【玩转数据系列四】听说啤酒和尿布很配?本期教你用协同过滤做推荐
(本文数据为虚构,仅供实验)
产品地址:https://data.aliyun.com/product/learn?spm=a21gt.99266.416540.102.OwEfx2
一、背景
数据挖掘的一个经典案例就是尿布与啤酒的例子。尿布与啤酒看似毫不相关的两种产品,但是当超市将两种产品放到相邻货架销售的时候,会大大提高两者销量。很多时候看似不相关的两种产品,却会存在这某种神秘的隐含关系,获取这种关系将会对提高销售额起到推动作用,然而有时这种关联是很难通过理性的分析得到的。这时候我们需要借助数据挖掘中的常见算法-协同过滤来实现。这种算法可以帮助我们挖掘人与人以及商品与商品的关联关系。
协同过滤算法是一种基于关联规则的算法,以购物行为为例。假设有甲和乙两名用户,有a、b、c三款产品。如果甲和乙都购买了a和b这两种产品,我们可以假定甲和乙有近似的购物品味。当甲购买了产品c而乙还没有购买c的时候,我们就可以把c也推荐给乙。这是一种典型的user-based情况,就是以user的特性做为一种关联。
本文的业务场景如下:
通过一份7月份前的用户购物行为数据,获取商品的关联关系,对用户7月份之后的购买形成推荐,并评估结果。比如用户甲某在7月份之前买了商品A,商品A与B强相关,我们就在7月份之后推荐了商品B,并探查这次推荐是否命中。
二、数据集介绍
数据源:本数据源为天池大赛提供数据,数据按时间分为两份,分别是7月份之前的购买行为数据和7月份之后的。
具体字段如下:
| 字段名 | 含义 | 类型 | 描述 |
|---|---|---|---|
| user_id | 用户编号 | string | 购物的用户ID |
| item_id | 物品编号 | string | 被购买物品的编号 |
| active_type | 购物行为 | string | 0表示点击,1表示购买,2表示收藏,3表示购物车 |
| active_date | 购物时间 | string | 购物发生的时间 |
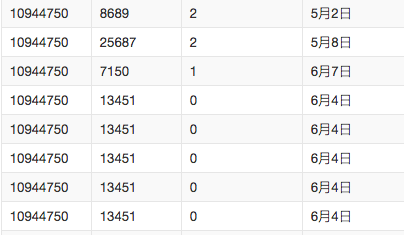
数据截图:
三、数据探索流程
首先,实验流程图:
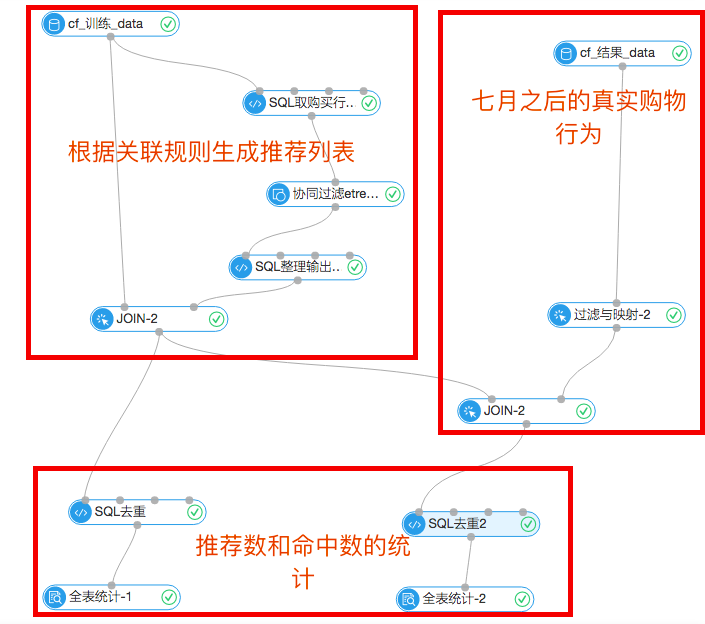
1.协同过滤推荐流程
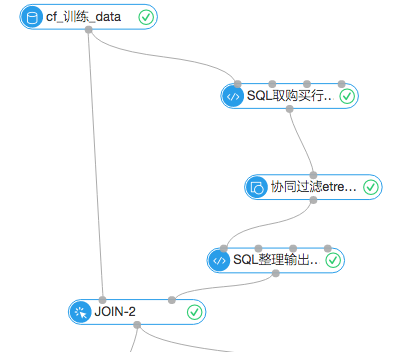
