finish_date, a.[type], a.backup_start_date_time, a.backup_finish_date_time, a.prev_backup_finish_date_time, a.backup_type, a.backup_size_MB, a.prev_backup_size_MB, a.backup_size_MB_CHANGE, a.cbackup_size_MB, a.prev_cbackup_size_MB, a.cbackup_size_MB_CHANGEFROM #Details aORDER BYa.Row_Seq -- can order by this since all rows are sequenced, not partitioned first.-- Show latest backups types per database with size changes from previous backupSELECTa.[database_name], a.backup_finish_date, a.[type], a.backup_start_date_time, a.backup_finish_date_time, a.prev_backup_finish_date_time, a.backup_type, a.backup_size_MB, a.prev_backup_size_MB, a.backup_size_MB_CHANGE, a.cbackup_size_MB, a.prev_cbackup_size_MB, a.cbackup_size_MB_CHANGE--, x.Row_SeqFROM #Details aCROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database per typeb.Row_SeqFROM #Details bWHERE b.[database_name] = a.[database_name]AND b.[type] = a.[type]ORDER BYb.backup_finish_date_time DESC) xWHERE x.Row_Seq = a.Row_Seq -- only display the rows that match the latest backup per database per typeORDER BYa.Row_Seq-- get the latest backups ONLY per database, also show the other types in the same row-- Show latest backups types per database with size changes from previous backupSELECTa.[database_name]--, a.backup_finish_date AS latest_backup_finish_date--, a.backup_type AS latest_backup_type--, a.backup_finish_date_time--, a.prev_backup_finish_date_time, ISNULL( ( a.backup_type + ' – ' + LTRIM(ISNULL(STR(ABS(DATEDIFF(DAY, GETDATE(),a.backup_finish_date_time))) + ' days
ago', 'NEVER'))+ ' – ' + CONVERT(VARCHAR(20), a.backup_start_date_time, 103) + ' ' + CONVERT(VARCHAR(20),
a.backup_start_date_time, 108)+ ' – ' + CONVERT(VARCHAR(20), a.backup_finish_date_time, 103) + ' ' + CONVERT(VARCHAR(20),
a.backup_finish_date_time, 108)+ ' (' + CAST(DATEDIFF(second, a.backup_finish_date_time,a.backup_finish_date_time) AS VARCHAR(4)) + ' '+ 'seconds)'), '-') AS LastBackup , a.backup_size_MB AS Last_backup_size_MB, a.prev_backup_size_MB, a.backup_size_MB_CHANGE, a.cbackup_size_MB AS Last_cbackup_size_MB, a.prev_cbackup_size_MB, a.cbackup_size_MB_CHANGE--, x.Row_Seq, f.* -- full backup sizes: lastest, previous, and change, d.* -- differential backup sizes: lastest, previous, and change, l.* -- log backup sizes: lastest, previous, and changeFROM #Details aCROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database b.Row_SeqFROM #Details bWHERE b.[database_name] = a.[database_name]ORDER BYb.backup_finish_date_time DESC) xCROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database for full b.backup_size_MB AS Last_FullBackup_size_MB, b.prev_backup_size_MB AS Prev_FullBackup_size_MB, b.backup_size_MB_CHANGE AS FullBackup_size_MB_CHANGE, b.cbackup_size_MB AS Last_CFullBackup_size_MB, b.prev_cbackup_size_MB AS Prev_CFullBackup_size_MB, b.cbackup_size_MB_CHANGE AS CFullBackup_size_MB_CHANGEFROM #Details bWHERE b.[database_name] = a.[database_name]AND b.backup_type = 'full'ORDER BYb.backup_finish_date_time DESC) fCROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database for differentialb.backup_size_MB AS Last_DiffBackup_size_MB, b.prev_backup_size_MB AS Prev_DiffBackup_size_MB, b.backup_size_MB_CHANGE AS DiffBackup_size_MB_CHANGE, b.cbackup_size_MB AS Last_CDiffBackup_size_MB, b.prev_cbackup_size_MB AS Prev_CDiffBackup_size_MB, b.cbackup_size_MB_CHANGE AS CDiffBackup_size_MB_CHANGEFROM #Details bWHERE b.[database_name] = a.[database_name]AND b.backup_type = 'differential'ORDER BYb.backup_finish_date_time DESC) dCROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database for logb.backup_size_MB AS Last_LogBackup_size_MB, b.prev_backup_size_MB AS Prev_LogBackup_size_MB, b.backup_size_MB_CHANGE AS LogBackup_size_MB_CHANGE, b.cbackup_size_MB AS Last_CLogBackup_size_MB, b.prev_cbackup_size_MB AS Prev_CLogBackup_size_MB, b.cbackup_size_MB_CHANGE AS CLogBackup_size_MB_CHANGEFROM #Details bWHERE b.[database_name] = a.[database_name]AND b.backup_type = 'log'ORDER BYb.backup_finish_date_time DESC) lWHERE x.Row_Seq = a.Row_Seq -- only display the rows that match the latest backup per database ORDER BYa.Row_SeqDROP TABLE #Base
