【机器学习】监督学习的分类:判别/生成模型,概率/非概率模型、参数/非参数模型
转载:https://blog.csdn.net/qq_39521554/article/details/79134274
机器学习是一个有着多分支的学科。其中,监督学习是其中发展最为成熟的分支。这不仅是由于在监督学习框架下面有各种各样的学习模型,如逻辑斯特回归、朴素贝叶斯、支持向量机等,更是因为这个框架有着坚实的理论支撑,机器学习中的计算学习理论就是主要为监督学习服务的:这套理论以概率的方式回答了哪些问题是可学习的,学习成功的概率有多大等问题,其中比较常见的理论有VC理论、PAC理论、PAC-Bayes理论等。为了尽可能理清监督学习的框架,本文尝试从几个比较通用的视角来看待这些经典的监督学习模型,并对它们进行分类。其中,几个通用的视角具体是指:判别模型 VS 生成模型、 非概率模型 VS 概率模型、参数模型 VS 非参数模型,而本文涉及到的经典的监督学习模型包括感知机、逻辑斯特回归、高斯判别分析、朴素贝叶斯、支持向量机、神经网络、k近邻。
问题设定:
假设输入空间(特征空间)为欧几里得空间X,维数是d,我们主要考虑二分类问题,所以输出空间设定为Y(Y={-1,1})。x代表输入空间中的一个随机向量,y代表输出空间中的一个随机变量。P(x,y)是x与y的联合分布,我们并不知道这个联合分布的形式,但由这个分布产生了m个样例,构成我们的训练集D,
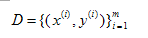
1 判别模型 VS 生成模型
1.1 判别模型
按照文献[1]与[2]给出的解释,判别模型分为两种:(1)直接对输入空间到输出空间的映射进行建模,也就是学习函数 h,
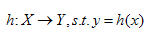
(2)对条件概率P(y|x)进行建模,然后根据贝叶斯风险最小化的准则进行分类:

感知机、逻辑斯特回归、支持向量机、神经网络、k近邻都属于判别学习模型。
1.2 生成模型
生成模型是间接地,先对P(x,y)进行建模,再根据贝叶斯公式
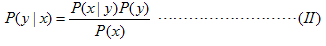
算出P(y|x),最后根据(I)来做分类 (由(I)可知,实际上不需要对P(x)进行建模)。<<Statistical learning theory>> 的作者Vapnik有句名言: "one should solve the [classification] problem directly and never solve a more general problem as an intermediate step[such as modeling P(x|y)]." 按照他这样说,我们只需对P(y|x)直接进行建模就行了,没必要间接地先对P(x,y)进行建模。但是对P(x,y)进行建模从而达到判别的目的也有它自身的一些优势,这一点文献[1]中给出了解释。高斯判别分析、朴素贝叶斯属于生成学习模型。
2 非概率模型 VS 概率模型
2.1 非概率模型
非概率模型指的是直接学习输入空间到输出空间的映射h,学习的过程中基本不涉及概率密度的估计,概率密度的积分等操作,问题的关键在于最优化问题的求解。通常,为了学习假设h(x),我们会先根据一些先验知识(prior knowledge) 来选择一个特定的假设空间H(函数空间),例如一个由所有线性函数构成的空间,然后在这个空间中找出泛化误差最小的假设出来,

其中l(h(x),y)是我们选取的损失函数,选择不同的损失函数,得到假设的泛化误差就会不一样。由于我们并不知道P(x,y),所以即使我们选好了损失函数,也无法计算出假设的泛化误差,更别提找到那个给出最小泛化误差的假设。于是,我们转而去找那个使得经验误差最小的假设,
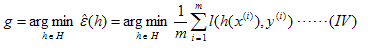
这种学习的策略叫经验误差最小化(ERM),理论依据是大数定律:当训练样例无穷多的时候,假设的经验误差会依概率收敛到假设的泛化误差。要想成功地学习一个问题,必须在学习的过程中注入先验知识[3]。前面,我们根据先验知识来选择假设空间,其实,在选定了假设空间后,先验知识还可以继续发挥作用,这一点体现在为我们的优化问题(IV)加上正则化项上,例如常用的L1正则化,L2正则化等。

正则化项一般是对模型的复杂度进行惩罚,例如我们的先验知识告诉我们模型应当是稀疏的,这时我们会选择L1范数。当然,加正则化项的另一种解释是为了防止对有限样例的过拟合,但这种解释本质上还是根据先验知识认为模型本身不会太复杂。在经验误差的基础上加上正则化项,同时最小化这两者,这种学习的策略叫做结构风险最小化(SRM)。最后,学习算法A根据训练数据集D,从假设空间中挑出一个假设g,作为我们将来做预测的时候可以用。具体来说,学习算法A其实是一个映射,对于每一个给定的数据集D,对于选定的学习策略(ERM or SRM),都有确定的假设与D对应

