高并发异步uwsgi+web.py+gevent
为什么用web.py?
python的web框架有很多,比如webpy、flask、bottle等,但是为什么我们选了webpy呢?想了好久,未果,硬要给解释,我想可能原因有两个:第一个是兄弟项目组用webpy,被我们组拿来主义,直接用了;第二个是我可能当时不知道有其他框架,因为刚工作,知识面有限。但是不管怎么样,webpy还是好用的,所有API的URL和class在一个文件中进行映射,可以很方便地查找某个class是为了哪个API服务的。(webpy的其中一个作者是Aaron Swartz,这是个牛掰的小伙,英年早逝)
这里对webpy、flask、bottle性能进行了测试,测试结果详见:webpy/flask/bottle性能测试
wsgi,这是python开发中经常遇到词(以前只管用了,趁写博客之际,好好学习下细节)。
wsgi协议
WSGI的官方文档参考http://www.python.org/dev/peps/pep-3333/。WSGI是the Python Web Server Interface,它的作用是在协议之间进行转换。WSGI是一个桥梁,一边是web服务器(web server),一边是用户的应用(wsgi app)。但是这个桥梁功能非常简单,有时候还需要别的桥(wsgi middleware)进行帮忙处理,下图说明了wsgi这个桥梁的关系。
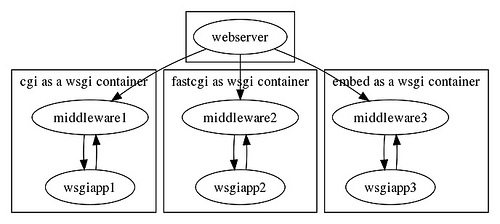
一个简单的WSGI应用:
def simple_app(environ, start_response):"""Simplest possible application object"""status = '200 OK'response_headers = [('Content-type', 'text/plain')]start_response(status, response_headers)return [HELLO_WORLD]这个是最简单的WSGI应用,那么两个参数environ,start_response是什么?
evniron是一系列环境变量,参考https://www.python.org/dev/peps/pep-3333/#id24,用于表示HTTP请求信息。(为了让理解更具体一点,下表给出一个例子,这是uWSGI传递给wsgi app的值)
{'wsgi.multiprocess': True,'SCRIPT_NAME': '','REQUEST_METHOD': 'GET','UWSGI_ROUTER': 'http','SERVER_PROTOCOL': 'HTTP/1.1','QUERY_STRING': '','x-wsgiorg.fdevent.readable': <built-infunctionuwsgi_eventfd_read>,'HTTP_USER_AGENT': 'curl/7.19.7(x86_64-unknown-linux-gnu)libcurl/7.19.7NSS/3.12.7.0zlib/1.2.3libidn/1.18libssh2/1.2.2','SERVER_NAME': 'localhost.localdomain','REMOTE_ADDR': '127.0.0.1','wsgi.url_scheme': 'http','SERVER_PORT': '7012','uwsgi.node': 'localhost.localdomain','uwsgi.core': 1023,'x-wsgiorg.fdevent.timeout': None,'wsgi.input': <uwsgi._Inputobjectat0x7f287dc81e88>,'HTTP_HOST': '127.0.0.1: 7012','wsgi.multithread': False,'REQUEST_URI': '/index.html','HTTP_ACCEPT': '*/*','wsgi.version': (1, 