由12306.cn谈谈网站性能技术
由12306.cn谈谈网站性能技术
12306.cn网站挂了,被全国人民骂了。我这两天也在思考这个事,我想以这个事来粗略地和大家讨论一下网站性能的问题。因为仓促,而且完全基于本人有限的经验和了解,所以,如果有什么问题还请大家一起讨论和指正。(这又是一篇长文,只讨论性能问题,不讨论那些UI,用户体验,或是是否把支付和购票下单环节分开的功能性的东西)
业务
任何技术都离不开业务需求,所以,要说明性能问题,首先还是想先说说业务问题。
- 其一,有人可能把这个东西和QQ或是网游相比。但我觉得这两者是不一样的,网游和QQ在线或是登录时访问的更多的是用户自己的数据,而订票系统访问的是中心的票量数据,这是不一样的。不要觉得网游或是QQ能行你就以为这是一样的。网游和QQ 的后端负载相对于电子商务的系统还是简单。
- 其二,有人说春节期间订火车的这个事好像网站的秒杀活动。的确很相似,但是如果你的思考不在表面的话,你会发现这也有些不一样。火车票这个事,还有很多查询操作,查时间,查座位,查铺位,一个车次不 行,又查另一个车次,其伴随着大量的查询操作,下单的时候需要对数据库操作。而秒杀,直接杀就好了。另外,关于秒杀,完全可以做成只接受前N个用户的请求(完全不操作后端的任何数据, 仅仅只是对用户的下单操作log),这种业务,只需要在内存cache中放好可秒杀的数量,还可以把数据分布开来放,100商品,10台服务器一台放10个,无需在当时操作任何数据库。可以订单数够后,停止秒杀,然后批量写数据库。而且秒杀的商品不多。火车票这个不是像秒杀那么简单的,春运时间,几乎所有的票都是热门票,而且几乎是全国人民都来了,而且还有转车业务,多条线的库存都要做事务操作,你想想吧,这有多难。(淘宝的双十一也就3百万用户,而火车票瞬时有千万级别甚至是亿级别的)(更新:2014年1月11日:来了淘宝后,对淘宝的系统有了解,淘宝的秒杀活动,本质上是用输验证码并在CDN上把用户直接过滤掉了,比如:1千万个用户过滤了只剩2万个用户,这样数据库就顶得住了)
- 其三,有人拿这个系统和奥运会的票务系统比较。我觉得还是不一样。虽然奥运会的票务系统当年也一上线就废了。但是奥运会用的是抽奖的方式,也就是说不存在先来先得的抢的方式,而且,是事后抽奖,事前只需要收信息,事前不需要保证数据一致性,没有锁,很容易水平扩展。
- 其四,订票系统应该和电子商务的订单系统很相似,都是需要对库存进行:1)占住库存,2)支付(可选),3)扣除库存的操作。这个是需要有一致性的检查的,也就是在并发时需要对数据加锁的。B2C的电商基本上都会把这个事干成异步的,也就是说,你下的订单并不是马上处理的,而是延时处理的,只有成功处理了,系统才会给你一封确认邮件说是订单成功。我相信有很多朋友都收到认单不成功的邮件。这就是说,数据一致性在并发下是一个瓶颈。
- 其五,铁路的票务业务很变态,其采用的是突然放票,而有的票又远远不够大家分,所以,大家才会有抢票这种有中国特色的业务的做法。于是当票放出来的时候,就会有几百万人甚至上千万人杀上去,查询,下单。几十分钟内,一个网站能接受几千万的访问量,这个是很恐怖的事情。据说12306的高峰访问是10亿PV,集中在早8点到10点,每秒PV在高峰时上千万。
多说几句:
- 库存是B2C的恶梦,库存管理相当的复杂。不信,你可以问问所有传统和电务零售业的企业,看看他们管理库存是多么难的一件事。不然,就不会有那么多人在问凡客的库存问题了。(你还可以看看《乔布斯传》,你就知道为什么Tim会接任Apple的CEO了,最主要的原因是他搞定了苹果的库存周期问题)
- 对于一个网站来说,浏览网页的高负载很容易搞定,查询的负载有一定的难度去处理,不过还是可以通过缓存查询结果来搞定,最难的就是下单的负载。因为要访问库存啊,对于下单,基本上是用异步来搞定的。去年双11节,淘宝的每小时的订单数大约在60万左右,京东一天也才能支持40万(居然比12306还差),亚马逊5年前一小时可支持70万订单量。可见,下订单的操作并没有我们相像的那么性能高。
- 淘宝要比B2C的网站要简单得多,因为没有仓库,所以,不存在像B2C这样有N个仓库对同一商品库存更新和查询的操作。下单的时候,B2C的 网站要去找一个仓库,又要离用户近,又要有库存,这需要很多计算。试想,你在北京买了一本书,北京的仓库没货了,就要从周边的仓库调,那就要去看看沈阳或 是西安的仓库有没有货,如果没有,又得看看江苏的仓库,等等。淘宝的就没有那么多事了,每个商户有自己的库存,库存就是一个数字,并且库存分到商户头上了,反而有利于性能扩展。
- 数据一致性才是真正的性能瓶颈。有 人说nginx可以搞定每秒10万的静态请求,我不怀疑。但这只是静态请求,理论值,只要带宽、I/O够强,服务器计算能力够,并支持的并发连接数顶得住10万TCP链接的建立 的话,那没有问题。但在数据一致性面前,这10万就完完全全成了一个可望不可及的理论值了。
我说那么多,我只是想从业务上告诉大家,我们需要从业务上真正了解春运铁路订票这样业务的变态之处。
前端性能优化技术
要解决性能的问题,有很多种常用的方法,我在下面列举一下,我相信12306这个网站使用下面的这些技术会让其性能有质的飞跃。
一、前端负载均衡
通过DNS的负载均衡器(一般在路由器上根据路由的负载重定向)可以把用户的访问均匀地分散在多个Web服务器上。这样可以减少Web服务器的请求负载。因为http的请求都是短作业,所以,可以通过很简单的负载均衡器来完成这一功能。最好是有CDN网络让用户连接与其最近的服务器(CDN通常伴随着分布式存储)。(关于负载均衡更为详细的说明见“后端的负载均衡”)
