嵌入式系统分类及其应用场景_词嵌入及其应用简介
嵌入式系统分类及其应用场景
Before I give you an introduction on Word Embeddings, take a look at the following examples and ask yourself what is common between them:
在向您介绍Word Embeddings之前,请看一下以下示例并问问自己它们之间的共同点是什么:
- Using customer reviews or employee survey responses to understand sentiments towards a particular product or company.
使用客户评论或员工调查回复来了解对特定产品或公司的看法。 - Using lyrics of songs you liked to recommend songs that are similar in contextual meaning.
您喜欢使用歌曲的歌词来推荐上下文含义相似的歌曲。 - Using a web translation service, like Google Translate, to convert webpage articles seamlessly to a different language.
使用Google翻译之类的网络翻译服务将网页文章无缝地转换为另一种语言。
You have probably guessed this right. All of these applications deal with large amounts of Text. Now obviously it’s a waste of resources to spend manual labor in these applications which have millions of sentences or documents containing text.
您可能已经猜对了。 所有这些应用程序都处理大量的Text 。 现在,显然,在具有数百万个包含文本的句子或文档的应用程序中花费体力劳动是浪费资源。
So what can we do now? We could feed this to Machine Learning and Deep Learning models and let them learn and figure out these applications. But most of these models can’t be fed textual data since they can’t interpret it in a human sense. Generally, they require numerical representations to perform any task. This is where Word Embeddings comes into use.
那么,我们现在该怎么办? 我们可以将其提供给机器学习和深度学习模型,让他们学习并找出这些应用程序。 但是,这些模型中的大多数不能提供文本数据,因为它们无法以人类的方式进行解释。 通常,它们需要数字表示形式才能执行任何任务。 这就是Word Embeddings启用的地方。
In this article we are going to address the following:
在本文中,我们将解决以下问题:
- What are Word Embeddings?
什么是词嵌入? - Why exactly do we prefer Word Embeddings?
为什么我们确切地偏爱词嵌入? - What are the different types of Word Embeddings?
单词嵌入有哪些不同类型? - What are their Applications?
它们的用途是什么?
什么是词嵌入? (What are Word Embeddings?)
Word Embeddings are a numerical vector representation of the text in the corpus that maps each word in the corpus vocabulary to a set of real valued vectors in a pre-defined N-dimensional space.
词嵌入是语料库中文本的数字矢量表示,它将语料库词汇表中的每个单词映射到预定义的N维空间中的一组实值向量。
These real valued vector-representation for each word in the corpus vocabulary are learned through supervised techniques such as neural network models trained on tasks such as sentiment analysis and document classification or through unsupervised techniques such as statistical analysis of documents.
语料库词汇表中每个单词的这些实值向量表示法是通过监督技术(例如对诸如情感分析和文档分类等任务训练的神经网络模型) 或通过诸如文献统计分析之类的无监督技术来学习的 。
The Word Embeddings try to capture the semantic, contextual and syntactic meaning of each word in the corpus vocabulary based on the usage of these words in sentences. Words that have similar semantic and contextual meaning also have similar vector representations while at the same time each word in the vocabulary will have a unique set of vector representation.
单词嵌入尝试根据句子中这些单词的用法来捕获语料库词汇中每个单词的语义,上下文和句法含义。 具有相似语义和上下文含义的单词也具有相似的矢量表示形式,同时词汇表中的每个单词将具有一组唯一的矢量表示形式。

The above image displays examples of words in vocabulary having similar contextual, semantic and syntactic meaning to be mapped in a 3-Dimensional Vector Space. In the above picture example of Verb Tense, we can observe that vector differences between word pairs: (walking & walked) and (swimming & swam) is roughly equal.
上图显示了词汇中具有相似上下文,语义和句法含义的单词的示例,这些单词要映射到3维向量空间中。 在上面的动词时态图片示例中,我们可以观察到单词对之间的向量差:( 行走和行走)和( 游泳和游泳)大致相等。
为什么我们确切地偏爱词嵌入? (Why exactly do we prefer Word Embeddings?)
Certain questions might have popped into your mind by now.
某些问题可能现在已经浮现在您的脑海。
- What is the simplest way to represent words numerically and why isn’t that sufficient?
用数字表示单词的最简单方法是什么,为什么还不够? - If Word Embeddings are so complex, why do we prefer them to simpler methods?
