Innodb事务和锁
事务概念
数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作,经典的事务场景是转账,A(id为3)给B(id为1)转账:
update user_account set balance = balance - 1000 where user_id = 3;
update user_account set balance = balance + 1000 where user_id = 1;这两个sql要保证必须同时成功或同时失败,否则数据将出现不一致的情况。
mysql中的事务
查看mysql事务开启状态:
show variables like 'autocommit'默认是ON。
mysql中开启事务
会话级别
set session autocommit = on/off; 这个是对当前会话设置自动提交,对其他会话不起作用,如果设置为off,这时候执行完sql后,当前会话都要手动加上commit才能提交事务。
手动开启
手动执行sql:
开启事务:begin / start transaction;
提交或回滚事务:commit / rollbackJDBC编程中:
connection.setAutoCommit(boolean);
connection.commit();Spring事务AOP编程:
expression=execution(com.gpedu.dao.*.*(..))mysql中默认是自动提交事务的。也就是在你执行sql语句的时候,它会自动在你sql前边加上begin或start transaction;在后边自动加上commit;从而事务就会自动提交。
当手动使用begin或start transaction时,mysql就会取消自动加事务,例如:
begin;
update user set name="faith" where id=1;执行后,数据库id为1的记录并不会改变,因为这时候mysql不会自动提交,当手动执行commit之后才会进行提交。
而因为mysql自动提交事务,所以如下两个sql实际上是在两个事务中的:
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +1000 where userID = 1;那么为了保证原子性,我们需要做如下操作:
begin;
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +1000 where userID = 1;
commit;这样就把这两个sql放到一个事务中去了。
在jdbc中将两个sql放到一个事务中,如下:
connection.setAutoCommit(boolean);
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +1000 where userID = 1;
connection.commit();Spring事务AOP编程,实际上也是做了手动开启操作:
expression=execution(com.faith.dao.*.*(..))这里设置了一个切面,基于这个切面的所有方法都会被拦截,这些方法配置事务的传播性质,拦截之后,spring会在方法之前加一个切面,设置会话手动提交,例如:
connection.setAutoCommit(boolean);然后在方法之后加一个切面,设置会话提交,例如:
connection.commit();当catch到异常的时候,就执行
connection.rollback();事务的特性
原子性(Atomicity)
事务是最小的工作单元,事务中的sql要么一起提交成功,要么全部失败回滚。
一致性(Consistency)
事务中操作的数据及状态改变是一致的,更新的数据必须完全符合预设的规则,不会因为事务或系统等原因导致状态的不一致。
隔离性(Isolation)
一个事务所操作的数据在提交之前,对其他事务的可见性设定。如果事务并发且相互不隔离,会导致脏读、不可重复读、幻读等系列问题。
持久性(Durability)
事务所做的修改会永久保存,不会因为系统意外导致数据的丢失。
原子性和一致性是两个不同的概念。对于原子性来说,如下的两条语句:
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +10000 where userID = 1;只要同时执行成功或失败就是符合原子性的。
而对于一致性来说是不成立的,因为实际给1转账1000,但是1的账户上多了10000,不符合转账的规则,导致了数据的不一致性。
事务的隔离级别
SQL92 ANSI/ISO标准
http://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt
Read Uncommitted(读未提交)--未解决任何并发问题,可以读到其他事务未提交的数据,会导致脏读(dirty read)。Read Committed(读已提交)--解决脏读问题,一个事务开始之后,只能看到己提交的事务所做的修改,但是未解决不可重复读(nonrepeatable read)。Repeatable Read (可重复读)--解决不可重复读问题,在同一个事务中多次读取同样的数据结果是一样的,这种隔离级别未定义解决幻读的问题。Serializable(串行化)--解决所有问题,最高的隔离级别,通过强制事务的串行执行。innodb对隔离级别的支持
