深度学习用于股票预测_用于自动股票交易的深度强化学习
深度学习用于股票预测
Note from Towards Data Science’s editors: While we allow independent authors to publish articles in accordance with our rules and guidelines, we do not endorse each author’s contribution. You should not rely on an author’s works without seeking professional advice. See our Reader Terms for details.
Towards Data Science编辑的注意事项: 尽管我们允许独立作者按照我们的 规则和指南 发表文章 ,但我们不认可每位作者的贡献。 您不应在未征求专业意见的情况下依赖作者的作品。 有关 详细信息, 请参见我们的 阅读器条款 。
This blog is based on our paper: Deep Reinforcement Learning for Automated Stock Trading: An Ensemble Strategy, presented at ICAIF 2020: ACM International Conference on AI in Finance.
该博客基于我们的论文: 《用于自动股票交易的深度强化学习:整体策略》 ,在ICAIF 2020 :ACM金融人工智能国际会议上发表。
Our codes are available on Github.
我们的代码可在Github上找到 。
Our paper will be available on arXiv soon.
我们的论文即将在arXiv上发布。
If you want to cite our paper, the reference format is as follows:
如果您想引用我们的论文,参考格式如下:
Hongyang Yang, Xiao-Yang Liu, Shan Zhong, and Anwar Walid. 2020. Deep Reinforcement Learning for Automated Stock Trading: An Ensemble Strategy. In ICAIF ’20: ACM International Conference on AI in Finance, Oct. 15–16, 2020, Manhattan, NY. ACM, New York, NY, USA.
杨洪阳,刘晓阳,山中和安华·瓦利德(Anwar Walid)。 2020年。《自动交易的深度强化学习:整体策略》。 在ICAIF '20:ACM金融人工智能国际会议上,2020年10月15日至16日,纽约曼哈顿。 美国纽约州ACM。
总览 (Overview)
One can hardly overestimate the crucial role stock trading strategies play in investment.
人们几乎不能高估股票交易策略在投资中的关键作用。
Profitable automated stock trading strategy is vital to investment companies and hedge funds. It is applied to optimize capital allocation and maximize investment performance, such as expected return. Return maximization can be based on the estimates of potential return and risk. However, it is challenging to design a profitable strategy in a complex and dynamic stock market.
获利的自动股票交易策略对投资公司和对冲基金至关重要。 它用于优化资本分配和最大化投资绩效,例如预期收益。 收益最大化可以基于潜在收益和风险的估计。 但是,在复杂而动态的股票市场中设计一种有利可图的战略是一项挑战。
Every player wants a winning strategy. Needless to say, a profitable strategy in such a complex and dynamic stock market is not easy to design.
每个玩家都希望有一个获胜的策略。 毋庸置疑,在如此复杂而动态的股票市场中,要制定一项有利可图的策略并不容易。
Yet, we are to reveal a deep reinforcement learning scheme that automatically learns a stock trading strategy by maximizing investment return.
