分析SQL Server备份
介绍 (Introduction)
Database backups are important and always something you should have in any environment. Outside of needing them to restore a given database they have some information that can be useful in certain situations. One situation I found them convenient is with consolidation projects. If the databases are online you can obviously go to the source SQL Server instance to gather that information, but as a consultant I don’t necessarily have access to every environment. You may have the same issue if you are being brought into a project and your customer or department manager just wants you to advise on how you would setup the server. One easy request is to have them point you where the backups are stored and ensure you have access to the files.
数据库备份非常重要,并且在任何环境中都应始终具有备份功能。 除了需要他们还原给定的数据库外,他们还有一些在某些情况下有用的信息。 我发现它们很方便的一种情况是合并项目。 如果数据库在线,则显然可以转到源SQL Server实例来收集该信息,但是作为顾问,我不一定可以访问每个环境。 如果您被带入一个项目,而您的客户或部门经理只是希望您就如何设置服务器提供建议,则可能会遇到相同的问题。 一个简单的要求是让他们指出备份的存储位置,并确保您可以访问文件。
The backup of a database can tell you everything from the compatibility level of the database to the date the database was created. You can find out the physical file names, size, and even the disk block size where the database was stored on the source server. The size is the information I am most interested in with consolidation projects. I can utilize this to analyze how much storage space I will need for the new server, and work out how I am going to need that storage carved up.
数据库的备份可以告诉您从数据库的兼容性级别到创建数据库的日期的所有信息。 您可以找到物理文件名,大小,甚至是源服务器上存储数据库的磁盘块大小。 大小是我对合并项目最感兴趣的信息。 我可以利用它来分析新服务器将需要多少存储空间,并确定需要多少存储空间。
After I get all that information together I pull it into Excel and then utilize pivot tables to calculate out the storage totals for all the databases, and can also create tables on drive letter or file type. I found PowerShell to be the best method, for me, to pull all the information out of the backup files into a format I could bring into Excel. I did actually consider writing PowerShell that would put it directly into Excel for me but that is not a strong area I use often so decided against it for right now. In this article I want to share the tool I created for this in PowerShell. I will then go through how I build the Pivot tables in Excel.
将所有信息汇总在一起后,将其放入Excel,然后利用数据透视表计算出所有数据库的存储总量,还可以创建有关驱动器号或文件类型的表。 对于我来说,我发现PowerShell是将备份文件中的所有信息提取为可导入Excel的格式的最佳方法。 实际上,我确实考虑过编写PowerShell,可以直接将它放入Excel中,但这并不是我经常选择的一个强项,因此现在就决定反对它。 在本文中,我想分享我在PowerShell中为此创建的工具。 然后,我将介绍如何在Excel中构建数据透视表。
剧本 (The Script)
Let me introduce you to, “GetBackupInformation.ps1”. This script will look like it does a good bit, but is pretty basic. I have included help information along with comments in the script itself to help with two things: (1) You learn how to use the script and (2) you possibly learn some new things with PowerShell. A few points about this script:
让我向您介绍“ GetBackupInformation.ps1”。 这个脚本看起来不错,但是很基础。 我在脚本本身中包括了帮助信息以及注释,以帮助您完成两件事:(1)您学习如何使用脚本,(2)您可能会使用PowerShell学习一些新东西。 有关此脚本的几点说明:
- Minimum required is PowerShell 3.0 or higher. 最低要求为PowerShell 3.0或更高版本。
- You will need access to at least one SQL Server instance, but it can be Express Edition. 您将需要访问至少一个SQL Server实例,但它可以是Express Edition。
- ** **
- The Connection String and Delimiter parameters I set to default vales, so you can change those to your environment or pass them each time. 我将“连接字符串”和“定界符”参数设置为默认值,因此您可以将其更改为您的环境或每次传递它们。
** I added the ability for this script to output to the console in the event you may want to send this data to another source altogether (Power BI, database, etc.). It is up to you once you have the output to take it and do what you want.