二、减少前端链接数
我看了一下12306.cn,打开主页需要建60多个HTTP连接,车票预订页面则有70多个HTTP请求,现在的浏览器都是并发请求的(当然,浏览器的一个页面的并发数是有限的,但是你挡不住用户开多个页面,而且,后端服务器TCP链接在前端断开始,还不会马上释放或重要)。所以,只要有100万个用户,就有可能会有6000万个链接(访问第一次后有了浏览器端的cache,这个数会下来,就算只有20%也是百万级的链接数),太多了。一个登录查询页面就好了。把js打成一个文件,把css也打成一个文件,把图标也打成一个文件,用css分块展示。把链接数减到最低。
三、减少网页大小增加带宽
这个世界不是哪个公司都敢做图片服务的,因为图片太耗带宽了。现在宽带时代很难有人能体会到当拨号时代做个图页都不敢用图片的情形(现在在手机端浏览也是这个情形)。我查看了一下12306首页的需要下载的总文件大小大约在900KB左右,如果你访问过了,浏览器会帮你缓存很多,只需下载10K左右的文件。但是我们可以想像一个极端一点的案例,1百万用户同时访问,且都是第一次访问,每人下载量需要1M,如果需要在120秒内返回,那么就需要,1M * 1M /120 * 8 = 66Gbps的带宽。很惊人吧。所以,我估计在当天,12306的阻塞基本上应该是网络带宽,所以,你可能看到的是没有响应。后面随着浏览器的缓存帮助12306减少很多带宽占用,于是负载一下就到了后端,后端的数据处理瓶颈一下就出来。于是你会看到很多http 500之类的错误。这说明后端服务器垮了。
四、前端页面静态化
静态化一些不常变的页面和数据,并gzip一下。还有一个变态的方法是把这些静态页面放在/dev/shm下,这个目录就是内存,直接从内存中把文件读出来返回,这样可以减少昂贵的磁盘I/O。使用nginx的sendfile功能可以让这些静态文件直接在内核心态交换,可以极大增加性能。
五、优化查询
很多人查询都是在查一样的,完全可以用反向代理合并这些并发的相同的查询。这样的技术主要用查询结果缓存来实现,第一次查询走数据库获得数据,并把数据放到缓存,后面的查询统统直接访问高速缓存。为每个查询做Hash,使用NoSQL的技术可以完成这个优化。(这个技术也可以用做静态页面)
对于火车票量的查询,个人觉得不要显示数字,就显示一个“有”或“无”就好了,这样可以大大简化系统复杂度,并提升性能。把查询对数据库的负载分出去,从而让数据库可以更好地为下单的人服务。
六、缓存的问题
缓存可以用来缓存动态页面,也可以用来缓存查询的数据。缓存通常有那么几个问题:
1)缓存的更新。也叫缓存和数据库的同步。有这么几种方法,一是缓存time out,让缓存失效,重查,二是,由后端通知更新,一量后端发生变化,通知前端更新。前者实现起来比较简单,但实时性不高,后者实现起来比较复杂 ,但实时性高。
2)缓存的换页。内存可能不够,所以,需要把一些不活跃的数据换出内存,这个和操作系统的内存换页和交换内存很相似。FIFO、LRU、LFU都是比较经典的换页算法。相关内容参看Wikipeida的缓存算法。
3)缓存的重建和持久化。缓存在内存,系统总要维护,所以,缓存就会丢失,如果缓存没了,就需要重建,如果数据量很大,缓存重建的过程会很慢,这会影响生产环境,所以,缓存的持久化也是需要考虑的。
诸多强大的NoSQL都很好支持了上述三大缓存的问题。
后端性能优化技术
前面讨论了前端性能的优化技术,于是前端可能就不是瓶颈问题了。那么性能问题就会到后端数据上来了。下面说几个后端常见的性能优化技术。
一、数据冗余
关于数据冗余,也就是说,把我们的数据库的数据冗余处理,也就是减少表连接这样的开销比较大的操作,但这样会牺牲数据的一致性。风险比较大。很多人把NoSQL用做数据,快是快了,因为数据冗余了,但这对数据一致性有大的风险。这需要根据不同的业务进行分析和处理。(注意:用关系型数据库很容易移植到NoSQL上,但是反过来从NoSQL到关系型就难了)
二、数据镜像
几乎所有主流的数据库都支持镜像,也就是replication。数据库的镜像带来的好处就是可以做负载均衡。把一台数据库的负载均分到多台上,同时又保证了数据一致性(Oracle的SCN)。最重要的是,这样还可以有高可用性,一台废了,还有另一台在服务。
数据镜像的数据一致性可能是个复杂的问题,所以我们要在单条数据上进行数据分区,也就是说,把一个畅销商品的库存均分到不同的服务器上,如,一个畅销商品有1万的库存,我们可以设置10台服务器,每台服务器上有1000个库存,这就好像B2C的仓库一样。
三、数据分区
数据镜像不能解决的一个问题就是数据表里的记录太多,导致数据库操作太慢。所以,把数据分区。数据分区有很多种做法,一般来说有下面这几种:
1)把数据把某种逻辑来分类。比如火车票的订票系统可以按各铁路局来分,可按各种车型分,可以按始发站分,可以按目的地分……,反正就是把一张表拆成多张有一样的字段但是不同种类的表,这样,这些表就可以存在不同的机器上以达到分担负载的目的。
2)把数据按字段分,也就是竖着分表。比如把一些不经常改的数据放在一个表里,经常改的数据放在另外多个表里。把一张表变成1对1的关系,这样,你可以减少表的字段个数,同样可以提升一定的性能。另外,字段多会造成一条记录的存储会被放到不同的页表里,这对于读写性能都有问题。但这样一来会有很多复杂的控制。
3)平均分表。因为第一种方法是并不一定平均分均,可能某个种类的数据还是很多。所以,也有采用平均分配的方式,通过主键ID的范围来分表。
4)同一数据分区。这个在上面数据镜像提过。也就是把同一商品的库存值分到不同的服务器上,比如有10000个库存,可以分到10台服务器上,一台上有1000个库存。然后负载均衡。
