阿里巴巴为什么选择Apache Flink?
本文主要整理自阿里巴巴计算平台事业部资深技术专家莫问在云栖大会的演讲。
合抱之木,生于毫末
随着人工智能时代的降临,数据量的爆发,在典型的大数据的业务场景下数据业务最通用的做法是:选用批处理的技术处理全量数据,采用流式计算处理实时增量数据。在绝大多数的业务场景之下,用户的业务逻辑在批处理和流处理之中往往是相同的。但是,用户用于批处理和流处理的两套计算引擎是不同的。
因此,用户通常需要写两套代码。毫无疑问,这带来了一些额外的负担和成本。阿里巴巴的商品数据处理就经常需要面对增量和全量两套不同的业务流程问题,所以阿里就在想,我们能不能有一套统一的大数据引擎技术,用户只需要根据自己的业务逻辑开发一套代码。这样在各种不同的场景下,不管是全量数据还是增量数据,亦或者实时处理,一套方案即可全部支持,这就是阿里选择Flink的背景和初衷。
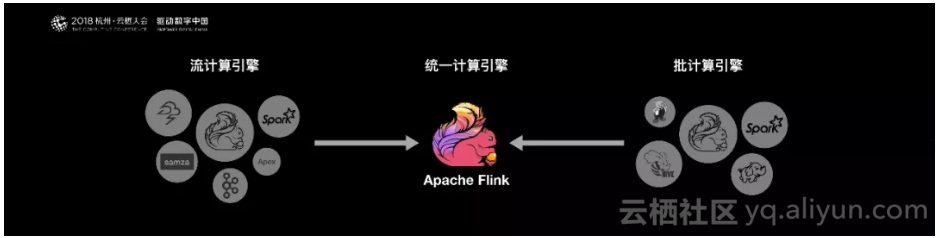
从技术,生态等各方面的综合考虑。首先,Spark的技术理念是基于批来模拟流的计算。而Flink则完全相反,它采用的是基于流计算来模拟批计算。
从技术发展方向看,用批来模拟流有一定的技术局限性,并且这个局限性可能很难突破。而Flink基于流来模拟批,在技术上有更好的扩展性。从长远来看,阿里决定用Flink做一个统一的、通用的大数据引擎作为未来的选型。
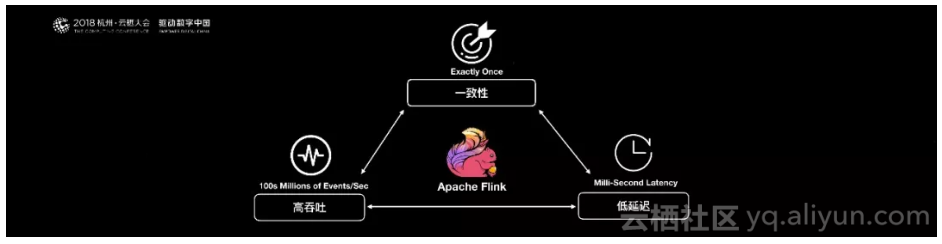
Flink是一个低延迟、高吞吐、统一的大数据计算引擎。在阿里巴巴的生产环境中,Flink的计算平台可以实现毫秒级的延迟情况下,每秒钟处理上亿次的消息或者事件。同时Flink提供了一个Exactly-once的一致性语义。保证了数据的正确性。这样就使得Flink大数据引擎可以提供金融级的数据处理能力。
Flink在阿里的现状
基于Apache Flink在阿里巴巴搭建的平台于2016年正式上线,并从阿里巴巴的搜索和推荐这两大场景开始实现。目前阿里巴巴所有的业务,包括阿里巴巴所有子公司都采用了基于Flink搭建的实时计算平台。同时Flink计算平台运行在开源的Hadoop集群之上。采用Hadoop的YARN做为资源管理调度,以 HDFS作为数据存储。因此,Flink可以和开源大数据软件Hadoop无缝对接。
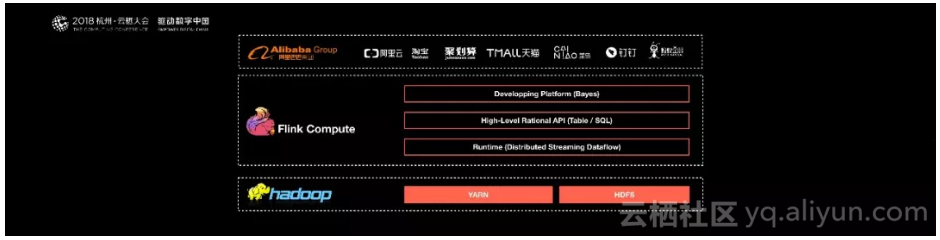
目前,这套基于Flink搭建的实时计算平台不仅服务于阿里巴巴集团内部,而且通过阿里云的云产品API向整个开发者生态提供基于Flink的云产品支持。
Flink在阿里巴巴的大规模应用,表现如何?
