【译】Blockchain-based Machine Learning Marketplaces
通过基于区块链市场的数据训练的机器学习模型有可能创造出世界上最强大的人工智能。 它们结合了两个强大的原始设备:私人机器学习,允许在不透露敏感私人数据的情况下进行培训,以及基于区块链的激励机制,这些激励机制允许这些系统吸引最佳数据和模型,使其变得更加智能。 其结果是任何人都可以出售其数据和开放市场的开放市场 保持数据私密性,而开发人员则可以使用激励措施为其算法吸引最佳数据。
构建这些系统具有挑战性,必要的构建块仍在创建中,但简单的初始版本看起来已经开始变得可能。 我相信这些市场将使我们摆脱当前Web 2.0数据垄断时代,进入数据和算法公开竞争的Web 3.0时代,两者都是直接货币化的。
起源
这个想法的基础是在2015年与理查德· 努梅莱的谈话 。 Numerai是一家对冲基金,它将加密的市场数据发送给任何想要竞争模拟股市的数据科学家。 Numerai将最好的模型提交结合到一个“ 元模型 ”中,交易了元模型,并支付模型表现良好的数据科学家。
让数据科学家参与竞争似乎是一个强大的想法 所以这让我想到:你能创建一个完全分散的版本的这个系统,可以推广到任何问题吗? 我相信答案是肯定的。
施工
作为一个例子,让我们尝试创建一个完全分散的系统,用于在分散交易所交易加密货币。 这是许多潜在的建筑之一:
数据数据提供者可以获取数据并将其提供给建模人员。
模型构建建模者选择要使用的数据并创建模型。 培训是使用安全的计算方法完成的,该方法允许模型在不暴露底层数据的情况下进行培训。 模型也被放样。
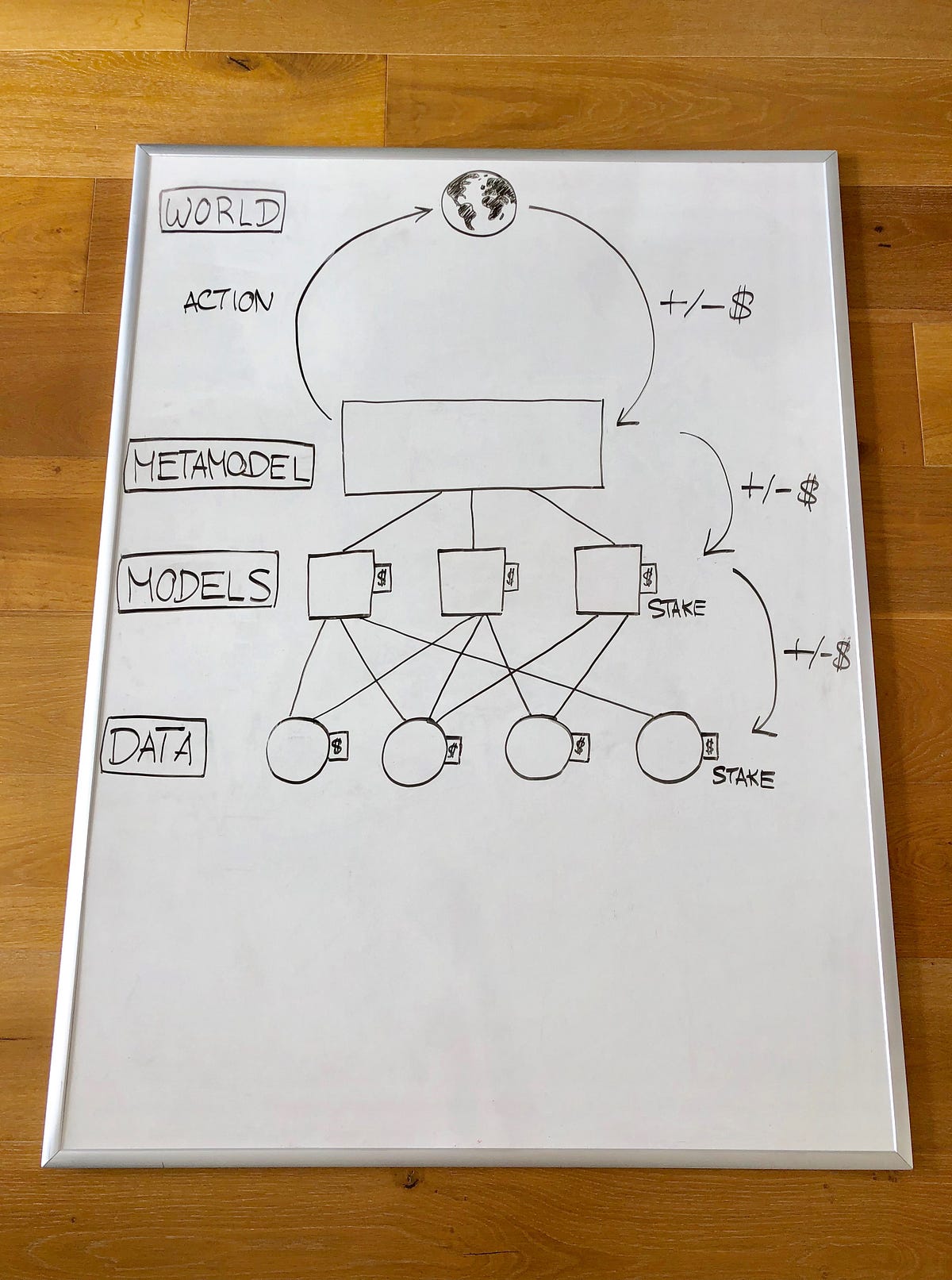
元模型构建元模型是基于考虑每个模型的放样的算法创建的。
创建元模型是可选的 - 您可以想象在未被组合到元模型中时使用的模型。
使用元模型智能合约通过分散交换机制在链上以编程方式进行元模型和交易。
分配收益/损失经过一段时间后,交易产生利润或亏损。 这种利润或损失是根据元模型的贡献者分成多少,这取决于他们制作多少智能元素。 负面贡献的模型拥有部分或全部资金。 然后,模型转向并对其数据提供者执行类似的分发/股权削减。
可验证的计算每个步骤的计算或者是集中式的,但可以使用像Truebit这样的验证游戏进行验证和挑战,或者使用安全的多方计算进行分散。
