ARM7 ARM 11
ARM7是冯诺依慢结构 ARM9、ARM11是哈佛结构,所以性能要高一点。 ARM9和ARM11大多带内存管理器,跑操作系统好一点,ARM7适合裸奔。 不跑操作系统,价格低一点的:ARM7、cortex-M3等等。 性价比高,可跑也可不跑操作系统的:ARM9、cortex-Rx等等。 性能高的,通常要跑操作系统的:ARM10、ARM11、Cortex-A8等等。 成熟的:ARM7\ARM9\ARM11。 发展趋势:Cortex-A、Cortex-R、Cortex-M。 其实弄ARM大多还是在嵌入式领域,不过现在很多上网本也开始ARM了,估计与intel竞争的时候快来了。 2410和2440都是三星公司生产的基于ARM9内核的芯,资源上相差不大,2440多了camara接口,速度要更快一些。上边讲的版本是指内核版本,而各个公司出的发行号又各有不同。比如三星的2440,atmel的9260.就好比linux的内核版本号与红帽子的发行号不一样是一个道理。
ARM9和ARM11大多带内存管理器,跑操作系统好一点,ARM7适合裸奔。
RM7是冯诺依慢结构,三级流水线结构
ARM9、ARM11是哈佛结构,5级流水线结构,所以性能要高一点。
ARM9和ARM11大多带内存管理器,跑操作系统好一点,ARM7适合裸奔。
我们惯称的 ARM9系列中又存在ARM9与ARM9E两个系列,其中ARM9 属于ARM v4T架构,典型处理器如ARM9TDMI和ARM922T;而ARM9E属于ARM v5TE架构,典型处理器如ARM926EJ和ARM946E。因为后者的芯片数量和应用更为广泛,所以我们提到ARM9的时候更多地是特指ARM9E系 列处理器(主要就是ARM926EJ和ARM946E这两款处理器)。下面关于ARM9的介绍也是更多地集中于ARM9E。
ARM7处理器和ARM9E处理器的流水线差别
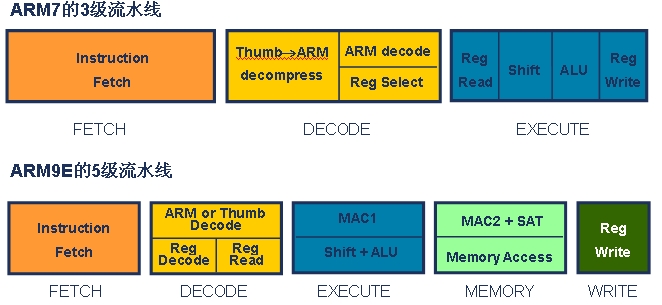
对嵌入式系统设计者来说,硬件通常是第一考虑的因素。针对处理器来说,流水线则是硬件差别的最明显标志,不同的流水线设计会产生一系列硬件差异。让我们来比较一下ARM7和ARM9E的流水线,如图1。
可 以看到ARM9E从ARM7的3级流水线增加到了5级,ARM9E的流水线中容纳了更多的逻辑操作,但是每一级的逻辑操作却变得更为简单。比如原来 ARM7的第三级流水,需要先内部读取寄存器、然后进行相关的逻辑和算术运算,接着处理结果回写,完成的动作非常复杂;而在ARM9E的5级流水中,寄存 器读取、逻辑运算、结果回写分散在不同的流水当中,使得每一级流水处理的动作非常简洁。这就使得处理器的主频可以大幅度地提高。因为每一级流水都对应 CPU的一个时钟周期,如果一级流水中的逻辑过于复杂,使得执行时间居高不下,必然导致所需的时钟周期变长,造成CPU的主频不能提升。所以流水线的拉 长,有利于CPU主频的提高。在常用的芯片生产工艺下,ARM7一般运行在100MHz左右,而ARM9E则至少在200MHz以上。
ARM9E处理器的存储器子系统
像ARM926EJ 和ARM946E这两个最常见的ARM9E处理器中,都带有一套存储器子系统,以提高系统性能和支持大型操作系统。如图2所示,一个存储器子系统包含一个 MMU(存储器管理单元)或MPU(存储器保护单元)、高速缓存(Cache)和写缓冲(Write Buffer);CPU通过该子系统与系统存储器系统相连。
高速缓存和写缓存 的引入是基于如下事实,即处理器速度远远高于存储器访问速度;如果存储器访问成为系统性能的瓶颈,则处理器再快也是浪费,因为处理器需要耗费大量的时间在 等待存储器上面。高速缓存正是用来解决这个问题,它可以存储最近常用的代码和数据,以最快的速度提供给CPU处理(CPU访问Cache不需要等待)。