感知机、支持向量机、神经网络、k近邻都属于非概率模型。线性支持向量机可以显式地写出损失函数——hinge损失。神经网络也可以显式地写出损失函数——平方损失。
时下流行的迁移学习,其中有一种迁移方式是基于样本的迁移。这种方式最后要解决的问题就是求解一个加权的经验误差最小化问题,而权重就是目标域与源域的边际密度之比。所以,线性支持向量机在迁移学习的环境下可以进行直接的推广。
2.2 概率模型
概率模型指出了学习的目的是学出P(x,y)或P(y|x),但最后都是根据(I)来做判别归类。对于P(x,y)的估计,一般是根据乘法公式P(x,y) = P(x|y)P(y)将其拆解成P(x|y),P(y)分别进行估计。无论是对P(x|y),P(y)还是P(y|x)的估计,都是会先假设分布的形式,例如逻辑斯特回归就假设了Y|X服从伯努利分布。分布形式固定以后,剩下的就是分布参数的估计问题。常用的估计有极大似然估计(MLE)和极大后验概率估计(MAP)等。其中,极大后验概率估计涉及到分布参数的先验概率,这为我们注入先验知识提供了途径。逻辑斯特回归、高斯判别分析、朴素贝叶斯都属于概率模型。
在一定的条件下,非概率模型与概率模型有以下对应关系

