hanlp和jieba等六大中文分工具的测试对比
本篇文章测试的哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba、FoolNLTK、HanLP这六大中文分词工具是由 水...琥珀 完成的。相关测试的文章之前也看到过一些,但本篇阐述的可以说是比较详细的了。这里就分享一下给各位朋友!
安装调用
jieba“结巴”中文分词:做最好的 Python 中文分词组件
THULAC清华大学:一个高效的中文词法分析工具包
FoolNLTK可能不是最快的开源中文分词,但很可能是最准的开源中文分词
教程:FoolNLTK 及 HanLP使用
HanLP最高分词速度2,000万字/秒
**中科院 Ictclas 分词系统 - NLPIR汉语分词系统
哈工大 LTP
LTP安装教程[python 哈工大NTP分词 安装pyltp 及配置模型(新)]
如下是测试代码及结果

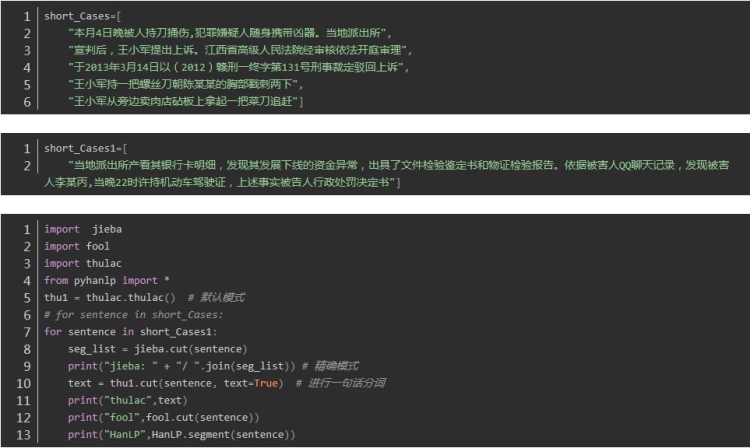
下面测试的文本上是极易分词错误的文本,分词的效果在很大程度上就可以提现分词器的分词情况。接下来验证一下,分词器的宣传语是否得当吧。
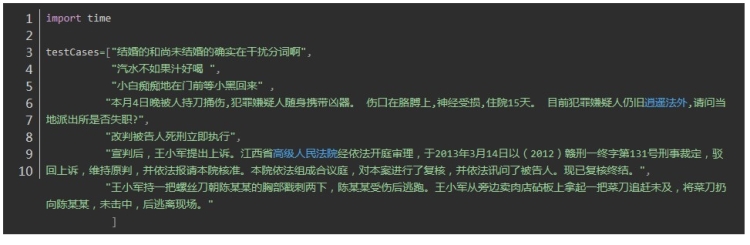
jieba 中文分词
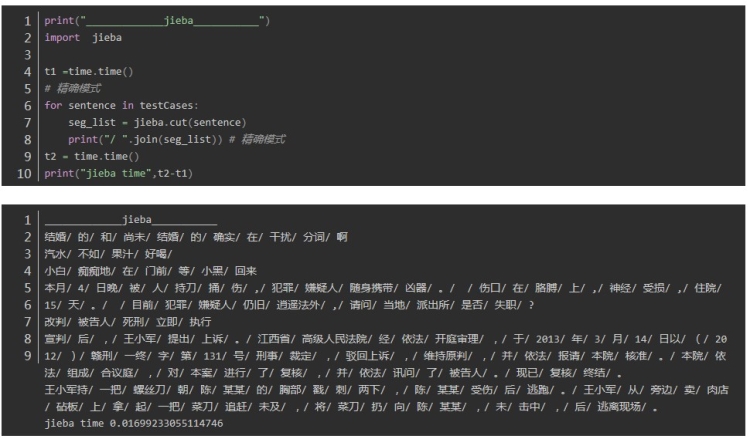
thulac 中文分词
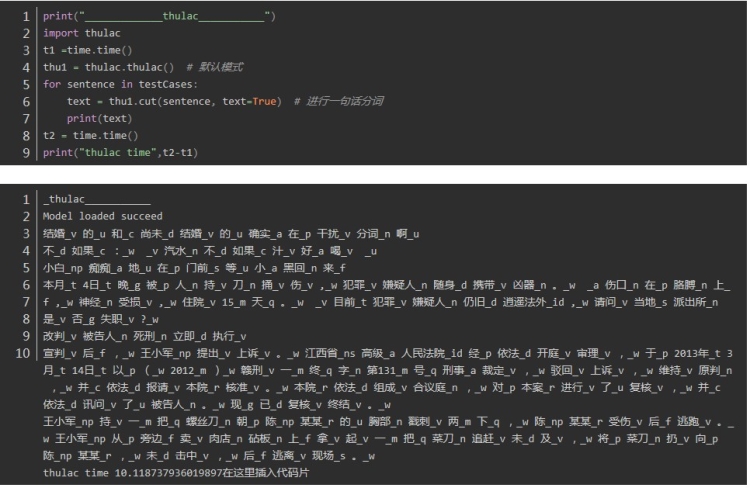
fool 中文分词
HanLP 中文分词
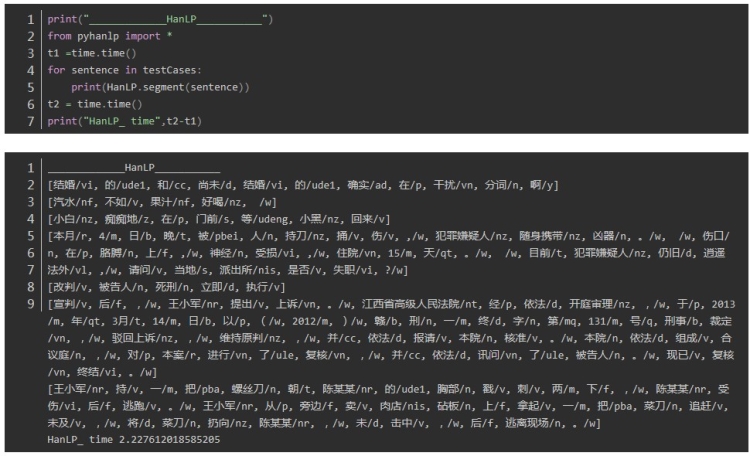
中科院分词 nlpir