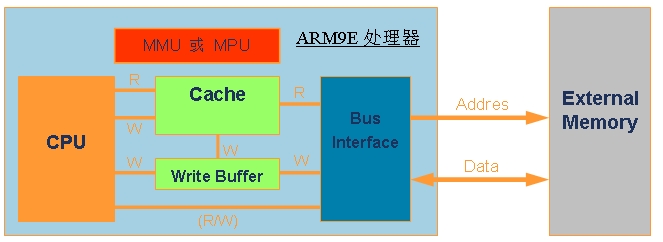
图2:复杂处理器内部的存储器子系统。
MMU则是用来支持存储器管理的硬件单元,满足现代平台操作系统内存管理的需要;它主要包括两个功能:一是支持虚拟/物理地址映射,二是提供不同存储器地址空间的保护机制。一个简单的例子可以帮助我们理解MMU的功能,
如 图3,在一个操作系统下,程序开发人员都是在操作系统给定的API和编程模型下开发程序;操作系统通常只开放一个确定的存储器地址空间给用户。这样就带来 一个直接的问题,所有的应用程序都使用了相同的存储器地址空间,如果这些程序同时启动的话(在现在的多任务系统中这是非常常见的),就会产生存储器访问冲 突。那操作系统是如何来避免这个问题的呢?
操作系统会利用MMU硬件单元完成 存储器访问虚拟地址到物理地址的转换。所谓虚拟地址就是程序员在程序中使用的逻辑地址,而物理地址则是真实存储器单元的空间地址。MMU通过一定的规则, 可以把相同的虚拟地址映射到不同的物理地址上去。这样,即使有多个使用相同虚拟地址的程序进程启动,也可以通过MMU调度把它们映射到不同的物理地址上 去,不会造成系统错误。
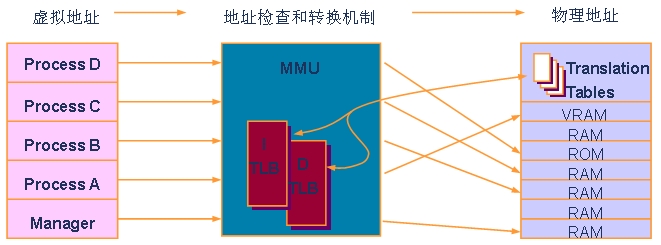
图3:MMU的功能和作用。
MMU 处理地址映射功能之外,还能给不同的地址空间设置不同的访问属性。比如操作系统把自己的内核程序地址空间设置为用户模式下不可访问,这样的话用户应用程序 就无法访问到该空间,从而保证操作系统内核的安全性。MPU与MMU的区别在于它只有给地址空间设置访问属性的功能而没有地址映射功能。
Cache以及MMU等硬件单元的引入,给系统程序员的编程模型带来了许多全新的变化。除了需要掌握基本的概念和使用方法之外,下面几个针对系统优化的点既有趣又重要:
1、系统实时性考虑
因 为保存地址映射规则的页表(Page Table)非常庞大,通常MMU中只是存储器了常用的一小段页表内容,大部分页表内容都存储于主存储器里面;当调用新的地址映射规则时,MMU可能需要 读取主存储器来更新页表。这在某些情况下会造成系统实时性的丢失。比如当需要执行一段关键的程序代码时,如果不巧这段代码使用的地址空间不在当前MMU的 页表处理范围里面,则MMU首先需要更新页表,然后完成地址映射,接着才能相应存储器访问;整个地址译码过程非常长,给实时性带来非常大的不利影响。所以 一般来说带MMU和Cache的系统在实时性上不如一些简单的处理器;不过也有一些办法能够帮助提高这些系统的实时效率。
一 个简单的办法是在需要的时候关闭MMU和Cache,这样就变成一个简单处理器了,可以马上提高系统实时性。当然很多情况下这不可行;在ARM的MMU和 Cache设计中,有一个锁定的功能,就是说你可以指定某一块页表在MMU中不会被更新掉,某一段代码或数据可以在Cache中锁定而不会被刷新掉;程序 员可以利用这个功能来支持那些实时性要求最高的代码,保证这些代码始终能够得到最快的响应和支持。
2、系统软件优化
在 嵌入式系统开发中,很多系统软件优化的方法都是相同和通用的,多数情况下这种规则也适用于ARM9E架构上。如果你已经是一个ARM7的编程高手,那么恭 喜你,以前你掌握的优化方法完全可以用在新的ARM9E平台上,但是会有一些新的特性需要你加倍注意。最重要的便是Cache的作用,Cache本身并不 带来编程模型和接口的变化,但是如果我们考察Cache的行为,就能够发现对于软件优化,Cache是有比较大的影响的。