**我添加了此脚本的功能,以便在您可能希望将这些数据完全发送到另一个源(Power BI,数据库等)的情况下输出到控制台。 一旦获得输出并执行所需的操作,就取决于您。
The background of this script came from having to use this process a few times, I decided to finally sit down and make it more robust. It could have been made complex by using SMO to read the backup files but I like shortcuts. I settled on just using T-SQL RESTORE command to read the backup file information, this is the reason a SQL Server instance is required. The script will simply execute “RESTORE FILELISTONLY” and “RESTORE HEADERONLY” against each backup file path that is passed to the script, which even on large backups these commands should only take a few seconds to execute, (should). The script will handle reading a single backup, multiple backup files, or a single backup file with multiple backups (backup set).
该脚本的背景源于不得不使用此过程几次,我决定最终坐下来,使其更加强大。 使用SMO读取备份文件可能会使它变得复杂,但是我喜欢快捷方式。 我决定仅使用T-SQL RESTORE命令读取备份文件信息,这就是需要SQL Server实例的原因。 该脚本将仅对传递给该脚本的每个备份文件路径执行“ RESTORE FILELISTONLY”和“ RESTORE HEADERONLY”,即使在大型备份中,这些命令也只需几秒钟即可执行(应该)。 该脚本将处理读取单个备份,多个备份文件或具有多个备份(备份集)的单个备份文件。
<#.SYNOPSISScript to pull out information about backup files.DESCRIPTIONScript to pull out information of a single or multiple backup files.PARAMETER connectionStringString. Connection string to connect to SQL Server instance..PARAMETER bacupfilesSystem.IO.FileInfo array. File information array..PARAMETER csvFileString. Full path to CSV file for output of backup information, file is deleted if it exist..PARAMETER delimiterString. Delimiter for CSV file..EXAMPLEOutput backup information to console of all backups in directory, using SQL Server instance on local hostGetBackupInformation -cn "Server=localhost;Integrated Security=true;Initial Catalog=master;" -backupFiles (Get-ChildItem C:\temp\backups).EXAMPLEOutput backup information of single backup to console, using SQL Server instance on local hostGetBackupInformation -cn "Server=localhost;Integrated Security=true;Initial Catalog=master;" -backupFiles (Get-ChildItem C:\temp\backups\MyBackup.bak).EXAMPLEOutput backup information to CSV of all backups in directory, using SQL Server instance on local hostGetBackupInformation -cn "Server=localhost;Integrated Security=true;Initial Catalog=master;" -backupFiles (Get-ChildItem C:\temp\backups) -csvFile C:\temp\BackupInfo.csv -delimiter "|"
#>
[cmdletbinding()]
param([Parameter(Mandatory = $false,Position = 0)][Alias("cn")][string]$connectionString = "Server=localhost\number12;Integrated Security=true;Initial Catalog=master;",[Parameter(Mandatory = $false,Position = 1)][Alias("bkfiles")][System.IO.FileInfo[]]$backupFiles,[Parameter(Mandatory = $false,Position = 2)][Alias("csv")][string]$csvFile,[Parameter(Mandatory = $false,Position = 3)][string]$delimiter = "|"
