SQL 难点解决:直观分组
1、 对位分组
示例 1:按顺序分别列出使用 Chinese、English、French 作为官方语言的国家数量
MySQL8:
with t(name,ord) as (select 'Chinese',1
union all select 'English',2
union all select 'French',3)
select t.name, count(countrycode) cnt
from t left join world.countrylanguage s on t.name=s.language
where s.isofficial='T'
group by name,ord
order by ord;
注意:表的字符集和数据库会话的字符集要保持一致。
(1) show variables like 'character_set_connection'查看当前会话字符集
(2) show create table world.countrylanguage查看表的字符集
(3) set character_set_connection=[字符集]更新当前会话字符集
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.countrylanguage where isofficial='T'") |
| 3 | [Chinese,English,French] |
| 4 | =A2.align@a(A3,Language) |
| 5 | =A4.new(A3(#):name, ~.len():cnt) |
A1: 连接数据库
A2: 查询出所有官方语言的记录
A3: 需要列出的语言
A4: 将所有记录按Language对位到A3相应位置
A5: 构造以语言和使用此语言为官方语言的国家数量的序表
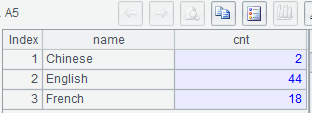
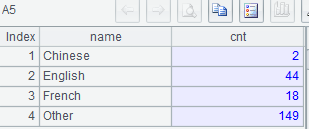
示例 2:按顺序分别列出使用 Chinese、English、French 及其它语言作为官方语言的国家数量
MySQL8:
with t(name,ord) as (select 'Chinese',1 union all select 'English',2
union all select 'French',3 union all select 'Other', 4),
s(name, cnt) as (
select language, count(countrycode) cnt
from world.countrylanguage s
where s.isofficial='T' and language in ('Chinese','English','French')
group by language
union all
select 'Other', count(distinct countrycode) cnt
from world.countrylanguage s
where isofficial='T' and language not in ('Chinese','English','French')
)
select t.name, s.cnt
from t left join s using (name)
order by t.ord;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.countrylanguage where isofficial='T'") |
| 3 | [Chinese,English,French,Other] |
| 4 | =A2.align@an(A3.to(3),Language) |
| 5 | =A4.new(A3(#):name, if(#<=3,~.len(), ~.icount(CountryCode)):cnt) |
A4: 将所有记录按Language对位到A3.to(3)相应位置,并追加一组用于存放不能对位的记录
A5: 第4组计算不同CountryCode的数量
2、 枚举分组
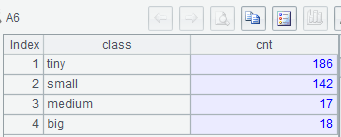
示例 1:按顺序列出各类型城市的数量
MySQL8:
with t as (select * from world.city where CountryCode='CHN'),
segment(class,start,end) as (select 'tiny', 0, 200000
union all select 'small', 200000, 1000000
union all select 'medium', 1000000, 2000000
union all select 'big', 2000000, 100000000
)
select class, count(1) cnt
from segment s join t on t.population>=s.start and t.population<s.end
group by class, start
order by start;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | =${string([20,100,200,10000].(~*10000).("?<"/~))} |
| 4 | [tiny,small,medium,big] |
| 5 | =A2.enum(A3,Population) |
| 6 | =A5.new(A4(#):class, ~.len():cnt) |
A3: ${…}宏替换,以大括号内表达式的结果作为新表达式进行计算,结果为序列["?<200000","?<1000000","?<2000000","?<100000000"]
A5: 针对 A2 中每条记录,寻找 A3 中第 1 个成立的条件,并追加到对应的组中
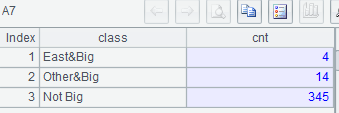
示例 2:列出华东地区大型城市数量、其它地区大型城市数量、非大型城市数量
MySQL8:
with t as (select * from world.city where CountryCode='CHN')
select 'East&Big' class, count(*) cnt
from t
where population>=2000000
and district in ('Shanghai','Jiangshu', 'Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Other&Big', count(*)
from t
where population>=2000000
and district not in ('Shanghai','Jiangshu','Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Not Big', count(*)
from t
where population<2000000;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | [Shanghai,Jiangshu, Shandong,Zhejiang,Anhui,Jiangxi] |
| 4 | [?(1)>=2000000 && A3.contain(?(2)), ?(1)>=2000000 && !A3.contain(?(2))] |
| 5 | [East&Big,Other&Big, Not Big] |
| 6 | =A2.enum@n(A4, [Population,District]) |
| 7 | =A6.new(A5(#):class, A6(#).len():cnt) |
A5: enum@n将不满足 A4 中所有条件的记录存放到追加的最后一组中
示例 3:列出所有地区大型城市数量、华东地区大型城市数量、非大型城市数量
MySQL8:
with t as (select * from world.city where CountryCode='CHN')
select 'Big' class, count(*) cnt
from t
where population>=2000000
union all
select 'East&Big' class, count(*) cnt
