《大规模元搜索引擎技(1)》一 2.1 系统体系结构
本节书摘来自华章出版社《大规模元搜索引擎技(1)》一书中的第2章,第2.1节,作者[美]孟卫一(Weiyi Meng)纽约州立大学宾汉姆顿分校於德(Clement T.Yu)伊利诺伊大学芝加哥分校,更多章节内容可以访问云栖社区“华章计算机”公众号查看
2.1 系统体系结构
搜索文本文档的元搜索引擎可分为两种类型:通用元搜索引擎和专用元搜索引擎。前者旨在搜索整个Web,而后者专注于在特定领域搜索信息(例如,新闻、招聘)。
构建每个类型的元搜索引擎有两种方法:
主流搜索引擎方法。这种方法使用少数的热门主流搜索引擎来构建元搜索引擎。因而,使用这种方法构建通用元搜索引擎,可以使用少量的主流搜索引擎,如Google、Yahoo!、Bing(MSN)和Ask。类似地,在特定领域建立一个专用元搜索引擎也可以使用这种方法,使用该领域的主流搜索引擎。例如,在新闻领域可以使用Google News、Yahoo!News、Reuters等。
大规模元搜索引擎方法。这种方法使用大量的以小搜索引擎为主的搜索引擎来构建元搜索引擎。例如,使用这种方法,我们可以想象用Web上所有文档驱动的搜索引擎来构建一个通用元搜索引擎。这样一个元搜索引擎将有数百万的成员搜索引擎。类似地,对于一个给定的领域,用这种方法可以通过连接该领域所有的搜索引擎来构建专用元搜索引擎。例如,在新闻领域可以使用数以万计的报纸和新闻站点的搜索引擎。
上述两种方法各有优缺点,本节将详细描述。相对于大规模元搜索引擎方法,主流搜索引擎方法的明显优势是主流元搜索引擎更容易构建,因为用这种方法构建元搜索引擎只需要很少数目的搜索引擎。目前几乎所有流行的元搜索引擎都是使用主流搜索引擎方法构建的,例如,Dogpile(http://www.dogpile.com/)、Mamma(http://www.mamma.com/)、MetaCrawler(http://www.metacrawler.com/),其中大多数只使用少数几个主流搜索引擎。AllInOneNews(http://www.allinonenews.com/)是大规模专用元搜索引擎的一个例子,它使用了约200个国家/地区的1800个左右的新闻搜索引擎。一般而言,建立大规模元搜索引擎需要更先进的技术。随着这些技术越来越成熟,可能会建立更多大规模元搜索引擎。
设计元搜索引擎系统的体系结构时应该同时考虑上述两种方法。图2-1所示的体系结构就是基于这种考虑。该体系结构包含一些重要的软件部件,包括搜索引擎选择器(search engine selector)、搜索引擎加入器(search engine incorporator)和结果合并器(result merger)。搜索引擎加入器由两个子部件组成:搜索引擎连接器(search engine connector)和结果抽取器(result extractor)。本书中我们把元搜索引擎中使用的那些搜索引擎称为元搜索引擎的成员搜索引擎(component search engine)。