)$sqlcn = New-Object System.Data.SqlClient.SqlConnection$sqlcn.ConnectionString = $connectionStringtry {$sqlcn.Open();}catch{$errText = $error[0].ToString()if ($rrText.Contains("Failed to connect")){Write-Verbose "Connection failed."Return "Connection failed to $server"$error[0] | select *}}if ($csvFile) {if (Test-Path $csvFile) {Remove-Item $csvFile -Force}}$result = [pscustomobject]@{BackupFile=$null; DatabaseName=$null; CompatibilityLevel=0; RecoveryModel=$null; LogicalName=$null; FileGroupName=$null; sizeMB=0; sizeGB=0; Type=$null; LocalDrive=$null}foreach ($b in $backupFiles) {$qryHeader = @"
RESTORE HEADERONLY FROM DISK = N'$($b.FullName)';
"@$sqlcmd = $sqlcn.CreateCommand()$sqlcmd.CommandText= $qryHeader$adp = New-Object System.Data.SqlClient.SqlDataAdapter $sqlcmd$dataHeader = New-Object System.Data.DataSet$adp.Fill($dataHeader) | Out-Null$headerRowCount = $dataHeader.Tables[0].Rows.Countif ($headerRowCount -eq 1) {$qryFilelist = @"
RESTORE FILELISTONLY FROM DISK = N'$($b.FullName)';
"@$sqlcmd.CommandText= $qryFilelist$dataFilelist = New-Object System.Data.DataSet$adp.Fill($dataFilelist) | Out-Null$fileListRowCount = $dataFilelist.Tables[0].Rows.Countfor ($f=0; $fileListRowCount -gt $f; $f++) {$result.BackupFile = $b.Name$result.DatabaseName = $dataHeader.Tables[0].Rows.DatabaseName$result.CompatibilityLevel = $dataHeader.Tables[0].Rows.CompatibilityLevel$result.RecoveryModel = $dataHeader.Tables[0].Rows.RecoveryModel$result.LogicalName = $dataFilelist.Tables[0].Rows[$f].LogicalName$result.FileGroupName = $dataFilelist.Tables[0].Rows[$f].FileGroupName$result.sizeMB = $dataFilelist.Tables[0].Rows[$f].size/1mb$result.sizeGB = $dataFilelist.Tables[0].Rows[$f].size/1gb$result.Type = $dataFilelist.Tables[0].Rows[$f].Type$result.LocalDrive = $nullif ($csvFile) {$result | Export-Csv -Path $csvFile -Delimiter $delimiter -NoClobber -NoTypeInformation -Append}else {$result}} #end for fileListRowCount} # end single backup setelse {#clearing the contents of the dataset$dataFileList.Reset()for ($h=0; $headerRowCount -gt $h; $h++) {#for getting backup info within backup set need to specify file number$fileNum = 1$qryFilelist = @"
RESTORE FILELISTONLY FROM DISK = N'$($b.FullName)' WITH FILE = $($fileNum);