如果词嵌入是如此复杂,为什么我们更喜欢它们而不是简单的方法?
Lets address these questions one by one.
让我们一个接一个地解决这些问题。
用数字表示单词的最简单方法是什么,为什么还不够? (What is the simplest way to represent words numerically and why isn’t that sufficient?)
The simplest ways to represent words numerically is to One-Hot-Encode unique word in a corpus of text. We can understand this better with an example. Suppose my corpus has only two documents:
用数字表示单词的最简单方法是对文本语料库中的唯一单词进行一次热编码 。 我们可以通过一个例子更好地理解这一点。 假设我的语料库只有两个文档:
* The King takes his Queen for dinner.* The husband takes his wife for dinner.
* 国王带女王用餐。 * 丈夫带妻子吃饭。
You might notice that these two documents have the same contextual meaning. When we apply one hot encoding to the documents, here’s what happens:
您可能会注意到,这两个文档具有相同的上下文含义。 当我们对文档应用一种热编码时,会发生以下情况:
We first construct an exhaustive vocabulary — {“The”, “King”, “husband”, “takes”, “his”, “Queen”, “wife”, “for”, “dinner”}. There are nine unique words in the document text, so each word will be represented as a vector with a length of 9. The vector will consist a "1" that corresponds to the position of the word in the vocabulary with a "0" everywhere else. Here is what those vectors look like:
文档文本中有9个唯一的单词,因此每个单词将被表示为一个长度为9的向量。该向量将包含一个“ 1”,该词与单词在词汇表中的位置相对应,并且到处都是“ 0”其他。 这些向量如下所示:
The - [1,0,0,0,0,0,0,0,0]King - [0,1,0,0,0,0,0,0,0] husband - [0,0,1,0,0,0,0,0,0]takes - [0,0,0,1,0,0,0,0,0] his - [0,0,0,0,1,0,0,0,0] Queen - [0,0,0,0,0,1,0,0,0]wife - [0,0,0,0,0,0,1,0,0] for - [0,0,0,0,0,0,0,1,0] dinner - [0,0,0,0,0,0,0,0,1]Lets address some disadvantages of this method.
让我们解决这种方法的一些缺点。
1. Scalability Issue- The above example contained only 2 sentences and only 9 words in vocabulary. But in a real-world scenario, we will have millions of sentences and millions of words in vocabulary. You can imagine how the dimensions of one-hot-encoded vectors for each word will explode in millions. This will lead to scalability issues when it is fed to our models, and in turn will lead to inefficiency in time and computational resources.
1. 可伸缩性问题 -上面的示例仅包含2个句子和9个单词。 但是在现实世界中,我们的词汇中将有数百万个句子和数百万个单词。 您可以想象每个单词的一键编码矢量的维数将爆炸成百万。 当将其提供给我们的模型时,这将导致可伸缩性问题,进而导致时间和计算资源的效率低下。
2. Sparsity Issue- Given that we will have 0’s everywhere except for single 1 at the correct location, the models have a very hard time learning this data, therefore your model may not generalize well over the test data.
2. 稀疏性问题-假设除了正确的单个1之外,到处都是0,因此模型很难学习此数据,因此您的模型可能无法很好地概括测试数据。
3. No Context Captured- Since one-hot-encoding blindly creates vectors without taking into account the shared dependencies and context in which each word of vocabulary lies, we lose the contextual and semantic information. In our example, that means that we lose context between similar word pairs — “king” and “queen” are similar to “husband” and “wife”.
3. 没有捕获上下文-由于单次热编码盲目地创建矢量,而没有考虑每个词汇所处的共享依赖关系和上下文,因此我们丢失了上下文和语义信息。 在我们的示例中,这意味着我们在相似的单词对之间失去了上下文- “国王”和“女王”类似于“丈夫”和“妻子” 。
如果词嵌入非常复杂,为什么我们更喜欢它们而不是简单的方法? (If Word Embeddings are so complex, why do we prefer them to simpler methods?)
There are many other simpler methods than Word Embeddings, such as Term-Frequency Matrix, TF-IDF Matrix and Co-occurrence Matrix. But even these methods face one or more issues in terms of scalability, sparsity and contextual dependency.
