impala的详细介绍--图文描述
Impala 是参照google 的新三篇论文Dremel(大批量数据查询工具)的开源实现,功能类似shark(依赖于hive)和Drill(apache),impala 是clouder 公司主导开发并开源,基于hive 并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。是使用cdh 的首选PB 级大数据实时查询分析引擎。(Impala 依赖cdh 是完全没有问题的,官网说可以单独运行,但是他单独运行会出现好多的问题)
参考:
http://www.cloudera.com/products/apache-hadoop/impala.html
http://www.impala.io/index.html
Impala与Shark、sparkSQL、Drill等的简单比较
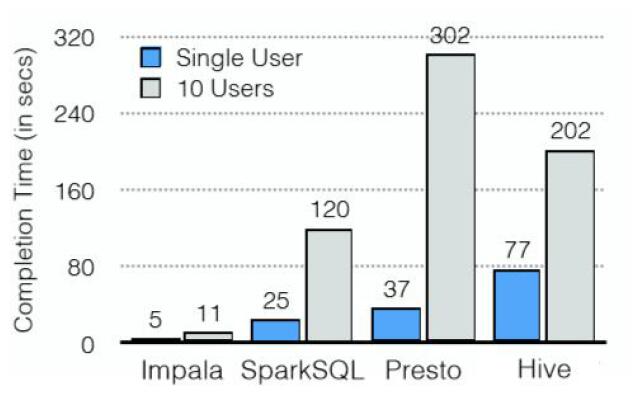
- Impala起步较早,目前能够商用的为数不多的大数据查询引擎之一;
- CDH5不支持sparkSQL;
- Drill起步晚,尚不成熟;
- shark功能和架构上同Impala相似,该项目已经停止开发。
Impala特点
- 基于内存进行计算,能够对PB级数据进行交互式实时查询/分析;
- 无需转换为MR,直接读取HDFS数据
- C++编写,LLVM统一编译运行
- 兼容HiveSQL
- 具有数据仓库的特性,可对hive数据直接做数据分析
- 支持Data Local
- 支持列式存储
- 支持JDBC/ODBC远程访问
- 支持sql92标准,并具有自己的解析器和优化器

Impala劣势
- 对内存依赖大
- C++编写 开源?!(对Java单纯的程序员来说太坑爹了。。。)
- 完全依赖于hive
- 实践过程中 分区超过1w 性能严重下下降(1.4 之前是这样,至于2.0 之后的版本,
就好多了) - 稳定性不如hive
impala与hive的关系
- Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive
的元数据库Metadata,意味着impala元数据都存储在Hive的
metastore中。并且impala兼容Hive的sql解析,实现了Hive的
SQL语义的子集,功能还在不断的完善中 - 也就是说hive活着,impala才能存在,否则随着消失
安装方式
- ClouderaManager
- 手动安装(不建议,太多坑)
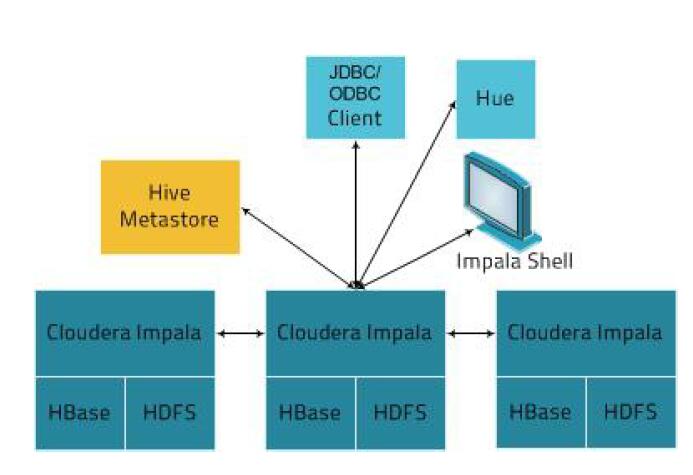
Impala核心组件
对于impala 来讲,是没有主节点的,而要理解主节点,impala statestore 和catalog server两个角色,就具备集群调节的功能,根据以上的特点,对impala 进行配置优化配置impala 内存,每一个deamon 都需要配置内存,因为真正做查询工作的就是deamon 所在的节点,所以impala 的总内存,就是所有deamon 节点的内存之和;如果要在哪台机器上面汇总,就需要在那一台机器上的内存调大一些;我们了解到的,真正提供查询的是deamon,那么我们连接哪一台呢?Impala,你可以连接其中deamon 任何一个都行,可以根据自己的需求来,(1)当你查询的量相对大的时候,你就连接内存大的机器,(2)当每台机器都适合查询的情况下也可以随机找一台机器,自己写一个轮询或者权重算法;解决高并发问题
- Statestore Daemon
- 负责收集分布在集群中各个impalad 进程的资源信息,各节点健康状况、同步节点信息.
