python怎么打开excel文件并处理_python处理excel文件
python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库。
可从这里下载https://pypi.python.org/pypi。下面分别记录python读和写excel.
python读excel——xlrd
这个过程有几个比较麻烦的问题,比如读取日期、读合并单元格内容。下面先看看基本的操作:
首先读一个excel文件,有两个sheet,测试用第二个sheet,sheet2内容如下:

python 对 excel基本的操作如下:# -*- coding: utf-8 -*-
importxlrd
importxlwt
fromdatetimeimportdate,datetime
defread_excel():
# 打开文件
workbook = xlrd.open_workbook(r'F:\demo.xlsx')
# 获取所有sheet
printworkbook.sheet_names()# [u'sheet1', u'sheet2']
sheet2_name = workbook.sheet_names()[1]
# 根据sheet索引或者名称获取sheet内容
sheet2 = workbook.sheet_by_index(1)# sheet索引从0开始
sheet2 = workbook.sheet_by_name('sheet2')
# sheet的名称,行数,列数
printsheet2.name,sheet2.nrows,sheet2.ncols
# 获取整行和整列的值(数组)
rows = sheet2.row_values(3)# 获取第四行内容
cols = sheet2.col_values(2)# 获取第三列内容
printrows
printcols
# 获取单元格内容
printsheet2.cell(1,0).value.encode('utf-8')
printsheet2.cell_value(1,0).encode('utf-8')
printsheet2.row(1)[0].value.encode('utf-8')
# 获取单元格内容的数据类型
printsheet2.cell(1,0).ctype
if__name__ =='__main__':
read_excel()
运行结果如下:
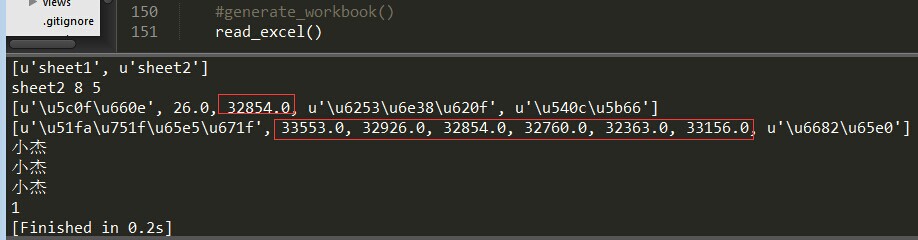
那么问题来了,上面的运行结果中红框框中的字段明明是出生日期,可显示的确实浮点数。好的,来解决第一个问题:
1、python读取excel中单元格内容为日期的方式
python读取excel中单元格的内容返回的有5种类型,即上面例子中的ctype:ctype :0empty,1string,2number,3date,4boolean,5error
即date的ctype=3,这时需要使用xlrd的xldate_as_tuple来处理为date格式,先判断表格的ctype=3时xldate才能开始操作。现在命令行看下:>>> sheet2.cell(2,2).ctype#1990/2/22
>>> sheet2.cell(2,1).ctype#24
>>> sheet2.cell(2,0).ctype#小胖
>>> sheet2.cell(2,4).ctype#空值(这里是合并单元格的原因)
>>> sheet2.cell(2,2).value#1990/2/22
33656.0
>>> xlrd.xldate_as_tuple(sheet2.cell_value(2,2),workbook.datemode)
(1992,2,22,0,0,0)
>>> date_value = xlrd.xldate_as_tuple(sheet2.cell_value(2,2),workbook.datemode)
>>> date_value
(1992,2,22,0,0,0)
>>> date(*date_value[:3])
datetime.date(1992,2,22)
>>> date(*date_value[:3]).strftime('%Y/%m/%d')
'1992/02/22'
即可以做下简单处理,判断ctype是否等于3,如果等于3,则用时间格式处理:if(sheet.cell(row,col).ctype ==3):
date_value = xlrd.xldate_as_tuple(sheet.cell_value(rows,3),book.datemode)
date_tmp = date(*date_value[:3]).strftime('%Y/%m/%d')
那么问题又来了,上面 sheet2.cell(2,4).ctype 返回的值是0,说明这个单元格的值是空值,明明是合并的单元格内容"好朋友",这个是我觉得这个包功能不完善的地方,如果是合并的单元格那么应该合并的单元格的内容一样,但是它只是合并的第一个单元格的有值,其它的为空。>>> sheet2.col_values(4)