Cache 在物理上就是一块高速SRAM,ARM9E的Cache组织宽度(cache line)都是4个word(也就是32个字节);Cache的行为受系统控制器控制而不是程序员,系统控制器会把最近访问存储器地址附近的内容复制到 Cache中去,这样,当CPU访问下一个存储器单元的时候(这个访问既可能是取指,也可能是数据),可能这个存储器单元的内容已经在Cache里了,所 以CPU不需要真的到主存储器上去读取内容,而直接读取Cache高速缓存上面的内容就可以了,从而加快了访问的速度。从Cache的工作原理我们可以看 到,其实Cache的调度是基于概率的,CPU要访问的数据既可能在Cache中已经存在(Cache hit),也可能没有存在(Cache miss)。在Cache miss的情况下,CPU访问存储器的速度会比没有Cache的情况更坏,因为CPU除了要从存储器访问数据以外,还需要处理Cache hit或miss的判断,以及Cache内容的刷新等动作。只有当Cache hit带来的好处超过Cache miss带来的牺牲的时候,系统的整体性能才能得到提高,所以Cache的命中率成为一个非常重要的优化指标。
根 据Cache行为的特点,我们可以直观地得到提高Cache命中率的一些方法,如尽可能把功能相关的代码和数据放置在一起,减少跳转次数;跳转经常会引起 Cache miss。保持合适的函数大小,不要书写太多过小的函数体,因为线性的程序执行流程是最为Cache友好的。循环体最好放置在4个word对齐的地址,这 样就能保证循环体在Cache中是行对齐的,并且占用最少的Cache行数,使得被多次调用的循环体得到更好的执行效率。
性能和效率的提升
前 面介绍了ARM9E相比于ARM7性能上的提高,这不仅表现在ARM9E有更快的主频、更多的硬件特性上面,还体现在某些指令的执行效率上面。执行效率我 们可以用CPU的时钟周期数(Cycle)来衡量;运行同一段程序,ARM9E的处理器可以比ARM7节省大约30%左右的时钟周期。
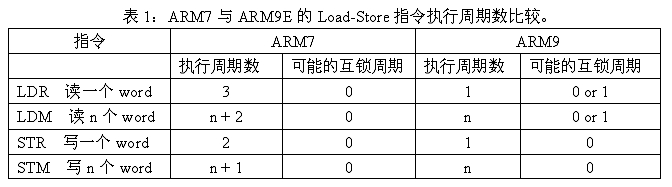
效 率的提高主要来自于ARM9E对于Load-Store指令执行效率的增强。我们知道在RISC架构的处理器中,程序中大约有30%的指令是Load- Store指令,这些指令的效率对系统效率的贡献是最明显的。ARM9E中有两个因素帮助提高Load-Store指令的效率:
1)ARM9内核是哈佛架构,拥有独立的指令和数据总线;相对应,ARM7内核是指令和数据总线复用的冯?诺依曼架构。
2)ARM9的5级流水线设计把存储器访问和寄存器写回放在不同的流水上面。
两 者结合,使得在指令流的执行过程中每个CPU时钟周期都可以完成一个Load或Store指令。下面的表格比较了ARM7和ARM9处理器之间的Load -Store指令。从中可以看出所有的Store指令ARM9比ARM7省1个周期,Load指令可以省2个周期(在没有互锁的情况下,编译工具能够通过 编译优化消除大多数的互锁可能)。
综合各种因素,ARM9E处理器拥有非常强大的性能。但是在实际的系统设计中,设计人员并不总是把处理器性能开到最大,理想情况是把处理器和系统运行频率降 低,使得性能刚好能满足应用需求;达到节省功耗和成本的目的。在评估系统能够提供的处理器能力过程中,DMIPS指标被很多人采用;同时它也被广泛应用于 不同处理器间的性能比较。
但是用DMIPS来衡量处理器性能存在很大的缺陷。 DMIPS并非字面上每秒百万条指令的意思,它是一个测量 CPU运行一个叫Dhrystone的测试程序时表现出来的相对性能高低的一个单位(很多场合人们也习惯用MIPS作为这个性能指标的单位)。因为基于程 序的测试容易受到恶意优化的干扰,并且DMIPS指标值的发布不受任何机构的监督,所以使用DMIPS进行评估时要慎重。例如对Dhrystone测试程 序进行不同的编译处理,在同一个处理器上运行也可以得出差别很大的结果,如图4中是ARM926EJ在32位0等待存储器上运行测试程序的结果。ARM一 直采用比较保守的值作为CPU的DMIPS标称值,如ARM926EJ是1.1DMPS/MHz。