DROP TABLE #Details附录(B) (Appendix (B))
The T-SQL is executed across all the SQL instances listed in the input file
T-SQL在输入文件中列出的所有SQL实例上执行
$filepath='\\hq6021\c$\serverlist.csv'Import-CSV $filepath -Header ServerName | Foreach-Object{write-output "processing $($_.ServerName)"Invoke-Sqlcmd -ServerInstance $_.ServerName -Database master -OutputAs DataTables -Query `
"DECLARE--@Database VARCHAR(50) = 'BI_DW'@Database VARCHAR(50) = NULL, @DaysBack INT = 8, @StartDate DATESET @StartDate = ( SELECT DATEADD(day,-1* @DaysBack,CAST(GETDATE() AS DATE)))DECLARE@Base AS TABLE -- match table data types except for fields not in table
( DBName VARCHAR(128), StartDateTime DATETIME, FinishDateTime DATETIME, TypeCode CHAR(1), TypeDesc VARCHAR(15), FinishDate DATE, SizeMB NUMERIC(35,13), cSizeMB NUMERIC(35,13), RowSeq INT
)-- collect base dataINSERT INTO @BaseSELECTa.[database_name] AS DBName, a.backup_start_date AS StartDateTime, a.backup_finish_date AS FinishDateTime, a.[Type] AS TypeCode, CASE a.[Type]WHEN 'D' THEN 'full'WHEN 'L' THEN 'log'WHEN 'I' THEN 'differential'ELSE 'other'END AS TypeDesc, CAST(a.backup_finish_date AS DATE) AS FinishDate, a.backup_size/1024/1024.00 AS SizeMB, a.compressed_backup_size/1024/1024.00 AS cSizeMB , ROW_NUMBER() OVER(ORDER BY a.[database_name], a.[Type], a.backup_finish_date DESC) AS RowSeqFROM msdb.dbo.backupset aWHERE ( a.[database_name] = @DatabaseOR @Database IS NULL)AND a.backup_finish_date >= DATEADD(week,-1,@StartDate) -- get extra week so 2 weeks of FULL backup come through-- create details from base
; WITH CTE_Details
AS
(SELECTa.DBName, a.FinishDate, a.TypeCode, a.StartDateTime, a.FinishDateTime, b.FinishDateTime AS FinishDateTime_prev, a.TypeDesc, x.SizeMB, x.SizeMB_prev, x.SizeMB_chng, x.cSizeMB, x.cSizeMB_Prev, x.cSizeMB_chng, a.RowSeqFROM @Base aINNER JOIN @Base b -- do INNER, don't show the row with no previous records, nothing to compare to anyway except NULLON b.DBName = a.DBNameAND b.TypeCode = a.TypeCodeAND b.RowSeq = a.RowSeq + 1 -- get the previous row to compare difference in size changesCROSS APPLY ( SELECTCAST(a.SizeMB - b.SizeMB AS DECIMAL(20,2)) AS SizeMB_chng, CAST(a.cSizeMB - b.cSizeMB AS DECIMAL(10,2)) AS cSizeMB_chng, CAST(a.SizeMB AS DECIMAL(10,2)) AS SizeMB, CAST(b.SizeMB AS DECIMAL(10,2)) AS SizeMB_prev, CAST(a.cSizeMB AS DECIMAL(10,2)) AS cSizeMB, CAST(b.cSizeMB AS DECIMAL(10,2)) AS cSizeMB_Prev) xWHERE a.FinishDateTime >= @StartDate -- limit result set to last 14 days of backups
)-- get the latest backups ONLY per database, also show the other types in the same row-- Show latest backups types per database with size changes from previous backup-- include total log since last differential, and average differential since last fullSELECT@@SERVERNAME Servername,CONVERT(VARCHAR(25), a.DBName) AS dbName,CONVERT(VARCHAR(10), DATABASEPROPERTYEX(a.DBName, 'status')) [Status],(SELECT COUNT(1) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid !=0 ) DataFiles,(SELECT SUM((size*8)/1024) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid!=0) [DataMB],(SELECT COUNT(1) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid=0) LogFiles,(SELECT SUM((size*8)/1024) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid=0) [LogMB],(SELECT SUM((size*8)/1024) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name