[u'\u5173\u7cfb', u'\u597d\u670b\u53cb','', u'\u540c\u5b66','','', u'\u4e00\u4e2a\u4eba','']
>>> foriinrange(sheet2.nrows):
printsheet2.col_values(4)[i]
关系
好朋友
同学
一个人
>>> sheet2.row_values(7)
[u'\u65e0\u540d',20.0, u'\u6682\u65e0','','']
>>> foriinrange(sheet2.ncols):
printsheet2.row_values(7)[i]
无名
20.0
暂无
>>>
2、读取合并单元格的内容
这个是真没技巧,只能获取合并单元格的第一个cell的行列索引,才能读到值,读错了就是空值。
即合并行单元格读取行的第一个索引,合并列单元格读取列的第一个索引,如上述,读取行合并单元格"好朋友"和读取列合并单元格"暂无"只能如下方式:>>>printsheet2.col_values(4)[1]
好朋友
>>> printsheet2.row_values(7)[2]
暂无
>>> sheet2.merged_cells # 明明有合并的单元格,为何这里是空
[]
疑问又来了,合并单元格可能出现空值,但是表格本身的普通单元格也可能是空值,要怎么获取单元格所谓的"第一个行或列的索引"呢?
这就要先知道哪些是单元格是被合并的!
3、获取合并的单元格
读取文件的时候需要将formatting_info参数设置为True,默认是False,所以上面获取合并的单元格数组为空,>>> workbook = xlrd.open_workbook(r'F:\demo.xlsx',formatting_info=True)
>>> sheet2 = workbook.sheet_by_name('sheet2')
>>> sheet2.merged_cells
[(7,8,2,5), (1,3,4,5), (3,6,4,5)]
merged_cells返回的这四个参数的含义是:(row,row_range,col,col_range),
其中[row,row_range)包括row,不包括row_range,
col也是一样,
即(1, 3, 4, 5)的含义是:第1到2行(不包括3)合并,(7, 8, 2, 5)的含义是:第2到4列合并。
利用这个,可以分别获取合并的三个单元格的内容:>>>printsheet2.cell_value(1,4)#(1, 3, 4, 5)
好朋友
>>> printsheet2.cell_value(3,4)#(3, 6, 4, 5)
同学
>>> printsheet2.cell_value(7,2)#(7, 8, 2, 5)
暂无
发现规律了没?是的,获取merge_cells返回的row和col低位的索引即可! 于是可以这样一劳永逸:>>> merge = []
>>> for(rlow,rhigh,clow,chigh)insheet2.merged_cells:
merge.append([rlow,clow])
>>> merge
[[7,2], [1,4], [3,4]]
>>> forindexinmerge:
printsheet2.cell_value(index[0],index[1])
暂无
好朋友
同学
>>>
python写excel——xlwt
写excel的难点可能不在构造一个workbook的本身,而是填充的数据,不过这不在范围内。在写excel的操作中也有棘手的问题,比如写入合并的单元格就是比较麻烦的,另外写入还有不同的样式。这些要看源码才能研究的透。
我"构思"了如下面的sheet1,即要用xlwt实现的东西:
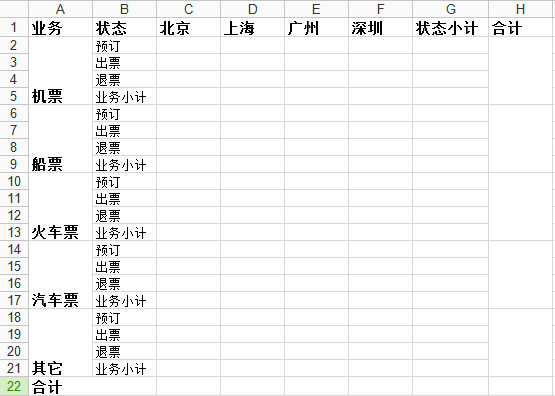
基本上看起来还算复杂,而且看起来"很正规",完全是个人杜撰。
代码如下:'''''
设置单元格样式
'''
defset_style(name,height,bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
# borders= xlwt.Borders()
# borders.left= 6
# borders.right= 6
# borders.top= 6
# borders.bottom= 6
style.font = font
# style.borders = borders
returnstyle
#写excel
defwrite_excel():
f = xlwt.Workbook() #创建工作簿
'''''
创建第一个sheet:
sheet1
'''
sheet1 = f.add_sheet(u'sheet1',cell_overwrite_ok=True)#创建sheet