0),'x-wsgiorg.fdevent.writable': <built-infunctionuwsgi_eventfd_write>,'wsgi.run_once': False,'wsgi.errors': <openfile'wsgi_errors', mode'w'at0x2fd46f0>,'REMOTE_PORT': '56294','uwsgi.version': '1.9.10','wsgi.file_wrapper': <built-infunctionuwsgi_sendfile>,'PATH_INFO': '/index.html'
}
start_response是个函数对象,参考https://www.python.org/dev/peps/pep-3333/#id26,其定义为为start_response(status, response_headers, exc_info=None),其作用是设置HTTP status码(如200 OK)和返回结果头部。
WSGI服务器
wsgi服务器就是为了构建一个让WSGI app运行的环境。运行时需要传入正确的参数,以及正确地返回结果,最终把结果返回客户端。工作流程大致是,获取客户端的request信息,封装到environ参数,然后把执行结果返回给客户端。
对于webpy而言,其内置了一个CherryPy服务器。CheckPy在运行时,采用多线程模式,主线程负责accept客户端请求,将请求放入一个request Queue里面,然后有N个子线程负责从Queue中取出request,然后处理后将结果返回给客户端。不过看起来,这个内置的服务器看起来是为了开发调试用,因为webpy并未开放这个默认容器的参数调节,例如线程数目,所以为了寻求高效地托管WSGI app,不建议用这个默认的容器。这可能也是使用uWSGI的原因,因为我们的线上系统有几个API的访问量很大,目前大概是250万次/天。(当然对于业务量不是很大的服务,可能这个默认的CheckPy也就够了)
uWSGI
我们知道,Python有把大锁GIL,会将多个线程退化为串行执行,所以一个多线程python进程,并不能充分使用多核CPU资源,所以对于Python进程,可能采用多进程部署方式比较有利于充分利用多核的CPU资源。
uWSGI就是这么一个项目,可以以多进程方式执行WSGI app,其工作模式为 1 master进程 + N worker进程(N*m线程),主进程负责accept客户端request,然后将请求转发给worker进程,因此最终是worker进程负责处理客户端request,这样很方便的将WSGI app以多进程方式进行部署。以下给出uwsgi响应客户端请求的执行流程图:
![]() 值得注意的是,在master进程接收到客户端请求时,以round-bin方式分发给worker进程,所以多个process在处理前端请求时,所承受的负载相对还是均衡的。(这是我测试时的经验,改天再扒一下uwsgi的源代码确认一下 TODO)。关于uWSGI的使用,可能并不是这里的重点,不再赘述。
值得注意的是,在master进程接收到客户端请求时,以round-bin方式分发给worker进程,所以多个process在处理前端请求时,所承受的负载相对还是均衡的。(这是我测试时的经验,改天再扒一下uwsgi的源代码确认一下 TODO)。关于uWSGI的使用,可能并不是这里的重点,不再赘述。
(其实看到uWSGI的多进程模型,我想到了Nginx,它也是多进程模型,这个也很有意思,由此了解了thunder herd问题,扯远了,继续往下说)
考虑一个应用场景:client向serverM(uwsgi)发起一个HTTP请求,serverM在处理这次请求时,需要访问另一个服务器serverN,直到serverN返回数据,serverM才会返回结果给client,即wsgi app是同步的。假如serverM访问serverN花费时间比较久,那么若是client请求数量比较多的情况下,(N*m)线程都会被占用,可想而知,大容量下的并发处理能力就受(N*m)的限制。
如果碰上了这种情况,怎么解决呢?