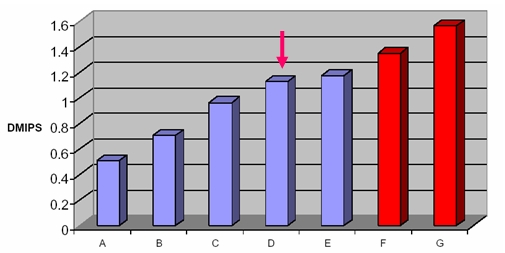
图4:不同测试条件下ARM926EJ处理器的DMIPS值。
DMIPS 另外一个缺点是不能测量处理器的数字信号处理能力和Cache/MMU子系统的性能。因为Dhrystone测试程序不包含DSP表达式,只包含一些整型 运算和字符串处理,并且测试程序偏小,几乎可以完整地放在Cache里面运行而无需与外部存储器进行交互。这样就难以反映处理器在一个真实系统中的真正性 能。
一种值得鼓励的评估方法是站在系统的角度看问题,而不仅仅拘泥于CPU本身;而系统性能评估最好的测试向量就是用户应用程序或相近的测试程序,这是用户所需的最真实的结果。
ARM9E处理器的DSP运算能力
伴 随应用程序的多样化和复杂化,诸如多媒体、音视频功能在嵌入式系统里面也是全面开花。这些应用需要相当的DSP处理能力;如果是在传统的RISC架构上实 现这些算法,所需的资源(频率和存储器等)会非常不经济。ARM9E处理器一个非常重要的优势就是拥有轻量级的DSP处理能力,以非常小的成本(CPU增 加功能需要增加硬件)换来了非常实用的DSP性能。
因为CPU的DSP能力并不直接反映在像DMIPS这样的评测指标中,同时像以前的ARM7处理器中也没有类似的概念;所以这一点对所有使用ARM9E处理器进行开发的人来说,都是需要注意的一个要点。
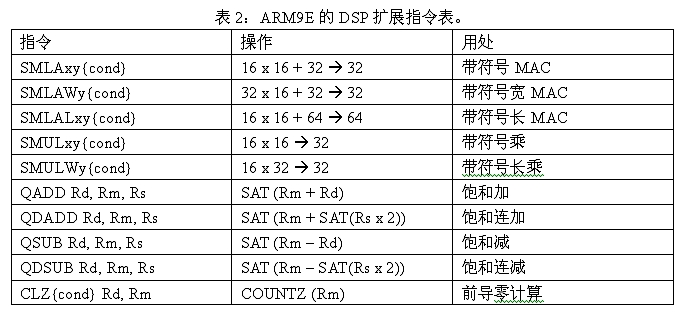
ARM9E的DSP扩展指令如表2所示,主要包括三个类型。
虽然现在很多人都批评Dhrystone用来测试CPU性能已经过时了,但它目前还是被用得最多的方法。
一直不知道到底怎么测,比如我测了AT91R4008这个keil提供的例子程序,它显示的结果是:
Dhrystones per second: 7352
这个数字怎么转换成MIPS? 网上有文章提到 除以 1757, 那这个芯片不是只有4.18MIPS?按每Mhz来算的话,40M的芯片只有 0.104? 这结果显然不正确的。
网友文章:http://www.ourdev.cn/bbs/bbs_content.jsp?bbs_sn=604659&bbs_page_no=1&bbs_id=1008
|
Dhrystone是测量处理器运算能力的最常见基准程序之一,常用于处理器的整形运算性能的测量。程序是用C语言编写的,因此C编译器的编译效率对测试结果也有很大影响。
Dhrystone的计量单位为每秒计算多少次Dhrystone,后来把在VAX-11/780机器上的测试结果1757 Dhrystones/s定义为1 Dhrystone MIPS(百万条指令每秒)。 测试采用Philips LPC2142,主频60MHz,内存加速模块全开,Flash周期为3,界面为Keil for ARM 3.30。编译时均对速度进行最大优化。测试结果如下: 编译器 CPU模式 Dhrystones/s DMIPS DMIPS/MHz RealView V2.2 Thumb 78951.5 44.9 0.75 可见,运行最快的是采用RealView V2.2编译的代码,ARM模式下达到了0.91 DMIPS/MHz(不知道ARM7声称的0.9 MIPS/MHz是不是这样来的)。Keil的编译器效率最低,而且奇怪的是,使用Keil编译器,其ARM模式的优势体现不出来,反而比Thumb模式的性能略低,可能Keil编译器对ARM模式没有作多大的优化。 |