row0 = [u'业务',u'状态',u'北京',u'上海',u'广州',u'深圳',u'状态小计',u'合计']
column0 = [u'机票',u'船票',u'火车票',u'汽车票',u'其它']
status = [u'预订',u'出票',u'退票',u'业务小计']
#生成第一行
foriinrange(0,len(row0)):
sheet1.write(0,i,row0[i],set_style('Times New Roman',220,True))
#生成第一列和最后一列(合并4行)
i, j = 1,0
whilei <4*len(column0)andj < len(column0):
sheet1.write_merge(i,i+3,0,0,column0[j],set_style('Arial',220,True))#第一列
sheet1.write_merge(i,i+3,7,7)#最后一列"合计"
i += 4
j += 1
sheet1.write_merge(21,21,0,1,u'合计',set_style('Times New Roman',220,True))
#生成第二列
i = 0
whilei <4*len(column0):
forjinrange(0,len(status)):
sheet1.write(j+i+1,1,status[j])
i += 4
f.save('demo1.xlsx')#保存文件
if__name__ =='__main__':
#generate_workbook()
#read_excel()
write_excel()
需要稍作解释的就是write_merge方法:
write_merge(x, x + m, y, w + n, string, sytle)
x表示行,y表示列,m表示跨行个数,n表示跨列个数,string表示要写入的单元格内容,style表示单元格样式。其中,x,y,w,h,都是以0开始计算的。
这个和xlrd中的读合并单元格的不太一样。
如上述:sheet1.write_merge(21,21,0,1,u'合计',set_style('Times New Roman',220,True))
即在22行合并第1,2列,合并后的单元格内容为"合计",并设置了style。
如果需要创建多个sheet,则只要f.add_sheet即可。
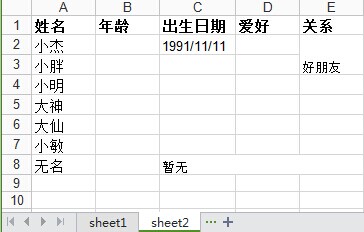
如在上述write_excel函数里f.save('demo1.xlsx') 这句之前再创建一个sheet2,效果如下:
代码也是真真的easy的了:'''''
创建第二个sheet:
sheet2
'''
sheet2 = f.add_sheet(u'sheet2',cell_overwrite_ok=True)#创建sheet2
row0 = [u'姓名',u'年龄',u'出生日期',u'爱好',u'关系']
column0 = [u'小杰',u'小胖',u'小明',u'大神',u'大仙',u'小敏',u'无名']
#生成第一行
foriinrange(0,len(row0)):
sheet2.write(0,i,row0[i],set_style('Times New Roman',220,True))
#生成第一列
foriinrange(0,len(column0)):
sheet2.write(i+1,0,column0[i],set_style('Times New Roman',220))
sheet2.write(1,2,'1991/11/11')
sheet2.write_merge(7,7,2,4,u'暂无')#合并列单元格
sheet2.write_merge(1,2,4,4,u'好朋友')#合并行单元格
f.save('demo1.xlsx')#保存文件
一、安装xlrd模块
到python官网下载http://pypi.python.org/pypi/xlrd模块安装,前提是已经安装了python 环境。
二、使用介绍
1、导入模块
import xlrd
2、打开Excel文件读取数据
data = xlrd.open_workbook('excelFile.xls')
3、使用技巧
获取一个工作表
table = data.sheets()[0] #通过索引顺序获取
table = data.sheet_by_index(0) #通过索引顺序获取
table = data.sheet_by_name(u'Sheet1')#通过名称获取
获取整行和整列的值(数组)
table.row_values(i)
table.col_values(i)
获取行数和列数
nrows = table.nrows
ncols = table.ncols
循环行列表数据
for i in range(nrows ):
print table.row_values(i)
单元格
cell_A1 = table.cell(0,0).value
cell_C4 = table.cell(2,3).value
