Apache Flink OLAP引擎性能优化及应用
精选30+云产品,助力企业轻松上云!>>> 
摘要:最近我们也正打算做OLAP分析平台,在调研的过程中,发现已有的成熟技术只能满足我们的部分需求,相信大家也有这样的困惑,本文分享的是来自阿里巴巴集团的技术专家贺小令分享为什么选择使用 Flink 作为新一代OLAP引擎以及他们是如何优化的。本次分享的主题为Apache Flink新场景——OLAP引擎,主要内容包括:
1.背景介绍
2.Apache Flink OLAP引擎
3.案例介绍
4.未来计划
正文开始。
1. OLAP及其分类

OLAP是一种让用户可以用从不同视角方便快捷的分析数据的计算方法。主流的OLAP可以分为3类:多维OLAP ( Multi-dimensional OLAP )、关系型OLAP ( Relational OLAP ) 和混合OLAP ( Hybrid OLAP ) 三大类。
多维OLAP ( MOLAP ):
传统的OLAP分析方式
数据存储在多维数据集中
关系型OLAP ( ROLAP ):
以关系数据库为核心,以关系型结构进行多维数据的表示
通过SQL的where条件以呈现传统OLAP的切片、切块功能
混合OLAP ( HOLAP ):
将MOLAP和ROLPA的优势结合起来,以获得更快的性能
接下来为大家详细介绍下:
① MOLAP
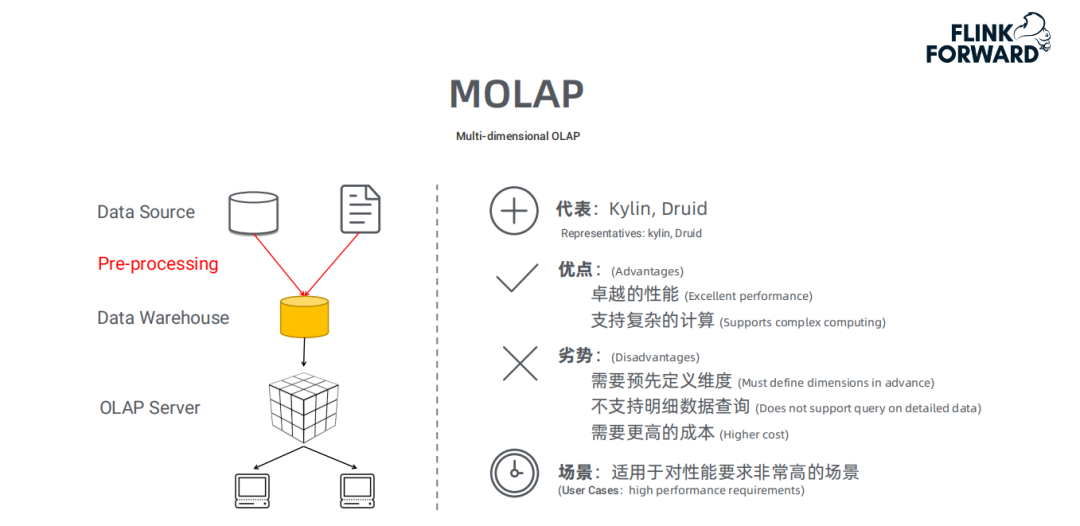
典型代表:
MOLAP的典型代表是Kylin和Druid。
处理流程:
对原始数据做数据预处理
预处理后的数据存至数据仓库
用户的请求通过OLAP server查询数据仓库中的数据
MOLAP的优点和缺点:
MOLAP的优点和缺点都来自于其数据预处理 ( pre-processing ) 环节。数据预处理,将原始数据按照指定的计算规则预先做聚合计算,这样避免了查询过程中出现大量的临时计算,提升了查询性能,同时也为很多复杂的计算提供了支持。
但是这样的预聚合处理,需要预先定义维度,会限制后期数据查询的灵活性;如果查询工作涉及新的指标,需要重新增加预处理流程,损失了灵活度,存储成本也很高;同时,这种方式不支持明细数据的查询。
因此,MOLAP适用于对性能非常高的场景。
② ROLAP
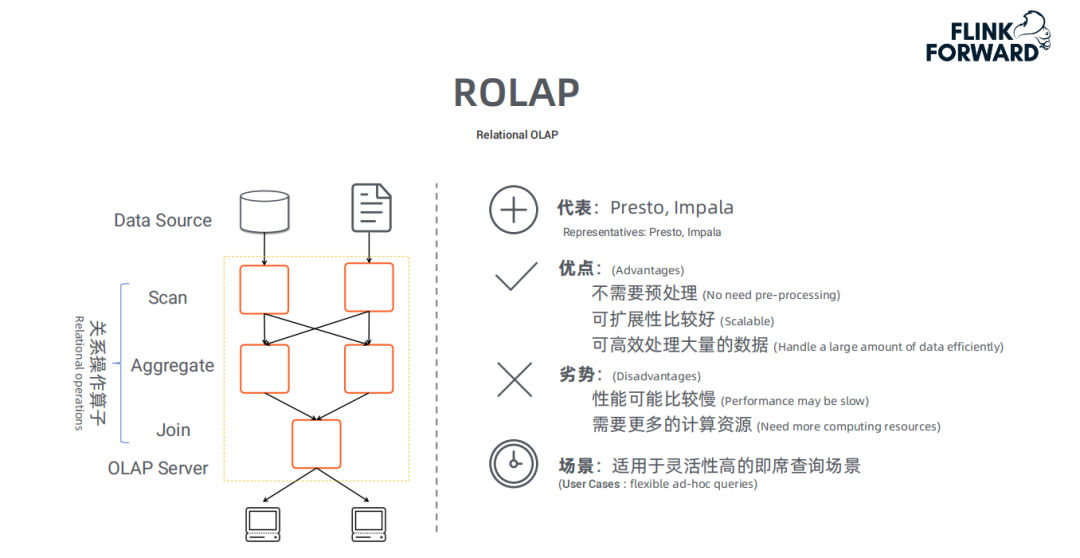
典型代表:
ROLAP的典型代表是Presto和Impala。
处理流程:
用户的请求直接发送给OLAP server
OLAP serve将用户的请求转换成关系型操作算子:
1. 通过SCAN扫描原始数据
2. 在原始数据基础上做过滤、聚合、关联等处理
将计算结果返回给用户
ROLAP的优点和缺点:
ROLAP不需要进行数据预处理 ( pre-processing ),因此查询灵活,可扩展性好。这类引擎使用MPP架构 ( 与Hadoop相似的大型并行处理架构,可以通过扩大并发来增加计算资源 ),可以高效处理大量数据。但是当数据量较大或query较为复杂时,查询性能也无法像MOLAP那样稳定。所有计算都是临时发生 ( 没有预处理 ),因此会耗费更多的计算资源。
因此,ROLAP适用于对查询灵活性高的场景。
③ HOLAP
混合OLAP,是MOLAP和ROLAP的一种融合。当查询聚合性数据的时候,使用MOLAP技术;当查询明细数据时,使用ROLAP技术。在给定使用场景的前提下,以达到查询性能的最优化。
2. Apache Flink介绍
① 当前Apache Flink支持的应用场景
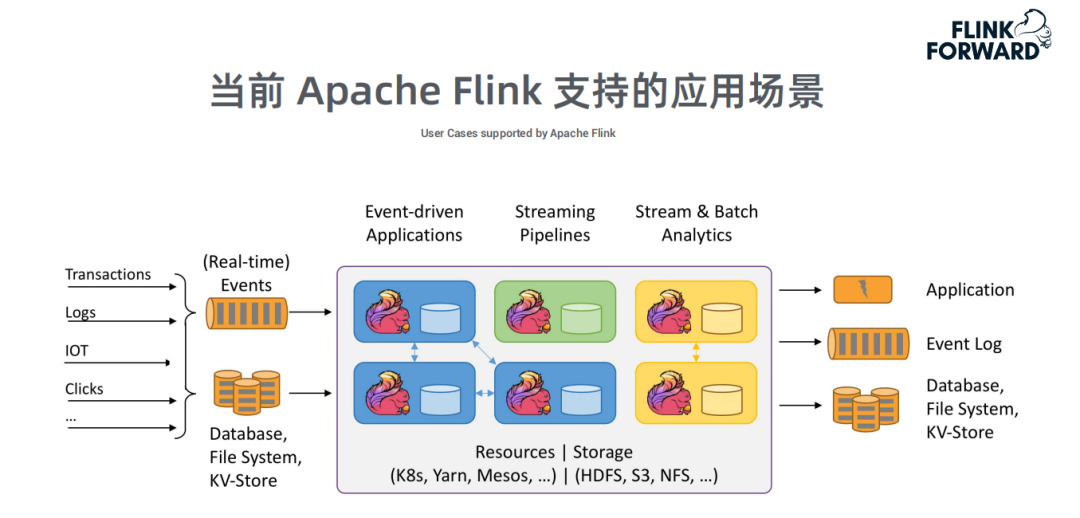
