【统计学习2】线性回归:RSS,TSS,T检测,F检测,假设检验
++++++++++++++++++++++
参考众多文章
++++++++++++++++++++++
第一:假设检验
以抛硬币来说
- H0 假设【假设】:硬币是公平【出现正反概率各为1/2】
- Ha 假设【检验】:硬币是有问题
整个假设检验过程,是在H0假设条件下,进行试验,如果推导出自相矛盾的结论,那么就拒绝H0假设。
【所谓的自相矛盾,试验结果,在H0假设条件下,出现的概率极小。】
p值:在假设原假设(H0)正确时,出现现状或更差的情况的概率。
1.1 H0假设下,我们知道抛硬币,出现正面的次数,符合二项式分布。
a、我们抛了10次硬币。
结果出现8次正面。
b、查询二项分布表,单侧p值【8,9,10】
p(8/9/10)=0.05
这个结果怎么解读?
在H0假设条件下【硬币公平的】,抛出8次正面及更极端的情况的单侧p值是0.05,如果显著水平0.05,那么我们拒绝改H0假设,而认为硬币是有问题的。
1.2 既然抛了8次正面,为啥还有加上9次正面,10次正面,这两个更极端的的概率?
- 一是:p值的定义如此。
- 二是,一般分布,不好求单点发概率,求区间的概率就很简单,就是那个面积。
![]()
1.3 显著水平0.05
其实显著水平是主观定义的值。
比如我们定义显著水平为0.01。
那么上例试验p值=0.05,小于显著水平0.01,那么就意味我们没办法拒绝H0假设,需要更多的试验,等p值小于这个0.01的 显著水平,我们就可以拒绝H0假设了。
第二:T检验
2.1、两块麦田,甲和乙,甲麦田传统工艺,乙麦田改进工艺。
已知甲样本株产量均值μ0=100,样本标准差σ【标准差未知】;
乙样本n,样本株产量均值X=120,样本标准差s,公式的xi是乙的单株产量【可以把乙的每个单株产量看作是单株均值产量】,x均值是甲的均值,因为甲的总体不知,又因为我们h0假设认为甲乙来自一个总体,所有用乙的单株产量暂代甲的单株常量。
![]()
2.2、假设检验
- H0假设【假设】:乙没有改进,甲乙都在一个分布下
- Ha假设【检验】:在H0假设下,乙均值X=120,样本标准差s能不能发生?
已知甲服从µ0=100,标准差 σ未知的正态分布,N(μ0,σ^2)。
![]()
2.3、t值的由来
t统计量公式:
![]()
a、分子=X - μ0,根据正太分布图,跨度为甲的标准差 σ,为了消除跨度的影响,我们将分子除以标准差,得(X - μ0)/σ,又因为甲的σ未知,用乙的s替代,最终为(X - μ0)/s
【由于甲的标准差 σ未知,但是我们假设甲乙服从同一个分布,故乙的标准差s来近似。】
****************************************************************************************************************************
我们都以甲乙两个样本的均值、标准差,来近似各自母体的均值、标准差。
****************************************************************************************************************************
b、分母s/√n 意思是:由样本推断总体均值的标准误差(standard error)。
解释:乙样本数,如果极多,那么我们显而易见,乙这个X=120,明细说明乙改进了产量。
为了在公式中体现样本个数的n的影响,所以我们让分母的s,除以根号n,从而减小分母值,最终使t值增大,来体现样本n的影响。
2.4、t分布
以上我们求出了t值,那么如何知道t值对应的p值?
