Spark2.4.0 SparkEnv 源码分析
Spark2.4.0 SparkEnv 源码分析
更多资源
- github: https://github.com/opensourceteams/spark-scala-maven-2.4.0
时序图
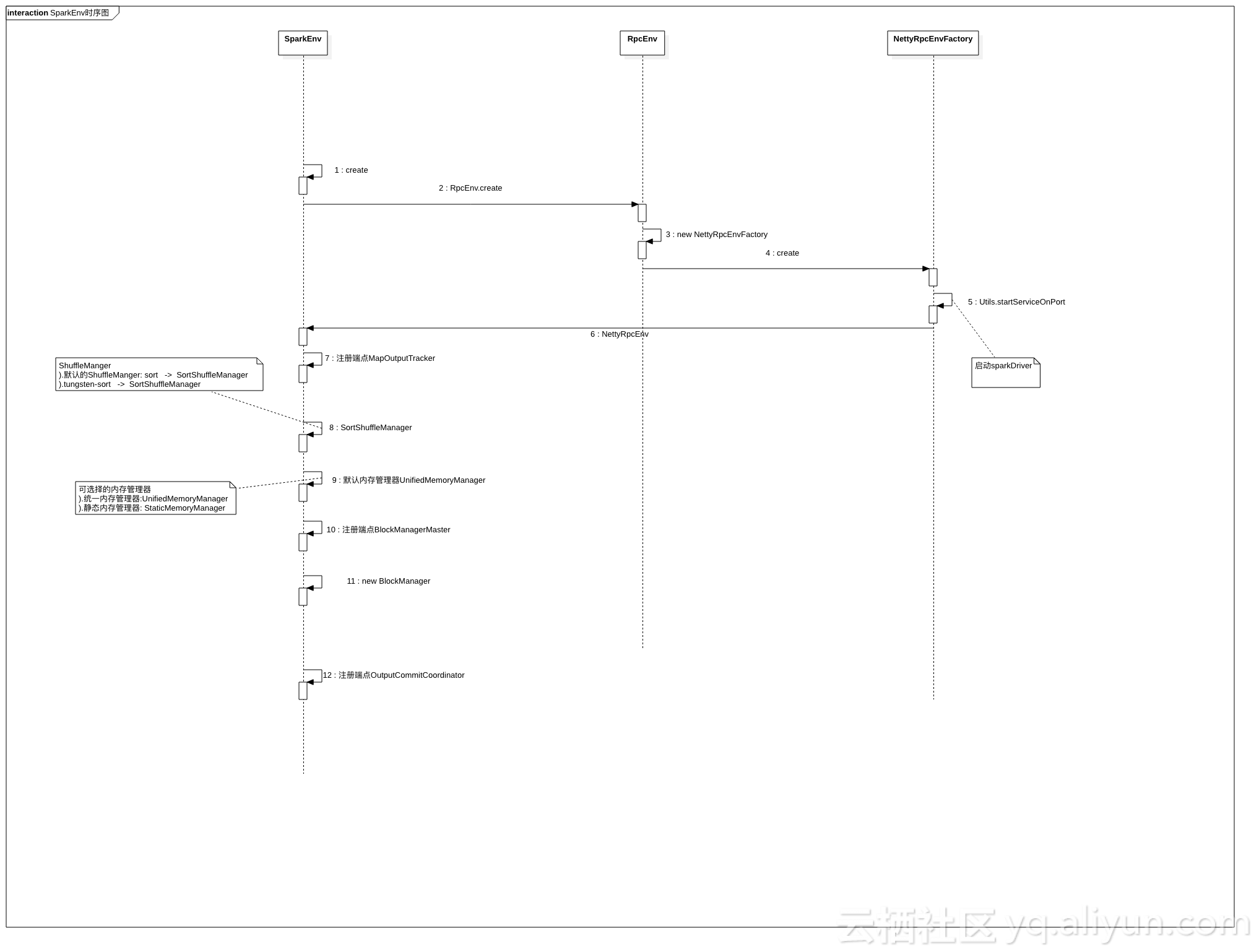
前置条件
- Hadoop版本: hadoop-2.9.2
- Spark版本: spark-2.4.0-bin-hadoop2.7
- JDK.1.8.0_191
- scala2.11.12
主要内容描述
- SparkEnv对象构建
- SparkEnv类中做如下操作
- ).new SecurityManager()
- ).new NettyRpcEnvFactory()
- ).创建NettyRpcEnv
- ).Utils.startServiceOnPort(启动sparkDriver)
- ). new BroadcastManager
- ).注册端点MapOutputTracker
- ).ShuffleManager:SortShuffleManager
- ).默认内存管理器:UnifiedMemoryManager
- ).注册端点MapOutputTracker
- ).SortShuffleManager
- ).UnifiedMemoryManager
- ).注册端点BlockManagerMaster
- ).new BlockManager
- ).注册端点OutputCommitCoordinator
SparkContext
SparkContext 类构造中调用createSparkEnv
private var _env: SparkEnv = _// Create the Spark execution environment (cache, map output tracker, etc)_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkContext.createSparkEnv()
- 调用SparkEnv.createDriverEnv函数,创建SparkEnv对象
// This function allows components created by SparkEnv to be mocked in unit tests:private[spark] def createSparkEnv(conf: SparkConf,isLocal: Boolean,listenerBus: LiveListenerBus): SparkEnv = {SparkEnv.createDriverEnv(conf, isLocal, listenerBus, SparkContext.numDriverCores(master, conf))}SparkEnv
SparkEnv.createDriverEnv()
- 调用create()方法
/*** Create a SparkEnv for the driver.*/private[spark] def createDriverEnv(conf: SparkConf,isLocal: Boolean,listenerBus: LiveListenerBus,numCores: Int,mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {assert(conf.contains(DRIVER_HOST_ADDRESS),s"${DRIVER_HOST_ADDRESS.key} is not set on the driver!")assert(conf.contains("spark.driver.port"), "spark.driver.port is not set on the driver!")val bindAddress = conf.get(DRIVER_BIND_ADDRESS)val advertiseAddress = conf.get(DRIVER_HOST_ADDRESS)val port = conf.get("spark.driver.port").toIntval ioEncryptionKey = if (conf.get(IO_ENCRYPTION_ENABLED)) {Some(CryptoStreamUtils.createKey(conf))} else {None}create(conf,SparkContext.DRIVER_IDENTIFIER,bindAddress,advertiseAddress,Option(port),isLocal,numCores,ioEncryptionKey,listenerBus = listenerBus,mockOutputCommitCoordinator = mockOutputCommitCoordinator)}SparkEnv.create()
- ).这个是最重要的方法
- ).SparkEnv对象是在这个方法中构造的
- ).new SecurityManager()
- ).new NettyRpcEnvFactory()
- ).创建NettyRpcEnv
- ).Utils.startServiceOnPort(启动sparkDriver)
- ). new BroadcastManager
- ).注册端点MapOutputTracker
- ).ShuffleManager:SortShuffleManager
- ).默认内存管理器:UnifiedMemoryManager
- ).注册端点MapOutputTracker
- ).SortShuffleManager
- ).UnifiedMemoryManager
- ).注册端点BlockManagerMaster
- ).new BlockManager
- ).注册端点OutputCommitCoordinator