from t
where population>=2000000
and district in ('Shanghai','Jiangshu','Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Not Big' class, count(*) cnt
from t
where population<2000000;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | [Shanghai,Jiangshu, Shandong,Zhejiang,Anhui,Jiangxi] |
| 4 | [?(1)>=2000000, ?(1)>=2000000 && A3.contain(?(2))] |
| 5 | [Big, East&Big, Not Big] |
| 6 | =A2.enum@rn(A4, [Population,District]) |
| 7 | =A6.new(A5(#):class, A6(#).len():cnt) |
A6: 若A2中记录满足A4中多个条件时,enum@r会将其追加到对应的每个组中
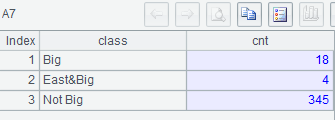
3、 返回值直接作为序号进行定位分组
示例 1: 按顺序列出各类型城市的数量
MySQL8: 参见“枚举分组”中 SQL
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | =[0,20,100,200].(~*10000) |
| 4 | [tiny,small,medium,big] |
| 5 | =A2.group@n(A3.pseg(Population)) |
| 6 | =A5.new(A4(#):class, ~.len():cnt) |
A5: 先计算 A2.Population 在 A3 中段号,然后根据段号进行定位分组
4、 原序保持下的相邻记录分组
示例 1: 列出前 10 届奥运金牌榜 (olympic 表中只有历届成绩前 3 名的信息,且没有奖牌完全相同的情况)
MySQL8:
with t1 as (select *,rank() over(partition by game order by gold*1000000+silver*1000+copper desc) rn from olympic where game<=10)
select game,nation,gold,silver,copper from t1 where rn=1;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query("select * from olympic where game<=10 order by game, gold*1000000+silver*1000+copper desc") |
| 3 | =A2.group@o1(game) |
A3: 按原序分到各组,每组取第 1 条记录组成新序表
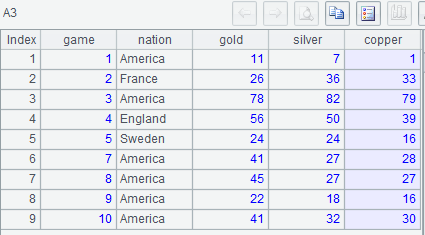
示例 2: 求奥运会国家总成绩蝉联第 1 的最长届数
MySQL8:
with t1 as (select *,rank() over(partition by game order by gold*1000000+silver*1000+copper desc) rn from olympic),
t2 as (select game,ifnull(nation<>lag(nation) over(order by game),0)neq from t1 where rn=1),
t3 as (select sum(neq) over(order by game) acc from t2),
t4 as (select count(acc) cnt from t3 group by acc)
select max(cnt) cnt from t4;
t1: 求出成绩排名
t2: 列出历届第1名,并根据nation是否与上届不同置标志neq(不同置1,相同置0)
t3: 累积标志neq到acc,可以保证相邻nation相同的acc相同,不相邻nation的acc不相同
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query("select * from olympic order by game, gold*1000000+silver*1000+copper desc") |
| 3 | =A2.group@o1(game) |
| 4 | =A3.group@o(nation) |
| 5 | =A4.max(~.len()) |
A4: 将相邻nation相同的记录按原序分到同组
A5: 求各组长度的最大值即最大届数

示例3:列出奥运会总成绩排名第一最长蝉联时的各届信息
MySQL:
with t1 as (select *,rank() over(partition by game order by gold*1000000+silver*1000+copper desc) rn from olympic),
t2 as (select *,ifnull(nation<>lag(nation) over(order by game),0)neq from t1 where rn=1),
t3 as (select *, sum(neq) over(order by game) acc from t2),
t4 as (select acc,count(acc) cnt from t3 group by acc),
t5 as (select * from t4 where cnt=(select max(cnt) cnt from t4))
select game,nation,gold,silver,copper from t3 join t5 using (acc);
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query("select * from olympic order by game, gold*1000000+silver*1000+copper desc") |
| 3 | =A2.group@o1(game) |
| 4 | =A3.group@o(nation) |
| 5 | =A4.maxp(~.len()) |
A5: 求出长度最大组
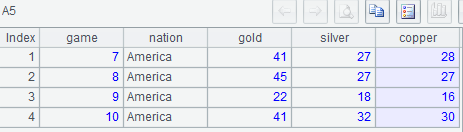
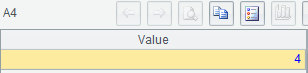
示例 4:求奥运会前3名金牌总数连续增长的最大届数
MySQL8:
with t1 as (select game,sum(gold) gold from olympic group by game),
t2 as (select game,gold, gold<=lag(gold,1,-1) over(order by game) lt from t1),
t3 as (select game, sum(lt) over(order by game) acc from t2),
t4 as (select count(*) cnt from t3 group by acc)
select max(cnt)-1 cnt from t4;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query("select game,sum(gold) gold from olympic group by game order by game") |
| 3 | =A2.group@i(gold<=gold[-1]) |
| 4 | =A3.max(~.len())-1 |
A3: 根据条件值按原序分组,若gold小于等于上一个gold则产生新分组
转载于:https://blog.51cto.com/12749034/2323803
SQL 难点解决:直观分组相关推荐
- SQL 难点解决:循环计算
SQL 虽然可以对集合中的记录进行循环计算, 但在循环计算过程中利用中间变量.同时计算多个值.前后记录访问.减少循环次数等方面差强人意.而集算器 SPL 则要直观许多,可以按自然思维习惯写出运算.这里 ...
