YOLO_ Real-Time Object Detection 实时目标检测
YOLO: Real-Time Object Detection 实时目标检测
You only look once(YOLO)是一种先进的实时目标检测系统。在Pascal Titan X上,它以每秒30帧的速度处理图像,在COCO test-dev上有57.9%的mAP。
与其他探测器的比较
YOLOv3是非常快速和准确的。在0.5 IOU下测得的mAP中,YOLOv3与Focal Loss相当,但速度快了4倍左右。此外,您可以轻松地在速度和精度之间进行折衷,只需更改模型的大小,而无需重新培训!
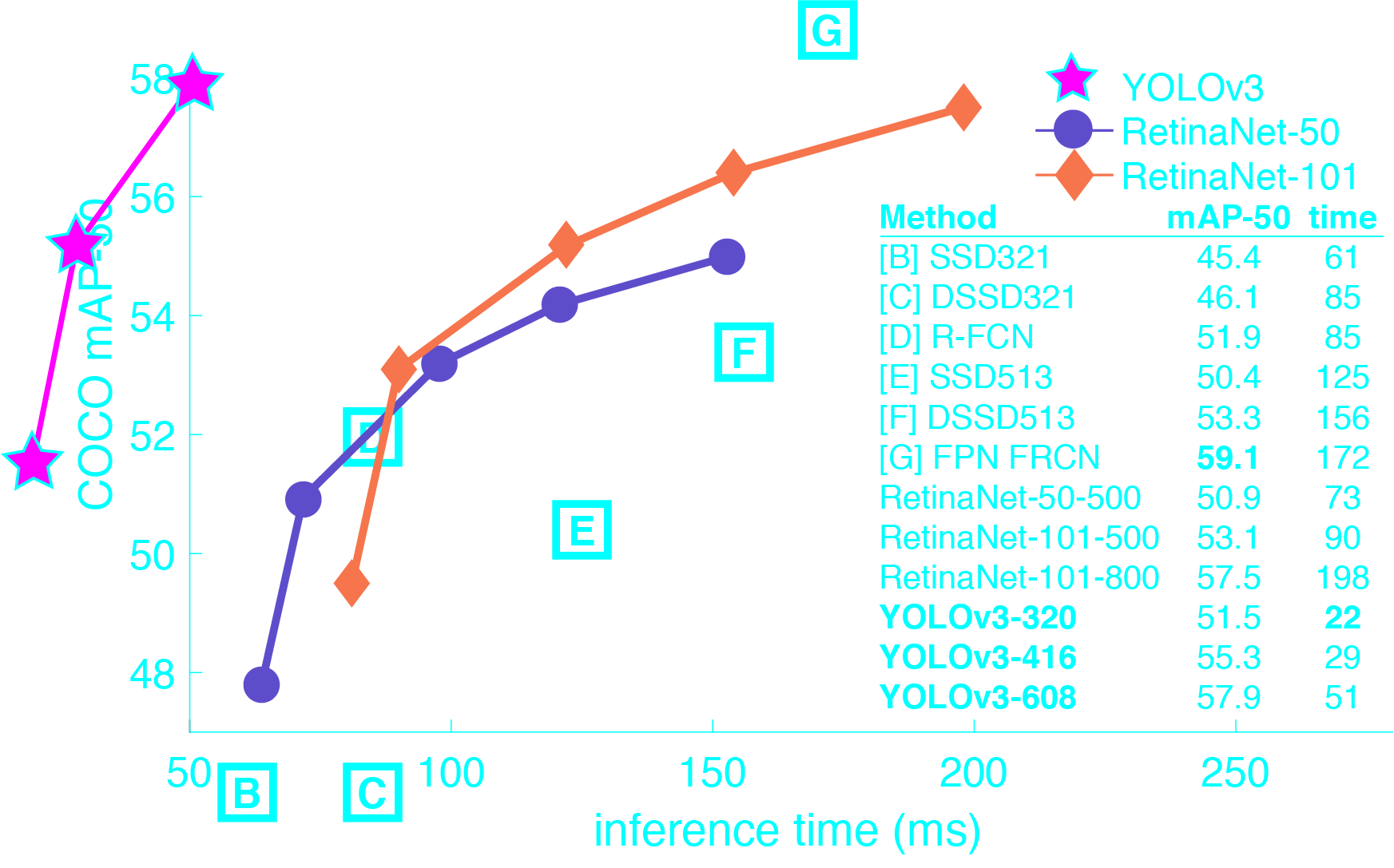
COCO数据集上的性能
| Model | Train | Test | mAP | FLOPS | FPS | Cfg | Weights |
|---|---|---|---|---|---|---|---|
| SSD300 | COCO trainval | test-dev | 41.2 | - | 46 | link | |
| SSD500 | COCO trainval | test-dev | 46.5 | - | 19 | link | |
| YOLOv2 608x608 | COCO trainval | test-dev | 48.1 | 62.94 Bn | 40 | cfg | weights |
| Tiny YOLO | COCO trainval | test-dev | 23.7 | 5.41 Bn | 244 | cfg | weights |
| — | |||||||
| SSD321 | COCO trainval | test-dev | 45.4 | - | 16 | link | |
| DSSD321 | COCO trainval | test-dev | 46.1 | - | 12 | link | |
| R-FCN | COCO trainval | test-dev | 51.9 | - | 12 | link | |
| SSD513 | COCO trainval | test-dev | 50.4 | - | 8 | link | |
| DSSD513 | COCO trainval | test-dev | 53.3 | - | 6 | link | |
| FPN FRCN | COCO trainval | test-dev | 59.1 | - | 6 | link | |
| Retinanet-50-500 | COCO trainval | test-dev | 50.9 | - | 14 | link | |
| Retinanet-101-500 | COCO trainval | test-dev | 53.1 | - | 11 | link | |
| Retinanet-101-800 | COCO trainval | test-dev | 57.5 | - | 5 | link | |
| YOLOv3-320 | COCO trainval | test-dev | 51.5 | 38.97 Bn | 45 | cfg | weights |
| YOLOv3-416 | COCO trainval | test-dev | 55.3 | 65.86 Bn | 35 | cfg | weights |
| YOLOv3-608 | COCO trainval | test-dev | 57.9 | 140.69 Bn | 20 | cfg | weights |
| YOLOv3-tiny | COCO trainval | test-dev | 33.1 | 5.56 Bn | 220 | cfg | weights |
| YOLOv3-spp | COCO trainval | test-dev | 60.6 | 141.45 Bn | 20 | cfg | weights |