下面对图2-1中元搜索引擎的主要部件进行更详细描述。
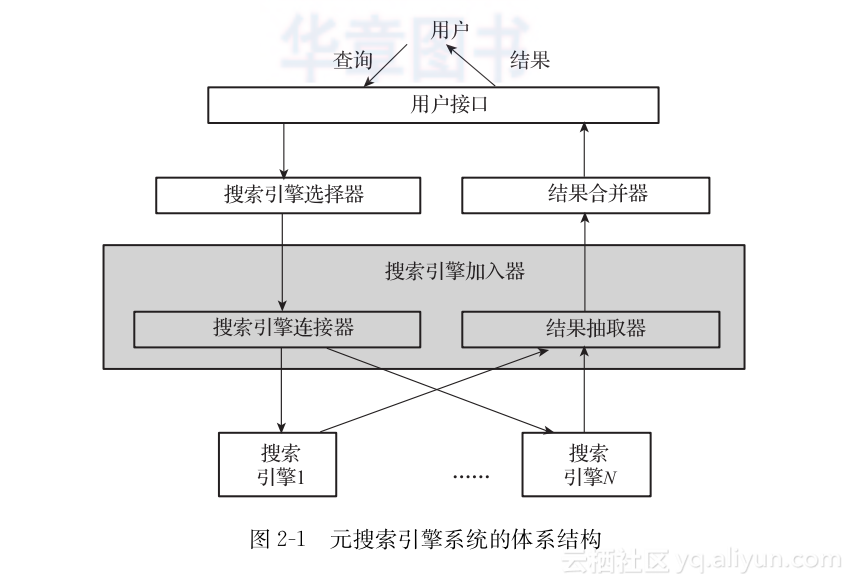
1.搜索引擎选择器
如果一个元搜索引擎中的成员搜索引擎的数目很少,比如小于10个,那么把每个提交给元搜索引擎的用户查询发送到所有成员搜索引擎也许是合理的。在这种情况下,很可能不需要搜索引擎选择器。然而,如果成员搜索引擎的数目很多,就像在使用大规模元搜索引擎,发送每个查询给所有成员搜索引擎将是一种低效率的策略,因为大多数成员搜索引擎对任何特定的查询是无用的。例如,假设用户想要从具有1000个成员搜索引擎的元搜索引擎中查找与其查询匹配的50个最佳结果。因为50个最佳结果将包含在不超过50个成员搜索引擎中,很明显,对这个特定的查询,至少950个成员搜索引擎是无用的。
把查询传递给无用的搜索引擎可能会导致严重的效率问题。一般而言,发送查询给无用的搜索引擎将导致资源浪费,包括元搜索引擎服务器、涉及每个搜索引擎的服务器和因特网资源。具体而言,发送查询给一个无用搜索引擎并处理返回结果会浪费元搜索引擎服务器的资源,其中发送查询时浪费的资源包括查询所需的格式重写,处理返回结果时浪费的资源包括接收返回的响应页面,从这些页面中抽取结果记录,并确定它们是否应该包含在最终的合并结果列表中,若是,还需要确定它们在合并后的结果列表中的位置。如果一个搜索引擎的结果最终毫无用处,那么接收来自元搜索引擎的查询、处理查询并返回结果给元搜索引擎将浪费搜索引擎的资源。最后,从元搜索引擎向无用搜索引擎传输查询,以及从这些搜索引擎向元搜索引擎传输无用的检索结果,都浪费了因特网的网络资源。
因此,把每个用户查询仅发送给潜在有用的搜索引擎去处理是重要的。对于一个给定查询,识别应该调用的潜在有用成员搜索引擎的问题称为搜索引擎选择问题(search engine selection problem),有时也称为数据库选择问题(database selection problem)、服务器选择问题(server selection problem)或查询路由问题(query routing problem)。显然,对于元搜索引擎,具有越多的成员搜索引擎和越多不同内容的成员搜索引擎,拥有一个有效的搜索引擎选择器就越重要。搜索引擎选择技术将在第3章讨论。
2.搜索引擎连接器
当一个成员搜索引擎被选择参与处理一个用户查询处理之后,搜索引擎连接器建立与此搜索引擎服务器的连接并将查询传给该服务器。不同的搜索引擎通常有不同的连接参数。因此,对每个搜索引擎都需要创建一个单独的连接器。一般而言,对于一个搜索引擎S,搜索引擎连接器需要知道S支持的HTTP连接参数。有3个基本参数:(a)搜索引擎服务器的名称和地址;(b)S支持的HTTP请求方法(通常是GET或POST);(c)用来保存实际查询字符串的字符串变量名。