a、概率密度函数
![]()
b、分布图
![]()
根据自由度v=n-1,查表得出对应的p值,看在相应的显著水平下,能否拒绝H0原假设。
第三:最小二乘
****************************************************************************************************************************
1、标准差(Standard Deviation )【反映的是数据点的波动情况】:是表示个体间变异大小的指标,反映了整个样本对样本平均数的离散程度,是数据精密度的衡量指标。
2、标准误差(Standard error)【反映的是均值的波动情况】:指在抽样试验(或重复的等精度测量)中,常用到样本平均数的标准差;反映样本平均数对总体平均数的变异程度,从而反映抽样误差的大小,是量度结果精密度的指标。
解释:随着样本数(或测量次数)n的增大,标准差趋向某个稳定值,即样本标准差s越接近总体标准差σ,而标准误则随着样本数(或测量次数)n的增大逐渐减小,即样本平均数越接近总体平均数μ;
3、置信区间:是对样本的某个总体参数的区间估计,这个参数的真实值有一定概率落在测量结果的周围的程度。
4、公式
a、标准差公式:
![]()
b、标准误差公式:
设n个测量值的误差为E1、E2……En,则这组测量值的标准误差σ等于:
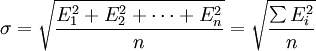
其中,E = Xi − T,式中:E-误差;Xi-测定值;T-真实值。
由于被测量的真值是未知数,各测量值的误差也都不知道,因此不能按上式求得标准误差。
测量时能够得到的是算术平均值,它最接近真值(N),而且也容易算出测量值和算术平均值之差,称为残差(记为v)。理论分析表明可以用残差v表示有限次(n次)观测中的某一次测量结果的标准误差σ,其计算公式为:
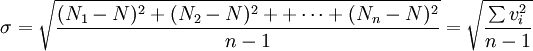
对于一组等精度测量(n次测量)数据的算术平均值,其误差应该更小些。理论分析表明,它的算术平均值的标准误差。有的书中或计算器上用符号s表示):

c、标准误是标准差的1/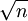
d、置信区间
β1的95%置信区间=【β1-2SE(β1),β1+2SE(β1)】
****************************************************************************************************************************
最小二乘法:通过RSS最小,确认系数项和截距项的值。
实际中,我们可以得到一批观察数据,从中计算最小二乘线的参数,但是总体的回归直线观察不到。
我们有一组【Y,X】的观测值,共有n个值
其中Y变量对应:y1,y2,y3,,,,,,,,,,,,,yn
X变量对应:x1,x2,x3,,,,,,,,,,,,,,,xn
a、样本均值估计总体均值
那么我们这单一的一组y变量均值µ0,对y总体真实均值µ的估计有多准确?偏离有多远?
整体的回归方程:标准偏差SE(µ0)=σ / √n
变型:Var(µ0)=σ^2/n
其中:分子σ,是总体观察值yi均值的标准差,由残差标准误RSE估计;分母是样本数量n的根号值。
标准偏差SE(µ0),告诉我们估计 样本均值µ0,偏离总体真实均值µ平均量。
标准差公式,告知我样本数量n越多,偏差越小。
b、探究最小二乘得到的β0、β1,与总体真实的β0、β1接近程度
SE(β0)
SE(β1)
c、对标准偏差SE(µ0)的估计是残差标准误RSE/√n【意思是模型正确,且β0、β1真实值,但是依然有偏离】。
总体观察值yi均值的标准差σ的方差σ^2,由RSS来估计。
第四:线性回归名词
1、残差平方和RSS(residual sum of squares)【别称SSE(Sum of Squares for Error)】
RSS = Σi=1n (yi - yi^)2
![]()
2、残差标准误RSE(residual standard error)
RSE = √(RSS/(n-2))
3、回归平方和SSR(sum of squares for regression)【别称SSM(Sum of Squares for Model)】
【别称ESS(explained sum of squares) 】
SSR = Σi=1n (yi^ - y)2
4、总平方和SST(Sum of Squares Total)
SST = Σi=1n (yi - y)2
5、一般情况下:总平方和=回归平方和 + 残差平方和
SST=SSR + RSS
证明:维基的证明
解释:SST总平方和表示,数据的总差异,我们知道总差异,两部分组成,可解释的+不可解释的。
SSR回归平方和表示,数据可解释的差异【也就是回归方程能解释的差异】
RSS残差平方和,表示不可解释的差异。【回归方程无法解释的】
6、自由度【p回归系数的个数】
RSS残差平方和的自由度 dfr = n -p -1
SSR回归平方和的自由度 dfm= p
总平方和的自由都 dft = n -1
dft = dfr + drm
============================================================================
在统计学中,自由度指的是计算某一统计量时,取值不受限制的变量个数。通常df=n-k。其中n为样本含量,k为被限制的条件数或变量个数,或计算某一统计量时用到其它独立统计量的个数。在估计总体的方差时,使用的是离差平方和。只要n-1个数的离差平方和确定了,方差也就确定了;因为在均值确定后,如果知道了其中n-1个数的值,第n个数的值也就确定了。这里,均值就相当于一个限制条件,由于加了这个限制条件,估计总体方差的自由度为n-1。
============================================================================
7、残差平方和均方【不可解释的方差】
MSR(Mean of Squares for residual) = RSS / DFR
回归平方和均方【可解释的方差】
MSM( Mean of Squares for Model) = SSR /DFM
第五:线性回归和方差分析
1、方差分析中的分析变量实际上就是线性回归中的因变量,方差分析中的分组变量就是线性回归中的自变量。
线性回归和方差分析的因变量是一样的,都是连续型资料,
自变量就不一样了,方差分析中是分类变量,而线性回归中是连续型数据。
2、区别对比【研究ABC三种药物,对肺活量影响,分三组,每组5个试验个体,目的自然是看三种药物是否有区别,也就是看3组因变量间的差异是否显著】
a、方差分析
![]()
b、改成线性回归的样子
![]()
3、解释
怎么样,这种形式跟线性回归的形式差不多了吧?