但是,我们将揭示一种深度强化学习方案,该方案可以通过最大化投资回报来自动学习股票交易策略。

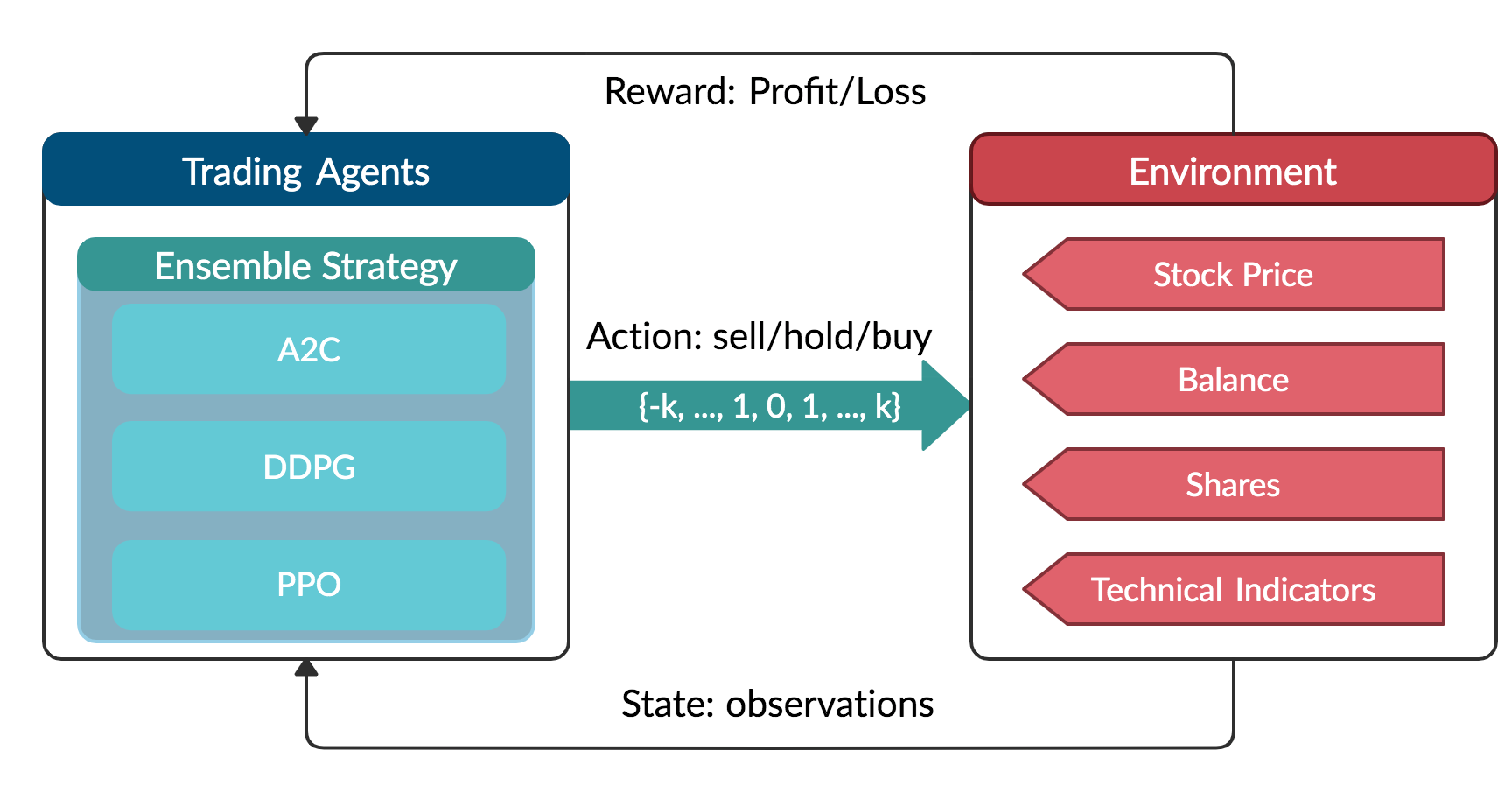
Our Solution: Ensemble Deep Reinforcement Learning Trading StrategyThis strategy includes three actor-critic based algorithms: Proximal Policy Optimization (PPO), Advantage Actor Critic (A2C), and Deep Deterministic Policy Gradient (DDPG).It combines the best features of the three algorithms, thereby robustly adjusting to different market conditions.
我们的解决方案 :整合深度强化学习交易策略此策略包括三种基于行为者批评的算法:近距离策略优化(PPO),优势行为者批评者(A2C)和深度确定性策略梯度(DDPG)。 它结合了三种算法的最佳功能,从而可以稳健地适应不同的市场条件。
The performance of the trading agent with different reinforcement learning algorithms is evaluated using Sharpe ratio and compared with both the Dow Jones Industrial Average index and the traditional min-variance portfolio allocation strategy.
使用夏普比率评估具有不同强化学习算法的交易代理商的绩效,并与道琼斯工业平均指数和传统的最小方差投资组合分配策略进行比较。
第1部分。为什么要在股票交易中使用深度强化学习(DRL)? (Part 1. Why do you want to use Deep Reinforcement Learning (DRL) for stock trading?)
Existing works are not satisfactory. Deep Reinforcement Learning approach has many advantages.