/*** Helper method to create a SparkEnv for a driver or an executor.*/private def create(conf: SparkConf,executorId: String,bindAddress: String,advertiseAddress: String,port: Option[Int],isLocal: Boolean,numUsableCores: Int,ioEncryptionKey: Option[Array[Byte]],listenerBus: LiveListenerBus = null,mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnv = {val isDriver = executorId == SparkContext.DRIVER_IDENTIFIER// Listener bus is only used on the driverif (isDriver) {assert(listenerBus != null, "Attempted to create driver SparkEnv with null listener bus!")}val securityManager = new SecurityManager(conf, ioEncryptionKey)if (isDriver) {securityManager.initializeAuth()}ioEncryptionKey.foreach { _ =>if (!securityManager.isEncryptionEnabled()) {logWarning("I/O encryption enabled without RPC encryption: keys will be visible on the " +"wire.")}}val systemName = if (isDriver) driverSystemName else executorSystemNameval rpcEnv = RpcEnv.create(systemName, bindAddress, advertiseAddress, port.getOrElse(-1), conf,securityManager, numUsableCores, !isDriver)// Figure out which port RpcEnv actually bound to in case the original port is 0 or occupied.if (isDriver) {conf.set("spark.driver.port", rpcEnv.address.port.toString)}// Create an instance of the class with the given name, possibly initializing it with our confdef instantiateClass[T](className: String): T = {val cls = Utils.classForName(className)// Look for a constructor taking a SparkConf and a boolean isDriver, then one taking just// SparkConf, then one taking no argumentstry {cls.getConstructor(classOf[SparkConf], java.lang.Boolean.TYPE).newInstance(conf, new java.lang.Boolean(isDriver)).asInstanceOf[T]} catch {case _: NoSuchMethodException =>try {cls.getConstructor(classOf[SparkConf]).newInstance(conf).asInstanceOf[T]} catch {case _: NoSuchMethodException =>cls.getConstructor().newInstance().asInstanceOf[T]}}}// Create an instance of the class named by the given SparkConf property, or defaultClassName// if the property is not set, possibly initializing it with our confdef instantiateClassFromConf[T](propertyName: String, defaultClassName: String): T = {instantiateClass[T](conf.get(propertyName, defaultClassName))}val serializer = instantiateClassFromConf[Serializer]("spark.serializer", "org.apache.spark.serializer.JavaSerializer")logDebug(s"Using serializer: ${serializer.getClass}")val serializerManager = new SerializerManager(serializer, conf, ioEncryptionKey)val closureSerializer = new JavaSerializer(conf)def registerOrLookupEndpoint(name: String, endpointCreator: => RpcEndpoint):RpcEndpointRef = {if (isDriver) {logInfo("Registering " + name)rpcEnv.setupEndpoint(name, endpointCreator)} else {RpcUtils.makeDriverRef(name, conf, rpcEnv)}}val broadcastManager = new BroadcastManager(isDriver, conf, securityManager)val mapOutputTracker = if (isDriver) {new MapOutputTrackerMaster(conf, broadcastManager, isLocal)} else {new MapOutputTrackerWorker(conf)}// Have to assign trackerEndpoint after initialization as MapOutputTrackerEndpoint// requires the MapOutputTracker itselfmapOutputTracker.trackerEndpoint = registerOrLookupEndpoint(MapOutputTracker.ENDPOINT_NAME,new MapOutputTrackerMasterEndpoint(rpcEnv, mapOutputTracker.asInstanceOf[MapOutputTrackerMaster], conf))// Let the