(1)增大N,即worker的数量:在增加进程的数量的时候,进程是要消耗内存的,并且如果进程数量太多的情况下(并且进程均处于活跃状态),进程间的切换会消耗系统资源的,所以N并不是越大越好。一般情况下,可能将进程数目设置为CPU数量的2倍。
(2)增大m,即worker的线程数量:在创建线程的时候,最大能够多大呢?由于线程栈是要消耗内存的,因此线程的数量跟系统设置(virtual memory)和(stack size)有关。线程数量太大会不会不太好?(这个肯定不好,我答不上来 TODO)
由此在大并发需求的情况下,我了解到了C10K问题,并进一步学习到I/O的多路复用的epoll,可以避免阻塞调用在某个socket上。比如libevent就是封装了多个平台的高效地I/O多路复用方法,在linux上用的就是epoll。但是这里我们不讨论epoll或者libevent的使用,我们这里引入gevent模块。
gevent协程
gevent在使用时,跟thread的接口很像,但是thread是由操作系统负责调度,而gevent是用户态的“线程”,也叫协程。gevent的好处就是无需等待I/O,当发生I/O调用是,gevent会主动切换到另一gevent进行运行,这样在等待socket数据返回时,可以充分利用CPU资源。
在使用gevent内部实现:
1. gevent 协程切换使用greenlet项目,greenlet其实就是一个函数,及保存函数的上下文(也就是栈),greenlet的切换由应用程序自己控制,所以非常适合对于I/O型的应用程序,发生I/O时就切换,这样能够充分利用CPU资源。
2. gevent在监控socket事件时,使用了libevent,就是高级的epoll。
3. python中有个猴子补丁(monkey patch)的说法,在python进程中,python的函数都是对象,存在于进程的全局字典中,因此,开发者可以通过替换这些对象,来改变标准库函数的实现,这样还不用修改已有的应用程序。在gevent里,也有这样的monkey patch,通过gevent.monkey.patch_all()替换掉了标准库中阻塞的模块,这样不用修改应用程序就能充分享受gevent的优势了。(真是方便啊)
使用gevent需注意的问题
1. 无意识地引入阻塞模块
我们知道gevent通过monkey patch替换掉了标准库中阻塞的模块,但是有的时候可能我们会“无意识”地引入阻塞模块,例如MySQL-Python,pylibmc。这两个模块是通过C扩展程序实现的,都需要进行socket通信,由于调用的底层C的socket接口,所以超出了gevent的管控范围,这样就在使用这两个模块跟mysql或者memcached进行通信时,就退化为了阻塞调用。
这样一个应用场景:在一个gevent进程中,基于MySQL-Python模块,创建一个跟mysql有10个连接的连接池,当并发量大的情况下,我们期望这10个连接可以同时处理对mysql的10个请求。实际如我们期望的这样么?的确跟期望不一样,因为在conn.query()的时候,阻塞了进程,这样意味着同一时刻不可能同时有2个对mysql的访问,所以并发不起来了。如mysql响应很慢的话,那么整个process跟hang住了没什么两样(这个时候,便不如多线程的部署模式了,因为多个线程的话,一个线程hang住,另一个线程还是有机会执行的)。
如何解决:在这些需要考虑并发的效率的场景,尽量避免引入阻塞模块,可以考虑纯python实现的模块,例如MySQL-Python->pymysql, pylibmc->memcached(这个python实现的memcached client可能不太完备,例如一致性hash目前都没实现)。
2. gevent在遇到I/O访问时,会进行greenlet切换。若是某个greenlet需要占用大量计算,那么若是计算任务过多(激进一点,陷入死循环),可能会导致其他greenlet没有机会执行。若是一个gevent进程需要执行多个任务时,若某个任务计算过多,可能会影响其他任务的执行。例如我曾遇到一个进程中,采用生产者任务(统计数据,将结果放入内存)+消费者任务(将计算结果写入磁盘),然而当数据很大的时候,生产者任务占用大量的CPU资源,然而消费者任务不能及时将统计结果写入磁盘,即生产太快,消费太慢,这样内存占用越来越多,一度高达2G内存。所以鉴于此,需要根据任务的特点(I/O密集或者CPU密集),合理分配进程任务。
参考:
https://www.python.org/dev/peps/pep-3333/
http://www.oschina.net/question/12_26400
http://blog.jobbole.com/77240/
http://www.tuicool.com/articles/2aIZZb
以上为工作经验总结,在整理成文的时候,才发现有些知识点只是一知半解,所以需要继续完善该文。
转载于:https://www.cnblogs.com/figo-cui/articles/5058565.html
高并发异步uwsgi+web.py+gevent相关推荐
- python websocket异步高并发_高并发异步uwsgi+web.py+gevent
为什么用web.py? python的web框架有很多,比如webpy.flask.bottle等,但是为什么我们选了webpy呢?想了好久,未果,硬要给解释,我想可能原因有两个:第一个是兄弟项目组用 ...