首先输入的数据源是7月份之前的购物行为数据,通过SQL脚本取出用户的购买行为数据,进入协同过滤组件。协同过滤的组件设置中把TopN设置成1,表示每个item返回最相近的item和它的权重。通过购买行为,分析出哪些商品被同一个user购买的可能性最大。设置图如下:

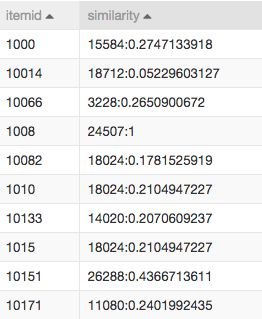
协同过滤结果,表示的是商品的关联性,itemid表示目标商品,similarity字段的冒号左侧表示与目标关联性高的商品,右边表示概率:
2.推荐
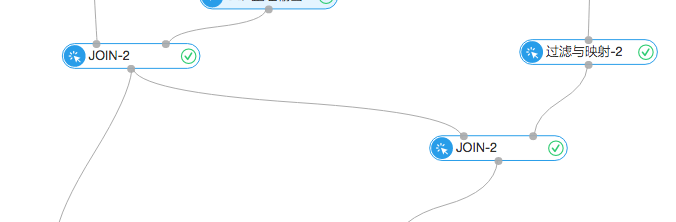
上述步骤介绍了如何生成强关联商品的对应列表。这里使用了比较简单的推荐规则,比如用户甲某在7月份之前买了商品A,商品A与B强相关,我们就在7月份之后推荐了商品B,并探查这次推荐是否命中。这个步骤是通过下图实现的:
3.结果统计
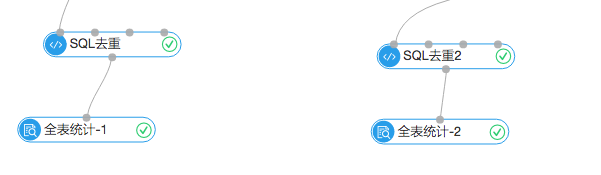
上面是统计模块,左边的全表统计展示的是根据7月份之前的购物行为生成的推荐列表,去重后一共18065条。右边的统计组件显示一共命中了90条。
四、推荐系统反思
根据上文的统计结果可以看出,本次试验的推荐效果并不理想,原因在如下几方面。
1)首先本文只是针对了业务场景大致介绍了协同过滤推荐的用法。很多针对于购物行为推荐的关键点都没有处理,比如说时间序列,购物行为一定要注意对于时效性的分析,跨度达到几个月的推荐不会有好的效果。其次没有注意推荐商品的属性,本文只考虑了商品的关联性,没有考虑商品是否为高频或者是低频商品,比如说用户A上个月买了个手机,A下个月就不大会继续购买手机,因为手机是低频消费品。
2)基于关联规则的推荐很多时候最好是作为补充,真正想提高准确率还是要依靠机器学习算法训练模型的方式。
五、其它
作者微信公众号(与作者讨论):

参与讨论:云栖社区公众号
免费体验:阿里云数加机器学习平台
往期文章:
【玩转数据系列一】人口普查统计案例
【玩转数据系列二】机器学习应用没那么难,这次教你玩心脏病预测
【玩转数据系列三】利用图算法实现金融行业风控
【玩转数据系列四】听说啤酒和尿布很配?本期教你用协同过滤做推荐相关推荐
- hive 如果表不存在则创建_从零开始学习大数据系列(四十七) Hive中数据的加载与导出...
[本文大约1400字,阅读时间5~10分钟] 在<从零开始学习大数据系列(三十八) Hive中的数据库和表>和<从零开始学习大数据系列(四十二)Hive中的分区>文章中,我们已 ...