除了词嵌入以外,还有许多其他更简单的方法,例如术语频率矩阵,TF-IDF矩阵和共现矩阵。 但是,即使这些方法在可伸缩性,稀疏性和上下文相关性方面也面临一个或多个问题。
Therefore, we prefer Word Embeddings since it resolves all the issues mentioned above. The embeddings maps each word to a N-Dimensional space where N ranges from 50–1000 in contrast to a Million-Dimensional Space. Thus we resolve scalability issues. Since each vector in the embeddings is densely populated in contrast to a vector containing 0’s everywhere, we have also resolved the sparsity issues. Thus the model can now learn better and generalize well. Finally, these vectors are learned in a way that captures the shared context and dependencies among the words.
因此,我们更喜欢Word Embeddings,因为它可以解决上述所有问题。 嵌入将每个单词映射到一个N维空间,其中N与50维空间相比,N的范围是50-1000。 因此,我们解决了可伸缩性问题。 与每个位置都包含0的向量相比,嵌入中的每个向量都被密集地填充,因此我们也解决了稀疏性问题。 因此,该模型现在可以更好地学习并且可以很好地概括。 最后,以捕获单词之间共享上下文和依存关系的方式学习这些向量。
不同类型的单词嵌入 (Different Types of Word Embeddings)
In this section, we will be reviewing the following State-Of-The-Art (SOTA) Word Embeddings:
在本节中,我们将审阅以下最新技术(SOTA)词嵌入:
- Word2Vec
Word2Vec - Glove
手套 - ELMo
艾莫
This is not an exhaustive list, but a great place to start with. There are many other SOTA Word Embeddings such as Bert (developed by Jacob Devlin at Google) and GPT (developed at OpenAI) that have also made advanced breakthroughs in NLP applications.
这不是一个详尽的清单,而是一个很好的起点。 还有许多其他的SOTA单词嵌入,例如Bert (由Google的Jacob Devlin开发)和GPT (由OpenAI开发)在NLP应用中也取得了先进的突破。
Word2Vec (Word2Vec)
Word2Vec is an algorithm developed by Tomas Mikolov, et al. at Google in 2013. The algorithm was built on the idea of the distributional hypothesis. The distributional hypothesis suggests that words occurring in similar linguistic contexts will also have similar semantic meaning. Word2Vec uses this concept to map words having similar semantic meaning geometrically close to each other in a N-Dimensional vector space.
Word2Vec是Tomas Mikolov等人开发的算法。 该算法于2013年在Google提出。该算法基于分布假设的思想。 分布假设表明,在相似的语言环境中出现的单词也将具有相似的语义。 Word2Vec使用此概念将具有相似语义的单词映射到N维向量空间中彼此几何接近的单词。
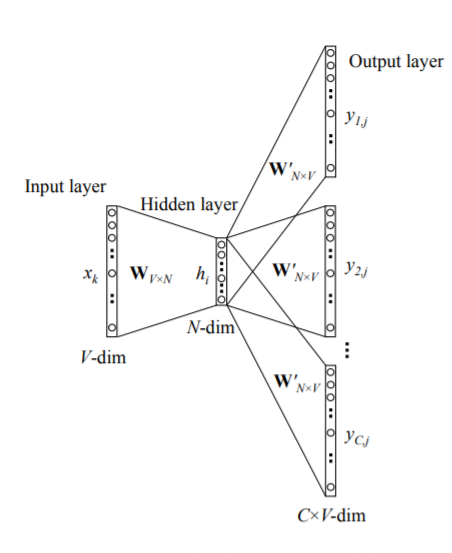
Word2Vec uses the approach of training a group of shallow, 2-layer neural networks to reconstruct the linguistic context of words. It takes in a large corpus of text as an input and produces a vector space with dimensions in the order of hundreds. Each unique word in the corpus vocabulary is assigned a unique corresponding vector in the space.
Word2Vec使用训练一组浅的两层神经网络的方法来重建单词的语言环境。 它以大量的文本集作为输入,并产生尺寸为数百个的向量空间。 语料库词汇表中的每个唯一单词在空间中分配有一个唯一的对应向量。
It can be implemented using either of the two techniques: Common Bag of Words(CBOW) or Skip Gram.
