[kubernetes] 资源管理 --- 资源预留实践
一 概述
1.1 问题
系统资源可分为两类:可压缩资源(CPU)和不可压缩资源(memory、storage)。可压缩资源比如CPU超配后,在系统满负荷时会划分时间片分时运行进程,系统整体会变慢(一般不会导致太大的问题)。但不可压缩资源如Memory,当系统内存不足时,就有可能触发系统 OOM;这时候根据 oom score 来确定优先杀死哪个进程,而 oom_score_adj 又是影响 oom score 的重要参数,其值越低,表示 oom 的优先级越低。在计算节点中,进程的 oom_score_adj 如下:
![]()
所以,OOM 的优先级如下:
BestEffort Pod > Burstable Pod > 其它进程 > Guaranteed Pod > kubelet/docker 等 > sshd 等
在Kubernetes平台,默认情况下Pod能够使用节点全部可用资源。如果节点上的Pod负载较大,那么这些Pod可能会与节点上的系统守护进程和k8s组件争夺资源并导致节点资源短缺,甚至引发系统OOM,导致某些进程被Linux系统的OOM killer机制杀掉,假如被杀掉的进程是系统进程或K8S组件,会导致比较严重的问题。
1.2 解决方案
针对这种问题,主要有两种解决方案(两种也可以结合使用):
启用kubelet的Node Allocatable特性,为系统守护进程和k8s组件预留资源。 官方文档:https://kubernetes.io/docs/tasks/administer-cluster/reserve-compute-resources
设置pod的驱逐策略,在pod使用资源到一定程度时进行pod驱逐。官方文档:https://kubernetes.io/docs/tasks/administer-cluster/out-of-resource/#eviction-policy
二 Kubelet Node Allocatable
kubelet的启动配置中有一个Node Allocatable特性,来为系统守护进程和k8s组件预留计算资源,使得即使节点满负载运行时,也不至于出现pod去和系统守护进程以及k8s组件争抢资源,导致节点挂掉的情况。kubernetes官方建议根据各个节点的负载情况来具体配置相关参数。
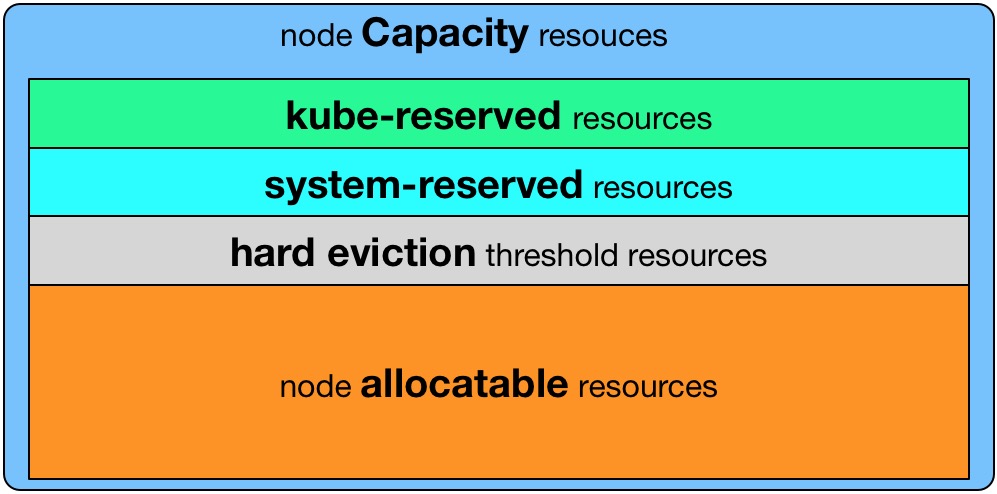
- Kubelet Node Allocatable用来为Kube组件和System进程预留资源,从而保证当节点出现满负荷时也能保证Kube和System进程有足够的资源。
- 目前支持cpu, memory, ephemeral-storage三种资源预留。
- Node Capacity是Node的所有硬件资源,kube-reserved是给kube组件预留的资源,system-reserved是给System进程预留的资源, eviction-threshold是kubelet eviction的阈值设定,allocatable才是真正scheduler调度Pod时的参考值(保证Node上所有Pods的request resource不超过Allocatable)。
Node Allocatable Resource = Node Capacity - Kube-reserved - system-reserved - eviction-threshold
如何配置
- --enforce-node-allocatable,默认为pods,要为kube组件和System进程预留资源,则需要设置为
pods,kube-reserved,system-reserve。 - --cgroups-per-qos,Enabling QoS and Pod level cgroups,默认开启。开启后,kubelet会将管理所有workload Pods的cgroups。
- --cgroup-driver,默认为cgroupfs,另一可选项为systemd。取决于容器运行时使用的cgroup driver,kubelet与其保持一致。比如你配置docker使用systemd cgroup driver,那么kubelet也需要配置--cgroup-driver=systemd。
- --kube-reserved,用于配置为kube组件(kubelet,kube-proxy,dockerd等)预留的资源量,比如—kube-reserved=cpu=1000m,memory=8Gi,ephemeral-storage=16Gi。
- --kube-reserved-cgroup,如果你设置了--kube-reserved,那么请一定要设置对应的cgroup,并且该cgroup目录要事先创建好,否则kubelet将不会自动创建导致kubelet启动失败。比如设置为kube-reserved-cgroup=/kubelet.service 。
- --system-reserved,用于配置为System进程预留的资源量,比如—system-reserved=cpu=500m,memory=4Gi,ephemeral-storage=4Gi。