- SQL 难点解决:集合及行号
[摘要] SQL 虽然有集合概念,但对于集合运算.特别是有序集合运算,提供的支持却很有限,经常要采用很费解的思路才能完成,计算效率也不佳.而集算器 SPL 在方面则要直观许多,可以按自然思维习惯写出运 ...
- sql多表查询分组最大值
问题描述:有三张表:学生表Student(id,name),id为主键:课程表Subject(id,name),id为主键:分数表score(studentid,subjectid,score),其中 ...
- weblogic.jdbc.wrapper.Blob_oracle_sql_BLOB cannot be cast to oracle.sql.BLOB 解决方法
weblogic.jdbc.wrapper.Blob_oracle_sql_BLOB cannot be cast to oracle.sql.BLOB 解决方法 参考文章: (1)weblogic. ...
- 使用Source Safe for SQL Server解决数据库版本管理问题
使用Source Safe for SQL Server解决数据库版本管理问题 参考文章: (1)使用Source Safe for SQL Server解决数据库版本管理问题 (2)https:// ...
- mdcsoft服务器网络安全解决方案-SQL注入解决
{ 推荐大家,SQL注入最牛的解决办法在http://blog.mdcsoft.cn/archives/200805/46.html 太强大了,直接从IIS入口直接过滤掉了非法请求,mdcsoft-i ...
- 50 个 Redis 必备知识:基础知识,架构、调优和监控知识及难点解决
本文包括:30 个 Redis 基础知识:10个 Redis 架构和运维必懂的知识:Redis 调优.监控知识和10个具体应用难点. 30 个 Redis 基础知识 1.Redis支持哪几种数据类型? ...
- Sql Server 解决“用户登录失败,错误编18456”
Sql Server 解决"用户登录失败,错误编号18456" 1.说明 2.其他错误信息 排错分析 1.说明 因密码或用户名错误而使身份验证失败并导致连接尝试被拒时,类似以下内容 ...
- SQL:在使用分组函数统计并进行分组时,发现有两条除了统计数据不一样,其他都一样的数据
场景:需要根据字段sex对表中的数据进行分组,并统计不同sex的总数,在运行 select sex,count(1) num from a group by sex;语句时发现结果如下图: 经检查发现 ...
最新文章
- 胶囊网络为何如此热门?与卷积神经网络相比谁能更胜一筹?
- myeclipse转maven项目
- 从基础设施到云原生应用,全方位解读阿里云原生新锐开源项目
- java操作redis redis连接池
- httpclient依赖_.NetCore 3.1高性能微服务架构:封装调用外部服务的接口方法HttpClient客户端思路分析...
- java 集合数组 例子_Java数组元素去重(不使用集合)(示例代码)
- Software caused connection abort: socket write error 问题原因推测
- mysql outfile 权限_MYSQL解决select ... into outfile '..' mysql写文件权限问题 Can't create/write to file...
- 联想硬盘保护安装linux,【原创参赛】联想硬盘保护系统 (详细说明)
- android开发点击部分文字颜色,墨迹天气推Android版 单城数据流量不足0.5k
- 卷积可视化网站---CNN初学者的神器
- 痛失移动支付的翼支付,未来仍存四大机会?
- SE-ResNet34对结构性数据进行多分类
- 【阅读笔记】联邦学习实战——联邦个性化推荐案例
- 云ERP来的正是时候!
- 微信小程序如何申请注册教程
- 【Java设计模式】简单学装饰模式——来杯咖啡,先糖后奶
- 【Python+Pycharm】单词底部有波浪线,提示typo in word时
- 一键获取主图设计模板的工具平台
- mw150uh linux驱动下载,水星MW150UH无线网卡驱动