托管数据和模型要么托管在IPFS上,要么托管在安全的多方计算网络中,因为链上存储将会过于昂贵。
是什么让这个系统强大?
吸引全球最佳数据的激励措施吸引数据的激励措施是系统中最有效的部分,因为数据往往成为大多数机器学习的限制因素 。 以同样的方式,比特币通过开放式激励机制创建了一个全球计算能力最强的紧急系统,适当设计的数据激励结构将为您的应用程序带来世界上最好的数据。 关闭数据来自数千或数百万个来源的系统几乎是不可能的。
算法之间的竞争在以前不存在的地方创建模型/算法之间的公开竞争。 使用数千种竞争新闻源算法来分散Facebook。
奖励的透明度数据和模型提供商可以看到他们获得了他们提交的公平价值,因为所有计算都是可验证的,使他们更有可能参与。
自动化在链上直接生成值并在令牌中直接生成值创建了一个自动化的,不受信任的闭环。
网络效应来自用户,数据提供者和数据科学家的多边网络效应使系统自我强化。 它的表现越好,吸引的资金就越多,这意味着更多的潜在支出,这吸引了更多的数据提供者和数据科学家,他们使系统变得更加智能,反过来吸引更多的资本,并且又回到了原来的位置。
隐私
除了以上几点,一个主要特点是隐私。 它允许1)人们提交数据,否则这些数据太私密而无法共享,2)阻止数据和模型的经济价值泄漏。 如果在未公开的情况下保持未加密,则数据和模型将被免费复制,并由尚未贡献任何工作的其他人使用( “免费搭车者”问题 )。
对搭便车问题的部分解决方案是私下出售数据。 即使买家选择转售或发布数据,其价值随着时间而衰减。 但是,这种方法限制了我们的短期使用情况,并且仍然会产生典型的隐私问题。 因此,更复杂但功能更强大的方法是使用安全计算形式。
安全计算
安全的计算方法允许模型在数据上进行训练而不会泄露数据本身。 目前使用和研究的安全计算有三种主要形式: 同态加密 (HE), 安全 多方计算(MPC)和零知识证明 (ZKPs)。 多方计算目前最常用于私人机器学习,因为同态加密过于缓慢,如何将ZKP应用于机器学习并不明显。 安全计算方法正处于计算机科学研究的前沿。 它们通常比常规计算慢几个数量级,是系统的主要瓶颈,但近年来一直在改进。
终极推荐系统
