mysql flicker_分布式全局序列ID方案之Flicker优化方案
1 Flicker的解决方案
MySQL中id自增的特性,可以借此来生成全局的序列号,Flicker在解决全局ID生成方案里就采用了MySQL自增长ID的机制(auto_increment + replace into + MyISAM)。一个生成64位ID方案具体就是这样的:
先创建单独的数据库,然后创建一个表:
CREATE TABLE borrow_order (
id bigint(20) unsigned NOT NULL auto_increment,
stub char(1) NOT NULL default '',
PRIMARY KEY (id),
UNIQUE KEY stub (stub)
) ENGINE=MyISAM
当我们插入记录后,执行SELECT * from borrow_order ,查询结果就是这样的:
+-------------------+------+
| id | stub |
+-------------------+------+
| 1 | 192.168.100.102 |
+-------------------+------+
在我们的应用端需要做下面这两个操作,在一个事务会话里提交:
REPLACE INTO borrow_order (stub) VALUES ('192.168.100.102');
SELECT LAST_INSERT_ID();
上述操作,通过 replace into 操作,首先尝试插入数据到表中,如果发现表中已经有此行数据则先删除此行数据,然后插入新的数据。 如果没有此行数据的话,直接插入新数据。注意:插入的行字段需要有主键索引或者唯一索引,否则会出错
通过上述方式,就可以拿到不重复且自增的ID了。
到上面为止,我们只是在单台数据库上生成ID,从高可用角度考虑,接下来就要解决单点故障问题:Flicker启用了两台数据库服务器来生成ID,通过区分auto_increment的起始值和步长来生成奇偶数的ID。
DBServer1:
auto-increment-increment = 2
auto-increment-offset = 1
DBServer2:
auto-increment-increment = 2
auto-increment-offset = 2
最后,在客户端只需要通过轮询方式取ID就可以了。
优点:充分借助数据库的自增ID机制,提供高可靠性,生成的ID有序。
缺点:占用两个独立的MySQL实例,有些浪费资源,成本较高
数据库中记录过多,每次生成id都需要请求数据库
2 优化方案
采用批量生成的方式,内存缓存号段,降低数据库的写压力,提升整体性能
2.1 方案1 mysql双主架构
采用双主架构的方式来显示高可用,数据库只值存在已备用号段的最大值。
我们新建一张表
CREATE TABLE `id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
`increment_step` int(10) NOT NULL COMMENT '步幅长度',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
如此我们可以通过 getIdService服务 来对单实例数据库批量获取id,具体步骤如下:
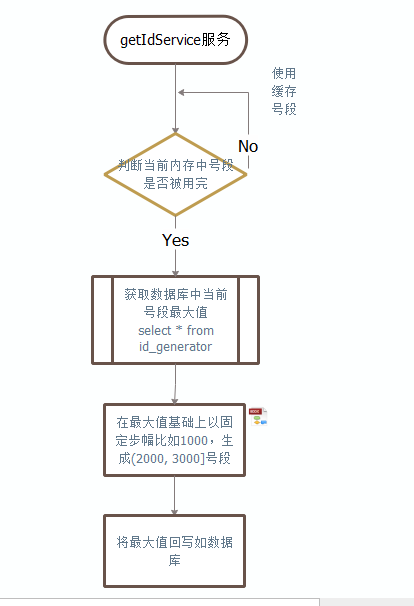
优缺点
>优点
数据库只保存一条记录
性能极大增强
缺点:
如getIdService重启,内存中未使用的ID号段未分配,导致ID空洞
服务没有做HA,无法保证高可用
问题解决方案: 数据库使用双主架构保证高可用,服务通过多个getIdService服务去获取Id,减少ID空洞的数量
上述方案还是存在问题,当多个服务去访问数据库,或者同一服务同时多个线程去访问就会产生竞态条件,产生并发安全问题。
在当前读多写少的场景下,我们可以使用数据库CAS乐观锁去解决并发问题来保证原子性。
假设 同时有两个服务获取到current_max_id的最大值都是3000,然后生成号段后,
回写数据库update id_generator set current_max_id=4000; 此时就会产生的id就会重复,
我们通过CAS方式改写为:update id_generator set current_max_id=4000 where max_id=3000;
来保证生成的id全局唯一
该方案的好处是:
水平扩展达到分布式ID生成服务性能
使用CAS简洁的保证不会生成重复的ID
缺点:
由于有多个service,生成的ID 不是绝对递增的,而是趋势递增的
2.2 方案2 多实例
基于Flicker方案
REPLACE INTO borrow_order (stub) VALUES ('192.168.1.1');
SELECT LAST_INSERT_ID();
当多个服务器的时候,这个表是这样的:
id stub
5 192.168.1.1
2 192.168.1.2
3 192.168.1.3
4 192.168.1.4
每台服务器设置好增幅只更新自己的那条记录,保证了单线程操作单行记录。这时候每个机器拿到的分别是5,2,3,4这4个id。这方案直接通过服务器隔离,解决原子性获得id的问题。
2.3 服务层原子性操作CAS
我们可以AtomicLong来实现ID自增,流程图如下:
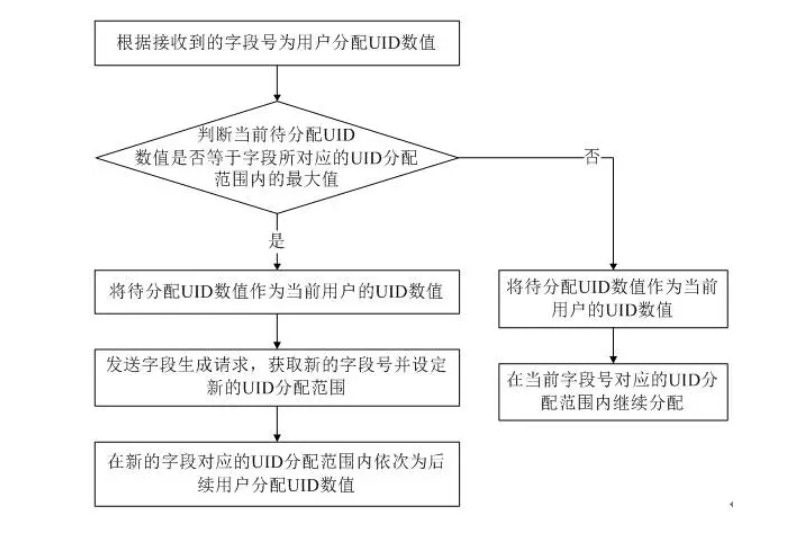
伪代码实现
private static AtomicLong atomicLong;