- 如何从购物数据中挖掘出啤酒与尿布的关联关系?
首先说一个关联分析的经典案例,零售业巨头沃尔玛对消费者的购物行为进行分析时发现,男性顾客在购买婴儿尿布时,通常会顺带购买几瓶啤酒来犒劳自己,于是推出了尿布和啤酒摆在一起销售的促销手段.而这个举措真 ...
- python协同过滤电影推荐_python实现基于用户的协同过滤算法(CF)——以电影评价数据(ml-100k)为例...
程序简介 项目以ml-100k电影评分数据集为输入,实现了基于用户的协同过滤算法,最后预测的MAE为0.84,因为经过优化,10万条评分数据运行时间不超过2分钟 协同过滤算法(CF)基于对用户历史行为 ...
- 【玩转数据系列三】利用图算法实现金融行业风控
(本文数据为虚构,仅供实验) 产品地址:https://data.aliyun.com/product/learn?spm=a21gt.99266.416540.102.OwEfx2 一.背景 本文将 ...
- Oracle数据系列(四)、高级查询2
第四章.Oracle高级查询2 学习目标 4.1.模糊查询LIKE 查询时,字段内容并不一定与查询内容完全匹配,只要字段含有这些内容就行. #查询以李姓开头的员工信息 select * from em ...
- 【玩转数据系列十三】机器学习算法基于信用卡消费记录做信用评分
原文链接 机器学习算法基于信用卡消费记录做信用评分 背景 如果你是做互联网金融的,那么一定听说过评分卡.评分卡是信用风险评估领域常用的建模方法,评分卡并不简单对应于某一种机器学习算法,而是一种通用的建 ...
- 大数据毕业设计 协同过滤商品推荐系统设计与实现
文章目录 1 简介 2 常见推荐算法 2.1 协同过滤 2.2 分解矩阵 2.3 聚类 2.4 深度学习 3 协同过滤原理 4 系统设计 4.1 示例代码(py) 5 系统展示 5.1 系统界面 5. ...
- Python 玩转数据 5 - 图解 Python 赋值,浅拷贝 copy.copy() 和 深拷贝 copy.deepcopy() 原理
引言 上面文章有介绍 Python 动态类型 共享引用等相关知识,有这个基础,我们来深入研究一下 Python 赋值,拷贝的原理,有涉及到可变类型和不可变类型的不同处理.更多 Pyton 进阶系列文章 ...
- 用python玩转数据Python便捷数据获取与预处理 quiz
用python玩转数据第四章测试 Python便捷数据获取与预处理 quiz 1.pandas模块中的read_csv()函数在日常使用较多,它除了可以读取csv格式的文件并将结果转换成一个DataF ...
最新文章
- 从汗水物流到智慧物流,物流产业智能化
- cordova flie文件目录_Cordova文件插件目录错误
- 左神算法:将单链表的每K个节点之间逆序(Java版)
- Caffe阅读代码并修改
- 这些Android高级必会知识点你能答出来几个?含BATJM大厂
- Bootstrap 重置样式
- 20050909:女乘客钓男司机?
- 《Adobe Illustrator CS6中文版经典教程(彩色版)》—第0课0.14节使用画笔工具
- Ubuntu安装Caffe过程和BUG以及解决方案(全网最全)
- win10电脑任务栏软件图标变成白色解决办法
- 第二十九课: 斯涅尔定律、折射及全反射
- 【Windows】虚拟机配置及Win7电脑搭建服务器
- 房间类游戏后台框架(一)—介绍
- 如何format格式化ftl模板
- 网易宝系统架构之我见:高可用篇
- 1-关于单片机通信数据传输(中断发送,大小端,IEEE754浮点型格式,共用体,空闲中断,环形队列)
- C/C++编程新手入门基础系列:俄罗斯方块小游戏制作源代码
- mac os 视频播放器 免费
- 金山WPS服务端研发实习面经——一、二面+HR面
- 1024 献礼,10 个前端开发者必收的高赞资源