负责query 的调度.(并非绝对,倘若他存在,那就帮忙,若不存在,那就不用他)
对于一个正常运转的集群,并不是一个关键进程.
- 负责收集分布在集群中各个impalad 进程的资源信息,各节点健康状况、同步节点信息.
- Catalog Daemon(1.2 版本之后才加入)
- 把impala表的metadata分发到各个impalad 中,说他是基于hive 的,所以就需要metadata数据分到impalad 中,以前没有此进程,就是手动来进行同步的。虽然之后加入了,但是也没有那么智能,并不是保证所有的数据都能同步,比如你插入一些数据,他可以把数据发到其他节点,但是比如创建表ddl 语句,建议去手动做一下。接收来自statestore 的所有请求,当impala deamon节点插入或者查询数据时候(数据改变的时候),他把自己的操作结果汇报给state deamon,然后state store 请求catelog deamon,告知重新更新元数据信息给impalad 中,所以catalog deamon 与statedeamon 放到一台机器上,而且不建议在此机器上再去安装impala deamon 进程,避免造成提供查询造成集群管理出问题
- Impala Daemon(主要来提供查询)
- 主要接收查询请求,接收client、hue、jdbc 或者odbc 请求、query 执行并返回给中心协调节点(对应的服务实例是impalad)子节点上的守护进程,负责向statestore 保持通信,汇报工作

- 主要接收查询请求,接收client、hue、jdbc 或者odbc 请求、query 执行并返回给中心协调节点(对应的服务实例是impalad)子节点上的守护进程,负责向statestore 保持通信,汇报工作
Impala架构

- Client(shell,jdbc,odbc)发送请求到impalad 进程上,发送节点可以是随机的,impalad 之间,也有相互通信
- Statestore 和catelog 划到同一节点,目的就是这两个进程在协调工作时候,避免因网络问题造成失败
- Hive metastore 是比较重要的,此时statestore 和catelog 通信,将数据同步到其他节点
- Impalad 最好与hdfsDataNode 在同一节点,这样能更快速的查询计算,然后返回结果即可(理想状态的就是数据本地化)
- Impalad 里面包含三个组件
- Query planner(查询解析器)
- 将我们的字符串sql 语句解释成为执行计划,
- ii. Query coordinator(中心协调节点)
- 由这个组件来指定来查询的主节点(头),指定好之后通知其他节点我的主节点作用,待你们查询完成之后的结果,返回给头节点
- Query executor(查询执行器)
- 而做查询工作的是就是executor
- Query planner(查询解析器)
- Impalad 里面包含三个组件
impala 外部shell
- -h(--help)帮助-------查看所有命令的帮助文档
- -r(--refresh_after_connect)刷新所有元数据(当hive 创建数据的时候,你需要刷新到,才能看到hive 元数据的改变)整体刷新*---全量刷新,万不得已才能用;不建议定时去刷新hive 源数据,数据量太大时候,一个刷新,很有可能会挂掉;创建hive 表,然后刷新。
- -B(--delimited)去格式化输出* 大量数据加入格式化,性能受到影响
- --output_delimiter=character 指定分隔符与其他命令整合
- --print_header 打印列名(去格式化,但是显示列名字)
- -v 查看对应版本(会有坑)
- Impala 的查询会以最新版本为准,如果版本不一致,会造成查询结果失败
- mpala-shell 与impala 的版本查看,必须版本一致
- -f 执行查询文件*
select name,count(name) as name_count from person group by name--创建包含该sql的文件- --query_file 指定查询文件(建议sql 语句写到一行,因为shell 会读取文件一行一行的命令)
- Impala-shell --query_file=xxx
- -i 连接到对应的impalad