当实现一个成员搜索引擎数目少的元搜索引擎时,可以由经验丰富的开发者为每个搜索引擎手动编写连接器。然而,对于大规模元搜索引擎来说,这可能会非常耗时和昂贵。因此,开发自动生成连接器的能力是非常重要的。
需要注意的是,一个智能元搜索引擎如果发现修改接收到的用户查询可以潜在地提高搜索效率,那么它可能会先修改该查询并把修改后的查询传送给搜索引擎连接器。例如,元搜索引擎可能通过使用查询扩展技术为原始用户查询增加一些相关词来增大获取更多相关文档的机会。
搜索引擎连接器将在第4章讨论。
3.结果抽取器
当一个成员搜索引擎处理一个查询之后,搜索引擎将返回一个或多个响应页面。一个典型的响应页面包含多个(通常10个)查询结果记录(Search Result Record,SRR),每个记录对应一个检索到的Web页面,该记录通常包含URL、页面标题、页面内容的简短摘要(称为概览,snippet)和一些其他的信息,例如页面大小。图2-2显示了Google搜索引擎的一个响应页面的上部。响应页面是动态生成的HTML文档,它们通常也包含与用户查询不相关的内容,例如广告(赞助商链接)和网站的信息。
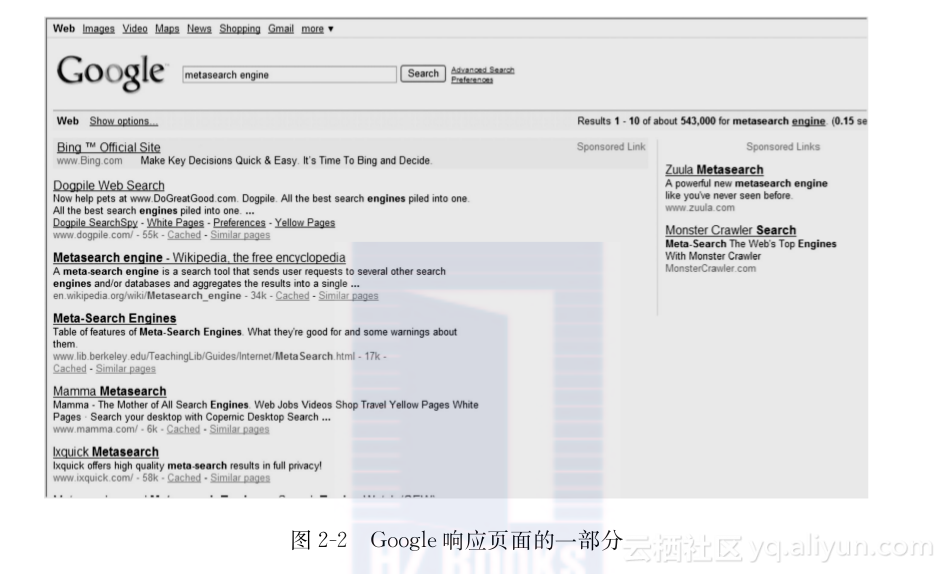
需要一个程序(即结果抽取器)从每个响应页面中抽取正确的SRR,以便把来自不同成员搜索引擎的SRR合并成一个排序列表。这个程序有时称为抽取包装器(extraction wrapper)。由于来自不同搜索引擎的结果通常格式不同,所以需要为每个成员搜索引擎配备单独的结果抽取器。尽管经验丰富的程序员可以手动编写抽取器,但对于大规模元搜索引擎,更希望研发能够自动生成抽取器的技术。
结果抽取技术将在第4章讨论。
4.结果合并器
被选择的成员搜索引擎的结果返回给元搜索引擎之后,结果合并器把结果合并成一个排序列表。然后把排序的SRR列表呈现给用户,或许一次一个包含10条记录的页面,就像大多数搜索引擎一样。
很多因素会影响结果合并的进行以及输出结果像什么样子。其中的一些因素为:1)不同成员搜索引擎索引的各个文档集合之间存在多少重叠?可能的情形从没有重叠到这些文档集合完全相同,以及介于这两个极端之间的任意情况。2)什么样的信息存在或可用来进行合并?可能利用的信息包括:成员搜索引擎结果记录的本地排序、结果记录的标题和概览、每个结果的完整文档、每个检索文档的发布时间、搜索引擎与其检索结果所对应的查询之间的潜在相关性,以及其他信息。好的结果合并器应将所有返回结果按其需求度降序排列。
结果合并的不同方法将在第5章中讨论。
《大规模元搜索引擎技(1)》一 2.1 系统体系结构相关推荐
- 《大规模元搜索引擎技》——第1章 绪言1.1 Web上查找信息
本节书摘来自华章出版社<大规模元搜索引擎技>一书中的第1章,第1节,作者 [美]孟卫一(Weiyi Meng), 纽约州立大学, 宾汉姆顿分校於德(Clement T.Yu),伊利诺伊大学 ...