Apache Flink支持的3种典型应用场景:
01. 事件驱动的应用
反欺诈
基于规则的监控报警
02. 流式Pipeline
数据ETL
实时搜索引擎的索引
03. 批处理&流处理分析
网络质量监控
消费者实时数据分析
② Apache Flink 架构
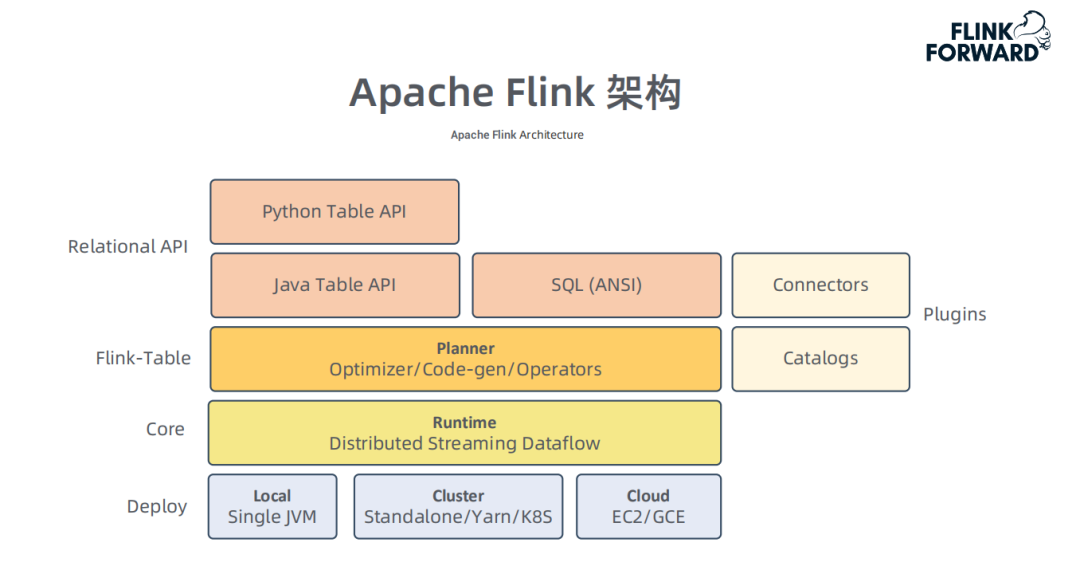
③ Apache Flink 优势

01. 统一框架 ( 不区分流处理和批处理 )
用户API统一
执行引擎统一
02. 多层次API
标准SQL APL
Table API
DataStream API ( 灵活,无schema限制 )
03. 高性能
支持内存计算
支持代价模型优化
支持代码动态生成
04. 方便集成
支持丰富的Connectors
方便对接现有catalog
05. 灵活的Failover策略
在Pipeline下支持快速failover
类似MapReduce、Spark一样支持shuffle数据落盘
06. 易部署维护
灵活部署方案
支持高可用
1. Apache Flink OLAP引擎
① 为什么Apache Flink 可以做ROLAP引擎?
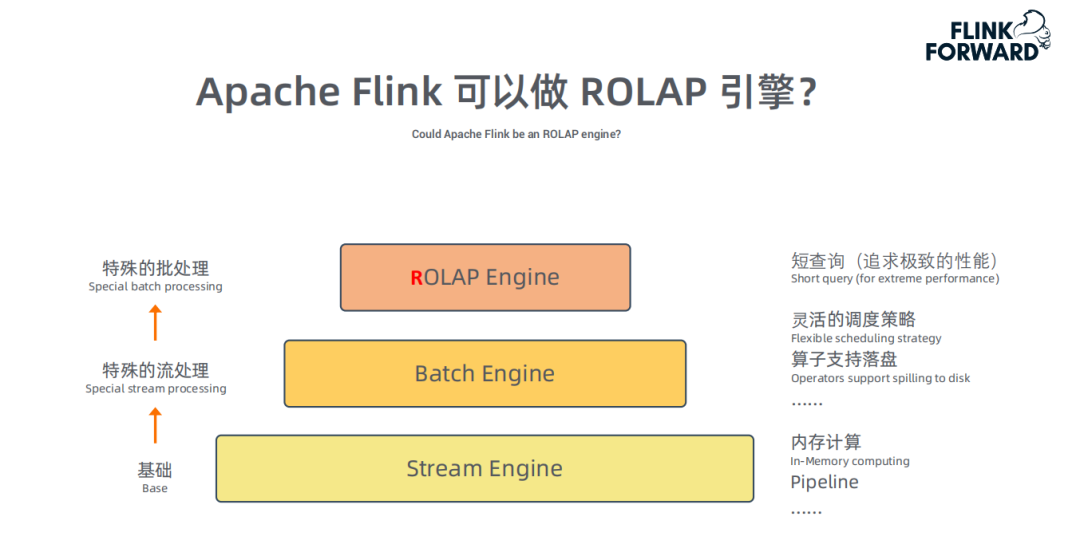
Flink的核心和基础是流计算,支持高性能、低延迟的大规模计算
Blink将批看作有限流,批处理是针对有限数据集的优化,因此批处理引擎也是构建在流引擎上 ( 已开源 )
OLAP是响应时间要求更短的批处理,因此OLAP可以看作是一种特殊的批。OLAP引擎也可以构建在现有的批引擎上
注:Flink OLAP引擎目前不带存储,只是一个计算框架
② Apache Flink 做OLAP引擎的优势

统一引擎:流处理、批处理、OLAP统一使用Flink引擎
降低学习成本,仅需要学习一个引擎
