Ai Studio零基础学习心得
内容提要:参见了百度AI Studio的零基础深度学习,让我之前对神经网络的理解加深了。哈哈哈,本来就是自学的,所以有很多盲点没有扫清。然后因为要百度要一个心得体会才能结业,所以处于期末考试的我还是出来写一篇水文。因为基础不好,这篇文章主要是给零基础的人看的。有错也请指出,原谅我这菜鸟。
主要讲解方向为
神经网络:
在学习的开始,我们先用numpy和python语言在线性回归的基础上构建神经网络,来对波士顿房价进行预测。
网络结构:
![]()
Numpy构建神经网络代码:
# 导入需要用到的package
import numpy as np
import json
#导入并处理数据
def load_data(): # 从文件导入数据datafile = './work/housing.data'data = np.fromfile(datafile, sep=' ')# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio)training_data = data[:offset]# 计算训练集的最大值,最小值,平均值maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \training_data.sum(axis=0) / training_data.shape[0]# 对数据进行归一化处理for i in range(feature_num):#print(maximums[i], minimums[i], avgs[i])data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])# 训练集和测试集的划分比例training_data = data[:offset]test_data = data[offset:]return training_data, test_data
# 训练函数
class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights,1)self.w[5] = -100.self.w[9] = -100.self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)gradient_w = (z-y)*xgradient_w = np.mean(gradient_w, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = (z - y)gradient_b = np.mean(gradient_b) return gradient_w, gradient_bdef update(self, graident_w5, gradient_w9, eta=0.01):net.w[5] = net.w[5] - eta * gradient_w5net.w[9] = net.w[9] - eta * gradient_w9def train(self, x, y, iterations=100, eta=0.01):points = []losses = []for i in range(iterations):points.append([net.w[5][0], net.w[9][0]])z = self.forward(x)L = self.loss(z, y)gradient_w, gradient_b = self.gradient(x, y)gradient_w5 = gradient_w[5][0]gradient_w9 = gradient_w[9][0]self.update(gradient_w5, gradient_w9, eta)losses.append(L)if i % 50 == 0:print('iter {}, point {}, loss {}'.format(i, [net.w[5][0], net.w[9][0]], L))return points, losses# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=2000
# 启动训练
points, losses = net.train(x, y, iterations=num_iterations, eta=0.01)# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
利用飞浆框架进行搭建线性回归的神经网络代码(网络搭建过程类型):
#加载飞桨、Numpy和相关类库
import paddle
import paddle.fluid as fluid
import paddle.fluid.dygraph as dygraph
from paddle.fluid.dygraph import Linear
import numpy as np
import os
import random
def load_data():# 从文件导入数据datafile = './work/housing.data'data = np.fromfile(datafile, sep=' ')# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio)training_data = data[:offset]# 计算train数据集的最大值,最小值,平均值maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \training_data.sum(axis=0) / training_data.shape[0]# 记录数据的归一化参数,在预测时对数据做归一化global max_valuesglobal min_valuesglobal avg_valuesmax_values = maximumsmin_values = minimumsavg_values = avgs# 对数据进行归一化处理for i in range(feature_num):#print(maximums[i], minimums[i], avgs[i])data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])# 训练集和测试集的划分比例#ratio = 0.8#offset = int(data.shape[0] * ratio)training_data = data[:offset]test_data = data[offset:]return training_data, test_dataclass Regressor(fluid.dygraph.Layer):def __init__(self):super(Regressor, self).__init__()# 定义一层全连接层,输出维度是1,激活函数为None,即不使用激活函数self.fc = Linear(input_dim=13, output_dim=1, act=None)# 网络的前向计算函数def forward(self, inputs):x = self.fc(inputs)return x
# 定义飞桨动态图的工作环境
with fluid.dygraph.guard():# 声明定义好的线性回归模型model = Regressor()# 开启模型训练模式model.train()# 加载数据training_data, test_data = load_data()# 定义优化算法,这里使用随机梯度下降-SGD# 学习率设置为0.01opt = fluid.optimizer.SGD(learning_rate=0.01, parameter_list=model.parameters())with dygraph.guard(fluid.CPUPlace()):EPOCH_NUM = 10 # 设置外层循环次数BATCH_SIZE = 10 # 设置batch大小# 定义外层循环for epoch_id in range(EPOCH_NUM):# 在每轮迭代开始之前,将训练数据的顺序随机的打乱np.random.shuffle(training_data)# 将训练数据进行拆分,每个batch包含10条数据mini_batches = [training_data[k:k+BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)]# 定义内层循环for iter_id, mini_batch in enumerate(mini_batches):x = np.array(mini_batch[:, :-1]).astype('float32') # 获得当前批次训练数据y = np.array(mini_batch[:, -1:]).astype('float32') # 获得当前批次训练标签(真实房价)# 将numpy数据转为飞桨动态图variable形式house_features = dygraph.to_variable(x)prices = dygraph.to_variable(y)# 前向计算predicts = model(house_features)# 计算损失loss = fluid.layers.square_error_cost(predicts, label=prices)avg_loss = fluid.layers.mean(loss)if iter_id%20==0:print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy()))# 反向传播avg_loss.backward()# 最小化loss,更新参数opt.minimize(avg_loss)# 清除梯度model.clear_gradients()# 保存模型fluid.save_dygraph(model.state_dict(), 'LR_model')
# 定义飞桨动态图工作环境
with fluid.dygraph.guard():# 保存模型参数,文件名为LR_modelfluid.save_dygraph(model.state_dict(), 'LR_model')print("模型保存成功,模型参数保存在LR_model中")def load_one_example(data_dir):f = open(data_dir, 'r')datas = f.readlines()# 选择倒数第10条数据用于测试tmp = datas[-10]tmp = tmp.strip().split()one_data = [float(v) for v in tmp]# 对数据进行归一化处理for i in range(len(one_data)-1):one_data[i] = (one_data[i] - avg_values[i]) / (max_values[i] - min_values[i])data = np.reshape(np.array(one_data[:-1]), [1, -1]).astype(np.float32)label = one_data[-1]return data, labelwith dygraph.guard():# 参数为保存模型参数的文件地址model_dict, _ = fluid.load_dygraph('LR_model')model.load_dict(model_dict)model.eval()# 参数为数据集的文件地址test_data, label = load_one_example('./work/housing.data')# 将数据转为动态图的variable格式test_data = dygraph.to_variable(test_data)results = model(test_data)# 对结果做反归一化处理results = results * (max_values[-1] - min_values[-1]) + avg_values[-1]print("Inference result is {}, the corresponding label is {}".format(results.numpy(), label))
因为我写博客不多,所以讲解的可能不太清楚。如果相关代码看的不太舒服可以去链接: 百度零基础深度学习看一下,里面有最详细的讲解。
卷积和池化:
卷积计算
卷积是数学分析中的一种积分变换的方法,在图像处理中采用的是卷积的离散形式。这里需要说明的是,在卷积神经网络中,卷积层的实现方式实际上是数学中定义的互相关 (cross-correlation)运算,与数学分析中的卷积定义有所不同,这里跟其他框架和卷积神经网络的教程保持一致,都使用互相关运算作为卷积的定义,具体的计算过程如 图7 所示。
图7:卷积计算过程
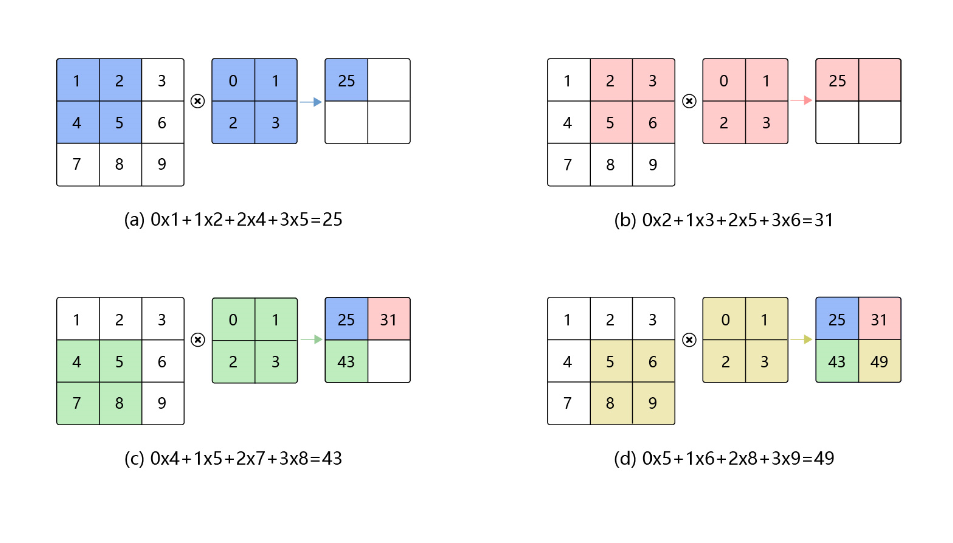
说明:
卷积核(kernel)也被叫做滤波器(filter),假设卷积核的高和宽分别为 k h k_h kh和 k w k_w kw,则将称为 k h × k w k_h\times k_w kh×kw卷积,比如 3 × 5 3\times5 3×5卷积,就是指卷积核的高为3, 宽为5。
- 如图7(a)所示:左边的图大小是 3 × 3 3\times3 3×3,表示输入数据是一个维度为 3 × 3 3\times3 3×3的二维数组;中间的图大小是 2 × 2 2\times2 2×2,表示一个维度为 2 × 2 2\times2 2×2的二维数组,我们将这个二维数组称为卷积核。先将卷积核的左上角与输入数据的左上角(即:输入数据的(0, 0)位置)对齐,把卷积核的每个元素跟其位置对应的输入数据中的元素相乘,再把所有乘积相加,得到卷积输出的第一个结果
0 × 1 + 1 × 2 + 2 × 4 + 3 × 5 = 25 ( a ) 0\times1 + 1\times2 + 2\times4 + 3\times5 = 25 \ \ \ \ \ \ \ (a) 0×1+1×2+2×4+3×5=25 (a)
- 如图7(b)所示:将卷积核向右滑动,让卷积核左上角与输入数据中的(0,1)位置对齐,同样将卷积核的每个元素跟其位置对应的输入数据中的元素相乘,再把这4个乘积相加,得到卷积输出的第二个结果,
0 × 2 + 1 × 3 + 2 × 5 + 3 × 6 = 31 ( b ) 0\times2 + 1\times3 + 2\times5 + 3\times6 = 31 \ \ \ \ \ \ \ (b) 0×2+1×3+2×5+3×6=31 (b)
- 如图7(c)所示:将卷积核向下滑动,让卷积核左上角与输入数据中的(1, 0)位置对齐,可以计算得到卷积输出的第三个结果,
0 × 4 + 1 × 5 + 2 × 7 + 3 × 8 = 43 ( c ) 0\times4 + 1\times5 + 2\times7 + 3\times8 = 43 \ \ \ \ \ \ \ (c) 0×4+1×5+2×7+3×8=43 (c)
- 如图7(d)所示:将卷积核向右滑动,让卷积核左上角与输入数据中的(1, 1)位置对齐,可以计算得到卷积输出的第四个结果,
0 × 5 + 1 × 6 + 2 × 8 + 3 × 9 = 49 ( d ) 0\times5 + 1\times6 + 2\times8 + 3\times9 = 49 \ \ \ \ \ \ \ (d) 0×5+1×6+2×8+3×9=49 (d)
卷积核的计算过程可以用下面的数学公式表示,其中 a a a 代表输入图片, b b b 代表输出特征图, w w w 是卷积核参数,它们都是二维数组, ∑ u , v \sum{u,v}{\ } ∑u,v 表示对卷积核参数进行遍历并求和。
b [ i , j ] = ∑ u , v a [ i + u , j + v ] ⋅ w [ u , v ] b[i, j] = \sum_{u,v}{a[i+u, j+v]\cdot w[u, v]} b[i,j]=u,v∑a[i+u,j+v]⋅w[u,v]
举例说明,假如上图中卷积核大小是 2 × 2 2\times 2 2×2,则 u u u可以取0和1, v v v也可以取0和1,也就是说:
b [ i , j ] = a [ i + 0 , j + 0 ] ⋅ w [ 0 , 0 ] + a [ i + 0 , j + 1 ] ⋅ w [ 0 , 1 ] + a [ i + 1 , j + 0 ] ⋅ w [ 1 , 0 ] + a [ i + 1 , j + 1 ] ⋅ w [ 1 , 1 ] b[i, j] = a[i+0, j+0]\cdot w[0, 0] + a[i+0, j+1]\cdot w[0, 1] + a[i+1, j+0]\cdot w[1, 0] + a[i+1, j+1]\cdot w[1, 1] b[i,j]=a[i+0,j+0]⋅w[0,0]+a[i+0,j+1]⋅w[0,1]+a[i+1,j+0]⋅w[1,0]+a[i+1,j+1]⋅w[1,1]
读者可以自行验证,当 [ i , j ] [i, j] [i,j]取不同值时,根据此公式计算的结果与上图中的例子是否一致。
- 【思考】 当卷积核大小为 3 × 3 3 \times 3 3×3时,b和a之间的对应关系应该是怎样的?