为了说明私人机器学习的潜力,想象一下名为“终极推荐系统”的应用程序。它会监视您在设备上执行的所有操作:您的浏览记录,您在应用中执行的所有操作,手机上的图片,位置数据,消费记录,可穿戴传感器,短信,家中的相机,未来的相机。 然后给你推荐:你应该访问的下一个网站,阅读文章,听歌或购买产品。
这个推荐系统会非常有效。 比谷歌,Facebook或其他任何现有的数据孤岛都要多,因为它具有 一个最大纵向的观点,你可以从数据中学习,否则将是太私人的考虑分享 。 与以前的加密货币交易系统的例子类似,它可以通过允许一个专注于不同领域的模型市场(例如:网站推荐,音乐)竞争访问您的加密数据并向您推荐某些东西,甚至可能支付给您为您提供数据或您关注所产生的建议。
谷歌的联邦学习和苹果的差异隐私是这种私人机器学习方向迈出的一步,但仍需要信任 ,不允许用户直接检查其安全性,并保持数据存储。
目前的方法
这很早。 很少有组织有任何工作,大多数人都试图一口咬下一块。
来自Algorithmia Research的一个简单结构将模型的精确度设置为高于某个回测阈值:
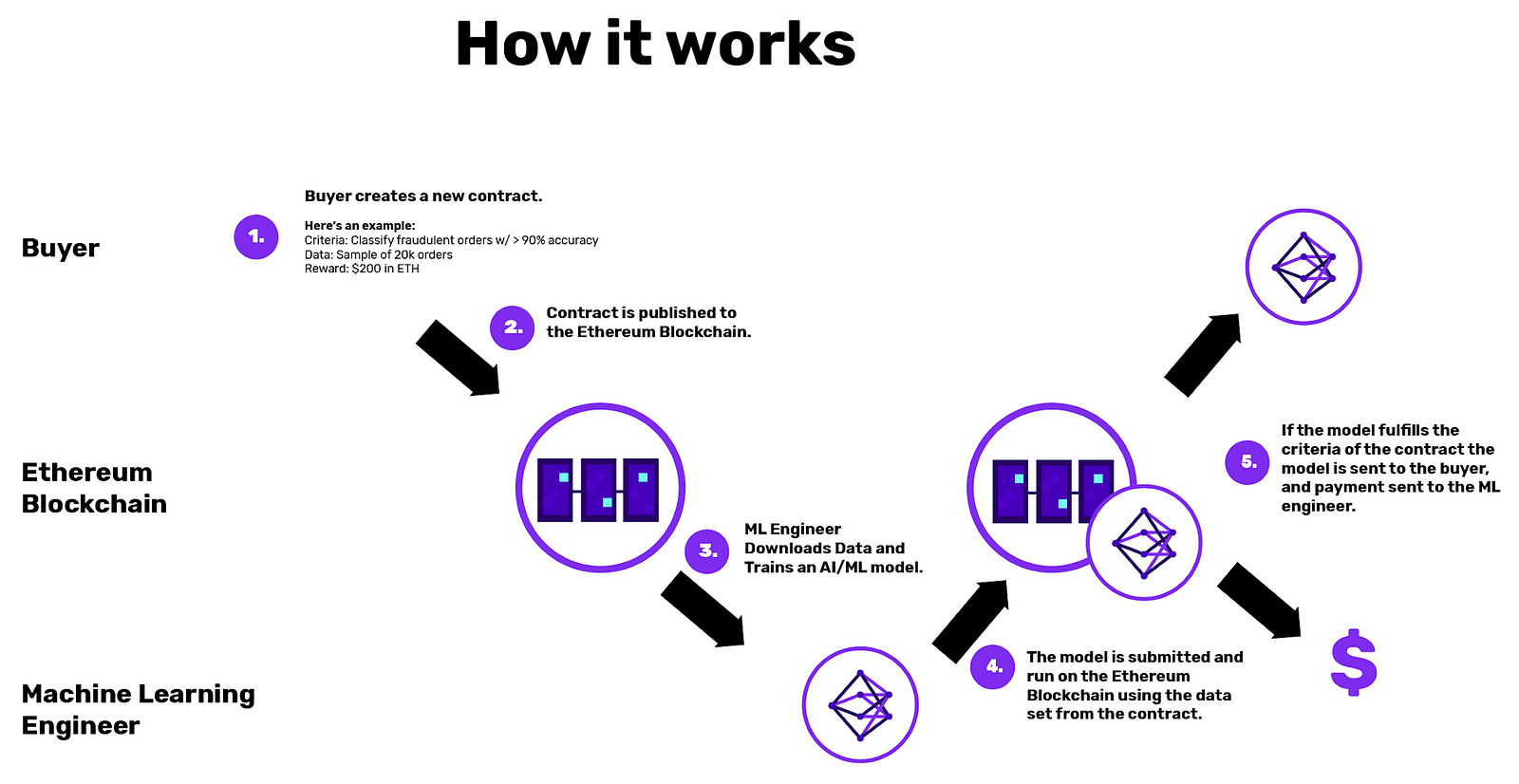
由Algorithmia Research创建机器学习模型的简单构造
Numerai目前进一步采取三个步骤:它使用加密数据(尽管不完全同态),它将众包模型结合到元模型中,并根据未来表现(本例中为股票交易一周)奖励模型,而不是通过回溯测试一个名为Numeraire的土生土星纪念币。 数据科学家必须将Numeraire作为游戏中的皮肤,激励将会发生的事情(未来的表现),而不是发生的事情(被测试的性能)。 但是,它目前集中分发数据,限制感觉是最重要的因素。
没有人为数据创建一个成功的基于区块链的市场。 海洋是一个早期尝试勾勒出一个。
还有一些人正在开始构建安全的计算网络。 Openmined正在创建一个多方计算网络,用于在Unity之上培训机器学习模型,该网络可以在任何设备上运行,包括游戏控制台(类似于家中的Folding ),然后扩展以确保MPC的安全。 谜也有类似的机智。
一个迷人的最终状态将是相互拥有的元模型,它使数据提供者和模型创建者的所有权与他们做出更聪明的决定成比例 。 这些模型将被标记化,随着时间的推移可以派发股息,甚至可能受到培训者的支配。 一种互相拥有的蜂巢式思维。 最初的Openmined视频是迄今为止我所见过的最接近的结构。
哪些方法可能首先起作用?