按照网友提供的数据, dhrystonesPerSecond除以1757这个值的结果是正确的。
什么是RealView MDK
RealView MDK开发工具源自德国Keil公司,被全球超过10万的嵌入式开发工程师验证和使用,是ARM公司目前最新推出的针对各种嵌入式处理器的软件开发工具。 RealView MDK集成了业内最领先的技术,包括µVision3集成开发环境与 RealView编译器。支持ARM7、ARM9和最新的Cortex-M3核处理器,自动配置启动代码,集成Flash烧写模块,强大的 Simulation设备模拟,性能分析等功能,与ARM之前的工具包ADS等相比,RealView编译器的最新版本可将性能改善超过20%
RealView MDK的突出特性:
菜鸟的阿拉伯飞毯 —— 启动代码生成向导,自动引导,一日千里
启动代码和系统硬件结合紧密,必须用汇编语言编写,因而成为许多工程师难以跨越多门槛。 RealView MDK的µVision3工具可以帮您自动生成完善的启动代码,并提供图形化的窗口,随您轻松修改。无论对于初学者还是有经验的开发工程师,都能大大节省时间,提高开发效率。
高手的无剑胜有剑 —— 软件模拟器,完全脱离硬件的软件开发过程
RealView MDK的设备模拟器可以仿真整个目标硬件,包括快速指令集仿真、外部信号和I/O仿真、中断过程仿真、片内所有外围设备仿真等。开发工程师在无硬件的情况下即可开始软件开发和调试,使软硬件开发同步进行,大大缩短开发周期。而一般的ARM开发工具仅提供指令集模拟器,只能支持ARM内核模拟调试。
专家的哈雷望远镜 —— 性能分析器,看得更远、看得更细、看得更清
RealView MDK的性能分析器好比哈雷望远镜,让您看得更远和更准,它辅助您查看代码覆盖情况,程序运行时间,函数调用次数等高端控制功能,指导您轻松的进行代码优化,成为嵌入式开发高手。通常这些功能只有价值数千美元的昂贵的Trace工具才能提供。
业界最优秀的编译器——RealView 编译器,代码更小,性能更高
RealView MDK的RealView编译器与ADS 1.2比较:
代码密度:比ADS 1.2编译的代码尺寸小10%;
代码性能:比ADS 1.2编译的代码性能高20%。
配备ULINK2仿真器+ Flash编程模块,轻松实现Flash烧写
RealView MDK无需寻求第三方编程软件与硬件支持,通过配套的ULINK2仿真器与Flash编程工具,轻松实现CPU片内FLASH、外扩FLASH烧写,并支持用户自行添加FLASH编程算法;而且能支持FLASH整片删除、扇区删除、编程前自动删除以及编程后自动校验等功能,轻松方便。
绝对的高性价比——国际品质,本土价格
RealView MDK中国版保留了RealView MDK国际版的所有卓越性能,而产品价格和国内普通开发工具的价格差不多 ;另外我们还根据不同需求,专门定制了4个版本,以满足工程师们不同的需要。这绝对是您选择开发工具的首选。
更贴身的服务——专业的本地化的技术支持和服务
RealView MDK中国版用户将享受到专业的本地化的技术支持和服务,包括电话、Email、论坛、中文技术文档等,这将为国内工程师们开发出更有竞争力的产品提供更多的助力
ARM7 ARM 11相关推荐
- 【飞腾平台安装windows arm 11系统】
飞腾平台安装windows arm 11系统 配置要求: 虚拟机工具phyvirt安装包和windows镜像获取 步骤1 点击基于已有镜像创建按钮 步骤2 选择已有的QCOW2文件 步骤3 设置好虚拟 ...