"@$sqlcmd.CommandText= $qryFilelist$dataFilelist = New-Object System.Data.DataSet$adp.Fill($dataFilelist) | Out-Null$fileListRowCount = $dataFilelist.Tables[0].Rows.Countfor ($f=0; $fileListRowCount -gt $f; $f++) {$result.BackupFile = $b.Name$result.DatabaseName = $dataHeader.Tables[0].Rows[$h].DatabaseName$result.CompatibilityLevel = $dataHeader.Tables[0].Rows[$h].CompatibilityLevel$result.RecoveryModel = $dataHeader.Tables[0].Rows[$h].RecoveryModel$result.LogicalName = $dataFilelist.Tables[0].Rows[$f].LogicalName$result.FileGroupName = $dataFilelist.Tables[0].Rows[$f].FileGroupName$result.sizeMB = $dataFilelist.Tables[0].Rows[$f].size/1mb$result.sizeGB = $dataFilelist.Tables[0].Rows[$f].size/1gb$result.Type = $dataFilelist.Tables[0].Rows[$f].Type$result.LocalDrive = $nullif ($csvFile) {$result | Export-Csv -Path $csvFile -Delimiter $delimiter -NoClobber -NoTypeInformation -Append}else {$result}} #end for fileListRowCount#this is to clear the dataset as we are done with te current data$dataFileList.Reset()#incrementing file number to get the next backup set$fileNum++} #end for headerRowCount}} #end foreach file
#close the connection to SQL Server
$sqlcn.Close();#start up Excel automatically by uncommenting below line
#Start-Process Excel.exe示例数据 (Example Data)
The below screen shot illustrates how the script can be used and provides a sample of what backup information I am pulling:
下面的屏幕快照说明了如何使用脚本,并提供了我提取的备份信息的示例:
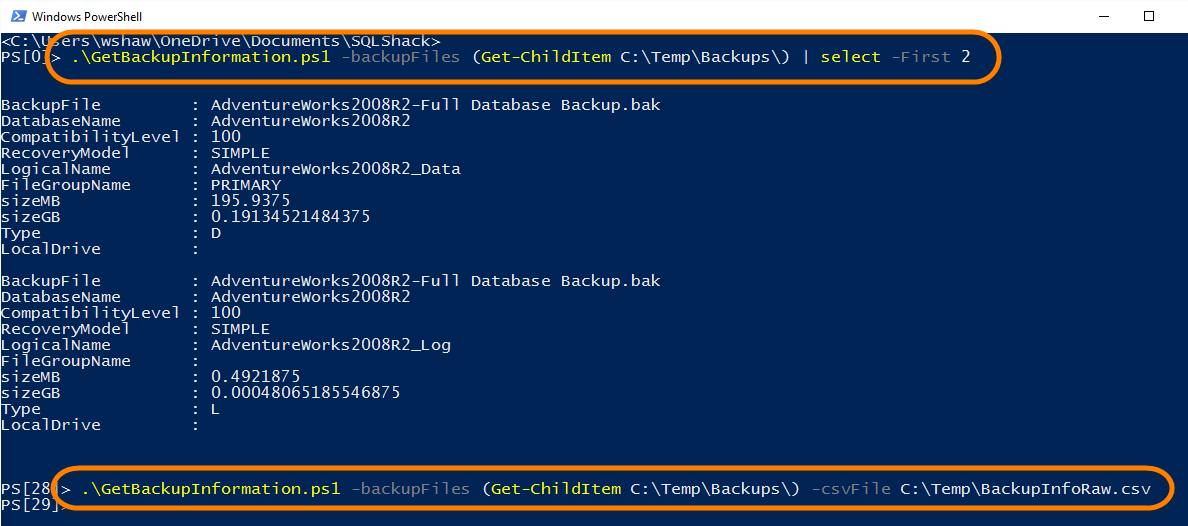
The last command I am utilizing the CSV parameter, and will use that file to import into Excel.
我使用的最后一个命令是CSV参数,并将使用该文件导入Excel。
One note, if you notice the “LocalDrive” column is empty. I went ahead and just added this column, but do not currently populate it until I bring the data into Excel. If you have a standard drive letter mapping for data and log drives, you could add some logic to the script to have it populate this column if you wish.
请注意,如果您注意到“ LocalDrive”列为空。 我继续并仅添加了此列,但是直到将数据带入Excel之前,当前不填充它。 如果您具有用于数据和日志驱动器的标准驱动器号映射,则可以根据需要向脚本添加一些逻辑以使其填充此列。
建立枢轴 (Building the Pivot)
I start out just bringing the CSV file into Excel and doing a bit of formatting. I also filled in the “LocalDrive” columns with some drive letters for reference on drive size.
我刚开始只是将CSV文件导入Excel并进行了一些格式化。 我还用一些驱动器号填充了“ LocalDrive”列,以供参考驱动器大小。
Now you go into the Insert ribbon and click on “PivotTable”:
现在,您进入“插入”功能区,然后单击“数据透视表”:

Click OK
点击确定
A new worksheet is going to be created and you will be presented with something similar to the below screenshot.
将创建一个新的工作表,并且将为您提供类似于以下屏幕截图的内容。
You can now just click on the check box for the data you want to include, and Excel will take a guess where you want it to go (Rows, Columns, etc.). I however tend to just drag and drop where I want it to go.