可以使用以下两种技术之一来实现它: 通用单词袋(CBOW)或跳过 语法 。
a) Common Bag of WordsThis technique uses the shallow 2-layer neural network to predict the probability of a word given the context. A context can be a single word or a group of words. The following diagram illustrates the concept:
a) 常用单词袋该技术使用浅层2层神经网络预测给定上下文的单词概率。 上下文可以是单个单词或一组单词。 下图说明了该概念:

The input will be the context of words each of them being one-hot-encoded and fed to the network and the output is the probability distributions of each word in the vocabulary.
输入将是单词的上下文,每个单词都经过一次热编码并馈送到网络,输出是单词中每个单词的概率分布。
b) Skip GramThe skip gram is the flipped version of CBOW. We feed the model a single word and the model tries to predict the words surrounding it. The input is the one-hot-encoded vector of the word and the output is a series of probability distributions of each word in the vocabulary. For example, “I am going for a walk”.
b) 跳越克跳过克是CBOW的翻转形式。 我们给模型一个单词,模型试图预测周围的单词。 输入是单词的单次编码矢量,输出是词汇中每个单词的一系列概率分布。 例如, “我要去散步”。
The vocabulary is — [“I”, “am”, “going”, “for”, “a”, “walk”]. Length of Vocabulary V=6 For setting the number of surrounding words that model tries to predict, we define Context Window.
为了设置模型尝试预测的周围单词的数量,我们定义了“上下文窗口”。
Let Context Window C=4Let the input be one of the words in the vocabulary. We will input the one-hot-encoded representation of this word of dimension V and the model is expected produce an output of series of probability distributions of each word with the output dimension being C*V.
让输入成为词汇表中的单词之一。 我们将输入这个维数为V的单词的单次热编码表示,并且期望该模型产生每个单词的概率分布系列的输出,且输出维数为C * V。
Word2Vec was a major breakthrough in the field of Word Embeddings because it was able to capture relations in algebraic representations that were never captured before. For example, If we took words such as “King”, “Queen”, “man”, “wife” and mapped these words into the vector space, we found out out that the vector distance between “King” and “Queen” was the same as the vector distance between “man” and “woman”, which could allow us to produce outputs like the following:
Word2Vec是词嵌入领域的一项重大突破,因为它能够捕获以前从未捕获的代数表示形式中的关系。 例如,如果我们使用诸如“ King”,“ Queen”,“ man”,“ wife”之类的词并将这些词映射到向量空间中,我们发现“ King”与“ Queen”之间的向量距离为与“男人”和“女人”之间的向量距离相同,这可以使我们产生如下输出:
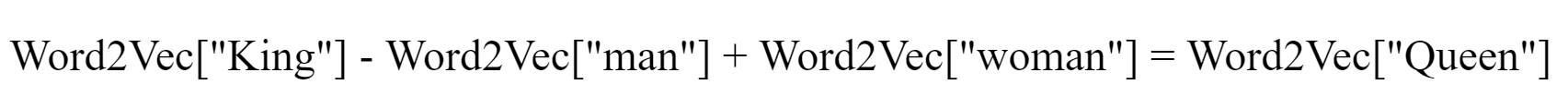
手套 (Glove)
While the Word2Vec technique relies on local statistics (local context surrounding the word) to derive local semantics of a word, the Glove technique goes one step further by combining local statistics with global statistics such as Latent Semantic Analysis (Word Co-occurrence Matrix) to capture the global semantic relationships of a word. Glove was developed by Pennington, et al. at Stanford.
虽然Word2Vec技术依赖于本地统计信息 (单词周围的本地上下文)来得出单词的本地语义,但Glove技术却通过将本地统计信息与诸如潜在语义分析 (单词共现矩阵)之类的全局统计信息相结合而进一步向前发展了一步。捕获单词的全局语义关系。 手套由Pennington等人开发。 在斯坦福。
For example, consider the co-occurrence probabilities for target words ice and steam with various probe words from the vocabulary. Here are some actual probabilities from a 6 billion word corpus:
例如,考虑目标词“ 冰”和“ 蒸汽”与来自词汇表的各种探测词的共现概率。 这是一个来自60亿个单词的语料库的实际概率:

From the above table, we can observe that ice co-occurs with solid more frequently than it does with gas, and steam co-occurs with gas more frequently than with solid. Both words co-occur with their shared property water frequently, and both co-occur with the unrelated word fashion infrequently. From the ratio of probabilities, we can observe that non-discriminative words(water & fashion) have a ratio of probabilities approximately equal to 1, whereas discriminative words(solid and gas) have either high ratio of probabilities or very low ratio of probabilities. Using this method, the ratio of probabilities encodes some crude form of meaning associated with the abstract concept of thermodynamic phases. These ratios of probabilities are then encoded in the form of vector differences in N-Dimensional space.