private static Long currentMaxId;
public synchronized static void deployIdService(String[] args) {
//判断是否为空调用id生成服务
getIdService();
//判断内存中的号段是否使用完
if (atomicLong.get() < currentMaxId) {
//获取id
long id = atomicLong.getAndIncrement();
}else {
//使用重新分配
atomicLong.set(200);
currentMaxId = 300L;
}
}
这里有个小问题,就是在服务器重启后,因为号码缓存在内存,会浪费掉一部分用户ID没有发出去,所以在可能频繁发布的应用中,尽量减小号段放大的步长n,能够减少浪费。
如果再追求极致,可以监听spring或者servlet上下文的销毁事件,把当前即将发出去的用户ID保存起来,下次启动时候加载进入内存。
Reference
mysql flicker_分布式全局序列ID方案之Flicker优化方案相关推荐
- Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案
Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案 参考文章: (1)Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案 (2)https://www.cnblogs.com/ ...
- java 唯一id生成算法_分布式全局唯一ID生成方案之snowflake算法
已有的方案: 可大致分为: 完全依赖关系/非关系型数据库递增的方案 完全不依赖数据源作为生成因子的UUID 半依赖数据源作为生成因子的snowflake 为什么推荐snowflake? 这个问题,可以 ...
- 分布式全局唯一ID的实现
分布式全局唯一ID的实现 前言 上周末考完试,这周正好把工作整理整理,然后也把之前的一些素材,整理一番,也当自己再学习一番. 一方面正好最近看到几篇这方面的文章,另一方面也是正好工作上有所涉及,所以决 ...
- [分布式] ------ 全局唯一id生成之雪花算法(Twitter_Snowflake)
雪花算法(Twitter_Snowflake) 我们知道,分布式全局唯一id的生成,一般是以下几种: 基于雪花算法生成 基于数据库 基于redis 基于zookeeper 本文说下雪花算法,后面附源码 ...
- 分布式全局唯一id实现-2 springCloud-MyBatis-Plus集成百度分布式全局id(uid-generator)
前言:MyBatis-Plus 集成百度的uid-generator ,实现业务实体在insert 实体时,可以自动获取全局id,完成数据保存: 1 uid-generator 全局id 生成的方式了 ...
- 分布式全局唯一id实现-2.1 springCloud-MyBatis-Plus集成百度分布式全局id(uid-generator)--优化版
前言:在上一篇 springCloud-MyBatis-Plus集成百度分布式全局id, id的生成全部交予程序实现,虽然可以通过集群的方式来提高id 生成服务的高可用性,但是依然需要考虑极端情况,在 ...
- mysql io 100_MySQL服务器 IO 100%的分析与优化方案
压力测试过程中,如果因为资源使用瓶颈等问题引发最直接性能问题是业务交易响应时间偏大,TPS逐渐降低等.而问题定位分析通常情况下,最优先排查的是监控服务器资源利用率,例如先用TOP 或者nmon等查看C ...
- mysql产品优化方案_mysql的优化方案
简介 在本文中,主要写一下自己所查阅和理解的mysql优化方案. 我的理解是数据库的优化对于我们'非专业'人员,mysql的优化也没那么复杂了,真的要玩转mysql的话,肯定得需要很多年的经验了. 参 ...
- mysql数据库优化方案_mysql数据库优化方案
1.活动/峰值连接数 (图1)中当前活动的连接为1个,自MySQL服务启动以来,最高连接数为54:当最高连接数接近或等于(图2)中的max_connections时,应适当增加max_connecti ...
最新文章
- 分享 10 个超实用的 Python 编程技巧
- 51Nod 1314 定位系统
- 配置WCF同时支持WSDL和REST,swaggerwcf生成文档
- .NET Core 3.0预览版7中的ASP.NET Core和Blazor更新
- Laravel Composer 命令大全
- 大数据批量插入小练习_SqlServer
- redhat虚拟机安装
- STM32 USART 波特率计算
- PythonWEB框架之Tornado
- 新书介绍:CCNA基础教程
- 思科模拟器 交换机链路聚合(二层、三层)
- 思考题4:掷骰子游戏
- WDF驱动中访问 PCI 设备配置空间
- android 进入recovery,安卓手机如何进入Recovery模式的通用方式详解
- 英国留学生论文introduction部分怎么写比较好?
- 苹果系统python读取文件_python中文件的读取与写入以及os模块
- java 判断fibonacci_Java程序检查给定的数字是否是斐波纳契数
- 微信内置浏览器不支持打开网页或下载APP怎么办,微信跳转浏览器原理
- Kafka KSQL实战
- 家用宽带优化-光猫桥接,路由器拨号