现在,您只需单击要包含的数据的复选框,Excel就会猜测您要去的数据(行,列等)。 但是,我倾向于将其拖放到想要的位置。
So just drag the following rows to the noted areas:
因此,只需将以下行拖动到指定的区域:
- Rows: DatabaseName 行:DatabaseName
- Columns: LocalDrive 列:LocalDrive
- Values: sizeMB (or sizeGB if you wish) 值:sizeMB(如果需要,则为sizeGB)
In the end it should look something like this:
最后,它应该看起来像这样:
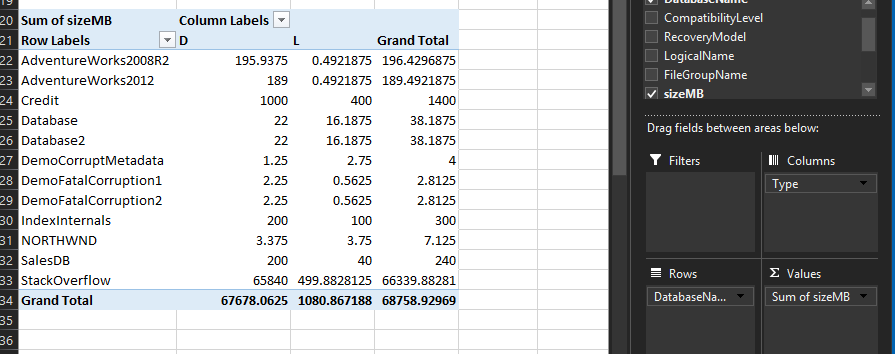
Now I want to add another PivotTable to this same spreadsheet, this new table will show me the size of each database based on “Type” column. You can repeat the above steps and the only change is when you get to the step 2, before you click on OK perform the following step:
现在,我想向该电子表格添加另一个数据透视表,该新表将根据“类型”列向我显示每个数据库的大小。 您可以重复上述步骤,唯一的更改是进入第2步,然后单击“确定”,然后执行以下步骤:
Select “Existing Worksheet”
选择“现有工作表”
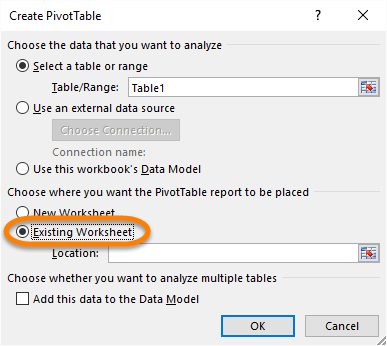
Now click on the location selector
现在点击位置选择器
This is just going to point Excel where you want the new table created.
这只是将Excel指向您要在其中创建新表的位置。
- Click on “Sheet3” 点击“ Sheet3”
- Click on cell “A20” 单击单元格“ A20”
- Click on location selector to back to the previous screen 单击位置选择器以返回上一屏幕
- Click OK. 单击确定。
- To create the next table, you follow same as we did above with the exception that “Columns” you would want to use “Type” instead of “LocalDrive” as we did previously. 要创建下一个表,请按照与上述相同的步骤进行操作,只是要使用“类型”代替“ LocalDrive”来使用“列”。
This should leave you with a table similar to below:
这应该为您提供类似于以下的表格:
摘要 (Summary)
I hope this script will provide you with some insightful information with any consolidation project you may be working on, or even just in your day-to-day work as a DBA. I have found PivotTables in Excel can help make some tasks as a DBA very quick and easy. If you have not noticed this can also be a good tool for visually showing the numbers in a manner upper management can understand why that purchase request is being submitted for more storage.
我希望该脚本将为您提供有关您可能正在从事的任何合并项目甚至是作为DBA的日常工作的一些有见地的信息。 我发现Excel中的数据透视表可以帮助您快速,轻松地完成作为DBA的某些任务。 如果您没有注意到,这也可能是一个很好的工具,可以直观地显示数字,以使高级管理层可以理解为什么要提交该购买请求以用于更多存储。
参考资料 (References)
- Creating Pivot Tables in Excel 在Excel中创建数据透视表
- T-SQL command RESTORE FILELISTONLY T-SQL命令RESTORE FILELISTONLY
- T-SQL command RESTORE HEADERONLY T-SQL命令RESTORE HEADERONLY
翻译自: https://www.sqlshack.com/analyzing-sql-server-backups/
分析SQL Server备份相关推荐
- SQL Server备份的三个恢复模型
在SQL Server 2000中,有无数种备份数据库的方法.无论你的数据库有多大.改变是否频繁,都有满足你的要求的备份策略.让我们看看几种可以在不同环境下工作的基本备份策略. 本文假定你有备份数据库 ...