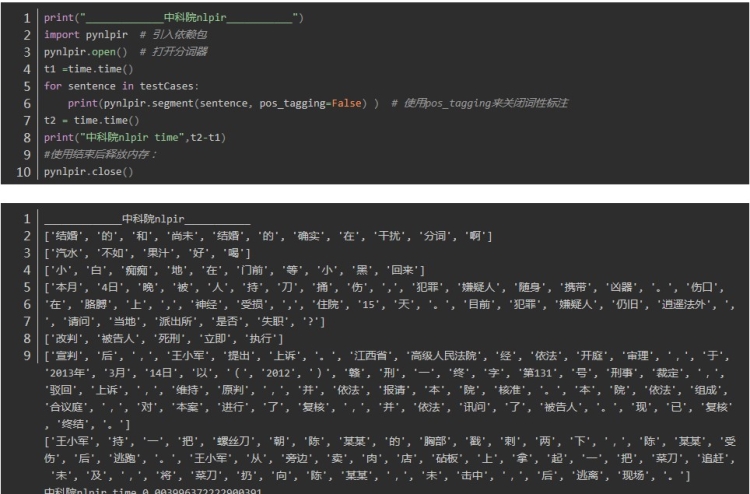
哈工大ltp 分词
以上可以看出分词的时间,为了方便比较进行如下操作:
分词效果对比
结果为:
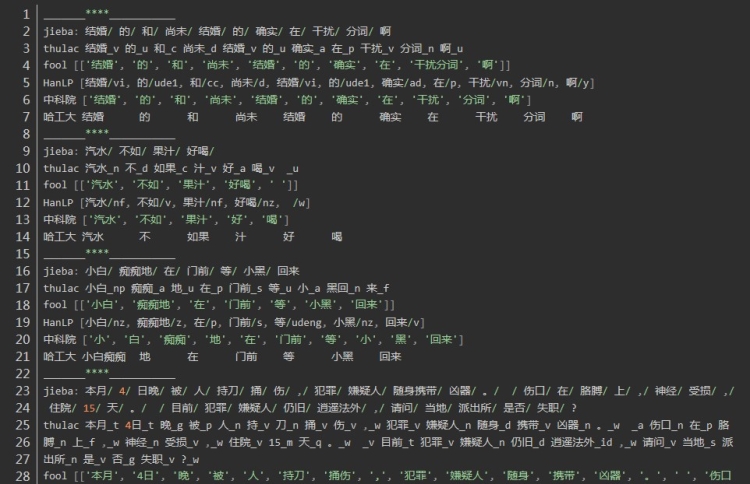
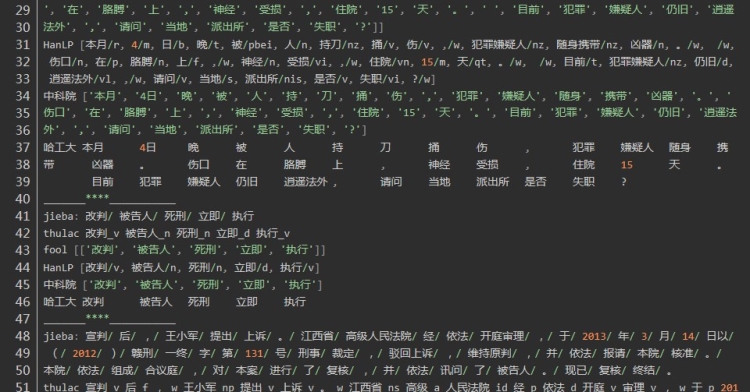
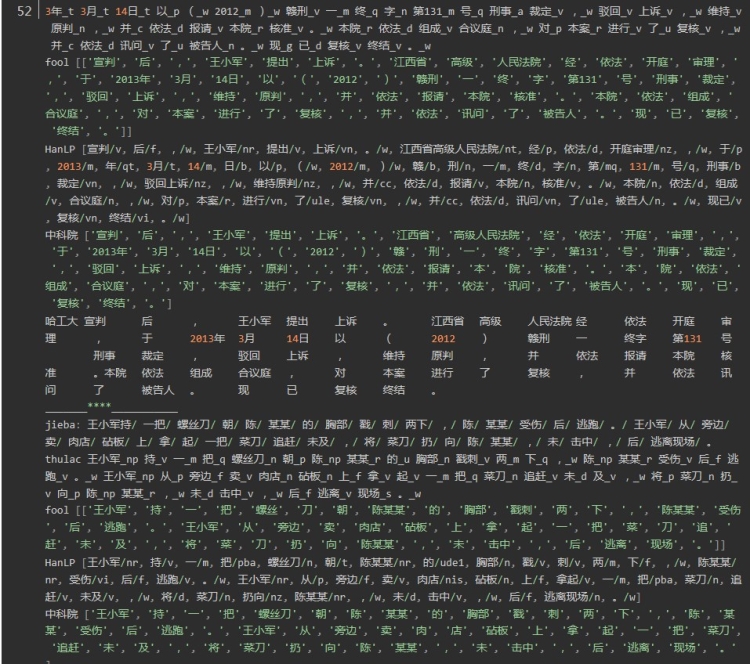

总结:
1.时间上(不包括加载包的时间),对于相同的文本测试两次,四个分词器时间分别为:
jieba: 0.01699233055114746 1.8318662643432617
thulac : 10.118737936019897 8.155954599380493
fool: 2.227612018585205 2.892209053039551
HanLP: 3.6987085342407227 1.443108320236206
中科院nlpir:0.002994060516357422
哈工大ltp_ :0.09294390678405762
可以看出平均耗时最短的是中科院nlpir分词,最长的是thulac,时间的差异还是比较大的。
2.分词准确率上,通过分词效果操作可以看出
第一句:结婚的和尚未结婚的确实在干扰分词啊
四个分词器都表现良好,唯一不同的是fool将“干扰分词”合为一个词
第二句:汽水不如果汁好喝,重点在“不如果”,“”不如“” 和“”如果“” 在中文中都可以成词,但是在这个句子里是不如 与果汁 正确分词
jieba thulac fool HanLP
jieba、 fool 、HanLP正确 thulac错误