使用行列索引
cell_A1 = table.row(0)[0].value
cell_A2 = table.col(1)[0].value
简单的写入
row = 0
col = 0
# 类型 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
ctype = 1 value = '单元格的值'
xf = 0 # 扩展的格式化
table.put_cell(row, col, ctype, value, xf)
table.cell(0,0) #单元格的值'
table.cell(0,0).value #单元格的值'
三、Demo代码
Demo代码其实很简单,就是读取Excel数据。# -*- coding: utf-8 -*-
importxdrlib ,sys
importxlrd
defopen_excel(file='file.xls'):
try:
data = xlrd.open_workbook(file)
returndata
exceptException,e:
printstr(e)
#根据索引获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的所以 ,by_index:表的索引
defexcel_table_byindex(file='file.xls',colnameindex=0,by_index=0):
data = open_excel(file)
table = data.sheets()[by_index]
nrows = table.nrows #行数
ncols = table.ncols #列数
colnames = table.row_values(colnameindex) #某一行数据
list =[]
forrownuminrange(1,nrows):
row = table.row_values(rownum)
ifrow:
app = {}
foriinrange(len(colnames)):
app[colnames[i]] = row[i]
list.append(app)
returnlist
#根据名称获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的所以 ,by_name:Sheet1名称
defexcel_table_byname(file='file.xls',colnameindex=0,by_name=u'Sheet1'):
data = open_excel(file)
table = data.sheet_by_name(by_name)
nrows = table.nrows #行数
colnames = table.row_values(colnameindex) #某一行数据
list =[]
forrownuminrange(1,nrows):
row = table.row_values(rownum)
ifrow:
app = {}
foriinrange(len(colnames)):
app[colnames[i]] = row[i]
list.append(app)
returnlist
defmain():
tables = excel_table_byindex()
forrowintables:
printrow
tables = excel_table_byname()
forrowintables:
printrow
if__name__=="__main__":
main()
基本的代码结构
data = xlrd.open_workbook(EXCEL_PATH)
table = data.sheet_by_index(0)
lines = table.nrows
cols = table.ncols
print u'The total line is %s, cols is %s'%(lines, cols)
读取某个单元格:
table.cell(x, y).value
x:行
y:列
行,列都是从0开始
* 时间类型的转换,把excel中时间转成python 时间(两种方式)
excel某个单元格 2014/7/8
xlrd.xldate_as_tuple(table.cell(2,2).value, 0) #转化为元组形式
(2014, 7, 8, 0, 0, 0)
xlrd.xldate.xldate_as_datetime(table.cell(2,2).value, 1) #直接转化为datetime对象
datetime.datetime(2018, 7, 9, 0, 0)
table.cell(2,2).value #没有转化
41828.0
源码查看:
# @param xldate The Excel number
# @param datemode 0: 1900-based, 1: 1904-based.
xldate_as_tuple(xldate, datemode)