我不会声称知道什么是最好的结构,但我有一些想法。
我用来评估区块链想法的一篇论文是:在物理本地数字原生区块链原生区域,区块链本地越多越好。 较少的区块链本地化,引入了更可信的第三方,这增加了复杂性并减少了与其他系统构建模块的易用性。
在这里,我认为这意味着如果创造的价值可以量化,系统就更有可能工作 - 理想情况下直接以货币形式直接创建,更好的是代币。 这允许一个干净的闭环系统。 将以前的加密货币交易系统的例子与识别X射线肿瘤的例子进行比较。 在后者中,你需要说服一家保险公司X射线模型是有价值的,谈判如何有价值,然后相信一小群身在现场的人来验证模型的成功/失败。
这并不是说对社会用途而言,数字原生的积极总和不会出现。 像前面提到的推荐系统可能非常有用。 如果附属于管理市场 ,他们是另一种情况,模型可以采用程序化的方式采取行动,并且系统的回报是代币(在这种情况下来自管理市场),再次创造一个干净的闭合回路。 现在看起来很模糊,但我预计区块链本地任务的领域会随着时间的推移而扩大。
启示
首先,分散式机器学习市场可以消除目前科技巨头的数据垄断。 在过去的20年中,他们将互联网上的主要价值创造源头标准化和商品化:专有数据网络和围绕它们的强大网络效应。 结果, 价值创造从数据转移到算法。
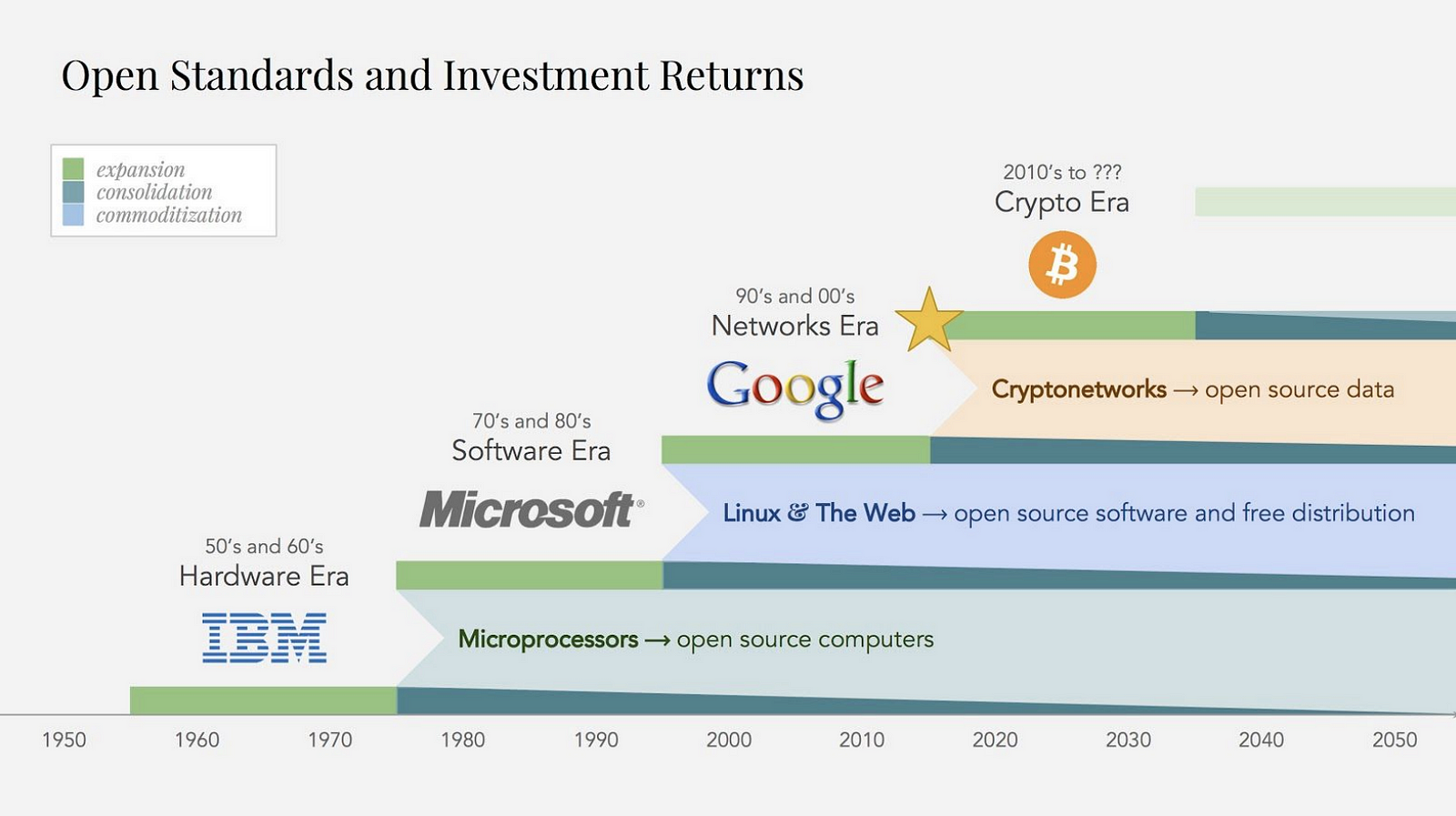
科技领域的标准化和商品化周期,我们正在接近数据垄断网络时代的结束。 占位符图。
换句话说,他们为AI 创建了一个 直接的商业模式 。 喂养和训练它。
其次,他们创造了世界上最强大的AI系统,通过直接的经济激励为他们吸引最好的数据和模型。 他们的力量通过多方面的网络效应而增加。 随着Web 2.0时代的数据网络垄断变得商品化,它们似乎成为下一个重新聚合点的理想选择。 我们可能还有几年的时间,但看起来方向正确。
第三,正如推荐系统的例子所示, 搜索是颠倒的 。 产品搜索和竞争者不是搜索产品的人 (信贷给布拉德这个框架)。 每个人都可能有个人策展市场,推荐系统在竞争中将最相关的内容放入其供稿中,并且相关性由个人定义。
第四,它们使我们能够从Google和Facebook等公司使用的功能强大的基于机器学习的服务中获得同样的好处,而不会泄漏我们的数据。
