Mysql查询(基于某酒店2000w条数据)
2019独角兽企业重金招聘Python工程师标准>>> 
1、仅仅是学习
前阵子手贱,下载网上流传的某酒店2000w开房记录,顺手就给下载了。下载cvs格式,导入数据时好多失败,随后下载Sql-Server-2008-R2版本的记录,由于模糊查询非常慢,就开始改造mysql版本的(注:SQL-Server不熟而且太占内存了,4G的基本跑起来比较费力)。贴上SQL-Server的建表语句:
CREATE TABLE [dbo].[cdsgus]([Name] [nvarchar](2000) NULL,[CardNo] [nvarchar](2000) NULL,[Descriot] [nvarchar](2000) NULL,[CtfTp] [nvarchar](2000) NULL,[CtfId] [nvarchar](2000) NULL,[Gender] [nvarchar](2000) NULL,[Birthday] [nvarchar](2000) NULL,[Address] [nvarchar](2000) NULL,[Zip] [nvarchar](2000) NULL,[Dirty] [nvarchar](2000) NULL,[District1] [nvarchar](2000) NULL,[District2] [nvarchar](2000) NULL,[District3] [nvarchar](2000) NULL,[District4] [nvarchar](2000) NULL,[District5] [nvarchar](2000) NULL,[District6] [nvarchar](2000) NULL,[FirstNm] [nvarchar](2000) NULL,[LastNm] [nvarchar](2000) NULL,[Duty] [nvarchar](2000) NULL,[Mobile] [nvarchar](2000) NULL,[Tel] [nvarchar](2000) NULL,[Fax] [nvarchar](2000) NULL,[EMail] [nvarchar](2000) NULL,[Nation] [nvarchar](2000) NULL,[Taste] [nvarchar](2000) NULL,[Education] [nvarchar](2000) NULL,[Company] [nvarchar](2000) NULL,[CTel] [nvarchar](2000) NULL,[CAddress] [nvarchar](2000) NULL,[CZip] [nvarchar](2000) NULL,[Family] [nvarchar](2000) NULL,[Version] [nvarchar](2000) NULL,[id] [int] IDENTITY(1,1) NOT NULL,CONSTRAINT [PK_cdsgus] PRIMARY KEY CLUSTERED ([id] ASC) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]) ON [PRIMARY]从建表语句看,这表建得实在是不太好!不管,先看看数据有多少:
select COUNT(*) FROM [shifenzheng].[dbo].[cdsgus]; # 查询非常慢的(5分钟左右)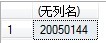
2、开始MySql之旅
开始导入数据(开始mysql建表语句也和上面一样),然后几经折腾,最终确定表结构如下(内存不够,放弃ENGINE=MEMORY):
mysql> show create table customer;
+--------------------------+
| Table | Create Table
+--------------------------+
| customer | CREATE TABLE `customer` (`Name` varchar(80) NOT NULL,`CardNo` varchar(10) DEFAULT NULL,`Descriot` varchar(100) DEFAULT NULL,`CtfTp` varchar(4) DEFAULT NULL,`CtfId` varchar(40) DEFAULT NULL,`Gender` varchar(8) DEFAULT NULL,`Birthday` int(9) DEFAULT NULL,`Address` varchar(100) DEFAULT NULL,`Zip` int(10) DEFAULT NULL,`Dirty` varchar(20) DEFAULT NULL,`District1` varchar(6) DEFAULT NULL,`District2` varchar(4) DEFAULT NULL,`District3` varchar(6) DEFAULT NULL,`District4` varchar(6) DEFAULT NULL,`District5` varchar(8) DEFAULT NULL,`District6` varchar(20) DEFAULT NULL,`FirstNm` varchar(50) DEFAULT NULL,`LastNm` varchar(20) DEFAULT NULL,`Duty` varchar(20) DEFAULT NULL,`Mobile` varchar(40) DEFAULT NULL,`Tel` varchar(40) DEFAULT NULL,`Fax` varchar(40) DEFAULT NULL,`EMail` varchar(60) DEFAULT NULL,`Nation` varchar(25) DEFAULT NULL,`Taste` varchar(100) DEFAULT NULL,`Education` varchar(20) DEFAULT NULL,`Company` varchar(80) DEFAULT NULL,`CTel` varchar(20) DEFAULT NULL,`CAddress` varchar(60) DEFAULT NULL,`CZip` int(8) DEFAULT NULL,`Family` int(10) DEFAULT NULL,`Version` datetime DEFAULT NULL,`id` int(11) NOT NULL,PRIMARY KEY (`id`),KEY `index_Name` (`Name`) USING BTREE,KEY `index_CtfId` (`CtfId`) USING BTREE