其它说明:
在卷积神经网络中,一个卷积算子除了上面描述的卷积过程之外,还包括加上偏置项的操作。例如假设偏置为1,则上面卷积计算的结果为:
0 × 1 + 1 × 2 + 2 × 4 + 3 × 5 + 1 = 26 0\times1 + 1\times2 + 2\times4 + 3\times5 \mathbf{\ + 1} = 26 0×1+1×2+2×4+3×5 +1=26
0 × 2 + 1 × 3 + 2 × 5 + 3 × 6 + 1 = 32 0\times2 + 1\times3 + 2\times5 + 3\times6 \mathbf{\ + 1} = 32 0×2+1×3+2×5+3×6 +1=32
0 × 4 + 1 × 5 + 2 × 7 + 3 × 8 + 1 = 44 0\times4 + 1\times5 + 2\times7 + 3\times8 \mathbf{\ + 1} = 44 0×4+1×5+2×7+3×8 +1=44
0 × 5 + 1 × 6 + 2 × 8 + 3 × 9 + 1 = 50 0\times5 + 1\times6 + 2\times8 + 3\times9 \mathbf{\ + 1} = 50 0×5+1×6+2×8+3×9 +1=50
填充(padding)
在上面的例子中,输入图片尺寸为 3 × 3 3\times3 3×3,输出图片尺寸为 2 × 2 2\times2 2×2,经过一次卷积之后,图片尺寸变小。卷积输出特征图的尺寸计算方法如下:
H o u t = H − k h + 1 H_{out} = H - k_h + 1 Hout=H−kh+1
W o u t = W − k w + 1 W_{out} = W - k_w + 1 Wout=W−kw+1
如果输入尺寸为4,卷积核大小为3时,输出尺寸为 4 − 3 + 1 = 2 4-3+1=2 4−3+1=2。读者可以自行检查当输入图片和卷积核为其他尺寸时,上述计算式是否成立。通过多次计算我们发现,当卷积核尺寸大于1时,输出特征图的尺寸会小于输入图片尺寸。说明经过多次卷积之后尺寸会不断减小。为了避免卷积之后图片尺寸变小,通常会在图片的外围进行填充(padding),如 图8 所示。
图8:图形填充
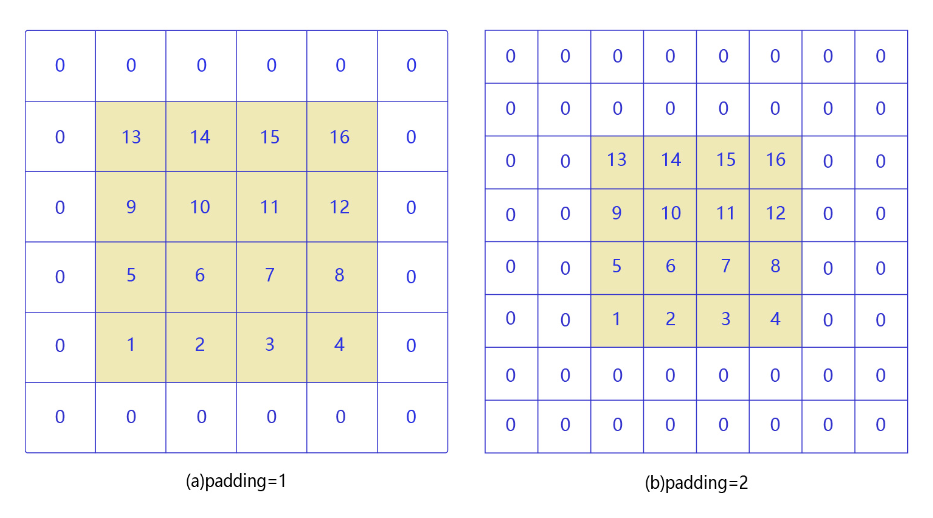
如图8(a)所示:填充的大小为1,填充值为0。填充之后,输入图片尺寸从 4 × 4 4\times4 4×4变成了 6 × 6 6\times6 6×6,使用 3 × 3 3\times3 3×3的卷积核,输出图片尺寸为 4 × 4 4\times4 4×4。
如图8(b)所示:填充的大小为2,填充值为0。填充之后,输入图片尺寸从 4 × 4 4\times4 4×4变成了 8 × 8 8\times8 8×8,使用 3 × 3 3\times3 3×3的卷积核,输出图片尺寸为 6 × 6 6\times6 6×6。
如果在图片高度方向,在第一行之前填充 p h 1 p_{h1} ph1行,在最后一行之后填充 p h 2 p_{h2} ph2行;在图片的宽度方向,在第1列之前填充 p w 1 p_{w1} pw1列,在最后1列之后填充 p w 2 p_{w2} pw2列;则填充之后的图片尺寸为 ( H + p h 1 + p h 2 ) × ( W + p w 1 + p w 2 ) (H + p_{h1} + p_{h2})\times(W + p_{w1} + p_{w2}) (H+ph1+ph2)×(W+pw1+pw2)。经过大小为 k h × k w k_h\times k_w kh×kw的卷积核操作之后,输出图片的尺寸为:
H o u t = H + p h 1 + p h 2 − k h + 1 H_{out} = H + p_{h1} + p_{h2} - k_h + 1 Hout=H+ph1+ph2−kh+1
W o u t = W + p w 1 + p w 2 − k w + 1 W_{out} = W + p_{w1} + p_{w2} - k_w + 1 Wout=W+pw1+pw2−kw+1
在卷积计算过程中,通常会在高度或者宽度的两侧采取等量填充,即 p h 1 = p h 2 = p h , p w 1 = p w 2 = p w p_{h1} = p_{h2} = p_h,\ \ p_{w1} = p_{w2} = p_w ph1=ph2=ph, pw1=pw2=pw,上面计算公式也就变为:
H o u t = H + 2 p h − k h + 1 H_{out} = H + 2p_h - k_h + 1 Hout=H+2ph−kh+1
W o u t = W + 2 p w − k w + 1 W_{out} = W + 2p_w - k_w + 1 Wout=W+2pw−kw+1
卷积核大小通常使用1,3,5,7这样的奇数,如果使用的填充大小为 p h = ( k h − 1 ) / 2 , p w = ( k w − 1 ) / 2 p_h=(k_h-1)/2, p_w=(k_w-1)/2 ph=(kh−1)/2,pw=(kw−1)/2,则卷积之后图像尺寸不变。例如当卷积核大小为3时,padding大小为1,卷积之后图像尺寸不变;同理,如果卷积核大小为5,使用padding的大小为2,也能保持图像尺寸不变。
步幅(stride)
图8 中卷积核每次滑动一个像素点,这是步幅为1的特殊情况。图9 是步幅为2的卷积过程,卷积核在图片上移动时,每次移动大小为2个像素点。
图9:步幅为2的卷积过程
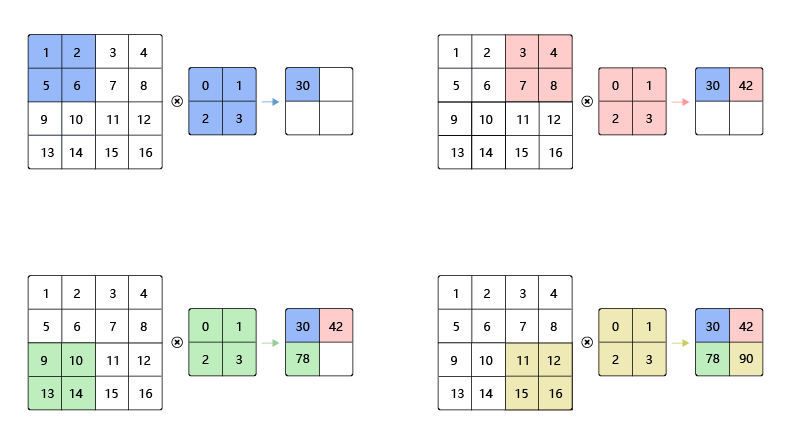
当宽和高方向的步幅分别为 s h s_h sh和 s w s_w sw时,输出特征图尺寸的计算公式是:
H o u t = H + 2 p h − k h s h + 1 H_{out} = \frac{H + 2p_h - k_h}{s_h} + 1 Hout=shH+2ph−kh+1
W o u t = W + 2 p w − k w s w + 1 W_{out} = \frac{W + 2p_w - k_w}{s_w} + 1 Wout=swW+2pw−kw+1
假设输入图片尺寸是 H × W = 100 × 100 H\times W = 100 \times 100 H×W=100×100,卷积核大小 k h × k w = 3 × 3 k_h \times k_w = 3 \times 3 kh×kw=3×3,填充 p h = p w = 1 p_h = p_w = 1 ph=pw=1,步幅为 s h = s w = 2 s_h = s_w = 2 sh=sw=2,则输出特征图的尺寸为:
H o u t = 100 + 2 − 3 2 + 1 = 50 H_{out} = \frac{100 + 2 - 3}{2} + 1 = 50 Hout=2100+2−3+1=50
W o u t = 100 + 2 − 3 2 + 1 = 50 W_{out} = \frac{100 + 2 - 3}{2} + 1 = 50 Wout=2100+2−3+1=50
感受野(Receptive Field)
输出特征图上每个点的数值,是由输入图片上大小为 k h × k w k_h\times k_w kh×kw的区域的元素与卷积核每个元素相乘再相加得到的,所以输入图像上 k h × k w k_h\times k_w kh×kw区域内每个元素数值的改变,都会影响输出点的像素值。我们将这个区域叫做输出特征图上对应点的感受野。感受野内每个元素数值的变动,都会影响输出点的数值变化。比如 3 × 3 3\times3 3×3卷积对应的感受野大小就是 3 × 3 3\times3 3×3。
多输入通道、多输出通道和批量操作
前面介绍的卷积计算过程比较简单,实际应用时,处理的问题要复杂的多。例如:对于彩色图片有RGB三个通道,需要处理多输入通道的场景。输出特征图往往也会具有多个通道,而且在神经网络的计算中常常是把一个批次的样本放在一起计算,所以卷积算子需要具有批量处理多输入和多输出通道数据的功能,下面将分别介绍这几种场景的操作方式。
- 多输入通道场景
上面的例子中,卷积层的数据是一个2维数组,但实际上一张图片往往含有RGB三个通道,要计算卷积的输出结果,卷积核的形式也会发生变化。假设输入图片的通道数为 C i n C_{in} Cin,输入数据的形状是 C i n × H i n × W i n C_{in}\times{H_{in}}\times{W_{in}} Cin×Hin×Win,计算过程如 图10 所示。
对每个通道分别设计一个2维数组作为卷积核,卷积核数组的形状是 C i n × k h × k w C_{in}\times{k_h}\times{k_w} Cin×kh×kw。
对任一通道 c i n ∈ [ 0 , C i n ) c_{in} \in [0, C_{in}) cin∈[0,Cin),分别用大小为 k h × k w k_h\times{k_w} kh×kw的卷积核在大小为 H i n × W i n H_{in}\times{W_{in}} Hin×Win的二维数组上做卷积。
将这 C i n C_{in} Cin个通道的计算结果相加,得到的是一个形状为 H o u t × W o u t H_{out}\times{W_{out}} Hout×Wout的二维数组。
图10:多输入通道计算过程
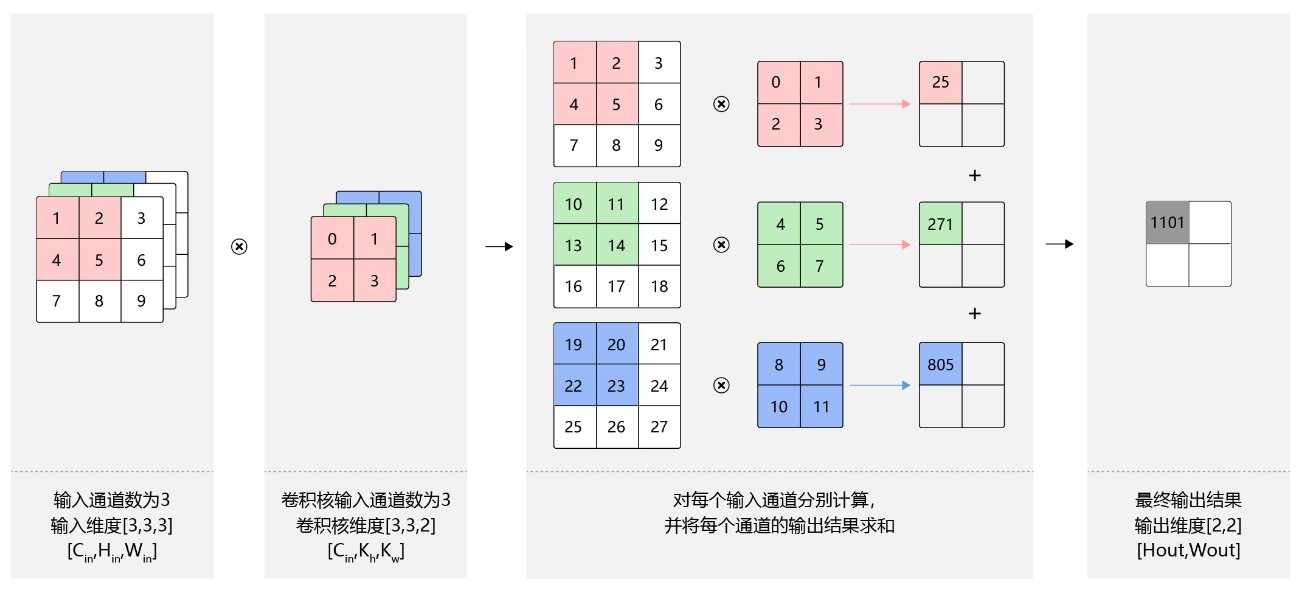
- 多输出通道场景
一般来说,卷积操作的输出特征图也会具有多个通道 C o u t C_{out} Cout,这时我们需要设计 C o u t C_{out} Cout个维度为 C i n × k h × k w C_{in}\times{k_h}\times{k_w} Cin×kh×kw的卷积核,卷积核数组的维度是 C o u t × C i n × k h × k w C_{out}\times C_{in}\times{k_h}\times{k_w} Cout×Cin×kh×kw,如 图11 所示。
- 对任一输出通道 c o u t ∈ [ 0 , C o u t ) c_{out} \in [0, C_{out}) cout∈[0,Cout),分别使用上面描述的形状为 C i n × k h × k w C_{in}\times{k_h}\times{k_w} Cin×kh×kw的卷积核对输入图片做卷积。
- 将这 C o u t C_{out} Cout个形状为 H o u t × W o u t H_{out}\times{W_{out}} Hout×Wout的二维数组拼接在一起,形成维度为 C o u t × H o u t × W o u t C_{out}\times{H_{out}}\times{W_{out}} Cout×Hout×Wout的三维数组。
说明:
通常将卷积核的输出通道数叫做卷积核的个数。
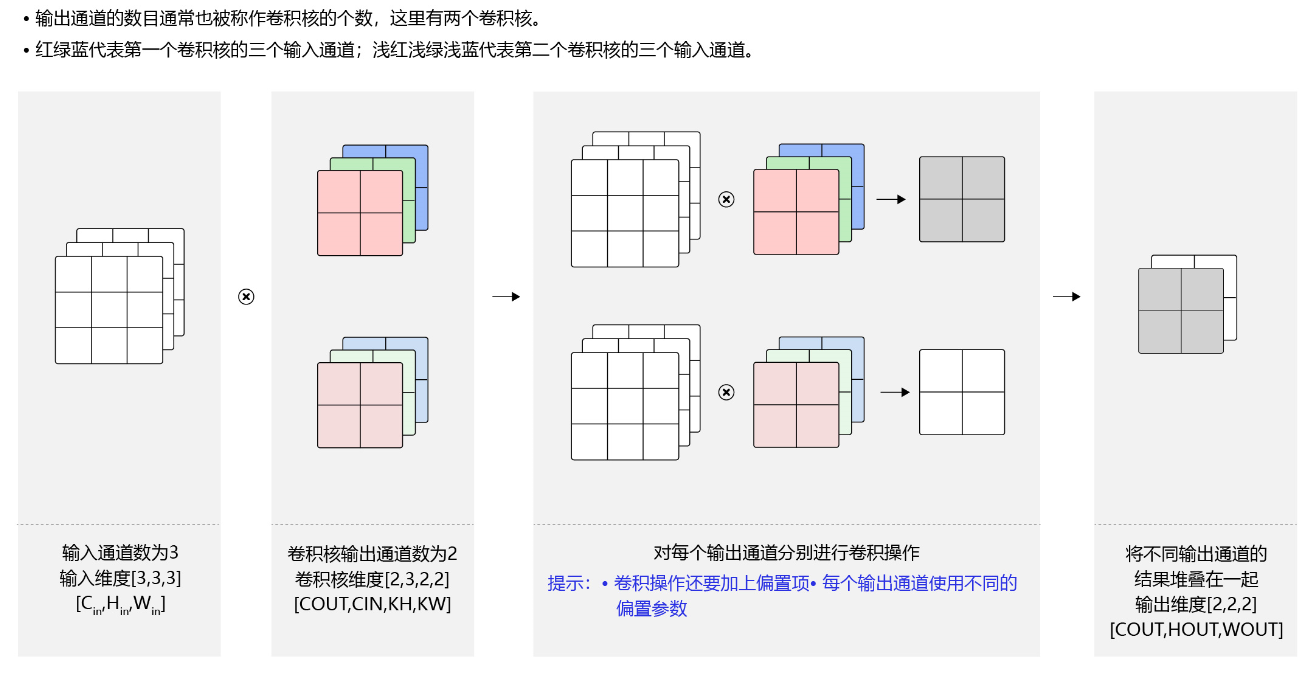
图11:多输出通道计算过程
- 批量操作
在卷积神经网络的计算中,通常将多个样本放在一起形成一个mini-batch进行批量操作,即输入数据的维度是 N × C i n × H i n × W i n N\times{C_{in}}\times{H_{in}}\times{W_{in}} N×Cin×Hin×Win。由于会对每张图片使用同样的卷积核进行卷积操作,卷积核的维度与上面多输出通道的情况一样,仍然是 C o u t × C i n × k h × k w C_{out}\times C_{in}\times{k_h}\times{k_w} Cout×Cin×kh×kw,输出特征图的维度是 N × C o u t × H o u t × W o u t N\times{C_{out}}\times{H_{out}}\times{W_{out}} N×Cout×Hout×Wout,如 图12 所示。
图12:批量操作
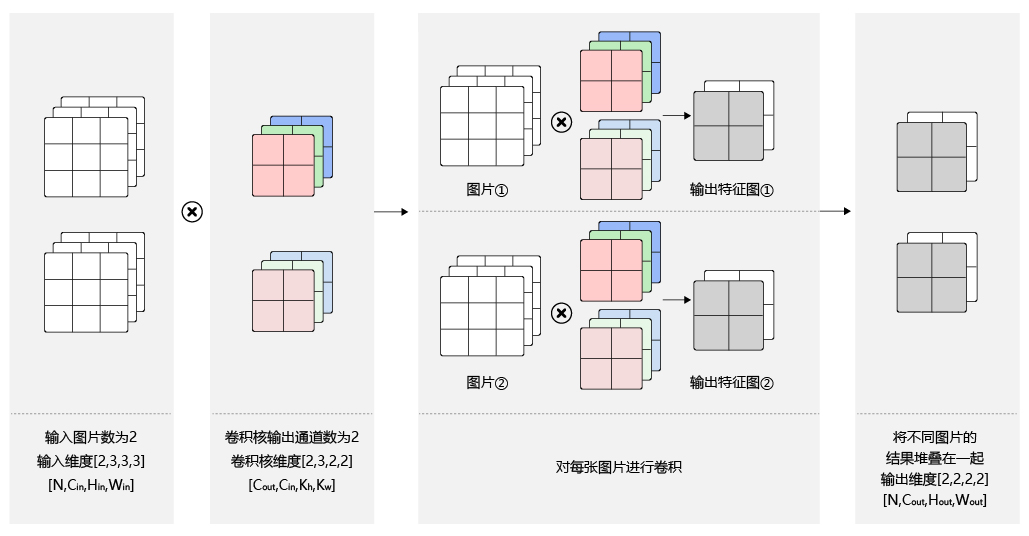
飞桨卷积API介绍
飞桨卷积算子对应的API是paddle.fluid.dygraph.Conv2D,用户可以直接调用API进行计算,也可以在此基础上修改。常用的参数如下:
- num_channels (int) - 输入图像的通道数。
- num_fliters (int) - 卷积核的个数,和输出特征图通道数相同,相当于上文中的 C o u t C_{out} Cout。
- filter_size(int|tuple) - 卷积核大小,可以是整数,比如3,表示卷积核的高和宽均为3 ;或者是两个整数的list,例如[3,2],表示卷积核的高为3,宽为2。
- stride(int|tuple) - 步幅,可以是整数,默认值为1,表示垂直和水平滑动步幅均为1;或者是两个整数的list,例如[3,2],表示垂直滑动步幅为3,水平滑动步幅为2。
- padding(int|tuple) - 填充大小,可以是整数,比如1,表示竖直和水平边界填充大小均为1;或者是两个整数的list,例如[2,1],表示竖直边界填充大小为2,水平边界填充大小为1。
- act(str)- 应用于输出上的激活函数,如Tanh、Softmax、Sigmoid,Relu等,默认值为None。
输入数据维度 [ N , C i n , H i n , W i n ] [N, C_{in}, H_{in}, W_{in}] [N,Cin,Hin,Win],输出数据维度 [ N , n u m _ f i l t e r s , H o u t , W o u t ] [N, num\_filters, H_{out}, W_{out}] [N,num_filters,Hout,Wout],权重参数 w w w的维度 [ n u m _ f i l t e r s , C i n , f i l t e r _ s i z e _ h , f i l t e r _ s i z e _ w ] [num\_filters, C_{in}, filter\_size\_h, filter\_size\_w] [num_filters,Cin,filter_size_h,filter_size_w],偏置参数 b b b的维度是 [ n u m _ f i l t e r s ] [num\_filters] [num_filters]。
卷积算子应用举例
下面介绍卷积算子在图片中应用的三个案例,并观察其计算结果。
案例1——简单的黑白边界检测
下面是使用Conv2D算子完成一个图像边界检测的任务。图像左边为光亮部分,右边为黑暗部分,需要检测出光亮跟黑暗的分界处。
可以设置宽度方向的卷积核为 [ 1 , 0 , − 1 ] [1, 0, -1] [1,0,−1],此卷积核会将宽度方向间隔为1的两个像素点的数值相减。当卷积核在图片上滑动的时候,如果它所覆盖的像素点位于亮度相同的区域,则左右间隔为1的两个像素点数值的差为0。只有当卷积核覆盖的像素点有的处于光亮区域,有的处在黑暗区域时,左右间隔为1的两个点像素值的差才不为0。将此卷积核作用到图片上,输出特征图上只有对应黑白分界线的地方像素值才不为0。具体代码如下所示,结果输出在下方的图案中。
import matplotlib.pyplot as pltimport numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D
from paddle.fluid.initializer import NumpyArrayInitializer
%matplotlib inlinewith fluid.dygraph.guard():# 创建初始化权重参数ww = np.array([1, 0, -1], dtype='float32')# 将权重参数调整成维度为[cout, cin, kh, kw]的四维张量w = w.reshape([1, 1, 1, 3])# 创建卷积算子,设置输出通道数,卷积核大小,和初始化权重参数# filter_size = [1, 3]表示kh = 1, kw=3# 创建卷积算子的时候,通过参数属性param_attr,指定参数初始化方式# 这里的初始化方式时,从numpy.ndarray初始化卷积参数conv = Conv2D(num_channels=1, num_filters=1, filter_size=[1, 3],param_attr=fluid.ParamAttr(initializer=NumpyArrayInitializer(value=w)))# 创建输入图片,图片左边的像素点取值为1,右边的像素点取值为0img = np.ones([50,50], dtype='float32')img[:, 30:] = 0.# 将图片形状调整为[N, C, H, W]的形式x = img.reshape([1,1,50,50])# 将numpy.ndarray转化成paddle中的tensorx = fluid.dygraph.to_variable(x)# 使用卷积算子作用在输入图片上y = conv(x)# 将输出tensor转化为numpy.ndarrayout = y.numpy()f = plt.subplot(121)
f.set_title('input image', fontsize=15)
plt.imshow(img, cmap='gray')f = plt.subplot(122)
f.set_title('output featuremap', fontsize=15)
# 卷积算子Conv2D输出数据形状为[N, C, H, W]形式
# 此处N, C=1,输出数据形状为[1, 1, H, W],是4维数组
# 但是画图函数plt.imshow画灰度图时,只接受2维数组
# 通过numpy.squeeze函数将大小为1的维度消除
plt.imshow(out.squeeze(), cmap='gray')
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZO6eMSZE-1598577714759)(output_12_0.png)]
# 查看卷积层的参数
with fluid.dygraph.guard():# 通过 conv.parameters()查看卷积层的参数,返回值是list,包含两个元素print(conv.parameters())# 查看卷积层的权重参数名字和数值print(conv.parameters()[0].name, conv.parameters()[0].numpy())# 参看卷积层的偏置参数名字和数值print(conv.parameters()[1].name, conv.parameters()[1].numpy())
[name conv2d_0.w_0, dtype: VarType.FP32 shape: [1, 1, 1, 3] lod: {}dim: 1, 1, 1, 3layout: NCHWdtype: floatdata: [1 0 -1]
, name conv2d_0.b_0, dtype: VarType.FP32 shape: [1] lod: {}dim: 1layout: NCHWdtype: floatdata: [0]
]
conv2d_0.w_0 [[[[ 1. 0. -1.]]]]