- --impalad 指定impalad 去执行任务
- --fe_port 指定备用端口(通常不用去指定)
- -o 保存执行结果到文件***
- --output_file 指定输出文件名
- 组合应用:
impala-shell -B --Print_header -f test.sss -o result.txt Impala-shell -B -f test.xxx -o result.txt非重要的shell
- mpala-shell 命令用法:
- Impala-shell --user root
- -u 执行某一用户运行impala-shell
- --user 指定用户执行shell 命令
- --ssl 通过ssl 验证方式方式执行
- --ca_cert 指定第三方用户证书
- --config_file 临时指定配置文件
- -p 显示执行计划
- --quiet 不显示多余信息
impala-shell -q "select * from impala.rstest limit 5" -p ###这个命令虽然很有用,但是我们使用的时候很少,因为内部shell 有一个更好用的profile
- --quiet 不显示多余信息
-q 不进入impala-shell 执行查询
-c 忽略错误语句继续执行
-d 指定进入某一个数据库
Impala-shell -d database(database 指定数据库名称)
- -u 执行某一用户运行impala-shell
- Impala-shell --user root
- mpala-shell 命令用法:
Impala-shell(内部shell)
- 帮助选项
- help
- 连接到某个impalad 实例
- connect <hostname>
- 刷新某个表元数据
- *refresh <tablename> //属于增量刷新
- 刷新元数据库
- *invalidate metadata //全量刷新,性能消耗较大
- 显示一个查询的执行计划及各步骤信息
- *explain <sql> //可以设置set explain_level 四个级别0开始,一般用2级别即可,查看执行计划等详细信息
- 不退出impala-shell 执行操作系统命令
- shell <shell>
- shell ls
- 显示查询底层信息(底层执行计划,用于性能优化)
- *profile //在查询完成之后执行
- 执行计划存储下来分析
impala-shell -q "select name from person" -p >> impalalog.123 - 查看StateStore(监控管理)
– http://cdh1:25020/
- 查看Catalog(监控管理)
– http://cdh2:25010/
Impala 存储与分区
- 需要注意的是impala 除了全部支持hive 的文件类型,自己还支持parquet 这样的文件类型,当然了,这个类型并不是impala 自己独有的,比如spark sql,shark sql 都支持这样的类型;Rcfile 本身快一些,但是不如text 才做起来更方便

- 压缩方式

- 添加分区方式
--1、partitioned by 创建表时,添加该字段指定分区列表 --2、使用alter table 进行分区的添加和删除操作 • create table t_person(id int, name string, age int) partitioned by (type string); • alter table t_person add partition (type='man'); • alter table t_person drop partition (type='man'); • alter table t_person drop partition (sex='man',type='boss'); 分区内添加数据
insert into t_person partition (type='boss') values (1,'zhangsan',18),(2,'lisi',23)insert into t_person partition (type='coder') values (3,'wangwu',22),(4,'zhaoliu’,28),(5,'tianqi',24)查询指定分区数据