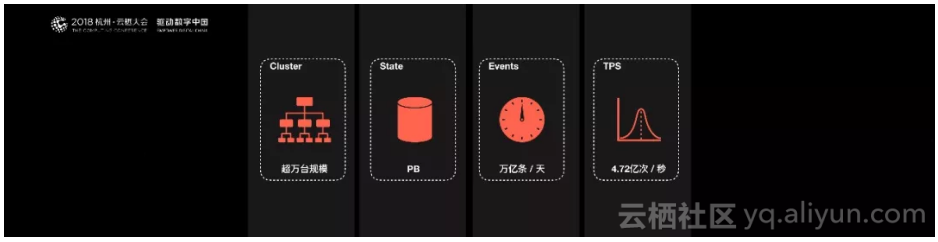
规模:一个系统是否成熟,规模是重要指标,Flink最初上线阿里巴巴只有数百台服务器,目前规模已达上万台,此等规模在全球范围内也是屈指可数;
状态数据:基于Flink,内部积累起来的状态数据已经是PB级别规模;
Events:如今每天在Flink的计算平台上,处理的数据已经超过万亿条;
PS:在峰值期间可以承担每秒超过4.72亿次的访问,最典型的应用场景是阿里巴巴双11大屏;
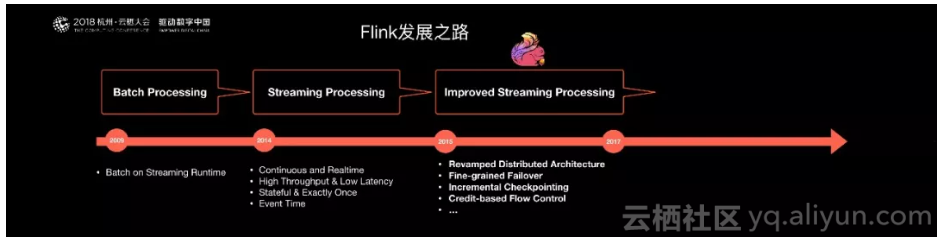
Flink的发展之路
接下来从开源技术的角度,来谈一谈Apache Flink是如何诞生的,它是如何成长的?以及在成长的这个关键的时间点阿里是如何进入的?并对它做出了那些贡献和支持?