提高开发效率,很多SQL是流批通用
提高维护效率,可以更集中维护好一个引擎
既有优势:利用Flink已有的很多特性,使OLAP使用场景更为广泛
使用流处理的内存计算、Pipeline
支持代码动态生成
也可以支持批处理数据落盘能力
相互增强:OLAP能享有现有引擎的优势,同时也能增强引擎能力
无统计信息场景的优化
开发更高效的算子
使Flink同时兼备流、批、OLAP处理的能力,成为更通用的框架
2. 性能优化
OLAP 对查询时间非常敏感,当前很多组件的性能不满足要求,因此我们对Flink做了很多相关优化。
① 服务架构的优化
客户端服务化:
下图介绍了一条SQL怎么在客户端一步一步变为JobGraph,最终提交给JM:
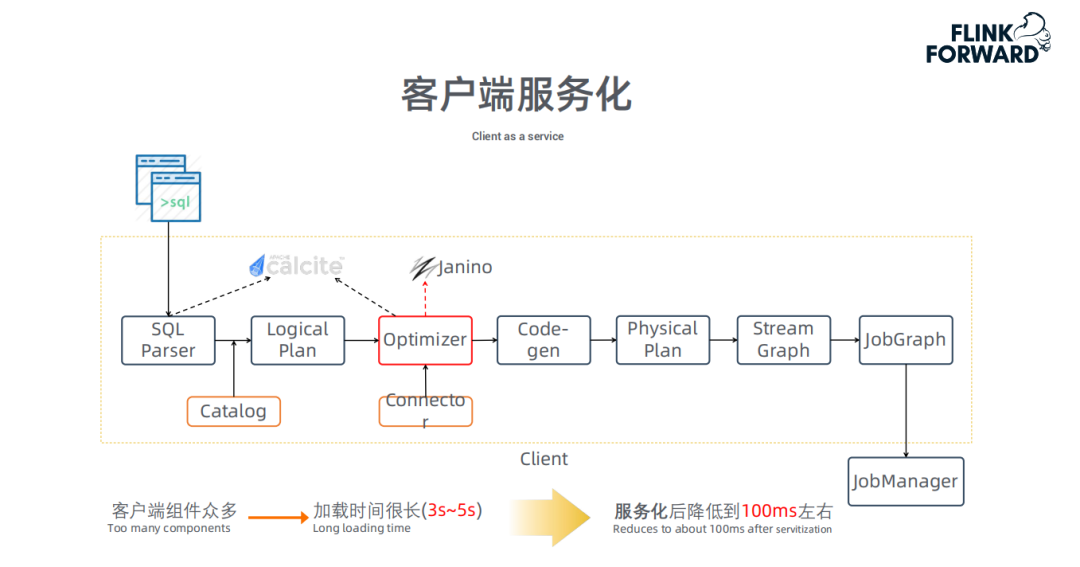
在改动之前,每次接受一个query时会启动一个新的JVM进程来进行作业的编译。其中JVM的启动、Class的加载、代码的动态编译 ( 如Optimizer模块由于需要通过Janino动态编译进行cost计算 ) 等操作都非常耗时 ( 需要约3~5s )。因此,我们将客户端进行服务化,将整个Client做成Service,当接收到用户的query时,无需重复各项加载工作,可将延时降低至100ms 左右。
自定义CollectionTableSink:
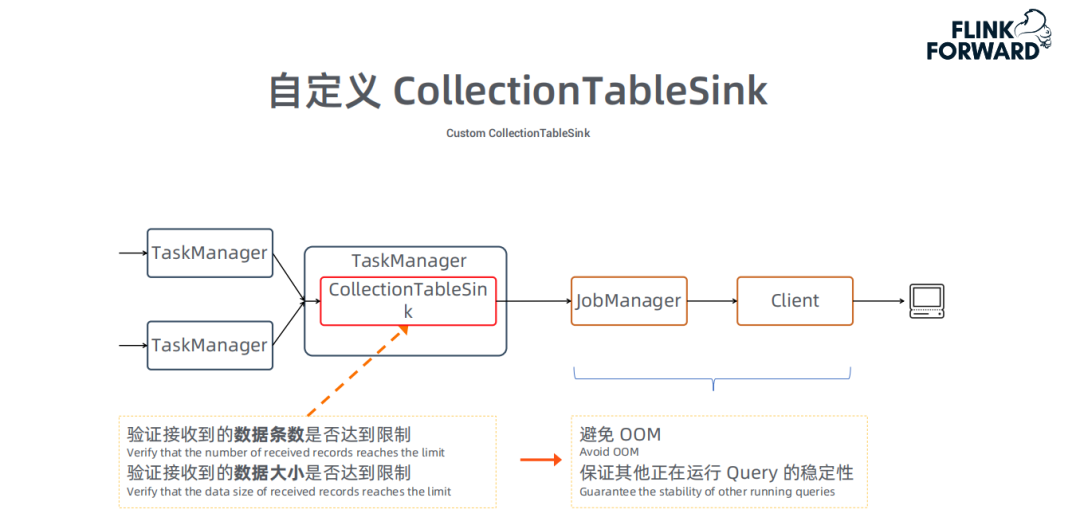
这部分优化,源于OLAP的一个特性:OLAP会将最终计算结果发给客户端,通过JobManager转发给Client。假如某个query的结果数据量很大,会让JobManager OOM ( OutOfMemory );如果同时执行多个query,也会相互影响。因此,我们从新实现了一个CollectionTableSink,限制数据的条数和数据大小,避免出现OOM,保证多个Query同时运行时的稳定性。