第三句: 小白痴痴地在门前等小黑回来,体现在人名的合理分词上
正确是:
小白/ 痴痴地/ 在/ 门前/ 等/ 小黑/ 回来
jieba、 fool 、HanLP正确,thulac在两处分词错误: 小白_np 痴痴_a 地_u 在_p 门前_s 等_u 小_a 黑回_n 来_f
第四句:是有关司法领域文本分词
发现HanLP的分词粒度比较大,fool分词粒度较小,导致fool分词在上有较大的误差。在人名识别上没有太大的差异,在组织机构名上分词,分词的颗粒度有一些差异,Hanlp在机构名的分词上略胜一筹。
六种分词器使用建议:
对命名实体识别要求较高的可以选择HanLP,根据说明其训练的语料比较多,载入了很多实体库,通过测试在实体边界的识别上有一定的优势。
中科院的分词,是学术界比较权威的,对比来看哈工大的分词器也具有比较高的优势。同时这两款分词器的安装虽然不难,但比较jieba的安装显得繁琐一点,代码迁移性会相对弱一点。哈工大分词器pyltp安装配置模型教程
结巴因为其安装简单,有三种模式和其他功能,支持语言广泛,流行度比较高,且在操作文件上有比较好的方法好用python -m jieba news.txt > cut_result.txt
对于分词器的其他功能就可以在文章开头的链接查看,比如说哈工大的pyltp在命名实体识别方面,可以输出标注的词向量,是非常方便基础研究的命名实体的标注工作。
精简文本 效果对比

hanlp和jieba等六大中文分工具的测试对比相关推荐
- jieba textrank关键词提取 python_五款中文分词工具在线PK: Jieba, SnowNLP, PkuSeg,THULAC, HanLP...