- --system-reserved-cgroup,如果你设置了--system-reserved,那么请一定要设置对应的cgroup,并且该cgroup目录要事先创建好,否则kubelet将不会自动创建导致kubelet启动失败。比如设置为system-reserved-cgroup=/system.slice。
- --eviction-hard,用来配置kubelet的hard eviction条件,只支持memory和ephemeral-storage两种不可压缩资源。当出现MemoryPressure时,Scheduler不会调度新的Best-Effort QoS Pods到此节点。当出现DiskPressure时,Scheduler不会调度任何新Pods到此节点。关于Kubelet Eviction的更多解读,请参考我的相关博文。
- Kubelet Node Allocatable的代码很简单,主要在
pkg/kubelet/cm/node_container_manager.go,感兴趣的同学自己去走读一遍。
3. 实践
根据是否对system和kube做cgroup上的硬限制进行划分,资源预留主要有两种方式:
- 只对所有pod使用的资源总量做cgroup级别的限制,对system和kube不做cgroup级别限制
- 对pod、system、kube均分别做cgroup级别限制
方式1—只限制pod资源总量
1 将以下内容添加到kubelet的启动参数中:
--enforce-node-allocatable=pods \
--cgroup-driver=cgroupfs \
--kube-reserved=cpu=1,memory=1Gi,ephemeral-storage=10Gi \
--system-reserved=cpu=1,memory=2Gi,ephemeral-storage=10Gi \
--eviction-hard=memory.available<500Mi,nodefs.available<10%
按以上设置
节点上可供Pod所request的资源总和allocatable计算如下:
allocatable = capacity - kube-reserved - system-reserved - eviction-hard
节点上所有Pod实际使用的资源总和不会超过:
capacity - kube-reserved - system-reserved
2. 重启kubelet
service kubelet restart
3. 验证
1.验证公式计算的allocatable与实际一致
通过kubectl describe node查看节点实际capacity及allocatable的值
Capacity:cpu: 8memory: 32930152Ki(约31.4G)pods: 110
Allocatable:cpu: 6memory: 29272424Ki(约27.9G)pods: 110根据公式capacity - kube-reserved - system-reserved - eviction-hard,memory的allocatable的值为31.4G - 1G - 2G - 0.5G = 27.9G,与Allocatable的值一致。
2.验证公式计算的总使用量限制与实际值一致
查看kubepods控制组中对内存的限制值memory.limit_in_bytes(memory.limit_in_bytes值决定了Node上所有的Pod实际能使用的内存上限)
$ cat /sys/fs/cgroup/memory/kubepods/memory.limit_in_bytes
30499250176(约28.4G)
根据公式capacity - kube-reserved - system-reserved,Node上Pod能实际使用的资源上限值为:31.4G - 1G -2G = 28.4G,与实际一致。
方式2—同时限制pod、k8s系统组件、linux系统守护进程资源
配置过程
1.将以下内容添加到kubelet的启动参数中:
--enforce-node-allocatable=pods,kube-reserved,system-reserved \
--cgroup-driver=cgroupfs \
--kube-reserved=cpu=1,memory=1Gi,ephemeral-storage=10Gi \
--kube-reserved-cgroup=/system.slice/kubelet.service \
--system-reserved cpu=1,memory=2Gi,ephemeral-storage=10Gi \
--system-reserved-cgroup=/system.slice \
--eviction-hard=memory.available<500Mi,nodefs.available<10%