调度优化:
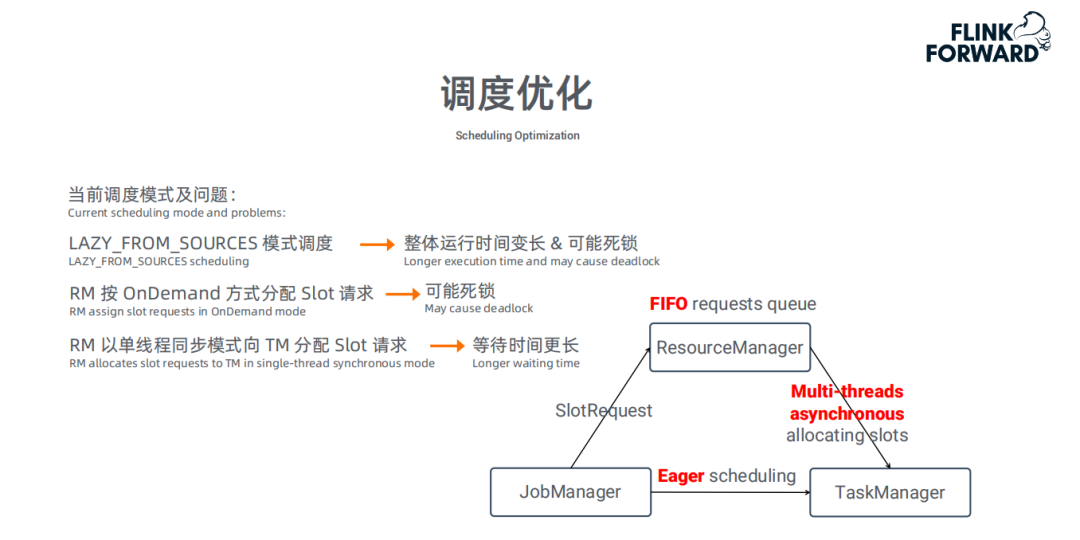
在Batch模式下的调度存在以下问题:
使用Lazy_from_sources模式调度,会导致整体运行时间较长,也可能造成死锁。
注:调度死锁是指在资源有限的情况下,多个Job同时运行时,如果多个Job都只申请到了部分资源并没有剩余资源可以申请,导致Job没法继续执行,新的Job也没法提交
RM ( Resource Manager ) 按OnDemand方式分配Slot需求,也会造成死锁
RM以单线程同步模式向TM ( Transaction Manager ) 分配Slot请求,会造成等待时间更长。
针对上述问题,我们提出了以下几点改动:
采用Eager调度模式 ( 确保所有的资源都申请到后才开始运行 )
使用FIFO ( 先进先出队 ) 模式申请资源 ( 确保当前Job的资源分配结束后才开始下一个Job的资源分配 )
将单线程同步模式改为多线程异步模式,减少任务启动时间和执行时间
② 针对source的优化
在ROLAP的执行场景中,所有数据都是通过扫描原始数据表后进行处理;因此,基于Source的读取性能非常关键,直接影响Job的执行效率。
Project&Filter下堆:
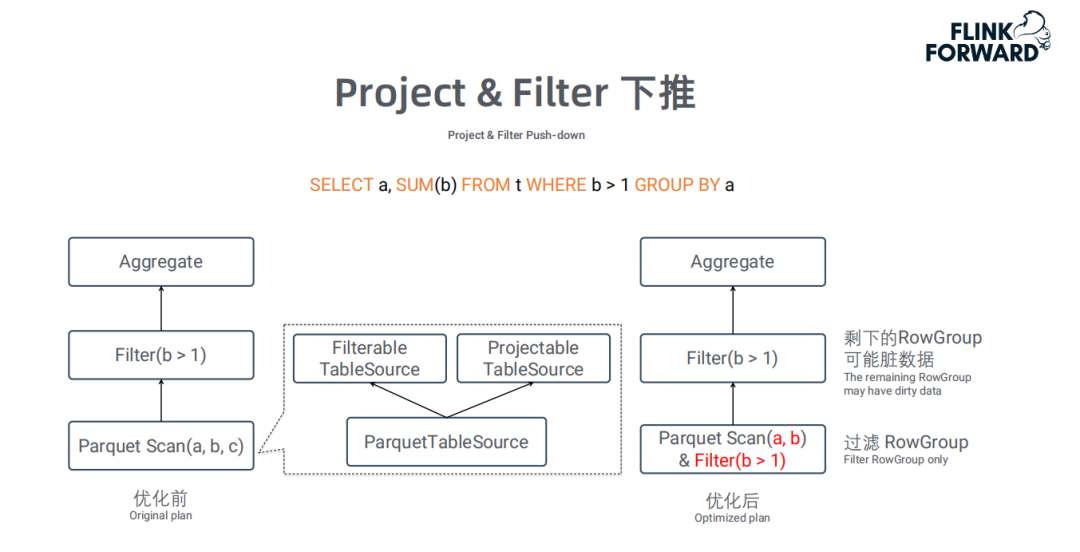
像Parquet这类的列存文件格式,支持按需读取相所需列,同时支持RowGroup级别的过滤。利用该特性,可以将Project和Filter下推到TableSource,从而只需要扫描Query中涉及的字段和满足条件的RowGroup,大大提升读取效率。
Aggregate下堆:

这个优化也是充分利用了TableSource的特性:例如Parquet文件的metadata中已经存储了每个RowGroup的统计信息 ( 如 max、min等 ),因此在做max、min这类聚合统计时,可直接读取metadata信息,而不需要先读取所有原始数据再计算。
③ 在没有统计信息场景下做的优化
消除CrossJoin:
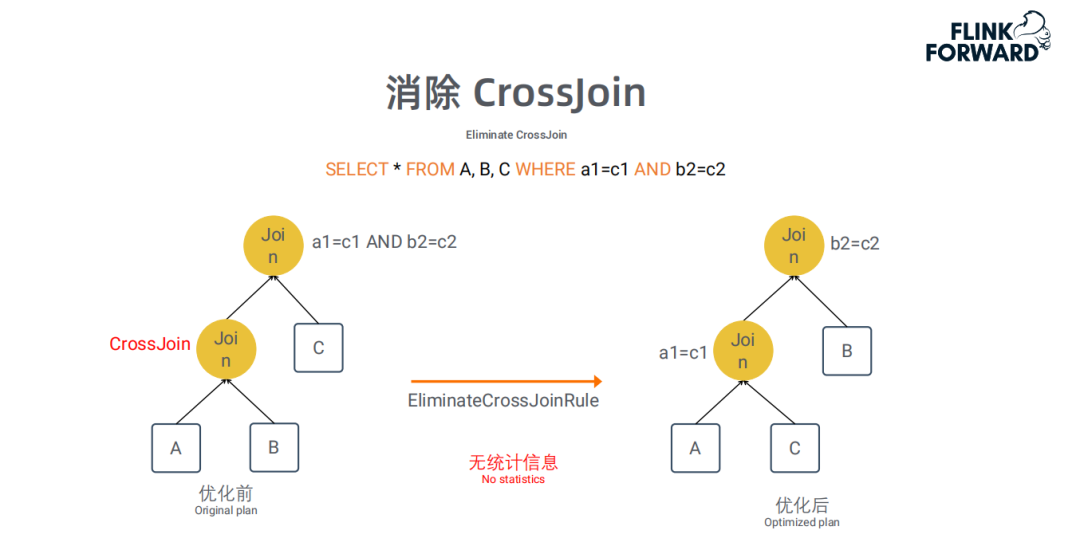
CrossJoin是没有任何Join条件,将Join的两张表的数据做笛卡尔积,导致Join的结果膨胀非常厉害,这类Join应该尽量避免。我们对含有CrossJoin的Plan进行改写:将有join条件的表格先做join ( 通常会因为一些数据Join不上而减少数据 ),从而提高执行效率。这是一个确定性的改写,即使在没有统计信息的情况下,也可以使用该优化。
自适应的Local Aggregate:
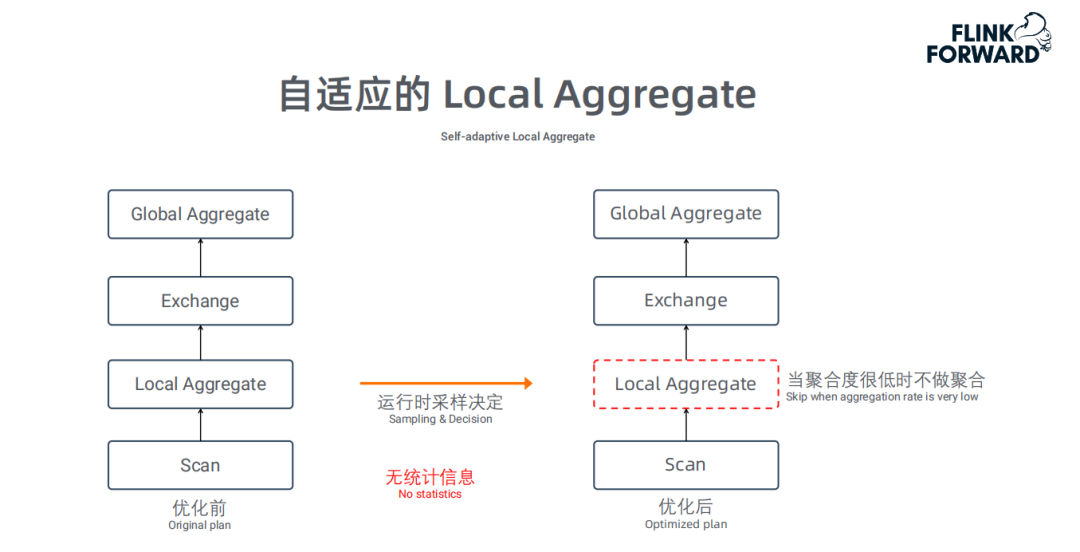
通常情况下,两阶段的Aggregate是非常高效的,因为LocalAggregate能聚合大量数据,导致Shuffle的数据量会变少。但是当LocalAggregate的聚合度很低的时候, Local聚合操作的意义不大,反而会浪费CPU。在没有任何统计信息的情况下,优化器没法决定是否要产生LocalAggregate算子;因此,我们采用运行时采样的方式来判断聚合度,如果聚合度低于设定的阈值,我们将关闭聚合操作,改为仅做数据转发;经我们测试,部分场景有30% 的性能提升。
3. 测试结果

上图是Flink和Presto基于1T数据做的SSB ( Star Schema Benchmark ) 测试,从图中可以看出 Flink和Presto整体上不相上下,甚至有些Query Flink性能优于Presto。注:Flink OLAP从开始到嘉宾分享时,只有3个月时间。
