lstm 文本分类_带有lstm和单词嵌入的灾难推文上的文本分类
lstm 文本分类
This was my first Kaggle notebook and I thought why not write it on Medium too?
Ť他是我第一次Kaggle的笔记本电脑,我想,为什么不把它写在中吗?
Full code on my Github.
我的Github上的完整代码。
In this post, I will elaborate on how to use fastText and GloVe as word embedding on LSTM model for text classification. I got interested in Word Embedding while doing my paper on Natural Language Generation. It showed that embedding matrix for the weight on embedding layer improved the performance of the model. But since it was NLG, the measurement was objective. And I only used fastText too. So in this article, I want to see how each method (with fastText and GloVe and without) affects to the prediction. On my Github code, I also compare the result with CNN. The dataset that i use here is from one of competition on Kaggle, consisted of tweets and labelled with whether the tweet is using disastrous words to inform a real disaster or merely just used it metaphorically. Honestly, on first seeing this dataset, I immediately thought about BERT and its ability to understand way better than what I proposed on this article (further reading on BERT).
在本文中,我将详细介绍如何将fastText和GloVe用作词嵌入在LSTM模型上进行文本分类。 在撰写有关自然语言生成的论文时,我对词嵌入感兴趣。 结果表明,嵌入权重的嵌入矩阵提高了模型的性能。 但是由于它是NLG,因此测量是客观的。 而且我也只使用fastText。 因此,在本文中,我想了解每种方法(带有fastText和GloVe(不带)的方法)如何影响预测。 在我的Github代码上,我还将结果与CNN进行了比较。 我在这里使用的数据集来自Kaggle上的一项竞赛,由tweet组成,并标有tweet是使用灾难性单词来告知真实灾难还是只是隐喻地使用它。 老实说,在第一次看到该数据集时,我立即想到了BERT及其理解方式的能力比我在本文中提出的更好( 进一步阅读BERT )。
But anyway, in this article I will focus on fastText and GloVe.
但是无论如何,在本文中,我将专注于fastText和GloVe。
Let’s go?
我们走吧?
数据+预处理 (Data + Pre-Processing)
The data consisted of 7613 tweets (columns Text) with label (column Target) whether they were talking about a real disaster or not. With 3271 rows informing real disaster and 4342 rows informing not real disaster. The data shared on kaggle competition, and if you want to learn more about the data you can read it here.
数据由7613条带有标签(列目标)的推文(列文本)组成,无论他们是否在谈论真正的灾难。 其中3271行通知真正的灾难,而4342行通知不是真正的灾难。 关于kaggle竞赛的数据共享,如果您想了解更多有关数据的信息,可以在这里阅读。

Example of real disaster word in a text :
文本中真实灾难词的示例:
“ Forest fire near La Ronge Sask. Canada “
“ La Ronge Sask附近的森林大火 。 加拿大“
Example of the use of disaster word but not about disaster:
使用灾难字但不涉及灾难的示例:
“These boxes are ready to explode! Exploding Kittens finally arrived! gameofkittens #explodingkittens”
这些盒子准备爆炸了 ! 爆炸的小猫终于来了! gameofkittens #explodingkittens”
The data will be divided for training (6090 rows) and testing (1523 rows) then proceed to pre-processing. We will only be using the text and target columns.