这三种分区都有好有坏。最常用的还是第一种。数据一旦分区,你就需要有一个或是多个调度来让你的前端程序知道去哪里找数据。把火车票的数据分区,并放在各个省市,会对12306这个系统有非常有意义的质的性能的提高。
四、后端系统负载均衡
前面说了数据分区,数据分区可以在一定程度上减轻负载,但是无法减轻热销商品的负载,对于火车票来说,可以认为是大城市的某些主干线上的车票。这就需要使用数据镜像来减轻负载。使用数据镜像,你必然要使用负载均衡,在后端,我们可能很难使用像路由器上的负载均衡器,因为那是均衡流量的,因为流量并不代表服务器的繁忙程度。因此,我们需要一个任务分配系统,其还能监控各个服务器的负载情况。
任务分配服务器有一些难点:
- 负载情况比较复杂。什么叫忙?是CPU高?还是磁盘I/O高?还是内存使用高?还是并发高?还是内存换页率高?你可能需要全部都要考虑。这些信息要发送给那个任务分配器上,由任务分配器挑选一台负载最轻的服务器来处理。
- 任务分配服务器上需要对任务队列,不能丢任务啊,所以还需要持久化。并且可以以批量的方式把任务分配给计算服务器。
- 任务分配服务器死了怎么办?这里需要一些如Live-Standby或是failover等高可用性的技术。我们还需要注意那些持久化了的任务的队列如何转移到别的服务器上的问题。
我看到有很多系统都用静态的方式来分配,有的用hash,有的就简单地轮流分析。这些都不够好,一个是不能完美地负载均衡,另一个静态的方法的致命缺陷是,如果有一台计算服务器死机了,或是我们需要加入新的服务器,对于我们的分配器来说,都需要知道的。另外,还要重算哈希(一致性hash可以部分解决这个问题)。
还有一种方法是使用抢占式的方式进行负载均衡,由下游的计算服务器去任务服务器上拿任务。让这些计算服务器自己决定自己是否要任务。这样的好处是可以简化系统的复杂度,而且还可以任意实时地减少或增加计算服务器。但是唯一不好的就是,如果有一些任务只能在某种服务器上处理,这可能会引入一些复杂度。不过总体来说,这种方法可能是比较好的负载均衡。
五、异步、 throttle 和 批量处理
异步、throttle(节流阀) 和批量处理都需要对并发请求数做队列处理的。
- 异步在业务上一般来说就是收集请求,然后延时处理。在技术上就是可以把各个处理程序做成并行的,也就可以水平扩展了。但是异步的技术问题大概有这些,a)被调用方的结果返回,会涉及进程线程间通信的问题。b)如果程序需要回滚,回滚会有点复杂。c)异步通常都会伴随多线程多进程,并发的控制也相对麻烦一些。d)很多异步系统都用消息机制,消息的丢失和乱序也会是比较复杂的问题。
- throttle 技术其实并不提升性能,这个技术主要是防止系统被超过自己不能处理的流量给搞垮了,这其实是个保护机制。使用throttle技术一般来说是对于一些自己无法控制的系统,比如,和你网站对接的银行系统。
- 批量处理的技术,是把一堆基本相同的请求批量处理。比如,大家同时购买同一个商品,没有必要你买一个我就写一次数据库,完全可以收集到一定数量的请求,一次操作。这个技术可以用作很多方面。比如节省网络带宽,我们都知道网络上的MTU(最大传输单元),以态网是1500字节,光纤可以达到4000多个字节,如果你的一个网络包没有放满这个MTU,那就是在浪费网络带宽,因为网卡的驱动程序只有一块一块地读效率才会高。因此,网络发包时,我们需要收集到足够多的信息后再做网络I/O,这也是一种批量处理的方式。批量处理的敌人是流量低,所以,批量处理的系统一般都会设置上两个阀值,一个是作业量,另一个是timeout,只要有一个条件满足,就会开始提交处理。
所以,只要是异步,一般都会有throttle机制,一般都会有队列来排队,有队列,就会有持久化,而系统一般都会使用批量的方式来处理。
云风同学设计的“排队系统” 就是这个技术。这和电子商务的订单系统很相似,就是说,我的系统收到了你的购票下单请求,但是我还没有真正处理,我的系统会跟据我自己的处理能力来throttle住这些大量的请求,并一点一点地处理。一旦处理完成,我就可以发邮件或短信告诉用户你来可以真正购票了。
在这里,我想通过业务和用户需求方面讨论一下云风同学的这个排队系统,因为其从技术上看似解决了这个问题,但是从业务和用户需求上来说可能还是有一些值得我们去深入思考的地方:
1)队列的DoS攻击。首先,我们思考一下,这个队是个单纯地排队的吗?这样做还不够好,因为这样我们不能杜绝黄牛,而且单纯的ticket_id很容易发生DoS攻击,比如,我发起N个 ticket_id,进入购票流程后,我不买,我就耗你半个小时,很容易我就可以让想买票的人几天都买不到票。有人说,用户应该要用身份证来排队, 这样在购买里就必需要用这个身份证来买,但这也还不能杜绝黄牛排队或是号贩子。因为他们可以注册N个帐号来排队,但就是不买。黄牛这些人这个时候只需要干一个事,把网站搞得正常人不能访问,让用户只能通过他们来买。
2)对列的一致性?对这个队列的操作是不是需要锁?只要有锁,性能一定上不去。试想,100万个人同时要求你来分配位置号,这个队列将会成为性能瓶颈。你一定没有数据库实现得性能好,所以,可能比现在还差。抢数据库和抢队列本质上是一样的。