现有作品不令人满意。 深度强化学习方法具有许多优势。
1.1 DRL和现代投资组合理论(MPT) (1.1 DRL and Modern Portfolio Theory (MPT))
MPT performs not so well in out-of-sample data.
MPT在样本外数据中表现不佳。
MPT is very sensitive to outliers.
MPT 对异常值非常敏感 。
MPT is calculated only based on stock returns, if we want to take other relevant factors into account, for example some of the technical indicators like Moving Average Convergence Divergence (MACD), and Relative Strength Index (RSI), MPT may not be able to combine these information together well.
MPT 仅基于股票收益进行计算,如果我们要考虑其他相关因素 ,例如某些技术指标,例如移动平均收敛散度(MACD)和相对强度指数(RSI) ,MPT可能无法将这些信息很好地结合在一起。
1.2 DRL和监督式机器学习预测模型 (1.2 DRL and supervised machine learning prediction models)
DRL doesn’t need large labeled training datasets. This is a significant advantage since the amount of data grows exponentially today, it becomes very time-and-labor-consuming to label a large dataset.
DRL不需要大型的标签训练数据集 。 这是一个重要的优势,因为如今的数据量呈指数增长,因此标记大型数据集变得非常耗时且费力。
DRL uses a reward function to optimize future rewards, in contrast to an ML regression/classification model that predicts the probability of future outcomes.
与预测未来结果可能性的ML回归/分类模型相比,DRL使用奖励函数来优化未来奖励。
1.3 采用DRL股票交易中 的R ationale (1.3 The rationale of using DRL for stock trading)
The goal of stock trading is to maximize returns, while avoiding risks. DRL solves this optimization problem by maximizing the expected total reward from future actions over a time period.
股票交易的目的是在避免风险的同时最大化回报 。 DRL通过最大化一段时间内来自未来行动的预期总回报来解决此优化问题。
Stock trading is a continuous process of testing new ideas, getting feedback from the market, and trying to optimize the trading strategies over time. We can model stock trading process as Markov decision process which is the very foundation of Reinforcement Learning.
股票交易是一个不断测试新想法,从市场上获得反馈以及不断优化交易策略的连续过程 。 我们可以将股票交易过程建模为马尔可夫决策过程 ,这是强化学习的基础。
1.4 深度强化学习的优势 (1.4 The advantages of deep reinforcement learning)
Deep reinforcement learning algorithms can outperform human players in many challenging games. For example, in March 2016, DeepMind’s AlphaGo program, a deep reinforcement learning algorithm, beat the world champion Lee Sedol at the game of Go.
在许多具有挑战性的游戏中,深度强化学习算法可以胜过人类玩家 。 例如,2016年3月, DeepMind的AlphaGo程序(一种深度强化学习算法)在Go游戏中击败了世界冠军Lee Sedol。
Return maximization as trading goal: by defining the reward function as the change of the portfolio value, Deep Reinforcement Learning maximizes the portfolio value over time.
最大化回报作为交易目标 :通过将回报函数定义为投资组合价值的变化,深度强化学习可以使投资组合价值随时间最大化。
The stock market provides sequential feedback. DRL can sequentially increase the model performance during the training process.
股市提供顺序反馈 。 DRL可以在训练过程中顺序提高模型性能。
The exploration-exploitation technique balances trying out different new things and taking advantage of what’s figured out. This is difference from other learning algorithms. Also, there is no requirement for a skilled human to provide training examples or labeled samples. Furthermore, during the exploration process, the agent is encouraged to explore the uncharted by human experts.
勘探开发技术可以平衡尝试各种新事物并利用发现的优势。 这与其他学习算法不同。 而且,不需要技术人员提供训练实例或标记的样品。 此外,在探索过程中,鼓励代理商探索人类专家未知的领域。
Experience replay: is able to overcome the correlated samples issue, since learning from a batch of consecutive samples may experience high variances, hence is inefficient. Experience replay efficiently addresses this issue by randomly sampling mini-batches of transitions from a pre-saved replay memory.
经验重播 :能够克服相关样本的问题,因为从一批连续样本中学习可能会遇到很大的差异,因此效率很低。 体验重播通过从预先保存的重播内存中随机采样过渡的迷你批来有效地解决了这个问题。
Multi-dimensional data: by using a continuous action space, DRL can handle large dimensional data.