- 《大规模元搜索引擎技(1)》一第1章 绪言
本节书摘来自华章出版社<大规模元搜索引擎技(1)>一书中的第1章,作者[美]孟卫一(Weiyi Meng)纽约州立大学宾汉姆顿分校於德(Clement T.Yu)伊利诺伊大学芝加哥分校,更 ...
- 《大规模元搜索引擎技(1)》一1.1 Web上查找信息
本节书摘来自华章出版社<大规模元搜索引擎技(1)>一书中的第1章,第1.1节,作者[美]孟卫一(Weiyi Meng)纽约州立大学宾汉姆顿分校於德(Clement T.Yu)伊利诺伊大学芝 ...
- 《大规模元搜索引擎技》——1.2 文本检索概述
本节书摘来自华章出版社<大规模元搜索引擎技>一书中的第1章,第1.2节,作者 [美]孟卫一(Weiyi Meng), 纽约州立大学, 宾汉姆顿分校於德(Clement T.Yu),伊利诺伊 ...
- 《大规模元搜索引擎技(1)》一导读
前 言 当下大数据技术发展变化日新月异,大数据应用已经遍及工业和社会生活的方方面面,原有的数据管理理论体系与大数据产业应用之间的差距日益加大,而工业界对于大数据人才的需求却急剧增加.大数据专业人才的培 ...
- 集成搜索引擎与元搜索引擎
搜 索引擎是开启网络知识殿堂的钥匙,获取知识信息的工具.随着网络技术的飞速发展,搜索技术的日臻完善,中外搜索引擎已广为人们熟知和使用.任何搜索引擎的 设计,均有其特定的数据库索引范围.独特的功能和使用 ...
- 元搜索引擎的研究和设计
一. 引言 在互联网发展初期,网站相对较少,网页数量亦较少,因而信息查找比较容易.随着Internet的飞速发展,人们越来越依靠网络来查找他们所需要的信息,然而伴随互联网爆炸性的发展,普通网络用户想找 ...
- 元搜索引擎的研究和设计(计算技术研究所 李锐)
http://blog.csdn.net/colin719/archive/2005/01/06/243144.aspx 元搜索引擎的研究和设计 计算技术研究所 李锐 colin719@126.com ...
- 全媒体运营师胡耀文教你:大规模用户运营体系背后的3大子系统
其实用户运营体系的搭建和用户运营模型的梳理二者是一体的,因为只有梳理清楚了用户运营模型,才能够在这个基础上去搭建起来我们的用户运营体系,它是这样的一个关系. 相信大家对于用户运营以及大规模用户的管理这 ...
- 如何成功构建大规模 Web 搜索引擎架构?
Web搜索引擎十分复杂,我们的产品是一个分布式系统,在性能和延迟方面有非常苛刻的要求.除此之外,这个系统的运营也非常昂贵,需要大量人力,当然也需要大量金钱. 这篇文章将探讨我们使用的一些技术栈,以及我 ...
最新文章
- Standup Timer的MVC模式及项目结构分析
- 园林工程中植物搭配要注意哪些地方?
- python代码基础题-Python初学者福利 完整试题附答案 干货(收藏篇)
- golang中的mysql类型对应
- 开发Android应用 提升性能的小技巧
- JSON.parse 解析json字符串时,遇换行符报错
- thinkPHP5.0数据查询表达式生成技巧
- 网络工程师为什么要学python_网络工程师学python
- PHP学习笔记 - 在Eclipse中使用XDebug调试代码 | Using XDebug debug code in eclipse
- 第六章节 多态 (多态的概述)
- 李阳疯狂英语900句 331-545
- 各种常用的 Win32Api 汇总(持续更新中. . .)
- 图像直方图规定化 matlab代码,MATLAB图像直方图规定化问题
- 盛世zeepower远程距离隔空无线充投放商用 低频磁共振无线充电技术——充电有效距离 20-45mm
- RocKey4加密狗复制软件及教程
- 热敏电阻 温度 电阻换算
- 我喜欢的乐队-Descending
- 情人节程序员用HTML网页表白【情人节爱你的代码】 HTML5七夕情人节表白网页源码 HTML+CSS+JavaScript
- 请将插入点移动到word域以外-NoteExpress
- idea右侧maven依赖飘红解决办法