3)队列的等待时间。购票时间半小时够不够?多不多?要是那时用户正好不能上网呢?如果时间短了,用户不够时间操作也会抱怨,如果时间长了,后面在排队的那些人也会抱怨。这个方法可能在实际操作上会有很多问题。另外,半个小时太长了,这完全不现实,我们用15分钟来举例:有1千万用户,每一个时刻只能放进去1万个,这1万个用户需要15分钟完成所有操作,那么,这1千万用户全部处理完,需要1000*15m = 250小时,10天半,火车早开了。(我并非信口开河,根据铁道部专家的说明:这几天,平均一天下单100万,所以,处理1000万的用户需要十天。这个计算可能有点简单了,我只是想说,在这样低负载的系统下用排队可能都不能解决业务问题)
4)队列的分布式。这个排队系统只有一个队列好吗?还不足够好。因为,如果你放进去的可以购票的人如果在买同一个车次的同样的类型的票(比如某动车卧铺),还是等于在抢票,也就是说系统的负载还是会有可能集中到其中某台服务器上。因此,最好的方法是根据用户的需求——提供出发地和目的地,来对用户进行排队。而这样一来,队列也就可以是多个,只要是多个队列,就可以水平扩展了。这样可以解决性能问题,但是没有解决用户长时间排队的问题。
我觉得完全可以向网上购物学习。在排队(下单)的时候,收集好用户的信息和想要买的票,并允许用户设置购票的优先级,比如,A车次卧铺买 不到就买 B车次的卧铺,如果还买不到就买硬座等等,然后用户把所需的钱先充值好,接下来就是系统完全自动地异步处理订单。成功不成功都发短信或邮件通知用户。这样,系统不仅可以省去那半个小时的用户交互时间,自动化加快处理,还可以合并相同购票请求的人,进行批处理(减少数据库的操作次数)。这种方法最妙的事是可以知道这些排队用户的需求,不但可以优化用户的队列,把用户分布到不同的队列,还可以像亚马逊的心愿单一样,通过一些计算就可以让铁道部做车次统筹安排和调整(最后,排队系统(下单系统)还是要保存在数据库里的或做持久化,不能只放在内存中,不然机器一down,就等着被骂吧)。
小结
写了那么多,我小结一下:
0)无论你怎么设计,你的系统一定要能容易地水平扩展。也就是说,你的整个数据流中,所有的环节都要能够水平扩展。这样,当你的系统有性能问题时,“加30倍的服务器”才不会被人讥笑。
1)上述的技术不是一朝一夕能搞定的,没有长期的积累,基本无望。我们可以看到,无论你用哪种都会引发一些复杂性,设计总是在做一种权衡。
2)集中式的卖票很难搞定,使用上述的技术可以让订票系统能有几佰倍的性能提升。而在各个省市建分站,分开卖票,是能让现有系统性能有质的提升的最好方法。
3)春运前夕抢票且票量供远小于求这种业务模式是相当变态的,让几千万甚至上亿的人在某个早晨的8点钟同时登录同时抢票的这种业务模式是变态中的变态。业务形态的变态决定了无论他们怎么办干一定会被骂。
4)为了那么一两个星期而搞那么大的系统,而其它时间都在闲着,有些可惜了,这也就是铁路才干得出来这样的事了。
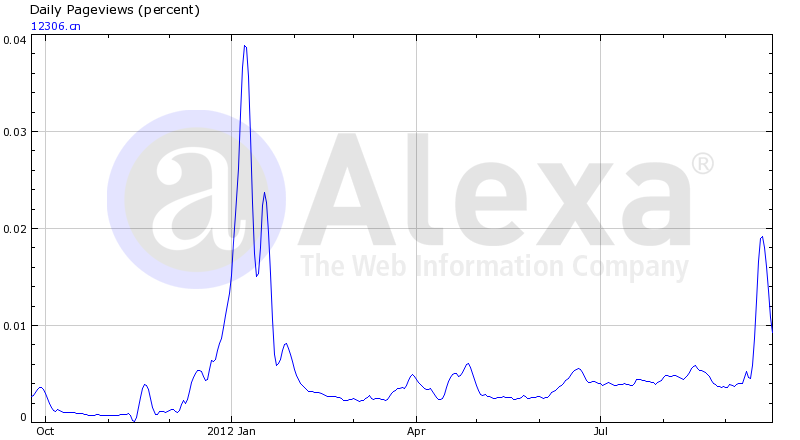
更新2012年9月27日
Alexa 统计的12306的PV (注:Alexa的PV定义是:一个用户在一天内对一个页面的多次点击只算一次)
(本文转载时请注明作者和出处,请勿于记商业目的)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell.cn ,请勿用于任何商业用途)

 (85 人打了分,平均分: 4.88 )
(85 人打了分,平均分: 4.88 )
相关文章
- 2012年06月20日 性能调优攻略
- 2012年09月07日 无锁队列的实现
- 2012年07月11日 28个Unix/Linux的命令行神器
- 2012年05月03日 用Unix的设计思想来应对多变的需求
- 2012年03月13日 多版本并发控制(MVCC)在分布式系统中的应用
- 2014年01月20日 分布式系统的事务处理
- 2012年07月13日 代码执行的效率
- 2012年03月26日 需求变化与IoC
- jordge2012年9月24日15:57 | #1回复 | 引用
把票务问题,归结为库存问题,是受传统业务模型限制了。为一张车票设计对象,代价太大,如果发售15天的票,再按照列车的运力2000人,计算,不管有没有人买这些票,都得占据15*2000=30000条库存/趟列车——这简直是在糟蹋硬件。。。。。采用这种模型还使得扩展性变得极差,必须采用异构数据模型替代(nosql),增加了设计和开发难度,一致性的性能将会成为个系统之间的瓶颈。总之,需要更好的模型,才能得到更好的性价比。
- 大自在真人2012年9月30日10:34 | #2回复 | 引用
可以了解一下Oracle的锁机制,没有锁管理器,并发压力被下放到数据库内存结构和数据块以及Undu段上了@bsidb
- appledf2012年10月6日22:33 | #3回复 | 引用
同意1楼看法,
这种业务相对单一的系统使用nosql会好很多.
服务器端解析和应答,可以考虑另行开发.减少不不要的开销.
增强吞吐量,参考小nodejs - Jerrygee2012年10月6日23:30 | #4回复 | 引用
如果只是为了解决这个订票问题,不应该从技术上着手。业务模式稍微调整下,根本不需要很难的技术。单一技术化解决问题是个死胡同。
拥塞问题的关键是没有解决好调度,结果导致大量的重复和无效操作。首先,说线上跟车站售票系统共享一个数据库限制了性能,根本不是那么回事。分析一下:
1.库存不是瓶颈。线下的卖票窗口可以把所有的票卖光,而这些交易都是通过现有的数据库完成的,节假日去窗口买票都是没有票卖,就说明原有的线下系统的问题不是交易处理能力不够,票都卖没了。这就说明数据库的交易处理能力完全可以把所有票都卖出去,问题是线上系统上了以后,没有调度好请求。我们根本不用去分析什么票锁定的细节实现,现有系统能卖光票,事实已经说话了。我们需要去担忧什么后端数据库的性能问题么?