AND groupid!=0)+(SELECT SUM((size*8)/1024) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid=0) TotalSizeMB,CONVERT(sysname,DatabasePropertyEx(name,'Recovery')) RecoveryModel ,CONVERT(VARCHAR(20), crdate, 103) + ' ' + CONVERT(VARCHAR(20), crdate, 108) AS [Creationdate]-- , a.DBName, ISNULL(a.TypeDesc + ' – ' + LTRIM(ISNULL(STR(ABS(DATEDIFF(DAY, GETDATE(),a.FinishDateTime))) + ' days ago', 'NEVER'))+ ' – ' + CONVERT(VARCHAR(20), a.StartDateTime, 103) + ' ' + CONVERT(VARCHAR(20), a.StartDateTime, 108)+ ' – ' + CONVERT(VARCHAR(20), a.FinishDateTime, 103) + ' ' + CONVERT(VARCHAR(20), a.FinishDateTime, 108)+ ' (' + CAST(DATEDIFF(second, a.FinishDateTime,a.FinishDateTime) AS VARCHAR(4)) + ' seconds)','-') AS LastBackup, a.SizeMB AS SizeMB_last, a.SizeMB_prev, a.SizeMB_chng, a.cSizeMB AS cSizeMB_last, a.cSizeMB_prev, a.cSizeMB_chng, f.* -- full backup sizes: lastest, previous, and change, d.* -- differential backup sizes: lastest, previous, and change, l.* -- log backup sizes: lastest, previous, and change, ( SELECT -- total log size since last differentialsum(c.SizeMB) FROM CTE_Details cWHERE c.TypeDesc = 'log'AND c.DBName = a.DBNameAND c.FinishDateTime >= d.diff_FinishDateTime_last -- since last differentialGROUP BYc.DBName, c.TypeDesc) AS Log_Total_SizeMB_SinceLastDiff, ( SELECT -- average differential size since last fullsum(c.SizeMB)FROM CTE_Details cWHERE c.TypeDesc = 'differential'AND c.DBName = a.DBNameAND c.FinishDateTime >= f.full_FinishDateTime_last -- since last differentialGROUP BYc.DBName, c.TypeDesc) AS Diff_Avg_SizeMB_SinceLastFullFROM CTE_Details aINNER JOIN ( SELECT -- do this rather than Cross apply, doesn't perform query for each row.MAX(b.FinishDateTime) AS FinishDateTime, b.DBNameFROM CTE_Details b GROUP BYb.DBName) xON x.DBName = a.DBNameAND x.FinishDateTime = a.FinishDateTime--CROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database -- b.RowSeq-- FROM CTE_Details b-- WHERE b.DBName = a.DBName-- ORDER BY-- b.FinishDateTime DESC-- ) xOUTER APPLY ( SELECT TOP 1 -- get the latest backup record per database for full b.SizeMB AS Full_SizeMB_last, b.SizeMB_prev AS Full_SizeMB_prev, b.cSizeMB_chng AS Full_SizeMB_chng, b.cSizeMB AS Full_cSizeMB_last, b.cSizeMB_Prev AS Full_cSizeMB_prev, b.cSizeMB_chng AS Full_cSizeMB_chng, b.FinishDateTime AS Full_FinishDateTime_lastFROM CTE_Details bWHERE b.DBName = a.DBNameAND b.TypeDesc = 'full'ORDER BYb.FinishDateTime DESC) fOUTER APPLY ( SELECT TOP 1 -- get the latest backup record per database for differentialb.SizeMB AS Diff_SizeMB_last, b.SizeMB_prev AS Diff_SizeMB_prev, b.cSizeMB_chng AS Diff_SizeMB_chng, b.cSizeMB AS Diff_cSizeMB_last, b.cSizeMB_Prev AS Diff_cSizeMB_prev, b.cSizeMB_chng AS Diff_cSizeMB_chng, b.FinishDateTime AS Diff_FinishDateTime_lastFROM CTE_Details bWHERE b.DBName = a.DBNameAND b.TypeDesc = 'differential'ORDER BYb.FinishDateTime DESC) dOUTER APPLY ( SELECT TOP 1 -- get the latest backup record per database for logb.SizeMB AS Log_SizeMB_last, b.SizeMB_prev AS Log_SizeMB_prev, b.cSizeMB_chng AS Log_SizeMB_chng, b.cSizeMB AS Log_cSizeMB_last, b.cSizeMB_Prev AS Log_cSizeMB_prev, b.cSizeMB_chng AS Log_cSizeMB_chng, b.FinishDateTime AS Log_FinishDateTime_lastFROM CTE_Details bWHERE b.DBName = a.DBNameAND b.TypeDesc = 'log'ORDER BYb.FinishDateTime DESC) linner join sys.sysdatabases DBon db.name=a.DBName--WHERE x.RowSeq = a.RowSeq -- only display the rows that match the latest backup per database "`
|Write-SqlTableData -ServerInstance hqdbt01 -DatabaseName SQLShackDemo -SchemaName dbp -TableName BackupInfoTable -Force
}翻译自: https://www.sqlshack.com/planning-sql-server-backup-restore-strategy-multi-server-environment-using-powershell-t-sql/
使用PowerShell和T-SQL在多服务器环境中规划SQL Server备份和还原策略相关推荐
- SQL Server中的尾日志备份和还原
A tail-log backup is a special type of transaction log backup. In this type of backup, the log recor ...