) ENGINE=MyISAM DEFAULT CHARSET=utf8 |
+--------------------------+mysql> show create table test;
+--------------------------+
| Table | Create Table
+--------------------------+
| test | CREATE TABLE `test` (`Name` varchar(80) NOT NULL,`CardNo` varchar(10) DEFAULT NULL,`Descriot` varchar(100) DEFAULT NULL,`CtfTp` varchar(4) DEFAULT NULL,`CtfId` varchar(40) DEFAULT NULL,`Gender` varchar(8) DEFAULT NULL,`Birthday` int(9) DEFAULT NULL,`Address` varchar(100) DEFAULT NULL,`Zip` int(10) DEFAULT NULL,`Dirty` varchar(20) DEFAULT NULL,`District1` varchar(6) DEFAULT NULL,`District2` varchar(4) DEFAULT NULL,`District3` varchar(6) DEFAULT NULL,`District4` varchar(6) DEFAULT NULL,`District5` varchar(8) DEFAULT NULL,`District6` varchar(20) DEFAULT NULL,`FirstNm` varchar(50) DEFAULT NULL,`LastNm` varchar(20) DEFAULT NULL,`Duty` varchar(20) DEFAULT NULL,`Mobile` varchar(40) DEFAULT NULL,`Tel` varchar(40) DEFAULT NULL,`Fax` varchar(40) DEFAULT NULL,`EMail` varchar(60) DEFAULT NULL,`Nation` varchar(25) DEFAULT NULL,`Taste` varchar(100) DEFAULT NULL,`Education` varchar(20) DEFAULT NULL,`Company` varchar(80) DEFAULT NULL,`CTel` varchar(20) DEFAULT NULL,`CAddress` varchar(60) DEFAULT NULL,`CZip` int(8) DEFAULT NULL,`Family` int(10) DEFAULT NULL,`Version` datetime DEFAULT NULL,`id` int(11) NOT NULL,PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 |
+--------------------------+表customer,test结构式一样的,数据也是一样的,只是customer多了两个索引:
KEY `index_Name` (`Name`) USING BTREE,KEY `index_CtfId` (`CtfId`) USING BTREE终端编码统一设置成utf8:
mysql> show variables like '%char%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+先看看表空间的大小:
mysql> select table_name, data_length/(1024 * 1024), index_length/(1024 * 1024) from tables where table_schema='hotel';
+------------+---------------------------+----------------------------+
| table_name | data_length/(1024 * 1024) | index_length/(1024 * 1024) |
+------------+---------------------------+----------------------------+
| customer | 2713.3337 | 566.7627 |
| test | 2713.3337 | 196.2305 |
+------------+---------------------------+----------------------------+
2 rows in set (0.00 sec)多了两列的索引就多了370M左右。
3、MySql的测试数据:
| 条数\时间 | TABLE `test` | TABLE `customer` |
| ① | ||
| count(*) ... where name like '徐%' | 369670 (1 min 2.63 sec) | 369670 (0.45 sec) |