2.基于第一点,连现有的这个通用的交易系统都可以满足交易需求,那么如果想进一步加快出票速度,加一个网上订票系统数据库(参照第一点来说这没多大必要),也很简单。不需要很复杂的同步技术,只要改造或者配置现有的客票数据库,加一个批量调票接口即可。12306只要按照一定的时间间隔,对于已经卖完的票,从现有数据库系统里面调票。每次按照比例或者一定的张数来调整,线上每车次总票数也可以限定(否则可能线下买不到票了)。举个例子,比如每隔5分钟,某车次A卖光了,查了线下库里面还有1000张,那么一次可以扣比如200张出来,批量在线下库里设置标志(批量做比单张做效率显然要高很多)。或者按照一个车厢为单位调都可以。然后这批票进入线上库,调过来后,线上库里面该怎么设计存储模式,用高性能的机器都没问题,根本不受现有系统影响。如果需要,卖不完的票还可以回调。3.排队和异步。跟线下系统比,线上系统导致请求数拥塞的一个关键问题是重复请求:重复刷新和重复排队。线下一个人不可能短时间内去窗口排N次,那么我们线上系统也要保证。线上的优势是可以异步,对应到现实,类似于银行的领号。解决重复排队,就必须要能鉴别用户实体,用预先注册和线下验证结合的方式就能实现。每个用户根据身份证事先在系统里注册一个ID,注册时,使用身份证号和住址信息,就基本能杜绝冒名注册。或者只是用身份证号也可以,用户必须要预先注册,如果只使用身份证号那么存在冒名注册的可能,就需要提供线下拿身份证去验证的手段。(平时非高峰时间允许现有的不用身份证登录购买方式)。
订票过程:
a.余票查询:余票查询不需要严格跟实际库同步,同样定时同步即可。也就是查询到的是准实时的数据。这样这部分数据只要从客票数据库定时推送就可以。数据分布都可以独立优化。这里只有一个接口来更新数据,开放给外部的基本是只读的,不涉及到锁的问题。数据是准实时的(对于这样一个业务系统,完全实时根本没意义)。刷新的间隔后台可以根据规则调整。这个查询功能可以很容易的水平扩展。
b.订票:用户编辑一个订单,填写需要的车次。比如可以填n个车次/硬座/卧铺的组合选择。用户根据前面间隔查询的结果,大概可以估算客票订出的速度,填几个车次,提交订单。订单进入排队。系统根据现有队列长度估算处理时间反馈,如果觉得时间太长可以立即取消。
c.队列限制机制:每个客户提交订单的时候系统在客户记录上标记上次提交的时间(包括立即取消的),间隔一定时间内重复提交直接拒绝(间隔值根据情况调整)。超过这个时间后,重复提交,系统直接在现有队列里面查找,如果查找到现有的订单还没处理完,直接拒绝。这样就杜绝基本重复提交的情况。身份证号码是个分布很有规律的东西,这个队列查找很容易优化。订单一定时间后没有排到处理,用户可以取消排队。频繁恶意提交订单的,提交间隔按照一定规律加大。外挂严重的话,刷外挂的直接法律处罚。d.支付问题:用户在查客票时已经确定了票价,票款预先存入。订票时不需要跟银行接口打交道。直接在用户帐户扣钱。这样只要票有肯定可以成功,没有的话短信或者其他方式通知用户。
e.票锁定问题,如果票进入自己系统了,怎么搞都可以了。比如按照车次分库,分拣排队的单子,根据某辆车达到的请求量和间隔最大时间两个指标,把分拣后同一个车次批量出票分发。卖完了的车,没票就是没票了,通知用户订票失败,再订就不可能再有票出来。退出来的票量也不多,为这部分不必要导致重复提交无效订单和增加复杂性,退出来的票放到线下去卖就是了。4.公平原则的保证:前面有人提到网络延时问题和不会上网人群的问题。不会上网的人可以找人帮忙注册用户,买票可以允许特定机构代买,类似订票点那样一张票收5元钱手续费。网络延时问题,这个具体的表现可能要测试后才知道具体情况,不过,有了前面的限制重复提交,限制提交间隔的措施,这个排队会好很多。对于抢队列问题,引入一定时间段内随机排队,比如0-5分钟内用户在队列里面,5-10分钟内提交的订单,在5-10分钟内收订单,到第10分钟末,这批用户顺序随机打乱一次,然后再排在0-5分钟那波后面。每天不同的时段这个值还可以根据负载和票供应调整,这个时间分段调整一个合理的数值,可以保证网速快的不会排网速慢的前面。(这里有个问题是,提交订单在大并发请求的时候,会演化为拼网速抢前面时间段的问题。而时段内随机排序在某种情况下演化为摇号,对于热门票,比如半小时内就卖光的,这种票按照排队已经早失去公平意义了,干脆就让它每天或者几小时后就随机排一次,就演化为摇号好了。这一点没有完美方案。)
总结一下,关键点就是:全异步,无竞争,杜绝重复排队。
硬件上没多少投入。只要保证每个用户能成功提交订单就行了。 - Jerrygee2012年10月6日23:50 | #5回复 | 引用
还有人提到IBM的方案,IBM的方案很多都是大忽悠。IBM的很多技术方案,看起来似乎很美。仔细一推敲漏洞就出来了,但是他们往往通过偷换概念,避重就轻之类忽悠过去。他们的强项是方案包装能力,不是方案好,更不是方案的实际能力,拿了方案,拿了钱,到实际实现了一看根本不是那么回事,拍板的领导这个时候也只能哑巴吃黄连,说这方案挺好。
公司里曾经有一次跟IBM合作,钱一签合同就给了大半,但是后来交付难,方案不可靠,功能效果差。后来我干脆扔了这个方案,自己设计了个方案,用免费的东西实施半个月完成了。 - scott2012年10月12日17:21 | #6回复 | 引用
“单一技术化解决问题是个死胡同”, 这句话很赞同。“程序猿”很容易陶醉在自己的纯技术方案中,而忘记了非技术的方案。@Jerrygee
- yalung2012年10月12日17:45 | #7回复 | 引用
不明白锁库存怎么会成为瓶颈,只有属于同一个车次的才需要锁。不同车次的自然并发了。
- yalung2012年10月12日18:17 | #8回复 | 引用
或者这么想吧,假设12306网站限制为只售卖一个车次的票,这个是不是相对比较简单?
由于大家都知道了只有这个车次的才能网上买,所以访问量也会比现在少很多。那么如果这一个车次可以做好了,多个车次就不成问题,在最前端有一个入口,用户首先选择车次,然后就直接路由到了处理该车次的子站(服务器)。
主入口(主站)不需要任何处理,只帮助用户根据目的地获取车次信息,这些信息都是静态的(甚至都可以下载到客户端),就算这时候显示车次剩余票量,也没有关系,这个读操作并不需要锁,读到较旧数据也无妨;用户一旦选择了车次,就分流到子站处理交易过程,这时候和12306支持一个车次的购票没有区别。
- oneman2012年10月16日17:37 | #9回复 | 引用
其实我觉得架构是次要的,关键是铁道部的运营能力不行,很多时候一些简单的策略就可以弥补开发商的不足。
- dfg2012年10月19日15:52 | #10回复 | 引用
alert(‘aaa’);
- 24影视2012年10月27日16:04 | #11回复 | 引用
原来要考虑这么多问题的
- hejxing2012年11月6日03:49 | #12回复 | 引用
关键是铁铁老大没有做好这个系统的动力!