user specify short names for shuffle managersval shortShuffleMgrNames = Map("sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")val shuffleMgrClass =shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName)val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false)val memoryManager: MemoryManager =if (useLegacyMemoryManager) {new StaticMemoryManager(conf, numUsableCores)} else {UnifiedMemoryManager(conf, numUsableCores)}val blockManagerPort = if (isDriver) {conf.get(DRIVER_BLOCK_MANAGER_PORT)} else {conf.get(BLOCK_MANAGER_PORT)}val blockTransferService =new NettyBlockTransferService(conf, securityManager, bindAddress, advertiseAddress,blockManagerPort, numUsableCores)val blockManagerMaster = new BlockManagerMaster(registerOrLookupEndpoint(BlockManagerMaster.DRIVER_ENDPOINT_NAME,new BlockManagerMasterEndpoint(rpcEnv, isLocal, conf, listenerBus)),conf, isDriver)// NB: blockManager is not valid until initialize() is called later.val blockManager = new BlockManager(executorId, rpcEnv, blockManagerMaster,serializerManager, conf, memoryManager, mapOutputTracker, shuffleManager,blockTransferService, securityManager, numUsableCores)val metricsSystem = if (isDriver) {// Don't start metrics system right now for Driver.// We need to wait for the task scheduler to give us an app ID.// Then we can start the metrics system.MetricsSystem.createMetricsSystem("driver", conf, securityManager)} else {// We need to set the executor ID before the MetricsSystem is created because sources and// sinks specified in the metrics configuration file will want to incorporate this executor's// ID into the metrics they report.conf.set("spark.executor.id", executorId)val ms = MetricsSystem.createMetricsSystem("executor", conf, securityManager)ms.start()ms}val outputCommitCoordinator = mockOutputCommitCoordinator.getOrElse {new OutputCommitCoordinator(conf, isDriver)}val outputCommitCoordinatorRef = registerOrLookupEndpoint("OutputCommitCoordinator",new OutputCommitCoordinatorEndpoint(rpcEnv, outputCommitCoordinator))outputCommitCoordinator.coordinatorRef = Some(outputCommitCoordinatorRef)val envInstance = new SparkEnv(executorId,rpcEnv,serializer,closureSerializer,serializerManager,mapOutputTracker,shuffleManager,broadcastManager,blockManager,securityManager,metricsSystem,memoryManager,outputCommitCoordinator,conf)// Add a reference to tmp dir created by driver, we will delete this tmp dir when stop() is// called, and we only need to do it for driver. Because driver may run as a service, and if we// don't delete this tmp dir when sc is stopped, then will create too many tmp dirs.if (isDriver) {val sparkFilesDir = Utils.createTempDir(Utils.getLocalDir(conf), "userFiles").getAbsolutePathenvInstance.driverTmpDir = Some(sparkFilesDir)}envInstance}
end
Spark2.4.0 SparkEnv 源码分析相关推荐
- Spark2.0.2源码分析——RPC 通信机制(消息处理)
RPC 是一种远程过程的调用,即两台节点之间的数据传输. 每个组件都有它自己的执行环境,RPC 的执行环境就是 RPCENV,RPCENV 是 Spark 2.x.x 新增加的,用于替代之前版本的 a ...