| count(*) ... where name like 'xu%' | 1834 (1 min 2.32 sec) | 1834 (0.45 sec) |
| name ... where name like '徐%' | 369670 (1 min 2.91 sec) | 369670 (0.30 sec) |
| name ... where name like 'xu%' | 1834 (1 min 3.27 sec) | 1834 (0.15 sec) |
| name ... where binary name like 'xu%' | 605 (1 min 2.89 sec) | 605 (7.62 sec) |
| ② | ||
| count(*) ... where name like '%徐' | 912(1 min 1.89 sec) | 912(7.45 sec) |
| count(*) ... where name like '%xu' | 326(1 min 1.71 sec) | 326(7.25 sec) |
| name ... where name like '%徐' | 912 (1 min 3.19 sec) | 912 (7.42 sec) |
| name ... where name like '%xu' | 326 (1 min 3.69 sec) | 326 (7.48 sec) |
| name ... where binary name like '%xu' | 117 (1 min 7.49 sec) | 117 (6.76 sec) |
| ③ | ||
| count(*) ... where name like '%徐%' | 373621(1 min 2.98 sec) | 373621(8.08 sec) |
| count(*) ... where name like '%xu%' | 3347(1 min 3.26 sec) | 3347(7.98 sec) |
| name ... where name like '%徐%' | 373621 (1 min 3.02 sec) | 373621 (7.49 sec) |
| name ... where name like '%xu%' | 3347 (1 min 3.55 sec) | 3347 (7.29 sec) |
| name ... where binary name like '%xu%' | 1059 (1 min 2.93 sec) | 1059 (6.94 sec) |
| ④ | ||
| name,ctfid,id ... where name like '徐%' | 369670 (1 min 1.48 sec) | 369670 (大于40min) |
| name,ctfid,id ... where name like 'xu%' | 1834 (1 min 1.40 sec) | 1834 (17.77, 0.02 sec) |
| name,ctfid,id ... where name binary like 'xu%' | 605 (1 min 4.45 sec) | 605 (1min 12.59 sec) |
| ⑤ | ||
| name,ctfid,id ... where name like '%徐%' | 373621 (1 min 2.59 sec) | 373621 (1 min 2.18 sec) |
| name,ctfid,id ... where name like '%xu%' | 3347 (1 min 5.52 sec) | 3347 (1min 1.77 sec) |
| name,ctfid,id ... where binary name like '%xu%' | 1059 (1 min 2.83 sec) | 1059 (1min 0.38 sec) |
| ⑥ | ||
| name ... where name = '徐' | 120 (1 min 2.70 sec) | 120 (0.16 sec) |
| name ... where name = 'xu' | 38 (1 min 8.17 sec) | 38 (0.01 sec) |
| ⑦ | ||
| name,ctfid,id ... where name = '徐' | 120 (1 min 11.80 sec) | 120 (0.60 sec) |
| name,ctfid,id ... where name = 'xu' | 38 (1 min 3.43 sec) | 38 (0.58 sec) |
| ⑧ | ||
| name,ctfid,id ... where name like '%徐%' limit 1000 | 1000 (0.05 sec) | 1000 (0.06 sec) |
| name,ctfid,id ... where name like '%徐%' limit 10000 | 10000 (0.40 sec) | 10000 (0.39 sec) |
| name,ctfid,id ... where name like '%xu%' limit 1000 | 1000 (18.91 sec) | 1000 (19.28 sec) |
| name,ctfid,id ... where name like '%xu%' limit 10000 | 10000 (1 min 1.74 sec) | 10000 (59.71 sec) |
| ⑨ | ||
| name,ctfid,id ... where name like '%徐%' limit 1000, 1000 | 1000 (0.31 sec) | 1000 (0.31 sec) |
| name,ctfid,id ... where name like '%徐%' limit 10000, 1000 | 1000 (1.48, 0.41 sec) | 1000 (1.52, 0.46 sec) |