conv2d_0.b_0 [0.]
案例2——图像中物体边缘检测
上面展示的是一个人为构造出来的简单图片使用卷积检测明暗分界处的例子,对于真实的图片,也可以使用合适的卷积核对它进行操作,用来检测物体的外形轮廓,观察输出特征图跟原图之间的对应关系,如下代码所示:
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D
from paddle.fluid.initializer import NumpyArrayInitializerimg = Image.open('./work/000000098520.jpg')
with fluid.dygraph.guard():# 设置卷积核参数w = np.array([[-1,-1,-1], [-1,8,-1], [-1,-1,-1]], dtype='float32')/8w = w.reshape([1, 1, 3, 3])# 由于输入通道数是3,将卷积核的形状从[1,1,3,3]调整为[1,3,3,3]w = np.repeat(w, 3, axis=1)# 创建卷积算子,输出通道数为1,卷积核大小为3x3,# 并使用上面的设置好的数值作为卷积核权重的初始化参数conv = Conv2D(num_channels=3, num_filters=1, filter_size=[3, 3], param_attr=fluid.ParamAttr(initializer=NumpyArrayInitializer(value=w)))# 将读入的图片转化为float32类型的numpy.ndarrayx = np.array(img).astype('float32')# 图片读入成ndarry时,形状是[H, W, 3],# 将通道这一维度调整到最前面x = np.transpose(x, (2,0,1))# 将数据形状调整为[N, C, H, W]格式x = x.reshape(1, 3, img.height, img.width)x = fluid.dygraph.to_variable(x)y = conv(x)out = y.numpy()plt.figure(figsize=(20, 10))
f = plt.subplot(121)
f.set_title('input image', fontsize=15)
plt.imshow(img)
f = plt.subplot(122)
f.set_title('output feature map', fontsize=15)
plt.imshow(out.squeeze(), cmap='gray')
plt.show()[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eOYtrVEX-1598577714760)(output_15_0.png)]
案例3——图像均值模糊
另外一种比较常见的卷积核是用当前像素跟它邻域内的像素取平均,这样可以使图像上噪声比较大的点变得更平滑,如下代码所示:
import matplotlib.pyplot as pltfrom PIL import Imageimport numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D
from paddle.fluid.initializer import NumpyArrayInitializer# 读入图片并转成numpy.ndarray
#img = Image.open('./images/section1/000000001584.jpg')
img = Image.open('./work/000000355610.jpg').convert('L')
img = np.array(img)# 换成灰度图with fluid.dygraph.guard():# 创建初始化参数w = np.ones([1, 1, 5, 5], dtype = 'float32')/25conv = Conv2D(num_channels=1, num_filters=1, filter_size=[5, 5], param_attr=fluid.ParamAttr(initializer=NumpyArrayInitializer(value=w)))x = img.astype('float32')x = x.reshape(1,1,img.shape[0], img.shape[1])x = fluid.dygraph.to_variable(x)y = conv(x)out = y.numpy()plt.figure(figsize=(20, 12))
f = plt.subplot(121)
f.set_title('input image')
plt.imshow(img, cmap='gray')f = plt.subplot(122)
f.set_title('output feature map')
out = out.squeeze()
plt.imshow(out, cmap='gray')plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nCs6o1LQ-1598577714761)(output_17_0.png)]
池化(Pooling)
池化是使用某一位置的相邻输出的总体统计特征代替网络在该位置的输出,其好处是当输入数据做出少量平移时,经过池化函数后的大多数输出还能保持不变。比如:当识别一张图像是否是人脸时,我们需要知道人脸左边有一只眼睛,右边也有一只眼睛,而不需要知道眼睛的精确位置,这时候通过池化某一片区域的像素点来得到总体统计特征会显得很有用。由于池化之后特征图会变得更小,如果后面连接的是全连接层,能有效的减小神经元的个数,节省存储空间并提高计算效率。
如 图13 所示,将一个 2 × 2 2\times 2 2×2的区域池化成一个像素点。通常有两种方法,平均池化和最大池化。
图13:池化
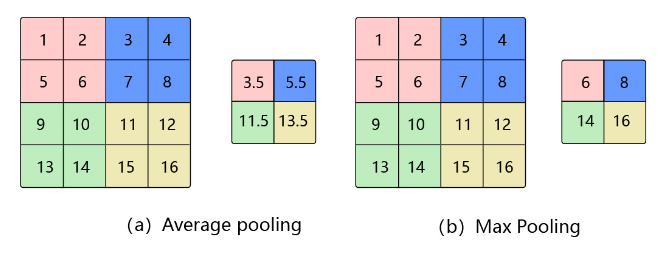
- 如图13(a):平均池化。这里使用大小为 2 × 2 2\times2 2×2的池化窗口,每次移动的步幅为2,对池化窗口覆盖区域内的像素取平均值,得到相应的输出特征图的像素值。
- 如图13(b):最大池化。对池化窗口覆盖区域内的像素取最大值,得到输出特征图的像素值。当池化窗口在图片上滑动时,会得到整张输出特征图。池化窗口的大小称为池化大小,用 k h × k w k_h \times k_w kh×kw表示。在卷积神经网络中用的比较多的是窗口大小为 2 × 2 2 \times 2 2×2,步幅为2的池化。
与卷积核类似,池化窗口在图片上滑动时,每次移动的步长称为步幅,当宽和高方向的移动大小不一样时,分别用 s w s_w sw和 s h s_h sh表示。也可以对需要进行池化的图片进行填充,填充方式与卷积类似,假设在第一行之前填充 p h 1 p_{h1} ph1行,在最后一行后面填充 p h 2 p_{h2} ph2行。在第一列之前填充 p w 1 p_{w1} pw1列,在最后一列之后填充 p w 2 p_{w2} pw2列,则池化层的输出特征图大小为:
H o u t = H + p h 1 + p h 2 − k h s h + 1 H_{out} = \frac{H + p_{h1} + p_{h2} - k_h}{s_h} + 1 Hout=shH+ph1+ph2−kh+1
W o u t = W + p w 1 + p w 2 − k w s w + 1 W_{out} = \frac{W + p_{w1} + p_{w2} - k_w}{s_w} + 1 Wout=swW+pw1+pw2−kw+1
在卷积神经网络中,通常使用 2 × 2 2\times2 2×2大小的池化窗口,步幅也使用2,填充为0,则输出特征图的尺寸为:
H o u t = H 2 H_{out} = \frac{H}{2} Hout=2H
W o u t = W 2 W_{out} = \frac{W}{2} Wout=2W
通过这种方式的池化,输出特征图的高和宽都减半,但通道数不会改变。
ReLU激活函数
前面介绍的网络结构中,普遍使用Sigmoid函数做激活函数。在神经网络发展的早期,Sigmoid函数用的比较多,而目前用的较多的激活函数是ReLU。这是因为Sigmoid函数在反向传播过程中,容易造成梯度的衰减。让我们仔细观察Sigmoid函数的形式,就能发现这一问题。
Sigmoid激活函数定义如下:
y = 1 1 + e − x y = \frac{1}{1 + e^{-x}} y=1+e−x1
ReLU激活函数的定义如下:
y = { 0 , ( x < 0 ) x , ( x ≥ 0 ) y=\left\{ \begin{aligned} 0 & , & (x<0) \\ x & , & (x\ge 0) \end{aligned} \right. y={0x,,(x<0)(x≥0)
下面的程序画出了Sigmoid和ReLU函数的曲线图:
# ReLU和Sigmoid激活函数示意图
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patchesplt.figure(figsize=(10, 5))# 创建数据x
x = np.arange(-10, 10, 0.1)# 计算Sigmoid函数
s = 1.0 / (1 + np.exp(0. - x))# 计算ReLU函数
y = np.clip(x, a_min=0., a_max=None)#####################################
# 以下部分为画图代码
f = plt.subplot(121)
plt.plot(x, s, color='r')
currentAxis=plt.gca()
plt.text(-9.0, 0.9, r'$y=Sigmoid(x)$', fontsize=13)
currentAxis.xaxis.set_label_text('x', fontsize=15)
currentAxis.yaxis.set_label_text('y', fontsize=15)f = plt.subplot(122)
plt.plot(x, y, color='g')
plt.text(-3.0, 9, r'$y=ReLU(x)$', fontsize=13)
currentAxis=plt.gca()
currentAxis.xaxis.set_label_text('x', fontsize=15)
currentAxis.yaxis.set_label_text('y', fontsize=15)plt.show()[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hOfrtU3Y-1598577714762)(output_20_0.png)]
梯度消失现象
在神经网络里面,将经过反向传播之后,梯度值衰减到接近于零的现象称作梯度消失现象。
从上面的函数曲线可以看出,当x为较大的正数的时候,Sigmoid函数数值非常接近于1,函数曲线变得很平滑,在这些区域Sigmoid函数的导数接近于零。当x为较小的负数的时候,Sigmoid函数值非常接近于0,函数曲线也很平滑,在这些区域Sigmoid函数的导数也接近于0。只有当x的取值在0附近时,Sigmoid函数的导数才比较大。可以对Sigmoid函数求导数,结果如下所示:
d y d x = − 1 ( 1 + e − x ) 2 ⋅ d ( e − x ) d x = 1 2 + e x + e − x \frac{dy}{dx} = -\frac{1}{(1+e^{-x})^2} \cdot \frac{d(e^{-x})}{dx} = \frac{1}{2 + e^x + e^{-x}} dxdy=−(1+e−x)21⋅dxd(e−x)=2+ex+e−x1
从上面的式子可以看出,Sigmoid函数的导数 d y d x \frac{dy}{dx} dxdy最大值为 1 4 \frac{1}{4} 41。前向传播时, y = S i g m o i d ( x ) y=Sigmoid(x) y=Sigmoid(x);而在反向传播过程中,x的梯度等于y的梯度乘以Sigmoid函数的导数,如下所示:
∂ L ∂ x = ∂ L ∂ y ⋅ ∂ y ∂ x \frac{\partial{L}}{\partial{x}} = \frac{\partial{L}}{\partial{y}} \cdot \frac{\partial{y}}{\partial{x}} ∂x∂L=∂y∂L⋅∂x∂y
使得x的梯度数值最大也不会超过y的梯度的 1 4 \frac{1}{4} 41。
由于最开始是将神经网络的参数随机初始化的,x很有可能取值在数值很大或者很小的区域,这些地方都可能造成Sigmoid函数的导数接近于0,导致x的梯度接近于0;即使x取值在接近于0的地方,按上面的分析,经过Sigmoid函数反向传播之后,x的梯度不超过y的梯度的 1 4 \frac{1}{4} 41,如果有多层网络使用了Sigmoid激活函数,则比较靠后的那些层梯度将衰减到非常小的值。
ReLU函数则不同,虽然在 x < 0 x\lt 0 x<0的地方,ReLU函数的导数为0。但是在 x ≥ 0 x\ge 0 x≥0的地方,ReLU函数的导数为1,能够将y的梯度完整的传递给x,而不会引起梯度消失。
批归一化(Batch Normalization)
批归一化方法方法(Batch Normalization,BatchNorm)是由Ioffe和Szegedy于2015年提出的,已被广泛应用在深度学习中,其目的是对神经网络中间层的输出进行标准化处理,使得中间层的输出更加稳定。
通常我们会对神经网络的数据进行标准化处理,处理后的样本数据集满足均值为0,方差为1的统计分布,这是因为当输入数据的分布比较固定时,有利于算法的稳定和收敛。对于深度神经网络来说,由于参数是不断更新的,即使输入数据已经做过标准化处理,但是对于比较靠后的那些层,其接收到的输入仍然是剧烈变化的,通常会导致数值不稳定,模型很难收敛。BatchNorm能够使神经网络中间层的输出变得更加稳定,并有如下三个优点:
使学习快速进行(能够使用较大的学习率)
降低模型对初始值的敏感性
从一定程度上抑制过拟合
BatchNorm主要思路是在训练时按mini-batch为单位,对神经元的数值进行归一化,使数据的分布满足均值为0,方差为1。具体计算过程如下:
1. 计算mini-batch内样本的均值
μ B ← 1 m ∑ i = 1 m x ( i ) \mu_B \leftarrow \frac{1}{m}\sum_{i=1}^mx^{(i)} μB←m1i=1∑mx(i)
其中 x ( i ) x^{(i)} x(i)表示mini-batch中的第 i i i个样本。
例如输入mini-batch包含3个样本,每个样本有2个特征,分别是:
x ( 1 ) = ( 1 , 2 ) , x ( 2 ) = ( 3 , 6 ) , x ( 3 ) = ( 5 , 10 ) x^{(1)} = (1,2), \ \ x^{(2)} = (3,6), \ \ x^{(3)} = (5,10) x(1)=(1,2), x(2)=(3,6), x(3)=(5,10)
对每个特征分别计算mini-batch内样本的均值:
μ B 0 = 1 + 3 + 5 3 = 3 , μ B 1 = 2 + 6 + 10 3 = 6 \mu_{B0} = \frac{1+3+5}{3} = 3, \ \ \ \mu_{B1} = \frac{2+6+10}{3} = 6 μB0=31+3+5=3, μB1=32+6+10=6
则样本均值是:
μ B = ( μ B 0 , μ B 1 ) = ( 3 , 6 ) \mu_{B} = (\mu_{B0}, \mu_{B1}) = (3, 6) μB=(μB0,μB1)=(3,6)
2. 计算mini-batch内样本的方差
σ B 2 ← 1 m ∑ i = 1 m ( x ( i ) − μ B ) 2 \sigma_B^2 \leftarrow \frac{1}{m}\sum_{i=1}^m(x^{(i)} - \mu_B)^2 σB2←m1i=1∑m(x(i)−μB)2
上面的计算公式先计算一个批次内样本的均值 μ B \mu_B μB和方差 σ B 2 \sigma_B^2 σB2,然后再对输入数据做归一化,将其调整成均值为0,方差为1的分布。
对于上述给定的输入数据 x ( 1 ) , x ( 2 ) , x ( 3 ) x^{(1)}, x^{(2)}, x^{(3)} x(1),x(2),x(3),可以计算出每个特征对应的方差:
σ B 0 2 = 1 3 ⋅ ( ( 1 − 3 ) 2 + ( 3 − 3 ) 2 + ( 5 − 3 ) 2 ) = 8 3 \sigma_{B0}^2 = \frac{1}{3} \cdot ((1-3)^2 + (3-3)^2 + (5-3)^2) = \frac{8}{3} σB02=31⋅((1−3)2+(3−3)2+(5−3)2)=38
σ B 1 2 = 1 3 ⋅ ( ( 2 − 6 ) 2 + ( 6 − 6 ) 2 + ( 10 − 6 ) 2 ) = 32 3 \sigma_{B1}^2 = \frac{1}{3} \cdot ((2-6)^2 + (6-6)^2 + (10-6)^2) = \frac{32}{3} σB12=31⋅((2−6)2+(6−6)2+(10−6)2)=332
则样本方差是:
σ B 2 = ( σ B 0 2 , σ B 1 2 ) = ( 8 3 , 32 3 ) \sigma_{B}^2 = (\sigma_{B0}^2, \sigma_{B1}^2) = (\frac{8}{3}, \frac{32}{3}) σB2=(σB02,σB12)=(38,332)
3. 计算标准化之后的输出
x ^ ( i ) ← x ( i ) − μ B ( σ B 2 + ϵ ) \hat{x}^{(i)} \leftarrow \frac{x^{(i)} - \mu_B}{\sqrt{(\sigma_B^2 + \epsilon)}} x^(i)←(σB2+ϵ) x(i)−μB
其中 ϵ \epsilon ϵ是一个微小值(例如 1 e − 7 1e-7 1e−7),其主要作用是为了防止分母为0。