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 不可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | ==不可能== |
| 串行化 | 不可能 | 不可能 | 不可能 |
在92标准中,可重复读级别可以不解决幻读问题,但是innodb存储引擎的可重复读解决了幻读问题。
锁
锁用来管理不同事务对共享资源的并发访问。
表锁与行锁:
锁定粒度:表锁 > 行锁表锁直接锁定表,行锁只锁定一行。加锁效率:表锁 > 行锁直接对表加锁块,而行锁需要在表中找到指定的行记录。冲突概率:表锁 > 行锁,表锁锁定的记录更多,更容易产生冲突。并发性能:表锁 < 行锁InnoDB存储引擎只有行锁,没有表锁,但它也能实现表锁的效果,因为它的表锁是把表中所有的行都锁一遍,就成了表锁。这个只是实现了表锁的效果,但是和真正的表锁效率相比要低下很多。
innodb的锁类型
InnoDB默认select语句不加任何锁类型,但是delete、update、insert 默认会加上X锁。
innodb共有八种锁:
共享锁(行锁):Shared Locks排它锁(行锁):Exclusive Locks意向锁共享锁(表锁):Intention Shared Locks意向锁排它锁(表锁):Intention Exclusive Locks自增锁:AUTO-INC Locks关于行锁的锁:记录锁 Record Locks间隙锁 Gap Locks临键锁 Next-key Locks共享锁
又称为读锁,简称S锁,多个事务对于同一数据可以共享一把共享锁,持有共享锁的事务都能访问到数据,但是只能读不能修改。
共享锁示例:
begin;
select * from user WHERE id=1 LOCK IN SHARE MODE;不执行commit操作,这时候在另一个窗口执行:
select * from user WHERE id=1;
update user set name='2' where id=1;select操作可以查到数据,但是update会被阻塞,直到最开始申请到共享锁的事务执行commit或rollback来释放享锁,之后update才会继续执行。
排他锁
又称为写锁,简称X锁,排他锁不能与其他锁并存,如一个事务获取了某条记录的排他锁,其他事务就不能再获取该行的锁(共享锁、排他锁),即不能读不能写,只有持有排他锁的事务才可以对记录进行读取和修改(其他事务要读取数据可来自于快照)。
排它锁示例:
begin;
update user set name='2' where id=1;不执行commit操作,这时候在另一个窗口执行:
select * from user WHERE id=1 LOCK IN SHARE MODE;
update user set name='3' where id=1;这两条操作都会被阻塞,直至持有排它锁的事务commit或rollback之后才能继续执行。
意向共享锁(IS)
表示事务准备给数据行加入共享锁,即一个数据行加共享锁前必须先取得该表的IS锁,意向共享锁之间是可以相互兼容的。
意向排它锁(IX)
表示事务准备给数据行加入排他锁,即一个数据行加排他锁前必须先取得该表的IX锁,意向排它锁之间也是可以相互兼容的。
意向锁(IS 、IX)是InnoDB在数据操作之前自动加的,不需要用户干预,我们编码时不需要对意向锁进行特殊处理。
意向锁是表级锁,之间是相互兼容的,也就是说多个持有锁的线程,可以同时持有意向锁。比如update id=1,update id=2,他们可以同时持有意向锁。
意向锁存在的意义:
只有当事务想去进行锁表时,意向锁才会发挥作用,事务会先判断意向锁是否存在,如果存在,说明此时肯定有行锁存在,这时候不能进行表锁,则可快速返回该表不能启用表锁,省略了进入底层扫描全表的数据。
自增锁
针对自增列自增长的一个特殊的表级别锁,可以使用如下语句查看自增锁的模式:
show variables like 'innodb_autoinc_lock_mode';此参数可取的值有三个:0、1、2,默认取值1。
取值0:传统方式,串行自增,并且是连续的。这种模式下需要语句执行完成才释放自增锁,所以性能最低。例如:1、2、3、4、5、6,没有人为删除情况下,表中id字段一定是连续的。
取值1:连续方式,自增的,并且是连续的。当语句申请到自增锁就释放自增锁,自增锁就可以给其它语句使用,性能会好很多。但因为不会等待语句事务执行完毕就释放了自增锁,可能该事务回滚了,所以id可能会出现断续的情况,例如:1、2、6,8,10
2:交错方式,多语句插入数据时,有可能自增的序列号和执行先后顺不一致,并且中间可能有断裂。一次分配一批自增值,然后下个语句就再进行分配一批自增值,阻塞很小,性能很高。例如:1、2、3、6、5。
设置为2时,需要确认表是否需要连续的自增值,如果需要,就不要使用这个值。
临键锁(Next-key locks)
当sql执行按照索引进行检索,查询条件为范围查找(between and、<、>等)并且有数据命中,则此时SQL语句加上的锁为Next-key locks,锁住索引范围为记录的本区间 + 本区间下一个区间(左开右闭)。
mysql会对记录自动划分出区间,如下:
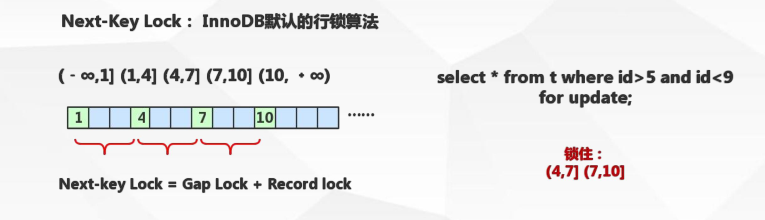
如果为1,2,4,7,10,区间则为(-&,1],(1,2],(2,4],(4,7],(7,10],(10,+&)。划分区间是依据B+树节点之间的间隙来划分的,1和2之间没有间隙,但是在树中,是两个不同的节点,它们之间是有间隙的。