y就是因变量,x就是自变量。唯一与线性回归不同的地方是:线性回归中的x和y是一一对应的。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
【方差齐性检测【不同样本的方差大致相等】,线性回归中,因为我们无法对【x1,y1】这对数据做方差齐性分析,因为x1只对应一个y1,但是真实总体上,一个x1值可以对应无数个y1的值,只是总体谁也不知。实际操作中,我们只好看残差分布图,如果是随机分布,那么我们认为满足方差齐性检测。】
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
而方差分析的x和y是一对多的,即1个x对应多个y值,但这不影响分析。
其实即使在线性回归中,偶尔也会出现一对多的现象的。比如体重对肺活量的影响,如果有好几个人体重相同而肺活量不同,就出现了一对多的现象。这就跟方差分析更像了。
最后加点总结性的、理论性的东西,一般线性模型的形式大致可以这样:
y=α+βx+ε,
这个其实大家都应该很熟悉了,在统计教材中的线性回归章节中一般都有这个公式。这里的y就是因变量,x就是自变量,但是这里需要注意的就是,x是分类变量的时候,就变成了方差分析的形式了,当x是连续型变量的时候,就变成了线性回归的形式了。
第六:线性回归的T检验
检测对象:单个回归系数参数是否显著为0。
构造原理:检测的系数是否足够接近0值?服从的分布是t分布。
前提条件:方差齐性检测【不同样本的方差大致相等】,线性回归中,因为我们无法对【x1,y1】这对数据做方差齐性分析,因为x1只对应一个y1,但是真实总体上,一个x1值可以对应无数个y1的值,只是总体谁也不知。实际操作中,我们只好看残差分布图,如果是随机分布,那么我们认为满足方差齐性检测。
如果残差分布呈有规律,那么我们要做变换,比如log变换,,各自核函数等等
线性回归:y = β1 * x + β0 + e
y = 8*x + 6 + e
- H0假设【假设】:β1=0
- Ha假设【检验】:如果在β1=0条件下,求出β1的值是否极小概率的事情?
T检验的原始公式:
![]()
线性回归T检验公式:
t=(β1 - 0)/ SE(β1 )
其中:SE(β1 ) 指的是回归系数的β1的标准偏差。
第七:线性回归的F检
============================================================================
定义:F检验又叫方差齐性检验,主要通过比较两组数据的方差 S^2,以确定他们的分布是否有显著性差异。至于两组数据之间是否存在系统误差,则在进行F检验并确定它们的分布没有显著性差异之后,再进行t检验。
其他解释:其中一点是看残差方差与样本方差相比是不是足够缩小,说明大部分样本信息已经包含在了主体模型当中。
============================================================================
构造原理:从离差平方和分解公式出发,以回归平方和均方/残差平方和均方比值,推断解释变量整体对被解释变量的线性关系是否显著。
检测对象:整个方程所有回归系数是否全部显著为0的检测。
线性回归:y = β0 + β1 * x + β2 * x ,,, βp * x + e
- H0假设【假设】:β1=β2=βp=0
- Ha假设【检验】:至少有一个β不为0, H0假设【假设】条件下,F检验呈现卡方分布。
F检验公式=MSM/MSR
=(SSR/p) / (RSS/n-p-1)
= 可以解释的 / 不明原因的【个体带来的残差】
F检测的结果,查表p值,看能否拒绝原假设。
如果拒绝,那么说明至少有一个β不为0.
此外:一元线性回归中,F=T^2。参考链接:百度文档
【统计学习2】线性回归:RSS,TSS,T检测,F检测,假设检验相关推荐
- 基于统计学习---面向新闻的发生地与提及地检测
基于统计学习---面向新闻的发生地与提及地检测 一.摘要 二.流程 2.1- 数据构建及数据预处理 2.2- 全国5级地址实体二叉树 2.3- 命名实体识别相关算法 2.4- 新闻中特征信息分析 2. ...