select id,name from t_person where type='coder'
impala-SQL、JDBC、性能优化
- 加载数据:
- insert 语句:插入数据时每条数据产生一个数据文件,不建议用此方式加载批量数据
- load data 方式:在进行批量插入时使用这种方式比较合适
- 来自中间表:此种方式使用于从一个小文件较多的大表中读取文件并写入新的表生产少量的数据文件。也可以通过此种方式进行格式转换。
- 空值处理:
- impala 将“\n”表示为NULL,在结合sqoop 使用是注意做相应的空字段过滤,也可以使用以下方式进行处理:
alter table name set tblproperties (“serialization.null.format”=“null”) 配置:
– impala.driver=org.apache.hive.jdbc.HiveDriver – impala.url=jdbc:hive2://node2:21050/;auth=noSasl – impala.username= – impala.password=尽量使用PreparedStatement执行SQL语句:
性能上PreparedStatement要好于Statement
Statement存在查询不出数据的情况
执行计划
– 查询sql执行之前,先对该sql做一个分析,列出需要完成这一项查询的
详细方案(命令:explain sql、profile)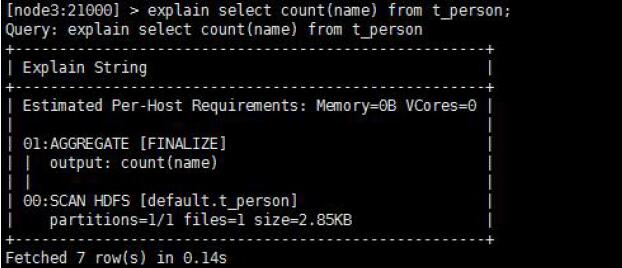
总结:
1、SQL优化,使用之前调用执行计划
2、选择合适的文件格式进行存储
3、避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间
表)
4、使用合适的分区技术,根据分区粒度测算
5、使用compute stats进行表信息搜集
6、网络io的优化:
a.避免把整个数据发送到客户端
b.尽可能的做条件过滤
c.使用limit字句
d.输出文件时,避免使用美化输出
7、使用profile输出底层信息计划,在做相应环境优化
Impala SQL VS HiveQL
- 支持数据类型
- INT
- TINYINT
- SMALLINT
- BIGINT
- BOOLEAN
- CHAR
- VARCHAR
- STRING
- FLOAT
- DOUBLE
- REAL
- DECIMAL
- TIMESTAMP
- CDH5.5版本以后才支持一下类型
- ARRAY
- MAP
- STRUCT
- Complex
- 此外,Impala不支持HiveQL以下特性:
- – 可扩展机制,例如:TRANSFORM、自定义文件格式、自定义SerDes
- – XML、JSON函数
- – 某些聚合函数:
- covar_pop, covar_samp, corr, percentile,percentile_approx, histogram_numeric, collect_set
- Impala仅支持:AVG,COUNT,MAX,MIN,SUM
- – 多Distinct查询
- – HDF、UDAF
Impala SQL(和Hive类似)
- 视图
- – 创建视图:create view v1 as select count(id) as total from tab_3 ;
- – 查询视图:select * from v1;
- – 查看视图定义:describe formatted v1
- 注意:
- 不能向impala的视图进行插入操作
- insert 表可以来自视图
impala的详细介绍--图文描述相关推荐
- Cadence OrCAD Capture管脚Passive和Power属性功能详细介绍图文教程
⏪<上一篇>
- 【WiFi密码破解详细图文教程】ZOL仅此一份 详细介绍从CDlinux U盘启动到设置扫描破解
From: http://softbbs.zol.com.cn/1/32_7991.html 每天都能看到有不少网友在回复论坛之前发布的一篇破解WiFi密码的帖子,并伴随各种疑问.今天流云就为大家准备 ...
- 【WiFi密码破解详细图文教程】ZOL仅此一份 详细介绍从CDlinux U盘启动到设置扫描破解-破解软件论坛-ZOL中关村在线...