Flink诞生于欧洲的一个大数据研究项目StratoSphere。该项目是柏林工业大学的一个研究性项目。早期,Flink是做Batch计算的,但是在2014年,StratoSphere里面的核心成员孵化出Flink,同年将Flink捐赠Apache,并在后来成为Apache的顶级大数据项目,同时Flink计算的主流方向被定位为Streaming,即用流式计算来做所有大数据的计算,这就是Flink技术诞生的背景。

2014年Flink作为主攻流计算的大数据引擎开始在开源大数据行业内崭露头角。区别于Storm,Spark Streaming以及其他流式计算引擎的是:它不仅是一个高吞吐、低延迟的计算引擎,同时还提供很多高级的功能。比如它提供了有状态的计算,支持状态管理,支持强一致性的数据语义以及支持Event Time,WaterMark对消息乱序的处理。
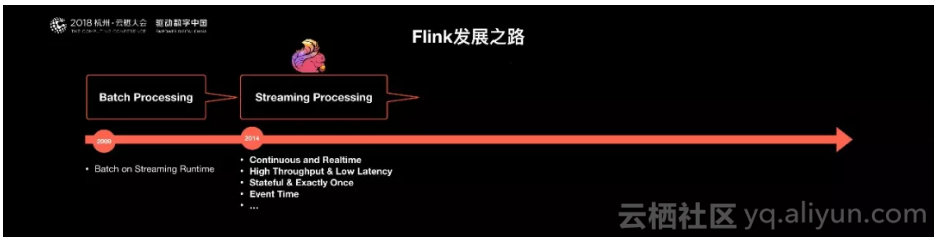
Flink核心概念以及基本理念
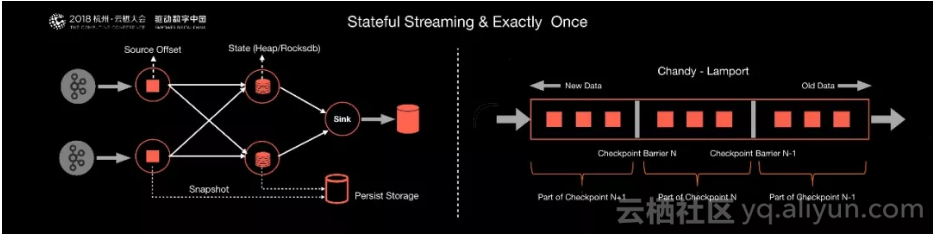
Flink最区别于其他流计算引擎的,其实就是状态管理。
什么是状态?例如开发一套流计算的系统或者任务做数据处理,可能经常要对数据进行统计,如Sum,Count,Min,Max,这些值是需要存储的。因为要不断更新,这些值或者变量就可以理解为一种状态。如果数据源是在读取Kafka,RocketMQ,可能要记录读取到什么位置,并记录Offset,这些Offset变量都是要计算的状态。
Flink提供了内置的状态管理,可以把这些状态存储在Flink内部,而不需要把它存储在外部系统。这样做的好处是第一降低了计算引擎对外部系统的依赖以及部署,使运维更加简单;第二,对性能带来了极大的提升:如果通过外部去访问,如Redis,HBase它一定是通过网络及RPC。如果通过Flink内部去访问,它只通过自身的进程去访问这些变量。同时Flink会定期将这些状态做Checkpoint持久化,把Checkpoint存储到一个分布式的持久化系统中,比如HDFS。这样的话,当Flink的任务出现任何故障时,它都会从最近的一次Checkpoint将整个流的状态进行恢复,然后继续运行它的流处理。对用户没有任何数据上的影响。
Flink是如何做到在Checkpoint恢复过程中没有任何数据的丢失和数据的冗余?来保证精准计算的?