update user set name=1 where id>5 and id<10上面的sql选中的记录是id=7,这时候锁住的区间是(4,7],(7,10],(4,7]是本区间,而(7,10]是本区间的下一个区间。
锁住本区间和相邻区间就是防止幻读,例如这里的>5和<9条件,肯定是要锁定(4,7],(7,10]区间才能实现的,也就是要锁住本区间和相邻区间。
锁住区间是因为B+树的特性,如果把这个例子中的id换成age就更好理解了。
因为innodb默认隔离级别是可重复读,而前边说了innodb的可重复读还捎带解决了幻读问题,而幻读问题就是临键锁配合mvcc一起解决的。
间隙锁(Gap locks)
当sql执行按照索引进行检索,查询条件为范围查找并且查询的数据不存在,这时SQL语句加上的锁即为Gap locks,锁住索引不存在的区间(左开右开)。
只在可重复读隔离级别存在是因为innodb的可重复读解决了幻读问题。
Record locks
当sql执行按照唯一性(Primary key、Unique key)索引进行检索,查询条件为精准等值匹
配且查询的数据是存在,这时SQL语句加上的锁即为记录锁Record locks,这种情况只针对唯一索引,所以对应的是const或equ_ref级别的查询。
innodb的行锁锁住了哪些内容
得出结论之前先做个测试。例如user表中,id,name,age,create_time字段,id和name有索引,create_time没有加索引。
测试1
begin;
select * from user where id=1;不执行commit或rollback。然后在其他线程执行:
select * from user where id=1; 阻塞
select * from user where id=2; 非阻塞
select * from user where id=3; 非阻塞测试2
begin;
select * from user where name=‘1’;不执行commit或rollback。然后在其他线程执行:
select * from user where name=‘1’; 阻塞
select * from user where name=‘2’; 非阻塞
select * from user where name=‘3’; 非阻塞测试3
begin;
select * from user where create_time=1;不执行commit或rollback。然后在其他线程执行:
select * from user where create_time=1; 阻塞
select * from user where create_time=2; 阻塞
select * from user where create_time=3; 阻塞结论:InnoDB的行锁是通过给索引树中的索引项加锁来实现的,如果是聚集索引,那么直接锁住聚集索引的索引项,如果是非聚集索引,那么会锁住当前索引的索引项,以及对应的聚集索引中的索引项。
也就是说对于非聚集索引,会在两棵索引树中分别上锁。只有通过索引条件进行数据检索,InnoDB才使用行级锁,否则,InnoDB将使用表锁(锁住索引的所有记录)。
表锁是非常耗费性能的,所以要避免表锁。这种特性可以给平时写sql带来一些启发,例如:
delete from user where create_time;导致表锁
delete from user where id=1;行锁;写删改的sql时候,要考虑where条件是否命中了索引,要避免表锁出现,删一条记录,却导致整张表被锁住了,这是一件很郁闷的事。
锁如何解决并发问题
脏读
加上X锁可以解决脏读。
不可重复读
模拟不可重复读:
select name from user where id=1;// name='1'
update user set name='2' where id=1; // 执行成功
select name from user where id=1;// name='2'上面两个select的结果不同,导致了不可重复读。解决方法是给这两个select加上S锁:
select name from user where id=1 LOCK IN SHARE MODE;// name='1'
update user set name='2' where id=1; // 阻塞
select name from user where id=1 LOCK IN SHARE MODE;// name='1'这样在当前事务执行完毕之前,不可能被其他事务更改值,从而解决了不可重复读的问题。
幻读
加临键锁可以解决幻读。
死锁
多个并发事务每个事务都持有锁,每个事务都需要再继续持有其他事务持有的锁,但谁都不释放自己手中的锁,产生锁的循环等待,这就形成了死锁。
死锁的避免
类似的业务逻辑以固定的顺序访问表和行。大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率。降低隔离级别,如果业务允许,将隔离级别调低也是较好的选择为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添加上锁(或者说是表锁),表锁造成的锁冲突比行锁要严重的多Innodb事务和锁相关推荐
- mysql innodb禁用事务_MySQL InnoDB事务中锁问题(三)
试想,事务如果都是串行的,那么就不需要锁了,但是性能肯定没法接受.加锁只是为了提高事务并行度,并且解决并发事务执行过程中引起的脏写.脏读.不可重复读.幻读这些问题的一种解决方案(MVCC算是一种解决脏 ...