数据将被分为训练(6090行)和测试(1523行),然后进行预处理。 我们将只使用text和target列。
from sklearn.model_selection import train_test_splitdata = pd.read_csv('train.csv', sep=',', header=0)train_df, test_df = train_test_split(data, test_size=0.2, random_state=42, shuffle=True)Pre-processing steps that used here:
此处使用的预处理步骤:
- Case Folding
折叠箱 - Cleaning Stop Words
清洁停用词 - Tokenizing
代币化
from sklearn.utils import shuffleraw_docs_train = train_df['text'].tolist()raw_docs_test = test_df['text'].tolist()num_classes = len(label_names)processed_docs_train = []for doc in tqdm(raw_docs_train): tokens = word_tokenize(doc) filtered = [word for word in tokens if word not in stop_words] processed_docs_train.append(" ".join(filtered))processed_docs_test = []for doc in tqdm(raw_docs_test): tokens = word_tokenize(doc) filtered = [word for word in tokens if word not in stop_words] processed_docs_test.append(" ".join(filtered))tokenizer = Tokenizer(num_words=MAX_NB_WORDS, lower=True, char_level=False)tokenizer.fit_on_texts(processed_docs_train + processed_docs_test) word_seq_train = tokenizer.texts_to_sequences(processed_docs_train)word_seq_test = tokenizer.texts_to_sequences(processed_docs_test)word_index = tokenizer.word_indexword_seq_train = sequence.pad_sequences(word_seq_train, maxlen=max_seq_len)word_seq_test = sequence.pad_sequences(word_seq_test, maxlen=max_seq_len)词嵌入 (Word Embedding)
Step 1. Download Pre-trained model
步骤1.下载预训练的模型
The first step on working both with fastText and Glove is downloading each of pre-trained model. I used Google Colab to prevent the use of big memory on my laptop, so I downloaded it with request library and unzip it directly on the notebook.
使用fastText和Glove的第一步是下载每个预先训练的模型。 我使用Google Colab来防止在笔记本电脑上使用大内存,因此我将其与请求库一起下载并直接将其解压缩。
I used the biggest pre-trained model from both word embedding. fastText model gave 2 million word vectors (600B tokens) and GloVe gave 2.2 million word vectors (840B tokens), both trained on Common Crawl.
我使用了两个词嵌入中最大的预训练模型。 fastText模型提供了200万个单词向量(600B令牌),而GloVe提供了220万个单词向量(840B令牌),均在Common Crawl上进行了训练。
fastText pre-trained download
fastText预培训下载
import requests, zipfile, iozip_file_url = “https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M.vec.zip"r = requests.get(zip_file_url)z = zipfile.ZipFile(io.BytesIO(r.content))z.extractall()GloVe pre-trained download
GloVe预先培训的下载
import requests, zipfile, iozip_file_url = “http://nlp.stanford.edu/data/glove.840B.300d.zip"r = requests.get(zip_file_url)z = zipfile.ZipFile(io.BytesIO(r.content))z.extractall()Step 2. Load Pre-trained model to Word Vectors
步骤2.将预训练的模型加载到Word向量
FastText gave the format to load the word vectors and so I used that to load both models.
FastText给出了加载单词向量的格式,因此我使用它来加载两个模型。
embeddings_index = {}f = codecs.open(‘crawl-300d-2M.vec’, encoding=’utf-8')# for Glove# f = codecs.open(‘glove.840B.300d.txt’, encoding=’utf-8')for line in tqdm(f):values = line.rstrip().rsplit(‘ ‘)word = values[0]coefs = np.asarray(values[1:], dtype=’float32')embeddings_index[word] = coefsf.close()Step 3. Embedding Matrix
步骤3.嵌入矩阵
Embedding matrix will be used in embedding layer for the weight of each word in training data. It’s made by enumerating each unique word in the training dataset that existed in tokenized word index and locate the embedding weight with the weight from fastText orGloVe (more about embedding matrix).
嵌入矩阵将在嵌入层中用于训练数据中每个单词的权重。 它是通过枚举标记词索引中存在的训练数据集中的每个唯一单词,并使用来自fastText或GloVe的权重( 更多有关嵌入矩阵 )来定位嵌入权重而制成的。
But there is a possibility that there are words that aren’t in the vectors such as typos or abbreviation or usernames. Those words will be stored in a list and we can compare the performance of handling words from fastText and GloVe
但是有可能存在矢量中没有的单词,例如错别字或缩写或用户名。 这些单词将存储在列表中,我们可以比较处理来自fastText和GloVe的单词的性能
words_not_found = []nb_words = min(MAX_NB_WORDS, len(word_index)+1)embedding_matrix = np.zeros((nb_words, embed_dim))for word, i in word_index.items(): if i >= nb_words: continue embedding_vector = embeddings_index.get(word) if (embedding_vector is not None) and len(embedding_vector) > 0: embedding_matrix[i] = embedding_vector else: words_not_found.append(word)print('number of null word embeddings: %d' % np.sum(np.sum(embedding_matrix, axis=1) == 0))Number of null word embeddings on fastText is 9175 and on GloVe is 9186. Can be assumed that fastText handle more words even when the pre-trained was trained on fewer words.