- GCC Arm 11.3rel1, 12.2编译提示 _close is not implemented and will always fail
使用GCC Arm工具链开发的项目, 在11.2下编译正常, 但是升级到 arm-gnu-toolchain-11.3.rel1 以及 arm-gnu-toolchain-12.2 之后, 编译出现警 ...
- ARM 之八 Cortex-M/R 内核启动过程 / 程序启动流程(基于IAR)
在前面的文章<ARM 之 Cortex-M/R 内核启动过程 / 程序启动流程(基于ARMCC)>中已经介绍过了 Cortex-M/R 内核相关内容.这里基于 IAR 的启动流程与之前 ...
- 嵌入式:ARM相关开发工具概述
文章目录 JTAG仿真器 J-LINK仿真调试器 J-Link ARM主要特点 U-LINK仿真调试器 ULINK2特点 ULINK和JLINK的比较 ADS1.2集成开发环境 使用ADS创建工程 J ...
- 单片机和ARM的区别
1.软件方面 这应该是最大的区别了.引入了操作系统.为什么引入操作系统?有什么好处嘛? 1)方便.主要体现在后期的开发,即在操作系统上直接开发应用程序.不像单片机一样一切都要重新写.前期的操作系统移植 ...
- Cortex-M3 VS ARM7
要使用低成本的 32位处理器,开发人员面临两种选择,基于Cortex-M3内核或者ARM7TDMI内核的处理器.如何做出选择?选择标准又是什么?本文主要介绍了ARM Cortex-M3内核微控制器区别 ...
- ARM嵌入式开发总结
读大学时学过计算机组成原理.操作系统.计算机网络等等课程,但是大学生都知道,上完那些课只是懂一点皮毛而已,打打酱油就过去了.特别是对于软件工程师,一定要多实践.多思考才行.理论知识显得并没有搞硬件或者 ...
- 【嵌入式开发】 ARM 关闭 MMU ( 存储体系 | I/D-Cache | MMU | CP15 寄存器 | C1 控制寄存器 | C7 寄存器 | 关闭 MMU )
一. MMU 概念 1. ARM 存储 (1) ARM 的存储体系 (2) Cache 由来 (3) Cache 定义 2. MMU (1) 虚拟地址 与 物理地址 (2) MMU 作用 及 关闭原因 ...
- 【嵌入式开发】 ARM 汇编 (指令分类 | 伪指令 | 协处理器访问指令)
作者 : 韩曙亮 博客地址 : http://blog.csdn.net/shulianghan/article/details/42408137 转载请著名出处 本博客相关文档下载 : -- A ...
最新文章
- 谷歌新研究:基于数据共享的神经网络快速训练方法
- 十八、深入Java 访问修饰符和非访问修饰符
- ios取两个数之间的随机小数_如果取到小数区间内的任一数字?
- 计算机学业水平测试题及答案初中,初中信息技术学业水平考试试题30号试题.doc...
- 【操作系统】多线程与多任务的比较
- 表达式类型( 一个表达式和一棵二叉树之间,存在着自然的对应关系。写一个程序,实现 基于二叉树表示的算术表达式Expression的操作)
- Fiddler安装教程(图文版)
- Linux 命令(54)—— trap 命令(builtin)
- 计算机桌面显示本地磁盘c,开机自动打开本地磁盘C的解决办法
- 蓝桥杯- 煤球数目-java
- python求素数代码_Python实现高效求解素数代码实例
- web元素定位之------日历控件的定位
- iPhone iPad游戏应用开发视频教程
- 读书笔记:深度学习入门-基于python的理论与实现(俗称鱼书)
- 屏幕录像软件使用教程?
- IEEE论文latex模板
- 科学计算机怎么算四分位数,科学网—四分位数间距 - 贺小星的博文
- android辅助功能demo,Android中的辅助功能实现问题
- 新鲜出炉的三维动画应用领域,学3D建模好工作找不完
- Pandas+Numpy 数据中空值的处理操作:判断、查找、填充及删除