- InnoDB 事务/锁/多版本分析?你了解多少?
目录 • InnoDB事务 – 事务结构/功能 – XA事务/Group Commit – mini-transaction• InnoDB锁 – 锁结构/类型/功能 – 锁等待/死锁检测 – 自增序 ...
- mysql 事务 innodb 锁表_MySQL性能优化之Innodb事务系统,值得收藏
概述 今天主要分享下Innodb事务系统的一些优化相关,以下基于mysql 5.7. Innodb中的事务.视图.多版本 1.事务 在Innodb中,每次开启一个事务时,都会为该session分配一个 ...
- 同时更改一条数据_数据库中的引擎、事务、锁、MVCC(二)
二.事务 介绍锁之前,咱们先介绍一下 什么叫做事务. 事务就是一组对数据库的一系列的操作,要么同时成功,要么同时失败. 1.事务的特性(ACID): 原子性:事务是整个操作,不可分割,要么都成功,要么 ...
- mySQL教程 第10章 事务和锁
第10章 事务和锁 数据库事务(Database Transaction) ,是指作为单个逻辑工作单元执行的一系列操作. 事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据 ...
- mysql 事务涉及锁吗_MySQL-锁机制和事务
测试: 4.5.innodb_locks_unsafe_for_binlog innodb_locks_unsafe_for_binlog参数用来控制innodb中是否允许间隔锁,默认是OFF代表允许 ...
- Mysql事务和锁原理
一.mysql事务:MySql开启事务:begin. 1.并发事务产生的读问题 1)更新丢失:后提交事务会覆盖先提交的事务.乐观锁可解决. 2)脏读:A读到B未提交update数据.不符合一致性 3 ...
- mysql如何实现读提交锁_MySQL学习笔记(二)—MySQL事务及锁详解
一.事务 数组库的一组操作,要么全部成功,要么全部失败 举例:银行转账 A账户向B账户转100 A账户余额扣去100 B账户余额增加100 上述两个操作要么全部成功,要么全部失败,部分成功或失败,数据 ...
- sybase 事务插入时不可查询_InnoDB事务与锁
事务 可以理解为数据库执行的一个最基础的单位,其包含有限的操作命令(crud). 事务的属性(ACID):事务必须满足四个属性,原子性(atomicity).一致性(consistency).隔离性( ...
最新文章
- date 的基本使用 suse
- 在Intellij idea 中YAML文件出现代码提示
- birt java api_「Birt」birt api生成报表 | 学步园
- Fiddler笔记(3)接口测试
- IIS添加对ashx文件的支持
- python输出名字和字数_Python字数和排名
- 推荐视频反馈系统设计
- 今秋如何让自己的C币也来个大丰收
- 如何从被领导到领导别人
- .NET Core 分析程序集更优方法,超越ReflectionOnlyLoad
- php 爬虫登录网站,Python爬虫模拟登录带验证码网站
- Python编程快速上手-让繁琐工作自动化 — 读书与代码笔记
- 28个在线游戏编程学习网站
- 通达信交易接口以什么形式执行下单的?
- linux系统u盘安装教程
- Contrastive Loss 对比损失函数
- Android中高德地图与百度地图坐标转换
- 用 dism 合并与删除 wim 映像
- 知识图谱系列(二):构建一个医疗知识图谱
- Vue系列之—文件目录详解