对于上述给定的输入数据 x ( 1 ) , x ( 2 ) , x ( 3 ) x^{(1)}, x^{(2)}, x^{(3)} x(1),x(2),x(3),可以计算出标准化之后的输出:
x ^ ( 1 ) = ( 1 − 3 8 3 , 2 − 6 32 3 ) = ( − 3 2 , − 3 2 ) \hat{x}^{(1)} = (\frac{1 - 3}{\sqrt{\frac{8}{3}}}, \ \ \frac{2 - 6}{\sqrt{\frac{32}{3}}}) = (-\sqrt{\frac{3}{2}}, \ \ -\sqrt{\frac{3}{2}}) x^(1)=(38 1−3, 332 2−6)=(−23 , −23 )
x ^ ( 2 ) = ( 3 − 3 8 3 , 6 − 6 32 3 ) = ( 0 , 0 ) \hat{x}^{(2)} = (\frac{3 - 3}{\sqrt{\frac{8}{3}}}, \ \ \frac{6 - 6}{\sqrt{\frac{32}{3}}}) = (0, \ \ 0) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ x^(2)=(38 3−3, 332 6−6)=(0, 0)
x ^ ( 3 ) = ( 5 − 3 8 3 , 10 − 6 32 3 ) = ( 3 2 , 3 2 ) \hat{x}^{(3)} = (\frac{5 - 3}{\sqrt{\frac{8}{3}}}, \ \ \frac{10 - 6}{\sqrt{\frac{32}{3}}}) = (\sqrt{\frac{3}{2}}, \ \ \sqrt{\frac{3}{2}}) \ \ \ \ x^(3)=(38 5−3, 332 10−6)=(23 , 23 )
- 读者可以自行验证由 x ^ ( 1 ) , x ^ ( 2 ) , x ^ ( 3 ) \hat{x}^{(1)}, \hat{x}^{(2)}, \hat{x}^{(3)} x^(1),x^(2),x^(3)构成的mini-batch,是否满足均值为0,方差为1的分布。
如果强行限制输出层的分布是标准化的,可能会导致某些特征模式的丢失,所以在标准化之后,BatchNorm会紧接着对数据做缩放和平移。
y i ← γ x i ^ + β y_i \leftarrow \gamma \hat{x_i} + \beta yi←γxi^+β
其中 γ \gamma γ和 β \beta β是可学习的参数,可以赋初始值 γ = 1 , β = 0 \gamma = 1, \beta = 0 γ=1,β=0,在训练过程中不断学习调整。
上面列出的是BatchNorm方法的计算逻辑,下面针对两种类型的输入数据格式分别进行举例。飞桨支持输入数据的维度大小为2、3、4、5四种情况,这里给出的是维度大小为2和4的示例。
- 示例一: 当输入数据形状是 [ N , K ] [N, K] [N,K]时,一般对应全连接层的输出,示例代码如下所示。
这种情况下会分别对K的每一个分量计算N个样本的均值和方差,数据和参数对应如下:
- 输入 x, [N, K]
- 输出 y, [N, K]
- 均值 μ B \mu_B μB,[K, ]
- 方差 σ B 2 \sigma_B^2 σB2, [K, ]
- 缩放参数 γ \gamma γ, [K, ]
- 平移参数 β \beta β, [K, ]
# 输入数据形状是 [N, K]时的示例
import numpy as npimport paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import BatchNorm
# 创建数据
data = np.array([[1,2,3], [4,5,6], [7,8,9]]).astype('float32')
# 使用BatchNorm计算归一化的输出
with fluid.dygraph.guard():# 输入数据维度[N, K],num_channels等于Kbn = BatchNorm(num_channels=3) x = fluid.dygraph.to_variable(data)y = bn(x)print('output of BatchNorm Layer: \n {}'.format(y.numpy()))# 使用Numpy计算均值、方差和归一化的输出
# 这里对第0个特征进行验证
a = np.array([1,4,7])
a_mean = a.mean()
a_std = a.std()
b = (a - a_mean) / a_std
print('std {}, mean {}, \n output {}'.format(a_mean, a_std, b))# 建议读者对第1和第2个特征进行验证,观察numpy计算结果与paddle计算结果是否一致
output of BatchNorm Layer: [[-1.2247438 -1.2247438 -1.2247438][ 0. 0. 0. ][ 1.2247438 1.2247438 1.2247438]]
std 4.0, mean 2.449489742783178, output [-1.22474487 0. 1.22474487]
- 示例二: 当输入数据形状是 [ N , C , H , W ] [N, C, H, W] [N,C,H,W]时, 一般对应卷积层的输出,示例代码如下所示。
这种情况下会沿着C这一维度进行展开,分别对每一个通道计算N个样本中总共 N × H × W N\times H \times W N×H×W个像素点的均值和方差,数据和参数对应如下:
- 输入 x, [N, C, H, W]
- 输出 y, [N, C, H, W]
- 均值 μ B \mu_B μB,[C, ]
- 方差 σ B 2 \sigma_B^2 σB2, [C, ]
- 缩放参数 γ \gamma γ, [C, ]
- 平移参数 β \beta β, [C, ]
小窍门:
可能有读者会问:“BatchNorm里面不是还要对标准化之后的结果做仿射变换吗,怎么使用Numpy计算的结果与BatchNorm算子一致?” 这是因为BatchNorm算子里面自动设置初始值 γ = 1 , β = 0 \gamma = 1, \beta = 0 γ=1,β=0,这时候仿射变换相当于是恒等变换。在训练过程中这两个参数会不断的学习,这时仿射变换就会起作用。
# 输入数据形状是[N, C, H, W]时的batchnorm示例
import numpy as npimport paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import BatchNorm# 设置随机数种子,这样可以保证每次运行结果一致
np.random.seed(100)
# 创建数据
data = np.random.rand(2,3,3,3).astype('float32')
# 使用BatchNorm计算归一化的输出
with fluid.dygraph.guard():# 输入数据维度[N, C, H, W],num_channels等于Cbn = BatchNorm(num_channels=3)x = fluid.dygraph.to_variable(data)y = bn(x)print('input of BatchNorm Layer: \n {}'.format(x.numpy()))print('output of BatchNorm Layer: \n {}'.format(y.numpy()))# 取出data中第0通道的数据,
# 使用numpy计算均值、方差及归一化的输出
a = data[:, 0, :, :]
a_mean = a.mean()
a_std = a.std()
b = (a - a_mean) / a_std
print('channel 0 of input data: \n {}'.format(a))
print('std {}, mean {}, \n output: \n {}'.format(a_mean, a_std, b))# 提示:这里通过numpy计算出来的输出
# 与BatchNorm算子的结果略有差别,
# 因为在BatchNorm算子为了保证数值的稳定性,
# 在分母里面加上了一个比较小的浮点数epsilon=1e-05
input of BatchNorm Layer: [[[[0.54340494 0.2783694 0.4245176 ][0.84477615 0.00471886 0.12156912][0.67074907 0.82585275 0.13670659]][[0.5750933 0.89132196 0.20920213][0.18532822 0.10837689 0.21969749][0.9786238 0.8116832 0.17194101]][[0.81622475 0.27407375 0.4317042 ][0.9400298 0.81764936 0.33611196][0.17541045 0.37283206 0.00568851]]][[[0.25242636 0.7956625 0.01525497][0.5988434 0.6038045 0.10514768][0.38194343 0.03647606 0.89041156]][[0.98092085 0.05994199 0.89054596][0.5769015 0.7424797 0.63018394][0.5818422 0.02043913 0.21002658]][[0.5446849 0.76911515 0.25069523][0.2858957 0.8523951 0.9750065 ][0.8848533 0.35950786 0.59885895]]]]
output of BatchNorm Layer: [[[[ 0.4126078 -0.46198368 0.02029109][ 1.4071034 -1.3650038 -0.97940934][ 0.832831 1.344658 -0.9294571 ]][[ 0.2520175 1.2038351 -0.84927964][-0.9211378 -1.1527538 -0.8176896 ][ 1.4666051 0.96413004 -0.961432 ]][[ 0.9541142 -0.9075856 -0.36629617][ 1.37925 0.9590063 -0.6945517 ][-1.2463869 -0.5684581 -1.8291974 ]]][[[-0.5475932 1.2450331 -1.3302356 ][ 0.5955492 0.6119205 -1.0335984 ][-0.12019944 -1.2602081 1.5576957 ]][[ 1.473519 -1.2985382 1.2014993 ][ 0.25745988 0.7558342 0.41783488][ 0.27233088 -1.4174379 -0.8467981 ]][[ 0.02166975 0.79234385 -0.98786545][-0.86699003 1.0783203 1.4993572 ][ 1.1897788 -0.6142123 0.20769882]]]]
channel 0 of input data: [[[0.54340494 0.2783694 0.4245176 ][0.84477615 0.00471886 0.12156912][0.67074907 0.82585275 0.13670659]][[0.25242636 0.7956625 0.01525497][0.5988434 0.6038045 0.10514768][0.38194343 0.03647606 0.89041156]]]
std 0.4183686077594757, mean 0.3030227720737457, output: [[[ 0.41263014 -0.46200886 0.02029219][ 1.4071798 -1.3650781 -0.9794626 ][ 0.8328762 1.3447311 -0.92950773]][[-0.54762304 1.2451009 -1.3303081 ][ 0.5955816 0.61195374 -1.0336547 ][-0.12020606 -1.2602768 1.5577804 ]]]
- 预测时使用BatchNorm
上面介绍了在训练过程中使用BatchNorm对一批样本进行归一化的方法,但如果使用同样的方法对需要预测的一批样本进行归一化,则预测结果会出现不确定性。
例如样本A、样本B作为一批样本计算均值和方差,与样本A、样本C和样本D作为一批样本计算均值和方差,得到的结果一般来说是不同的。那么样本A的预测结果就会变得不确定,这对预测过程来说是不合理的。解决方法是在训练过程中将大量样本的均值和方差保存下来,预测时直接使用保存好的值而不再重新计算。实际上,在BatchNorm的具体实现中,训练时会计算均值和方差的移动平均值。在飞桨中,默认是采用如下方式计算:
s a v e d _ μ B ← s a v e d _ μ B × 0.9 + μ B × ( 1 − 0.9 ) saved\_\mu_B \leftarrow \ saved\_\mu_B \times 0.9 + \mu_B \times (1 - 0.9) saved_μB← saved_μB×0.9+μB×(1−0.9)
s a v e d _ σ B 2 ← s a v e d _ σ B 2 × 0.9 + σ B 2 × ( 1 − 0.9 ) saved\_\sigma_B^2 \leftarrow \ saved\_\sigma_B^2 \times 0.9 + \sigma_B^2 \times (1 - 0.9) saved_σB2← saved_σB2×0.9+σB2×(1−0.9)
在训练过程的最开始将 s a v e d _ μ B saved\_\mu_B saved_μB和 s a v e d _ σ B 2 saved\_\sigma_B^2 saved_σB2设置为0,每次输入一批新的样本,计算出 μ B \mu_B μB和 σ B 2 \sigma_B^2 σB2,然后通过上面的公式更新 s a v e d _ μ B saved\_\mu_B saved_μB和 s a v e d _ σ B 2 saved\_\sigma_B^2 saved_σB2,在训练的过程中不断的更新它们的值,并作为BatchNorm层的参数保存下来。预测的时候将会加载参数 s a v e d _ μ B saved\_\mu_B saved_μB和 s a v e d _ σ B 2 saved\_\sigma_B^2 saved_σB2,用他们来代替 μ B \mu_B μB和 σ B 2 \sigma_B^2 σB2。
丢弃法(Dropout)
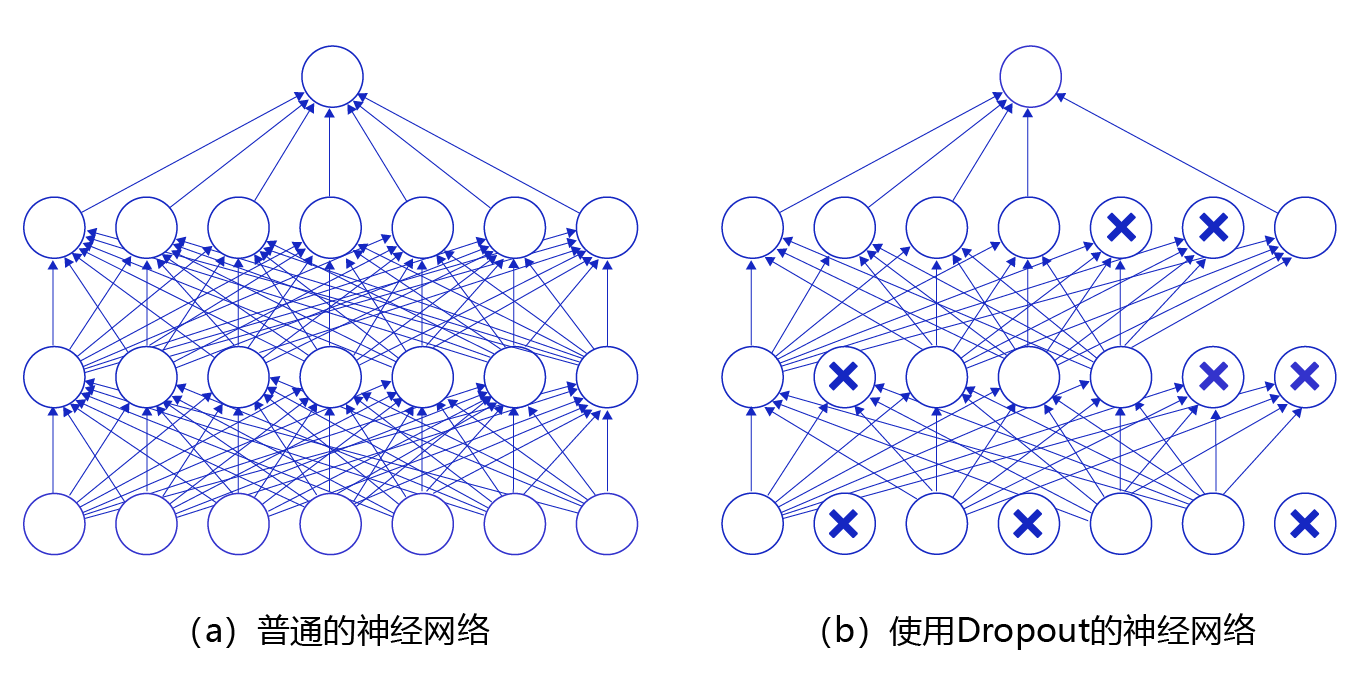
丢弃法(Dropout)是深度学习中一种常用的抑制过拟合的方法,其做法是在神经网络学习过程中,随机删除一部分神经元。训练时,随机选出一部分神经元,将其输出设置为0,这些神经元将不对外传递信号。
图14 是Dropout示意图,左边是完整的神经网络,右边是应用了Dropout之后的网络结构。应用Dropout之后,会将标了 × \times ×的神经元从网络中删除,让它们不向后面的层传递信号。在学习过程中,丢弃哪些神经元是随机决定,因此模型不会过度依赖某些神经元,能一定程度上抑制过拟合。
图14 Dropout示意图
在预测场景时,会向前传递所有神经元的信号,可能会引出一个新的问题:训练时由于部分神经元被随机丢弃了,输出数据的总大小会变小。比如:计算其 L 1 L1 L1范数会比不使用Dropout时变小,但是预测时却没有丢弃神经元,这将导致训练和预测时数据的分布不一样。为了解决这个问题,飞桨支持如下两种方法:
- downgrade_in_infer
训练时以比例 r r r随机丢弃一部分神经元,不向后传递它们的信号;预测时向后传递所有神经元的信号,但是将每个神经元上的数值乘以 ( 1 − r ) (1 - r) (1−r)。
- upscale_in_train
训练时以比例 r r r随机丢弃一部分神经元,不向后传递它们的信号,但是将那些被保留的神经元上的数值除以 ( 1 − r ) (1 - r) (1−r);预测时向后传递所有神经元的信号,不做任何处理。
在飞桨dropout API中,paddle.fluid.layers.dropout通过dropout_implementation参数来指定用哪种方式对神经元进行操作,dropout_implementation参数的可选值是’downgrade_in_infer’或’upscale_in_train’,缺省值是’downgrade_in_infer’。
说明:
不同框架对于dropout的默认处理方式可能不同,读者可以查看API详细了解。
飞桨dropout API包含的主要参数如下:
- x (Variable)- 数据类型是Tensor,需要采用丢弃法进行操作的对象。
- dropout_prob (float32) - 对 x x x中元素进行丢弃的概率,即输入单元设置为0的概率,该参数对元素的丢弃概率是针对于每一个元素而言而不是对所有的元素而言。举例说,假设矩阵内有12个数字,经过概率为0.5的dropout未必一定有6个零。
- is_test (bool) - 是否运行在测试阶段,由于dropout在训练和测试阶段表现不一样,通过此参数控制其表现,默认值为’False’。
- dropout_implementation (str) - 丢弃法的实现方式,有’downgrade_in_infer’和’upscale_in_train’两种,具体情况请见上面的说明,默认是’downgrade_in_infer’。
下面这段程序展示了经过dropout之后输出数据的形式。
# dropout操作
import numpy as npimport paddle
import paddle.fluid as fluid# 设置随机数种子,这样可以保证每次运行结果一致