| name,ctfid,id ... where name like '%徐%' limit 100000, 1000 | 1000 (17.18, 17.01 sec) | 1000 (14.01, 13.61 sec) |
| name,ctfid,id ... where name like '%xu%' limit 1000,1000 | 1000 (44.71 sec) | 1000 (41.81 sec) |
| name,ctfid,id ... where name like '%xu%' limit 2000,1000 | 1000 (48.02 sec) | 1000 (49.56 sec) |
注:有索引的时候,模糊查询单列数据占有很大的优势,等于查询也是。对比①②发现,模糊查询还是开始字符不模糊很有优势的(基本可以了解索引的分组规则)。第④条,说明索引也是有问题的,大概46分钟的时间(可能是bug),第④的第二条说明索引查询过的数据会缓存起来,索引第二次查询明显很快。对比binary(区分大小写),明显更加耗时。第⑨条,说明越往后的数据,limit查询起来越费时。
4、待解决的问题
limit关键字在数据量很多的性能瓶颈,其实就如这篇文章所说的:http://www.cnblogs.com/fjytzh/archive/2010/04/02/1702886.html,offset偏移比较大时,可以采用嵌套查询的方式来提高效率,但是目前我需要满足模糊查询的需要,这个方案有问题(确实测试了一下,不可行,比直接limit还要慢)。
试试http://grb12508.blog.163.com/blog/static/273784582009102448061/复合索引的方法(综上:如果对于有where 条件,又想走索引用limit的,必须设计一个索引,将where 放第一位,limit用到的主键放第2位,而且只能select 主键!),主要想通过name来查询id,故以name, id建复合索引(测试结果还可以)。
-- 添加复合索引alter table test add index (name, id);-- 查询的SQL语句(注意:这里如果用 id in (...)会很慢! http://codingstandards.iteye.com/blog/1344833 )select name, ctfid, id from test t inner join (select id as i_id from test where name like '徐%' limit 20000, 2000) as i on t.id=i.i_id;第一次查询比较慢,重复查询一下就很快(应该有缓存)。
5、最终建表语句
CREATE TABLE `customer` (`Name` varchar(80) NOT NULL,`CardNo` varchar(10) DEFAULT NULL,`Descriot` varchar(100) DEFAULT NULL,`CtfTp` varchar(4) DEFAULT NULL,`CtfId` varchar(40) DEFAULT NULL,`Gender` varchar(8) DEFAULT NULL,`Birthday` int(9) DEFAULT NULL,`Address` varchar(100) DEFAULT NULL,`Zip` int(10) DEFAULT NULL,`Dirty` varchar(20) DEFAULT NULL,`District1` varchar(6) DEFAULT NULL,`District2` varchar(4) DEFAULT NULL,`District3` varchar(6) DEFAULT NULL,`District4` varchar(6) DEFAULT NULL,`District5` varchar(8) DEFAULT NULL,`District6` varchar(20) DEFAULT NULL,`FirstNm` varchar(50) DEFAULT NULL,`LastNm` varchar(20) DEFAULT NULL,`Duty` varchar(20) DEFAULT NULL,`Mobile` varchar(40) DEFAULT NULL,`Tel` varchar(40) DEFAULT NULL,`Fax` varchar(40) DEFAULT NULL,`EMail` varchar(60) DEFAULT NULL,`Nation` varchar(25) DEFAULT NULL,`Taste` varchar(100) DEFAULT NULL,`Education` varchar(20) DEFAULT NULL,`Company` varchar(80) DEFAULT NULL,`CTel` varchar(20) DEFAULT NULL,`CAddress` varchar(60) DEFAULT NULL,`CZip` int(8) DEFAULT NULL,`Family` int(10) DEFAULT NULL,`Version` datetime DEFAULT NULL,`id` int(11) NOT NULL,PRIMARY KEY (`id`),KEY `index_Name_Id` (`Name`, `id`) USING BTREE,KEY `index_CtfId_Id` (`CtfId`, `id`) USING BTREE
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;转载于:https://my.oschina.net/twinkling/blog/180619
Mysql查询(基于某酒店2000w条数据)相关推荐
- mysql查询第11到20条数据_数据库查询语句怎样查询一个表中的第15到第20条数据...