其实他这个系统的数据和业务是最容易分区后并发的,绝对比QQ,京东简单! - tg2012年11月8日18:11 | #13回复 | 引用
@yalung 我的想法也是这样,按车次分库分表,问题的规模一下子就小了很多,一个车次也就是不到5000张票的销售问题。
- 访客2013年1月11日14:53 | #14回复 | 引用
恕我直言,看了您的方案,我感觉纯粹是为了减小数据库压力,而把bug转嫁到用户身上。异步的数据查询,查到有票其实未必有;如果再加上定票一次异步,下单一次异步,3个异步下来我觉得我买到票的几率趋于0。@Jerrygee
- 疑问从从2013年1月14日11:01 | #15回复 | 引用
1) 12306后台数据可以cache? 大家访问信息都是一样的,有无剩余票怎么判定?
2) nosql这个肯定不会用在12306的核心业务上吧!节假日期间临时添加上千台server不好么?
- 熊猫家族2013年1月16日09:35 | #16回复 | 引用
分析的有道理, 不过真正的细节可能太多了 我们往往可能没有考虑的全面吧
- 老蔡2013年1月16日13:14 | #17回复 | 引用
错字:
还不会马上释放或重要–>还不会马上释放或重用 - 大浪淘沙2013年1月20日15:34 | #18回复 | 引用
“打开主页需要建60多个HTTP连接,车票预订页面则有70多个HTTP请求,现在的浏览器都是并发请求的(当然,浏览器的一个页面的并发数是有限的,但是你挡不住用户开多个页面,而且,后端服务器TCP链接在前端断开始,还不会马上释放或重要)。所以,只要有100万个用户,就有可能会有6000万个链接”
1、“后端服务器TCP链接在前端断开始,还不会马上释放或重要”,这错字应该是想说后端在前端链接开始,还不会马上释放资源吧,说的是TIME_WAIT?TIME_WAIT是主动关闭方才会进入的,也就是前端主动关闭链接的话,后端并不会因此进入TIME_WAIT状态。
2、链接并不是那样算的。假设站点只有一个域,浏览器同域并发请求数为6,那么,打开主页需要60个链接的话,那么,浏览器会开6个链接,这6个链接处理完并不会关闭,而是直接复用再处理接下来的请求。因此即使你抓包看到有60个http请求,但并没有导致60个链接,是6个,谢谢。
- 种地的码农2013年1月21日11:13 | #19回复 | 引用
如果铁道部花的3亿元,货真价实的话,搞一套弹性分配的子系统解决并发问题,可行性有多高?
用户下单后,调度系统根据线路和车次,把用户请求分配到指定的子系统内处理。
每个子系统只卖指定的几个车厢的票。每个子系统都有结算和出票的功能。
原理是:根据起点和终点分配车厢,车厢分散在各个子系统内,只有重现身体证排重时,异步校验可解。
现在虚拟技术这么成熟,随时招唤多少系统都是可有的。
- Wooyun2013年1月21日16:49 | #20回复 | 引用
“>
- it民工2013年1月21日17:30 | #21回复 | 引用
种地的码农 :
如果铁道部花的3亿元,货真价实的话,搞一套弹性分配的子系统解决并发问题,可行性有多高?
用户下单后,调度系统根据线路和车次,把用户请求分配到指定的子系统内处理。
每个子系统只卖指定的几个车厢的票。每个子系统都有结算和出票的功能。
原理是:根据起点和终点分配车厢,车厢分散在各个子系统内,只有重现身体证排重时,异步校验可解。
现在虚拟技术这么成熟,随时招唤多少系统都是可有的。确实如此,可以通过虚拟技术让独立的自系统去处理特定范围的车票!而且扩展简单,方便.通过简单的配置即可实现
- 石板材2013年3月11日17:18 | #22回复 | 引用
楼主分析得很有道理。
- 大专2013年3月11日17:22 | #23回复 | 引用
访问10亿PV,流量真大。
- ナイキ サッカー2013年4月10日11:40 | #24回复 | 引用
I blog quite often and I truly thank you for your content. Your article has really peaked my interest. I’m going to take a note of your website and keep checking for new details about once a week. I opted in for your RSS feed too.
- 踏途如虹2013年7月1日02:11 | #25回复 | 引用
@soarstars
因为电信的带宽是计算好的 你没看微信挤压可多少带宽么 - xtt2013年7月2日15:45 | #26回复 | 引用
@大浪淘沙
当你说谢谢的时候,你有点太自大了,虚心一点好。前台连接不是数据库连接,不是说创建连接占据了大部分的时间成本,实际上也没有所谓的几个连接对象这样的概念,每个连接其实就是一次活动,6个连接只是限制同时进行6个这个活动,你说其实连接是复用的,创建连接需要多少时间?在整个时间周期内是完全忽略的,请几次查看httpwatch的时间周期,如果把一次连接的时间分段,实际上耗时间的不外乎是等待服务器计算响应的时间和数据传输时间,这部分时间是可观的,当你省下了次数,你就省下了n个这些时间,你还是省下了n个请求头信息(包含cookie)和响应头信息。 - taojing2013年8月6日20:50 | #27回复 | 引用
@Jerrygee
说的不错。单一的技术化思路,只会陷入技术死胡同越陷越深。有时候要跳出来,从业务上去看,从现实中一些事情去看。现实中的思想用到技术中去。技术只是一个工具而已,确定一种什么思想,然后以技术为工具去解决。单纯为技术而技术达不到境界的。万事万物有其相互融通的一面。哲学思想。
物理学家朱清时曾说:”科学家千辛万苦爬到山顶时,佛学大师已经在此等候多时了!”做技术做到高境界就是一种哲学思想层面上了。
在这里:http://www.bskk.com/thread-207412-1-1.html - 撒旦撒2013年8月19日15:15 | #28回复 | 引用
@Jerrygee 的撒的撒
- gcd03182013年12月30日04:11 | #29回复 | 引用
又快春运了……话说皓兄这还是工程师的眼光,不是产品和架构的眼光。其实唯一的问题就是,每次操作都要读/写数据库,根本不能靠缓存,如果页面性能好,让用户立刻可以操作,那数据库的压力必然是更大的。至于分中心存数据……似是而非。除了总入口和访问路由以外,数据本身也是问题。一列车的数据不能分开存放,但是用户可能要买任何车的任何两站之间的票。假设每列车的数据都存在始发站所在地的数据中心,那么买过路车,就可能需要连接多个数据中心,这时候恐怕最大的性能压力就转移到了数据路由上,最终用户体验到的还是一如既往的慢
说到底,前面有位网友说对了,业务有问题。其实火车票根本不适合网上销售,平时好买的时候没必要,等到不好买的时候不能指望 - 古城痴人2014年1月4日00:46 | #30回复 | 引用
细节是魔鬼,12306的业务肯定不像各位网友想的那么简单,这个真不是那么容易做出来的,都是站着说话不腰疼。
- 谷壳2014年1月9日10:57 | #31回复 | 引用
yalung :
或者这么想吧,假设12306网站限制为只售卖一个车次的票,这个是不是相对比较简单?