这其中原因是Flink利用了一套非常经典的Chandy-Lamport算法,它的核心思想是把这个流计算看成一个流式的拓扑,定期从这个拓扑的头部Source点开始插入特殊的Barries,从上游开始不断的向下游广播这个Barries。每一个节点收到所有的Barries,会将State做一次Snapshot,当每个节点都做完Snapshot之后,整个拓扑就算完整的做完了一次Checkpoint。接下来不管出现任何故障,都会从最近的Checkpoint进行恢复。
下面介绍Flink是如何解决乱序问题的。比如星球大战的播放顺序,如果按照上映的时间观看,可能会发现故事在跳跃。
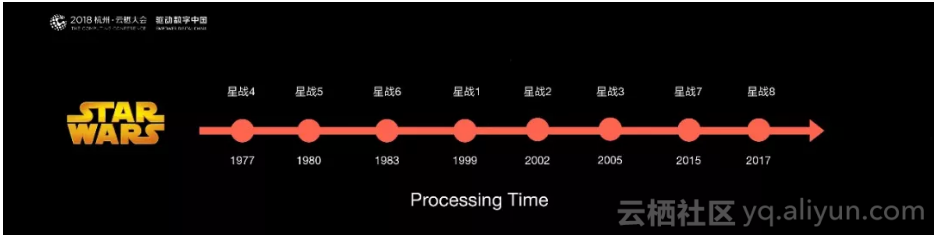
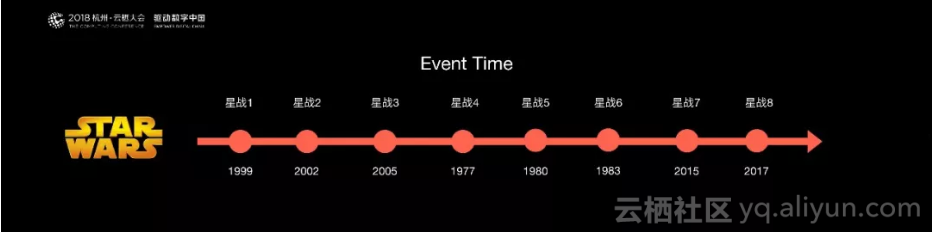
在流计算中,与这个例子是非常类似的。所有消息到来的时间,和它真正发生在源头,在线系统Log当中的时间是不一致的。在流处理当中,希望是按消息真正发生在源头的顺序进行处理,不希望是真正到达程序里的时间来处理。Flink提供了Event Time和WaterMark的一些先进技术来解决乱序的问题。使得用户可以有序的处理这个消息。这是Flink一个很重要的特点。
接下来要介绍的是Flink启动时的核心理念和核心概念,这是Flink发展的第一个阶段;第二个阶段时间是2015年和2017年,这个阶段也是Flink发展以及阿里巴巴介入的时间。故事源于2015年年中,我们在搜索事业部的一次调研。当时阿里有自己的批处理技术和流计算技术,有自研的,也有开源的。但是,为了思考下一代大数据引擎的方向以及未来趋势,我们做了很多新技术的调研。
结合大量调研结果,我们最后得出的结论是:解决通用大数据计算需求,批流融合的计算引擎,才是大数据技术的发展方向,并且最终我们选择了Flink。
但2015年的Flink还不够成熟,不管是规模还是稳定性尚未经历实践。最后我们决定在阿里内部建立一个Flink分支,对Flink做大量的修改和完善,让其适应阿里巴巴这种超大规模的业务场景。在这个过程当中,我们团队不仅对Flink在性能和稳定性上做出了很多改进和优化,同时在核心架构和功能上也进行了大量创新和改进,并将其贡献给社区,例如:Flink新的分布式架构,增量Checkpoint机制,基于Credit-based的网络流控机制和Streaming SQL等。
阿里巴巴对Flink社区的贡献
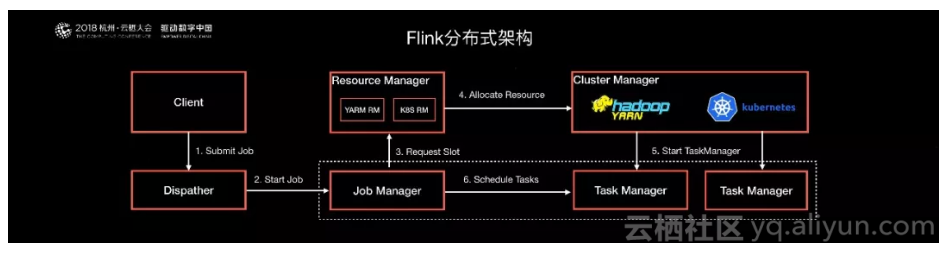