多维数据 :通过使用连续操作空间,DRL可以处理大型数据。
Computational power: Q-learning is a very important RL algorithm, however, it fails to handle large space. DRL, empowered by neural networks as efficient function approximator, is powerful to handle extremely large state space and action space.
计算能力 :Q学习是一种非常重要的RL算法,但是它不能处理大空间。 神经网络将DRL用作有效的函数逼近器,它可以强大地处理非常大的状态空间和动作空间。

第2部分:什么是强化学习? 什么是深度强化学习? 使用强化学习进行股票交易有哪些相关作品? (Part 2: What is Reinforcement Learning? What is Deep Reinforcement Learning? What are some of the related works to use Reinforcement Learning for stock trading?)
2.1概念 (2.1 Concepts)
Reinforcement Learning is one of three approaches of machine learning techniques, and it trains an agent to interact with the environment by sequentially receiving states and rewards from the environment and taking actions to reach better rewards.
强化学习是机器学习技术的三种方法之一,它通过顺序接收环境中的状态和奖励并采取行动以获得更好的奖励来训练代理与环境交互。
Deep Reinforcement Learning approximates the Q value with a neural network. Using a neural network as a function approximator would allow reinforcement learning to be applied to large data.
深度强化学习使用神经网络来近似Q值。 使用神经网络作为函数逼近器可以将强化学习应用于大数据。
Bellman Equation is the guiding principle to design reinforcement learning algorithms.
贝尔曼方程式是设计强化学习算法的指导原则。
Markov Decision Process (MDP) is used to model the environment.
马尔可夫决策过程(MDP)用于对环境进行建模。
2.2 相关作品 (2.2 Related works)
Recent applications of deep reinforcement learning in financial markets consider discrete or continuous state and action spaces, and employ one of these learning approaches: critic-only approach, actor-only approach, or and actor-critic approach.
深度强化学习在金融市场中的最新应用考虑了离散或连续的状态空间和动作空间,并采用了以下学习方法之一: 仅批评者方法,仅演员角色方法或演员批评方法。
1. Critic-only approach: the critic-only learning approach, which is the most common, solves a discrete action space problem using, for example, Q-learning, Deep Q-learning (DQN) and its improvements, and trains an agent on a single stock or asset. The idea of the critic-only approach is to use a Q-value function to learn the optimal action-selection policy that maximizes the expected future reward given the current state. Instead of calculating a state-action value table, DQN minimizes the mean squared error between the target Q-values, and uses a neural network to perform function approximation. The major limitation of the critic-only approach is that it only works with discrete and finite state and action spaces, which is not practical for a large portfolio of stocks, since the prices are of course continuous.
1.仅批评者的方法:仅批评者的学习方法是最常见的方法,它使用例如Q学习,深度Q学习(DQN)及其改进方法来解决离散的行动空间问题,并培训代理在单一股票或资产上。 仅限批评家的方法的想法是使用Q值函数来学习最佳操作选择策略,该策略在给定当前状态的情况下最大化预期的未来奖励。 DQN无需计算状态作用值表,而是将目标Q值之间的均方误差最小化 ,并使用神经网络执行函数逼近。 仅批评者方法的主要局限性在于,它仅适用于离散且有限的状态空间和动作空间,这对于大量的股票投资组合是不切实际的,因为价格当然是连续的。
Q-learning: is a value-based Reinforcement Learning algorithm that is used to find the optimal action-selection policy using a Q function.
Q学习:是一种基于值的强化学习算法,用于使用Q函数查找最佳的动作选择策略。
DQN: In deep Q-learning, we use a neural network to approximate the Q-value function. The state is given as the input and the Q-value of allowed actions is the predicted output.
DQN:在深度Q学习中,我们使用神经网络来近似Q值函数。 给出状态作为输入,允许动作的Q值是预测的输出。
2. Actor-only approach: The idea here is that the agent directly learns the optimal policy itself. Instead of having a neural network to learn the Q-value, the neural network learns the policy. The policy is a probability distribution that is essentially a strategy for a given state, namely the likelihood to take an allowed action. The actor-only approach can handle the continuous action space environments.