由于大家都知道了只有这个车次的才能网上买,所以访问量也会比现在少很多。
那么如果这一个车次可以做好了,多个车次就不成问题,在最前端有一个入口,用户首先选择车次,然后就直接路由到了处理该车次的子站(服务器)。
主入口(主站)不需要任何处理,只帮助用户根据目的地获取车次信息,这些信息都是静态的(甚至都可以下载到客户端),就算这时候显示车次剩余票量,也没有关系,这个读操作并不需要锁,读到较旧数据也无妨;用户一旦选择了车次,就分流到子站处理交易过程,这时候和12306支持一个车次的购票没有区别。我的观点与你的差不多,一个车次的票数和购票人数都比较有限,表的大小和锁开销都会小许多,并且购买人群的物理位置相对比较集中,先按只有一个车次来做并部署到主要城市,然后在前面加一个路由选择,水平扩展能力达到完美,一年就那么几天忙,暂时租用大量的服务器在投资上也很合算。
- free2014年1月10日14:16 | #32回复 | 引用
楼主的分析有理,但只针对实时业务系统,我认为12306的业务模式有问题,春运和十一等购票业务原本是预定业务,不是实时购票业务,如果做成类似于高考填志愿类型的预定业务,则不需要很复杂的技术就可实现售票操作;即填写购票意向,由后台服务器自动计算分配,采用类似第一志愿、优先级、摇号等策略应对票额不足情况;反正票不足,根本无法保持绝对公平,抢票只能是消耗不必要的资源,平时更是巨大的浪费;不如优雅点,填购票意向,等通知总好过没头脑一窝蜂的抢要好,也易设计实现。
后台计算分配票,在系统压力上,比千万人实时抢票,要低的多,资源占用也少的多,也容易测试和实现,还能有精力去研究提高购票的易用性。
所以,业务架构的严重错误,导致了今天的居民啊,可悲的是,他们还不打算改,要一条路走到黑。 - free2014年1月10日14:18 | #33回复 | 引用
楼主的分析有理,但只针对实时业务系统,我认为12306的业务模式有问题,春运和十一等购票业务原本是预定业务,不是实时购票业务,如果做成类似于高考填志愿类型的提前的预定业务,则不需要很复杂的技术就可实现售票操作;即提前若干天填写购票意向,由后台服务器在指定时间自动计算分配,采用类似第一志愿、优先级、摇号等策略应对票额不足情况;反正票不足,根本无法保持绝对公平,抢票只能是消耗不必要的资源,平时更是巨大的浪费;不如优雅点,填购票意向,等通知总好过没头脑一窝蜂的抢要好,也易设计实现。
后台计算分配票,在系统压力上,比千万人实时抢票,要低的多,资源占用也少的多,也容易测试和实现,还能有精力去研究提高购票的易用性。
所以,业务架构的严重错误,导致了今天的居民啊,可悲的是,他们还不打算改。 - free2014年1月10日14:21 | #34回复 | 引用
楼主的分析有理,但只针对实时高压力业务系统;我认为12306的业务模式有问题,春运和十一等购票业务原本是预定业务,不是实时购票业务;如果做成类似于高考填志愿类型的提前的预定业务,则不需要很复杂的技术就可实现售票操作;即提前若干天非集中式填写购票意向,由后台服务器在指定时间自动计算分配,采用类似第一志愿、优先级、摇号等策略应对票额不足情况;反正票不足,根本无法保持绝对公平,抢票只能是消耗不必要的资源,平时更是巨大的浪费;不如优雅点,填购票意向,等通知总好过没头脑一窝蜂的抢要好,也易设计实现。
后台计算分配票,在系统压力上,比千万人实时抢票,要低的多,资源占用也少的多,也容易测试和实现,还能有精力去研究提高购票的易用性。
所以,业务架构的严重错误,导致了今天的局面,可悲的是,他们还不打算改。 - 廖俊媛2014年1月11日10:48 | #35回复 | 引用
个人表示春运铁路运输的问题不然也不会那么多人怕买不到票而去抢票啊,不担心自己买不到票,就不会抢票,就不会出现这样的问题
- pydaniel2014年1月12日09:51 | #36回复 | 引用
这位兄台说得太有道理了。春运时期每个用户可以提前填写3个买票志愿,第一志愿填写自己最希望的日期和车次、席别;第二志愿、第三志愿以此类推,填好之后提交等结果,还可以让系统显示根据目前的填表数据你希望买的热门车次有多少人已经下单,中票的概率是多少;最后在截止日期所有填表全部提交,锁定,系统后台进行集中的数据处理、分配。那么这就不是处理实时抢票的问题了,而是变成如何最优分配购票志愿的问题了。这就是从业务模式上改进,而不是一味地死命追求实时抢票的这个死胡同。@free
- PHPdragon2014年1月22日09:30 | #37回复 | 引用
@Jerrygee
层主,你怎么知道这票是热门票?
这可是动态的,你想说系统可以实时的进行算法的切换吗?
你知道切换一下算法很容易吗?
不过有些观点比较认同,中国人的观念太配合上帝了,一切都按客户的需求来。
对于这种票务系统,业务逻辑完全可以由自己来捏,你要不要这么玩,随你,我才是游戏规则制定人。
不想玩,那就别买票别回家了!