np.random.seed(100)
# 创建数据[N, C, H, W],一般对应卷积层的输出
data1 = np.random.rand(2,3,3,3).astype('float32')
# 创建数据[N, K],一般对应全连接层的输出
data2 = np.arange(1,13).reshape([-1, 3]).astype('float32')
# 使用dropout作用在输入数据上
with fluid.dygraph.guard():x1 = fluid.dygraph.to_variable(data1)out1_1 = fluid.layers.dropout(x1, dropout_prob=0.5, is_test=False)out1_2 = fluid.layers.dropout(x1, dropout_prob=0.5, is_test=True)x2 = fluid.dygraph.to_variable(data2)out2_1 = fluid.layers.dropout(x2, dropout_prob=0.5, \dropout_implementation='upscale_in_train')out2_2 = fluid.layers.dropout(x2, dropout_prob=0.5, \dropout_implementation='upscale_in_train', is_test=True)print('x1 {}, \n out1_1 \n {}, \n out1_2 \n {}'.format(data1, out1_1.numpy(), out1_2.numpy()))print('x2 {}, \n out2_1 \n {}, \n out2_2 \n {}'.format(data2, out2_1.numpy(), out2_2.numpy()))
x1 [[[[0.54340494 0.2783694 0.4245176 ][0.84477615 0.00471886 0.12156912][0.67074907 0.82585275 0.13670659]][[0.5750933 0.89132196 0.20920213][0.18532822 0.10837689 0.21969749][0.9786238 0.8116832 0.17194101]][[0.81622475 0.27407375 0.4317042 ][0.9400298 0.81764936 0.33611196][0.17541045 0.37283206 0.00568851]]][[[0.25242636 0.7956625 0.01525497][0.5988434 0.6038045 0.10514768][0.38194343 0.03647606 0.89041156]][[0.98092085 0.05994199 0.89054596][0.5769015 0.7424797 0.63018394][0.5818422 0.02043913 0.21002658]][[0.5446849 0.76911515 0.25069523][0.2858957 0.8523951 0.9750065 ][0.8848533 0.35950786 0.59885895]]]], out1_1 [[[[0.54340494 0.2783694 0.4245176 ][0.84477615 0. 0. ][0.67074907 0.82585275 0. ]][[0.5750933 0.89132196 0. ][0.18532822 0. 0. ][0. 0. 0. ]][[0. 0. 0.4317042 ][0.9400298 0.81764936 0.33611196][0.17541045 0.37283206 0. ]]][[[0.25242636 0.7956625 0. ][0.5988434 0. 0. ][0. 0.03647606 0. ]][[0. 0. 0.89054596][0.5769015 0. 0.63018394][0. 0.02043913 0.21002658]][[0.5446849 0. 0.25069523][0.2858957 0. 0.9750065 ][0. 0. 0.59885895]]]], out1_2 [[[[0. 0. 0. ][0. 0.00471886 0. ][0. 0. 0. ]][[0.5750933 0. 0.20920213][0. 0. 0. ][0. 0. 0. ]][[0.81622475 0. 0.4317042 ][0.9400298 0.81764936 0. ][0. 0.37283206 0. ]]][[[0.25242636 0.7956625 0. ][0.5988434 0. 0. ][0. 0.03647606 0. ]][[0.98092085 0. 0.89054596][0. 0. 0. ][0.5818422 0.02043913 0.21002658]][[0.5446849 0. 0. ][0.2858957 0. 0.9750065 ][0. 0. 0.59885895]]]]
x2 [[ 1. 2. 3.][ 4. 5. 6.][ 7. 8. 9.][10. 11. 12.]], out2_1 [[ 2. 0. 6.][ 8. 0. 12.][ 0. 0. 0.][ 0. 22. 24.]], out2_2 [[ 0. 4. 0.][ 0. 10. 12.][14. 0. 18.][ 0. 22. 0.]]
用于视觉分类的各种网络:
用于视觉分类的常用网络:
LeNet:Yan LeCun等人于1998年第一次将卷积神经网络应用到图像分类任务上[1],在手写数字识别任务上取得了巨大成功。
AlexNet:Alex Krizhevsky等人在2012年提出了AlexNet[2], 并应用在大尺寸图片数据集ImageNet上,获得了2012年ImageNet比赛冠军(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。
VGG:Simonyan和Zisserman于2014年提出了VGG网络结构[3],是当前最流行的卷积神经网络之一,由于其结构简单、应用性极强而深受广大研究者欢迎。
GoogLeNet:Christian Szegedy等人在2014提出了GoogLeNet[4],并取得了2014年ImageNet比赛冠军。
ResNet:Kaiming He等人在2015年提出了ResNet[5],通过引入残差模块加深网络层数,在ImagNet数据集上的错误率降低到3.6%,超越了人眼识别水平。ResNet的设计思想深刻地影响了后来的深度神经网络的设计。
LeNet
LeNet是最早的卷积神经网络之一[1]。1998年,Yan LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征,其架构如 图1 所示,这里展示的是作者论文中的LeNet-5模型:
图1:LeNet模型网络结构示意图
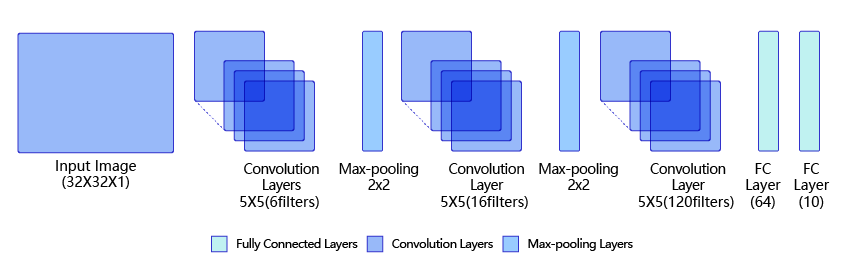
第一模块:包含5×5的6通道卷积和2×2的池化。卷积提取图像中包含的特征模式(激活函数使用sigmoid),图像尺寸从32减小到28。经过池化层可以降低输出特征图对空间位置的敏感性,图像尺寸减到14。
第二模块:和第一模块尺寸相同,通道数由6增加为16。卷积操作使图像尺寸减小到10,经过池化后变成5。
第三模块:包含5×5的120通道卷积。卷积之后的图像尺寸减小到1,但是通道数增加为120。将经过第3次卷积提取到的特征图输入到全连接层。第一个全连接层的输出神经元的个数是64,第二个全连接层的输出神经元个数是分类标签的类别数,对于手写数字识别其大小是10。然后使用Softmax激活函数即可计算出每个类别的预测概率。
【提示】:
卷积层的输出特征图如何当作全连接层的输入使用呢?
卷积层的输出数据格式是 [ N , C , H , W ] [N, C, H, W] [N,C,H,W],在输入全连接层的时候,会自动将数据拉平,
也就是对每个样本,自动将其转化为长度为 K K K的向量,
其中 K = C × H × W K = C \times H \times W K=C×H×W,一个mini-batch的数据维度变成了 N × K N\times K N×K的二维向量。
LeNet在手写数字识别上的应用
LeNet网络的实现代码如下:
# 导入需要的包
import paddle
import paddle.fluid as fluid
import numpy as np
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear# 定义 LeNet 网络结构
class LeNet(fluid.dygraph.Layer):def __init__(self, num_classes=1):super(LeNet, self).__init__()# 创建卷积和池化层块,每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化self.conv1 = Conv2D(num_channels=1, num_filters=6, filter_size=5, act='sigmoid')self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')self.conv2 = Conv2D(num_channels=6, num_filters=16, filter_size=5, act='sigmoid')self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')# 创建第3个卷积层self.conv3 = Conv2D(num_channels=16, num_filters=120, filter_size=4, act='sigmoid')# 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数self.fc1 = Linear(input_dim=120, output_dim=64, act='sigmoid')self.fc2 = Linear(input_dim=64, output_dim=num_classes)# 网络的前向计算过程def forward(self, x):x = self.conv1(x)x = self.pool1(x)x = self.conv2(x)x = self.pool2(x)x = self.conv3(x)x = fluid.layers.reshape(x, [x.shape[0], -1])x = self.fc1(x)x = self.fc2(x)return x
下面的程序使用随机数作为输入,查看经过LeNet-5的每一层作用之后,输出数据的形状
# 输入数据形状是 [N, 1, H, W]
# 这里用np.random创建一个随机数组作为输入数据
x = np.random.randn(*[3,1,28,28])
x = x.astype('float32')
with fluid.dygraph.guard():# 创建LeNet类的实例,指定模型名称和分类的类别数目m = LeNet(num_classes=10)# 通过调用LeNet从基类继承的sublayers()函数,# 查看LeNet中所包含的子层print(m.sublayers())x = fluid.dygraph.to_variable(x)for item in m.sublayers():# item是LeNet类中的一个子层# 查看经过子层之后的输出数据形状try:x = item(x)except:x = fluid.layers.reshape(x, [x.shape[0], -1])x = item(x)if len(item.parameters())==2:# 查看卷积和全连接层的数据和参数的形状,# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数bprint(item.full_name(), x.shape, item.parameters()[0].shape, item.parameters()[1].shape)else:# 池化层没有参数print(item.full_name(), x.shape)
[<paddle.fluid.dygraph.nn.Conv2D object at 0x7f3b91e66a10>, <paddle.fluid.dygraph.nn.Pool2D object at 0x7f3b91e66b90>, <paddle.fluid.dygraph.nn.Conv2D object at 0x7f3c141c4f50>, <paddle.fluid.dygraph.nn.Pool2D object at 0x7f3b91e7e110>, <paddle.fluid.dygraph.nn.Conv2D object at 0x7f3b91e7e170>, <paddle.fluid.dygraph.nn.Linear object at 0x7f3b91e7e290>, <paddle.fluid.dygraph.nn.Linear object at 0x7f3b91e7e410>]
conv2d_0 [3, 6, 24, 24] [6, 1, 5, 5] [6]
pool2d_0 [3, 6, 12, 12]
conv2d_1 [3, 16, 8, 8] [16, 6, 5, 5] [16]
pool2d_1 [3, 16, 4, 4]
conv2d_2 [3, 120, 1, 1] [120, 16, 4, 4] [120]
linear_0 [3, 64] [120, 64] [64]
linear_1 [3, 10] [64, 10] [10]
# -*- coding: utf-8 -*-# LeNet 识别手写数字import os
import random
import paddle
import paddle.fluid as fluid
import numpy as np# 定义训练过程
def train(model):print('start training ... ')model.train()epoch_num = 5opt = fluid.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameter_list=model.parameters())# 使用Paddle自带的数据读取器train_loader = paddle.batch(paddle.dataset.mnist.train(), batch_size=10)valid_loader = paddle.batch(paddle.dataset.mnist.test(), batch_size=10)for epoch in range(epoch_num):for batch_id, data in enumerate(train_loader()):# 调整输入数据形状和类型x_data = np.array([item[0] for item in data], dtype='float32').reshape(-1, 1, 28, 28)y_data = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)# 将numpy.ndarray转化成Tensorimg = fluid.dygraph.to_variable(x_data)label = fluid.dygraph.to_variable(y_data)# 计算模型输出logits = model(img)# 计算损失函数loss = fluid.layers.softmax_with_cross_entropy(logits, label)avg_loss = fluid.layers.mean(loss)if batch_id % 1000 == 0:print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))avg_loss.backward()opt.minimize(avg_loss)model.clear_gradients()model.eval()accuracies = []losses = []for batch_id, data in enumerate(valid_loader()):# 调整输入数据形状和类型x_data = np.array([item[0] for item in data], dtype='float32').reshape(-1, 1, 28, 28)y_data = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)# 将numpy.ndarray转化成Tensorimg = fluid.dygraph.to_variable(x_data)label = fluid.dygraph.to_variable(y_data)# 计算模型输出logits = model(img)pred = fluid.layers.softmax(logits)# 计算损失函数loss = fluid.layers.softmax_with_cross_entropy(logits, label)acc = fluid.layers.accuracy(pred, label)accuracies.append(acc.numpy())losses.append(loss.numpy())print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))model.train()# 保存模型参数fluid.save_dygraph(model.state_dict(), 'mnist')if __name__ == '__main__':# 创建模型with fluid.dygraph.guard():model = LeNet(num_classes=10)#启动训练过程train(model)start training ...