2.仅基于参与者的方法:这里的想法是代理直接学习最佳策略本身。 代替让神经网络学习Q值,神经网络学习策略。 策略是一种概率分布,本质上是一种针对给定状态的策略,即采取允许行动的可能性。 纯角色的方法可以处理连续的动作空间环境。
Policy Gradient: aims to maximize the expected total rewards by directly learns the optimal policy itself.
政策梯度:旨在通过直接学习最优政策本身来最大化预期的总回报。
3. Actor-Critic approach: The actor-critic approach has been recently applied in finance. The idea is to simultaneously update the actor network that represents the policy, and the critic network that represents the value function. The critic estimates the value function, while the actor updates the policy probability distribution guided by the critic with policy gradients. Over time, the actor learns to take better actions and the critic gets better at evaluating those actions. The actor-critic approach has proven to be able to learn and adapt to large and complex environments, and has been used to play popular video games, such as Doom. Thus, the actor-critic approach fits well in trading with a large stock portfolio.
3.行为者批判方法:行为者批判方法最近已在金融中应用。 想法是同时更新代表策略 的参与者网络和代表价值函数的批评者网络 。 评论者估计价值函数,而参与者则用策略梯度更新评论者指导的策略概率分布。 随着时间的流逝,演员学会采取更好的行动,评论家也变得更好地评估这些行动。 事实证明,演员批评方法能够学习并适应大型复杂环境,并且已被用于玩流行的视频游戏,例如《毁灭战士》。 因此,行动者批判方法非常适合大型股票投资组合的交易。
A2C: A2C is a typical actor-critic algorithm. A2C uses copies of the same agent working in parallel to update gradients with different data samples. Each agent works independently to interact with the same environment.
A2C: A2C是一种典型的actor-critic算法。 A2C使用并行工作的同一代理的副本来更新具有不同数据样本的梯度。 每个代理独立工作以与同一环境交互。
PPO: PPO is introduced to control the policy gradient update and ensure that the new policy will not be too different from the previous one.
PPO:引入PPO是为了控制策略梯度更新,并确保新策略与以前的策略没有太大不同。
DDPG: DDPG combines the frameworks of both Q-learning and policy gradient, and uses neural networks as function approximators.
DDPG: DDPG结合了Q学习和策略梯度的框架,并使用神经网络作为函数逼近器。
第3部分:如何使用DRL交易股票? (Part 3: How to use DRL to trade stocks?)

3.1数据 (3.1 Data)
We track and select the Dow Jones 30 stocks and use historical daily data from 01/01/2009 to 05/08/2020 to train the agent and test the performance. The dataset is downloaded from Compustat database accessed through Wharton Research Data Services (WRDS).
我们跟踪并选择道琼斯30只股票,并使用2009年1月1日至2020年5月8日的历史每日数据来训练代理商并测试业绩。 该数据集是从Compustat数据库下载的,该数据库可通过Wharton Research Data Services(WRDS)访问 。
The whole dataset is split in the following figure. Data from 01/01/2009 to 12/31/2014 is used for training, and the data from 10/01/2015 to 12/31/2015 is used for validation and tuning of parameters. Finally, we test our agent’s performance on trading data, which is the unseen out-of-sample data from 01/01/2016 to 05/08/2020. To better exploit the trading data, we continue training our agent while in the trading stage, since this will help the agent to better adapt to the market dynamics.
下图拆分了整个数据集。 2009年1月1日至2014年12月31日的数据用于训练 ,2015年10月1日至2015年12月31日的数据用于参数的验证和调整。 最后,我们测试代理商在交易数据上的表现,这是从01/01/2016到05/08/2020的未知样本数据。 为了更好地利用交易数据,我们将在交易阶段继续培训代理商,因为这将有助于代理商更好地适应市场动态。

3.2股票交易的MDP模型: (3.2 MDP model for stock trading:)
• State
深度学习用于股票预测_用于自动股票交易的深度强化学习相关推荐
- 基于深度学习的股票预测(完整版,有代码)
基于深度学习的股票预测 数据获取 数据转换 LSTM模型搭建 训练模型 预测结果 数据获取 采用tushare的数据接口(不知道tushare的筒子们自行百度一下,简而言之其免费提供各类金融数据 , ...