最近玩公众号会话停不下来:玩转腾讯词向量:Game of Words(词语的加减游戏),准备把NLP相关的模块搬到线上,准确的说,搬到AINLP公众号后台对话,所以,趁着劳动节假期,给AINLP公众号 ...
- python 分词工具对比_五款中文分词工具在线PK: Jieba, SnowNLP, PkuSeg, THULAC, HanLP
最近玩公众号会话停不下来: 玩转腾讯词向量:Game of Words(词语的加减游戏) ,准备把NLP相关的模块搬到线上,准确的说,搬到AINLP公众号后台对话,所以,趁着劳动节假期,给AINLP公 ...
- 中文分词工具比较 6大中文分词器测试(哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba、FoolNLTK、HanLP)
中文分词工具比较 6大中文分词器测试(jieba.FoolNLTK.HanLP.THULAC.nlpir.ltp) 哈工大LTP.中科院计算所NLPIR.清华大学THULAC和jieba 个人接触的分 ...
- 分词工具比较及使用(ansj、hanlp、jieba)
一.分词工具 ansj.hanlp.jieba 二.优缺点 1.ansj 优点: 提供多种分词方式 可直接根据内部词库分出人名.机构等信息 可构造多个词库,在分词时可动态选择所要使用的词库 缺点: 自 ...
- 中文分词工具jieba分词器的使用
1.常见的中文分词工具 中科院计算所的NLPIR 哈工大LTP 清华大学THULAC 斯坦福分词器 Hanlp分词器 jieba分词 IKAnalyzer 2.jieba分词算法主要有以下三种: 1. ...
- jieba库 python2.7 安装_Python中文分词工具大合集:安装、使用和测试
这篇文章事实上整合了前面两篇文章的相关介绍,同时添加一些其他的Python中文分词相关资源,甚至非Python的中文分词工具,仅供参考. 首先介绍之前测试过的8款中文分词工具,这几款工具可以直接在AI ...
- python中文分词工具jieba_Python 流行的中文分词工具之一 jieba
jieba分词是Python 里面几个比较流行的中文分词工具之一.为了理解分词工具的工作原理,以及实现细节对jieba进行了详细的阅读. 读代码之前,我有几个问题是这样的: 分词工具的实现都有哪几个步 ...
- ik分词和jieba分词哪个好_Pubseg:一种单双字串的BiLSTM中文分词工具
中文分词是中文自然语言处理中的重要的步骤,有一个更高精度的中文分词模型会显著提升文档分类.情感预测.社交媒体处理等任务的效果[1]. Pubseg是基于BiLSTM中文分词工具,基于ICWS2005P ...
- NLP算法-中文分词工具-Jieba
中文分词工具-Jieba 什么是Jieba? 1.Jieba 的特点 2.Jieba 分词的原理 3.Jieba 分词的三种模式 使用 Jieba 库进行分词 代码示例 测试说明 demo 什么是Ji ...
最新文章
- Dialplan 编程基础
- Ubuntu 安装软件的三种方式
- 【BIEE】BIEE报表根据维度表展示事实表不存在的维度
- 数据库中字段类型对应C#中的数据类型
- 华为交换机端口隔离配置
- Window之Fiddler构建请求
- Java基础:int和Integer的区别
- open函数和errno全局变量
- 修改smb默认端口_centos7 ssh端口更改方法
- Eos的Wasm智能合约的局限性
- java单例模式深入详解_javascript 模块依赖管理的本质深入详解
- java 上下文缓存_记一次JAVA 线上故障排查完整套路。
- 用C语言调用.bat批处理命令
- Java对接萤石云平台海康摄像头视频监控
- 数字图像处理——Sobel算子锐化、Prewitt算子锐化
- linux开发 | DM9000网卡驱动
- package.json scripts 脚本使用指南
- 输出三角形,平行四边形,菱形
- 电子计算机上gt键的功能,请问计算器里的GT键是做什么用的
- E. Eggfruit Cake
热门文章
- php多条件检索怎么写,sql查询同时满足三个条件 php查询数据库,同时满足三个条件的sql怎么写?...
- JAVA实时运算_Java 实时运算簿页面
- python如何制作一个工程软件_如何利用python制作一个解压缩软件-Go语言中文社区...
- Python多进程(process)和多线程(thread)的区别
- 如果你是测试在职,我给你几条快速成长的建议!供所有做软件测试的参考...
- python+selenium自动化测试-Windows环境搭建
- PAT甲级1020(附带前中序遍历の绝对干货)
- android日历信息获取错误,android – 从日历中获取事件
- Gradient-Based Learning Applied to Document Recognition
- 机器学习书籍资料推荐