epoch: 0, batch_id: 0, loss is: [2.604516]
epoch: 0, batch_id: 1000, loss is: [2.2969098]
epoch: 0, batch_id: 2000, loss is: [2.3357966]
epoch: 0, batch_id: 3000, loss is: [2.283255]
epoch: 0, batch_id: 4000, loss is: [2.2734518]
epoch: 0, batch_id: 5000, loss is: [2.336421]
[validation] accuracy/loss: 0.1876000016927719/2.2875757217407227
通过运行结果可以看出,LeNet在手写数字识别MNIST验证数据集上的准确率高达92%以上。那么对于其它数据集效果如何呢?我们通过眼疾识别数据集iChallenge-PM验证一下。
LeNet在眼疾识别数据集iChallenge-PM上的应用
iChallenge-PM是百度大脑和中山大学中山眼科中心联合举办的iChallenge比赛中,提供的关于病理性近视(Pathologic Myopia,PM)的医疗类数据集,包含1200个受试者的眼底视网膜图片,训练、验证和测试数据集各400张。下面我们详细介绍LeNet在iChallenge-PM上的训练过程。
说明:
如今近视已经成为困扰人们健康的一项全球性负担,在近视人群中,有超过35%的人患有重度近视。近视会拉长眼睛的光轴,也可能引起视网膜或者络网膜的病变。随着近视度数的不断加深,高度近视有可能引发病理性病变,这将会导致以下几种症状:视网膜或者络网膜发生退化、视盘区域萎缩、漆裂样纹损害、Fuchs斑等。因此,及早发现近视患者眼睛的病变并采取治疗,显得非常重要。
数据可以从AIStudio下载
数据集准备
/home/aistudio/data/data19065 目录包括如下三个文件,解压缩后存放在/home/aistudio/work/palm目录下。
- training.zip:包含训练中的图片和标签
- validation.zip:包含验证集的图片
- valid_gt.zip:包含验证集的标签
注意:
valid_gt.zip文件解压缩之后,需要将“/home/aistudio/work/palm/PALM-Validation-GT/”目录下的“PM_Label_and_Fovea_Location.xlsx”文件转存成.csv格式,本节代码示例中已经提前转成文件labels.csv。
# 初次运行时将注释取消,以便解压文件
# 如果已经解压过,不需要运行此段代码,否则由于文件已经存在,解压时会报错
!unzip -o -q -d /home/aistudio/work/palm /home/aistudio/data/data19065/training.zip
%cd /home/aistudio/work/palm/PALM-Training400/
!unzip -o -q PALM-Training400.zip
!unzip -o -q -d /home/aistudio/work/palm /home/aistudio/data/data19065/validation.zip
!unzip -o -q -d /home/aistudio/work/palm /home/aistudio/data/data19065/valid_gt.zip/home/aistudio/work/palm/PALM-Training400
查看数据集图片
iChallenge-PM中既有病理性近视患者的眼底图片,也有非病理性近视患者的图片,命名规则如下:
病理性近视(PM):文件名以P开头
非病理性近视(non-PM):
高度近视(high myopia):文件名以H开头
正常眼睛(normal):文件名以N开头
我们将病理性患者的图片作为正样本,标签为1; 非病理性患者的图片作为负样本,标签为0。从数据集中选取两张图片,通过LeNet提取特征,构建分类器,对正负样本进行分类,并将图片显示出来。代码如下所示:
import os
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from PIL import ImageDATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
# 文件名以N开头的是正常眼底图片,以P开头的是病变眼底图片
file1 = 'N0012.jpg'
file2 = 'P0095.jpg'# 读取图片
img1 = Image.open(os.path.join(DATADIR, file1))
img1 = np.array(img1)
img2 = Image.open(os.path.join(DATADIR, file2))
img2 = np.array(img2)# 画出读取的图片
plt.figure(figsize=(16, 8))
f = plt.subplot(121)
f.set_title('Normal', fontsize=20)
plt.imshow(img1)
f = plt.subplot(122)
f.set_title('PM', fontsize=20)
plt.imshow(img2)
plt.show()
2020-08-19 20:04:00,896-INFO: font search path ['/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/afm', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/pdfcorefonts']
2020-08-19 20:04:01,368-INFO: generated new fontManager
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-60sRwDNc-1598578137722)(output_11_1.png)]
# 查看图片形状
img1.shape, img2.shape
((2056, 2124, 3), (2056, 2124, 3))
定义数据读取器
使用OpenCV从磁盘读入图片,将每张图缩放到 224 × 224 224\times224 224×224大小,并且将像素值调整到 [ − 1 , 1 ] [-1, 1] [−1,1]之间,代码如下所示:
import cv2
import random
import numpy as np# 对读入的图像数据进行预处理
def transform_img(img):# 将图片尺寸缩放道 224x224img = cv2.resize(img, (224, 224))# 读入的图像数据格式是[H, W, C]# 使用转置操作将其变成[C, H, W]img = np.transpose(img, (2,0,1))img = img.astype('float32')# 将数据范围调整到[-1.0, 1.0]之间img = img / 255.img = img * 2.0 - 1.0return img# 定义训练集数据读取器
def data_loader(datadir, batch_size=10, mode = 'train'):# 将datadir目录下的文件列出来,每条文件都要读入filenames = os.listdir(datadir)def reader():if mode == 'train':# 训练时随机打乱数据顺序random.shuffle(filenames)batch_imgs = []batch_labels = []for name in filenames:filepath = os.path.join(datadir, name)img = cv2.imread(filepath)img = transform_img(img)if name[0] == 'H' or name[0] == 'N':# H开头的文件名表示高度近似,N开头的文件名表示正常视力# 高度近视和正常视力的样本,都不是病理性的,属于负样本,标签为0label = 0elif name[0] == 'P':# P开头的是病理性近视,属于正样本,标签为1label = 1else:raise('Not excepted file name')# 每读取一个样本的数据,就将其放入数据列表中batch_imgs.append(img)batch_labels.append(label)if len(batch_imgs) == batch_size:# 当数据列表的长度等于batch_size的时候,# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出imgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arraybatch_imgs = []batch_labels = []if len(batch_imgs) > 0:# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batchimgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arrayreturn reader# 定义验证集数据读取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):# 训练集读取时通过文件名来确定样本标签,验证集则通过csvfile来读取每个图片对应的标签# 请查看解压后的验证集标签数据,观察csvfile文件里面所包含的内容# csvfile文件所包含的内容格式如下,每一行代表一个样本,# 其中第一列是图片id,第二列是文件名,第三列是图片标签,# 第四列和第五列是Fovea的坐标,与分类任务无关# ID,imgName,Label,Fovea_X,Fovea_Y# 1,V0001.jpg,0,1157.74,1019.87# 2,V0002.jpg,1,1285.82,1080.47# 打开包含验证集标签的csvfile,并读入其中的内容filelists = open(csvfile).readlines()def reader():batch_imgs = []batch_labels = []for line in filelists[1:]:line = line.strip().split(',')name = line[1]label = int(line[2])# 根据图片文件名加载图片,并对图像数据作预处理filepath = os.path.join(datadir, name)img = cv2.imread(filepath)img = transform_img(img)# 每读取一个样本的数据,就将其放入数据列表中batch_imgs.append(img)batch_labels.append(label)if len(batch_imgs) == batch_size:# 当数据列表的长度等于batch_size的时候,# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出imgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arraybatch_imgs = []batch_labels = []if len(batch_imgs) > 0:# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batchimgs_array = np.array(batch_imgs).astype('float32')labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)yield imgs_array, labels_arrayreturn reader# 查看数据形状
DATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
train_loader = data_loader(DATADIR, batch_size=10, mode='train')
data_reader = train_loader()
data = next(data_reader)
data[0].shape, data[1].shapeeval_loader = data_loader(DATADIR, batch_size=10, mode='eval')
data_reader = eval_loader()
data = next(data_reader)
data[0].shape, data[1].shape
((10, 3, 224, 224), (10, 1))
启动训练
# -*- coding: utf-8 -*-# LeNet 识别眼疾图片import os
import random
import paddle
import paddle.fluid as fluid
import numpy as npDATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
DATADIR2 = '/home/aistudio/work/palm/PALM-Validation400'
CSVFILE = '/home/aistudio/labels.csv'# 定义训练过程
def train(model):with fluid.dygraph.guard():print('start training ... ')model.train()epoch_num = 1# 定义优化器opt = fluid.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameter_list=model.parameters())# 定义数据读取器,训练数据读取器和验证数据读取器train_loader = data_loader(DATADIR, batch_size=10, mode='train')valid_loader = valid_data_loader(DATADIR2, CSVFILE)for epoch in range(epoch_num):for batch_id, data in enumerate(train_loader()):x_data, y_data = dataimg = fluid.dygraph.to_variable(x_data)label = fluid.dygraph.to_variable(y_data)# 运行模型前向计算,得到预测值logits = model(img)# 进行loss计算loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label)avg_loss = fluid.layers.mean(loss)if batch_id % 10 == 0:print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))# 反向传播,更新权重,清除梯度avg_loss.backward()opt.minimize(avg_loss)model.clear_gradients()model.eval()accuracies = []losses = []for batch_id, data in enumerate(valid_loader()):x_data, y_data = dataimg = fluid.dygraph.to_variable(x_data)label = fluid.dygraph.to_variable(y_data)# 运行模型前向计算,得到预测值logits = model(img)# 二分类,sigmoid计算后的结果以0.5为阈值分两个类别# 计算sigmoid后的预测概率,进行loss计算pred = fluid.layers.sigmoid(logits)loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label)# 计算预测概率小于0.5的类别pred2 = pred * (-1.0) + 1.0# 得到两个类别的预测概率,并沿第一个维度级联pred = fluid.layers.concat([pred2, pred], axis=1)acc = fluid.layers.accuracy(pred, fluid.layers.cast(label, dtype='int64'))accuracies.append(acc.numpy())losses.append(loss.numpy())print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))model.train()# save params of modelfluid.save_dygraph(model.state_dict(), 'palm')# save optimizer statefluid.save_dygraph(opt.state_dict(), 'palm')# 定义评估过程
def evaluation(model, params_file_path):with fluid.dygraph.guard():print('start evaluation .......')#加载模型参数model_state_dict, _ = fluid.load_dygraph(params_file_path)model.load_dict(model_state_dict)model.eval()eval_loader = data_loader(DATADIR, batch_size=10, mode='eval')acc_set = []avg_loss_set = []for batch_id, data in enumerate(eval_loader()):x_data, y_data = dataimg = fluid.dygraph.to_variable(x_data)label = fluid.dygraph.to_variable(y_data)y_data = y_data.astype(np.int64)label_64 = fluid.dygraph.to_variable(y_data)# 计算预测和精度prediction, acc = model(img, label_64)# 计算损失函数值loss = fluid.layers.sigmoid_cross_entropy_with_logits(prediction, label)avg_loss = fluid.layers.mean(loss)acc_set.append(float(acc.numpy()))avg_loss_set.append(float(avg_loss.numpy()))# 求平均精度acc_val_mean = np.array(acc_set).mean()avg_loss_val_mean = np.array(avg_loss_set).mean()print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))# 导入需要的包
import paddle
import paddle.fluid as fluid
import numpy as np
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear# 定义 LeNet 网络结构
class LeNet(fluid.dygraph.Layer):def __init__(self, num_classes=1):super(LeNet, self).__init__()# 创建卷积和池化层块,每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化self.conv1 = Conv2D(num_channels=3, num_filters=6, filter_size=5, act='sigmoid')self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')self.conv2 = Conv2D(num_channels=6, num_filters=16, filter_size=5, act='sigmoid')self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')# 创建第3个卷积层self.conv3 = Conv2D(num_channels=16, num_filters=120, filter_size=4, act='sigmoid')# 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数self.fc1 = Linear(input_dim=300000, output_dim=64, act='sigmoid')self.fc2 = Linear(input_dim=64, output_dim=num_classes)# 网络的前向计算过程def forward(self, x, label=None):x = self.conv1(x)x = self.pool1(x)x = self.conv2(x)x = self.pool2(x)x = self.conv3(x)x = fluid.layers.reshape(x, [x.shape[0], -1])x = self.fc1(x)x = self.fc2(x)if label is not None:acc = fluid.layers.accuracy(input=x, label=label)return x, accelse:return xif __name__ == '__main__':# 创建模型with fluid.dygraph.guard():model = LeNet(num_classes=1)train(model)# evaluation(model, params_file_path="palm")start training ...
epoch: 0, batch_id: 0, loss is: [0.7796723]
epoch: 0, batch_id: 10, loss is: [0.97510546]
epoch: 0, batch_id: 20, loss is: [0.7067854]
epoch: 0, batch_id: 30, loss is: [0.6935623]
[validation] accuracy/loss: 0.4725000262260437/0.6945831179618835
通过运行结果可以看出,在眼疾筛查数据集iChallenge-PM上,LeNet的loss很难下降,模型没有收敛。这是因为MNIST数据集的图片尺寸比较小( 28 × 28 28\times28 28×28),但是眼疾筛查数据集图片尺寸比较大(原始图片尺寸约为 2000 × 2000 2000 \times 2000 2000×2000,经过缩放之后变成 224 × 224 224 \times 224 224×224),LeNet模型很难进行有效分类。这说明在图片尺寸比较大时,LeNet在图像分类任务上存在局限性。
AlexNet
通过上面的实际训练可以看到,虽然LeNet在手写数字识别数据集上取得了很好的结果,但在更大的数据集上表现却并不好。自从1998年LeNet问世以来,接下来十几年的时间里,神经网络并没有在计算机视觉领域取得很好的结果,反而一度被其它算法所超越。原因主要有两方面,一是神经网络的计算比较复杂,对当时计算机的算力来说,训练神经网络是件非常耗时的事情;另一方面,当时还没有专门针对神经网络做算法和训练技巧的优化,神经网络的收敛是件非常困难的事情。
随着技术的进步和发展,计算机的算力越来越强大,尤其是在GPU并行计算能力的推动下,复杂神经网络的计算也变得更加容易实施。另一方面,互联网上涌现出越来越多的数据,极大的丰富了数据库。同时也有越来越多的研究人员开始专门针对神经网络做算法和模型的优化,Alex Krizhevsky等人提出的AlexNet以很大优势获得了2012年ImageNet比赛的冠军。这一成果极大的激发了产业界对神经网络的兴趣,开创了使用深度神经网络解决图像问题的途径,随后也在这一领域涌现出越来越多的优秀成果。
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
使用Dropout抑制过拟合
使用ReLU激活函数减少梯度消失现象
说明:
下一节详细介绍数据增广的具体实现方式。
AlexNet的具体结构如 图2 所示:
图2:AlexNet模型网络结构示意图
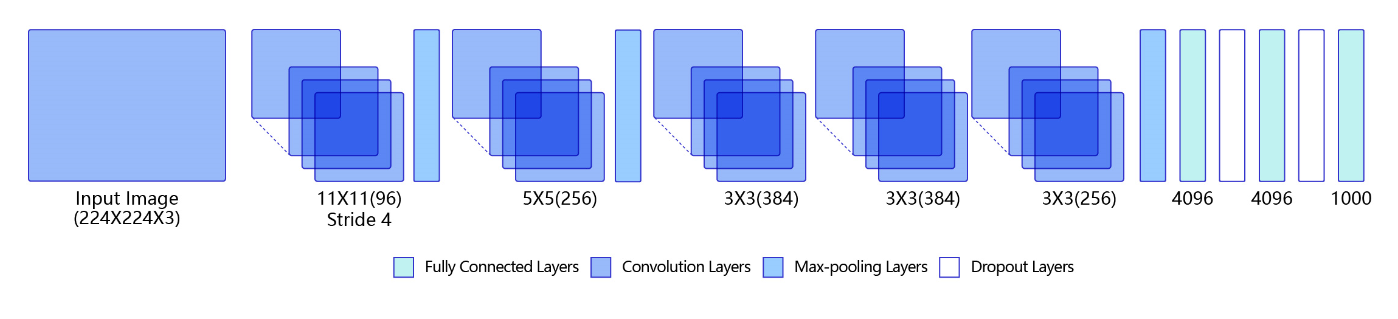
AlexNet在眼疾筛查数据集iChallenge-PM上具体实现的代码如下所示:
# -*- coding:utf-8 -*-# 导入需要的包
import paddle
import paddle.fluid as fluid
import numpy as np
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear# 定义 AlexNet 网络结构
class AlexNet(fluid.dygraph.Layer):def __init__(self, num_classes=1):super(AlexNet, self).__init__()# AlexNet与LeNet一样也会同时使用卷积和池化层提取图像特征# 与LeNet不同的是激活函数换成了‘relu’self.conv1 = Conv2D(num_channels=3, num_filters=96, filter_size=11, stride=4, padding=5, act='relu')self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')self.conv2 = Conv2D(num_channels=96, num_filters=256, filter_size=5, stride=1, padding=2, act='relu')self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')self.conv3 = Conv2D(num_channels=256, num_filters=384, filter_size=3, stride=1, padding=1, act='relu')self.conv4 = Conv2D(num_channels=384, num_filters=384, filter_size=3, stride=1, padding=1, act='relu')self.conv5 = Conv2D(num_channels=384, num_filters=256, filter_size=3, stride=1, padding=1, act='relu')self.pool5 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')self.fc1 = Linear(input_dim=12544, output_dim=4096, act='relu')self.drop_ratio1 = 0.5self.fc2 = Linear(input_dim=4096, output_dim=4096, act='relu')self.drop_ratio2 = 0.5self.fc3 = Linear(input_dim=4096, output_dim=num_classes)def forward(self, x):x = self.conv1(x)x = self.pool1(x)x = self.conv2(x)x = self.pool2(x)x = self.conv3(x)x = self.conv4(x)x = self.conv5(x)x = self.pool5(x)x = fluid.layers.reshape(x, [x.shape[0], -1])x = self.fc1(x)# 在全连接之后使用dropout抑制过拟合x= fluid.layers.dropout(x, self.drop_ratio1)x = self.fc2(x)# 在全连接之后使用dropout抑制过拟合x = fluid.layers.dropout(x, self.drop_ratio2)x = self.fc3(x)return x
with fluid.dygraph.guard():model = AlexNet()train(model)
start training ...