展开全部 用row_number来查询. 具体方法如下:62616964757a686964616fe4b893e5b19e31333337613830 以sqlserver2008R2为例. 1.创 ...
- mysql查询最小时间的一条数据_SQL 获取时间最小的一条数据
展开全部 1.首先最常用的32313133353236313431303231363533e4b893e5b19e31333431373233就是GETDATE了,如下图所示,直接获得当前最新的日期. ...
- mysql 表的第2条到4条记录,mysql怎么查询第2到4条数据
mysql怎么查询第2到4条数据 在mysql中可以通过"LIMIT"关键字来查询第2到4条数据,具体语句为"SELECT * FROM 数据表名 LIMIT 1,3;& ...
- mysql如何更新两条数据_mysql根据查询结果批量更新多条数据(插入或更新)
mysql根据查询结果批量更新多条数据(插入或更新) 1.1 前言 mysql根据查询结果执行批量更新或插入时经常会遇到1093的错误问题.基本上批量插入或新增都会涉及到子查询,mysql是建议不要对 ...
- mysql 表的第2条到4条记录_mysql怎么查询第2到4条数据?
在mysql中可以通过"LIMIT"关键字来查询第2到4条数据,具体语句为"SELECT * FROM 数据表名 LIMIT 1,3;",查询从第2条记录开始的 ...
- 1对多 只取一条 mysql_MySQL 多表关联一对多查询实现取最新一条数据的方法示例...
本文实例讲述了MySQL 多表关联一对多查询实现取最新一条数据的方法.分享给大家供大家参考,具体如下: MySQL 多表关联一对多查询取最新的一条数据 遇到的问题 多表关联一对多查询取最新的一条数据, ...
- mysql:取group by第一条数据
mysql:取group by第一条数据 示例数据(表enterprise_info) SELECT * FROM enterprise_info; id name gdp update_time 1 ...
- mysql 查询案例dept,emp表内数据
mysql 查询案例dept,emp表内数据 部门表 员工表 工资等级表 查询案例: 部门表 CREATE TABLE DEPT( DEPTNO INT PRIMARY KEY, – 部门编号 DNA ...
- laravel mysql rand_laravel如何从mysql数据库中随机抽取n条数据(高性能) - Laravel学习网...
laravel如何高性能地从mysql数据库中随机获取n条数据,有时候我们常常会需要从数据库随机获取数据,比如:给工作人员随机分配10个订单,随机从数据库中随机抽查100个用户:这样我们就需要随机从数 ...
- Mysql查询某字段值重复的数据个数
说明:表:survey_consumer,字段:province ,统计字段:count 语句说明:查询出survey_consumer表中province字段两个及以上相同的数据(没有重复的数据不会 ...
最新文章
- tomcat参数java_opts调整
- ffmpeg的map参数
- 5-3如何设置文件的缓冲
- Python学习笔记:常用第三方模块3
- (转)Virtual PC 2007虚拟网络设置
- Oracle Study之案例--数据恢复神器Flashback(2)
- 微信小程序入门二: 条件、遍历、网络请求、获取本地图片
- 利用JQuery插件CleverTabs实现多页签打开效果
- oracle视图无法使用rowid,请问:无法从没有键值保存表的连接视图中选择 ROWID 这个是什么原因啊?...
- java字节字符流实验报告_Java第09次实验(IO流)--实验报告
- 用JS实现视频播放器
- Windows2008 R2配置FTP教程
- svn报错E175002
- Excel 冻结窗格
- Programming-寻找发贴水王(C)
- 网络综合布线应用指南
- 天蝎座2019年4月运势
- 【kuangbin】简单搜索 - 13.非常可乐【BFS】
- 提交BlackBerry App World时候填写的SKU是什么?
- Tridium公司的Niagara N4 使用