工作原理
先前的检测系统重新利用分类器或定位器来执行检测。它们将模型应用于多个位置和比例的图像。高得分区域的图像被认为是检测。
我们使用完全不同的方法。我们将一个神经网络应用于整个图像。该网络将图像分为多个区域,并预测每个区域的边界框和概率。这些边界框由预测概率加权。
![]()
与基于分类器的系统相比,我们的模型有几个优点。它在测试时查看整个图像,因此它的预测是由图像中的全局上下文通知的。它还可以用一个网络评估来进行预测,不像R-CNN那样的系统,一张图像需要数千个网络评估。这使得它非常快,R-CNN快1000倍以上,比Fast R-CNN快100倍以上。。有关完整系统的详细信息,请参阅我们的paper。
版本3有什么新功能?
YOLOv3使用了一些技巧来改进训练和提高性能,包括:多尺度预测、更好的主干分类器等等。全部细节在我们的paper上!
使用预先训练的模型进行检测
这篇文章将指导你通过使用一个预先训练好的模型用YOLO系统检测物体。如果您还没有安装Darknet,应该先安装。或者不去读刚才运行的所有内容:
git clone https://github.com/pjreddie/darknet
cd darknet
make
Easy!
cfg/子目录中已经有YOLO的配置文件。你必须在这里下载预先训练的权重文件(237 MB)。或者运行以下命令:
wget https://pjreddie.com/media/files/yolov3.weights
然后启动探测器!
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
您将看到如下输出:
layer filters size input output0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs.......105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs106 detection
truth_thresh: Using default '1.000000'
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.029329 seconds.
dog: 99%
truck: 93%
bicycle: 99%
![]()
Darknet 打印出它检测到的物体,它的置信度,以及找到它们所花的时间。我们没有用OpenCV编译Darknet,所以它不能直接显示检测结果。相反,它将它们保存在predictions.png. 您可以打开它来查看检测到的对象。因为我们在CPU上使用Darknet,所以每个图像大约需要6-12秒。如果我们使用GPU版本,速度会快得多。
我已经提供了一些例子图片,以防你需要灵感。试用data/eagle.jpg, data/dog.jpg, data/person.jpg, 或 data/horses.jpg!
detect命令是更通用的命令版本的简写。它相当于命令:
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
如果您只想在一个图像上运行检测,则不需要知道这一点,但如果您想在网络摄像头上运行(稍后将看到)等其他操作,则知道这一点非常有用。
多个图像
不必在命令行中提供图像,您可以将其保留为空以尝试一行中的多个图像。相反,当配置和权重加载完成时,您将看到一个提示:
./darknet detect cfg/yolov3.cfg yolov3.weights
layer filters size input output0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs.......104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs106 detection
Loading weights from yolov3.weights...Done!