然后可以以各种操作流程来规避一些问题。 - CY’s BLOG2014年2月2日01:48 | #38回复 | 引用
来过。
- TThouse2014年7月8日14:47 | #39回复 | 引用
顶一下
- qq4051657982014年9月9日18:51 | #40回复 | 引用
@free
我一直也是奇怪为什么不用这种方式, 这个方式因为届时能统计所有用户请求而做统一规划,可以有很多的算法可以设计.
一旦做成实时抢票,锁就是必须要用的了,由锁带来的问题也出来了,最大的问题的就是性能不能水平扩展… 1个服务器加锁跟1000个服务器加锁是一样的速度,唯一的办法只有提高所有服务器性能,但这又是有上限的. 所以投多少钱都不会见效.
12306开通到现在已经好几年了,想不到现在还是有这样的问题. - max2014年11月5日18:01 | #41回复 | 引用
1)什么时候放多少张票,什么车次,出发地目的地,这些在发票之前就已经通过另一个统筹的小算法算出来了,所以每次发票内容都是预先知道的,完全可以放内存里
2)用户狂刷票的时候,刷到的是缓存,你应该遇到过刷到票了,敲过验证码之后没有票的情况,既然是缓存就没有锁,随便刷呗,这样就不是瓶颈
3)只有敲过验证码通过之后,才会修改票的数量,修改也是修改内存,异步同步数据库,再说了,这时的压力已经很小很小了,根本不是事
4)45分钟付款,更是异步的了,没付款再把票放回去总体来说 1,2压力大,但是不需要操作硬盘,容易优化;3,4需要操作硬盘,但压力已经很小很小了
- max2014年11月5日18:07 | #42回复 | 引用
@free
你说的不合理,抢票抢不到就算了,顶多骂几句在赶紧想办法.预定的话满心有票,准备回家的时候告诉你没有轮到,你该如何是好?





































由12306.cn谈谈网站性能技术相关推荐
- 从网上订火车票的网站12306.cn谈谈网站性能技术
从网上订火车票的网站12306.cn谈谈网站性能技术 12306.cn网站挂了,被全国人民骂了.我这两天也在思考这个事,我想以这个事来粗略地和大家讨论一下网站性能的问题.因为仓促,而且完全基于 本人有 ...
- 由12306.CN谈谈网站性能技术http://coolshell.cn/articles/6470.html
由12306.CN谈谈网站性能技术 2012年01月16日 陈皓 评论 340 条评论 163,061 人阅读 12306.cn网站挂了,被全国人民骂了.我这两天也在思考这个事,我想以这个事来粗略 ...
- 由 12306.cn 谈谈网站性能技术
http://www.oschina.net/news/24838/website-performance 原文出处:爱范儿 oschina 配图 12306.cn网站挂了,被全国人民骂了.我这两天也 ...
- 转-由12306.cn谈谈网站性能技术
转载:http://blog.jobbole.com/12151/ 12306.cn网站挂了,被全国人民骂了.我这两天也在思考这个事,我想以这个事来粗略地和大家讨论一下网站性能的问题.因为仓促,而且完 ...
- 酷壳网陈皓:由12306.cn谈谈网站性能技术
导读:关于铁道部的火车票网络订票系统,这些天招致的骂声不断,当然,除了发泄不满,更多的技术人员选择了献技献策,纷纷从自己专长的角度提出解决之法.本文作者更是从订票业务.前端性能优化技术.后端性能优化技 ...
- 由12306谈谈网站性能技术
最近在看学习分布式相关的知识,正好在网上看到了陈皓老师(左耳朵耗子)几年前写的这篇文章,读下来觉得很有意义,尤其是对企业级系统的性能优化提出了很多解决方案和思路.遂决定整理过来,方便以后回顾. 以下是 ...
- 12306.cn网站挂了”好文章收藏,引发的技术架构问题讨论。
12306.cn网站挂了,被全国人民骂了.我这两天也在思考这个事,我想以这个事来粗略地和大家讨论一下网站性能的问题.因为仓促,而且完全基于本人有限的经验和了解,所以,如果有什么问题还请大家一起讨论和指 ...
- 12306.cn网站的思考 (整理篇)
针对12306.cn网站应用架够的一些看法 背景 针对最近比较热点的列车网上订票系统频繁出现的系统问题,提出了一些自己的看法. 分析 几经分析考虑,认为可能存在几个系统瓶颈. 1.关联系统的系统负载能 ...
- 从铁道部12306.cn网站漫谈电子商务网站的“海量事务高速处理”系统
整篇文章论述的就是"海量事务高速处理"的经验和误区. 第一部分论述"海量事务高速处理"现阶段没有通用解决方案,尝试通用解决方案就是误区. 第二部分讲解算法问题. ...
- 12306网站性能分析(转)
12306.cn 网站挂了,被全国人民骂了,以这个事来粗略地讨论一下网站性能的问题.这是一篇长文,只讨论性能问题,不讨论那些UI,用户体验,或是是否把支付和购票下单环节分开的功能性的东西. 最近铁道部 ...
最新文章
- 张艺谋镜头里的科技力量:为世界注入5G之心
- python快速编程入门课后程序题答案-Python 入门编程题:1~10(答案)
- C++ Primer 5th笔记(chap 18 大型程序工具)多重继承下的类作用域
- 考虑 PHP 5.0~5.6 各版本兼容性的 cURL 文件上传
- python docx库使用样例_Python docx库用法示例分析
- gin ip 和 本地访问的结果不一样_golang web开发——gin实战之整合swagger
- matlab 纯数据表格,MATLAB uitable表格数据更新处理
- 小狼毫(Rime)输入法设置Shift直接上屏英文字符并切换为英文状态方法
- (67)FPGA面试题-为priority encoder编写Verilog代码,实现MUX4_1
- vue-lazyload的使用
- github代码管理总结
- 清理linux清理垃圾文件夹,让Ubuntu系统释放空间最有效的五种方法(清除不需要的或垃圾文件)...
- lammps教程:推荐几个比较实用的lammps自带函数(2)
- 0033【MySQL】Mysql备份导入异常:@@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty
- 《光剑文集》青玉案: 27首
- 警惕邮件中的发票链接
- c语言 long与integer,VB中Integer(整型)和Long(长整型)有什么区别?
- etcdctl-管理操作etcd集群
- 通过Value获取JSON中对应的KEY
- 我为什么要考非全日制研究生