我们举两个设计案例,第一个是阿里巴巴重构了Flink的分布式架构,将Flink的Job调度和资源管理做了一个清晰的分层和解耦。这样做的首要好处是Flink可以原生的跑在各种不同的开源资源管理器上。经过这套分布式架构的改进,Flink可以原生地跑在Hadoop Yarn和Kubernetes这两个最常见的资源管理系统之上。同时将Flink的任务调度从集中式调度改为了分布式调度,这样Flink就可以支持更大规模的集群,以及得到更好的资源隔离。
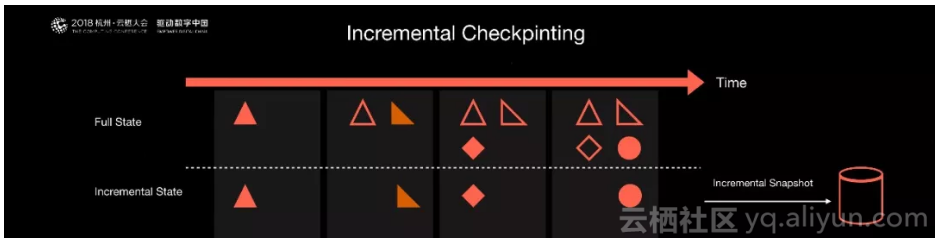
另一个是实现了增量的Checkpoint机制,因为Flink提供了有状态的计算和定期的Checkpoint机制,如果内部的数据越来越多,不停地做Checkpoint,Checkpoint会越来越大,最后可能导致做不出来。提供了增量的Checkpoint后,Flink会自动地发现哪些数据是增量变化,哪些数据是被修改了。同时只将这些修改的数据进行持久化。这样Checkpoint不会随着时间的运行而越来越难做,整个系统的性能会非常地平稳,这也是我们贡献给社区的一个很重大的特性。
经过2015年到2017年对Flink Streaming的能力完善,Flink社区也逐渐成熟起来。Flink也成为在Streaming领域最主流的计算引擎。因为Flink最早期想做一个流批统一的大数据引擎,2018年已经启动这项工作,为了实现这个目标,阿里巴巴提出了新的统一API架构,统一SQL解决方案,同时流计算的各种功能得到完善后,我们认为批计算也需要各种各样的完善。无论在任务调度层,还是在数据Shuffle层,在容错性,易用性上,都需要完善很多工作。
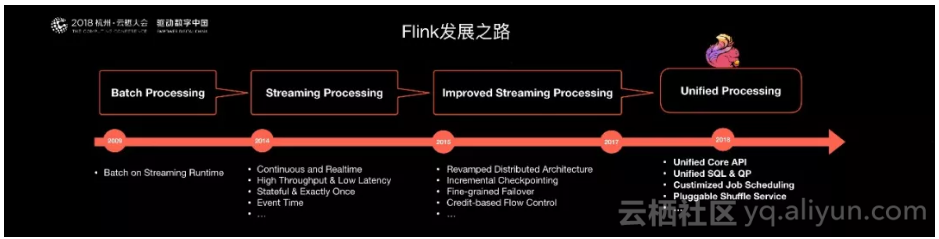
篇幅原因,下面主要和大家分享两点:
● 统一 API Stack
● 统一 SQL方案
先来看下目前Flink API Stack的一个现状,调研过Flink或者使用过Flink的开发者应该知道。Flink有2套基础的API,一套是DataStream,一套是DataSet。DataStream API是针对流式处理的用户提供,DataSet API是针对批处理用户提供,但是这两套API的执行路径是完全不一样的,甚至需要生成不同的Task去执行。所以这跟得到统一的API是有冲突的,而且这个也是不完善的,不是最终的解法。在Runtime之上首先是要有一个批流统一融合的基础API层,我们希望可以统一API层。
因此,我们在新架构中将采用一个DAG(有限无环图)API,作为一个批流统一的API层。对于这个有限无环图,批计算和流计算不需要泾渭分明的表达出来。只需要让开发者在不同的节点,不同的边上定义不同的属性,来规划数据是流属性还是批属性。整个拓扑是可以融合批流统一的语义表达,整个计算无需区分是流计算还是批计算,只需要表达自己的需求。有了这套API后,Flink的API Stack将得到统一。