从上表中可以看出,与气体相比, 冰与固体的共生频率更高,而与气体相比, 蒸汽与气体的共生频率更高。 这两个词经常与它们共有的水一起出现,而两个词却很少与不相关的词时尚一起出现。 从概率的比率中,我们可以观察到非歧视性词( 水和时尚)的概率比率大约等于1,而区分性词( 实心和气体)的概率比率很高或非常低。 使用这种方法,概率比可以编码与热力学相的抽象概念相关的某种粗略形式的含义。 然后以N维空间中矢量差的形式对这些概率比率进行编码。

In the above image, we notice that the vector differences between word pairs such as man & woman and king & queen are roughly equal. The distinguishing factor between these word pairs is gender. As well as this pattern, we can also observe many other interesting patterns in the above visualization from Glove.
在上图中,我们注意到男人和女人以及国王和王后等词对之间的向量差大致相等。 这些词对之间的区别因素是性别。 除了这种模式,我们还可以在上述Glove的可视化图中观察到许多其他有趣的模式。
艾莫 (ELMo)
Before we jump into ELMo, consider this example:
在进入ELMo之前,请考虑以下示例:
Her favorite fruit to eat is a date.
她最喜欢吃的水果是 约会 。
Joe took Alexandria out on a date.
乔 约会 了亚历山大 。
We can observe that date has different meanings in different contexts. Word embeddings such as Glove and Word2Vec will produce the same vector for the word date in both the sentences. Hence, our models would fail to distinguish between the polysemous (having different meaning and senses) words. These word embeddings just cannot grasp the context in which the word was used.
我们可以观察到, 日期在不同的上下文中具有不同的含义。 诸如Glove和Word2Vec的词嵌入将为两个句子中的词日期产生相同的向量。 因此,我们的模型将无法区分多义词 (具有不同的含义和感觉)。 这些词嵌入只是无法掌握使用该词的上下文。
ELMo resolves this issue by taking in the whole sentence as an input rather than a particular word and generating unique ELMo vectors for the same word used in different contextual sentences.
ELMo通过将整个句子(而不是特定单词)作为输入,并为用于不同上下文句子中的同一单词生成唯一的ELMo向量, 从而解决了此问题。
It was developed by NLP researchers (Peters et. al., 2017, McCann et. al., 2017, and Peters et. al., 2018 in the ELMo paper) at Allen Institute of AI.
它是由NLP研究人员( Peters等人,2017 , McCann等人,2017和Peters等人,2018在ELMo论文中 )在艾伦AI研究所开发的。

ELMo uses Bi-directional LSTM, which is pre-trained on a large text corpus to produce word vectors. It works by training to predict the next word given a sequence of words. This task is also known as Language Modeling.
ELMo使用双向LSTM,该双向LSTM在大型文本语料库上进行了预训练以生成单词向量。 它通过训练来预测给定单词序列的下一个单词。 此任务也称为语言建模。

ELMo representations are:
ELMo表示为:
Contextual: The ELMo vectors produced for a word depends on the context of the sentence the word is being used in.
上下文 :为一个单词生成的ELMo向量取决于该单词所使用的句子的上下文。
Character based: ELMo representations are purely character based, allowing the network to use morphological clues to form robust representations for out-of-vocabulary tokens unseen in training.