[WiFi密码破解详细图文教程]ZOL仅此一份 详细介绍从CDlinux U盘启动到设置扫描破解-破解软件论坛-ZOL中关村在线 好了,先说下提前要准备的东东吧: 1.U盘一枚,最小1G空间.需进行格 ...
- android飞行模式开启wifi,手机在飞行模式下怎么使用WiFi? 飞行模式下开启WiFi的方法图文教程详细介绍[多图]...
类型: 大小: 评分: 平台: 标签: 手机在飞行模式下怎么使用WiFi?相信很多朋友都还不太清楚吧?没关系,下面是友情小编搜集相关资料整理出来的手机在飞行模式下开启WiFi的方法图文教程详细介绍,希 ...
- 微型计算机怎么拆后盖,魅蓝E3后盖怎么打开?魅蓝E3手机后壳拆解步骤图文详细介绍...
魅蓝E3怎么拆开后盖?3月21日下午,魅蓝发布了"玩得流畅 拍得清晰"的魅蓝E3中端新机,作为E2的后作,带来了更好的拍照水准,另外还提升了处理器和其他特色功能等.而本文主要给大家 ...
- c语言%.6s和%6s的差别,6s和6的区别有哪些 各方面详细介绍【图文】
苹果 手机大家都听说过吧,它现在是很多年轻人追捧的对象,尤其是对于女性朋友来说,苹果手机是美国的一个手机品牌.在大陆市场非常受欢迎,它的价格虽然高,但是它的销量非常高,目前最为流行的款式就是苹果6S了 ...
- 红黑树(一)之 原理和算法详细介绍---转帖
目录 1 红黑树的介绍 2 红黑树的应用 3 红黑树的时间复杂度和相关证明 4 红黑树的基本操作(一) 左旋和右旋 5 红黑树的基本操作(二) 添加 6 红黑树的基本操作(三) 删除 作者:Sky W ...
- 红黑树(一)之 原理和算法详细介绍
出处:http://www.cnblogs.com/skywang12345/p/3245399.html 概要 目录 1 红黑树的介绍 2 红黑树的应用 3 红黑树的时间复杂度和相关证明 4 红黑树 ...
- http协议编程java_Java与Http协议的详细介绍
搜索热词 Java与Http协议的详细介绍 引言 http(超文本传输协议)是一个基于请求与响应模式的.无状态的.应用层的协议,常基于TCP的连接方式.HTTP协议的主要特点是: 1.支持客户/服务器 ...
最新文章
- 【ACM】杭电OJ 1001
- 向高手进阶,从 0 开始手写实现一个 RPC 框架!
- pokemon 下载 android,宝可梦pokemon home
- 程序猿修仙之路--数据结构之你是否真的懂数组? c#socket TCP同步网络通信 用lambda表达式树替代反射 ASP.NET MVC如何做一个简单的非法登录拦截...
- websocket没准备好如何解决_那些很重要,但是不常用的技术,websocket
- Apsara Stack 技术百科 | 浅谈阿里云混合云新一代运维平台演进与实践
- 协方差矩阵(covariance matrix)
- python实现多个excel文件两种方式合并:多表单形式合并、单表单(增加标识列来区分不同文件)形式合并
- 软件测试是做什么的?具体工作内容?
- 西门子plc烧录单片机_用51单片机做简易PLC
- 信号与系统matlab实验报告,信号与系统实验报告.doc
- linux拼音五笔输入法下载软件,自已动手制作Linux下拼音五笔输入法
- Hexo+Github轻松搭建个人博客
- MC74HC595驱动
- 前端面试 计算机网络篇
- adobe flash media service5简单使用
- 两因素重复测量方差分析,史上最详细SPSS教程!
- linux搭建本地YUM源配置详细步骤
- Flink入门教程(三)——窗口(一)
- Samplitude pro x4完美汉化破解版|Samplitude pro x4 64位完美汉化破解版(附汉化包)下载 v15.0.1.139