- 《强化学习周刊》第2期:多智能体强化学习(MARL)赋能“AI智能时代”
No.02 智源社区 强化学习组 R L 学 习 研究 观点 资源 活动 关于周刊 随着强化学习研究的不断成熟,如何将其结合博弈论的研究基础,解决多智能体连续决策与优化问题成为了新的研究领域,为了帮 ...
- 《强化学习周刊》第44期:RL-CoSeg、图强化学习、安全强化学习
No.44 智源社区 强化学习组 强 化 学 习 研究 观点 资源 活动 周刊订阅 告诉大家一个好消息,<强化学习周刊>已经开启"订阅功能",以后我们会向您自动推送最 ...
- 《强化学习周刊》第16期:多智能体强化学习的最新研究与应用
No.16 智源社区 强化学习组 强 化 学 习 研究 观点 资源 活动 关于周刊 强化学习作为人工智能领域研究热点之一,多智能强化学习的研究进展与成果也引发了众多关注.为帮助研究与工程人员了解该领 ...
- 《强化学习周刊》第69期:ICLR2023强化学习论文推荐、MIT实现自动调整内在奖励的强化学习...
No.69 智源社区 强化学习组 强 化 学 习 研究 观点 资源 活动 周刊订阅 告诉大家一个好消息,<强化学习周刊>已经开启"订阅功能",以后我们会向您自动推送最 ...
- 走向开放世界强化学习、IJCAI2022论文精选、机器人 RL 工具、强化学习招聘、《强化学习周刊》第73期...
No.73 智源社区 强化学习组 强 化 学 习 周刊订阅 <强化学习周刊>已经开启"订阅功能",扫描下面二维码,进入主页,选择"关注TA",我们 ...
- 【强化学习炼金术】李飞飞高徒范麟熙解析强化学习在游戏和现实中的应用
在新智元上一篇文章中,Jim Fan(范麟熙)介绍了强化学习的概念和目的.今天是<强化学习炼金术>Introduction第三讲. 在这一课里,Jim Fan会跟各位炼金术师们聊一聊游戏中 ...
- 深度学习cnn人脸检测_用于对象检测的深度学习方法:解释了R-CNN
深度学习cnn人脸检测 介绍 (Introduction) CNN's have been extensively used to classify images. But to detect an ...
- 深度学习做股票预测靠谱吗?
链接:https://www.zhihu.com/question/54542998 编辑:深度学习与计算机视觉 声明:仅做学术分享,侵删 作者:文兄 https://www.zhihu.com/qu ...
- 机器学习股票预测_是否进行基础投资工作,以尝试通过机器学习预测股票成功...
机器学习股票预测 Like most of you, I have a strong interest in making more money and growing my savings fast ...
最新文章
- mysql 4.1.10_Mysql4.1.10初级解读
- 再见,Kafka!再见,RocketMQ!
- 使用Delphi自带的TDockTabSet组件实现停靠功能(Jeremy North)
- Reactive Extensions简介一
- 结合zxing 和zbar 扫一扫
- [react] 请描述下事件在react中的处理方式是什么?
- 【算法分析与设计】基数排序
- 利用正则获取url传递的数据
- docker容器内漏洞_如何在2020年发现和修复Docker容器漏洞
- Airflow 中文文档:实验性 Rest API
- 杭电4500小Q系列故事——屌丝的逆袭
- python input函数的应用(接收用户的输入)
- metadata文件_用Kubernetes部署Springboot或Nginx,也就一个文件的事
- java大数据和python大数据的全面对比,哪个更主流?
- JVM基础思维导图(持续更新中)
- 高效能人士的七个习惯读后感与总结概括-(第五章)
- 最完整的Android 安卓开发体系了解一下
- 阿里面试官没想到,一个Volatile,我都能跟他吹半小时
- 魔兽私服 启动mysql_魔兽私服TrinityCore 运行调试流程
- WebView重定向和回退栈的问题,goBack不会回退的问题