至于如何设置cgroup结构,请参考官方建议。
2.为system.slice创建cpuset子系统:
mkdir -p /sys/fs/cgroup/cpuset/system.slice/kubelet.service
mkdir -p /sys/fs/cgroup/pids/system.slice/kubelet.service
mkdir -p /sys/fs/cgroup/devices/system.slice/kubelet.service
mkdir -p /sys/fs/cgroup/memory/system.slice/kubelet.service
mkdir -p /sys/fs/cgroup/hugetlb/system.slice/kubelet.service
mkdir -p /sys/fs/cgroup/cpu,cpuacct/system.slice/kubelet.service
mkdir -p /sys/fs/cgroup/blkio/system.slice/kubelet.service
mkdir -p /sys/fs/cgroup/systemd/system.slice/kubelet.service
备注:这一步手工创建,否则启动kubelet会报找不到相应cgroup的错误。
1. 可以看到未创建前system.slice这个cgroup是没有cpuset子系统的:
find /sys/fs/cgroup -name system.slice
/sys/fs/cgroup/devices/system.slice/sys/fs/cgroup/memory/system.slice/sys/fs/cgroup/blkio/system.slice/sys/fs/cgroup/cpu,cpuacct/system.slice/sys/fs/cgroup/systemd/system.slice2. 可以看到未创建前kubelet是没有cpuset子系统的:
find /sys/fs/cgroup -name kubelet.service
/sys/fs/cgroup/devices/system.slice/kubelet.service/sys/fs/cgroup/memory/system.slice/kubelet.service/sys/fs/cgroup/blkio/system.slice/kubelet.service/sys/fs/cgroup/cpu,cpuacct/system.slice/kubelet.service/sys/fs/cgroup/systemd/system.slice/kubelet.service3.重启kubelet
验证过程
这种情况下pod可分配的资源和实际可使用资源理论上与方法一的计算方式和结果是一样的,实际实验中也是一样的,在这里不做赘述。重点验证此情况下是否对k8s系统组件和linux系统守护进程做了cgroup硬限制。
查看system.slice控制组中对内存的限制值memory.limit_in_bytes:
$ cat /sys/fs/cgroup/memory/system.slice/memory.limit_in_bytes
2147483648(2G)
查看kubelet.service控制组中对内存的限制值memory.limit_in_bytes:
$ cat /sys/fs/cgroup/memory/system.slice/kubelet.service/memory.limit_in_bytes
1073741824(1G)
可以看到,方法2这种预留方式,对k8s组件和系统进程也做了cgroup硬限制,当k8s组件和系统组件资源使用量超过这个限制时,会出现这些进程被杀掉的情况。
例子
以如下的kubelet资源预留为例,Node Capacity为memory=32Gi, cpu=16, ephemeral-storage=100Gi,我们对kubelet进行如下配置:
--enforce-node-allocatable=pods,kube-reserved,system-reserved
--kube-reserved-cgroup=/system.slice/kubelet.service
--system-reserved-cgroup=/system.slice
--kube-reserved=cpu=1,memory=2Gi,ephemeral-storage=1Gi
--system-reserved=cpu=1,memory=1Gi,ephemeral-storage=1Gi
--eviction-hard=memory.available<500Mi,nodefs.available<10%
NodeAllocatable = NodeCapacity - Kube-reserved - system-reserved - eviction-threshold =
cpu=14, memory=28Gi ephemeral-storage=98Gi.