- SQL点滴12—SQL Server备份还原数据库中的小把戏
原文:SQL点滴12-SQL Server备份还原数据库中的小把戏 备份数据库时出现一个不太了解的错误 ,错误信息"is formatted to support 1 media fami ...
- SQL数据库恢复后出现对象名无效(SQL Server备份还原时造成孤立用户的解决方案
SQL数据库恢复后出现对象名无效(SQL Server备份还原时造成孤立用户的解决方案) 2011-04-18 09:38 以碰到这个烦人的问题,恢复的时候自带了个用户,但怎么也删除不掉,select ...
- oracle ola_Ola HallengrenSQL Server维护解决方案–安装和SQL Server备份解决方案
oracle ola Database administrators tend to use various scripts or applications, to make the daily SQ ...
- MSSQL · 最佳实践 · SQL Server备份策略
摘要 在上一期月报中我们分享了SQL Server三种常见的备份技术及工作方式,本期月报将分享如何充分利用三者的优点来制定SQL Server数据库的备份和还原策略以达到数据库快速灾难恢复能力. 上期 ...
- SQL Server 备份还原造成孤立用户的问题
首先需要了解一下SQL Server登录名和用户名的却别: 登录名:服务器方的一个实体,使用一个登录名只能进入服务器,但是不能让用户访问服务器中的数据库资源.每个登录名的定义存放在master数据库的 ...
- 【SQL Server备份恢复】数据库恢复:对page header的恢复
前两天在论坛,看到有个网友提问,说是: 格式化磁盘前把.mdf和.ldf拷贝出来了,然后格式化完成后在拷贝回去(拷贝前后都没有错误提示,文件大小也一样),在企业管理器中附加数据库出错,提示" ...
- Sql server 备份还原后出现“受限制用户”问题
http://jingyan.baidu.com/article/eb9f7b6dcbf1ea869264e856.html SQL数据库作备份和还原操作几乎是日常性事务了.但某次在对Sql Serv ...
- 使用PowerShell和T-SQL在多服务器环境中规划SQL Server备份和还原策略
介绍 (Introduction) Database availability is critical to every enterprise and conversely, unavailabili ...
最新文章
- TCP/IP协议:链路层
- cas单点登陆。就这一篇就够了!!!!!
- 水晶报表在浏览时,工具栏上的图标变成的X
- C++ NULL nullptr和0的区别
- vue.jsr入门_JSR-308和Checker框架为jOOQ 3.9添加了更多类型安全性
- 【Codeforces 1096D】Easy Problem
- java排序算法原理_排序算法原理与实现(java)
- dbForge mysql数据库比对
- 什么是 Elasticsearch?一篇搞懂
- 职场新人如何高效办公?这10款软件帮到你!
- 吉客云与金蝶云星空集成方案(吉客云主管库存)
- 亲密爱人:《亲密关系》读书笔记
- ps网页效果图转html,Photoshop制作简洁干净的网页效果图
- Ajax上传文件(视频),并获取上传进度、上传速度和剩余时间。
- python父亲节祝福_关于父亲节走心文案 父亲节文案朋友圈
- 《崩坏3》评测:游戏设计中整体性和利用率分析(下)
- SEM竞价推广如何提升流量精准度,增加展现、排名、线索量?
- C语言基础入门48篇_26_身份证号校验程序(以身份证的校验方式是实例加深对数组及函数封装的理解、字符-‘0‘得到字符对应的int类型数字)
- 基于微信运动场地预约小程序 毕业设计毕业论文 开题报告和效果图(基于微信小程序毕业设计题目选题课题)
- 大话设计模式读书笔记之原型模式