在fastText上,空词嵌入的数量是9175,在GloVe上,空词嵌入的数量是9186。可以假定即使对预训练的单词进行较少的训练,fastText也可以处理更多的单词。
长短期记忆(LSTM) (Long Short-Term Memory (LSTM))
You can do fine-tuning on hyper-parameters or architecture, but I’m going to use the very simple one with Embedding Layer, LSTM layer, Dense layer, and Drop out Layer.
您可以对超参数或体系结构进行微调,但我将使用非常简单的一种,包括“嵌入层”,“ LSTM层”,“密集层”和“退出层”。
from keras.layers import BatchNormalizationimport tensorflow as tfmodel = tf.keras.Sequential()model.add(Embedding(nb_words, embed_dim, input_length=max_seq_len, weights=[embedding_matrix],trainable=False))model.add(Bidirectional(LSTM(32, return_sequences= True)))model.add(Dense(32,activation=’relu’))model.add(Dropout(0.3))model.add(Dense(1,activation=’sigmoid’))model.summary()
from keras.optimizers import RMSpropfrom keras.callbacks import ModelCheckpointfrom tensorflow.keras.callbacks import EarlyStoppingmodel.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])es_callback = EarlyStopping(monitor='val_loss', patience=3)history = model.fit(word_seq_train, y_train, batch_size=256, epochs=30, validation_split=0.3, callbacks=[es_callback], shuffle=False)结果 (Result)
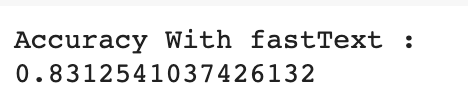
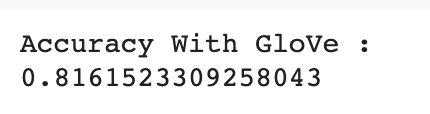
fastText gave the best performance with accuracy for about 83% while GloVe gave 81% accuracy. The difference on the performance isn’t so significant but to compare it with the performance of model without word embedding (68%), we can see the significant use of Word Embedding on embedding layer weight.
fastText的最佳性能约为83%,而GloVe的精度为81%。 性能上的差异不是很明显,但是将其与没有词嵌入的模型的性能进行比较(68%),我们可以看到词嵌入在嵌入层权重方面的重要用途。

For more about the training performance, detail code, and if you want to apply it on a different dataset, you can see the full code on my GitHub.
有关培训性能的更多信息,详细代码,以及如果要将其应用于其他数据集,则可以在我的GitHub上查看完整的代码。
Thank you for reading!
感谢您的阅读!
翻译自: https://towardsdatascience.com/text-classification-on-disaster-tweets-with-lstm-and-word-embedding-df35f039c1db
lstm 文本分类
相关文章:
- LeetCode第127题—单词接龙—Python实现
- 每天3分钟知晓天下事,一句话新闻资讯简报的公众号推荐
- Android初学习之四:知晓当前是哪一个活动和随时随地退出程序
- 图解图库JanusGraph系列-一文知晓“图数据“底层存储结构(JanusGraph data model)
- [日推荐]『与你见字如面』信息时代的一股清流
- cf869C The Intriguing Obsession
- C. The Intriguing Obsession(组合数学)
- 引用antd 组件,样式丢失
- 《如何优化项目一》:页面缓存优化
- 菜孔孔学python--集合
- JS对象基础-怎么理解对象
- JavaScript-深浅拷贝
- ES6——Symbol属性与for...of循环迭代器
- 菜孔孔学python--列表
- 菜孔孔学python--字典
- jQuery ? NO, Axios——请求数据
- Scratch编程与数学结合-蜗牛爬井问题
- 微信域名拦截检测API接口
- 微信域名防封,微信网址域名防封的几种方法
- 微信开发平台网址
- 微信域名被屏蔽被封了的解决办法 微信网址被屏蔽了红了照样打开
- php微信短网址生成,如何把微信文章网址长连接(长网址)转换为短连接(短网址)...
