如何用python爬取数据_如何使用python爬取知乎数据并做简单分析
原标题:如何使用python爬取知乎数据并做简单分析
一、使用的技术栈:
爬虫:python27 +requests+json+bs4+time
分析工具: ELK套件
开发工具:pycharm
数据成果简单的可视化分析
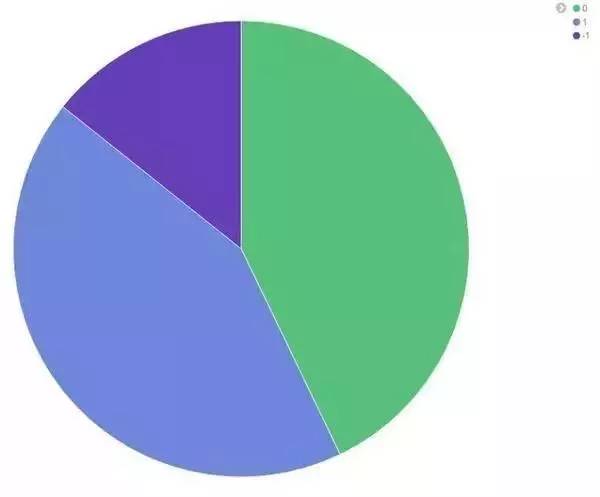
1.性别分布
0 绿色代表的是男性 ^ . ^
1 代表的是女性
-1 性别不确定
可见知乎的用户男性颇多。
二、粉丝最多的top30
粉丝最多的前三十名:依次是张佳玮、李开复、黄继新等等,去知乎上查这些人,也差不多这个排名,说明爬取的数据具有一定的说服力。

三、写文章最多的top30

四、爬虫架构
爬虫架构图如下:

说明:
选择一个活跃的用户(比如李开复)的url作为入口url.并将已爬取的url存在set中。
抓取内容,并解析该用户的关注的用户的列表url,添加这些url到另一个set中,并用已爬取的url作为过滤。
解析该用户的个人信息,并存取到本地磁盘。
logstash取实时的获取本地磁盘的用户数据,并给elsticsearch
kibana和elasticsearch配合,将数据转换成用户友好的可视化图形。
五、编码
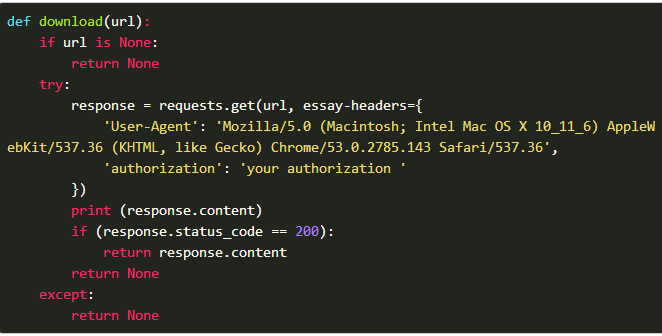
爬取一个url:
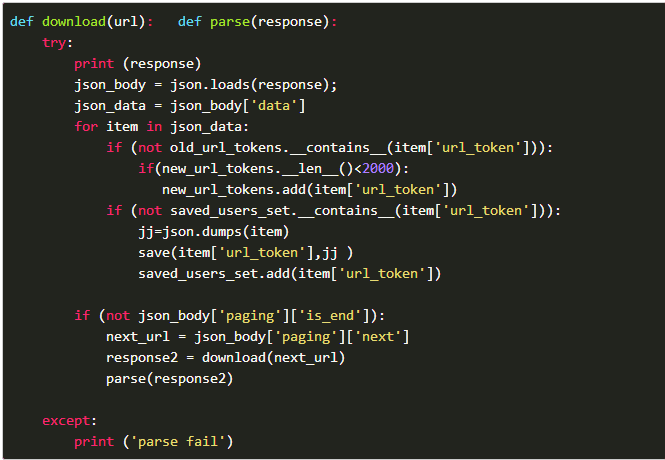
解析内容:
存本地文件:

代码说明:
* 需要修改获取requests请求头的authorization。
* 需要修改你的文件存储路径。
源码下载:点击这里,记得star哦!https://github.com/forezp/ZhihuSpiderMan
六、如何获取authorization
打开chorme,打开https://www.zhihu.com/,
登陆,首页随便找个用户,进入他的个人主页,F12(或鼠标右键,点检查)

七、可改进的地方
可增加线程池,提高爬虫效率
存储url的时候我才用的set(),并且采用缓存策略,最多只存2000个url,防止内存不够,其实可以存在redis中。
存储爬取后的用户我说采取的是本地文件的方式,更好的方式应该是存在mongodb中。
对爬取的用户应该有一个信息的过滤,比如用户的粉丝数需要大与100或者参与话题数大于10等才存储。防止抓取了过多的僵尸用户。
八、关于ELK套件
关于elk的套件安装就不讨论了,具体见官网就行了。网站:https://www.elastic.co/
另外logstash的配置文件如下:

从爬取的用户数据可分析的地方很多,比如地域、学历、年龄等等,我就不一一列举了。另外,我觉得爬虫是一件非常有意思的事情,在这个内容消费升级的年代,如何在广阔的互联网的数据海洋中挖掘有价值的数据,是一件值得思考和需不断践行的事情。(本文为方志朋博客原创,请点击阅读原文)返回搜狐,查看更多
责任编辑:
如何用python爬取数据_如何使用python爬取知乎数据并做简单分析相关推荐
- 使用Python爬取“最好大学网”软科中国最好大学排名2019并做可视化分析
使用Python爬取"最好大学网"软科中国最好大学排名2019并做可视化分析 简介 开发环境 爬取数据 1.获取网站页面 2.解析网页内容 3.存储数据 可视化分析 基本设置 显示 ...
- 如何用python爬取数据_入门用Python进行Web爬取数据:为数据科学项目提取数据的有效方法...
作者|LAKSHAY ARORA 编译|Flin 来源|analyticsvidhya 总览 Web抓取是一种从网站提取数据的高效方法(取决于网站的规定) 了解如何使用流行的BeautifulSoup ...
- python能爬取网站后台数据_如何利用Python爬取网站数据?
1.基本方法 其实用python爬取网页很简单,只有简单的几句话 这样就可以获得到页面的内容.接下来再用正则匹配去匹配所需要的内容就行了.但是,真正要做起来,就会有各种各样的细节问题. 2.登录 这是 ...
- 如何用python爬微博数据_怎样用python爬新浪微博大V所有数据?
最近为了做事件分析写了一些微博的爬虫,两个大V总共爬了超70W的微博数据. 官方提供的api有爬取数量上限2000,想爬取的数据大了就不够用了... 果断撸起袖子自己动手!先简单说一下我的思路: 一. ...
- python财务报表预测股票价格_机器学习股票价格预测从爬虫到预测-数据爬取部分...
声明:本文已授权公众号「AI极客研修站」独家发布 前言 各位朋友大家好,小之今天又来给大家带来一些干货了.上篇文章机器学习股票价格预测初级实战是我在刚接触量化交易那会,因为苦于找不到数据源,所以找的一 ...
- python爬取所有数据_入门用Python进行Web爬取数据:为数据科学项目提取数据的有效方法...
作者|LAKSHAY ARORA 编译|Flin 来源|analyticsvidhya 总览 Web抓取是一种从网站提取数据的高效方法(取决于网站的规定) 了解如何使用流行的BeautifulSoup ...
- 如何用python抓取文献_浅谈Python爬虫技术的网页数据抓取与分析
浅谈 Python 爬虫技术的网页数据抓取与分析 吴永聪 [期刊名称] <计算机时代> [年 ( 卷 ), 期] 2019(000)008 [摘要] 近年来 , 随着互联网的发展 , 如何 ...
- python爬取b站数据_如果利用Python爬取B站上千万数据?B站直播都是大屌萌妹吗?...
粉丝独白 说起热门的B站相信很多喜欢玩动漫的,看最有创意的Up主的同学一定非常熟悉.我突发奇想学Python这么久了,为啥不用Python爬取B站中我关注的人,已经关注的人他们关注的人,看看全站里面热 ...
- python获取币安k线数据_如何利用Python 爬取币乎的数据
1LSGO软件技术团队 贡献人:李金原 如果喜欢这里的内容,你能够给我最大的帮助就是转发,告诉你的朋友,鼓励他们一起来学习. If you like the content here, the gre ...
最新文章
- EOJ Monthly 2020.7 Sponsored by TuSimple 部分题解
- 5G与AI深度融合,人类世界即将产生巨变
- 【Unique Binary Search Trees II】cpp
- 使用cpanel后台的“时钟守护作业”功能完成空间的定时全备份
- Redis 常用操作命令
- 数据仓库中两种数据模型的分析比较
- 操作系统之进程管理:5、处理机调度
- 通过函数名字符串调用函数【C语言版】
- Git的一些必备用法
- 66. Landing Page
- python invalid character_python提示invalid character in identifier
- 单片机ISP烧录原理
- 《数据分析思维手册》和《数据分析师的职场真相》全集整理好啦,下载保存!...
- 项目整体管理:结束项目或阶段
- 2060显卡驱动最新版本_如何更新你的显卡驱动程序
- echarts世界地图中英文转换
- QCLOUD APIGATEWAY HTTP header字段整理
- Self-Attention详解
- BugkuCTF-WEB-flag在index里
- 屏幕增强字段如何保存修改记录