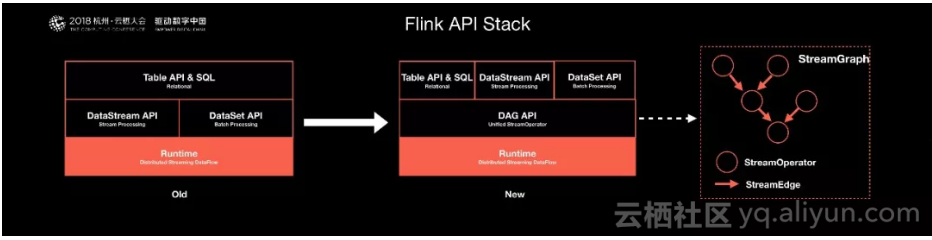
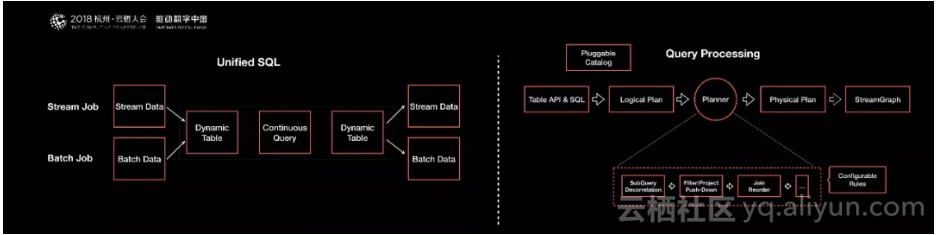
除了统一的基础API层和统一的API Stack外,同样在上层统一SQL的解决方案。流和批的SQL,可以认为流计算有数据源,批计算也有数据源,我们可以将这两种源都模拟成数据表。可以认为流数据的数据源是一张不断更新的数据表,对于批处理的数据源可以认为是一张相对静止的表,没有更新的数据表。整个数据处理可以当做SQL的一个Query,最终产生的结果也可以模拟成一个结果表。
对于流计算而言,它的结果表是一张不断更新的结果表。对于批处理而言,它的结果表是相当于一次更新完成的结果表。从整个SOL语义上表达,流和批是可以统一的。此外,不管是流式SQL,还是批处理SQL,都可以用同一个Query来表达复用。这样以来流批都可以用同一个Query优化或者解析。甚至很多流和批的算子都是可以复用的。
Flink的未来方向
首先,阿里巴巴还是要立足于Flink的本质,去做一个全能的统一大数据计算引擎。将它在生态和场景上进行落地。目前Flink已经是一个主流的流计算引擎,很多互联网公司已经达成了共识:Flink是大数据的未来,是最好的流计算引擎。下一步很重要的工作是让Flink在批计算上有所突破。在更多的场景下落地,成为一种主流的批计算引擎。然后进一步在流和批之间进行无缝的切换,流和批的界限越来越模糊。用Flink,在一个计算中,既可以有流计算,又可以有批计算。
第二个方向就是Flink的生态上有更多语言的支持,不仅仅是Java,Scala语言,甚至是机器学习下用的Python,Go语言。未来我们希望能用更多丰富的语言来开发Flink计算的任务,来描述计算逻辑,并和更多的生态进行对接。

最后不得不说AI,因为现在很多大数据计算的需求和数据量都是在支持很火爆的AI场景,所以在Flink流批生态完善的基础上,将继续往上走,完善上层Flink的Machine Learning算法库,同时Flink往上层也会向成熟的机器学习,深度学习去集成。比如可以做Tensorflow On Flink, 让大数据的ETL数据处理和机器学习的Feature计算和特征计算,训练的计算等进行集成,让开发者能够同时享受到多种生态给大家带来的好处。
原文发布时间为:2018-10-15
本文作者:莫问
本文来自云栖社区合作伙伴“阿里技术”,了解相关信息可以关注“阿里技术”。
阿里巴巴为什么选择Apache Flink?相关推荐
- 社区活动 | Apache Flink 1.9 版本即将发布,新版本有哪些新特性?