Enter Image Path:
输入图像路径,如data/horses.jpg让它为那个图像预测盒子。
![]()
一旦完成,它会提示您更多的路径来尝试不同的图像。完成后,使用Ctrl-C退出程序。
更改检测阈值
默认情况下,YOLO只显示置信度为.25或更高的对象。您可以通过将-thresh标志传递给yolo命令来改变这一点。例如,要显示所有检测,可以将阈值设置为0:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
所以这显然不是非常有用,但是你可以将它设置为不同的值来控制模型的阈值。
Tiny YOLOv3
我们有一个非常小的模型,也适用于受限环境,yolov3tiny。要使用此模型,请首先下载权重:
wget https://pjreddie.com/media/files/yolov3-tiny.weights
然后用微小的配置文件和权重运行探测器:
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
网络摄像头上的实时检测
如果看不到结果,那么在测试数据上运行YOLO就不是很有趣了。与其在一堆图像上运行它,不如在网络摄像头的输入上运行它!
要运行这个演示,你需要用CUDA和OpenCV编译Darknet。然后运行命令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
YOLO将显示当前FPS和预测类,以及在上面绘制边界框的图像。
你需要一个网络摄像头连接到OpenCV可以连接到的计算机上,否则它将无法工作。如果您连接了多个网络摄像头,并且想要选择使用哪一个,那么可以传递-c标志来选择(OpenCV默认使用网络摄像头0)。
如果OpenCV可以读取视频,也可以在视频文件上运行:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
这就是我们制作上述YouTube视频的方式。
对YOLO进行VOC培训
如果您想使用不同的训练模式、超参数或数据集,可以从头开始训练YOLO。下面是如何让它在Pascal VOC数据集上工作。
获取Pascal VOC数据
为了训练YOLO,你需要2007年到2012年的所有VOC数据。你可以在这里找到这些数据的链接。要获取所有数据,请创建一个目录来存储所有数据,然后从该目录运行:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
现在将有一个VOCdevkit/子目录,其中包含所有VOC训练数据。
生成VOC标签
现在我们需要生成Darknet使用的标签文件。Darknet希望每个图像都有一个.txt文件,图像中的每个地面真相对象都有一行,如下所示:
<object-class> <x> <y> <width> <height>
其中x、y、width和height相对于图像的宽度和高度。为了生成这些文件,我们将运行voc_label.py在Darknet的scripts/目录中编写脚本。我们再下载一次吧,因为我们很懒。
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py
几分钟后,这个脚本将生成所有必需的文件。它通常在VOCdevkit/VOC2007/labels/和VOCdevkit/VOC2012/labels/中生成大量标签文件。在您的目录中,您应该看到:
ls
2007_test.txt VOCdevkit
2007_train.txt voc_label.py
2007_val.txt VOCtest_06-Nov-2007.tar
2012_train.txt VOCtrainval_06-Nov-2007.tar
2012_val.txt VOCtrainval_11-May-2012.tar
像2007这样的文本文件_列车.txt列出当年的图像文件和图像集。Darknet需要一个文本文件,其中包含所有要训练的图像。在这个例子中,让我们训练除了2007测试集之外的所有东西,以便我们可以测试我们的模型。运行:
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
现在我们把2007年的trainval和2012年的trainval都列在一个大名单里。这就是我们要做的数据设置!
修改Pascal数据的Cfg
现在去你的Darknet文件夹。我们得换cfg/voc.data指向数据的配置文件:
1 classes= 202 train = <path-to-voc>/train.txt3 valid = <path-to-voc>2007_test.txt4 names = data/voc.names5 backup = backup
应该将替换为存放voc数据的目录。
下载预训练卷积权重
对于训练,我们使用在Imagenet上预先训练的卷积权重。我们使用来自 darknet53 模型的权重。你可以在这里下载卷积层的权重(76MB)。
wget https://pjreddie.com/media/files/darknet53.conv.74
训练模型
现在我们可以训练了!运行命令:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
在COCO上训练YOLO
如果您想使用不同的训练模式、超参数或数据集,可以从头开始训练YOLO。下面是如何让它在COCO数据集上工作。
获取COCO数据
为了训练YOLO,你需要所有的COCO数据和标签。脚本scripts/get_coco_dataset.sh我会帮你的。找出要将COCO数据放在何处并下载,例如:
cp scripts/get_coco_dataset.sh data
cd data
bash get_coco_dataset.sh
现在您应该拥有为Darknet生成的所有数据和标签。
修改COCO的cfg
现在去你的Darknet文件夹。我们得换cfg/coco.data指向数据的配置文件:
1 classes= 802 train = <path-to-coco>/trainvalno5k.txt3 valid = <path-to-coco>/5k.txt4 names = data/coco.names5 backup = backup
您应该将替换为放置coco数据的目录。
您还应该修改您的cfg模型以进行培训而不是测试,cfg/yolo.cfg应该是这样的:
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=8
....