基于字符 :ELMo表示完全基于字符,允许网络使用形态学线索来形成训练中未曾见过的词汇外标记的可靠表示。
词嵌入的应用 (Applications of Word Embeddings)
Word Embeddings have played a huge role across the complete spectrum of NLP applications. The following are some of the famous applications that use Word Embeddings:
词嵌入在整个NLP应用程序中都发挥了巨大作用。 以下是一些使用Word Embeddings的著名应用程序:
Word Embeddings have been integral in improving Document Search and Information Retrieval. An intuitive approach is to calculate Word Centroid Similarity. The representation for each document is the centroid of its respective word vectors. Since word vectors carry semantic information of the words, one could assume that the centroid of the word vectors within a document encodes its meaning to some extent. At query time, the centroid of the query’s word vectors is computed. The cosine similarity to the centroids of the (matching) documents is used as a measure of relevance. This speeds up the process and resolves the issue of search keywords needing to be exactly the same as those in the document.— Vec4ir by Lukas Galke
词嵌入已成为改善文档搜索和信息检索不可或缺的一部分。 一种直观的方法是计算单词质心相似度 。 每个文档的表示形式是其各个单词向量的质心。 由于单词向量携带单词的语义信息,因此可以假设文档中单词向量的质心在某种程度上对其含义进行了编码。 在查询时,将计算查询词向量的质心。 与(匹配)文档的质心的余弦相似度用作相关性的度量。 这样可以加快流程,并解决需要与文档中的搜索关键字完全相同的搜索关键字的问题。— Lukas Galke的Vec4ir
Word Embeddings have also improved Language Translation System. Facebook had recently released Multi-Lingual Word Embeddings (fastText) which has word vectors for 157 languages trained on Wikipedia and Crawl. Given a training data for example, Text Corpus having two language formats — Original Language: Japanese; Converted Language: English, we can feed the word vectors of the text corpus of these languages to a Deep Learning model say, Seq2Seq model and let it learn accordingly. During the evaluation-phase you can feed the test Japanese text corpus to this learned Seq2Seq and evaluate the results. fastText is considered one of the most efficient SOTA baselines.
单词嵌入还改善了语言翻译系统。 Facebook最近发布了多语言单词嵌入( fastText ),其中包含Wikipedia和Crawl上训练的157种语言的单词向量。 例如,给定训练数据,文本语料库具有两种语言格式-原始语言: 日语 ; 转换后的语言: 英语,我们可以将这些语言的文本语料库的单词向量输入到深度学习模型(即Seq2Seq模型)中,并据此进行学习。 在评估阶段,您可以将测试的日语文本语料库馈入此学习到的Seq2Seq并评估结果。 fastText被认为是最有效的SOTA基准之一。
- Lastly Word Embeddings have improved Text Classification accuracy in different domains such as Sentiment Analysis, Spam Detection and Document Classification.
最后,词嵌入在不同领域(例如情感分析,垃圾邮件检测和文档分类)中提高了文本分类的准确性。
翻译自: https://medium.com/compassred-data-blog/introduction-to-word-embeddings-and-its-applications-8749fd1eb232
嵌入式系统分类及其应用场景
相关文章:
- hotelling变换_基于Hotelling-T²的偏最小二乘(PLS)中的变量选择
- 命名实体识别 实体抽取_您的公司为什么要关心命名实体的识别
- 机器学习 异常值检测_异常值是否会破坏您的机器学习预测? 寻找最佳解决方案
- yolov3算法优点缺点_优点缺点
- 主成分分析具体解释_主成分分析-现在用您自己的术语解释
- netflix 数据科学家_数据科学和机器学习在Netflix中的应用
- python画交互式地图_使用Python构建交互式地图-入门指南
- 大疆 机器学习 实习生_我们的数据科学机器人实习生
- ai人工智能的本质和未来_人工智能的未来在于模型压缩
- tableau使用_使用Tableau探索墨尔本房地产市场
- 谷歌云请更正这张卡片的信息_如何识别和更正Google Analytics(分析)报告中的(未设置)值
- 科技情报研究所工资_我们所说的情报是什么?
- 手语识别_使用深度学习进行手语识别
- 数据科学的5种基本的面向业务的批判性思维技能
- 大数据技术 学习之旅_数据-数据科学之旅的起点
- 编写分段函数子函数_编写自己的函数
- 打破学习的玻璃墙_打破Google背后的创新深度学习
- 向量 矩阵 张量_张量,矩阵和向量有什么区别?