- 微信域名网址检测
- win10 64位注册TeeChart8.ocx
- win10注册mysql到windows服务报错:Install/Remove of the Service Denied
- WIN10 注册.dll regsvr32.exe错误 VC6添加插件
- Kafka使用报错Subscription to topics, partitions and pattern are mutually exclusive
- RabbitMQ topics
- Hot Research Topics
- kafka-topics.sh工具:查看/删除/修改/创建主题
lstm 文本分类_带有lstm和单词嵌入的灾难推文上的文本分类相关推荐
- python朴素贝叶斯的文本分类_自给自足,完全手写一个朴素贝叶斯分类器,完成文本分类...
Part 1: 本文解决的问题: 我在有这样的一个数据集,里面存放了人们对近期播放电影的评价,当然评价也就分成两部分,好评和差评.我们想利用这些数据训练一个模型,然后可以自动的对影评做出判断,到底是好 ...
- lstm时间序列预测模型_时间序列-LSTM模型
lstm时间序列预测模型 时间序列-LSTM模型 (Time Series - LSTM Model) Now, we are familiar with statistical modelling ...
- 判断字符串不超过20个字符_如何阻止超过140个字符的推文(如果确实需要)
判断字符串不超过20个字符 After over a decade of staunchly restricting users to 140 characters in each message, ...
- java docx文档解析_带有docx4j的Java Word(.docx)文档
java docx文档解析 几个月前,我需要创建一个包含许多表和段落的动态Word文档. 过去,我曾使用POI来实现此目的,但是我发现它很难使用,并且在创建更复杂的文档时对我来说效果不佳. 因此,对于 ...
- 按条件分类_保税仓储企业能否同时存储非保货物?“仓储货物安装台分类监管”如何申请?...
保税仓储企业能否同时存储非保货物呢?保税和非保货物是不是真的不能同在一个"屋檐下"呢?哪些企业可以开展"仓储货物按状态分类监管"业务?企业又该如何申请该项业务? ...
- 合成文本图像_设计中哪个更重要:图像还是文本?
合成文本图像 Technology has changed the modern world greatly in recent years and, in particular, it has ch ...
- 人人网 查看隐私照片_带有位置标签的照片真的是隐私问题吗?
人人网 查看隐私照片 When you take a photo with your smartphone (or a modern digital camera), it logs the phot ...
- nlp对语料进行分类_如何使用nlp对推文进行分类
nlp对语料进行分类 Over the years, we have seen Twitter evolve from just a social media to also a business a ...
- 自然语言处理-应用场景-文本分类:基于LSTM模型的情感分析【IMDB电影评论数据集】--(重点技术:自定义分词、文本序列化、输入数据批次化、词向量迁移使用)
文本情感分类 1. 案例介绍 现在我们有一个经典的数据集IMDB数据集,地址:http://ai.stanford.edu/~amaas/data/sentiment/,这是一份包含了5万条流行电影的 ...
最新文章
- 前沿分享:连接统计学,机器学习与自动推理的新兴交叉领域
- Python-面向对象 (二 继承)
- eclipse提示edit source lookup path的问题
- Python函数的动态参数
- 学习笔记(07):Python网络编程并发编程-客户端与服务端代码bug修复
- java resultset 映射到实例_[Java]ResultSet的用法与实例
- 卡尔曼滤波——16.新的均值和方差
- 【推荐实践】爱奇艺推荐中台探索与实践
- MyBatis集合Spring(三)之mapper
- 阶段1 语言基础+高级_1-3-Java语言高级_06-File类与IO流_05 IO字符流_8_使用try_catch_finally处理流中的异常...
- 2016年408考研算法题
- HTML5期末大作业:生态环境网站设计——环境保护主题-绿色环保 (9页) web期末作业设计网页_绿色环保大学生网页设计作业成品
- 西安交大计算机814大纲,西安交大考研辅导班:西安交通大学2020年809电子技术基础考研科目参考书目及考试大纲...
- 请求后台时对uri进行编码——即encodeURIComponent()的使用
- tomcat配置 详解
- AAC编解码原理概述
- 视频播放插件(video.js)
- Java集成SOX开发
- Arnold折射中使用LPE单独提取某个材质的渲染结果
- 关于如何使用内存擦车的