- 统计学习导论(ISLR)(三):线性回归(超详细介绍)
统计学习导论(ISLR) 参考资料: The Elements of Statistical Learning An Introduction to Statistical Learning 统计学习 ...
- 【统计学习系列】多元线性回归模型(六)——模型拟合质量评判:RMSE、R方、改进R方、AIC\BIC\SIC
文章目录 1. 前文回顾 2. 一些引理与离差平方和分解定理(可略) 2.1 引理1 2.2 引理2 2.3 引理3 2.4 平方和分解定理 3. 拟合优度评价指标I--均方根误差(RMSE) 4. ...
- 【统计学习系列】多元线性回归模型(五)——参数与模型的显著性检验:t检验与F检验
文章目录 1. 前文回顾 2. 单参数显著性检验--t检验 2.1 问题的提出 2.2 检验统计量--t统计量的构造 2.3 拒绝域的构造 2.4 浅谈p值 3. 回归方程显著性检验--F检验 3.1 ...
- 统计学习导论之R语言应用(三):线性回归R语言代码实战
统计学习导论(ISLR) 参考资料 The Elements of Statistical Learning An Introduction to Statistical Learning 统计学习导 ...
- 【统计学习系列】多元线性回归模型(四)——模型的参数估计II:区间估计
文章目录 1. 前文回顾 2. ***β*** 的区间估计 2.1 t统计量的构造 2.2 估计区间 3. *σ* 的区间估计 3.1 卡方统计量的构造 3.2 估计区间 4. ***y*** 的区间 ...
- 【统计学习3】线性回归:R方(R-squared)及调整R方(Adjusted R-Square)
第一:R方(R-squared) 定义:衡量模型拟合度的一个量,是一个比例形式,被解释方差/总方差. 公式:R-squared = SSR/TSS =1 - RSS/TSS 其中:TSS是执行回归分 ...
- 机器学习和统计学习的区别:10个统计分析方法
来源:THU数据派(ID:datapi) 无论你在数据科学中是何种立场,你都无法忽视数据的重要性,数据科学家的职责就是分析.组织和应用这些数据. 著名求职网站 Glassdoor 根据庞大的就业数据和 ...
- R统计绘图-多元线性回归(最优子集法特征筛选及模型构建,leaps)
此文为<精通机器学习:基于R>的学习笔记,书中第二章详细介绍了线性回归分析过程和结果解读. 回归分析的一般步骤: 1. 确定回归方程中的自变量与因变量. 2. 确定回归模型,建立回归方程. ...
最新文章
- 静态网页与动态的区别
- 创建型模式之Builder模式
- 【推荐系统】面向科研的推荐系统Benchmark诞生!
- java语言的编译器可以用python_jython实现java运行python代码
- 高并发高性能服务器是如何实现的
- Postgres-XL数据库集群在RedHat/Fedora/Oracle/CentOS平台上的搭建
- Python爬虫基础(三)urllib2库的高级使用
- 为什么易燥易怒以及柔润相处的练习
- python精彩编程200例-200G的Python初高级教程+项目实战案例源码,让你做有钱途的人才...
- [Spark]-结构化数据查询之自定义UDAF
- .NET开发设计模式-获取某个接口下面所有的派生类
- 喜报!木兰宽松许可证通过OSI认证,成为首个中英双语国际开源许可证!
- 用JS写一个电影《黑客帝国》显示屏黑底绿字雨风格的唐诗欣赏器
- php工程师等级划分,PCB工程师的这四个等级,你都修炼到了什么级别?
- HTML、css、js 特殊字符(空格符号)
- 4.12作业--CSS
- CircRNA–miRNA–mRNA调控网络分析
- 钉钉添加代收邮箱地址
- C++经典算法题-洗扑克牌(乱数排列)
- 神经网络模型量化论文小结
热门文章
- mysql修改data文件位置
- 嵌入式QT基础视频教程免费分享!
- phpinfo输出的PHP版本和php -v版本不一致 宝塔切换无效
- python实现操作PG数据库
- 查找缺失的DLL工具Dependency Walker
- sync.Pool 问题argument should be pointer-like to avoid allocations (SA6002)
- 基于matlab的LDPC编译码误码率仿真,调制方式为64QAM
- Android 题目动态存储+倒计时功能实现
- 国内首个基于 Rust 语言的 RPC 框架 — Volo 正式开源!
- js 让鼠标右下角有一排小字_JavaScript浮动广告代码,容纯DIV/CSS对联漂浮广告代码,兼容性非常好的js右下角与漂浮广告代码...