6 月 29 号,Apache Flink 社区 Meetup 北京站即将到来,此次 Meetup 一如既往地邀请了社区多位 Flink 技术专家现场分享.伴随着 Apache Flink 1.9 版 ...
- flink入门_阿里巴巴为何选择Flink?20年大佬分11章讲解Flink从入门到实践!
前言 Apache Flink 是德国柏林工业大学的几个博士生和研究生从学校开始做起来的项目,之前叫做 Stratosphere.他们在2014 年开源了这个项目,起名为 Flink. Apache ...
- 如何在 Apache Flink 中使用 Python API?
本文根据 Apache Flink 系列直播课程整理而成,由 Apache Flink PMC,阿里巴巴高级技术专家 孙金城 分享.重点为大家介绍 Flink Python API 的现状及未来规划, ...
- Apache Flink新场景——OLAP引擎
最近我们也正打算做OLAP分析平台,在调研的过程中,发现已有的成熟技术只能满足我们的部分需求,相信大家也有这样的困惑,本文分享的是来自阿里巴巴集团的技术专家贺小令分享为什么选择使用 Flink 作为新 ...
- Apache Flink OLAP引擎性能优化及应用
精选30+云产品,助力企业轻松上云!>>> 摘要:最近我们也正打算做OLAP分析平台,在调研的过程中,发现已有的成熟技术只能满足我们的部分需求,相信大家也有这样的困惑,本文分享的是来 ...
- python flink_如何在 Apache Flink 中使用 Python API?
原标题:如何在 Apache Flink 中使用 Python API? 导读:本文重点为大家介绍 Flink Python API 的现状及未来规划,主要内容包括:Apache Flink Pyth ...
- 阿里正式向 Apache Flink 贡献 Blink 源码
导读: 如同我们去年12月在 Flink Forward China 峰会所约,阿里巴巴内部 Flink 版本 Blink 将于 2019 年 1 月底正式开源.今天,我们终于等到了这一刻. 阿里资深 ...
- 修改代码150万行!Apache Flink 1.9.0做了这些重大修改!(附链接)
来源:阿里技术 本文约4100字,建议阅读8分钟. 本文为你介绍 Flink 1.9.0 中非常值得关注的重要功能与特性. [ 导读 ] 8月22日,Apache Flink 1.9.0 正式发布.早 ...
- 近期活动盘点:首届Apache Flink 极客挑战赛、2019年社会计算机国际会议
想知道近期有什么最新活动?大数点为你整理的近期活动信息在此: 7 月 24 日,阿里云峰会上海开发者大会开源大数据专场,阿里巴巴集团副总裁.计算平台事业部总裁贾扬清与英特尔高级首席工程师.大数据分析和 ...
最新文章
- 泰坦尼克号幸存率研究
- 用了这么多年的泛型,你对它到底有多了解?
- java项目遇到的问题_java系列:项目中遇到的一些问题(持续更新中)
- hprose java 下载_Hprose Java|Hprose For Java下载v2017.2.0官方版 附使用教程 - 欧普软件下载...
- 7.1 elementui的radio无法选中问题
- 查linux有哪些task_浅谈Linux线程模型
- postman测试登录后的接口_中文版Postman测试需要登陆才能访问的接口(基于Cookie)...
- linux创建raid5分区,linux RAID5 创建过程以及raid5扩容步骤(软raid)
- linux时间调整为dst,禁用Linux中的夏令时(DST)更改
- pycharm自动调整格式_PyCharm开发Django,好玩么?
- iOS:懒加载符号绑定流程
- Less变量动态修改
- python 图片验证码
- oracle请求输出全部都是fndwrr,oracle ebs系统维护技巧汇总
- python实现局域网攻击软件_使用python的scapy库进行局域网内的断网攻击(基于ARP协议)...
- vue地址栏隐藏id 隐藏参数
- 神经主题模型及应用(Neural Topic Model)
- IEEE PHM 2012挑战赛的轴承数据集及预处理程序(MATLAB代码)
- 上瘾:让用户养成使用习惯的四大产品逻辑
- ubuntu切换独立显卡的方法