epoch: 0, batch_id: 0, loss is: [0.68645483]
epoch: 0, batch_id: 10, loss is: [0.6189264]
epoch: 0, batch_id: 20, loss is: [0.6271447]
epoch: 0, batch_id: 30, loss is: [0.70667064]
[validation] accuracy/loss: 0.5300000309944153/0.5705490112304688
通过运行结果可以发现,在眼疾筛查数据集iChallenge-PM上使用AlexNet,loss能有效下降,经过5个epoch的训练,在验证集上的准确率可以达到94%左右。
VGG
VGG是当前最流行的CNN模型之一,2014年由Simonyan和Zisserman提出,其命名来源于论文作者所在的实验室Visual Geometry Group。AlexNet模型通过构造多层网络,取得了较好的效果,但是并没有给出深度神经网络设计的方向。VGG通过使用一系列大小为3x3的小尺寸卷积核和池化层构造深度卷积神经网络,并取得了较好的效果。VGG模型因为结构简单、应用性极强而广受研究者欢迎,尤其是它的网络结构设计方法,为构建深度神经网络提供了方向。
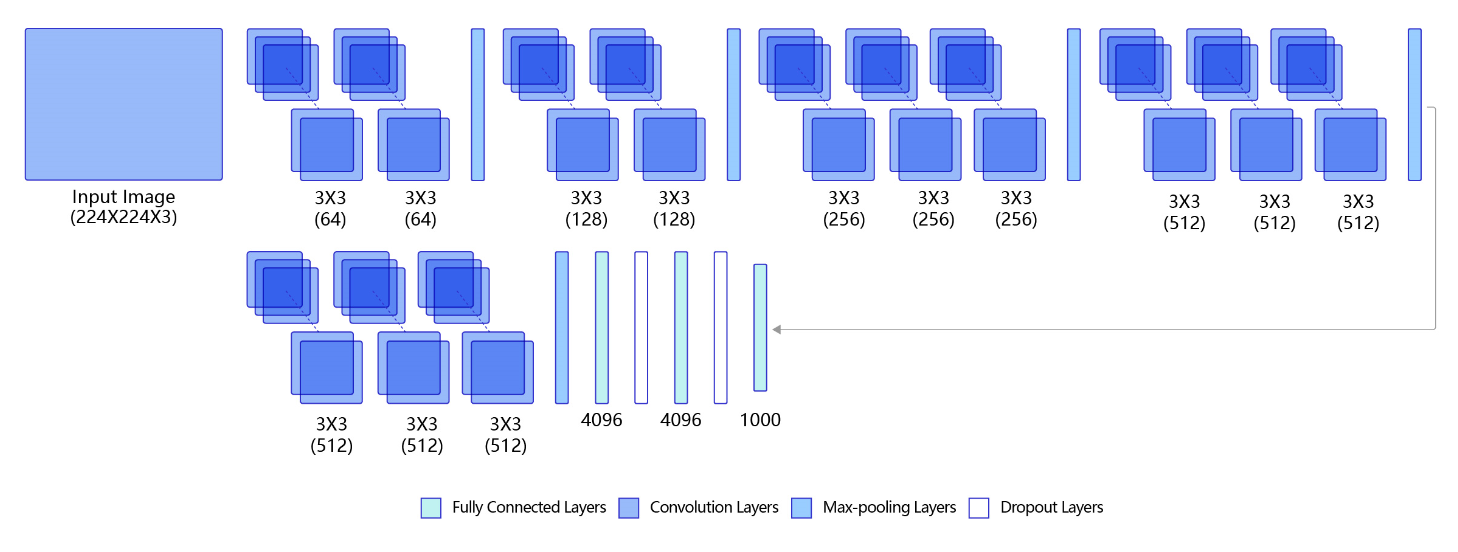
图3 是VGG-16的网络结构示意图,有13层卷积和3层全连接层。VGG网络的设计严格使用 3 × 3 3\times 3 3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。
在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。使用小的卷积核能够有效地减少参数的个数,使得训练和测试变得更加有效。比如使用两层 3 × 3 3\times 3 3×3卷积层,可以得到感受野为5的特征图,而比使用 5 × 5 5 \times 5 5×5的卷积层需要更少的参数。由于卷积核比较小,可以堆叠更多的卷积层,加深网络的深度,这对于图像分类任务来说是有利的。VGG模型的成功证明了增加网络的深度,可以更好的学习图像中的特征模式。
图3:VGG模型网络结构示意图
VGG在眼疾识别数据集iChallenge-PM上的具体实现如下代码所示:
# -*- coding:utf-8 -*-# VGG模型代码
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear
from paddle.fluid.dygraph.base import to_variable# 定义vgg块,包含多层卷积和1层2x2的最大池化层
class vgg_block(fluid.dygraph.Layer):def __init__(self, num_convs, in_channels, out_channels):"""num_convs, 卷积层的数目num_channels, 卷积层的输出通道数,在同一个Incepition块内,卷积层输出通道数是一样的"""super(vgg_block, self).__init__()self.conv_list = []for i in range(num_convs):conv_layer = self.add_sublayer('conv_' + str(i), Conv2D(num_channels=in_channels, num_filters=out_channels, filter_size=3, padding=1, act='relu'))self.conv_list.append(conv_layer)in_channels = out_channelsself.pool = Pool2D(pool_stride=2, pool_size = 2, pool_type='max')def forward(self, x):for item in self.conv_list:x = item(x)return self.pool(x)class VGG(fluid.dygraph.Layer):def __init__(self, conv_arch=((2, 64), (2, 128), (3, 256), (3, 512), (3, 512))):super(VGG, self).__init__()self.vgg_blocks=[]iter_id = 0# 添加vgg_block# 这里一共5个vgg_block,每个block里面的卷积层数目和输出通道数由conv_arch指定in_channels = [3, 64, 128, 256, 512, 512]for (num_convs, num_channels) in conv_arch:block = self.add_sublayer('block_' + str(iter_id), vgg_block(num_convs, in_channels=in_channels[iter_id], out_channels=num_channels))self.vgg_blocks.append(block)iter_id += 1self.fc1 = Linear(input_dim=512*7*7, output_dim=4096,act='relu')self.drop1_ratio = 0.5self.fc2= Linear(input_dim=4096, output_dim=4096,act='relu')self.drop2_ratio = 0.5self.fc3 = Linear(input_dim=4096, output_dim=1)def forward(self, x):for item in self.vgg_blocks:x = item(x)x = fluid.layers.reshape(x, [x.shape[0], -1])x = fluid.layers.dropout(self.fc1(x), self.drop1_ratio)x = fluid.layers.dropout(self.fc2(x), self.drop2_ratio)x = self.fc3(x)return x
with fluid.dygraph.guard():model = VGG()train(model)
start training ...
epoch: 0, batch_id: 0, loss is: [0.62793595]
epoch: 0, batch_id: 10, loss is: [0.75942206]
epoch: 0, batch_id: 20, loss is: [0.6681398]
epoch: 0, batch_id: 30, loss is: [0.7237751]
[validation] accuracy/loss: 0.5450000166893005/0.5371626615524292
通过运行结果可以发现,在眼疾筛查数据集iChallenge-PM上使用VGG,loss能有效的下降,经过5个epoch的训练,在验证集上的准确率可以达到94%左右。
GoogLeNet
GoogLeNet是2014年ImageNet比赛的冠军,它的主要特点是网络不仅有深度,还在横向上具有“宽度”。由于图像信息在空间尺寸上的巨大差异,如何选择合适的卷积核来提取特征就显得比较困难了。空间分布范围更广的图像信息适合用较大的卷积核来提取其特征;而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。为了解决这个问题,GoogLeNet提出了一种被称为Inception模块的方案。如 图4 所示:
说明:
- Google的研究人员为了向LeNet致敬,特地将模型命名为GoogLeNet
- Inception一词来源于电影《盗梦空间》(Inception)
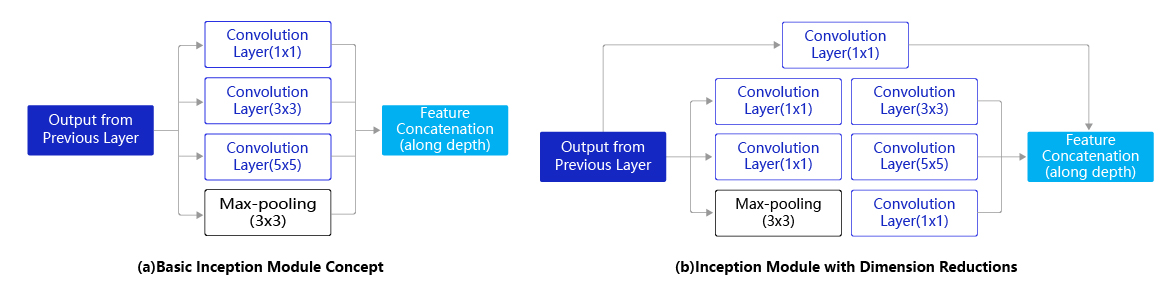
图4:Inception模块结构示意图
图4(a)是Inception模块的设计思想,使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征。Inception模块采用多通路(multi-path)的设计形式,每个支路使用不同大小的卷积核,最终输出特征图的通道数是每个支路输出通道数的总和,这将会导致输出通道数变得很大,尤其是使用多个Inception模块串联操作的时候,模型参数量会变得非常大。为了减小参数量,Inception模块使用了图(b)中的设计方式,在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。基于这一设计思想,形成了上图(b)中所示的结构。下面这段程序是Inception块的具体实现方式,可以对照图(b)和代码一起阅读。
提示:
可能有读者会问,经过3x3的最大池化之后图像尺寸不会减小吗,为什么还能跟另外3个卷积输出的特征图进行拼接?这是因为池化操作可以指定窗口大小 k h = k w = 3 k_h = k_w = 3 kh=kw=3,pool_stride=1和pool_padding=1,输出特征图尺寸可以保持不变。
Inception模块的具体实现如下代码所示:
class Inception(fluid.dygraph.Layer):def __init__(self, c1, c2, c3, c4, **kwargs):'''Inception模块的实现代码,c1, 图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数c2,图(b)中第二条支路卷积的输出通道数,数据类型是tuple或list, 其中c2[0]是1x1卷积的输出通道数,c2[1]是3x3c3,图(b)中第三条支路卷积的输出通道数,数据类型是tuple或list, 其中c3[0]是1x1卷积的输出通道数,c3[1]是3x3c4, 图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数'''super(Inception, self).__init__()# 依次创建Inception块每条支路上使用到的操作self.p1_1 = Conv2D(num_filters=c1, filter_size=1, act='relu')self.p2_1 = Conv2D(num_filters=c2[0], filter_size=1, act='relu')self.p2_2 = Conv2D(num_filters=c2[1], filter_size=3, padding=1, act='relu')self.p3_1 = Conv2D(num_filters=c3[0], filter_size=1, act='relu')self.p3_2 = Conv2D(num_filters=c3[1], filter_size=5, padding=2, act='relu')self.p4_1 = Pool2D(pool_size=3, pool_stride=1, pool_padding=1, pool_type='max')self.p4_2 = Conv2D(num_filters=c4, filter_size=1, act='relu')def forward(self, x):# 支路1只包含一个1x1卷积p1 = self.p1_1(x)# 支路2包含 1x1卷积 + 3x3卷积p2 = self.p2_2(self.p2_1(x))# 支路3包含 1x1卷积 + 5x5卷积p3 = self.p3_2(self.p3_1(x))# 支路4包含 最大池化和1x1卷积p4 = self.p4_2(self.p4_1(x))# 将每个支路的输出特征图拼接在一起作为最终的输出结果return fluid.layers.concat([p1, p2, p3, p4], axis=1)
GoogLeNet的架构如 图5 所示,在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3 ×3最大池化层来减小输出高宽。
- 第一模块使用一个64通道的7 × 7卷积层。
- 第二模块使用2个卷积层:首先是64通道的1 × 1卷积层,然后是将通道增大3倍的3 × 3卷积层。
- 第三模块串联2个完整的Inception块。
- 第四模块串联了5个Inception块。
- 第五模块串联了2 个Inception块。
- 第五模块的后面紧跟输出层,使用全局平均池化层来将每个通道的高和宽变成1,最后接上一个输出个数为标签类别数的全连接层。
说明:
在原作者的论文中添加了图中所示的softmax1和softmax2两个辅助分类器,如下图所示,训练时将三个分类器的损失函数进行加权求和,以缓解梯度消失现象。这里的程序作了简化,没有加入辅助分类器。
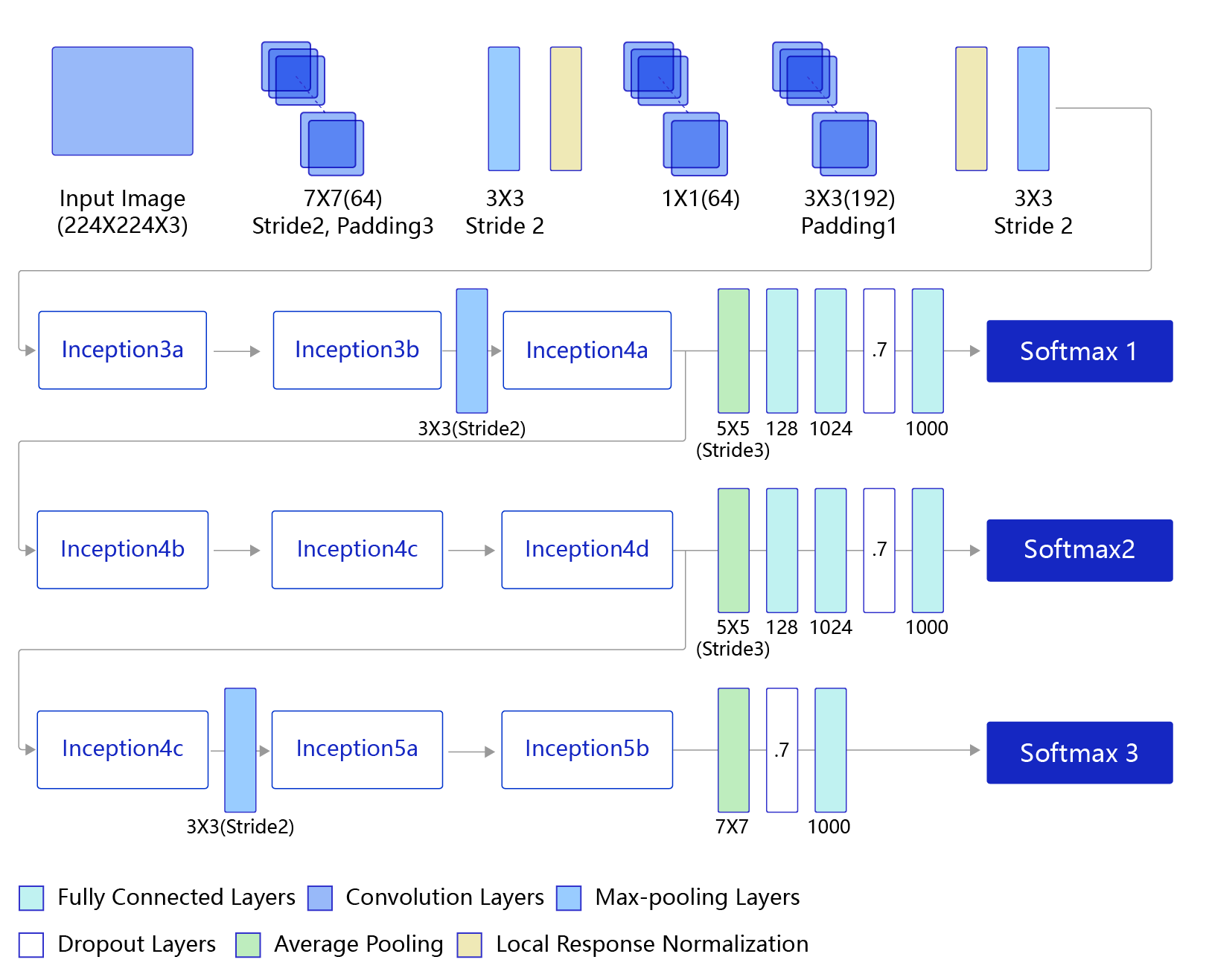
图5:GoogLeNet模型网络结构示意图
GoogLeNet的具体实现如下代码所示:
# -*- coding:utf-8 -*-# GoogLeNet模型代码
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear
from paddle.fluid.dygraph.base import to_variable# 定义Inception块
class Inception(fluid.dygraph.Layer):def __init__(self, c0,c1, c2, c3, c4, **kwargs):'''Inception模块的实现代码,c1, 图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数c2,图(b)中第二条支路卷积的输出通道数,数据类型是tuple或list, 其中c2[0]是1x1卷积的输出通道数,c2[1]是3x3c3,图(b)中第三条支路卷积的输出通道数,数据类型是tuple或list, 其中c3[0]是1x1卷积的输出通道数,c3[1]是3x3c4, 图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数'''super(Inception, self).__init__()# 依次创建Inception块每条支路上使用到的操作self.p1_1 = Conv2D(num_channels=c0, num_filters=c1, filter_size=1, act='relu')self.p2_1 = Conv2D(num_channels=c0, num_filters=c2[0], filter_size=1, act='relu')self.p2_2 = Conv2D(num_channels=c2[0], num_filters=c2[1], filter_size=3, padding=1, act='relu')self.p3_1 = Conv2D(num_channels=c0, num_filters=c3[0], filter_size=1, act='relu')self.p3_2 = Conv2D(num_channels=c3[0], num_filters=c3[1], filter_size=5, padding=2, act='relu')self.p4_1 = Pool2D(pool_size=3, pool_stride=1, pool_padding=1, pool_type='max')self.p4_2 = Conv2D(num_channels=c0, num_filters=c4, filter_size=1, act='relu')def forward(self, x):# 支路1只包含一个1x1卷积p1 = self.p1_1(x)# 支路2包含 1x1卷积 + 3x3卷积p2 = self.p2_2(self.p2_1(x))# 支路3包含 1x1卷积 + 5x5卷积p3 = self.p3_2(self.p3_1(x))# 支路4包含 最大池化和1x1卷积p4 = self.p4_2(self.p4_1(x))# 将每个支路的输出特征图拼接在一起作为最终的输出结果return fluid.layers.concat([p1, p2, p3, p4], axis=1) class GoogLeNet(fluid.dygraph.Layer):def __init__(self):super(GoogLeNet, self).__init__()# GoogLeNet包含五个模块,每个模块后面紧跟一个池化层# 第一个模块包含1个卷积层self.conv1 = Conv2D(num_channels=3, num_filters=64, filter_size=7, padding=3, act='relu')# 3x3最大池化self.pool1 = Pool2D(pool_size=3, pool_stride=2, pool_padding=1, pool_type='max')# 第二个模块包含2个卷积层self.conv2_1 = Conv2D(num_channels=64, num_filters=64, filter_size=1, act='relu')self.conv2_2 = Conv2D(num_channels=64, num_filters=192, filter_size=3, padding=1, act='relu')# 3x3最大池化self.pool2 = Pool2D(pool_size=3, pool_stride=2, pool_padding=1, pool_type='max')# 第三个模块包含2个Inception块self.block3_1 = Inception(192, 64, (96, 128), (16, 32), 32)self.block3_2 = Inception(256, 128, (128, 192), (32, 96), 64)# 3x3最大池化self.pool3 = Pool2D(pool_size=3, pool_stride=2, pool_padding=1, pool_type='max')# 第四个模块包含5个Inception块self.block4_1 = Inception(480, 192, (96, 208), (16, 48), 64)self.block4_2 = Inception(512, 160, (112, 224), (24, 64), 64)self.block4_3 = Inception(512, 128, (128, 256), (24, 64), 64)self.block4_4 = Inception(512, 112, (144, 288), (32, 64), 64)self.block4_5 = Inception(528, 256, (160, 320), (32, 128), 128)# 3x3最大池化self.pool4 = Pool2D(pool_size=3, pool_stride=2, pool_padding=1, pool_type='max')# 第五个模块包含2个Inception块self.block5_1 = Inception(832, 256, (160, 320), (32, 128), 128)self.block5_2 = Inception(832, 384, (192, 384), (48, 128), 128)# 全局池化,尺寸用的是global_pooling,pool_stride不起作用self.pool5 = Pool2D(pool_stride=1, global_pooling=True, pool_type='avg')self.fc = Linear(input_dim=1024, output_dim=1, act=None)def forward(self, x):x = self.pool1(self.conv1(x))x = self.pool2(self.conv2_2(self.conv2_1(x)))x = self.pool3(self.block3_2(self.block3_1(x)))x = self.block4_3(self.block4_2(self.block4_1(x)))x = self.pool4(self.block4_5(self.block4_4(x)))x = self.pool5(self.block5_2(self.block5_1(x)))x = fluid.layers.reshape(x, [x.shape[0], -1])x = self.fc(x)return xwith fluid.dygraph.guard():model = GoogLeNet()train(model)
start training ...