3 参数模型 VS 非参数模型
3.1 参数模型
如果我们对所要学习的问题有足够的认识,具备一定的先验知识,此时我们一般会假定要学习的目标函数f(x)或分布P(y|x)的具体形式。然后,通过训练数据集,基于ERM、SRM、MLE、MAP等学习策略,可以估计出f(x)或P(y|x)中含有的未知参数。一旦未知参数估计完毕,训练数据一般来说,就失去其作用了,因为这些估计出来的参数就是训练数据的浓缩。通过这种方式建立起来的模型就是参数模型。参数模型的一个很重要的特点是,如果对于模型的假设正确,那么只需要很少的训练数据就可以从假设空间中学出一个很好的模型。但是,如果模型的假设错误,那么无论训练的数据量有多大,甚至趋于无穷大,学出的模型都会与实际模型出现不可磨灭的偏差。感知机、逻辑斯特回归、高斯判别分析、朴素贝叶斯、线性支持向量机都属于参数模型。对于神经网络来说,当固定了隐层的数目以及每一层神经元的个数,它也属于参数模型。但由于隐层数目与每一层神经元个数的不确定性,很多时候,神经网络都被归类为半参数模型。
3.2 非参数模型
当我们对所要学习的问题知之甚少,此时我们一般不会对潜在的模型做过多的假设。在面对预测任务的时候,我们通常会用上所有的训练数据。例如简单的核密度估计(KDE)的表达式中,就带有所有训练数据的信息。通过这种方式建立的模型就是非参数模型。非参数模型的一个很重要的特点就是:let the data speak for itself. 正因为如此,非参数模型的存储开销、计算开销都会比参数模型大的多。但是,由于不存在模型的错误假定问题,可以证明,当训练数据量趋于无穷大的时候,非参数模型可以逼近任意复杂的真实模型。这正是非参数模型诱人的一点。另外需要说明的一点是,非参数模型之所以叫做非参数,并不是因为模型中没有参数。实际上,非参数模型中一般会含有一个或多个超参数,外加无穷多个普通的参数。k近邻就是典型的非参数模型。
时下流行的深度学习,其本质是一个半参数模型的神经网络。通过加大网络的深度(加大隐层数目)以及宽度(增加每一层神经元的个数),使假设空间的复杂度得到极大的提高。复杂的假设空间有极强的表达能力,当训练数据量很大的时候,不会陷入过拟合。所以,深度学习的成功,从理论上讲,一方面来源于海量的训练数据,另一方面来源于其复杂的网络结构。
参考文献
[1] On Discriminative vs. Generative classifiers: A comparison of logistic regression and naive Bayes. nips2002
[2] 《统计学习方法》 李航
[3] Label-Free Supervision of Neural Networks with Physics and Domain Knowledge. AAAI2016
【机器学习】监督学习的分类:判别/生成模型,概率/非概率模型、参数/非参数模型相关推荐
- 机器学习之判别/生成模型小结
1. 简介 监督学习的任务就是学习一个模型,应用该模型对给定的输入预测相应的输出,这个模型的一般形式为决策函数:f(X)f(X)f(X). 或者条件概率分布:P(Y∣X)P(Y∣X)P(Y∣X). 监 ...
- 机器学习监督学习之分类算法---朴素贝叶斯代码实践
目录 1. 言论过滤器 1.1 项目描述 1.2 朴素贝叶斯 工作原理: 1.2.1 词条向量 1.3 开发流程: 1.4 代码实现 1.4.1 创建样本 1.4.2 构建词汇表,用于建立词集向量 1 ...
- 机器学习监督学习之分类算法---朴素贝叶斯理论知识
感谢Jack-Cui大佬的知识分享 机器学习专栏点击这里 目录 感谢Jack-Cui大佬的知识分享 0. 概述 1. 朴素贝叶斯理论 1.1 贝叶斯理论 1.1.1 相关计算公式:条件概率公式,贝叶斯 ...
- 机器学习-监督学习之分类算法:K近邻法 (K-Nearest Neighbor,KNN)
目录 KNN概述 举个例子: K值选取 距离计算 曼哈顿距离,切比雪夫距离关系(相互转化) k-近邻(KNN)算法步骤 相关代码实现 简单实例:判断电影类别 创建数据集 数据可视化 分类测试 运行结果 ...
- 李宏毅机器学习课程4~~~分类:概率生成模型
分类问题用回归来解决? 当有右图所示的点时,这些点会大幅改变分类线的位置.这时候就会导致整体的回归结果变差.当把多分类当成回归问题,类别分别为1,2,3,4--,因为回归的问题是预测具体的值,这样定义 ...
- 深度学习笔记——生成模型
什么是生成模型 生成模型可以描述一个生成数据的模型,属于一种概率模型. 通过这个模型我们可生成不包含在训练数据集中的新的数据. 每次生成模型要输出不同的内容.如果说某些特定的图片服从某些概率分布,生成 ...
- 新闻分类任务(LDA模型,多项分布朴素贝叶斯)
新闻分类任务 1.利用gensim建立LDA模型将文本进行主题分类 2.利用多项分布朴素贝叶斯将文本进行分类 数据来源:http://www.sogou.com/labs/resource/list_ ...
- qda二次判别_R语言线性分类判别LDA和二次分类判别QDA实例
R语言实例链接:http://tecdat.cn/?p=5689 一.线性分类判别 对于二分类问题,LDA针对的是:数据服从高斯分布,且均值不同,方差相同. 概率密度: p是数据的维度. 分类判别函数 ...
- 文本分类 决策树 python_NLTK学习笔记(六):利用机器学习进行文本分类
关于分类文本,有三个问题 怎么识别出文本中用于明显分类的特征 怎么构建自动分类文本的模型 相关的语言知识 按照这个思路,博主进行了艰苦学习(手动捂脸..) 一.监督式分类:建立在训练语料基础上的分类 ...
- 机器学习基础(二十一)—— 分类与回归、生成模型与判别模型
无论是生成模型还是判别模型,都可作为一种分类器(classification)来使用: 1. 分类与回归 (1)分类的目标变量是标称型数据(categorical data),0/1,yes/no ( ...
最新文章
- 3项目在ie11浏览器打不开_Chrome/Safari都输了:新Edge浏览器率先实现100%支持HTML5...
- 推荐一个代码自动完成的工具AutoCode
- js 拖动层示例[转]
- MySQL SQL优化
- SVN的搭建及使用(三)用TortoiseSVN修改文件,添加文件,删除文件,以及如何解决冲突,重新设置用户名和密码等...
- 1.2.1bat脚本命令 DIR 显示磁盘目录与重定向符号 通配符
- GNN大有可为,从这篇开始学以致用
- 『数据库』你以为删库跑路就能让你老板内(lei)牛(liu)满面--数据库的恢复技术
- ruby mysql dbi_Ruby MySQL DBI实例
- 前端的深拷贝和浅拷贝_javascript中的深拷贝和浅拷贝?
- oracle把所有表查询权限赋与另一用户
- GTX1060 6G是低端电脑显卡吗?
- 三星死守中国市场,强撑溢价难挽回颓势吗?
- python3.9新特性_Python 3.9正式版,新特性提前一睹为快
- Exchange Server 2010全新部署
- 深度学习-扩展数据集
- PHP连接MySQL 8.0报错的解决办法
- ubuntu 20.10 安装万能五笔(ibus模式)
- 2022年素材网完整源码+带后台管理
- 邦纳超声波传感器Q45ULIU64BCR