训练模型
现在我们可以训练了!运行命令:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74
如果要使用多个GPU,请运行:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3
如果要从检查点停止并重新启动培训:
./darknet detector train cfg/coco.data cfg/yolov3.cfg backup/yolov3.backup -gpus 0,1,2,3
开源图像数据集上的YOLOv3
wget https://pjreddie.com/media/files/yolov3-openimages.weights./darknet detector test cfg/openimages.data cfg/yolov3-openimages.cfg yolov3-openimages.weights
Old YOLO Site怎么了?
如果您使用的是YOLO版本2,您仍然可以在此处找到该网站:https://pjreddie.com/darknet/yolov2/
引用
如果你在工作中使用YOLOv3,请引用我们的论文!
@article{yolov3,title={YOLOv3: An Incremental Improvement},author={Redmon, Joseph and Farhadi, Ali},journal = {arXiv},year={2018}
}
YOLO_ Real-Time Object Detection 实时目标检测相关推荐
- CVPR2020论文解读:3D Object Detection三维目标检测
CVPR2020论文解读:3D Object Detection三维目标检测 PV-RCNN:Point-Voxel Feature Se tAbstraction for 3D Object Det ...
- tensorflow精进之路(二十五)——Object Detection API目标检测(下)(VOC数据集训练自己的模型进行目标检测)
1.概述 上一讲,我们使用了别人根据COCO数据集训练好的模型来做目标检测,这一讲,我们就来训练自己的模型. 2.下载数据集 为了方便学习,我们先使用别人整理好的数据集来训练---VOC 2012数据 ...
- 论文翻译YOLOv4: Optimal Speed and Accuracy of Object Detection YOLOv4:目标检测的最佳速度和精度 论文中文翻译
摘要 有大量的特征被认为可以提高卷积神经网络(CNN)的精度.需要在大型数据集上对这些特性的组合进行实际测试,并对结果进行理论验证.某些特性在特定的建模中起决定性作用,而在特定的强制确定问题中起决定性 ...
- (Object detection)目标检测从入门到精通——第二部分
3.4 滑动窗口的卷积实现(Convolutional implementation of sliding windows) 上节课,我们学习了如何通过卷积网络实现滑动窗口对象检测算法,但效率很低.这 ...
- (Object detection)目标检测从入门到精通——第一部分
3.1 目标定位(Object localization) 大家好,欢迎回来,这一周我们学习的主要内容是对象检测,它是计算机视觉领域中一个新兴的应用方向,相比前两年,它的性能越来越好.在构建对象检测之 ...
- tensorflow精进之路(二十四)——Object Detection API目标检测(中)(COCO数据集训练的模型—ssd_mobilenet_v1_coco模型)
1.概述 上一讲简单的讲了目标检测的原理以及Tensorflow Object Detection API的安装,这一节继续讲Tensorflow Object Detection API怎么用. 2 ...
- tensorflow精进之路(二十三)——Object Detection API目标检测(上)(Fast R-CNN算法)
1.概述 上一讲,我们使用slim库对图片进行检测,每个物品用同一种颜色标注,显得乱七八糟的.这一讲,我们来学习目标检测.目标检测就是,输入一张图片,输出是将该图片中所含的所有目标物体识别,并标记出他 ...
- 【论文阅读】【综述】3D Object Detection 3D目标检测综述
目录 写在开头 3D Object Detection 相关博客: Sliding window Vote3Deep: Fast Object Detection in 3D Point Clouds ...
- 3D Object Detection 3D目标检测综述
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明. 本文链接: https://blog.csdn.net/wqwqqwqw1231/articl ...
最新文章
- elasticsearch 9300端口连接不上_SpringBoot2.x系列教程54--SpringBoot整合ElasticSearch方式一...
- iOS架构-多工程联编及framework之间的相互调用(19)
- 企业架构研究总结(2)——问题的由来和基本概念
- [转]linux tr命令详解
- BZOJ-3473 (广义后缀自动机:拓扑 or 启发式合并)
- java克鲁斯卡尔算法_Java语言基于无向有权图实现克鲁斯卡尔算法代码示例
- QPW 公告表(tf_notice)
- html5录像功能限制时间,HTML5拍照和摄像机功能实战详解
- gperftools mysql_利用 gperftools 对nginx mysql 内存管理 性能优化
- java 对象池 实现_Java对象池技术的原理及其实现
- 一场大病引起的诺贝尔2017年生理学奖角逐
- 黑客,计算机革命的英雄!
- 深度图像配准_巧解图像处理经典难题之图像配准
- Two sum (bilibili有讲解视频)
- 由于焦点冲突导致TextView的跑马灯效果和EditText不能共存的问题
- matlab绘制图像的直方图、杆状图和折线图等
- 什么是蒙特卡罗仿真?
- Python这些操作,逆天且实用
- 405错误,java.io.IOException: The temporary upload location [/tmp/tomcat.22.83/work/Tomcat/localhos解决办法
- Android Studio Gradle打包实践之多渠道+版本号管理