- 菜鸟读jQuery 2.0.3 源码分析系列(1)
原文链接在这里,作为一个菜鸟,我就一边读一边写 jQuery 2.0.3 源码分析系列 前面看着差不多了,看到下面一条(我是真菜鸟),推荐木有入门或者刚刚JS入门摸不着边的看看,大大们手下留情,想一起 ...
- Android 11.0 Settings源码分析 - 主界面加载
Android 11.0 Settings源码分析 - 主界面加载 本篇主要记录AndroidR Settings源码主界面加载流程,方便后续工作调试其流程. Settings代码路径: packag ...
- Android 8.0系统源码分析--Camera processCaptureResult结果回传源码分析
相机,从上到下概览一下,真是太大了,上面的APP->Framework->CameraServer->CameraHAL,HAL进程中Pipeline.接各种算法的Node.再往下的 ...
- photoshop-v.1.0.1源码分析第三篇–FilterInterface.p
photoshop-v.1.0.1源码分析第三篇–FilterInterface.p 总体预览 一.源码预览 二.语法解释 三.结构预览 四:语句分析 五:思维导图 六:疑留问题 一.源码预览 {Ph ...
- Pushlet 2.0.3 源码分析
转载地址:http://blog.csdn.net/yxw246/article/details/2418255 Pushlet 2.0.3 源码分析 ----服务器端 1 总体架构 Pushlet从 ...
- jQuery 2.0.3 源码分析 Deferred(最细的实现剖析,带图)
Deferred的概念请看第一篇 http://www.cnblogs.com/aaronjs/p/3348569.html ******************构建Deferred对象时候的流程图* ...
- 最细的实现剖析:jQuery 2.0.3源码分析Deferred
Deferred的概念请看第一篇 http://www.cnblogs.com/aaronjs/p/3348569.html **构建Deferred对象时候的流程图** **源码解析** 因为cal ...
- jQuery 2.0.3 源码分析 事件体系结构
那么jQuery事件处理机制能帮我们处理那些问题? 毋容置疑首先要解决浏览器事件兼容问题 可以在一个事件类型上添加多个事件处理函数,可以一次添加多个事件类型的事件处理函数 提供了常用事件的便捷方法 支 ...
最新文章
- Leangoo看板工具做单团队敏捷开发
- 大数运算(5)——大数除法(取模、取余)
- JavaScript实现Knapsack problem背包问题算法(附完整源码)
- Windows 10下使用Anaconda安装TensorFlow1.8
- L1-014 简单题 (5 分)
- python : 正确复制列表的方法
- JS调用webservice的两种方式
- C# 异步查询数据库(第二版)
- vue 倒计时 插件_VUE-倒计时插件使用(订单,砍价,拼团,倒计时使用)
- 【Python打卡2019】20190423之52周存钱挑战-for+range()函数使用
- 模电课程设计_函数发生器
- sdk 今日头条_今日头条商业SDK(激励视频)的坑
- 面试官没想到我对redis数据结构这么了解,直接给offer
- CAT 实时监控与项目集成
- 欧奈尔的RPS指标如何使用到股票预测
- House of orange
- (十六)ATP应用测试平台——java应用中的过滤器Filter、拦截器Interceptor、参数解析器Resolver、Aop切面,你会了吗?
- Kaggle实战:泰坦尼克幸存者预测 - 上
- SQL查询语句逻辑执行顺序
- cocos2d-html5游戏图片资源选择