第五,机器学习可以更快地推进,因为任何工程师都可以访问开放的数据市场,而不仅仅是大型Web 2.0公司的一小部分工程师。
挑战
首先,安全计算方法目前非常缓慢,机器学习的计算成本已经很高。 另一方面,对安全计算方法的兴趣已经开始出现,性能也在不断提高。 我看到过去6个月内HE,MPC和ZKPs显着性能改进的新方法。
计算为元模型提供的一组特定数据或模型的值很难。
清理和格式化众包数据具有挑战性。 我们很可能会看到一些工具,标准化和小企业的组合可以解决这个问题。
最后,具有讽刺意味的是,创建这种系统的广义构造的商业模式不如创建个体实例那么明确。 这似乎是很多新的加密原语,包括管理市场。
结论
私人机器学习与区块链激励相结合,可以在各种应用中创造出最强大的机器智能。 随着时间的推移,可以解决重大的技术挑战。 他们的长期潜力是巨大的,并且从大型互联网公司对数据的掌握中受到欢迎。 他们也有点可怕 - 他们引导自己存在,自我加强,消费私人数据,并且几乎不可能关闭,这让我怀疑是否创建它们比以前召唤更强大的Moloch 。 无论如何,它们是加密货币如何缓慢并突然进入每个行业的又一例证。
感谢 Andrew Trask , Richard Craib , Trent McConaghy , Brad Burnham ,Joel Monegro , Simon de la Rouviere , Gavin Uhma , Morten Dahl ,Jonathan Libov , Matt Huang , Laura Behrens Wu , Naval Ravikant 和Daniel Gross 的对话,帖子。
https://medium.com/@FEhrsam/blockchain-based-machine-learning-marketplaces-cb2d4dae2c17
【译】Blockchain-based Machine Learning Marketplaces相关推荐
- 【译】Using Machine Learning to Understand the Ethereum Blockchain
ConsenSys的 定量开发人员 Paul Lintilhac 目前,数据科学分析的温床研究领域是机器学习,一种使用算法研究大量数据的AI形式. 它用于从测序DNA到研究金融市场和脑机接口的所有事情 ...