1. Apache Flink OLAP在数据探查上的应用
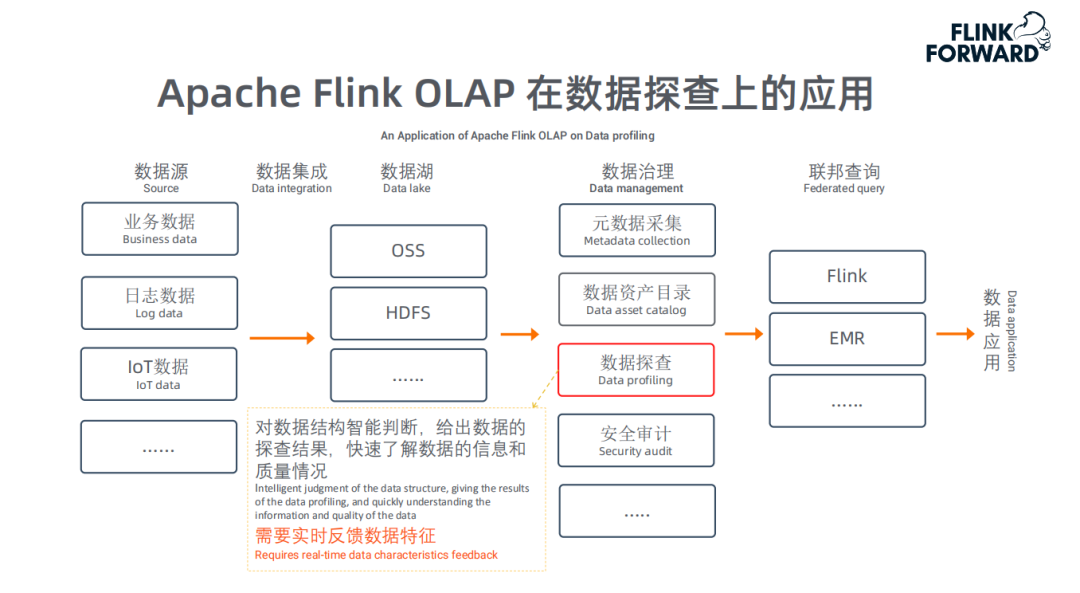
上图描述了一个数据湖应用的完整架构,Flink OLAP主要用于"数据探查"。数据探查是对数据结构做智能判断,给出数据的探查结果,快速了解数据的信息和质量情况。即用户可以在管控平台上了解数据湖中任意一份数据的数据特性。用户通过Web交互操作选择相应的表和指标后立即展示相关结果指标,因此要求低延迟、实时反馈。而且数据湖中很多数据没有任何统计信息;前述的各种查询、聚合层面的优化,主要为这类场景服务。
2. 整体架构

上图是这类应用的整体架构。整套服务托管到Kubernetes上,最终访问的数据是OSS;目前这套架构正在阿里云上做公测,邀请广大用户试用。
推回社区:目前所有工作都是基于内部Flink,希望推回社区;
资源隔离:后期很多功能的开发和优化会围绕多Query运行时的"资源隔离";
优化&性能:围绕OLAP的特性,在此场景下会进一步做优化和性能提升等方面的工作。
专注大数据技术、架构、实战
关注我,带你不同角度看数据架构

本文分享自微信公众号 - 大数据每日哔哔(bb-bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Apache Flink OLAP引擎性能优化及应用相关推荐
- Flink从入门到精通100篇(二十二)-Apache Flink OLAP引擎性能优化及应用
前言 本次分享的主题为Apache Flink新场景--OLAP引擎,主要内容包括: 背景介绍 Apache Flink OLAP引擎 案例介绍 未来计划 1. OLAP及其分类 OLAP是一种让用户 ...