Scheduler会确保Node上所有的Pod Resource Request不超过NodeAllocatable。Pods所使用的memory和storage之和超过NodeAllocatable后就会触发kubelet Evict Pods。
参考:
https://my.oschina.net/jxcdwangtao/blog/1629059
https://blog.csdn.net/liukuan73/article/details/81054961
https://blog.csdn.net/liukuan73/article/details/82024085
[kubernetes] 资源管理 --- 资源预留实践相关推荐
- [kubernetes] 资源管理 ---- 资源请求和限制
当Kubernetes调度Pod时,容器是否有足够的资源来实际运行是很重要的. 如果大型应用程序被调度到资源有限的节点上,则节点可能会耗尽内存或CPU资源,并且可能会停止工作! 请求和限制 请求和限制 ...
- 云原生之容器编排实践-Kubernetes资源管理:标签选择器,注解以及命名空间
背景 前面的几篇文章我们从一个简单的 SpringBoot 服务开始,依次将其打包为镜像,推送至私有镜像仓库,安装 Kubernetes 的极简实践环境 minikube , minikube 传递秘 ...
- 【kubernetes/k8s源码分析】 kubelet cgroup 资源预留源码分析
kubernetes 1.13 WHY 默认情况下 pod 能够使用节点全部可用资源.用户 pod 中的应用疯狂占用内存,pod 将与 node 上的系统守护进程和 kubernetes 组件争夺资源 ...
- kubernetes集群节点资源预留
问题 默认kubelet没有配置资源预留,host上所有的资源(cpu, 内存, 磁盘) 都是可以给 pod 使用的.而当一个节点上的 pod 将资源吃满时,系统层面可能会干掉 k8s 核心组件进程, ...
- 美团点评Kubernetes集群管理实践
背景 作为国内领先的生活服务平台,美团点评很多业务都具有非常显著.规律的"高峰"和"低谷"特征.尤其遇到节假日或促销活动,流量还会在短时间内出现爆发式的增长.这 ...
- 浅析Kubernetes资源管理
女主宣言 Kubernetes的系统资源分为可压缩资源(CPU)和不可压缩资源(memory.storage).默认情况下,kubelet没有做资源预留限制,这样节点上的所有资源都能被Pod使用.若节 ...
- Koordinator 0.6:企业级容器调度系统解决方案,引入 CPU 精细编排、资源预留与全新的重调度框架
阿里云原生开源的混部系统 Koordinator 基于阿里超大规模混部生产实践经验而来,旨在为用户打造云原生场景下接入成本最低.混部效率最佳的解决方案,助力用户企业实现云原生后提升计算资源利用率.降低 ...
- Koordinator 0.6:企业级容器调度系统解决方案,引入 CPU 精细编排、资源预留与全新的重调度框架...
阿里云原生开源的混部系统 Koordinator 基于阿里超大规模混部生产实践经验而来,旨在为用户打造云原生场景下接入成本最低.混部效率最佳的解决方案,助力用户企业实现云原生后提升计算资源利用率.降低 ...
- 基于Docker和Kubernetes的企业级DevOps实践训练营
基于Docker和Kubernetes的企业级DevOps实践训练营 课程准备 离线镜像包 百度:https://pan.baidu.com/s/1N1AYGCYftYGn6L0QPMWIMw 提取码 ...
最新文章
- 多模态理论张德禄_观点 | 多模态研究:认知语言学的新方法
- A*算法解决八数码问题 Java语言实现
- Java NIO 介绍和基本demo
- mysql过滤器_MYSQL复制过滤器
- 写出计算机视觉技术的基本应用,青岛大学研究生专业介绍:计算机应用技术
- html消除样式,清除css样式
- 火箭十八连胜内幕大曝光(坚持看完)(搞笑)
- 设备屏幕亮度调节代码实现
- python中如何进行类的派生与继承_python 面向对象之继承与派生
- 启动docker 服务时 虚拟机端口转发 外部无法访问
- android点击按钮打开蓝牙,Android打开蓝牙的两种方式
- 如何使用云桌面进行开发?
- python如何检测文件或图片类型
- 导出MySQL数据项到excel及数据错位的解决办法
- C++高阶 RAII机制(以对象管理资源)
- postgresq的日志
- 想搞机器学习,不会特征工程?你TM逗我那!
- 近几年比较火的团队协作、项目管理工具测评及工具选择原则介绍
- 企业领袖必读的10本管理学书籍
- JAVA高考加油,给高考学子加油打气的祝福语