- java sql封装,在Java系统中封装SQL语言的处理方法及系统的制作方法
在Java系统中封装SQL语言的处理方法及系统的制作方法[ 技术领域: ][0001]本发明涉及计算机数据处理 技术领域: ,特别是涉及一种在Java系统中封装SQL语言的处理方法及系统.[ 背景技术 ...
- 64位环境中使用SQL查询excel的方式解决
--64位环境中使用SQL查询excel的方式 环境: OS:Windows Server 2008 R2 Enterprise MSSQL:Microsoft SQL Server 2008 R2 ...
- 【SQL】服务器环境下的SQL
一.大型数据库的三层体系结构 web服务器:比如在淘宝页面上,输入"牛肉干",就是web服务器来处理,提交给应用服务器. 应用服务器:在获取到"牛肉干"这个请求 ...
- sql修改链接服务器,sqlserver中修改链接服务器
sqlserver中修改链接服务器 内容精选 换一换 RDS for SQL Server实例将默认开启SQL审计功能,并且不支持关闭.SQL审计功能会将对服务级.数据库级.表级的主要变更操作记录进审 ...
- ArcGIS——数据库空间SQL(一、oracle中使用sql空间查询及st_astext等函数出错问题)
一.引言 将shp文件导入oracle中就想着直接用sql进行普通查询和空间查询,这样直接通过webserver发布就可以不用arcgis server直接进行接口调用了,感觉这样比较接触底层些,所以 ...
- 思科服务器备份文件失败,思科路由器tftp备份、还原 IOS升级的方法
思科路由器tftp备份.还原 IOS升级的方法 1700,2600,3600,7200系列 1.IOS映像恢复的方法及步骤 1) 连接PC的COM1口与路由器的console口,使用PC的超级终端软件 ...
- 微软服务器ip,微软服务器环境中的IP地址管理
本文主要讨论Men&Mice方案在微软服务器中的IP地址空间管理.Men&Mice方案是一个针对Microsoft AD(活动目录)和相关问题的IP地址解决方案.Men&Mic ...
- SQL数据库中BAK文件的备份和还原
对于数据库的恢复非常建议采用BAK文件的方法进行备份和还原,因为该种方法相对于SQL脚本文件不仅简单而且高效.具体步骤如下: 1.备份Bak文件 1.右键需要备份的数据库(这里以 MyDB 为例)–& ...
最新文章
- java.lang.IllegalArgumentException: columnNames.length = 3, columnValues.length = 4
- 与流氓软件的一次艰苦“奋战”
- 使用Unoconv和LibreOffice进行格式转换实现在线预览 doc,doxc,xls,xlsx,ppt,pptx 文件
- 漫步最优化二——基本优化问题
- 随想录(ionic开发app)
- 用javascript实现win7系统扫雷游戏
- 艾宾浩斯遗忘曲线-计划表30天
- Python学习(52周存钱)
- python 时间序列异常值_干货 :时间序列异常检测
- 两个自然数互素(relatively prime)
- 关于360插件化框架Replugin竖屏修改为横屏解决方案
- Python3.9标准库math中的函数汇总介绍(53个函数和5个常数)
- 振荡周期、机器周期、指令周期
- 基于格的 Hash 函数(SWIFFT) BKW 算法
- LaTeX 中少量俄文的输入
- 了解海外域名市场,把域名卖到全世界!
- Codechef June Challenge 2020 简要题解
- 王爽汇编语言 实验3
- [科普]DLL是什么
- 数据结构与算法_c#_猎豹网校