输入一个日期类型的单元格会返回一个时间结构组成的元组,可以根据这个元组组成时间类型
datemode 有2个选项基本我们都会使用1900为基础的时间戳
##
# Convert an Excel date/time number into a datetime.datetime object.
#
# @param xldate The Excel number
# @param datemode 0: 1900-based, 1: 1904-based.
#
# @return a datetime.datetime() object.
#
def xldate_as_datetime(xldate, datemode)
输入参数和上面的相同,但是返回值是一个datetime类型,就不需要在自己转换了
当然这两个函数都有相应的逆函数,把python类型变成相应的excle时间类型。
脚本里先注明# -*- coding:utf-8 -*-
1. 确认源excel存在并用xlrd读取第一个表单中每行的第一列的数值。importxlrd, xlwt
importos
assertos.path.isfile('source_excel.xls'),"There is no timesheet exist. Exit..."
book = xlrd.open_workbook('source_excel.xls')
sheet=book.sheet_by_index(0)
forrowsinrange(sheet.nrows):
value = sheet.cell(rows,0).value
2. 用xlwt准备将从源表中读出的数据写入新表,并设定行宽和表格的格式。合并单元格2行8列后写入标题,并设定格式为之前定义的tittle_style。
使用的是write_merge。wbk = xlwt.Workbook(encoding='utf-8')
sheet_w = wbk.add_sheet('write_after', cell_overwrite_ok=True)
sheet_w.col(3).width =5000
tittle_style = xlwt.easyxf('font: height 300, name SimSun, colour_index red, bold on; align: wrap on, vert centre, horiz center;')
sheet_w.write_merge(0,2,0,8,u'这是标题',tittle_style)
3. 当函数中要用到全局变量时,注意加global。否则会出现UnboundLocalError:local variable'xxx' referenced before assignment.check_num =0
defcheck_data(sheet):
globalcheck_num
check_num=check_num+1
4. 写入日期和带格式的数值。原来从sheet中读取的日期格式为2014/4/10,处理后只保留日期并做成数组用逗号分隔后写入新的excel。date_arr = []
date=sheet.cell(row,2).value.rsplit('/')[-1]
ifdatenotindate_arr:
date_arr.append(date)
sheet_w.write_merge(row2,row2,6,6,date_num, normal_style)
sheet_w.write_merge(row2,row2,7,7,','.join(date_arr), normal_style)
5. 当从excel中读取的日期格式为xldate时,就需要使用xlrd的xldate_as_tuple来处理为date格式。先判断表格的ctype确实是xldate才能开始操作,否则会报错。之后date格式可以使用strftime来转化为string。如:date.strftime("%Y-%m-%d-%H")fromdatetimeimportdate,datetime
fromxlrdimportxldate_as_tuple
if(sheet.cell(rows,3).ctype ==3):
num=num+1
date_value = xldate_as_tuple(sheet.cell_value(rows,3),book.datemode)
date_tmp = date(*date_value[:3]).strftime("%d")
6. 最后保存新写的表
python怎么打开excel文件并处理_python处理excel文件相关推荐
- python中读写excel的扩展库_Python读写Excel文件第三方库汇总,你想要的都在这儿!...
常见库简介 xlrd xlrd是一个从Excel文件读取数据和格式化信息的库,支持.xls以及.xlsx文件. http://xlrd.readthedocs.io/en/latest/ 1.xlrd ...
- python打开文件注意事项_Python 中关于文件操作的注意事项
文件操作 #打开文件 f = open('要打开的文件路径',mode = 'r/w/a', encoding = '文件原来写入时的编码') #操作 data = f.read() #读取 f.wr ...