- monk js_使用Monk AI进行手语分类
- 辍学的名人_辍学效果如此出色的5个观点
- 强化学习-动态规划_强化学习-第5部分
- 查看-增强会话_会话式人工智能-关键技术和挑战-第2部分
- 我从未看过荒原写作背景_您从未听说过的最佳数据科学认证
- nlp算法文本向量化_NLP中的标记化算法概述
- 数据科学与大数据排名思考题_排名前5位的数据科学课程
- 《成为一名机器学习工程师》_如何在2020年成为机器学习工程师
- 打开应用蜂窝移动数据就关闭_基于移动应用行为数据的客户流失预测
- 端到端机器学习_端到端机器学习项目:评论分类
- python 数据科学书籍_您必须在2020年阅读的数据科学书籍
- ai人工智能收入_人工智能促进收入增长:使用ML推动更有价值的定价
嵌入式系统分类及其应用场景_词嵌入及其应用简介相关推荐
- 词嵌入 网络嵌入_词嵌入简介
词嵌入 网络嵌入 深度学习 , 自然语言处理 (Deep Learning, Natural Language Processing) Word embedding is a method to ca ...
- 词嵌入 网络嵌入_词嵌入深入实践
词嵌入 网络嵌入 介绍 (Introduction) I'm sure most of you would stumble sooner or later on the term "Word ...
- 嵌入式和非嵌入式_我如何向非技术同事解释词嵌入
嵌入式和非嵌入式 数据科学 (Data Science) Word embeddings. 词嵌入. What are they? What do they look like? How are th ...
- 嵌入式系统基本概念(硬件篇)
嵌入式系统组成: 硬件子系统.软件子系统. 嵌入式系统分类: 通用计算机型:通用计算机或嵌入式单板机(如PC104模块)嵌入到应用系统内部. 专用计算机型:面向具体应用系统量身定制,体积小功耗低. 硬 ...
- 2022-2028年中国嵌入式系统行业市场专项调研及竞争战略分析报告
报告类型:产业研究 报告格式:电子版.纸介版 出品单位:智研咨询-产业信息网 嵌入式系统由硬件和软件组成.是能够独立进行运作的器件.其软件内容只包括软件运行环境及其操作系统.硬件内容包括信号处理器.存 ...
- 计算机三级之嵌入式系统学习笔记8
嵌入式系统是嵌入式计算机系统的简称,它是一种嵌入在设备(或系统)内部,为特定应用而设计开发的专用计算机系统 嵌入式系统与通用计算机一样,也由硬件和软件组成 能够按照指令的规定高速度完成二进制数据算数和 ...
- 嵌入式系统学习-------1.什么是嵌入式系统?
什么是嵌入式系统? 我们在日常的生活当中经常会听说到嵌入式应用,而在物联网的发展下,嵌入式的应用也变得更加多样起来,我们不禁会有一个疑问,什么是嵌入式系统,下面我们一起学习一下. 嵌入式系统定义 简单 ...
- 嵌入式系统开发的基础知识
一. 嵌入式系统的特点.分类.发展与应用 1.嵌入式系统定义 1)广义上:带有微处理器的专用软件系统. 2)狭义上:使用嵌入式微处理器构成的具有自己的操作系统和特定功能,用于特定场合. 3)以应用为中 ...
- 嵌入式学习(1)嵌入式的分类、ARM KEIL的说明、嵌入式操作系统、介绍
1.嵌入式系统的分类 嵌入式系统源于微型计算机,是嵌入到系统对象体系中去,实现嵌入对象智能化的计算机. 嵌入式系统分类 (1) 嵌入式微处理器(EMBEDDED MICROPROCESSOR UNIT ...
最新文章
- 自动化测试selenium+java学习笔记
- 全面解读PyTorch内部机制
- mysql画事实表_sql生成事实表数据库
- 单IP无TMG拓扑Lync Server 2013:外部访问
- Cannot load JDBC driver class 'com.mysql.jdbc.Driver '
- Manecher算法
- 苹果mac专业音频处理软件:Audition
- ubuntu ffmpeg 下载安装
- python实用代码
- Excel函数实战技巧精粹(五)LEN和LENB等函数之常用用法
- 几种常用App原型设计工具详解
- 项目成本管理:成本与成本管理概念
- elementui下载到本地
- 阿里云国际版云服务器自助诊断系统-Unirech
- extern 用法小结
- 中国 IM 企业的新机会?揭秘融云全球通信云网络背后的技术 | 对话 WICC
- AGV搬运机器人「眼睛」的未来:3D视觉导航方案
- 借生态力量,openGauss突破性能瓶颈
- UITableView关闭键盘/收起键盘的方法总结
- 华山论剑之契约式编程与防御式编程