epoch: 0, batch_id: 0, loss is: [0.80774987]
epoch: 0, batch_id: 10, loss is: [0.4686487]
epoch: 0, batch_id: 20, loss is: [0.70196533]
epoch: 0, batch_id: 30, loss is: [0.69787705]
[validation] accuracy/loss: 0.6899999380111694/0.6595117449760437
通过运行结果可以发现,使用GoogLeNet在眼疾筛查数据集iChallenge-PM上,loss能有效的下降,经过5个epoch的训练,在验证集上的准确率可以达到95%左右。
ResNet
ResNet是2015年ImageNet比赛的冠军,将识别错误率降低到了3.6%,这个结果甚至超出了正常人眼识别的精度。
通过前面几个经典模型学习,我们可以发现随着深度学习的不断发展,模型的层数越来越多,网络结构也越来越复杂。那么是否加深网络结构,就一定会得到更好的效果呢?从理论上来说,假设新增加的层都是恒等映射,只要原有的层学出跟原模型一样的参数,那么深模型结构就能达到原模型结构的效果。换句话说,原模型的解只是新模型的解的子空间,在新模型解的空间里应该能找到比原模型解对应的子空间更好的结果。但是实践表明,增加网络的层数之后,训练误差往往不降反升。
Kaiming He等人提出了残差网络ResNet来解决上述问题,其基本思想如 图6所示。
- 图6(a):表示增加网络的时候,将 x x x映射成 y = F ( x ) y=F(x) y=F(x)输出。
- 图6(b):对图6(a)作了改进,输出 y = F ( x ) + x y=F(x) + x y=F(x)+x。这时不是直接学习输出特征 y y y的表示,而是学习 y − x y-x y−x。
- 如果想学习出原模型的表示,只需将 F ( x ) F(x) F(x)的参数全部设置为0,则 y = x y=x y=x是恒等映射。
- F ( x ) = y − x F(x) = y - x F(x)=y−x也叫做残差项,如果 x → y x\rightarrow y x→y的映射接近恒等映射,图6(b)中通过学习残差项也比图6(a)学习完整映射形式更加容易。
图6:残差块设计思想
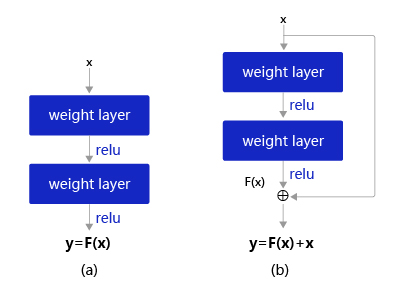
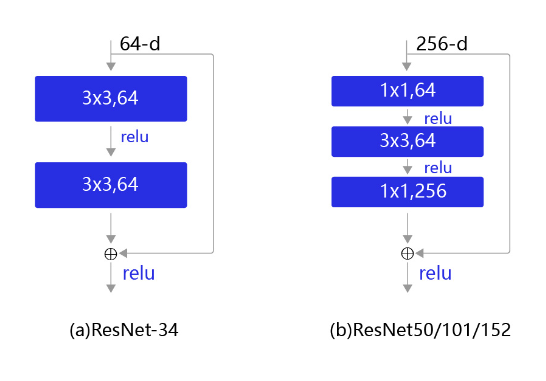
图6(b)的结构是残差网络的基础,这种结构也叫做残差块(Residual block)。输入 x x x通过跨层连接,能更快的向前传播数据,或者向后传播梯度。残差块的具体设计方案如 图7 所示,这种设计方案也成称作瓶颈结构(BottleNeck)。
图7:残差块结构示意图
下图表示出了ResNet-50的结构,一共包含49层卷积和1层全连接,所以被称为ResNet-50。
图8:ResNet-50模型网络结构示意图

ResNet-50的具体实现如下代码所示:
# -*- coding:utf-8 -*-# ResNet模型代码
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear
from paddle.fluid.dygraph.base import to_variable# ResNet中使用了BatchNorm层,在卷积层的后面加上BatchNorm以提升数值稳定性
# 定义卷积批归一化块
class ConvBNLayer(fluid.dygraph.Layer):def __init__(self,num_channels,num_filters,filter_size,stride=1,groups=1,act=None):"""num_channels, 卷积层的输入通道数num_filters, 卷积层的输出通道数stride, 卷积层的步幅groups, 分组卷积的组数,默认groups=1不使用分组卷积act, 激活函数类型,默认act=None不使用激活函数"""super(ConvBNLayer, self).__init__()# 创建卷积层self._conv = Conv2D(num_channels=num_channels,num_filters=num_filters,filter_size=filter_size,stride=stride,padding=(filter_size - 1) // 2,groups=groups,act=None,bias_attr=False)# 创建BatchNorm层self._batch_norm = BatchNorm(num_filters, act=act)def forward(self, inputs):y = self._conv(inputs)y = self._batch_norm(y)return y# 定义残差块
# 每个残差块会对输入图片做三次卷积,然后跟输入图片进行短接
# 如果残差块中第三次卷积输出特征图的形状与输入不一致,则对输入图片做1x1卷积,将其输出形状调整成一致
class BottleneckBlock(fluid.dygraph.Layer):def __init__(self,num_channels,num_filters,stride,shortcut=True):super(BottleneckBlock, self).__init__()# 创建第一个卷积层 1x1self.conv0 = ConvBNLayer(num_channels=num_channels,num_filters=num_filters,filter_size=1,act='relu')# 创建第二个卷积层 3x3self.conv1 = ConvBNLayer(num_channels=num_filters,num_filters=num_filters,filter_size=3,stride=stride,act='relu')# 创建第三个卷积 1x1,但输出通道数乘以4self.conv2 = ConvBNLayer(num_channels=num_filters,num_filters=num_filters * 4,filter_size=1,act=None)# 如果conv2的输出跟此残差块的输入数据形状一致,则shortcut=True# 否则shortcut = False,添加1个1x1的卷积作用在输入数据上,使其形状变成跟conv2一致if not shortcut:self.short = ConvBNLayer(num_channels=num_channels,num_filters=num_filters * 4,filter_size=1,stride=stride)self.shortcut = shortcutself._num_channels_out = num_filters * 4def forward(self, inputs):y = self.conv0(inputs)conv1 = self.conv1(y)conv2 = self.conv2(conv1)# 如果shortcut=True,直接将inputs跟conv2的输出相加# 否则需要对inputs进行一次卷积,将形状调整成跟conv2输出一致if self.shortcut:short = inputselse:short = self.short(inputs)y = fluid.layers.elementwise_add(x=short, y=conv2, act='relu')return y# 定义ResNet模型
class ResNet(fluid.dygraph.Layer):def __init__(self, layers=50, class_dim=1):"""layers, 网络层数,可以是50, 101或者152class_dim,分类标签的类别数"""super(ResNet, self).__init__()self.layers = layerssupported_layers = [50, 101, 152]assert layers in supported_layers, \"supported layers are {} but input layer is {}".format(supported_layers, layers)if layers == 50:#ResNet50包含多个模块,其中第2到第5个模块分别包含3、4、6、3个残差块depth = [3, 4, 6, 3]elif layers == 101:#ResNet101包含多个模块,其中第2到第5个模块分别包含3、4、23、3个残差块depth = [3, 4, 23, 3]elif layers == 152:#ResNet50包含多个模块,其中第2到第5个模块分别包含3、8、36、3个残差块depth = [3, 8, 36, 3]# 残差块中使用到的卷积的输出通道数num_filters = [64, 128, 256, 512]# ResNet的第一个模块,包含1个7x7卷积,后面跟着1个最大池化层self.conv = ConvBNLayer(num_channels=3,num_filters=64,filter_size=7,stride=2,act='relu')self.pool2d_max = Pool2D(pool_size=3,pool_stride=2,pool_padding=1,pool_type='max')# ResNet的第二到第五个模块c2、c3、c4、c5self.bottleneck_block_list = []num_channels = 64for block in range(len(depth)):shortcut = Falsefor i in range(depth[block]):bottleneck_block = self.add_sublayer('bb_%d_%d' % (block, i),BottleneckBlock(num_channels=num_channels,num_filters=num_filters[block],stride=2 if i == 0 and block != 0 else 1, # c3、c4、c5将会在第一个残差块使用stride=2;其余所有残差块stride=1shortcut=shortcut))num_channels = bottleneck_block._num_channels_outself.bottleneck_block_list.append(bottleneck_block)shortcut = True# 在c5的输出特征图上使用全局池化self.pool2d_avg = Pool2D(pool_size=7, pool_type='avg', global_pooling=True)# stdv用来作为全连接层随机初始化参数的方差import mathstdv = 1.0 / math.sqrt(2048 * 1.0)# 创建全连接层,输出大小为类别数目self.out = Linear(input_dim=2048, output_dim=class_dim,param_attr=fluid.param_attr.ParamAttr(initializer=fluid.initializer.Uniform(-stdv, stdv)))def forward(self, inputs):y = self.conv(inputs)y = self.pool2d_max(y)for bottleneck_block in self.bottleneck_block_list:y = bottleneck_block(y)y = self.pool2d_avg(y)y = fluid.layers.reshape(y, [y.shape[0], -1])y = self.out(y)return ywith fluid.dygraph.guard():model = ResNet()train(model)
start training ...
通过运行结果可以发现,使用ResNet在眼疾筛查数据集iChallenge-PM上,loss能有效的下降,经过5个epoch的训练,在验证集上的准确率可以达到95%左右。
小结
在这一节里,给读者介绍了几种经典的图像分类模型,分别是LeNet, AlexNet, VGG, GoogLeNet和ResNet,并将它们应用到眼疾筛查数据集上。除了LeNet不适合大尺寸的图像分类问题之外,其它几个模型在此数据集上损失函数都能显著下降,在验证集上的预测精度在90%左右。如果读者有兴趣的话,可以进一步调整学习率和训练轮数等超参数,观察是否能够得到更高的精度。
参考文献
[1] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learn- ing applied to document recognition. Proc. of the IEEE, 86(11):2278–2324, 1998
[2] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, pages 1097–1105, 2012.
[3] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014b.
[4]Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolu- tions. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015.
[5] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016a.
Ai Studio零基础学习心得相关推荐
- 零基础学习MSP430F552LP开发板,学习前期准备,Code Composer Studio(CCS)软件的安装
零基础学习MSP430F552LP开发板 一.前言 零基础学习MSP430F552LP开发板,为电子设计竞赛做准备以及学好这一款芯片. 在选择比赛题目时,发现有的题目时规定使用ti的芯片作为控制MCU ...
- 零基础学习Java培训有什么攻略
零基础学习Java培训有什么攻略?java是主流编程语言之一,我们在学习Java的时候需要制定Java学习路线图,Java涉及到的知识点非常的多,我们该从何学起呢?怎么系统的学习呢?来看看下面的详细介 ...
- 零基础自学python的建议-关于零基础学习 Python 有什么好的建议?
Python这种高级编程语言,相比前编程明星C++和Java等更简单易操作.,目前Python已成为最受AI从业者欢迎的语言. Python的10个基础知识点 Python是一个面向对象的解释型的交互 ...
- 【Python基础】零基础学习Python列表操作
作者:来自读者投稿 整理:Lemon 出品:Python数据之道 " 「Python数据之道」导读:本文来自读者投稿,Python数据之道早些时候也发过 Python 列表相关的文章,可以前 ...
- 零基础学习资料(建议收藏)
本次整理分享的是一些零基础学习的资料,网盘资料建议大家收藏,分享永久有效,如果后续做调整删除文件的话可能会提示分享不存在,此次的分享针对没有基础从头学的小伙伴们比较友好些,有需要的赶紧收藏起来吧 「零 ...
- 沉睡者IT:零基础学习短视频与+玩转抖音快手
零基础学习短视频与+玩转抖音快手 一.正常活跃账号 新号前期别刷粉.别刷赞.别刷任何量,千万别刷!养成一个良好的习惯,去观看作品, 把内容好的作品点赞收藏评论. 权重 权重是一个内在的数值,查看方式是 ...
- 2022最新网络安全零基础学习路线
前 言 写这篇文章的初衷是很多朋友都想了解如何入门/转行网络安全,实现自己的"黑客梦".文章的宗旨是: 1.指出一些自学的误区 2.提供客观可行的学习表 3.推荐我认为适合小白学习 ...
- 零基础学习深度学习_深度学习的基础!!!
零基础学习深度学习 The ability to learn from experience and perform better when confronted with similar chall ...
- 教你如何零基础学习视频剪辑,干货满满
5000字长文预警!!! 软件推荐+专业术语解析+视频素材网站分享 教你如何零基础学习视频剪辑,干货满满 那么在推荐视频剪辑软件之前,首先你应该明确自己的制作视频的目的. 是想成为专业剪辑师,从事专业 ...
最新文章
- Python编程基础:第五十八节 线程Threading
- Error Code: 1052. Column '列名' in where clause is ambiguous
- 细数你不得不知的容器安全工具
- http的302,303和307
- 传新一轮估值200亿美金 小红书回应:以老股东增持为主
- MSSQL 'CREATE/ALTER PROCEDURE' 必须是查询批次中的第一个语句。
- 自定义_Excel中的自定义函数(自定义函数的基础内容)
- JS性能优化 之 FOR循环
- C# 中的 ConfigurationManager类引用方法应用程序配置文件App.config的写法
- 杰控连接mysql_杰控FameView组态软件在数据库连接和查询方面的应用
- 手写汉字识别程序开发
- 远程访问服务器上的Jupyterlab
- 一页中关村 · 当百度碰见丧尸
- Kylin Error:Cannot start job scheduler due to lack of job lock
- 计算机网络安装,计算机网络系统安装操作指南.pdf
- iOS UIFont 字体名字大全
- 分布式秒杀电商-微服务架构图 上帝视角分析
- Python编程快速上手让繁琐工作自动化中文高清完整版PDF带书签
- carplay是否可以用安卓系统_苹果CarPlay系统是什么?安卓系统手机能用吗?
- 达梦数据文件误删了恢复