- python导入文件列行_python读写csv文件并增加行列的实例代码
python读写csv文件并增加行列,具体代码如下所示: # -*- coding: utf-8 -*- """ Created on Thu Aug 17 11:28: ...
- python为csv文件添加表头_python读csv文件时指定行为表头或无表头的方法
python读csv文件时指定行为表头或无表头的方法 pd.read_csv()方法中header参数,默认为0,标签为0(即第1行)的行为表头.若设置为-1,则无表头.示例如下: (1)不设置hea ...
- python处理excel的时间格式_Python处理excel数据,原来这么简单,VBA要尴尬了
工作中经常会遇到一些每天都要进行的重复操作,没一点技术含量,做起来却费时费力,还时不时出点小错.为应对这种情况,有些人会用VBA进行处理.但编辑了VBA功能的文件通用性不好,遇到领导.同事的excel ...
- python中的文件怎么处理_python 中有关文件处理
Python的文件处理 打开文件f = open ("path","mode") r 模式 以读的方式打开,定位到文件开头 , 默认的 mode.文件不存在直接 ...
- python文件后缀切割_python如何去除文件后缀
python去除文件后缀的方法: 1.调用os模块,用os模块的listdir()方法和walk()方法获取文件夹和文件名list_name = [] Makedir(outDir) for dir ...
- python复制excel内容和格式_Python对excel进行copy,包含单元格格式
#-*-coding=utf-8-*- ################################ #Func:读取零售集市数据字典,并重新写入excel,实现快速调整 #Author:winn ...
- python excel数据处理功能模块_Python 之Excel 数据处理
Python 之 Excel 数据处理 一.背景. 运维工作中,可能会遇到同事或者技术领导给Excel 数据进行,数据抽取汇总或者进行运维自动化提供元数据使用,针对以上场景我们需要进行python 处 ...
- python的脚本扩展名是什么_Python的脚本文件扩展名为()。
[单选题]在Python中可使用readline([size])来读取文件中的数据,如果参数size省略,则读取文件中的(). [单选题]佳能的标志属于哪种形式? [单选题]在open函数中访问模式参 ...
最新文章
- 【F#2.0系列】概述
- oracle查询一个字符串所在表
- 全球与中国人脸语音生物识别市场”十四“五规模状况与前景趋势分析报告2021-2027年版
- POJ 3084 Panic Room
- Flutter入门:动画相关
- asp.net core 系列之webapi集成EFCore的简单操作教程
- Fastjson - 详解SerializeFilter,格式化对象字段
- 计算机专项能力局域网管理,全国计算机信息技术考试局域网管理(Windows NT平台)管理员级考试考试大纲...
- Android 开机充电图标和充电动画
- 电脑维修知识:电脑常见故障维修大全及解决方法
- 520用Java制作一个表白app
- dym 微服务 快速开发框架
- C# 操作American_America.US7ASCII编码的Oracle数据库出现乱码的问题。
- 一位女测试工程师的成长
- 懒人笔记—python基础语法1
- 宝宝营养粥及如何提高宝宝睡眠
- springboot奥运会志愿者管理系统
- 科学中有故事,故事中有科学
- 最强汉字得到首字母拼音java版
- 老男孩mysql运维dba实战21部完整版_老男孩Mysql DBA高级运维系列课程(16部)
热门文章
- 面试官问我平时怎么看源码的,我把这篇文章甩给他了。
- 一年前3-1对应阿里P7,贬值得有点快,但说对标好像差点意思...
- 再有人问你volatile是什么,把这篇文章也发给他。
- 微信小程序,引爆新热点!JEECG社区小程序实战培训,业内首发,实战干货!
- 关于freemarker的classic_compatible属性的使用场景和解决
- linux下源码安装官方最新版Python
- 学习vi和vim编辑器(1):vi文本编辑器
- Java性能调优笔记
- Programming Computer Vision with Python (学习笔记十二) 1
- 工作流性能优化(敢问activiti有扩展性?)(3)