- 基于机器学习技术的用户行为分析:当前模型和应用研究综述(A survey for user behavior analysis based on machine learning technique)
A survey for user behavior analysis based on machine learning techniques: current models and applica ...
- 【译】The challenge of verification and testing of machine learning
在我们的第二篇文章中 ,我们给出了一些背景解释为什么攻击机器学习通常比维护它更容易. 我们看到了一些原因,为什么我们还没有完全有效的防范敌对的例子,我们猜测我们是否能够期待这样的防御. 在这篇文章中, ...
- 【译】Privacy and machine learning: two unexpected allies
在机器学习的许多应用中,例如用于医疗诊断的机器学习,我们希望具有机器学习算法,其不记住关于训练集的敏感信息,诸如个体患者的特定医疗历史. 差分隐私是衡量算法提供的隐私保证的框架. 通过差异隐私的镜头, ...
- Paper:《Multimodal Machine Learning: A Survey and Taxonomy,多模态机器学习:综述与分类》翻译与解读
Paper:<Multimodal Machine Learning: A Survey and Taxonomy,多模态机器学习:综述与分类>翻译与解读 目录 <Multimoda ...
- Eight Machine Learning JavaScript Frameworks to Explore
Eight Machine Learning JavaScript Frameworks to Explore [译]:8个值得探索的JavaScript机器学习框架 In this post, yo ...
- Federated Machine Learning: Concept and Applications
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 今天的人工智能仍然面临两大挑战.一种是,在大多数行业中,数据以孤岛的形式存在.二是加强数据隐私和安全.我们提出了一个解决这些挑战的可能方案 ...
- Machine Learning Algorithms Study Notes--Supervised Learning
转载自:http://www.tuicool.com/articles/VvuIvqU Machine Learning Algorithms Study Notes 高雪松 @雪松Cedro Mic ...
- Machine Learning Algorithms Study Notes
2 Supervised Learning 3 2.1 Perceptron Learning Algorithm (PLA) 3 2.1.1 PLA -- " ...
最新文章
- 学界 | DeepMind论文解读:通过删除神经元来了解深度学习
- 程序员的生活就是这么朴实无华,且没钱
- ComboBox的数据联动
- VTK修炼之道17:图像基本操作_图像信息的访问与修改(vtkImageData)
- boost::mp11::mp_quote_trait相关用法的测试程序
- php7插件开发,php7.2.6 插件fileinfo的安装
- 10步骤优化SQL Server 数据库性能
- Linux下串口通信详解
- [导入]Visual Studio 2005 Team Edition软件架构系列课程(1): 概述
- 2015/8/18 Python基本使用(2)
- 反射 数据类型_Java基础:反射机制详解
- Linux 内核的壳 —— shell
- 【渝粤教育】国家开放大学2018年春季 0631-21T动物常见病防治 参考试题
- 从非结构化数据到特色数据指标,AI如何更懂金融?
- 【统计学习方法】EM算法原理
- 阿里云发布智慧书店解决方案 联手新华书店总店落地首个“城市书房”
- 第一个STM8项目的记录
- 中移物联网综合面(害面试之前还是要休息好的)
- 用计算机计算1357城八十九十,1357单元.doc
- Python 3 《Class》入门练习