- 【flask】适合生产环境的高并发部署方案(gunicorn + gevent + supervisor)
文章目录 1.安装docker镜像 2.查看alphin版本 3.更换alpine源 4.更换pip源 5.安装requirements.txt 6.安装完成 7.启动flask应用 8.用gunic ...
- workerman高并发异步mysql_workerman怎么实现高并发
并发概念太模糊,这里以两种可以量化的指标并发连接数和并发请求数来说明. 并发连接数是指服务器当前时刻一共维持了多少TCP连接,而这些连接上是否有数据通讯并不关注. (推荐学习: workerman教程 ...
- 一个可供参考的Java高并发异步应用案例--转
原文地址:http://chuansong.me/n/355827651252 泰康在线微信公众号系泰康在线财产保险股份有限公司旗下平台,希望可以通过持续不断的创新,提升客户对于保险的认知及体验,通过 ...
- 支持高并发的IIS Web服务器常用设置
转一篇站长大人的文章 适用的IIS版本:IIS 7.0, IIS 7.5, IIS 8.0 适用的Windows版本:Windows Server 2008, Windows Server 2008 ...
- python链家网高并发异步爬虫asyncio+aiohttp+aiomysql异步存入数据
python链家网二手房异步IO爬虫,使用asyncio.aiohttp和aiomysql 很多小伙伴初学python时都会学习到爬虫,刚入门时会使用requests.urllib这些同步的库进行单线 ...
- python链家网高并发异步爬虫and异步存入数据
python链家网二手房异步IO爬虫,使用asyncio.aiohttp和aiomysql 很多小伙伴初学python时都会学习到爬虫,刚入门时会使用requests.urllib这些同步的库进行单线 ...
- aiohttp保存MySQL_python链家网高并发异步爬虫asyncio+aiohttp+aiomysql异步存入数据
python链家网二手房异步IO爬虫,使用asyncio.aiohttp和aiomysql 很多小伙伴初学python时都会学习到爬虫,刚入门时会使用requests.urllib这些同步的库进行单线 ...
- 前端调用mysql异步_python链家网高并发异步爬虫asyncio+aiohttp+aiomysql异步存入数据...
python链家网二手房异步IO爬虫,使用asyncio.aiohttp和aiomysql 很多小伙伴初学python时都会学习到爬虫,刚入门时会使用requests.urllib这些同步的库进行单线 ...
最新文章
- 代码实现UISlider 和 UISwitch
- C++中的4个类型转换关键字
- day53-Django之路由系统
- 快手直播怎么下载?一键轻松下载直播
- 预充电电路工作原理_变频器整流回路 为什么要预充电电路-工业支持中心-西门子中国...
- 性能测试:手机IOS性能测试
- 16.转圈圈报数游戏
- 2020微信对话截图生成器,各种截图一键制作!
- ubuntu 使用代理服务器 squid
- [Vijos]P1788 第k大
- 零基础的小明要如何成为前端工程师?
- testin云测操作步骤
- MPLS和LDP基本配置
- YYImage实现思路源码分析(图片解压缩原理)
- 社交网络:有意义的不仅是邓巴数
- C语言·XDOJ练习·股票计算
- Shader Graph 小草顶点动画
- SnnGrow快讯:微软 Win7/8.1 今日结束支持,不会再获得安全更新、AI工程化进程加速,人工智能需要怎样的数据?
- 密码必须符合复杂性要求
- 【转】四年记——身在中小企业
热门文章
- OpenGL ES SDK for Android - 4
- trafficserver records.config参数说明
- linux下修改当前目录下图像文件并删除
- Command(命令模式)
- Eclipse europa 更新时 Error retrieving feature.xml. [error in opening zip file]的解决
- linux python开发环境sql数据迁移到mysql_运用Python语言编写获取Linux基本系统信息(三):Python与数据库编程,把获取的信息存入数据库...
- golang new和make却别
- ios端input 光标问题
- Spring Cloud 微服务实战系列-Spring Boot再次入门(二)
- linux设备驱动编写基础