- Flink 新场景:OLAP 引擎性能优化及应用案例
摘要:本文由阿里巴巴技术专家贺小令(晓令)分享,主要介绍 Apache Flink 新场景 OLAP 引擎,内容分为以下四部分: 背景介绍 Flink OLAP 引擎 案例介绍 未来计划 一.背景介绍 ...
- OLAP引擎调研 —— OLAP引擎性能对比分析
涉及到的OLAP: 这里主要是查询网上的一些资料,总结整理,调研涉及的OLAP引擎主要有Kylin.Impala.Kudu.Presto.Druid.Clickhouse.Doris.TiDB.Haw ...
- 选择适合自己的 OLAP 引擎,干货
摘要:本文主要介绍了主流开源的OLAP引擎:Hive.Sparksql.Presto.Kylin.Impala.Druid.Clickhouse 等,逐一介绍了每一款开源 OLAP 引擎,包含架构.优 ...
- Apache Flink新场景——OLAP引擎
最近我们也正打算做OLAP分析平台,在调研的过程中,发现已有的成熟技术只能满足我们的部分需求,相信大家也有这样的困惑,本文分享的是来自阿里巴巴集团的技术专家贺小令分享为什么选择使用 Flink 作为新 ...
- Apache之三种工作模式和配置性能优化
1 Apache的3种模式和版本 Apache目前一共有三种稳定的MPM(Multi-Processing Module,多进程处理模块)模式,它们分别是prefork,worker和event. 我 ...
- 【MySQL】性能优化
文章目录 一.引言 1.1 研究背景 1.2 目的和方法论 二.数据库性能优化的基础知识 2.1 数据库设计原则 2.1.1遵循范式设计 2.1.2. 字段类型选择 2.1.3. 数据表分离 2.1. ...
- 叮咚买菜基于 Apache Doris 统一 OLAP 引擎的应用实践
导读: 随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时 OLAP 数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高 ...
- Apache Flink 在京东的实践与优化
简介: Flink 助力京东实时计算平台朝着批流一体的方向演进. 本文整理自京东高级技术专家付海涛在 Flink Forward Asia 2020 分享的议题<Apache Flink 在京东 ...
最新文章
- 如何利用Seaborn绘制热力图?
- vue-cli3.0控制台体验
- Oracle 触发器(上)
- 杭州登山地图是谁开发的_好天气继续,重阳节登高,五条杭州登山线路奉上
- Shell脚本编程之(二)简单的Shell脚本练习
- 易语言-MD5加密16位和32位方法
- ora01033是什么错误linux,Oracle错误:ORA-01033
- 计算机科学理论数学研讨会,2017年奇异摄动理论及其应用学术研讨会会议-上海交通大学数学系.DOC...
- 客户端无法向springcloud注册中心注册服务,提示连接超时
- Ubuntu 锁屏后键盘无法输入密码
- 智能水杯设计方案_智能水杯方案的结构、理念、特点
- 威联通212-P 安装远程迅雷,docker安装远程迅雷
- presenting view controller
- 2020年6月电子学会Python等级考试试卷(三级)考题解析
- 计算机网络 划分子网构造超网
- [Jzoj] 2198.简单数迷
- 樊登读书会终身成长读后感_《终身成长》读后感三篇
- 动画程序时长缩放是什么意思_1分钟做出高逼格动画!PPT中自带的小功能帮你一键搞定!...
- Linux-Samba的使用
- 软件架构图的艺术与从单体架构到异地多活,开心的学java架构